
2025-06-04-Wed-T-MySQL
基础
# mysql启动
net start mysql80
net stop mysql80
# 客户端连接
mysql -h 172.168.0.1 -P 3306 -u root -p
数据模型:
- 数据库
- 表
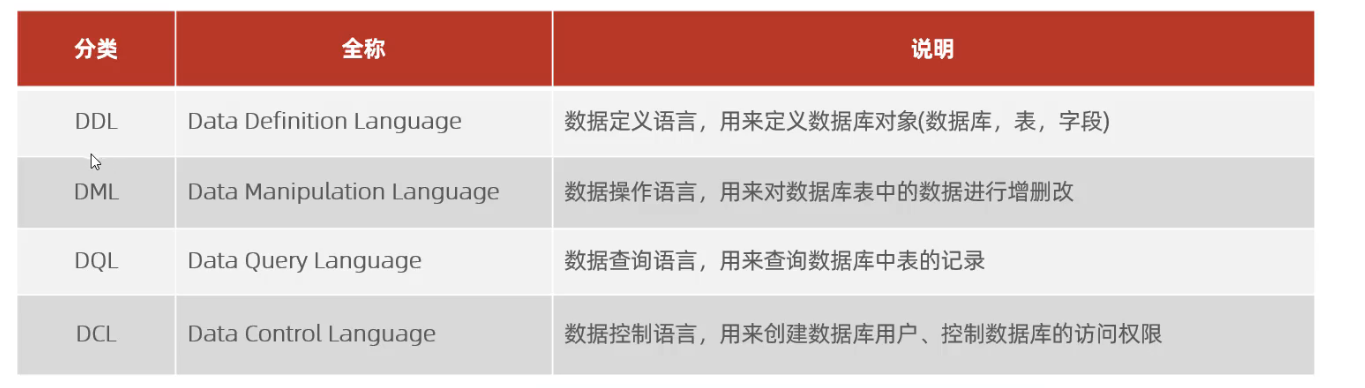
1. SQL
1.1 通用语法

1.2 SQL分类
1.3 DDL 定义库、表、字段
数据库
- 查询所有数据库
SHOW DATABASES;
- 查询当前数据库
SELECT DATABASE();
- 创建数据库
CREATE DATABASE [IF NOT EXISTS] 数据库名 [DEFAULT CHARSET 字符集] [COLLATE 排序规则]
# 字符集: utf8mb4是推荐选项,因为它支持更全面的Unicode字符集,包括Emoji表情 (多语言推荐)
# 排序规则: 排序规则通常与字符集相关联,如utf8mb4_unicode_ci (多语言推荐)
- 删除
DROP DATABASE [IF EXISTS] 数据库名;
- 使用
USE 数据库名;
表 和 字段
- 查询当前数据库所有表
SHOW TABLES;
- 查询表结构
DESC 表名;
- 查询指定表的建表语句
SHOW CREATE TABLE 表名;
- 创建表
CREATE TABLE 表名(
字段1 字段类型 [COMMENT 注释],
字段2 字段类型 [COMMENT 注释]
)[COMMENT 表注释]
- 修改
# 添加字段
ALTER TABLE 表名 ADD 字段名 类型 [COMMENT 注释] [约束];
# 更新字段
ALTER TABLE 表名 CHANGE 旧字段名 新字段名 类型 [COMMENT 注释] [约束]
# 删除字段
ALTER TABLE 表名 DROP 字段名;
# 修改表名
ALTER TABLE 表名 RENAME TO 新表名;
- 删除表
DROP TABLE [IF EXISTS] 表名;
# 删除指定表,并重新创建该表
TRUNCATE TABLE 表名
1.4 DML 操作表 增删改
INSERT
# 全部字段
INSERT INTO 表名 VALUES(值1,值2,值3...);
# 指定字段
INSERT INTO 表名 (字段1,字段2,字段3...) VALUES (值1,值2,值3...);
UPDATE
UPDATE `table_name` SET fild1=value1, fild2=value2 where fild3=value3;
DELETE
DELETE FROM `table_name` [WHERE `condition`]
# WHERE 条件下,删除满足该条件下的所有数据
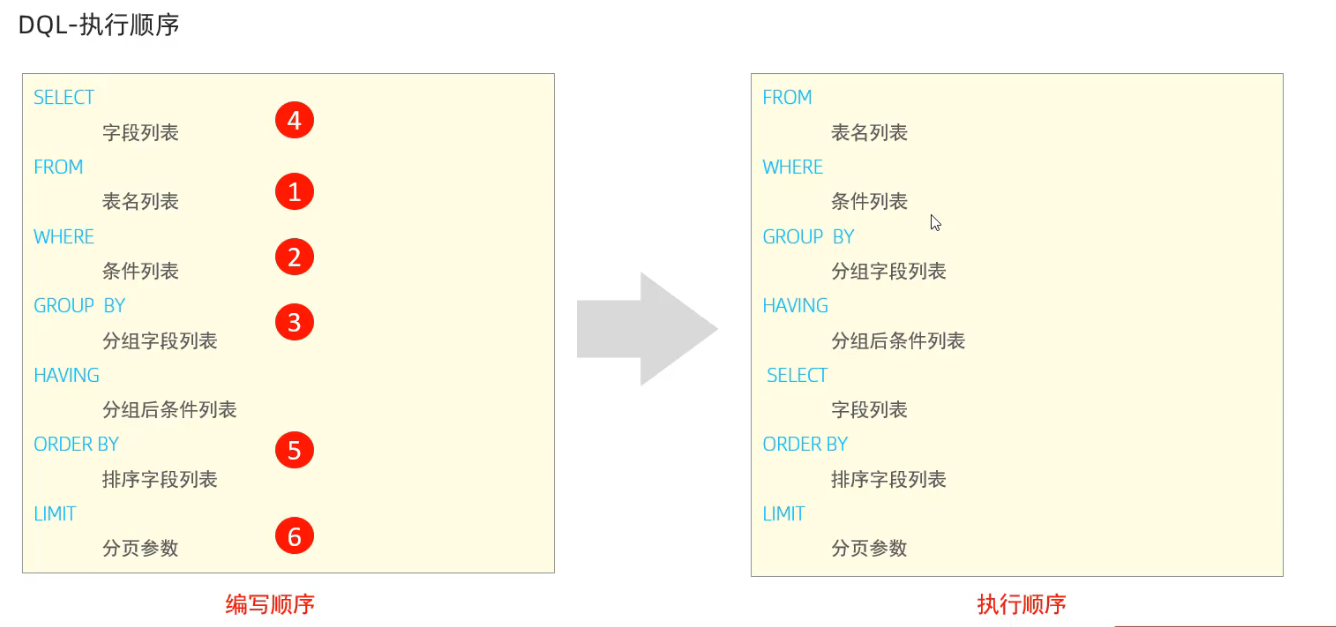
1.5 DQL 查询
SELECT
DISTINCT 字段列表 # DISTINCT 去除重复数据记录
FROM
表名列表
WHERE
条件列表 # 判空IS NULL ,NOT NULL
GROUP BY # 配合聚合函数count, max, min, avg, sum
分组字段列表
HAVING
分组后条件列表
ORDER BY
排序字段列表 ASC
LIMIT
分页参数 # LIMT 起始索引,查询记录数
# 起始索引: (页码-1)* 每页记录数
# 如果查第一页,起始索引可以省略,LIMIT 10 (查询前十条数据)

1.6 DCL 控制
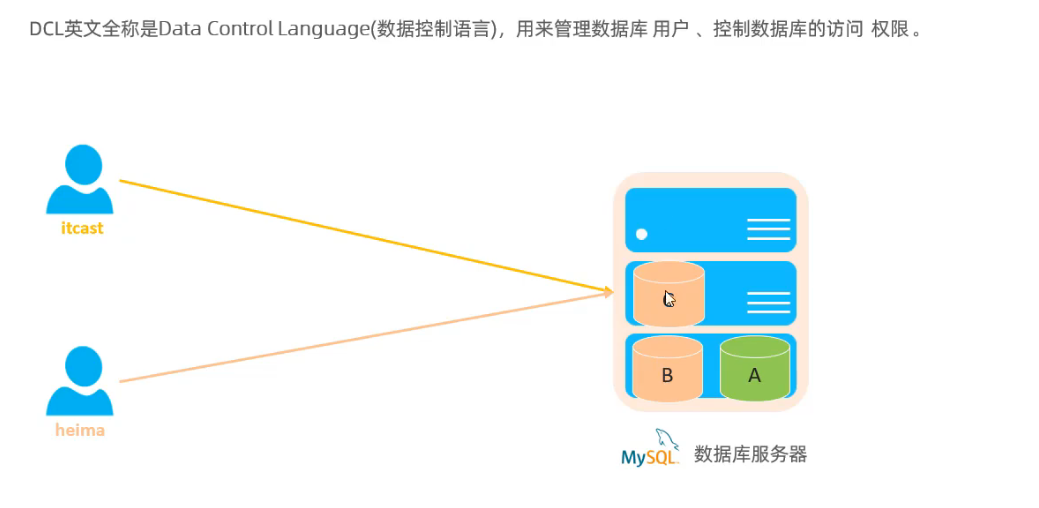
用户管理
- 查询用户
USE mysql; # 切换为系统数据库
SELECT * FROM user; # 查询用户表
- 创建用户
CREATE USER '用户名'@'主机名' IDENTIFIED BY '密码';
- 修改用户密码
ALTER USER '用户名'@'主机名' IDENTIFIED WITH mysql_native_password BY '新密码';
- 删除用户
DROP USER '用户名'@'主机名';
- 权限管理
# 查询权限
SHOW GRANTS FOR '用户名'@'主机';
#授权
GRANT 权限列表 ON 数据库名.表名 TO '用户名'@'主机名'; # GRANT all
#撤销权限
REVOKE 权限列表 ON 数据库名.表名 TO '用户名'@'主机名';
2. 函数
2.1 字符串函数
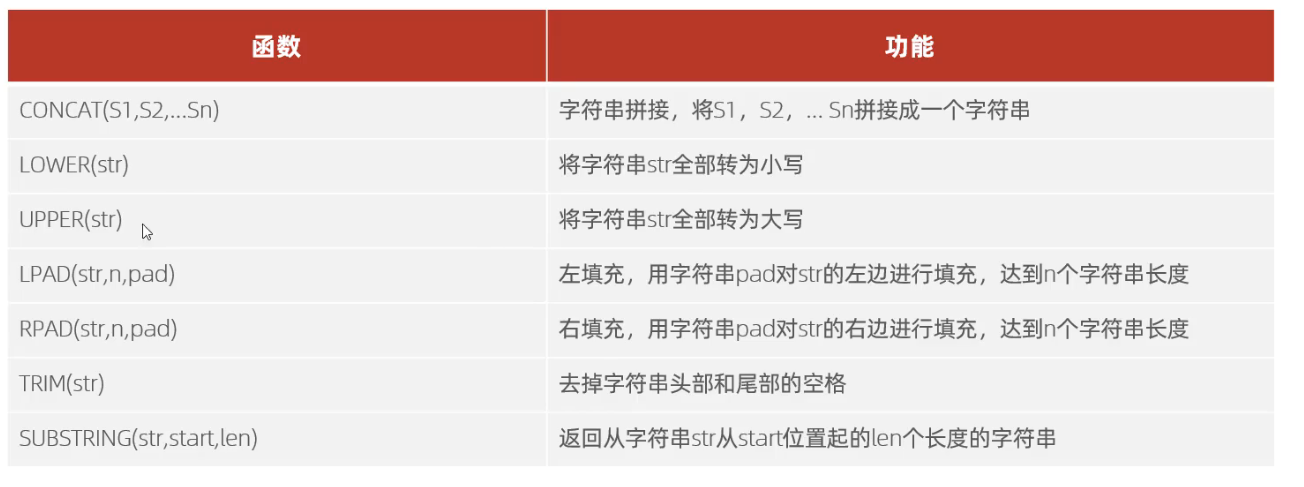
2.2 数值函数
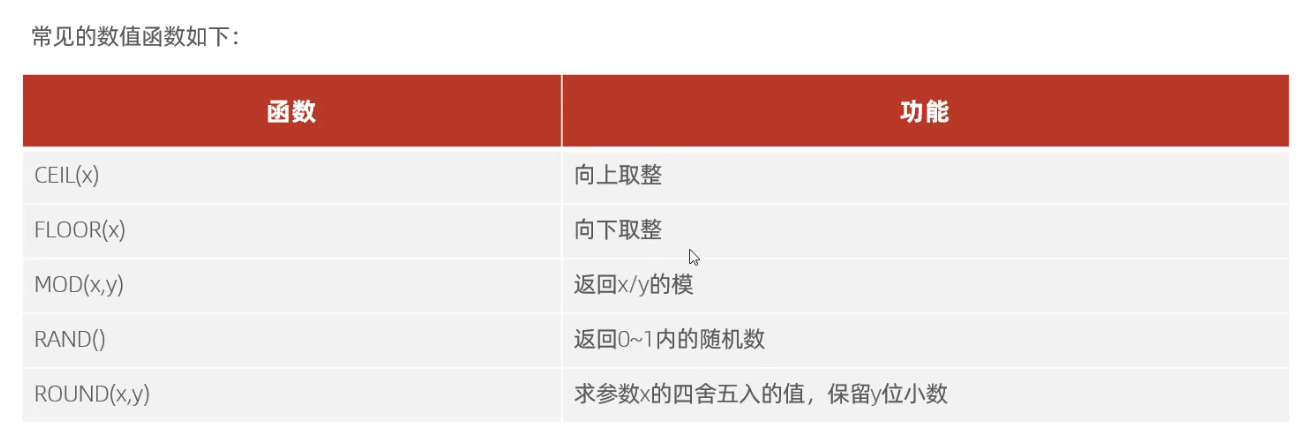
2.3 日期函数
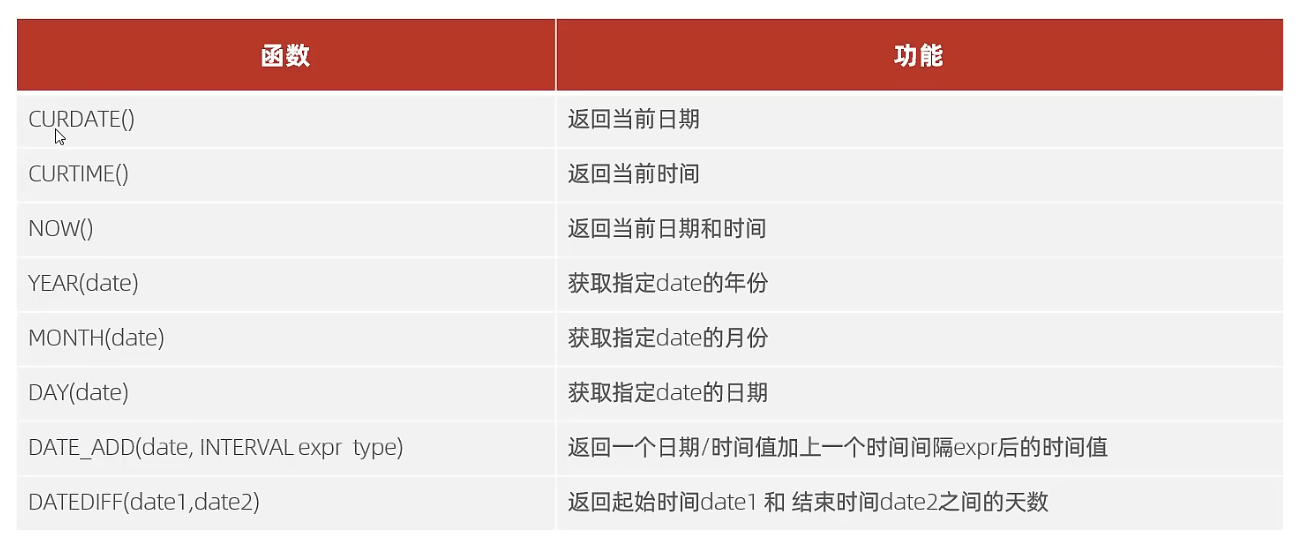
2.4 流程函数
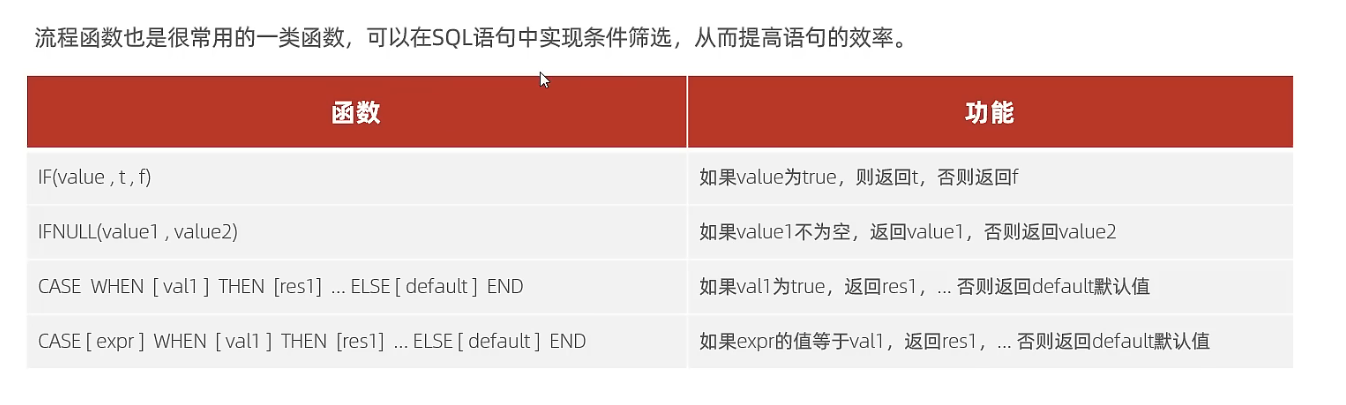
3. 约束

- 外键


CREATE TABLE t2(
id INT,
CONSTRAINT key_name FOREIGN KEY t2_feild REFERENCES t1(t1_feild)
)
外键约束行为


ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段) REFERENCES 主表名(主表字段) ON UPDATE CASCADE ON DELETE CASCADE
4. 多表查询
4.1 多表关系

- 一对多
- 多对多
- 一对一
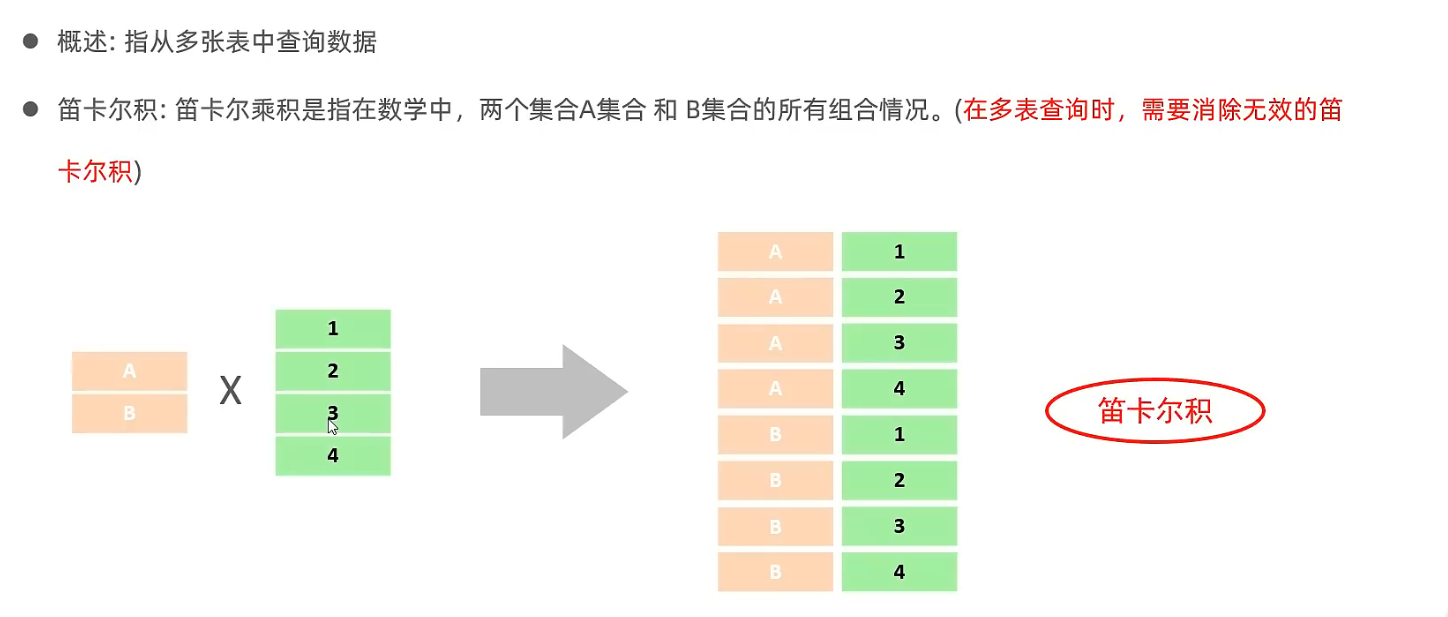

4.2 内连接
# 隐式内连接
SELECT 字段名 from 表名 表1,表2 where 条件;
# 显示内连接
SELECT 字段名 FROM 表1 [INNER] JOIN 表2 ON 连接条件;
4.3 外连接
# 左外连接
SELECT 字段列表 FROM 表1 LEFT [OUTER] JOIN 表2 ON 条件;
# 右外连接
SELECT 字段列表 FROM 表1 RIGHT [OUTER] JOIN 表2 ON 条件;
4.4 自连接
SELECT 表名 FROM 表A 别名1 JOIN 表A 别名2 ON 条件;
4.5 联合查询 union
作用:合并多次的查询记录
SELECT 字段列表 FROM 表 ... #
UNION [ALL] # 使用ALL字段,则直接合并,不去重.不使用则去重
SELECT 字段列表 FROM 表 ...;
注意事项:使用union,列数和字段类型必须完全一致
4.6 子查询
SELECT * FROM 表名 where column1 = (SELECT column1 FROM t2);

IN,NOT IN, ANY, SOME, ALL
- 行子查询
select * from emp where (salary,managerid) = (select salary, managerid) from emp where name = "jack");
- 表子查询
select * from emp where (job,salary) in (select job, salary from emp where name in ("jack","tom"));
5. 事务
5.1 事务简介

5.2 事务操作
select @@autocommit=0; # 设置为手动(0), 自动(1)
#事务操作: INSERT UPDATE DELETE
ROLLBACK;
COMMIT;
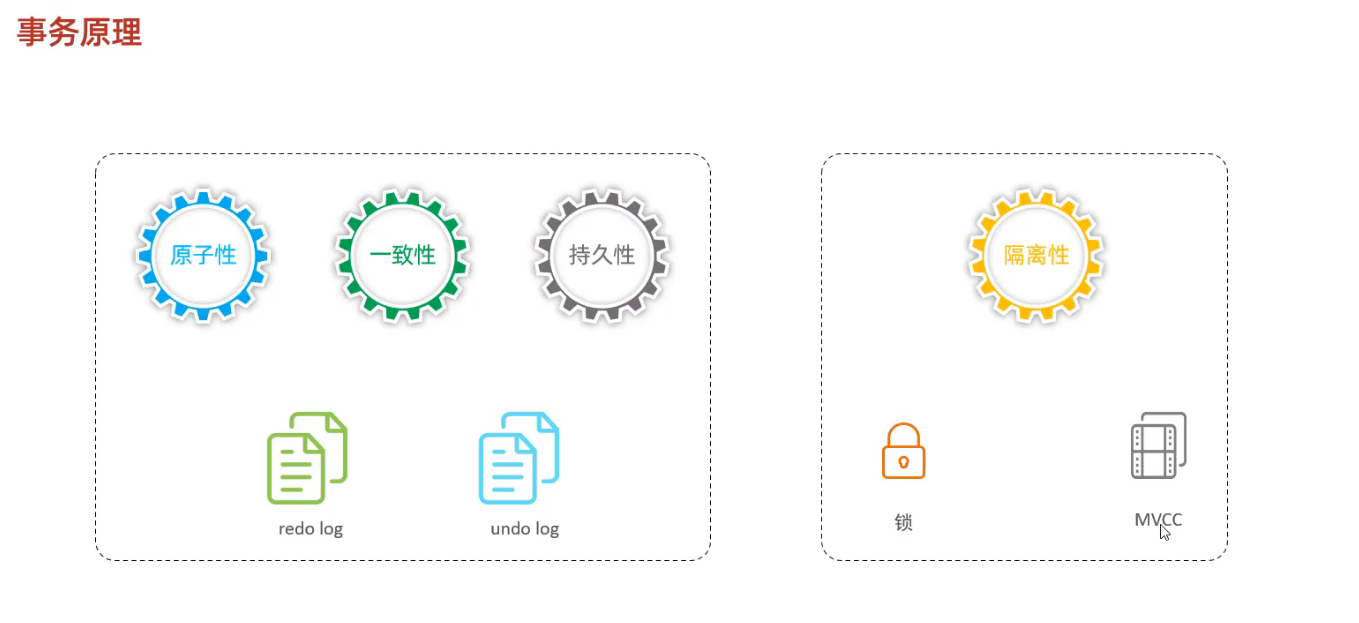
5.3 事务四大特性 ACID

5.4 并发事务问题

幻读针对插入操作
5.5 事务隔离级别
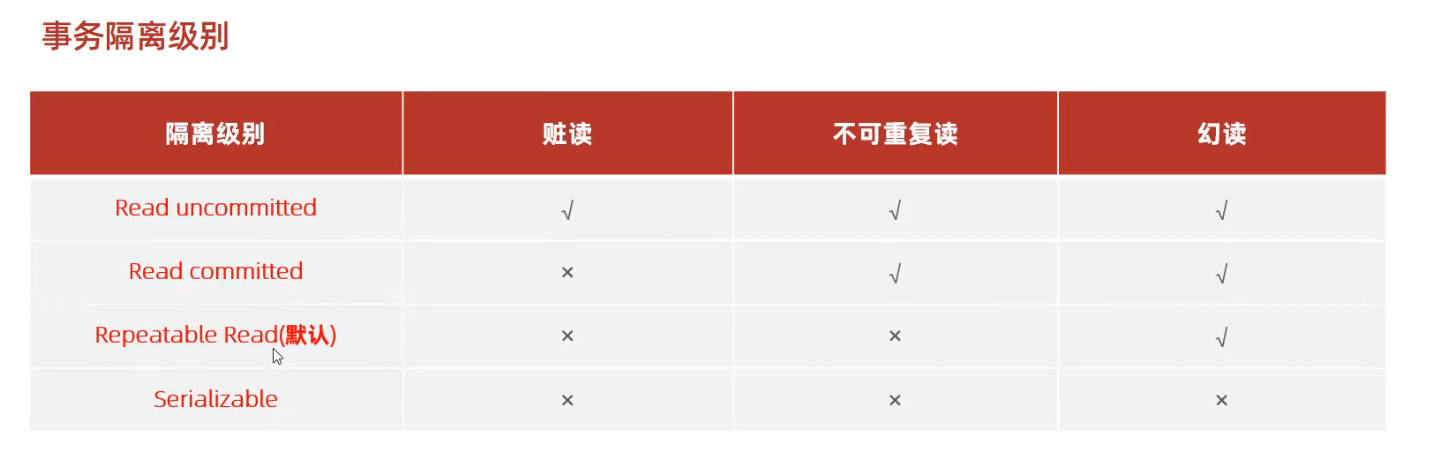
Mysql默认使用Repeatable Read, Oracle默认Read Commited
- 查看事务隔离级别
SELECT @@TRANSACTION_ISOLATION;
- 设置事务隔离级别
SET [SESSION|GLOBAL] TRANSACTION ISOLATION LEVEL {READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SERIALIZABLE}
# SESSION 代表仅对当前窗口的事务有效
READ UNCOMMITTED # 发生脏读
READ COMMITTED # 解决脏读,发生不可重复读
REPEATABLE READ # 解决不可重复读,发生幻读
SERIALIZABLE # 解决幻读
进阶
1. 存储引擎
1.1 MySQL体系结构
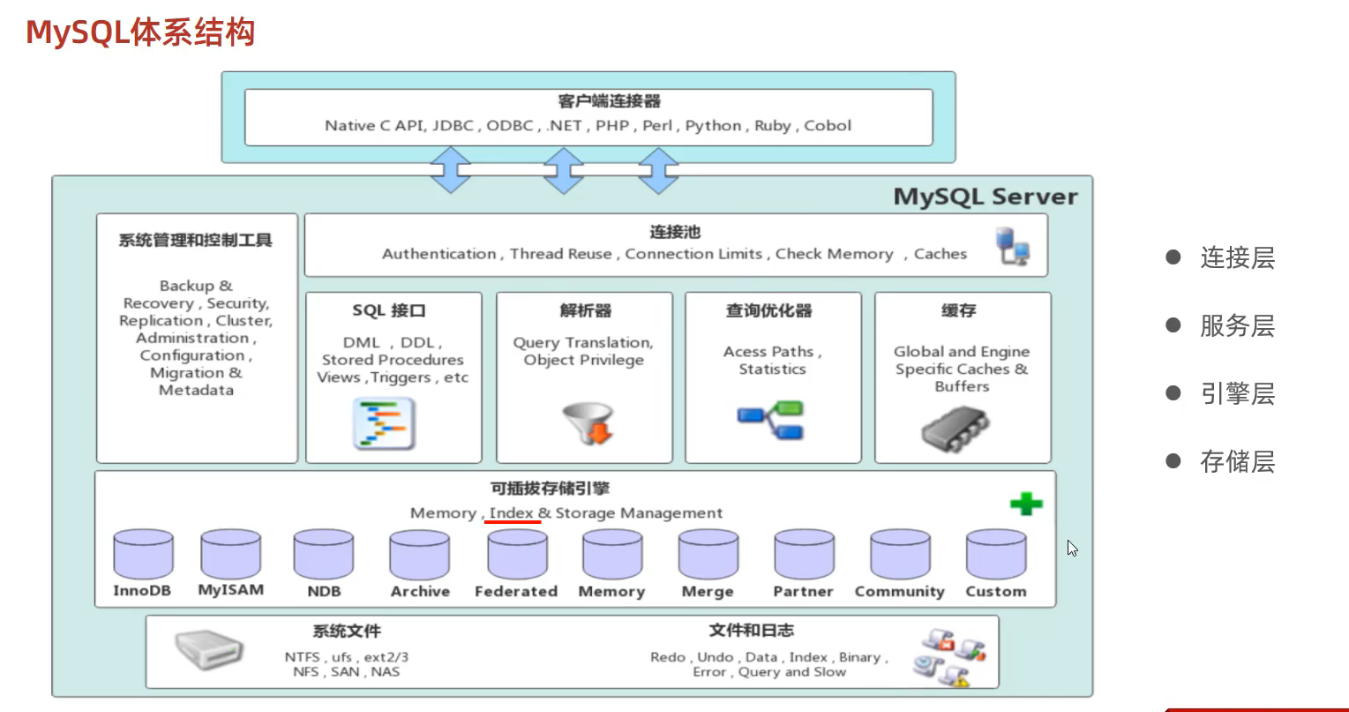
index【索引】在存储引擎层,所以不同的引擎,索引会有所不同
1.2 存储引擎简介
存储引擎是存储数据、建立索引、更新/查询数据等技术的实现方式。存储引擎是基于表的,而不是基于库的,所以存储引擎也可以被称为表类型。
-- 指定存储引擎
create table tableName(
fieldA INT,
fieldB CHAR,
...
)ENGINE=INNODB [COMMENT comments];
# 查看可支持的存储引擎
show engines;
| Engine Name | Support | Comment | Transactions | XA | Savepoints |
|---|---|---|---|---|---|
| InnoDB | DEFAULT | Supports transactions, row-level locking, and foreign keys | YES | YES | YES |
| FEDERATED | NO | Federated MySQL storage engine | |||
| MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO |
| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO |
| BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO |
| MyISAM | YES | MyISAM storage engine | NO | NO | NO |
| CSV | YES | CSV storage engine | NO | NO | NO |
| ARCHIVE | YES | Archive storage engine | NO | NO | NO |
| PERFORMANCE_SCHEMA | YES | Performance Schema | NO | NO | NO |
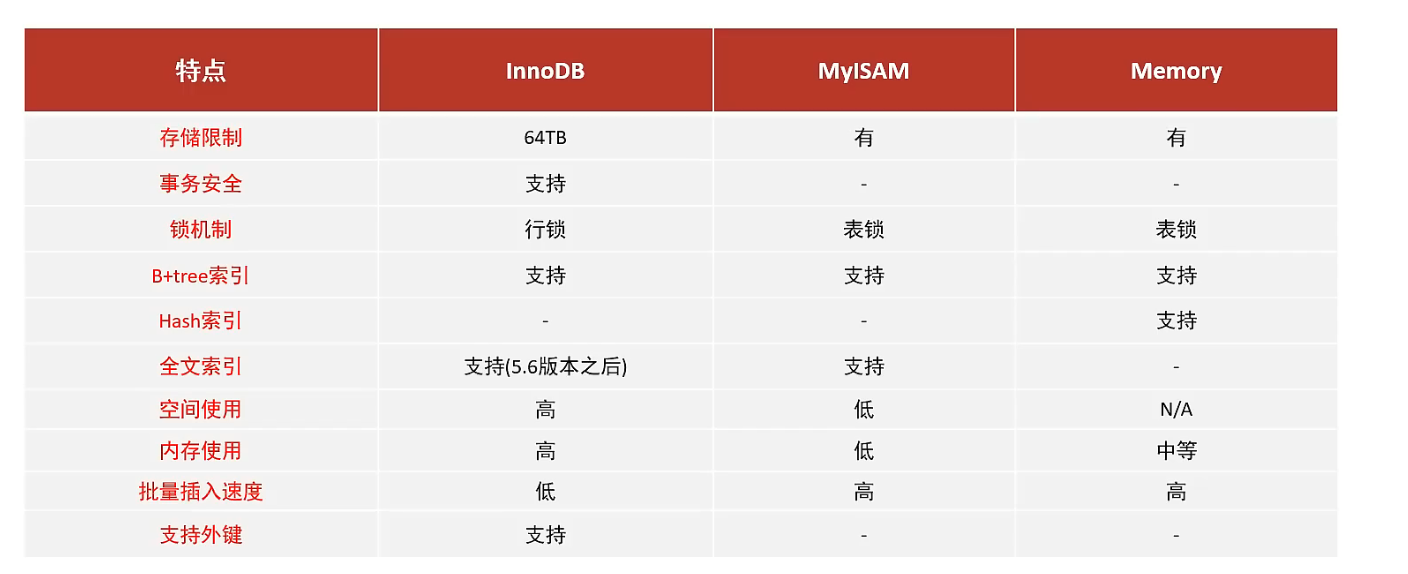
1.3 存储引擎特点
- InnoDB
InnoDB是一种兼顾高可靠性和高性能的通用存储引擎,在Mysql 5.5后,InnoDB是默认的mysql存储引擎
特点:
- DML操作遵循
ACID模型,支持事务; 行级锁,提高并发访问性能;- 支持
外键约束,保证数据完整性和准确性
文件:
xxx.ibd: xxx代表表名,innoDB引擎每一张表都会在磁盘有一个表空间文件,存储该表的表结构(frm,sdi), 数据和索引
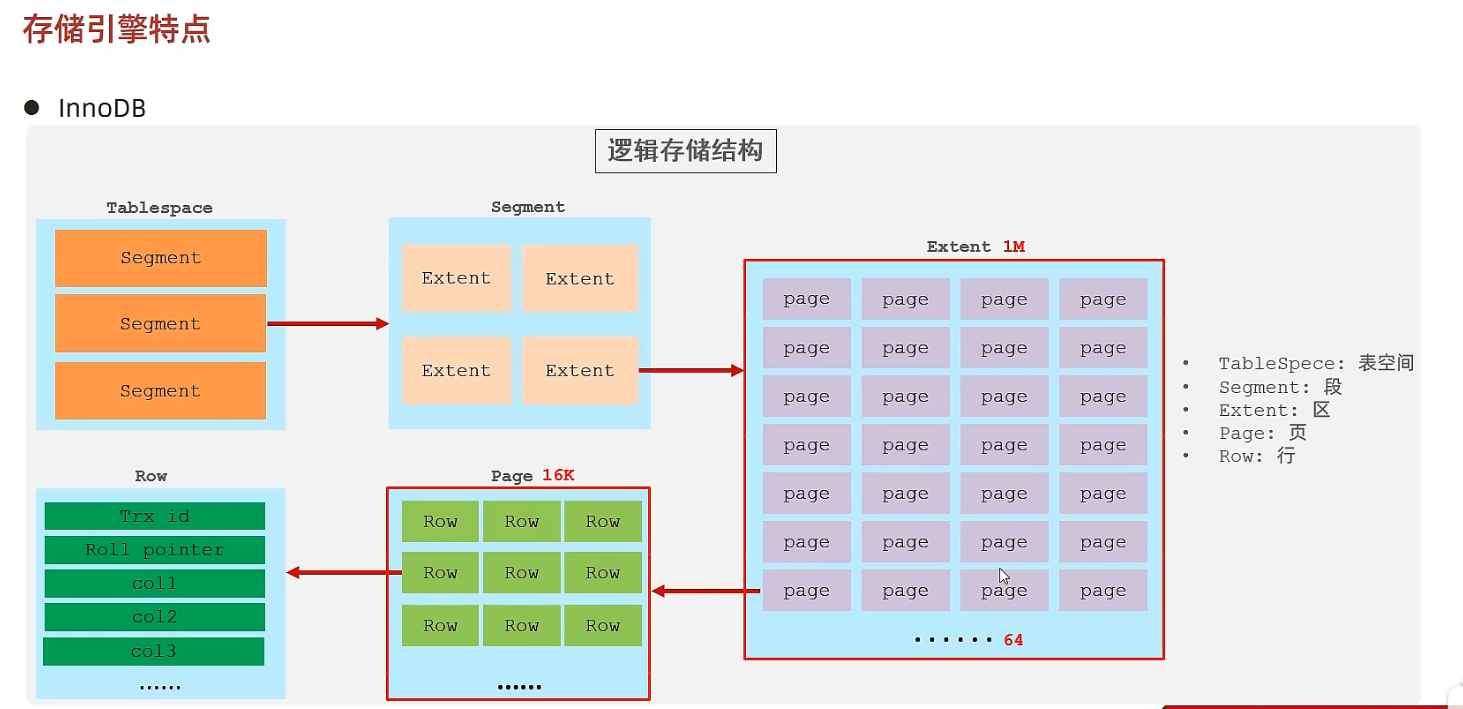
InnoDB逻辑存储结构
- MyISAM

- Memory

1.4 存储引擎选择

MyISAM: 日志数据、评论、 (被mongdb替换)
Memory:创建的临时表可使用,当作缓存 (redis替换)
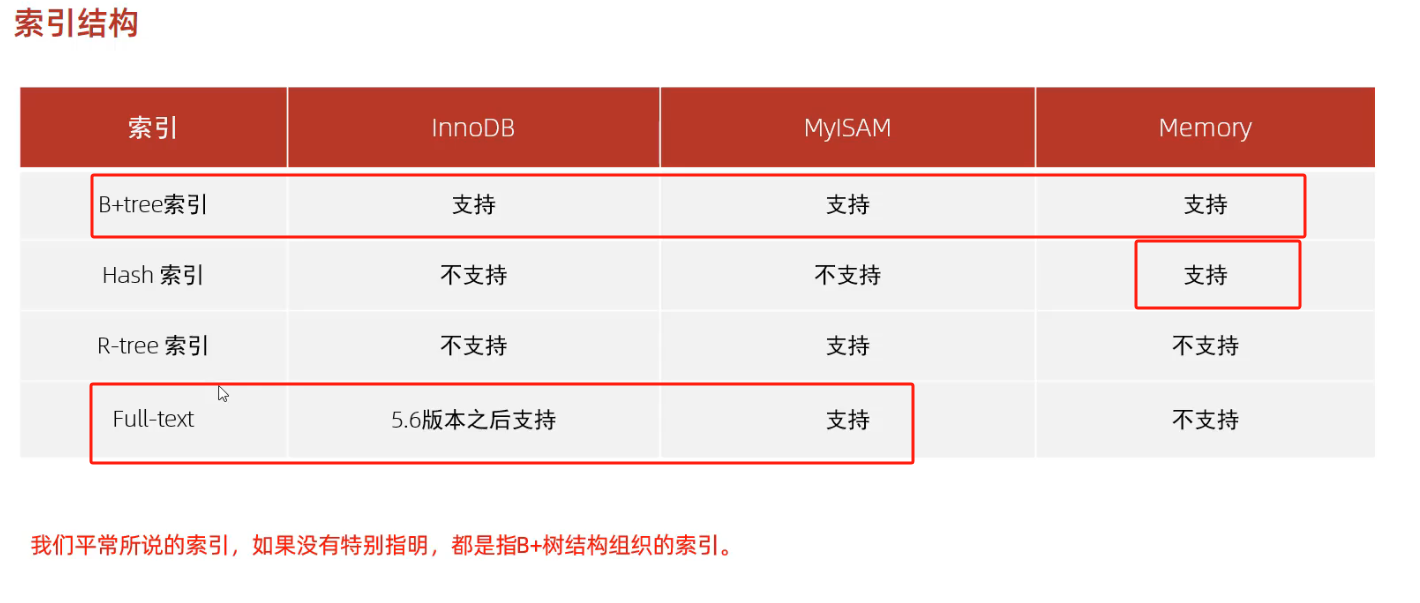
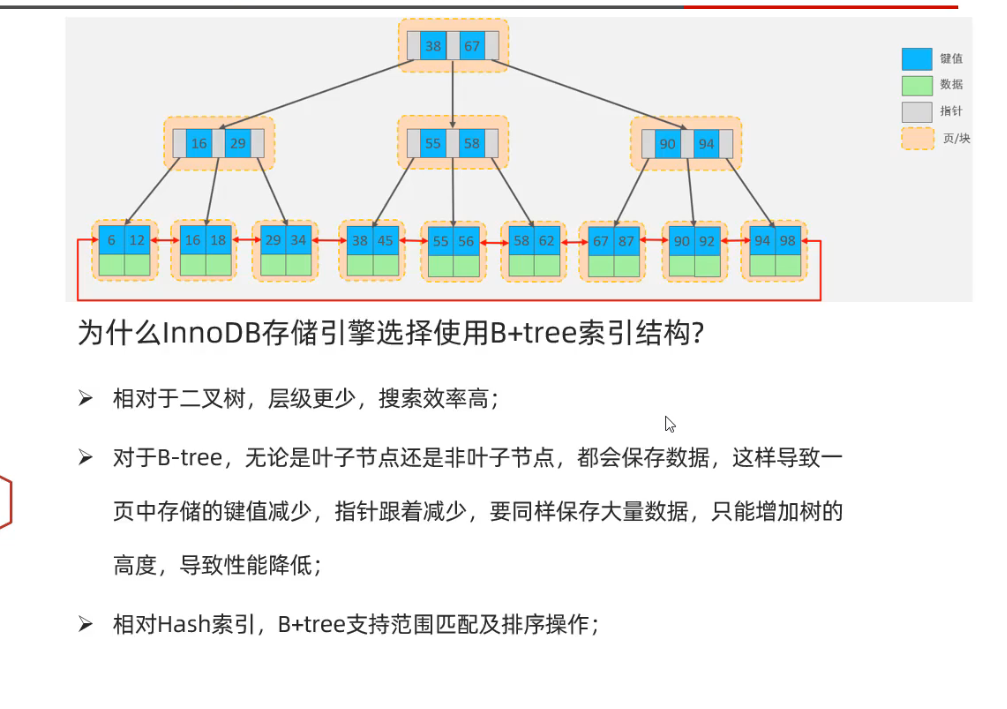
2. 索引
2.1 索引概述



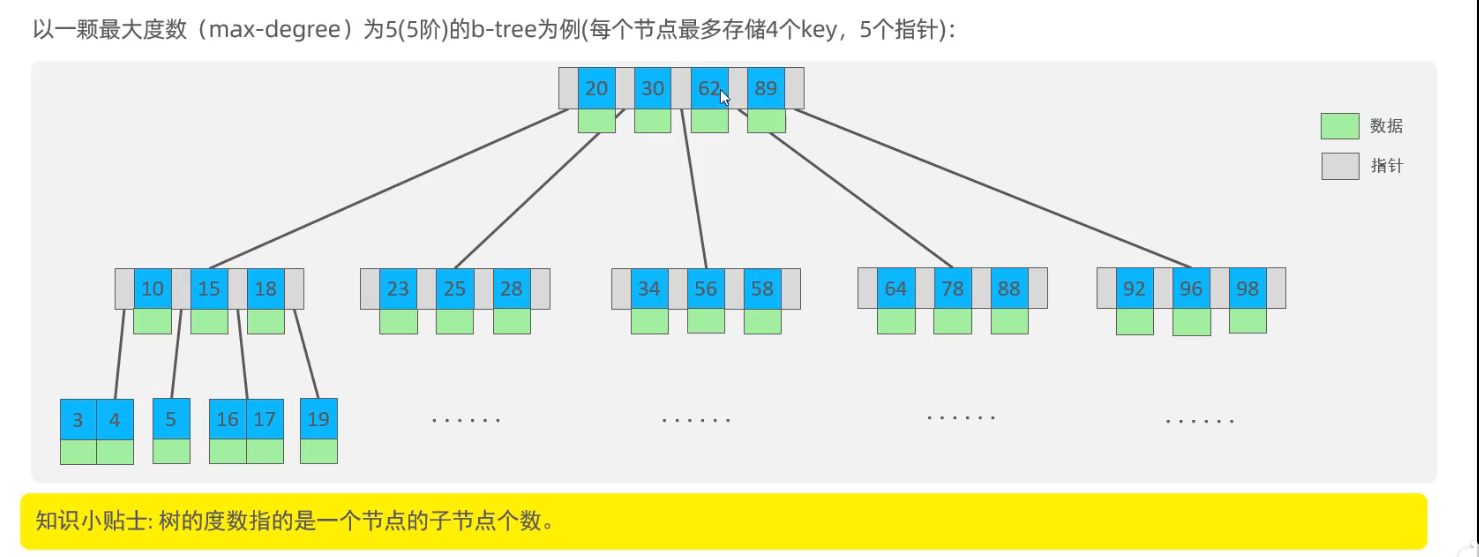
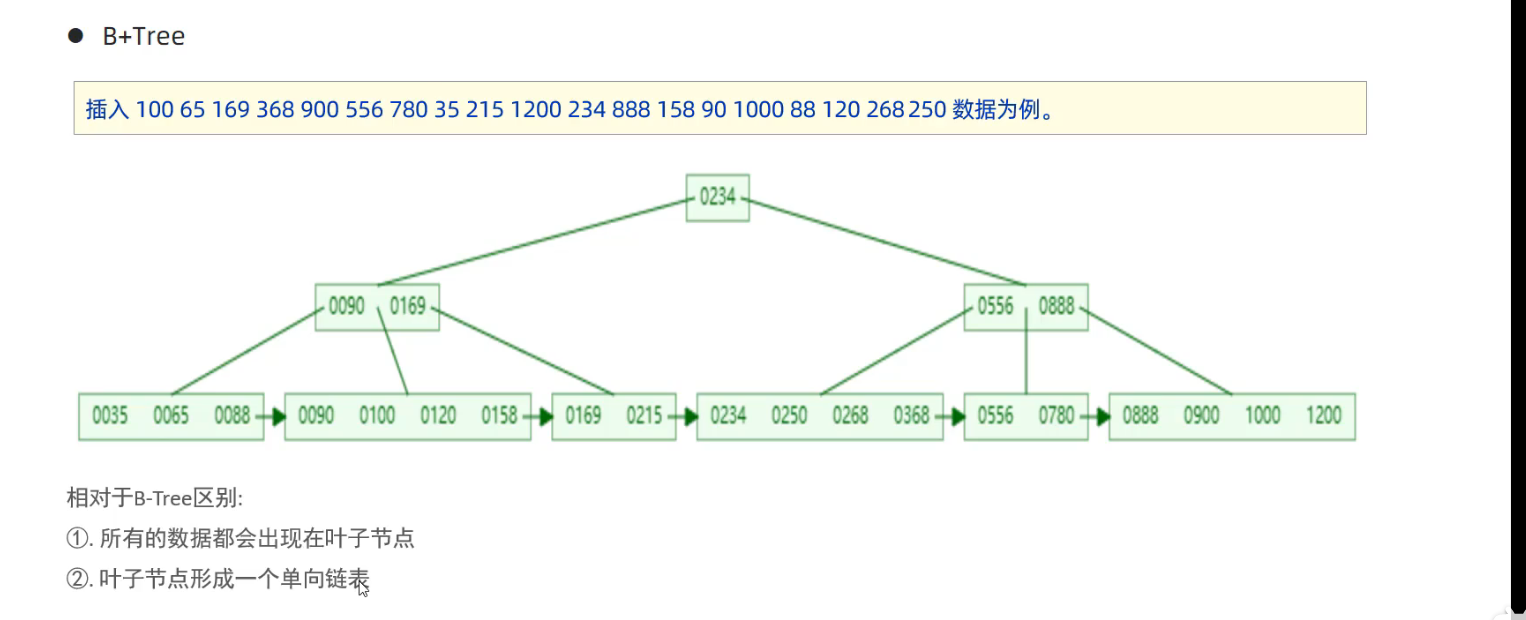
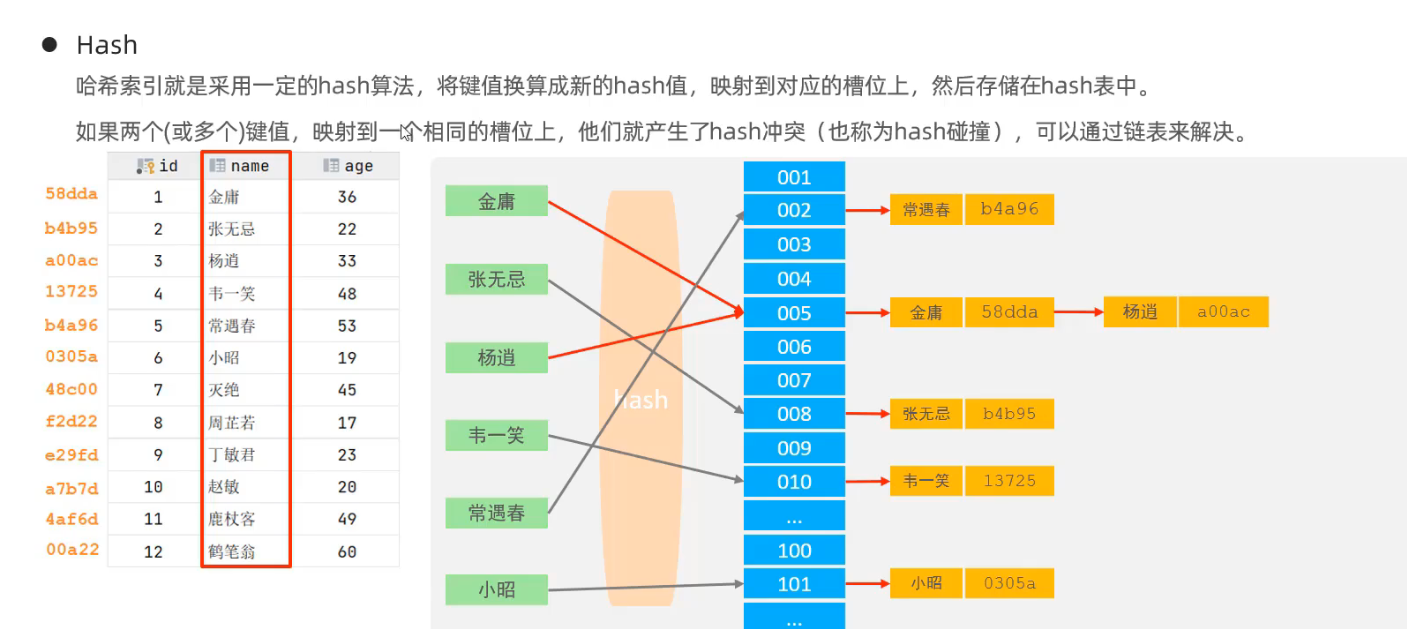
2.2 索引结构

- B树
- B+树
- Hash表


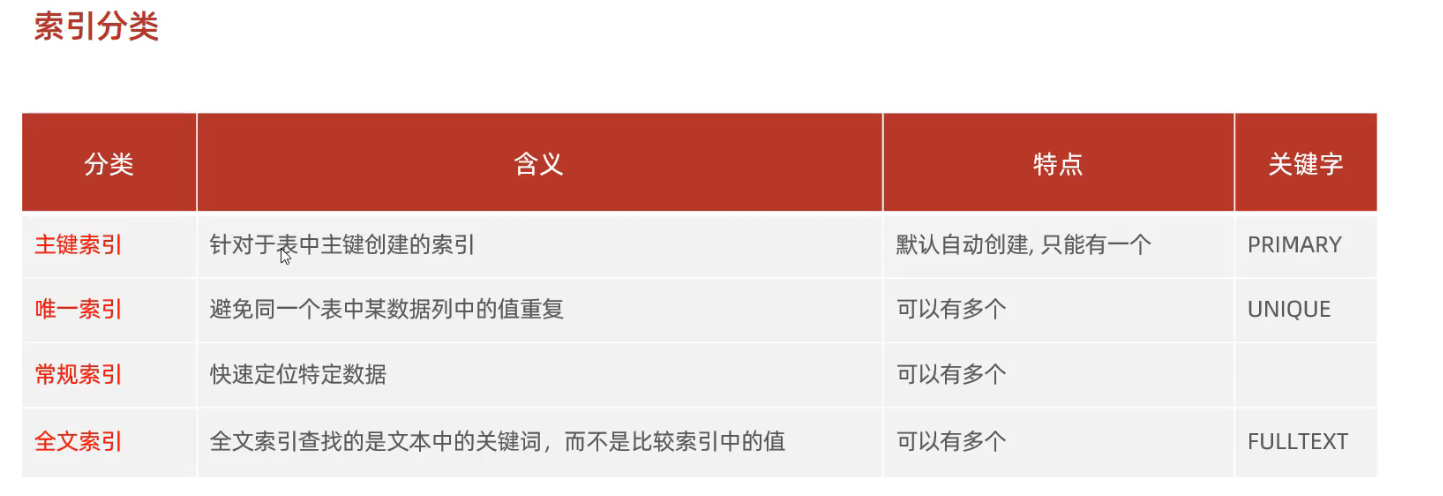
2.3 索引分类

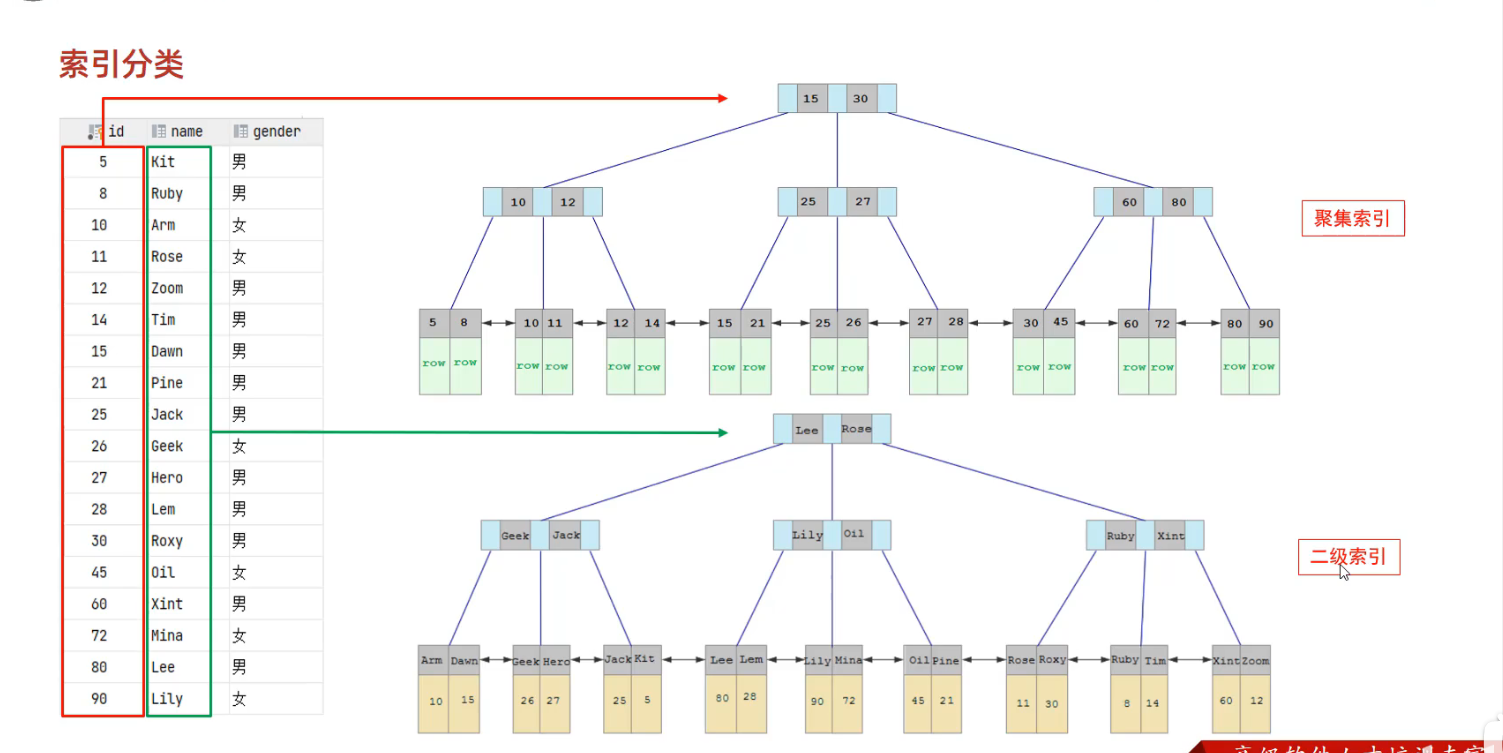
- 聚集索引
- 如果存在主键,主键索引就是聚集索引
- 如果不存在,将使用第一个唯一索引作为聚集索引
- 都不存在,则自动生成一个rowid作为隐藏的聚集索引
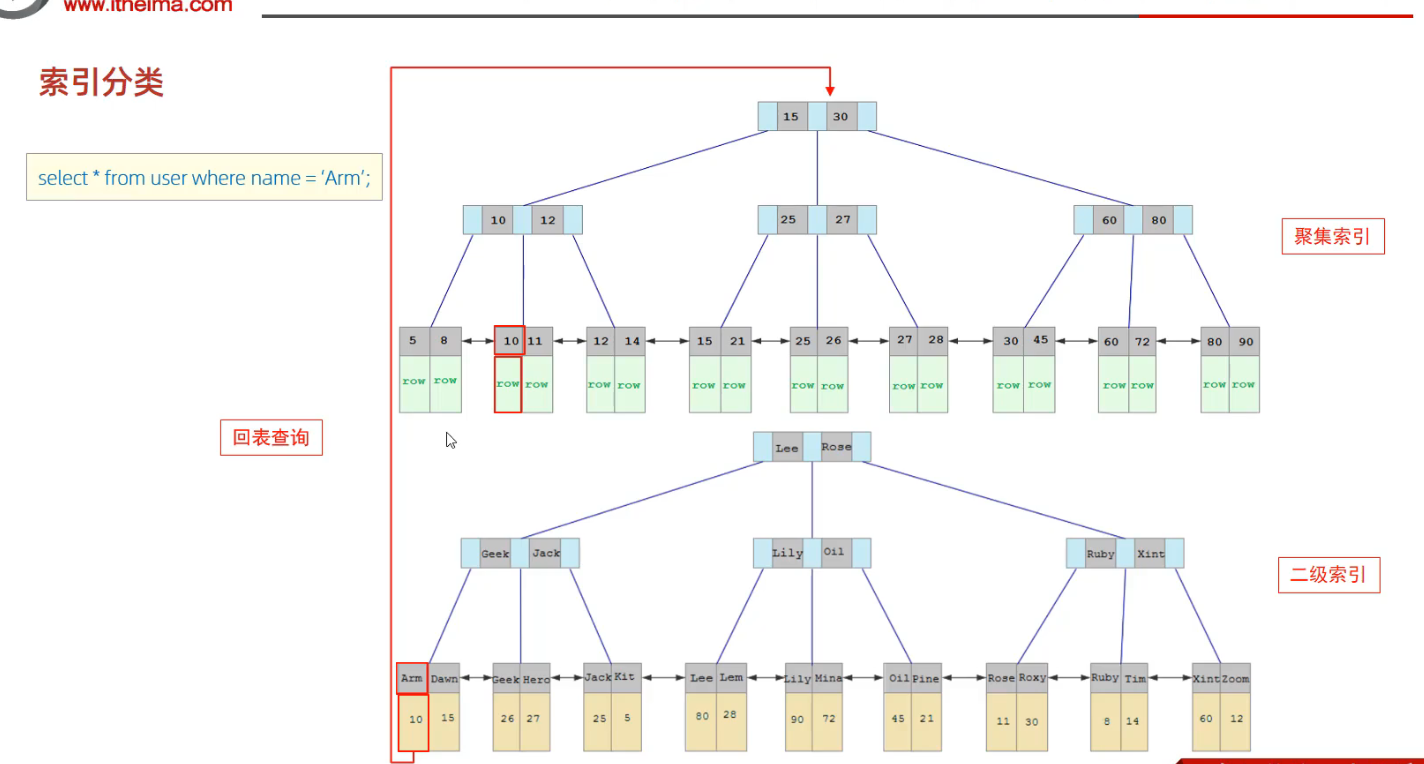
2.4 索引语法
创建索引
CREATE [UNIQUE|FULLTEXT] INDEX index_name ON `table_name` (index_col_name,...);
index_name用来
小括号里表示一个索引可以关联多个字段(联合索引)
查看索引
SHOW INDEX FROM `table_name`;
使用索引
SELECT * FROM user USE INDEX (index_name) where id = 1
删除索引
DROP INDEX index_name ON `table_name`;

# 1
CREATE INDEX idx_user_name on tb_user(name); # 常规索引,不需要指定索引类型
# 2
CREATE UNIQUE idx_phone ON tb_user(phone); # 创建唯一索引
# 3
CREATE INDEX idx_user_pro_age_status ON tb_user(profession,age,status); # 字段顺序有讲究
# 4
CREATE UNIQUE idx_user_email ON tb_user(email);
2.5 SQL性能分析
SQL执行频率
# 查看服务器的状态信息
SHOW [SESSION|GLOBAL] STATUS;
# 查看增删改查频率
SHOW GLOBAL STATUS LIKE 'Com_____'; # 几个下划线代表几个字符
慢查询日志
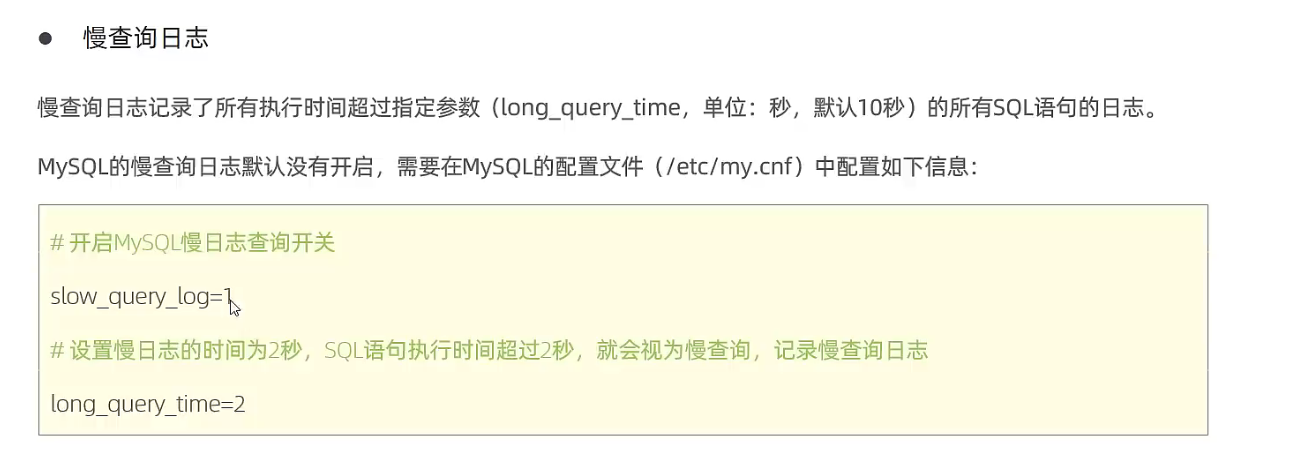
# 查询慢查询日志是否开启
show variables like 'slow_query_log'; # 慢查询日志默认关闭
# MySQL配置文件中开启慢查询日志
# 开启开关
slow_query_log=1
# 设置日志记录时间,此处设置为2秒,代表SQL语句的执行时间超过2秒,就会被视为慢查询,记录到日志中
long_query_time=2
# 慢查询日志存放地址
/var/lib/mysql/xxx.log
profile详情 - 每条语句耗时查询
show profiles能够在做SQL 优化时帮助我们了解时间都耗费到哪里
# 查看当前数据库是否支持profile操作
SELECT @@have_profiling;
# profiling默认是关闭的,可以通过set语句在session/g
SELECT @@profiling;
SET profiling=1;
# 查看每一条SQL耗时的基本情况
SHOW PROFILES;
# 查看指定query_id的SQL语句在各个阶段的耗时情况
SHOW profile for query query_id;
# 查看指定query_id的SQL语句在各个阶段的cpu使用情况
SHOW profile cpu for query query_id;
explain执行计划
通过EXPLAIN或DESC命令获取MySQL如何执行SELECT语句信息,包括SELECT语句执行过程中表如何连接和连接的顺序
# 直接在select语句之前加上关键字 explain / desc
EXPLAIN SELECT column_... FROM table_name_... where condition_...;
# id, select_type, table, partitions, type, possible_keys, key, key_len, ref, rows, filtered, Extra
-
id: 表的执行顺序。id相同,则从上往下执行。如果id不相同,则值大的先执行
-
select_type: 表示select的类型。SIMPLE简单表(无表连接或子查询);PRIMARY(主查询,即最外层的查询);UNION(连接的第二个或者后面的查询),SUBQUERY(子查询)
-
type:表示连接类型。性能由好到差依次是:NULL,system、const、eq_ref、ref、range、index、all-
NULL:不访问任何表
-
system:访问系统表
-
const:唯一索引查询 (select * from table_name where id = 1)
-
ref:非唯一性索引查询 (select * from table_name where name = "zs")
-
eq_ref: 连表查询的等值比较有唯一索引(
select a.*, b.* from a,b where a.id = b.id如果a.id是a唯一索引,则a为eq_ref ) -
range: 范围查询,range类型表示使用索引返回一个范围中的行。通常在查询中使用比较运算符(如 >, <, >=, <=, BETWEEN, IN)时会出现这种情况。例如:`EXPLAIN SELECT * FROM account WHERE id > 1; 在这个查询中,id 列有一个索引,MySQL 使用 range 类型来查找 id 大于 1 的所有行 -
index:用了索引,但遍历整个索引树 (select * from table_name)
-
all: 全表扫描
-
-
possible_key: 显示可能应用在这张表上的索引,一个或多个 -
key: 实际用到的索引 -
key_len: 使用的索引字节数(索引最大可能长度)越短越好 -
rows:预估值,需要执行查询的行数
-
filtered:查询结果行数占读取行数的百分比%
-
Extra: 额外信息
2.6 索引使用
在未使用索引时,执行如下sql效率低
SELECT * FROM table_a where name = "zs";
针对name字段建立索引
CREATE INDEX idx_a_name on table_a(name); # 注意:创建索引也需要耗时(构建B+树数据结构)
# 查看当前表索引
SHOW INDEX FROM table_a;
然后再次执行相同查询,效率提高
最左前缀法则
如果索引了多列(联合索引:一个索引关联了多个字段),要遵循最左前缀法则。最左前缀法则指从索引的最左列开始,并且不跳过索引中的列。如果跳跃某一列,则索引将部分失效(后面的字段索引失效)
# 背景table_a 表中有三个字段的联合索引 name age gender
# 1. 联合索引全部生效
SELECT * FROM table_a where name = "zs" and age = 18 and gender = "man";
SELECT * FROM table_a where age = 18 and gender = "man" and name = "zs"; # 也会生效,因为name存在
# 2. 联合索引部分生效 name字段生效
SELECT * FROM table_a where name = "zs" and gender = "man";
# 3. 联合索引全部失效
SELECT * FROM table_a where age = 18 and gender = "man";
范围查询
联合索引中,如果出现范围查询(>,<),范围查询右侧的列索引将失效
# 最右侧列 gender 失效
SELECT * FROM table_a where name = "zs" and age > 18 and gender = "man";
# 使用大于等于 >= 则不失效
SELECT * FROM table_a where name = "zs" and age >= 18 and gender = "man";
索引列运算
不要在索引列上进行运算操作,否则索引会失效
# 索引name失效,不走索引
SELECT * FROM table_a where SUBSTRING(name,1,1);
字符串查询需要加引号
字符串不加引号时,有时SQL也会执行,但是索引失效
# 背景:phone是索引字段
SELECT * FROM table_a where phone = 123; # 隐式类型转换,索引失效
% 模糊查询
头部模糊匹配,索引会失效。如果是尾部模糊匹配,索引不失效
# 头部模糊匹配,索引失效
SELECT * FROM table_a WHERE name like '%三'; # 全表扫描 ALL
# 尾部模糊匹配,索引不失效
SELECT * FROM table_a WHERE name like "张%"
OR连接的条件
使用OR语句,如果OR前后都有索引,索引才会生效
# 背景 id 和 name为索引字段, home为普通字段
# 索引生效
SELECT * FROM table_a where id = 1 or name = "zs"; # 使用到两个索引
# 不走索引
SELECT * FROM table_a where name = 'zs' or home = 'china'; # 全表扫描,使用0个索引
数据分布影响
如果MySQL评估使用索引比全表查询更慢,则不使用索引;
即:
如果查询最终的结果数量超过了全表的一半则不走索引, 使用全表查询
如果查询的最终结果数量小于全表的一半, 则走索引
# 不走索引
explain select * from pms_attr where attr_id is not null;
SQL语句添加索引提示
多个索引都可能用到的情况下, MySQL会进行自动选择.
也可以给MySQL提示使用哪个索引.
USE INDEX建议使用某个索引
SELECT * FROM table_a USE INDEX(idx_name) where name = "zs";
IGNORE INDEX不使用某索引
SELECT * FROM table_a IGNORE INDEX(idx_name_age_gender) WHERE name = "zs";
FORCE INDEX强制使用某个索引
SELECT * FROM table_a FORCE INDEX(idx_name) WHERE name = 'zs';
覆盖索引 select id, name
尽量使用覆盖索引, select id, name
using where, using index : 表示没有回表查询仅有using index: 表示使用了回表查询
不要使用 select *, 因为select * 很容易出现回表查询
前缀索引
某些字段为字符串时(varchar,text等),直接建立它们的索引会让索引长度很大, 浪费大量的磁盘IO, 影响查询效率. 此时只将字符串的一部分前缀建立索引, 这样可以节省空间,并提高索引效率.
- 语法
CREATE INDEX idx_xxx on table_a(column_name(n));
- 前缀长度
根据索引的选择性来确定, 当出现某个字符串的时候, 匹配前面n个字符, 刚好满足每次匹配时只有一个选择, 则为最佳长度.
SELECT COUNT(DISTINCT(SUBSTRING(column_name,1,n)))/ count(*) FROM table_a; # n尽可能小,结果刚好为1就是最佳长度
单列索引与联合索引
单列索引: 一个索引只包含单个列
联合索引: 一个索引包含多个列
在业务场景中,如果存在多个查询条件, 考虑对于查询字段建立索引时, 建议建立联合索引, 而非单列索引
2.7 索引设计原则

3. SQL优化
- 创建10万条数据
START TRANSACTION;
DROP PROCEDURE IF EXISTS insert_10W;
DELIMITER ;;
CREATE PROCEDURE insert_10W()
begin
declare i int;
SET i = 1;
WHILE i <= 100000 DO
INSERT INTO user (id,name, age,dpt, date) VALUES (i, CONCAT('name_', i), i % 120, CONCAT("dpt", i), DATE_ADD(CURDATE(), INTERVAL i DAY));
SET i = i + 1;
END WHILE;
END;;
DELIMITER ;
CALL insert_10W();
COMMIT;
- 开启trace
set session optimizer_trace="enabled=on",end_markers_in_json=on; -- 开启trace
select * from user where name like "name"; # 执行语句
select * from information_schema.OPTIMIZER_TRACE; # 查看trace
3.1 insert优化
- 批量插入
INSERT INTO table_a value(1,"tom"), (2,"jerry");
- 手动事务提交
start transaction;
insert...;
insert...;
commit;
- 主键顺序插入
主键按照递增的顺序插入
- 大批量数据使用load
# 1. 连接服务器时,加参数
mysql --local-infile -u root -p
# 2. 设置全局参数local_infile = 1; 开启从本地加载文件的开关
set global local_infile = 1;
# 3. 执行load指令将准备好的数据加载到表结构中
load data local infile "/root/sql.log" into table table_name_a fields terminated by ',' lines terminated by '\n';
3.2 主键优化
- 数据组织方式
innodb中, 表都是根据主键顺序组织存放的, 这种表是索引组织表(IOT).
页分裂
主键如果不按照顺序插入, 就可能会导致页分裂
- 页合并
删除数据时, 如果某个页中的记录小于阈值(默认50%), 则可能发生页合并
- 主键设计原则
- 满足业务需求的情况下,尽量降低主键的长度
- 插入数据时,尽量选择顺序插入,选择使用AUTO_INCREMENT自增主键
- 尽量不要使用UUID做主键或者是其他自然主键,如身份证号 (无序,且长度太长)
- 业务操作时,尽量避免对主键的修改
3.3 order by优化
- Using index:效率高,通过有序索引顺序扫描, 直接返回有序数据
- Using filesort: 不通过索引顺序排序, 效率低
CREATE INDEX idx_age_name on table_a(age asc, name desc);

# 配置文件示例 (my.cnf)
[mysqld]
sort_buffer_size = 2M # 从1-4MB开始测试
3.4 group by 优化

3.5 limit优化
SELECT * FROM table_a limit 9000000,10;
# 这条sql会排序9000010条记录,但只返回10条数据。 排序代价非常大
# 优化:覆盖索引+子查询
SELECT t.* from table_a t, (SELECT id FROM table_a LIMIT 9000000,10) ai where t.id = ai.id;
3.6 count优化

优化思路: 自己计数 (Redis) select count(1) from table_a 存到Redis

3.7 update优化
如果update时是根据某个没有索引的字段进行更新时, 行级锁会上升为表级锁. 所以更新字段时, 要根据索引字段进行更新

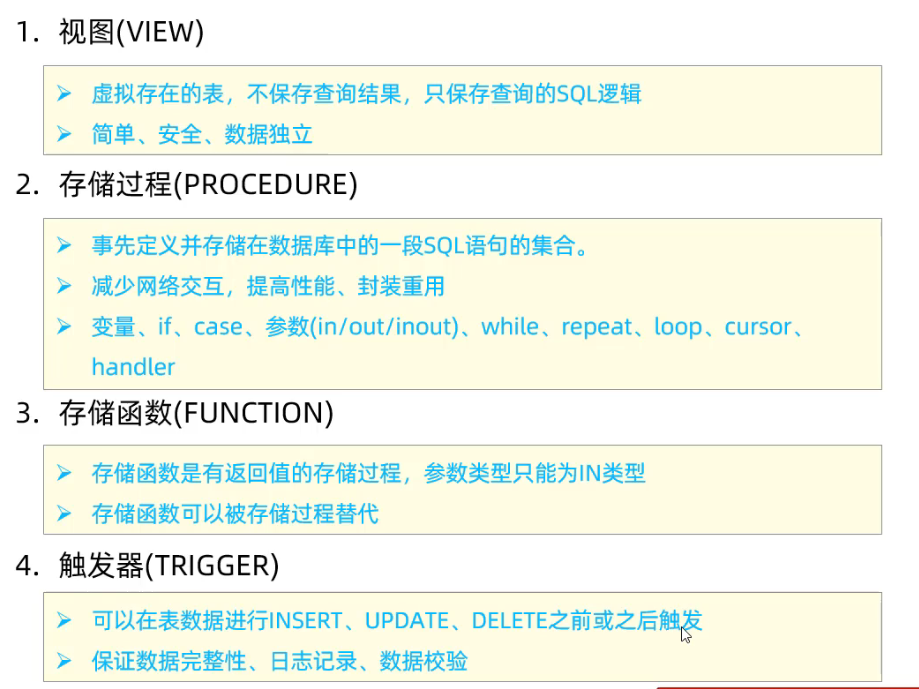
4. 视图/存储过程/触发器
4.1 视图


4.2 存储过程

4.3 存储函数
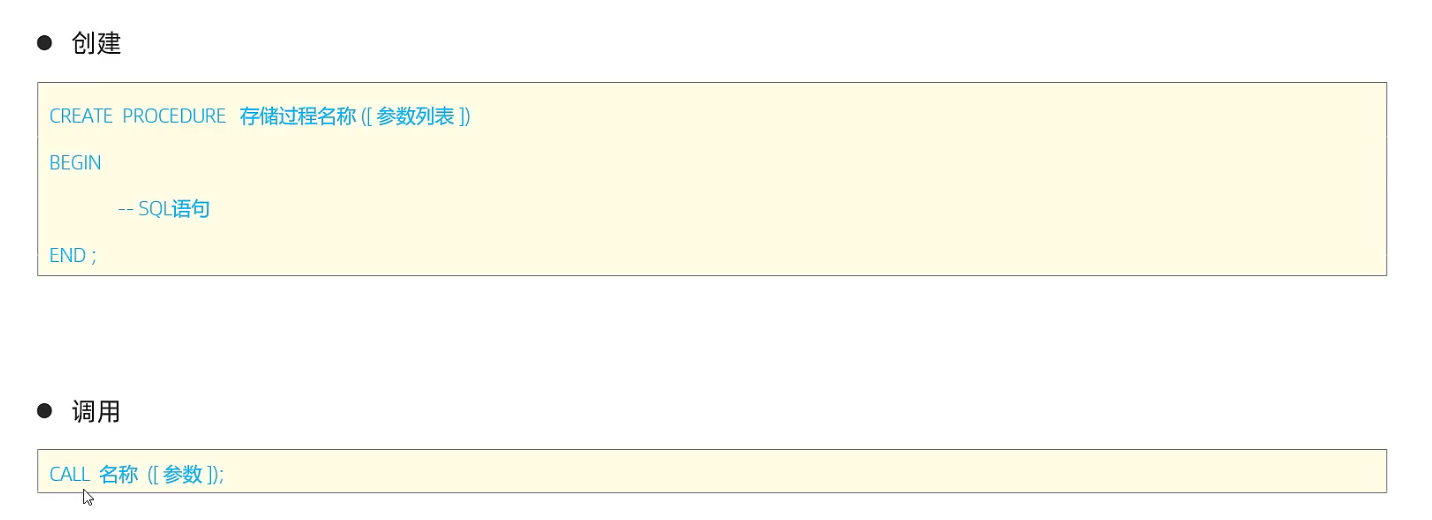

注意: 在命令行中,执行创建存储过程的SQL时,,需要通过关键字 delimiter 指定SQL语句的结束符
if loop while
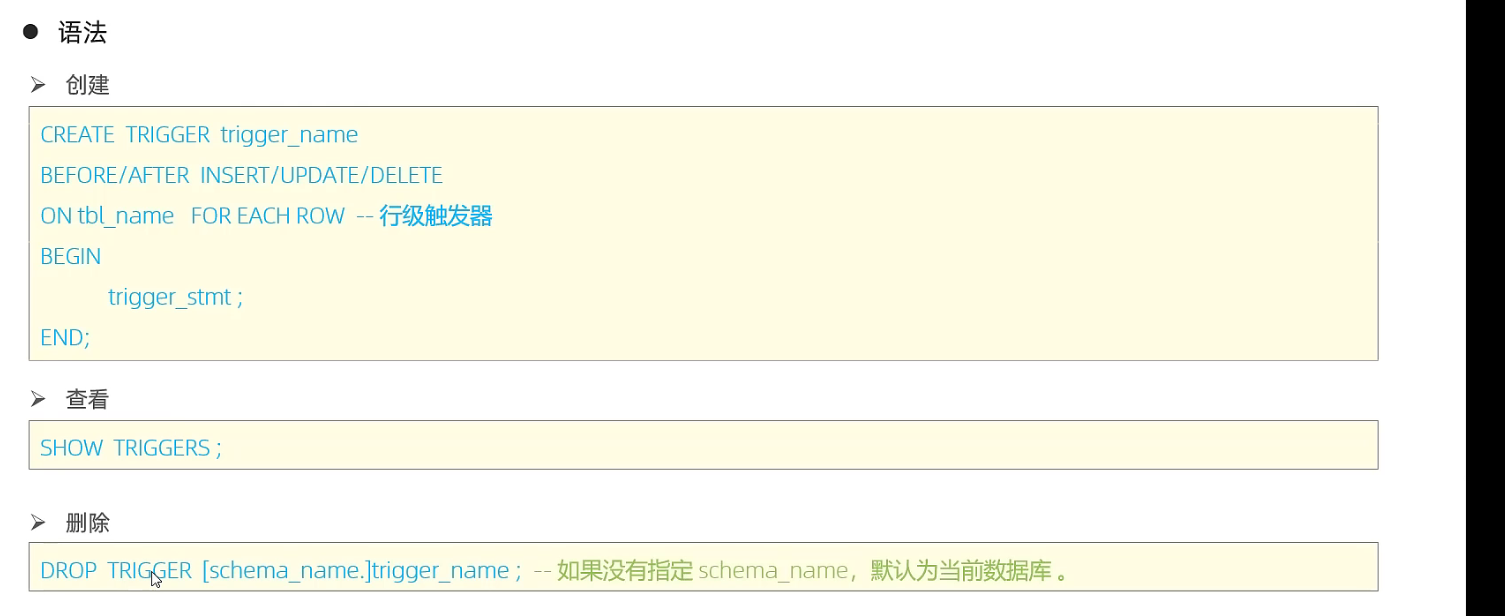
4.4 触发器

4.5 总结
5. 锁
5.1 概述
锁是计算机协调多个进程或线程并发访问某一资源的机制.
5.2 全局锁
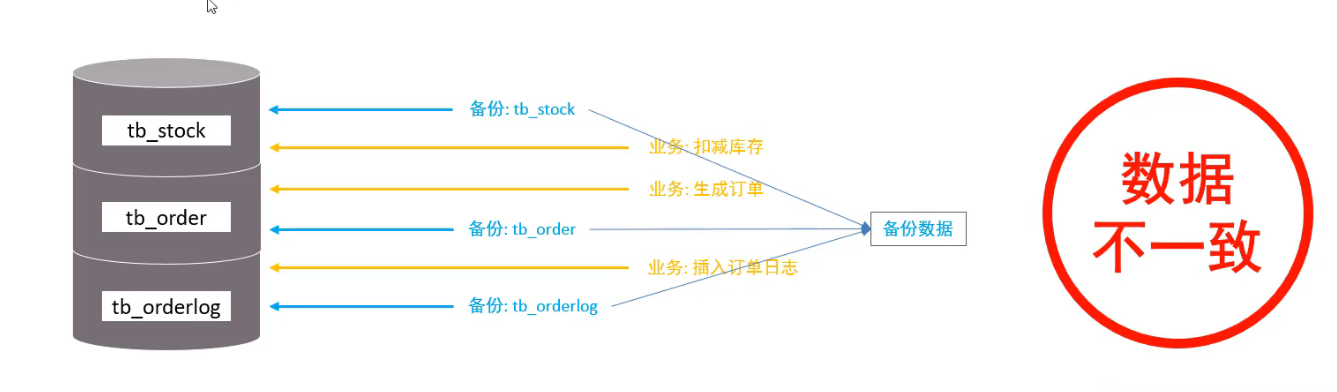
全局锁对整个数据库实例进行加锁, 加锁后的整个实例就处于只读状态.
最典型的应用场景是做全库的逻辑备份. 对所有表进行锁定, 保证数据一致性.
# 检查磁盘空间是否充足:
df -h
# 配置账户权限
GRANT SELECT, RELOAD, LOCK TABLES, REPLICATION CLIENT ON *.* TO 'backup_user'@'localhost' IDENTIFIED BY '密码';
FLUSH PRIVILEGES;
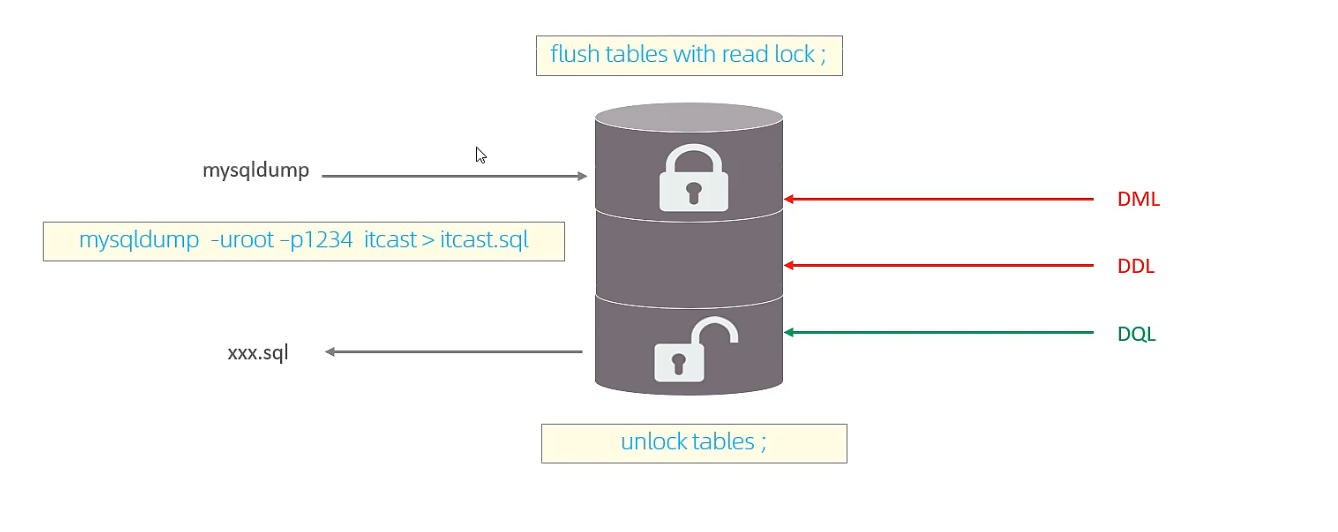
# 添加全局锁, 对某个数据库服务的所有数据库进行加锁
FLUSH TABLES WITH READ LOCK;
# 逻辑备份
# 备份单个库 操作系统命令行运行
mysqldump -u 用户 -p 密码 --databases 库名 > /路径/备份名.sql
# 备份所有库
mysqldump -u 用户 -p 密码 --all-databases > /路径/全量备份.sql
# 压缩备份
mysqldump -u 用户 -p 密码 库名 | gzip > 备份.sql.gz
# 解锁
UNLOCK TABLES;
- 特点
- 如果在主库上备份,那么在备份期间都不能执行更新. 业务基本上就得停摆
- 如果在从库上备份,那么在备份期间从库不能执行主库同步过来的二进制日志(binlog), 会导致主从延迟.
- 在InnoDB中, 可以在备份时加上参数
--single-transaction参数来完成不加锁的一致性数据备份.
mysqldump --single-transaction -uroot -proot -h192.168.56.2 test_lock > test.sql # 底层通过快照读实现
5.3 表级锁
每次操作锁住整张表.
分类:
- 表锁
- 元数据锁(meta data lock, MDL)
- 意向锁
表锁
- 表共享读锁(read lock)
# 加锁
LOCK TABLES table_a read;
# 解锁, 客户端连接断开会自动解锁
UNLOCK TABLES
- 表独占写锁(write lock)
# 加锁
LOCK TABLES table_a write;
UNLOCK TABLES;
元数据锁(meta data lock, MDL)
MDL加锁过程是系统自动控制, 无需显示使用. 在访问一张表的时候会自动加上. MDL锁主要作用是维护表元数据的数据一致性. 在表上有活动的事务时, 不可以对元数据进行写入操作. 为了避免DML和DDL冲突, 保证读写的正确性。
维护表结构的数据一致性.
即: 在某张表存在活动的事务时, 不能修改该表的表结构.
在MySQL5.5中引入了MDL,当对一张表进行增删改査的时候,加MDL读锁(共享);当对表结构进行变更操作的时候,加MDL写锁(排他)。

查看元数据锁:
select object_type,object_schema,object_name,lock_type,lock_duration from performance_schema.metadata_locks ;
意向锁
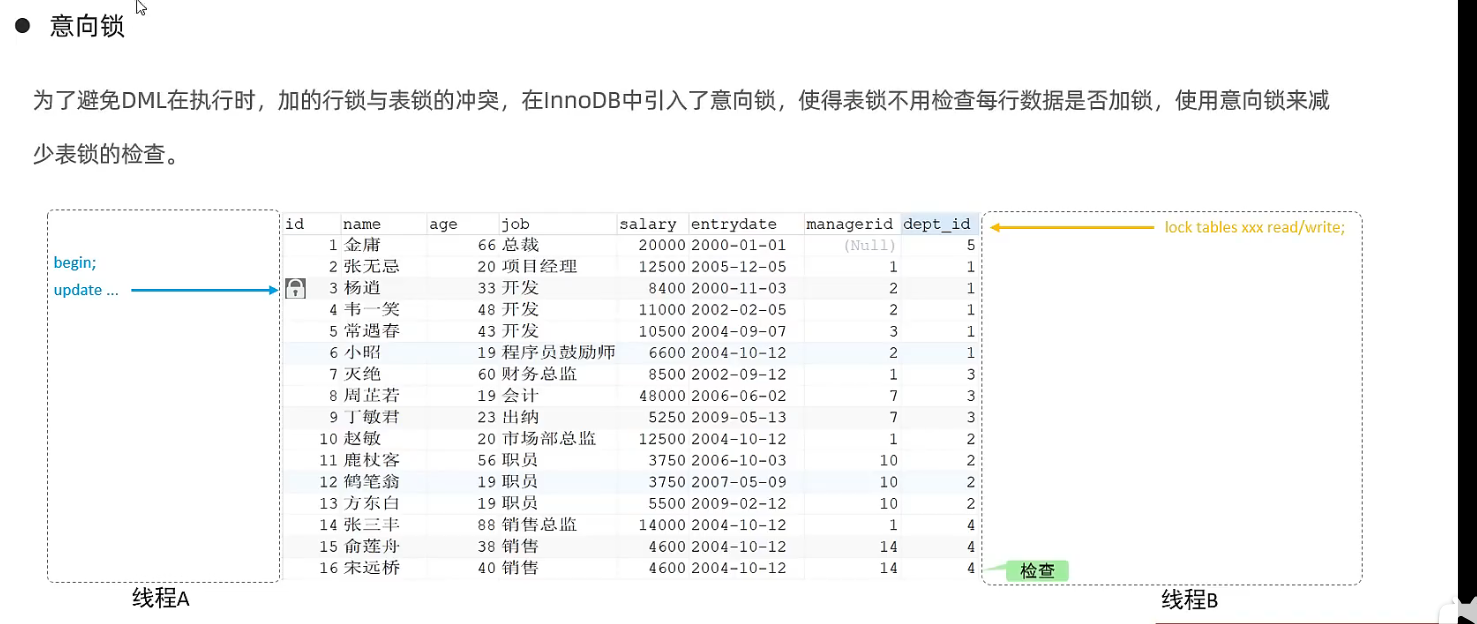


select object_type,object_schema,object_name,lock_type,lock_duration from performance_schema.data_locks;
5.4 行级锁
- 介绍
行级锁, 每次操作锁住对应的行数据。锁定粒度最小, 发生冲突的概率最低, 并发度最高。 应用到InnoDB中。
InnoDB是基于索引组织数据的。 行锁是通过对索引上的索引项加锁来实现的,而不是对记录加的锁。
-
行级锁分类
-
行锁(Record Lock):锁定单个行记录的锁。防止其他事务对此进行update和delete。RC和RR都支持

-
间隙锁(Gap Lock):锁定某个记录间隙(不含该记录)。确保索引记录间隙不变。防止其他事务在此间隙进行insert,产生幻读。在RR隔离级别下支持。

-
临键锁(Next-Key Lock):行锁和间隙锁的组合,同时锁住数据,并锁住前面的间隙。在RR下支持。

-

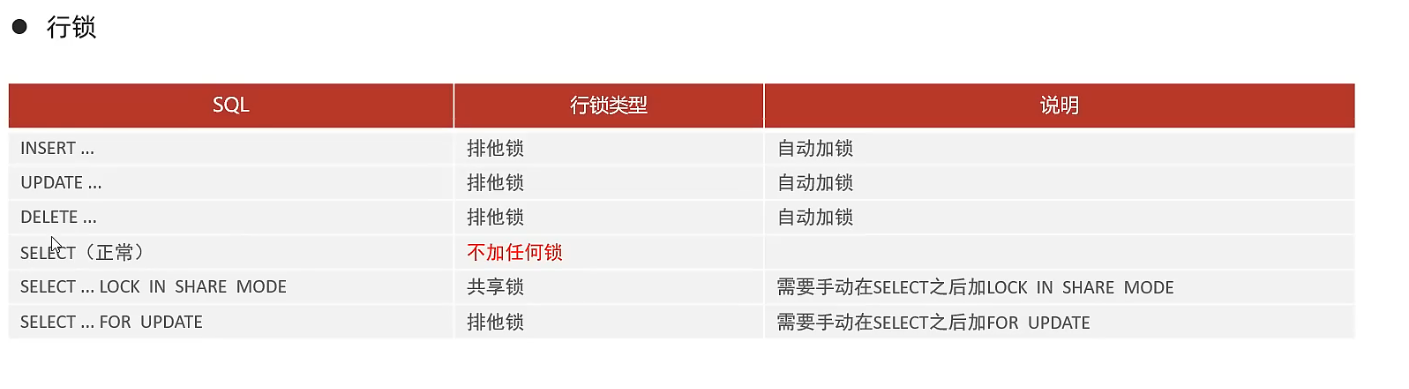
加了共享锁后,其他事务不能在该查询的区间之内进行insert,update、delete操作。


select * from a;
# +----+-------+------+
# | id | name | age |
# +----+-------+------+
# | 1 | tom | 111 |
# | 5 | zs | 38 |
# | 10 | jully | 30 |
# +----+-------+------+
# 3 rows in set (0.00 sec)
# 事务A
update a set name = "TT" where id = 2; # id=2数据不存在,自动升级为间隙锁,锁住1<id<5的间隙,防止插入操作
#Query OK, 0 rows affected (0.00 sec)
#Rows matched: 0 Changed: 0 Warnings: 0
# 事务B
insert into a (id,name,age) value(2,"jully",30); # 插入id=2的数据失败,因为有间隙锁

6. InnoDB引擎
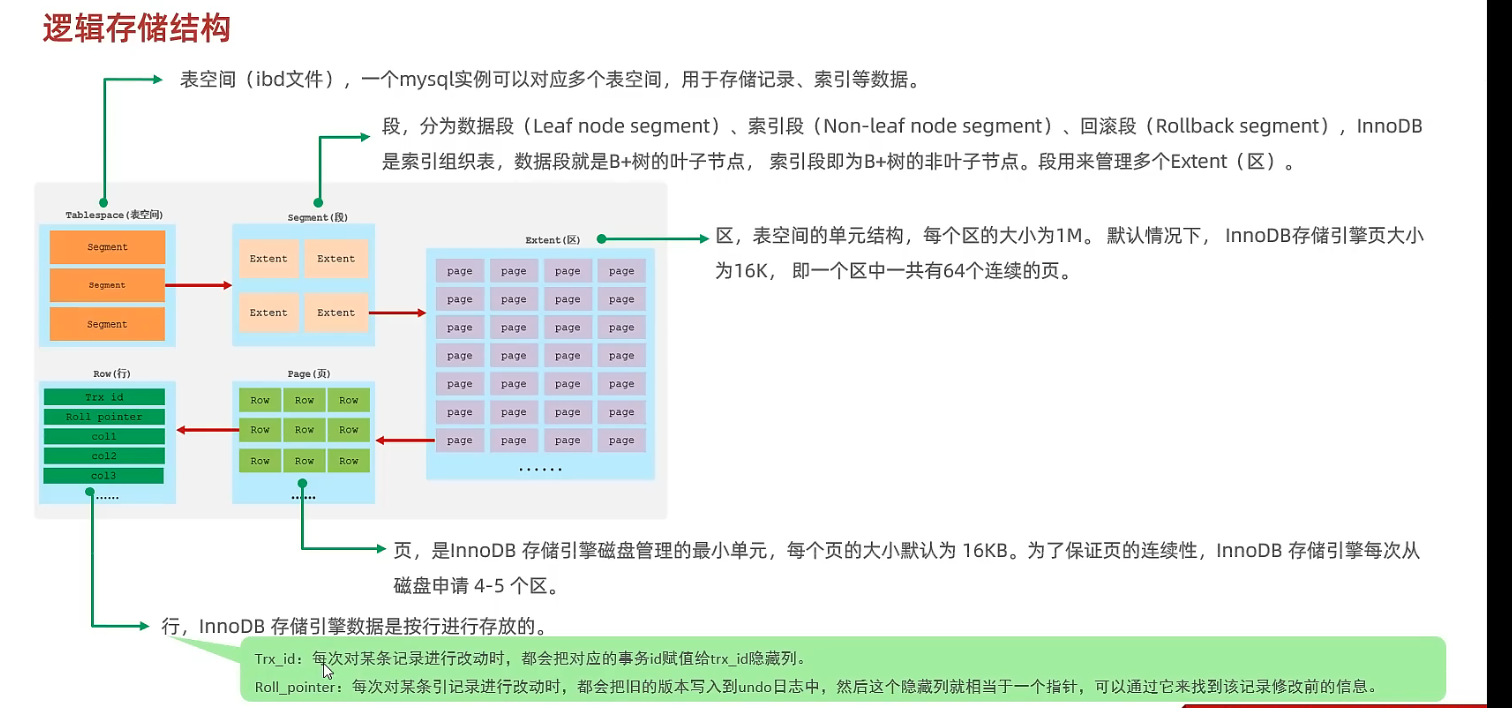
6.1 逻辑存储结构
6.2 架构
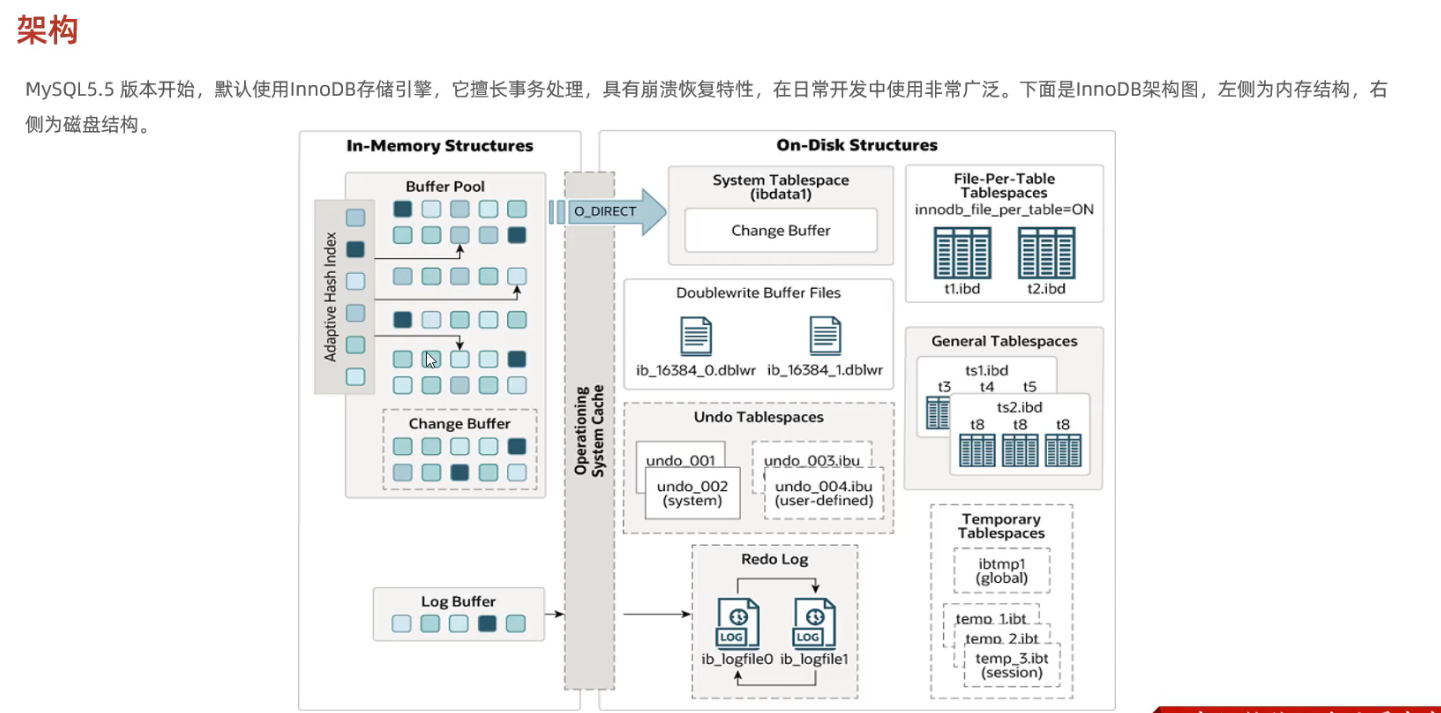
-
内存结构
-
磁盘结构
-
后台线程

6.3 事务原理
事务是一组操作的集合, 它是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求。 这些操作要么同时成功,要么同时失败。

redo log
MYSQL查询和插入数据的流程是怎样的 - 大魔王先生 - 博客园
物理数据页大小是16KB,刷盘比较耗时,可能就修改了数据页里的几 Byte 数据,有必要把完整的数据页刷盘吗?
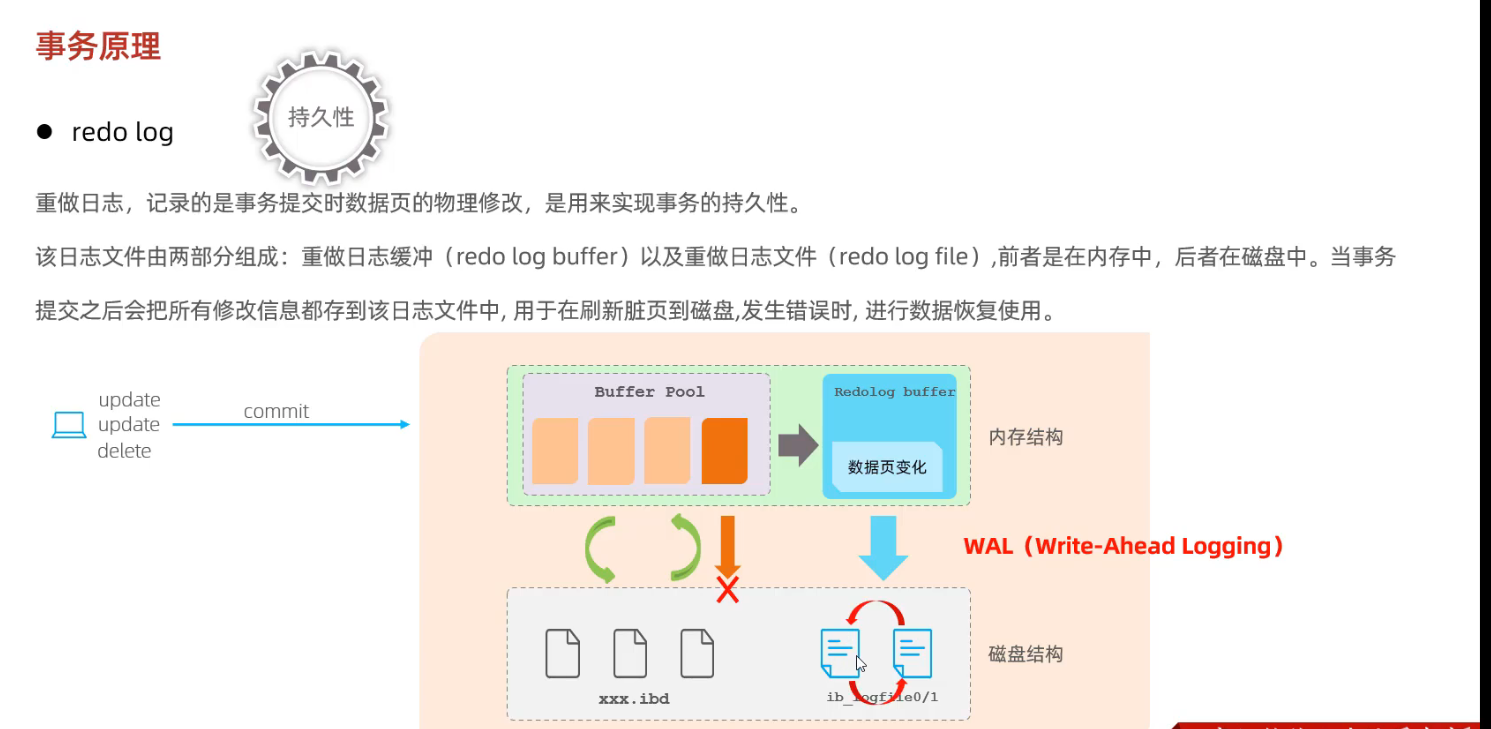
保证事务的持久性:如果buffer pool缓冲池中的脏页【脏数据】还没有进行刷盘的时候,此时数据库发生crash,重启服务后,我们可以通过redo log日志找到需要重放到磁盘文件的那些数据记录。
提高事务提交的速度: buffer pool缓冲池中的数据直接刷新到磁盘,是一个随机IO,效率较差,而把buffer pool中的数据记录到redo log,是一个顺序IO,可以提高事务提交的速度
undo log

6.4 MVCC
1) 基本概念
- 当前读
读取的是记录的最新版本。读取时还要保证其他的并发事务不能修改当前记录。会对读取的记录进行加锁。对于我们日常的操作,比如:
select ... lock in share mode; # 共享锁 - 当前读
select ... for update,delete,insert; # 排他锁 - 当前读
以上都是当前读。
- 快照读
简单的select语句(不加锁)就是快照读。非阻塞读。
Read Committed: 每次select,都生成一个快照读
Repeatable Read:开启事务后,第一个select语句才是快照读的地方
Serializable: 快照读会升级为当前读
- MVCC
全称Multi-Version Concurrency Control:多版本并发控制
指维护一个数据的多个版本,使得读写操作没有冲突,快照读为MySQL实现MVCC提供了一个非阻塞读的功能。
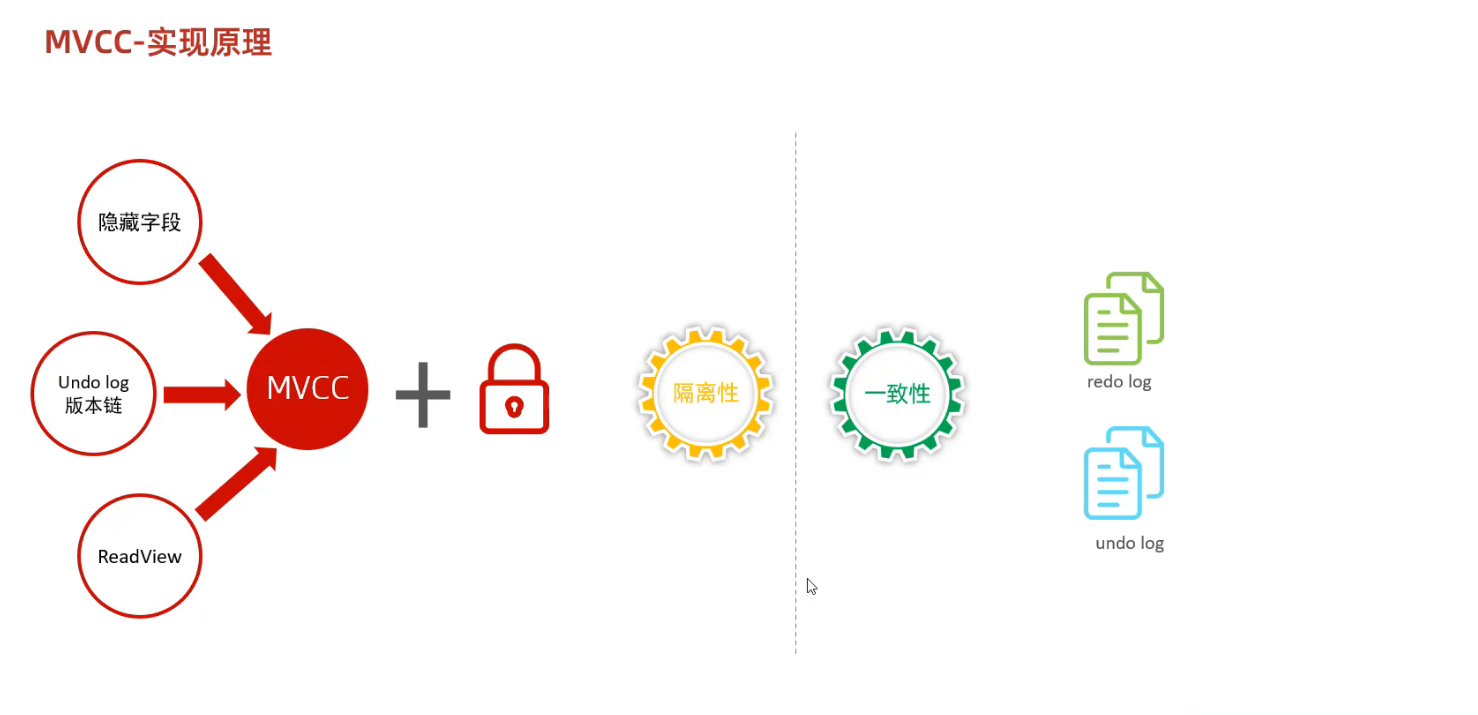
MVCC具体的实现,还需要依赖于数据库记录的二/三个隐式字段, undo log日志, readview
1) 记录当中的隐藏字段

表中有主键时不会生成DB_ROW_ID
# 查询表信息
show columns from user;
select * from INFORMATION_SCHEMA.COLUMNS where TABLE_NAME = 'user' and TABLE_SCHEMA='test';
# 使用 ibd2sdi工具可以解析 InnoDB 的表空间文件(.ibd 文件),查看表的元数据信息,其中就包含了这些隐藏字段
# 磁盘文件夹下
ibd2sdi table_a.ibd # 查看表的详细信息
3) undo log日志
回滚日志, 在insert, update, delete的时候产生的便于数据回滚的日志.
当insert的时候, 产生的undo log日志只在回滚时需要, 在事务提交后, 可被立即删除.
而update, delete的时候, 产生的undo log日志不仅在回滚时需要, 在快照读时也需要, 不会立即删除.
| 操作类型 | Undo Log 类型 | 事务提交后是否立即删除 | 主要原因 | 最终清理方式 |
|---|---|---|---|---|
| INSERT | Insert Undo Log | 可以 | 新插入的数据只对当前事务可见,其他事务不需要访问其旧版本。 | 事务提交后可直接删除,无需 Purge 线程干预。 |
| UPDATE/DELETE | Update Undo Log | 不可以 | 需为其他事务提供 MVCC(多版本并发控制) 读视图,保证可重复读和读已提交的隔离级别。 | 由后台 Purge 线程在确定无人使用时异步清理。 |
4) undo log版本链
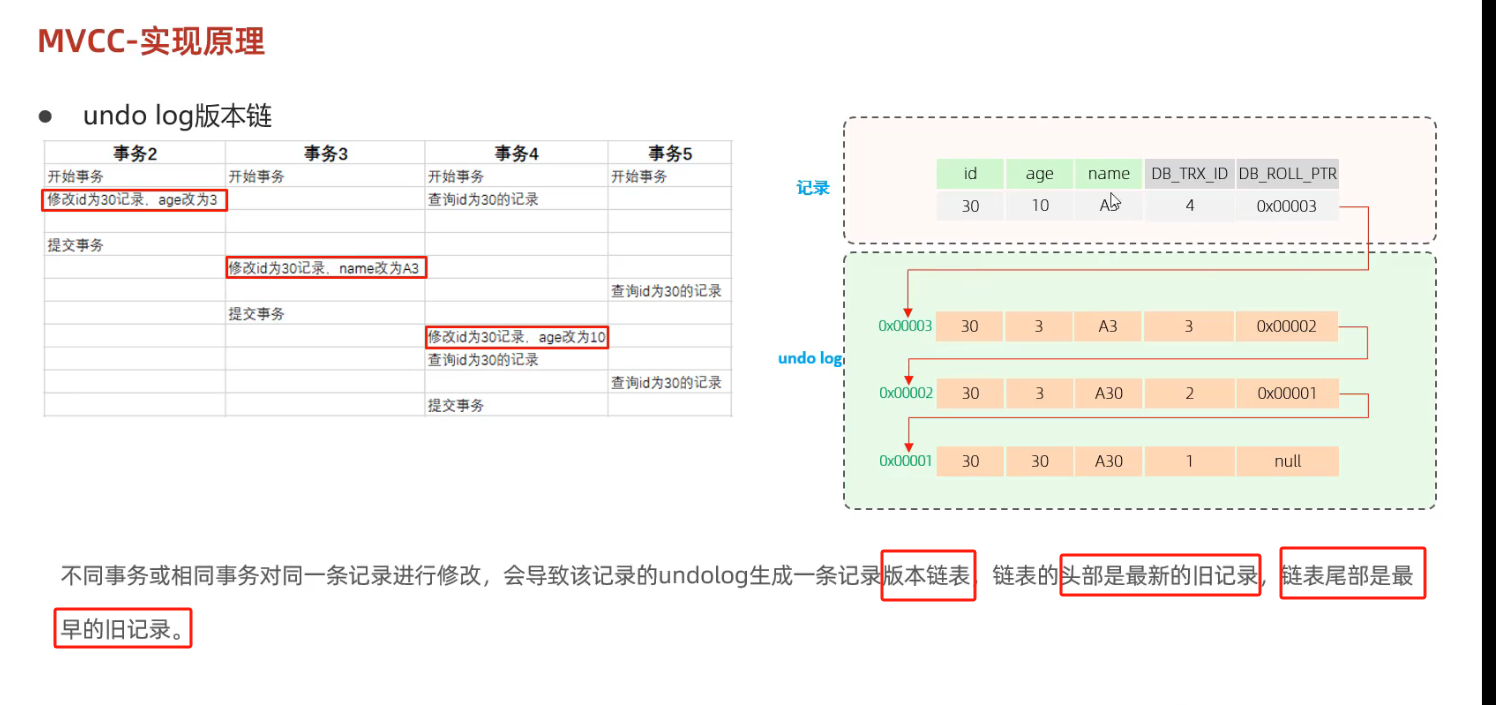
5) read view
Read View是快照读SQL执行时MVCC提取数据的依据, 记录并维护系统当前活跃的事务(未提交的事务) id;
Read View包含四个核心字段:


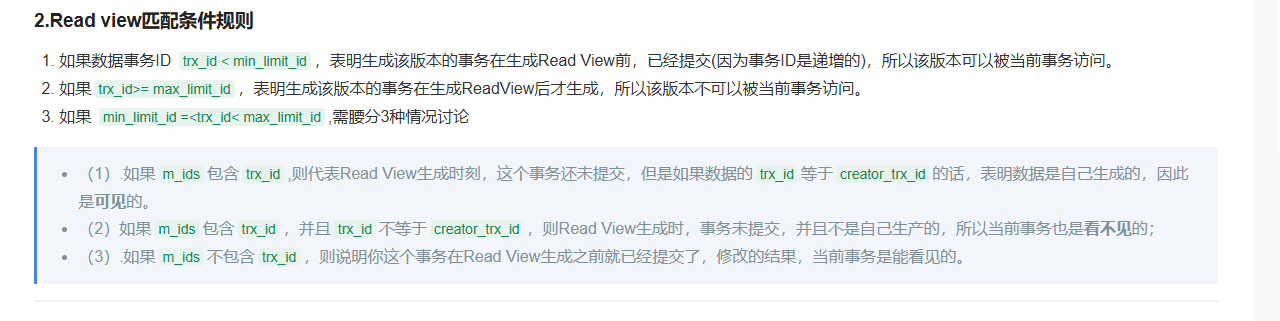
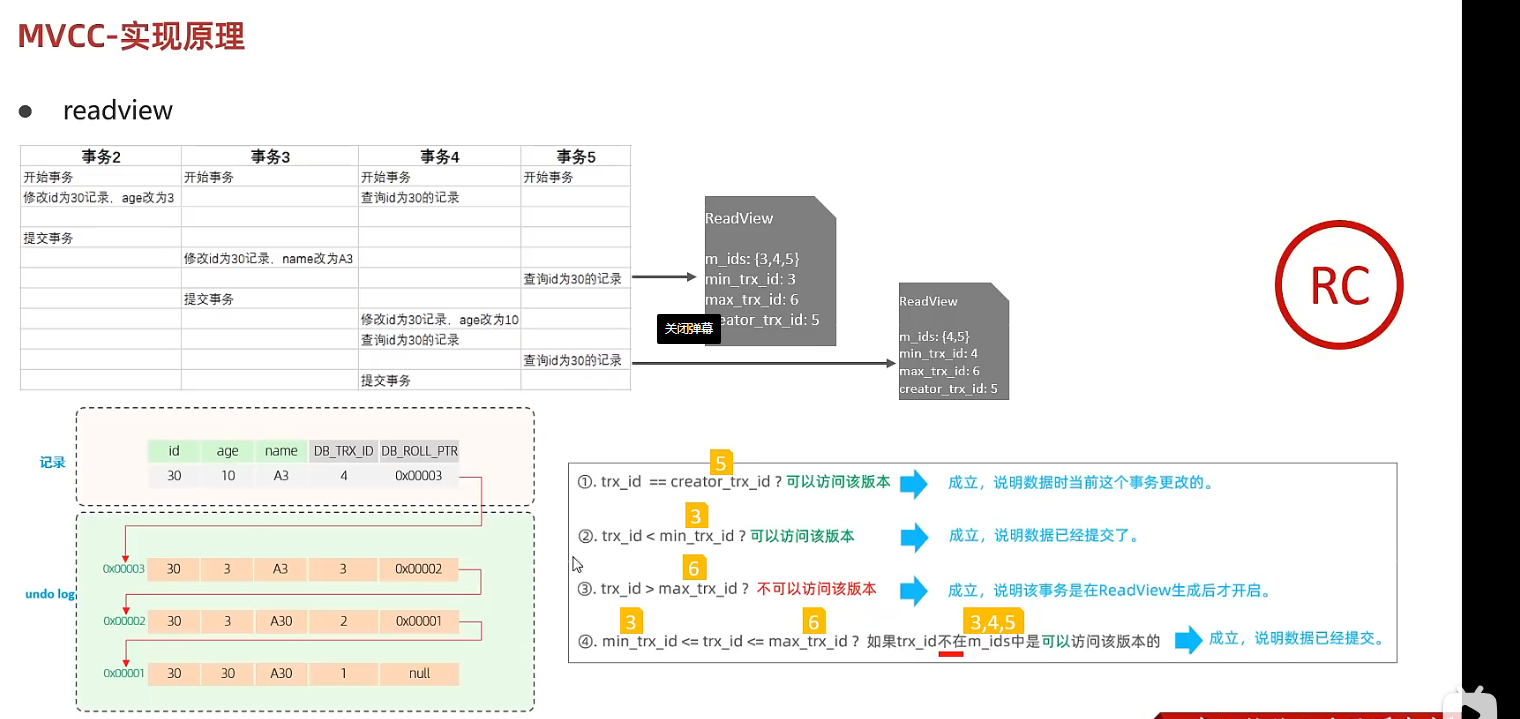
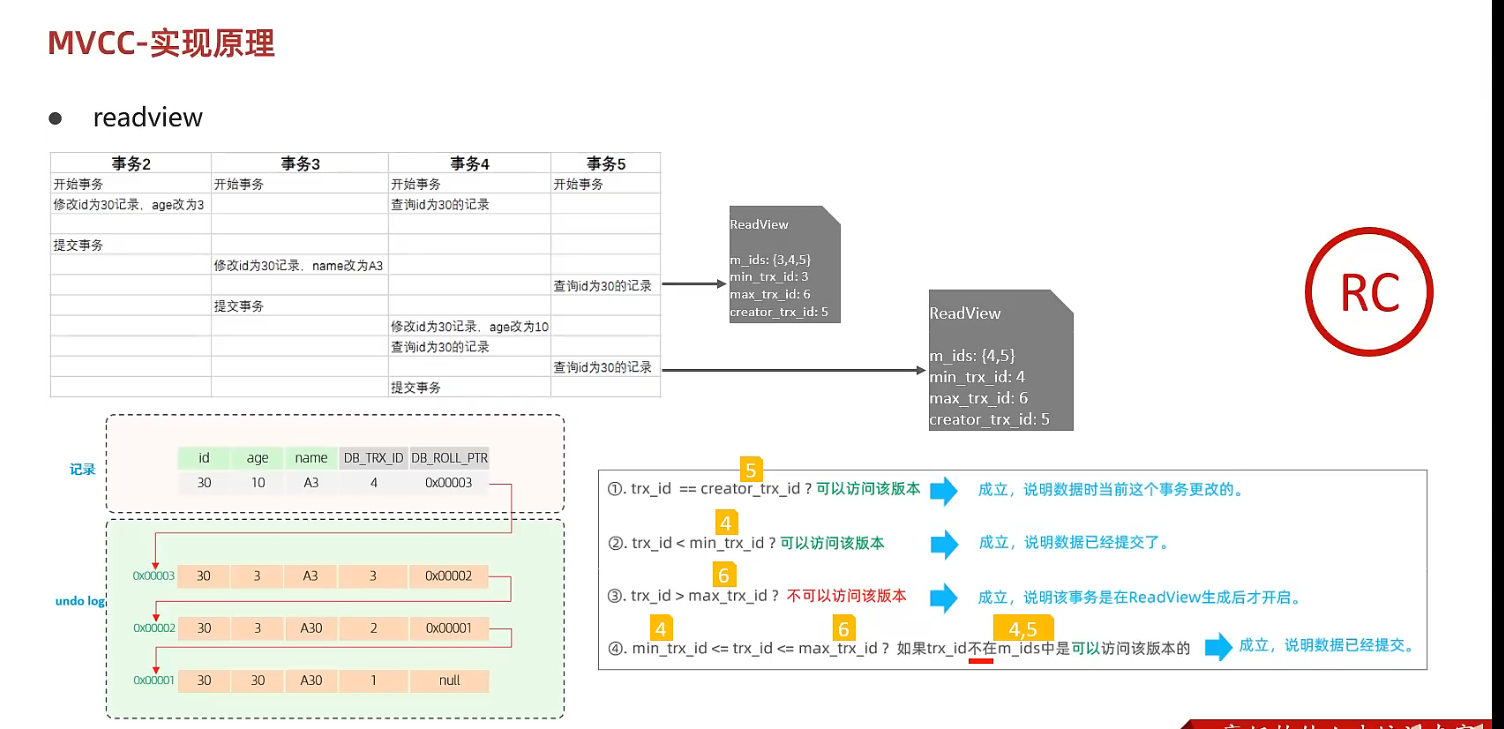
trx_id: 当前记录最后一次修改者的id;(待定)某个事务id
RC隔离级别下:
RR隔离级别下:
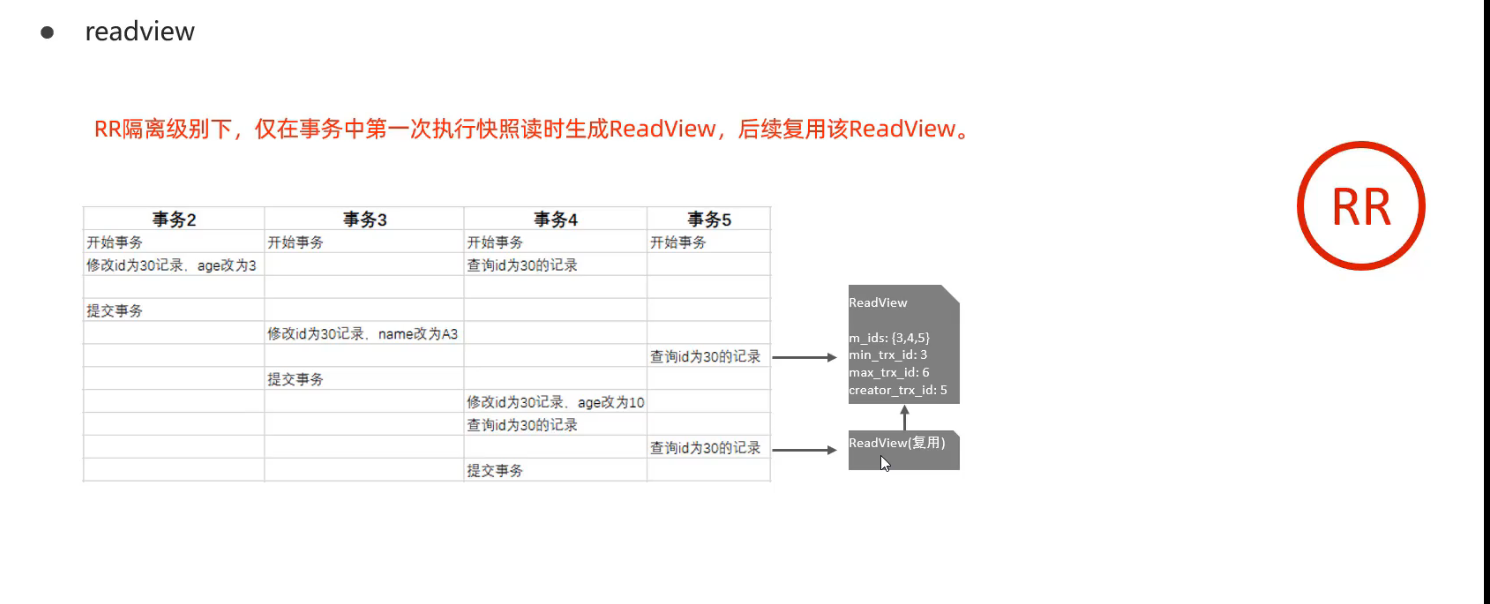
小结

7. MySQL管理
7.1 系统数据库

7.2 常用工具

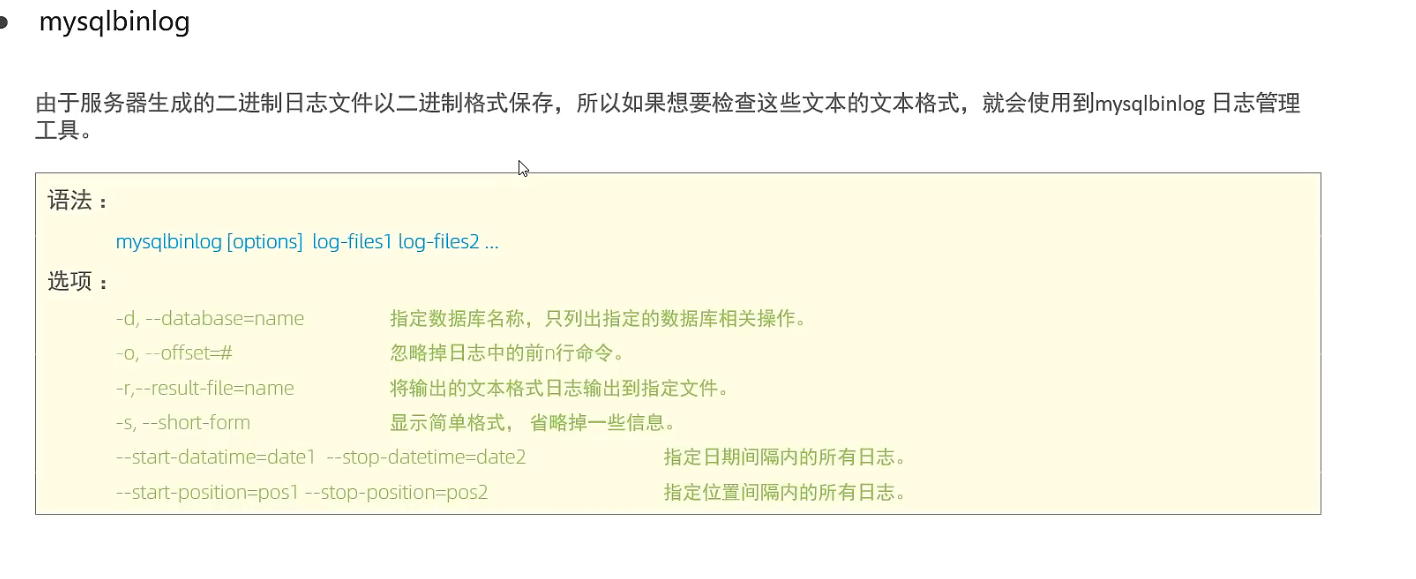
mysqlbinlog

mysqldump
数据库备份

数据库导入
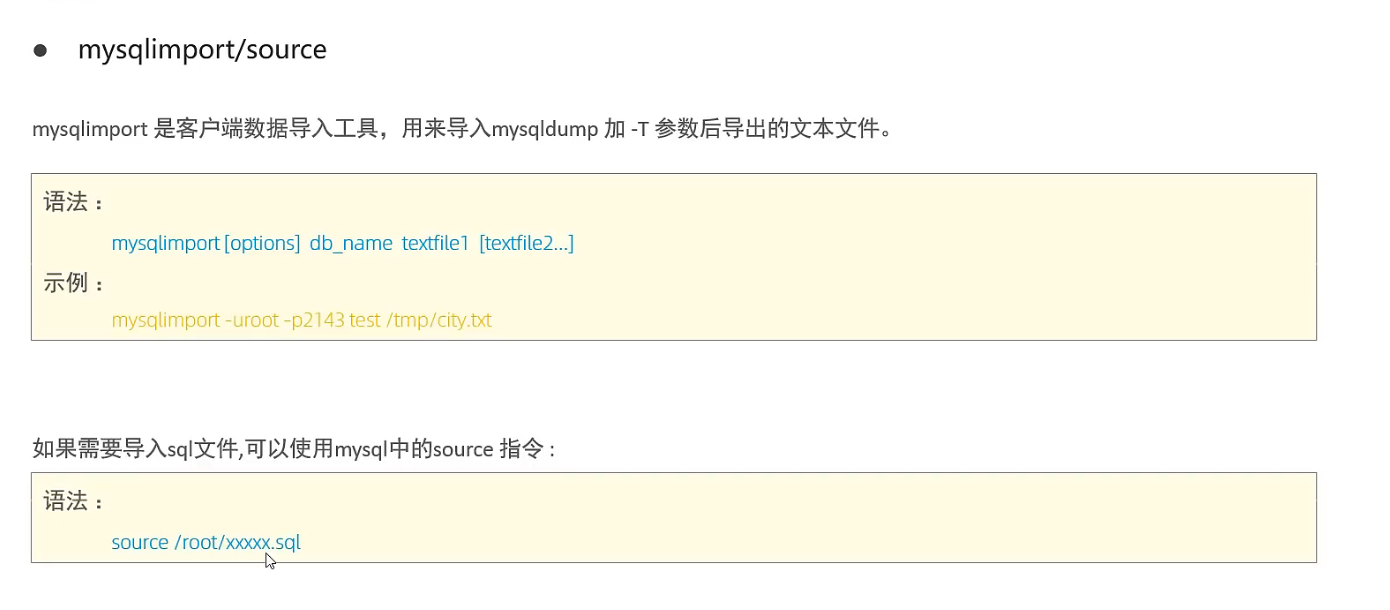

进阶篇总结
运维
1. 日志
1.1 错误日志
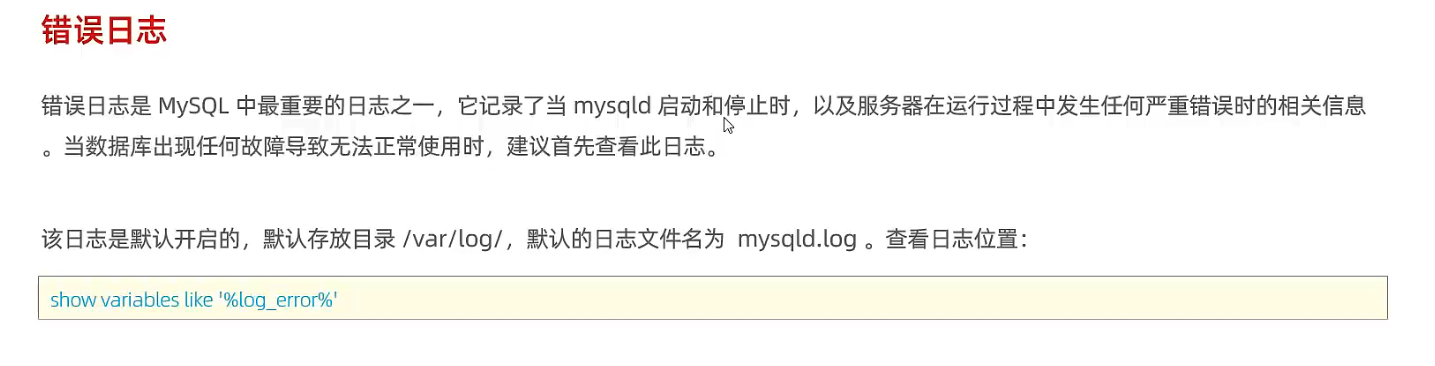
# 错误日志默认存放在/var/log/mysqld.log
SHOW VARIABLES LIKE "%log_error%";
1.2 二进制日志

# 查看二进制日志状态
SHOW VARIABLES LIKE "%log_bin";
# 在配置文件的[mysqld]中添加如下配置 ,
log-bin = /server/mysql_data/mysql-bin
# 重启数据库后配置即可生效
/etc/init.d/mysqld restart
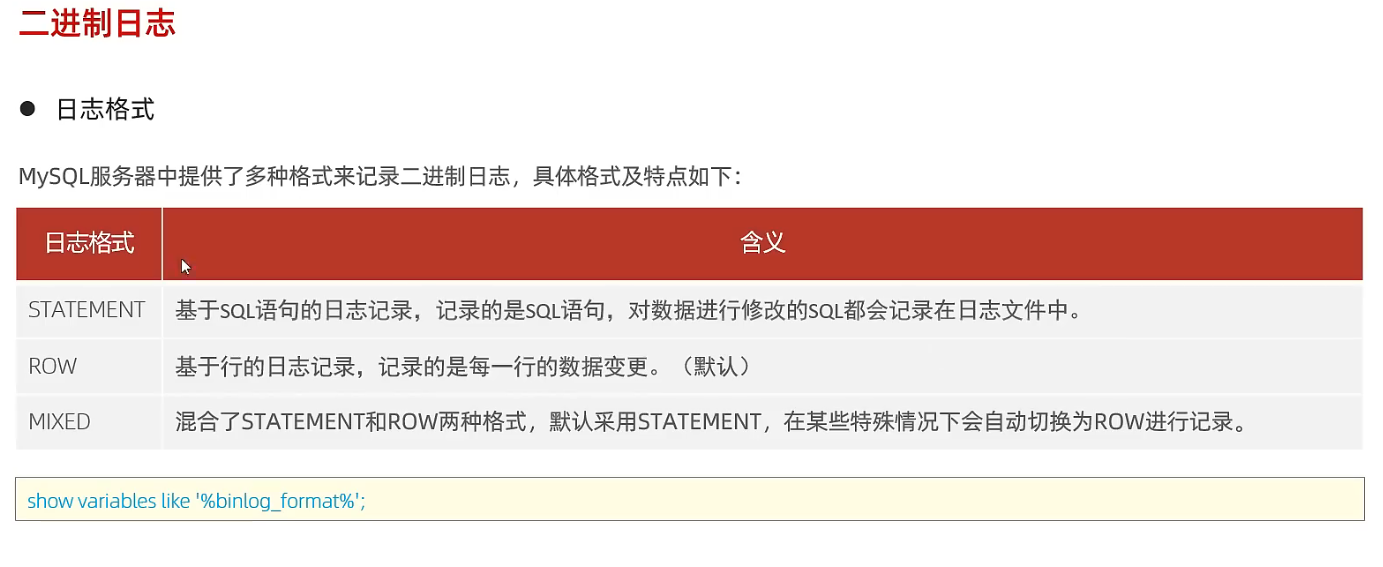
SHOW VARIABLES LIKE "%binlog_format%";

# 查询二进制日志默认过期时间
SHOW VARIABLES LIKE "%binlog_expire%";
1.3 查询日志
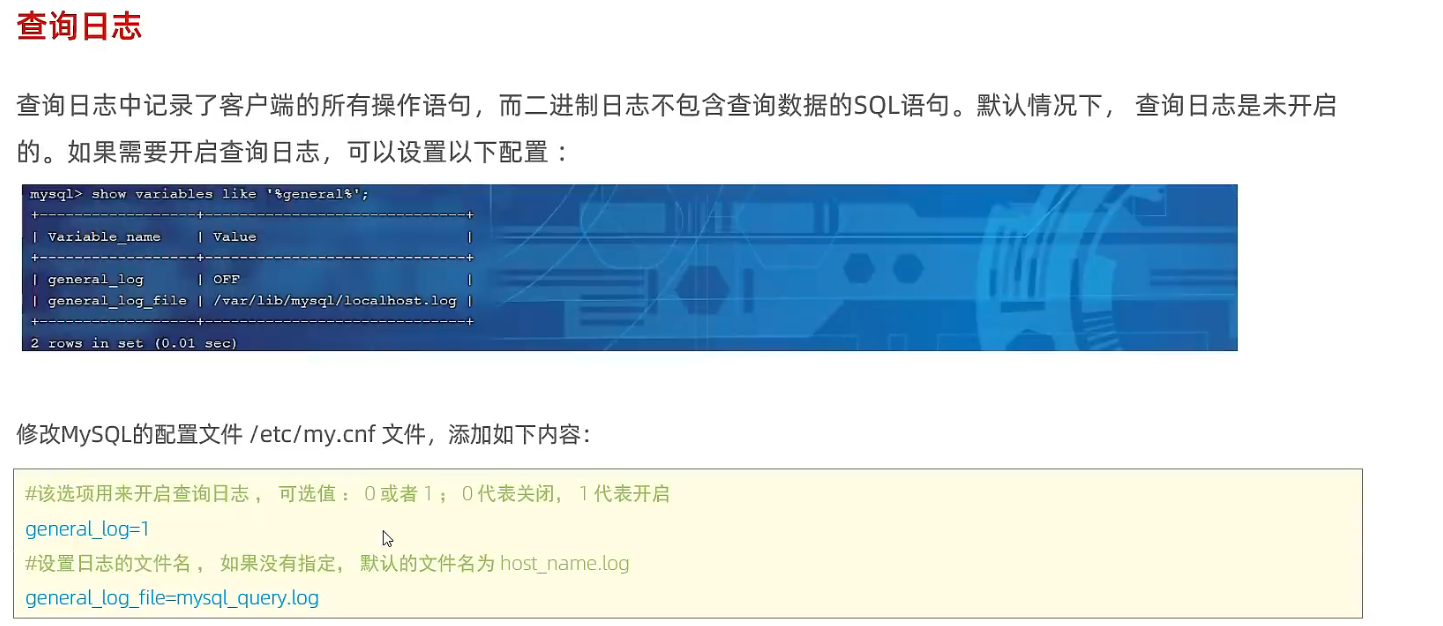
SHOW VARIABLES LIKE "%general%";
1.4 慢查询日志

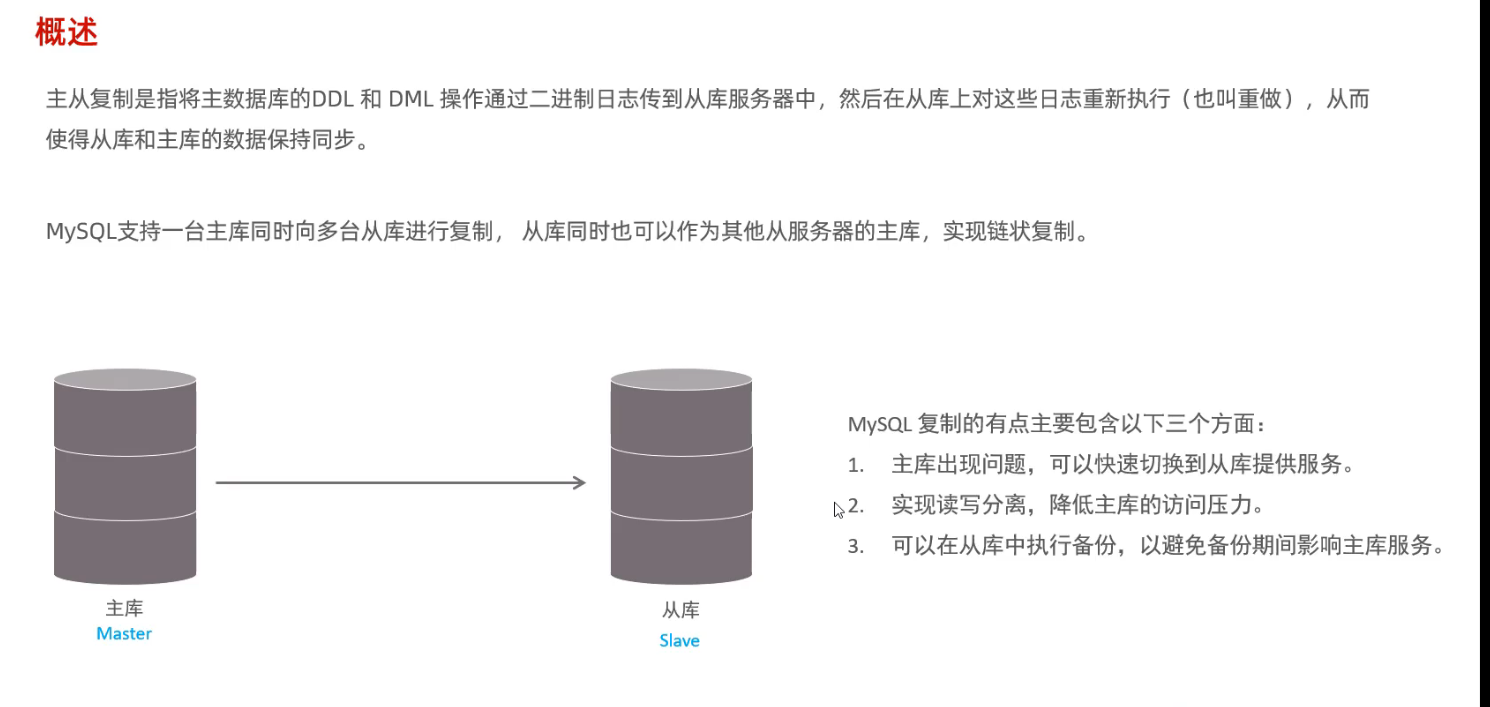
2. 主从复制
2.1 概述
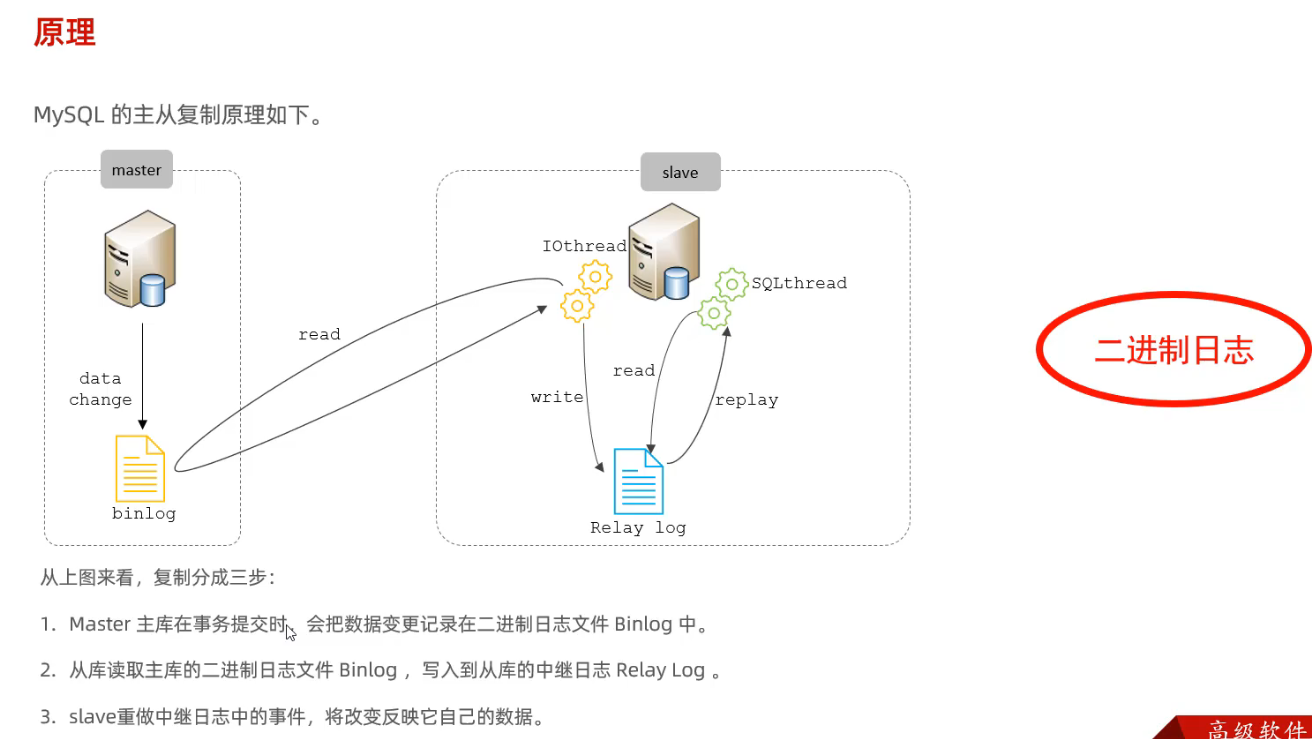
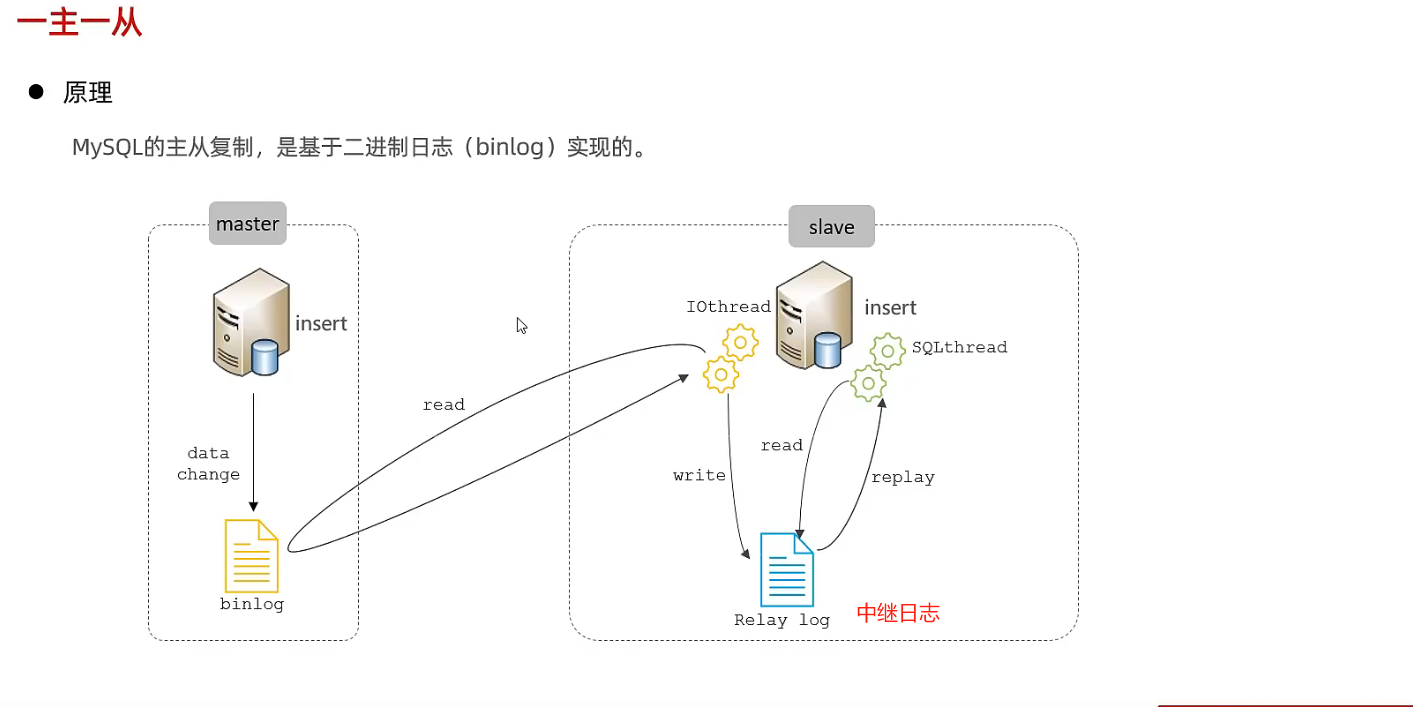
2.2 原理
2.3 搭建
1) 服务器准备

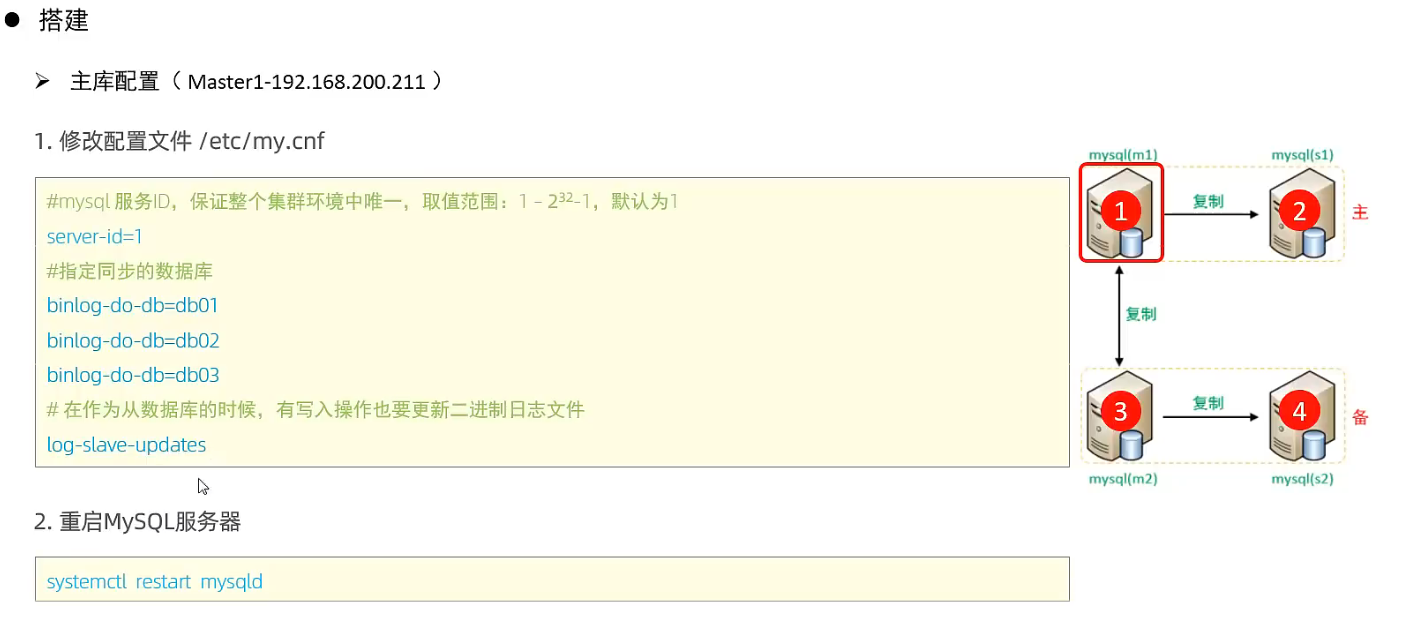
2) 主库配置
1 修改配置文件/etc/my.cnf
#
# Remove leading # and set to the amount of RAM for the most important data
# cache in MySQL. Start at 70% of total RAM for dedicated server, else 10%.
# innodb_buffer_pool_size = 128M
#
# Remove leading # to turn on a very important data integrity option: logging
# changes to the binary log between backups.
# log_bin
#
# Remove leading # to set options mainly useful for reporting servers.
# The server defaults are faster for transactions and fast SELECTs.
# Adjust sizes as needed, experiment to find the optimal values.
# join_buffer_size = 128M
# sort_buffer_size = 2M
# read_rnd_buffer_size = 2M
host-cache-size=0
skip-name-resolve
datadir=/var/lib/mysql
socket=/var/run/mysqld/mysqld.sock
secure-file-priv=/var/lib/mysql-files
user=mysql
pid-file=/var/run/mysqld/mysqld.pid
[client]
socket=/var/run/mysqld/mysqld.sock
!includedir /etc/mysql/conf.d/
# [mysqld] 定义mysqld区块
[mysqld]
# mysql 服务id,保证在整个集群环境中唯一,取值范围: 1~2^32 -1, 默认唯一
server-id=1
# 是否只读, 读写:0, 只读:1;
read-only=0
# 忽略的数据库,即不需要同步的数据库
# binlog-ignore-db=mysql
# 指定同步的数据库
# binlog-do-db=db01
docker network create mysql_net
docker pull mysql:latest
# 主库
docker run -p 3307:3306 --network mysql_net --name mysql_master \
-v /temp_mnt/mysql_master/log:/var/log/mysql \
-v /temp_mnt/mysql_master/data:/var/lib/mysql \
-v /temp_mnt/mysql_master/conf:/etc/mysql/conf.d \
-e MYSQL_ROOT_PASSWORD=root \
-d mysql:latest
# 从库
docker run -p 3308:3306 --network mysql_net --name mysql_slave \
-v /temp_mnt/mysql_slave/log:/var/log/mysql \
-v /temp_mnt/mysql_slave/data:/var/lib/mysql \
-v /temp_mnt/mysql_slave/conf:/etc/mysql/conf.d \
-e MYSQL_ROOT_PASSWORD=root \
-d mysql:latest
# 从库2
docker run -p 3309:3306 --network mysql_net --name mysql_slave2 \
-v /temp_mnt/mysql_slave2/log:/var/log/mysql \
-v /temp_mnt/mysql_slave2/data:/var/lib/mysql \
-v /temp_mnt/mysql_slave2/conf:/etc/mysql/conf.d \
-e MYSQL_ROOT_PASSWORD=root \
-d mysql:latest
2 重启mysql
systemctl restart mysqld
确保server id已经修改
SHOW VARIABLES LIKE 'server_id';
# 确保read_only 不是OFF
show global variables like "%read_only%";
3 登录master, 创建远程连接的账号, 并授予主从复制权限
# 创建用户backup, 并设置密码, 该用户可在任意主机连接该mysql服务
CREATE USER 'backup'@'%' IDENTIFIED BY 'backup';
# 为backup用户分配主从复制权限
GRANT REPLICATION SLAVE ON *.* TO 'backup'@'%';
4 通过指令, 查看二进制日志坐标
show binary log status; # 不同版本此命令有区别
# mysql> show binary log status;
# +---------------+----------+--------------+------------------+-------------------+
# | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
# +---------------+----------+--------------+------------------+-------------------+
# | binlog.000003 | 686 | | | |
# +---------------+----------+--------------+------------------+-------------------+
# 1 row in set (0.00 sec)
字段含义说明
file: 从哪个日志文件开始推送日志文件
position: 从哪个位置开始推送日志
Binlog_Do_DB : 指定需要同步的数据库
3) 从库配置
1 修改配置文件/etc/my.cnf
# [mysqld] 定义区块
# mysql 服务id,保证在整个集群环境中唯一,取值范围: 1~2^32 -1, 默认唯一
[mysqld]
server-id=2
# 是否只读, 读写:0, 只读:1; 普通用户只读
read-only=1
# 超级管理员只读
super-read-only=1
2 重启slave
systemctl restart mysqld
# 确保server id已修改,并与主库不同
SHOW VARIABLES LIKE 'server_id';
# 确保read_only 不是OFF
show global variables like "%read_only%";
3 登录slave 设置主库配置
# 8.0.23 版本
CHANGE REPLICATION SOURCE TO
SOURCE_HOST='mysql_master',
SOURCE_USER='backup',
SOURCE_PASSWORD='backup',
SOURCE_PORT=3306,
SOURCE_LOG_FILE='binlog.000003',
SOURCE_LOG_POS=686, -- 主库初始状态的bin log location是 686
GET_SOURCE_PUBLIC_KEY=1; -- 关键参数
START REPLICA; -- 重启复制
# 如果是旧版本,使用如下命令
CHANGE MASTER TO MASTER_HOST='mysql_master', MASTER_USER='backup',MASTER_PASSWORD='backup',MASTER_LOG_FILE='xxx',MASTER_LOG_POS='';
##在从库的 CHANGE REPLICATION SOURCE TO 命令中添加 GET_SOURCE_PUBLIC_KEY=1 参数,使从库主动请求主库的公钥加密密码:
#STOP REPLICA; -- 停止复制
#RESET REPLICA ALL; -- 清除旧配置
#CHANGE REPLICATION SOURCE TO
# SOURCE_HOST='mysql_master',
# SOURCE_USER='backup',
# SOURCE_PASSWORD='backup',
# SOURCE_PORT=3306,
# SOURCE_LOG_FILE='binlog.000003',
# SOURCE_LOG_POS=686,
# GET_SOURCE_PUBLIC_KEY=1; -- 关键参数
#START REPLICA; -- 重启复制
!!! 注意: 主库如果挂掉, 重启主库后需要重新查询二进制日志坐标并配置
# 主库中执行
show binary log status; # 不同版本此命令有区别
4 开启同步
START REPLICA; # 8.0.22 之后
START SLAVE; # 8.0.22 之前
5 查看主从同步状态
SHOW REPLICA STATUS\G;
# Replica_IO_Running: Connecting 表示连接中
# Replica_IO_Running: Yes 表示同步成功
SHOW SLAVE; # 8.0.22 之前
# 重新配置需要重新写参数
#在从库的 CHANGE REPLICATION SOURCE TO 命令中添加 GET_SOURCE_PUBLIC_KEY=1 参数,使从库主动请求主库的公钥加密密码:
STOP REPLICA; -- 停止复制
RESET REPLICA ALL; -- 清除旧配置
CHANGE REPLICATION SOURCE TO
SOURCE_HOST='mysql_master',
SOURCE_USER='backup2',
SOURCE_PASSWORD='backup',
SOURCE_PORT=3306,
SOURCE_LOG_FILE='binlog.000005',
SOURCE_LOG_POS=3381,
GET_SOURCE_PUBLIC_KEY=1; -- 关键参数
START REPLICA; -- 重启复制
# 查看主从同步状态
SHOW REPLICA STATUS\G;

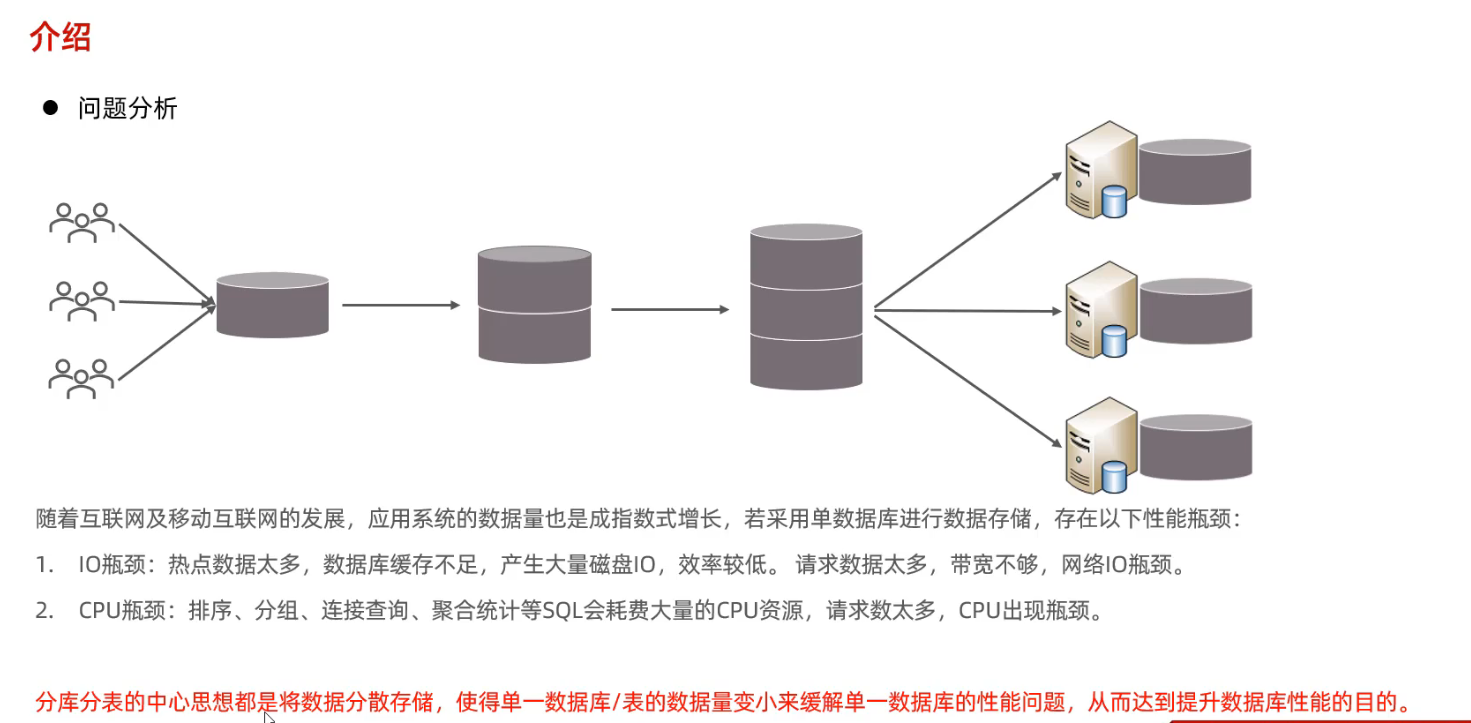
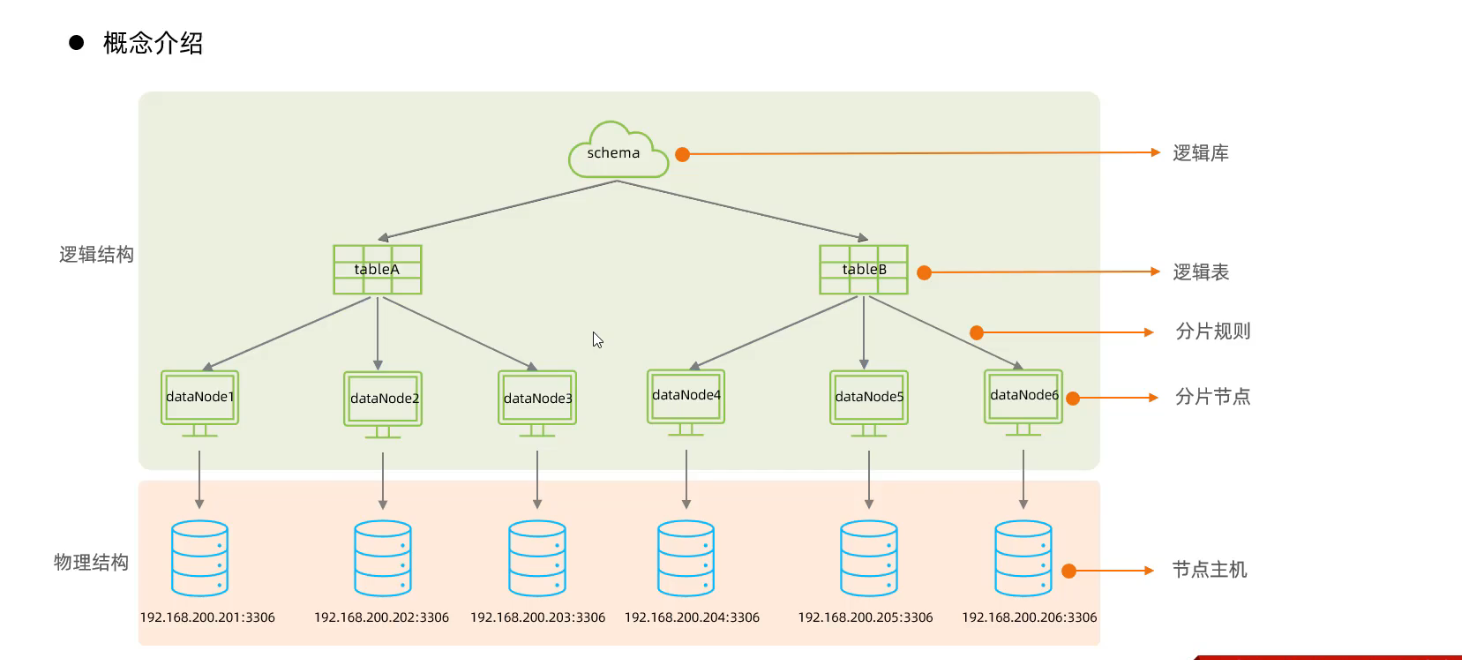
3. 分库分表
3.1 介绍
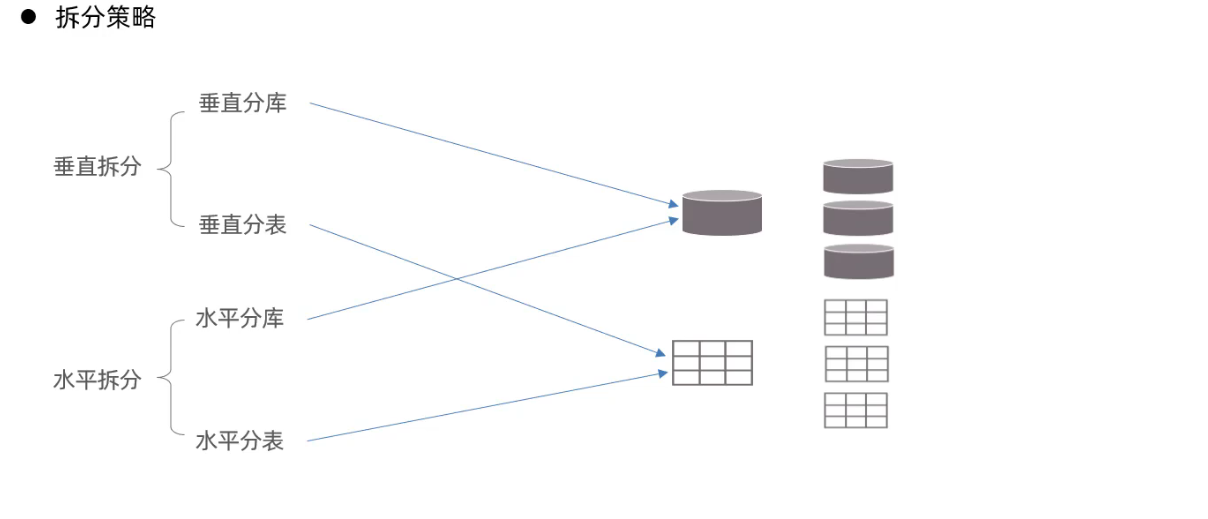
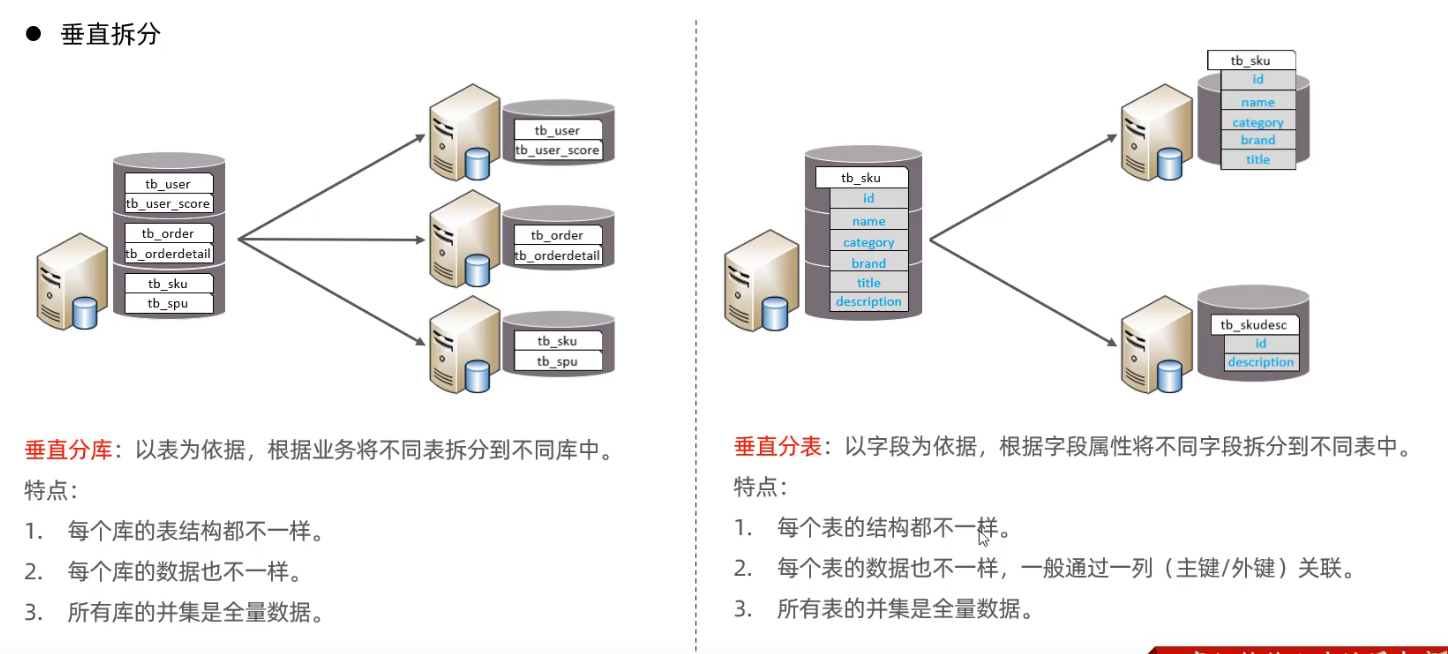
- 垂直分库与分表
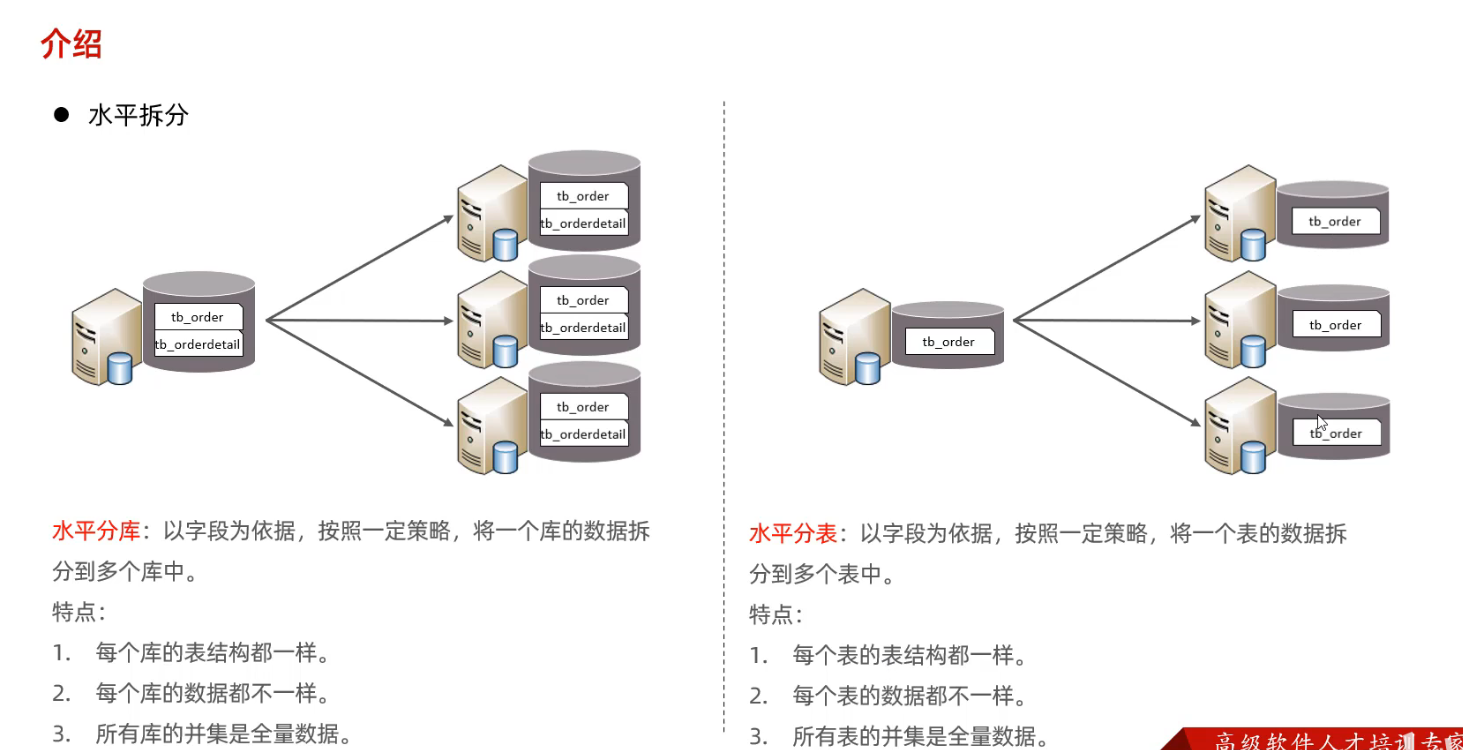
- 水平分库与水平分表

3.2 Mycat概述


GitHub - MyCATApache/Mycat-Server
3.3 Mycat入门
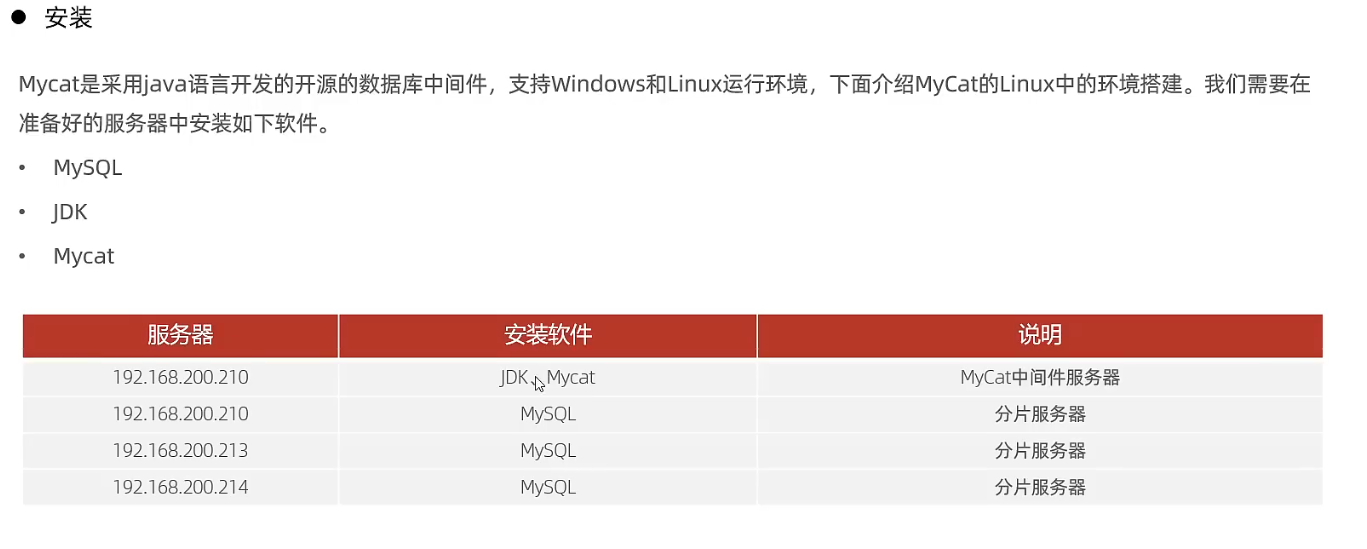

- jdk配置
# linux 中修改/etc/profile文件,文末添加
JAVA_HOME=/docker_img/jdk1.8.0_202
PATH=$JAVA_HOME/bin:$PATH
# shell中运行
source /etc/profile
# 制作Dockerfile
# FROM mysql:latest # 指定新镜像所基于的镜像,第一条指令必须为FROM指令,每创建一个镜像就需要一条FROM指令
# MAINTAINER FEI # 说明新镜像的维护人信息
# RUN命令 # 在所基于的镜像上执行命令,并提交到新的镜像中
# CMD[“要运行的程序”,“参数1”,“参数2”] # 指令启动容器时要运行的命令或脚本,Dockerfile只能有一条CMD指令,如果要指定多条则只能最后一条执行
# EXPOSE 端口号 # 指定新镜像加载到Docker时要开启端口
# ENV 环境变量 变量值 #设置一个环境变量的值,会被后面的RUN使用
# ADD 源文件/目录 目标文件/目录 #将源文件复制到目标文件,源文件要与Dockerfile位于相同目录中,或者是一个URL
# COPY 源文件/目录 目标文件/目录 #将本地主机上得文件/目录复制到目标地点,源文件/目录要与Dockerfile在相同的目录中
# VOLUME[“目录”] # 在容器中创建一个挂载点
# USER 用户名/UID # 指定运行容器时的用户
# WORKDIR路径 # 为后续的RUN、CMD、ENTRYPOINT指定工作目录
# ONBUILD命令 # 指定所生成的镜像作为一个基础镜像时所要运行的命令
# HEALTHCHECK # 健康检查
FROM mysql:latest
ENV MYSQL_ROOT_PASSWORD root
COPY ./mycat /usr/local/mycat
USER root
EXPOSE 22 3306
- 配置
conf\schema.xml

<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="DB01" checkSQLschema="true" sqlMaxLimit="100" randomDataNode="dn1">
<!-- auto sharding by id (long) -->
<!--splitTableNames 启用<table name 属性使用逗号分割配置多个表,即多个表使用这个配置-->
<table name="TB_ORDER" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" splitTableNames ="true"/>
<!-- <table name="oc_call" primaryKey="ID" dataNode="dn1$0-743" rule="latest-month-calldate"
/> -->
</schema>
<!-- <dataNode name="dn1$0-743" dataHost="localhost1" database="db$0-743"
/> -->
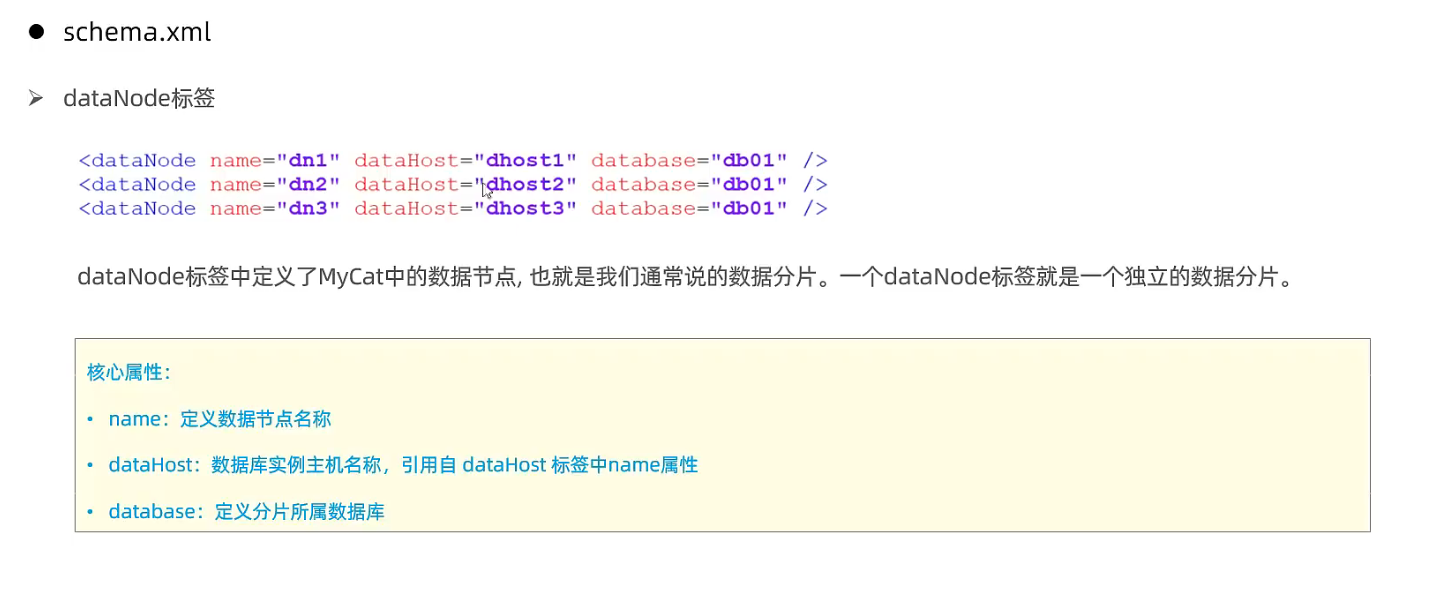
<dataNode name="dn1" dataHost="dhost1" database="db1" />
<dataNode name="dn2" dataHost="dhost2" database="db2" />
<dataNode name="dn3" dataHost="dhost3" database="db3" />
<!--<dataNode name="dn4" dataHost="sequoiadb1" database="SAMPLE" />
<dataNode name="jdbc_dn1" dataHost="jdbchost" database="db1" />
<dataNode name="jdbc_dn2" dataHost="jdbchost" database="db2" />
<dataNode name="jdbc_dn3" dataHost="jdbchost" database="db3" /> -->
<dataHost name="dhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="jdbc:mysql://192.168.56.2:3316?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root"
password="root">
</writeHost>
<!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> -->
</dataHost>
<dataHost name="dhost2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="jdbc:mysql://192.168.56.2:3326?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root"
password="root">
</writeHost>
<!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> -->
</dataHost>
<dataHost name="dhost3" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="jdbc:mysql://192.168.56.2:3336?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root"
password="root">
</writeHost>
<!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> -->
</dataHost>
<!--
<dataHost name="sequoiadb1" maxCon="1000" minCon="1" balance="0" dbType="sequoiadb" dbDriver="jdbc">
<heartbeat> </heartbeat>
<writeHost host="hostM1" url="sequoiadb://1426587161.dbaas.sequoialab.net:11920/SAMPLE" user="jifeng" password="jifeng"></writeHost>
</dataHost>
<dataHost name="oracle1" maxCon="1000" minCon="1" balance="0" writeType="0" dbType="oracle" dbDriver="jdbc"> <heartbeat>select 1 from dual</heartbeat>
<connectionInitSql>alter session set nls_date_format='yyyy-mm-dd hh24:mi:ss'</connectionInitSql>
<writeHost host="hostM1" url="jdbc:oracle:thin:@127.0.0.1:1521:nange" user="base" password="123456" > </writeHost> </dataHost>
<dataHost name="jdbchost" maxCon="1000" minCon="1" balance="0" writeType="0" dbType="mongodb" dbDriver="jdbc">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM" url="mongodb://192.168.0.99/test" user="admin" password="123456" ></writeHost> </dataHost>
<dataHost name="sparksql" maxCon="1000" minCon="1" balance="0" dbType="spark" dbDriver="jdbc">
<heartbeat> </heartbeat>
<writeHost host="hostM1" url="jdbc:hive2://feng01:10000" user="jifeng" password="jifeng"></writeHost> </dataHost> -->
<!-- <dataHost name="jdbchost" maxCon="1000" minCon="10" balance="0" dbType="mysql"
dbDriver="jdbc"> <heartbeat>select user()</heartbeat> <writeHost host="hostM1"
url="jdbc:mysql://localhost:3306" user="root" password="123456"> </writeHost>
</dataHost> -->
</mycat:schema>
- 配置
conf\server.xml

<?xml version="1.0" encoding="UTF-8"?>
<!-- - - Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License. - You
may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0
- - Unless required by applicable law or agreed to in writing, software -
distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the
License for the specific language governing permissions and - limitations
under the License. -->
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<system>
<property name="nonePasswordLogin">0</property> <!-- 0为需要密码登陆、1为不需要密码登陆 ,默认为0,设置为1则需要指定默认账户-->
<property name="ignoreUnknownCommand">0</property><!-- 0遇上没有实现的报文(Unknown command:),就会报错、1为忽略该报文,返回ok报文。
在某些mysql客户端存在客户端已经登录的时候还会继续发送登录报文,mycat会报错,该设置可以绕过这个错误-->
<property name="useHandshakeV10">1</property>
<property name="removeGraveAccent">1</property>
<property name="useSqlStat">0</property> <!-- 1为开启实时统计、0为关闭 -->
<property name="useGlobleTableCheck">0</property> <!-- 1为开启全加班一致性检测、0为关闭 -->
<property name="sqlExecuteTimeout">300</property> <!-- SQL 执行超时 单位:秒-->
<property name="sequnceHandlerType">1</property>
<!--<property name="sequnceHandlerPattern">(?:(\s*next\s+value\s+for\s*MYCATSEQ_(\w+))(,|\)|\s)*)+</property>
INSERT INTO `travelrecord` (`id`,user_id) VALUES ('next value for MYCATSEQ_GLOBAL',"xxx");
-->
<!--必须带有MYCATSEQ_或者 mycatseq_进入序列匹配流程 注意MYCATSEQ_有空格的情况-->
<property name="sequnceHandlerPattern">(?:(\s*next\s+value\s+for\s*MYCATSEQ_(\w+))(,|\)|\s)*)+</property>
<property name="subqueryRelationshipCheck">false</property> <!-- 子查询中存在关联查询的情况下,检查关联字段中是否有分片字段 .默认 false -->
<property name="sequenceHanlderClass">io.mycat.route.sequence.handler.HttpIncrSequenceHandler</property>
<!-- <property name="useCompression">1</property>--> <!--1为开启mysql压缩协议-->
<!-- <property name="fakeMySQLVersion">5.6.20</property>--> <!--设置模拟的MySQL版本号-->
<!-- <property name="processorBufferChunk">40960</property> -->
<!--
<property name="processors">1</property>
<property name="processorExecutor">32</property>
-->
<!--默认为type 0: DirectByteBufferPool | type 1 ByteBufferArena | type 2 NettyBufferPool -->
<property name="processorBufferPoolType">0</property>
<!--默认是65535 64K 用于sql解析时最大文本长度 -->
<!--<property name="maxStringLiteralLength">65535</property>-->
<!--<property name="sequnceHandlerType">0</property>-->
<!--<property name="backSocketNoDelay">1</property>-->
<!--<property name="frontSocketNoDelay">1</property>-->
<!--<property name="processorExecutor">16</property>-->
<!--
<property name="serverPort">8066</property> <property name="managerPort">9066</property>
<property name="idleTimeout">300000</property> <property name="bindIp">0.0.0.0</property>
<property name="dataNodeIdleCheckPeriod">300000</property> 5 * 60 * 1000L; //连接空闲检查
<property name="frontWriteQueueSize">4096</property> <property name="processors">32</property> -->
<!--分布式事务开关,0为不过滤分布式事务,1为过滤分布式事务(如果分布式事务内只涉及全局表,则不过滤),2为不过滤分布式事务,但是记录分布式事务日志-->
<property name="handleDistributedTransactions">0</property>
<!--
off heap for merge/order/group/limit 1开启 0关闭
-->
<property name="useOffHeapForMerge">0</property>
<!--
单位为m
-->
<property name="memoryPageSize">64k</property>
<!--
单位为k
-->
<property name="spillsFileBufferSize">1k</property>
<property name="useStreamOutput">0</property>
<!--
单位为m
-->
<property name="systemReserveMemorySize">384m</property>
<!--是否采用zookeeper协调切换 -->
<property name="useZKSwitch">false</property>
<!-- XA Recovery Log日志路径 -->
<!--<property name="XARecoveryLogBaseDir">./</property>-->
<!-- XA Recovery Log日志名称 -->
<!--<property name="XARecoveryLogBaseName">tmlog</property>-->
<!--如果为 true的话 严格遵守隔离级别,不会在仅仅只有select语句的时候在事务中切换连接-->
<property name="strictTxIsolation">false</property>
<property name="useZKSwitch">true</property>
<!--如果为0的话,涉及多个DataNode的catlet任务不会跨线程执行-->
<property name="parallExecute">0</property>
</system>
<!-- 全局SQL防火墙设置 -->
<!--白名单可以使用通配符%或着*-->
<!--例如<host host="127.0.0.*" user="root"/>-->
<!--例如<host host="127.0.*" user="root"/>-->
<!--例如<host host="127.*" user="root"/>-->
<!--例如<host host="1*7.*" user="root"/>-->
<!--这些配置情况下对于127.0.0.1都能以root账户登录-->
<!--
<firewall>
<whitehost>
<host host="1*7.0.0.*" user="root"/>
</whitehost>
<blacklist check="false">
</blacklist>
</firewall>
-->
<user name="root" defaultAccount="true">
<property name="password">mycat</property>
<property name="schemas">TESTDB</property>
<property name="defaultSchema">DB01</property>
<!--No MyCAT Database selected 错误前会尝试使用该schema作为schema,不设置则为null,报错 -->
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>
<user name="user">
<property name="password">user</property>
<property name="schemas">DB01</property>
<property name="readOnly">true</property>
<property name="defaultSchema">TESTDB</property>
</user>
</mycat:server>
# dhost1 3316
docker run -p 3316:3306 --network mysql_net --name dhost1 \
--restart=always \
-v /docker_img/dhost1/log:/var/log/mysql \
-v /docker_img/dhost1/data:/var/lib/mysql \
-v /docker_img/dhost1/conf:/etc/mysql/conf.d \
-e MYSQL_ROOT_PASSWORD=root \
-d mysql:latest
# dhost2 3326
docker run -p 3326:3306 --network mysql_net --name dhost2 \
--restart=always \
-v /docker_img/dhost2/log:/var/log/mysql \
-v /docker_img/dhost2/data:/var/lib/mysql \
-v /docker_img/dhost2/conf:/etc/mysql/conf.d \
-e MYSQL_ROOT_PASSWORD=root \
-d mysql:latest
# dhost3 3336
docker run -p 3336:3306 --network mysql_net --name dhost3 \
--restart=always \
-v /docker_img/dhost3/log:/var/log/mysql \
-v /docker_img/dhost3/data:/var/lib/mysql \
-v /docker_img/dhost3/conf:/etc/mysql/conf.d \
-e MYSQL_ROOT_PASSWORD=root \
-d mysql:latest
docker update dhost1 dhost2 dhost3 --restart=always # 默认no
- Mycat 启动
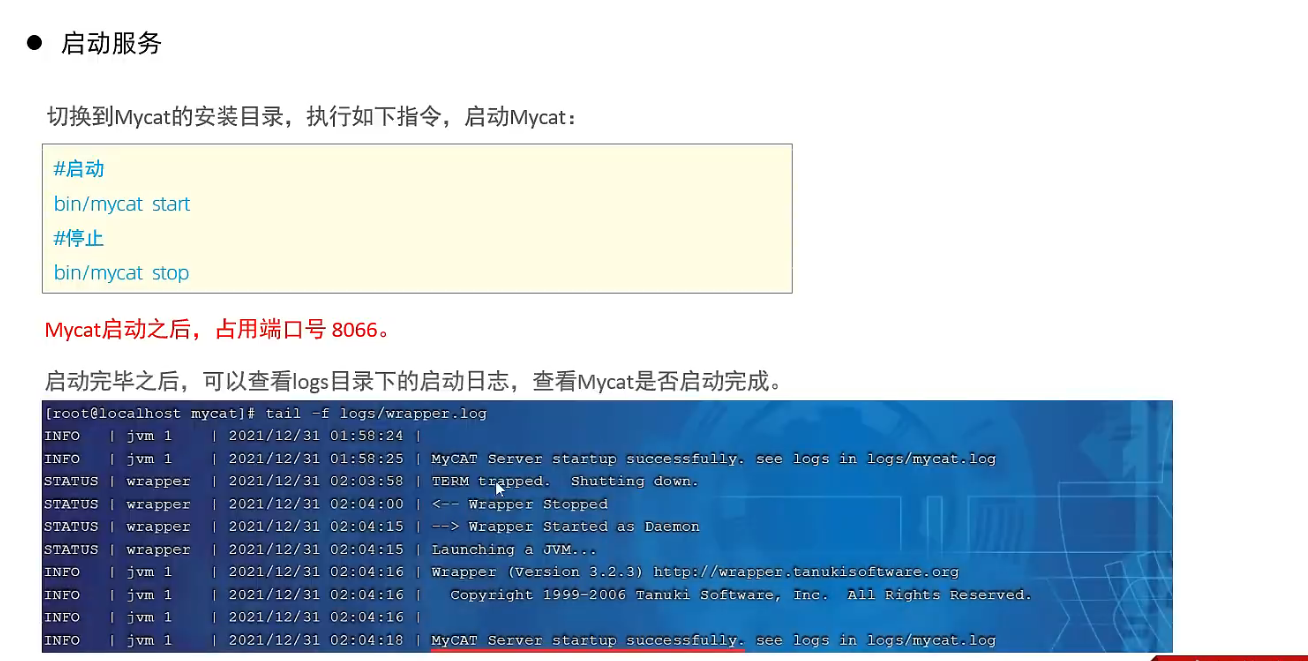
# 启动
bin/mycat start
# 停止
bin/mycat stop
# 查看日志
# cd /local/user/mycat
tail -f logs/wrapper.log
- 登录mycat
mysql -h 192.168.56.2 -P 8066 -uroot -p mycat
- mycat中创建数据表
USE DB01;
show tables;
create table TB_ORDER(
id int not null auto increment primary key,
name varchar(255));
USE DB01;
show tables;
create table TB_ORDER2(
id int not null auto increment primary key,
name varchar(255));
3.4 Mycat配置
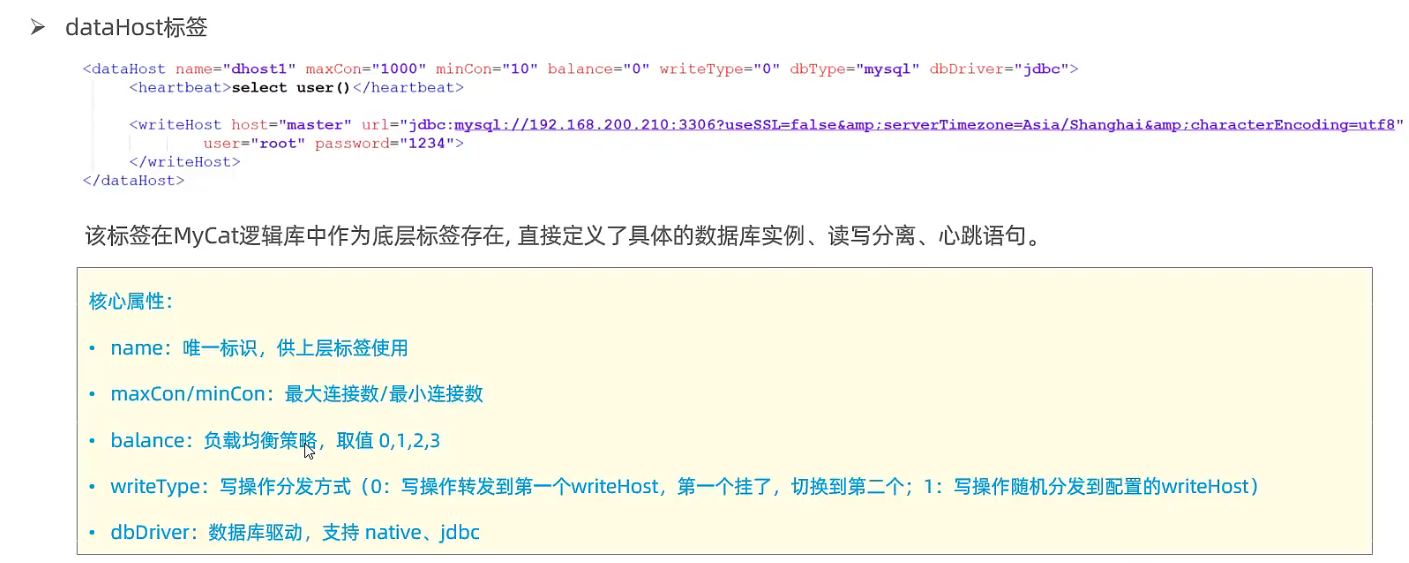
schema.xml



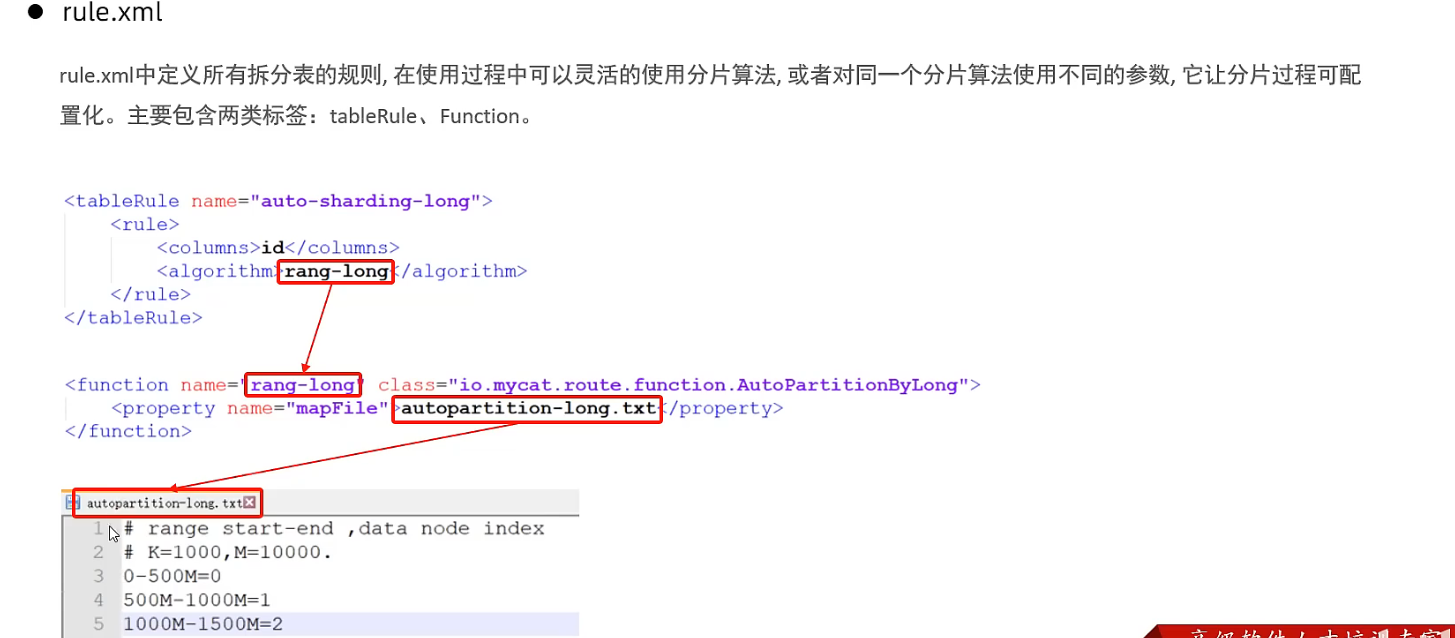
rule.xml
server.xml


- IUSD 增改查删权限
0000 # 增改查删权限都没有
1000 # 增
0100 # 改
0010 # 查
0001 # 删
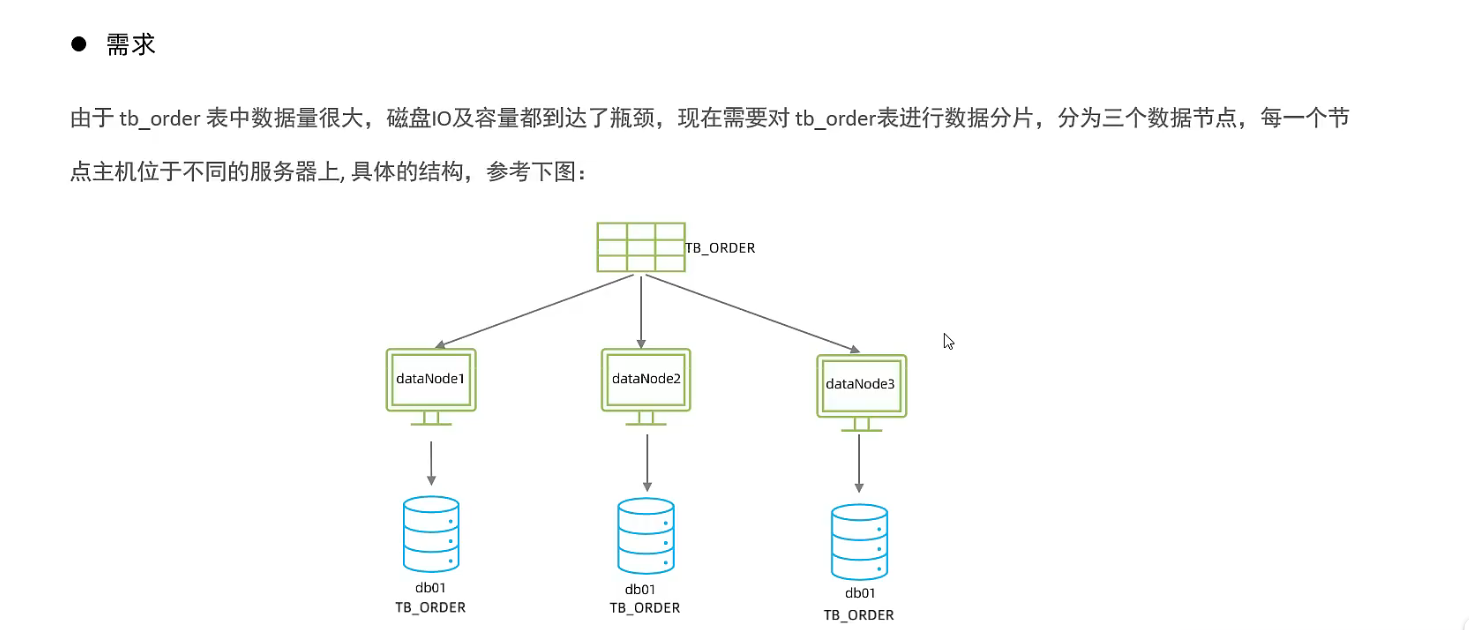
3.5 Mycat分片
垂直拆分 - 垂直分库
- 垂直分库
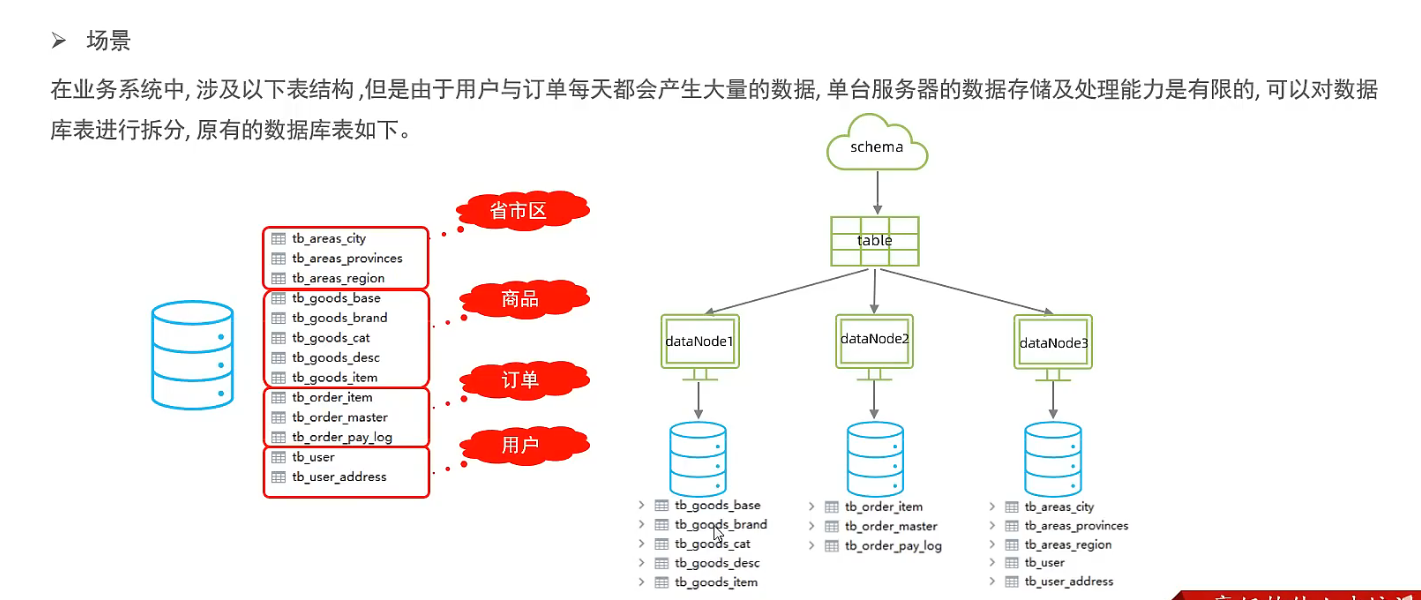
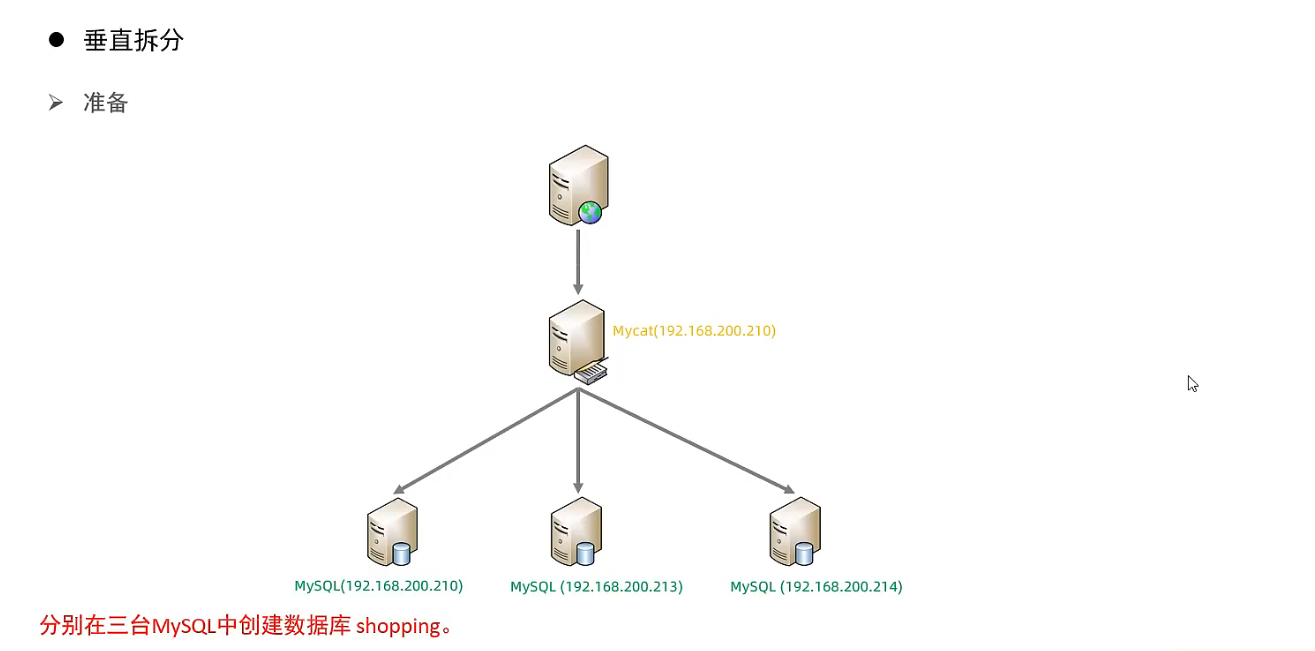
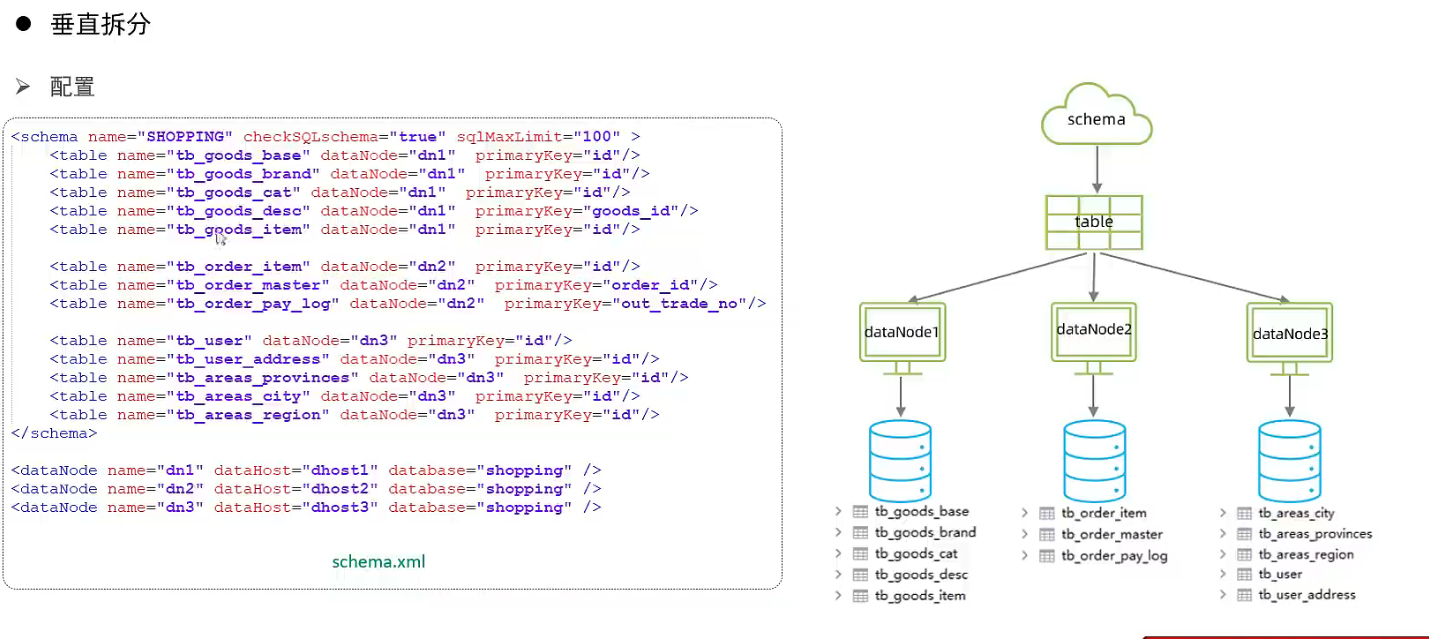
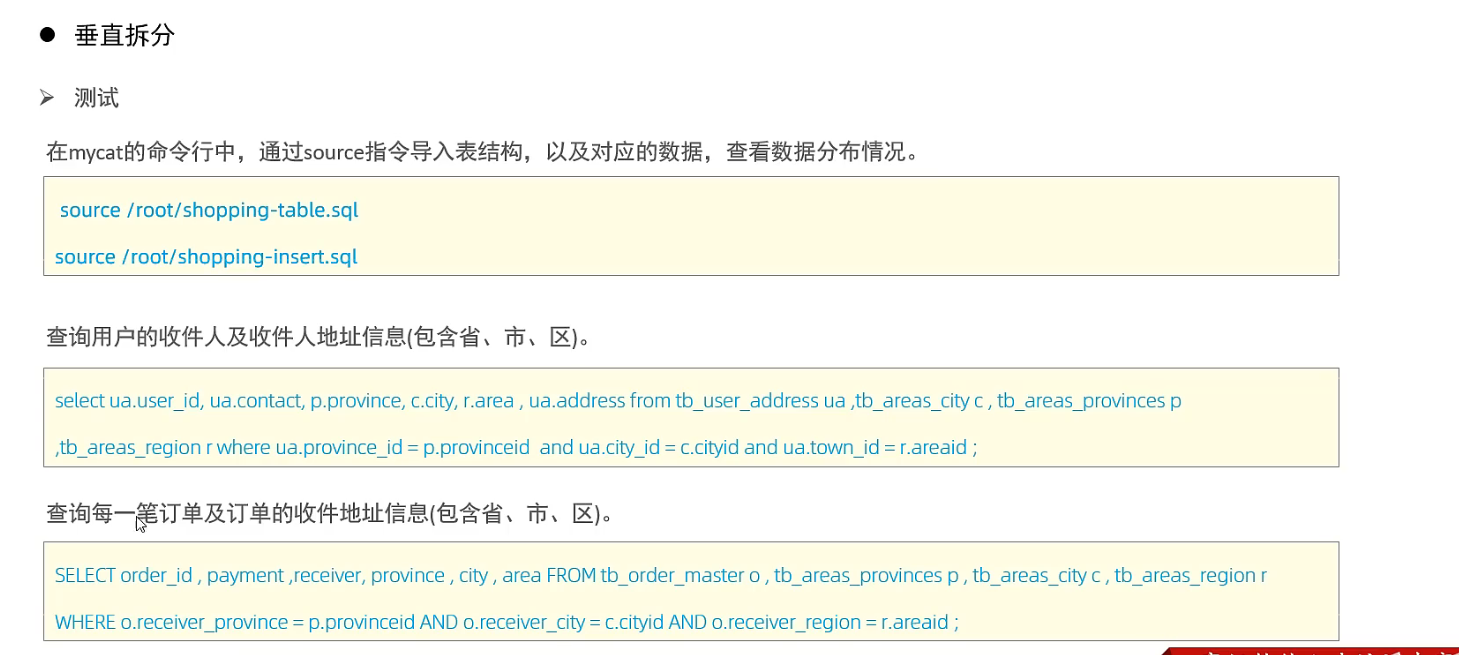
对于联表查询, 如果这些表在同一个数据库分片中, 可以执行成功, 否则执行失败. 失败需要重新配置全局表

水平拆分 - 水平分表
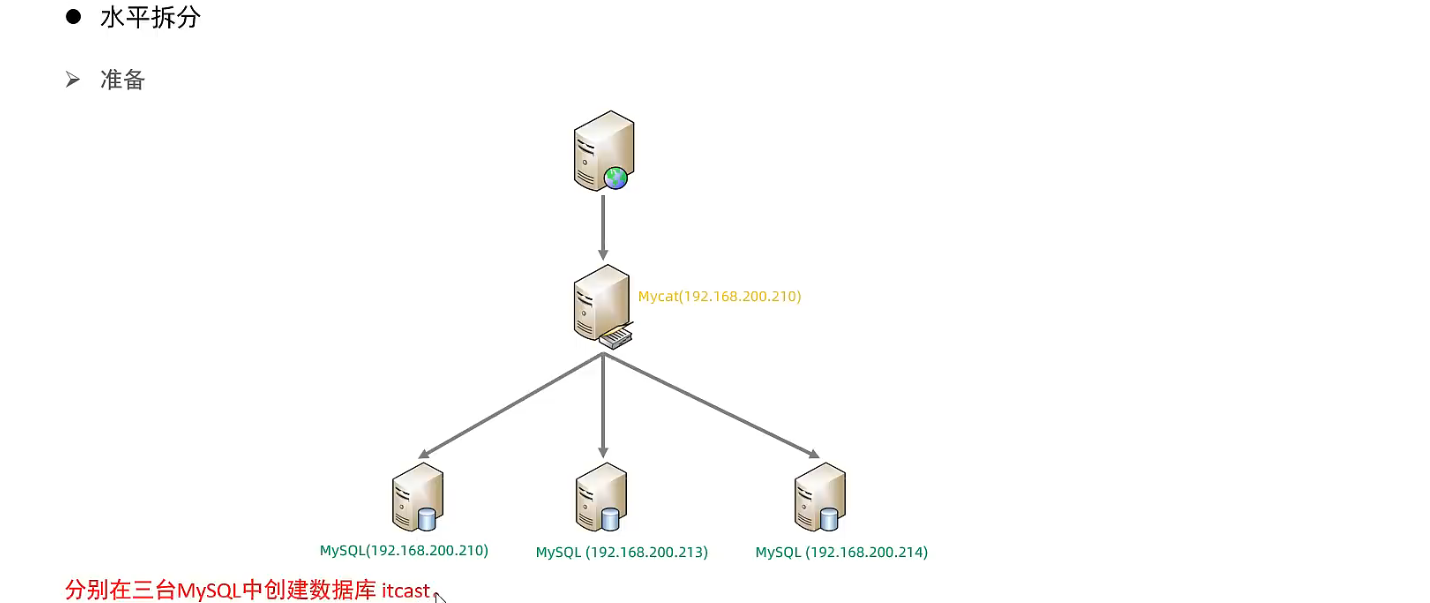
同入门案例
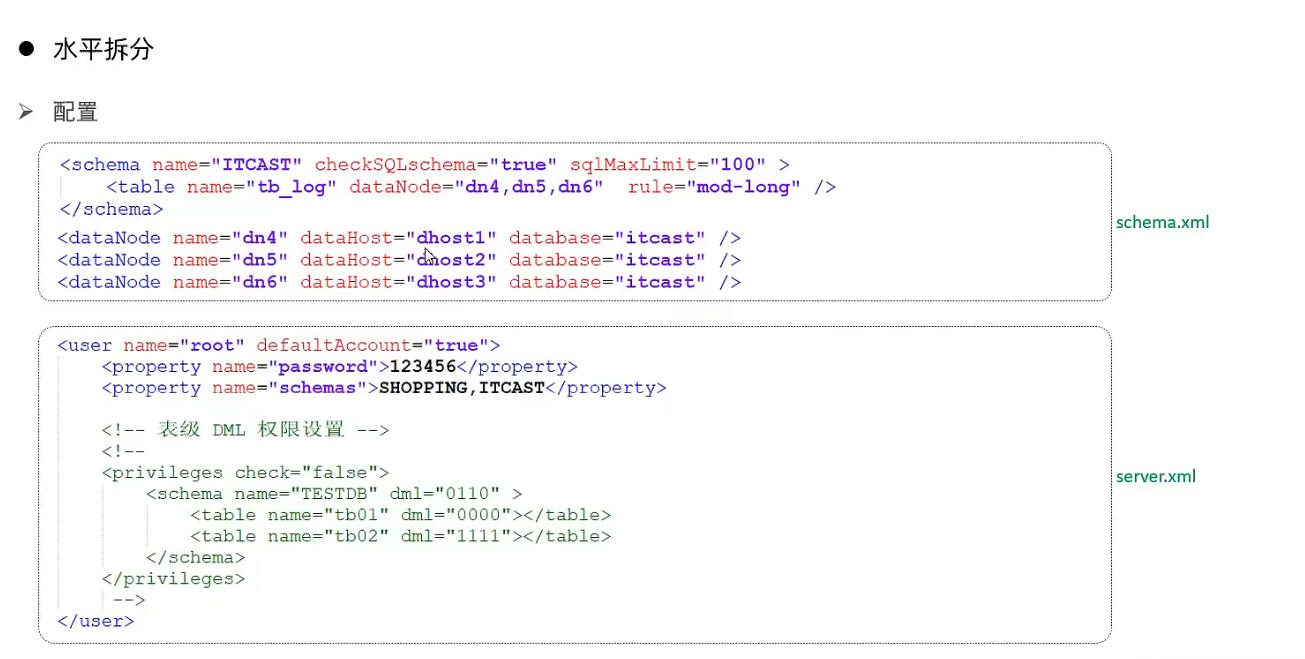
分片规则
- 范围分片
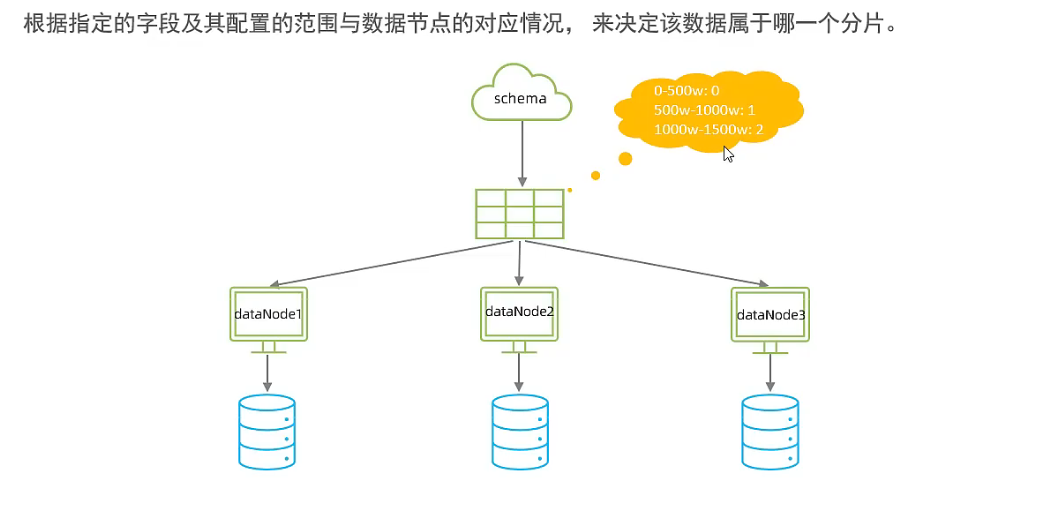
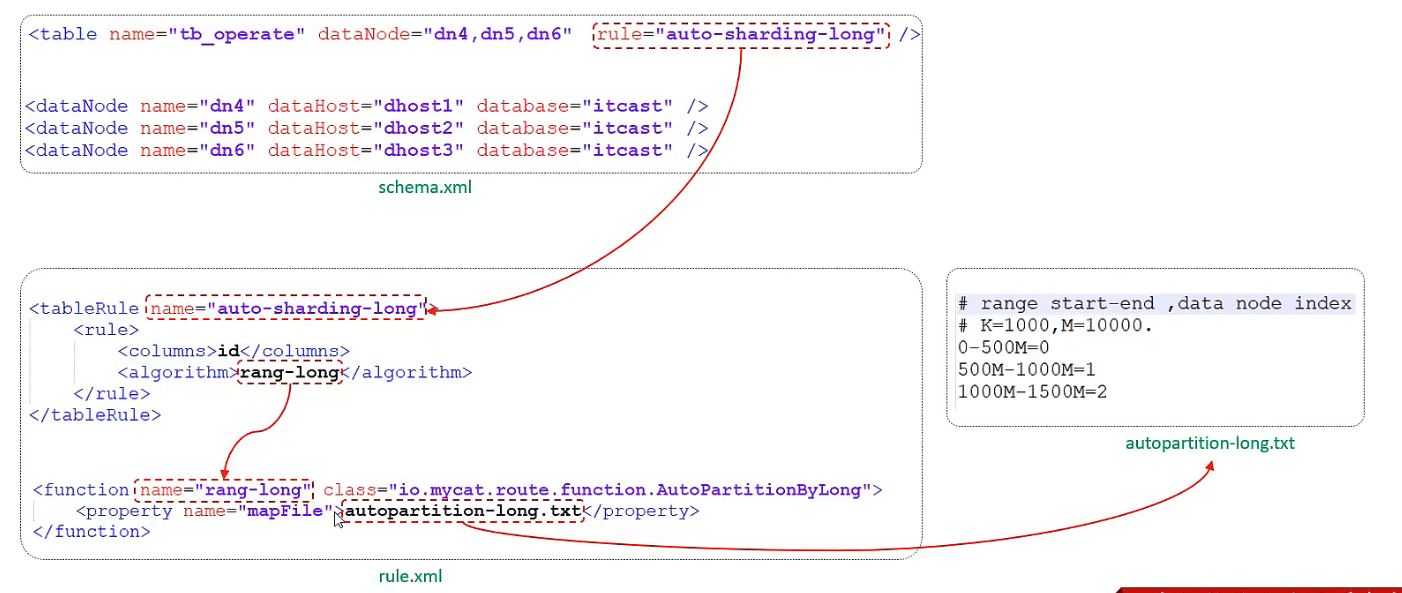
- 取模分片
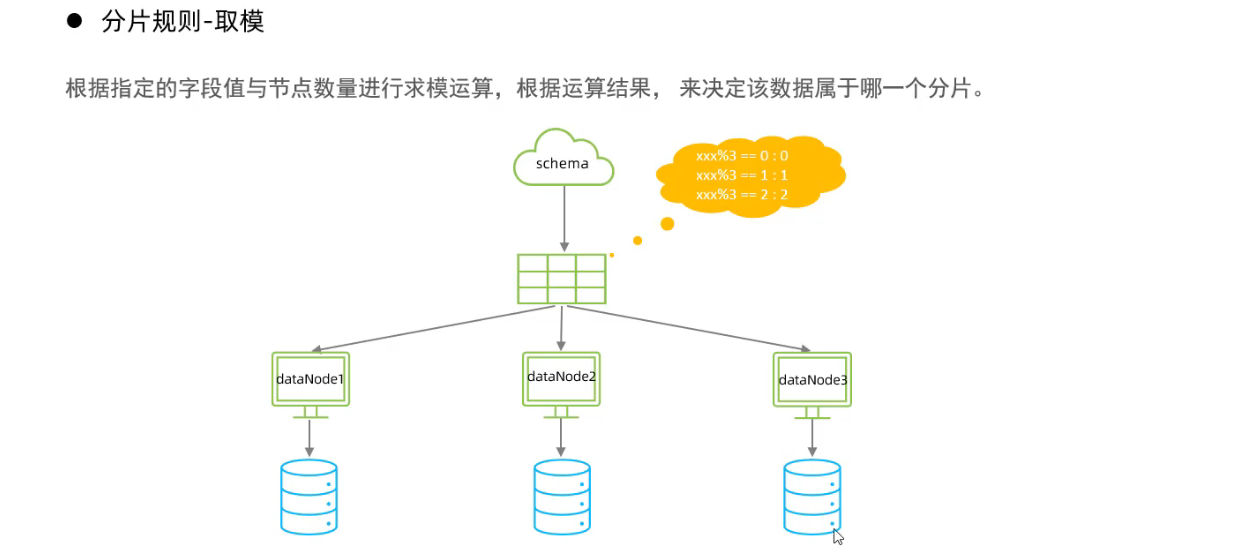
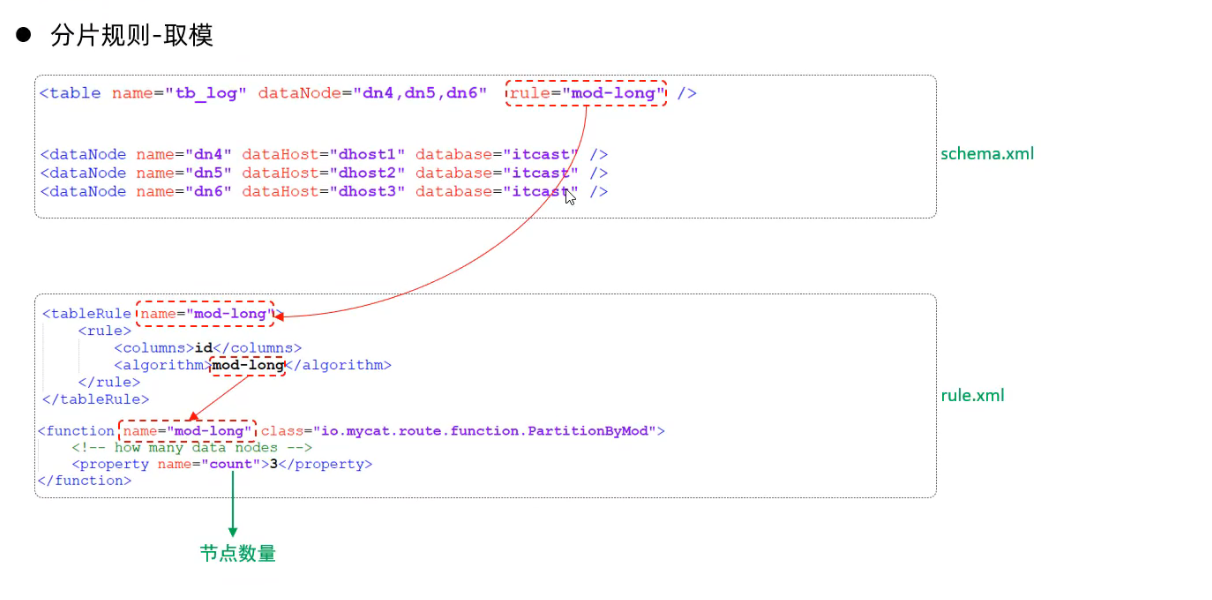
哈希分片
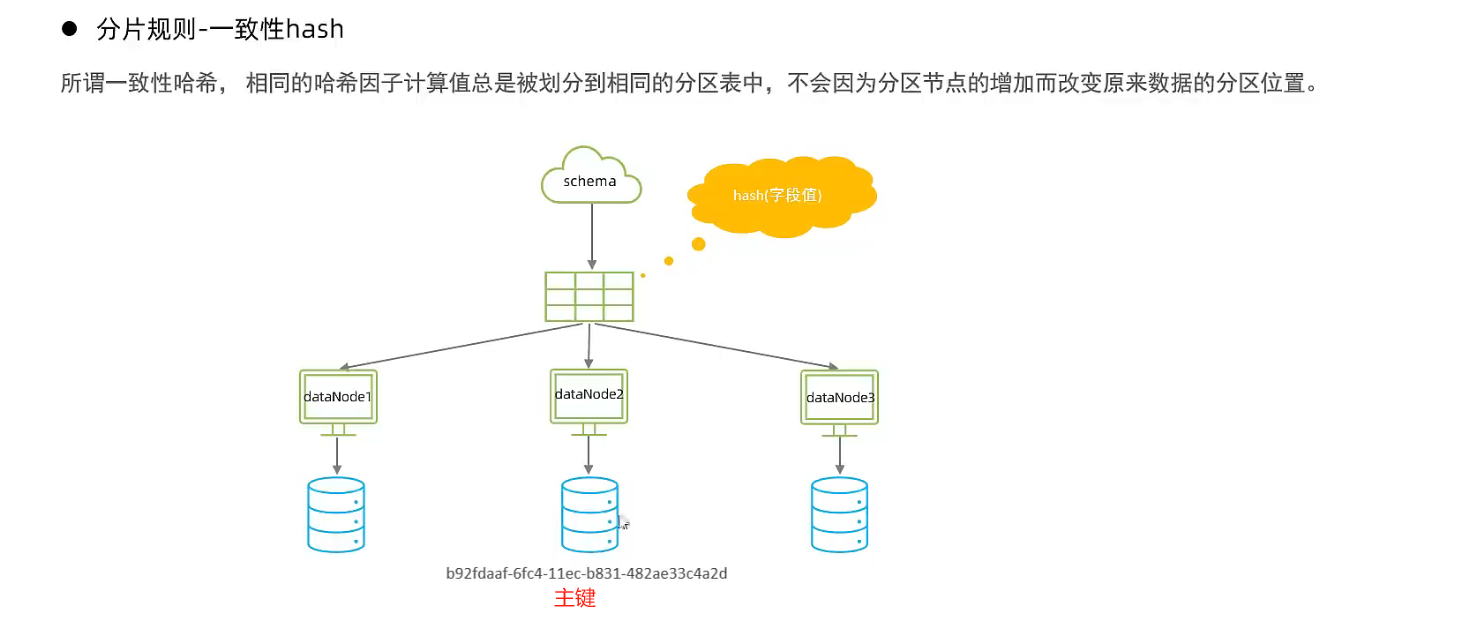

- 枚举分片
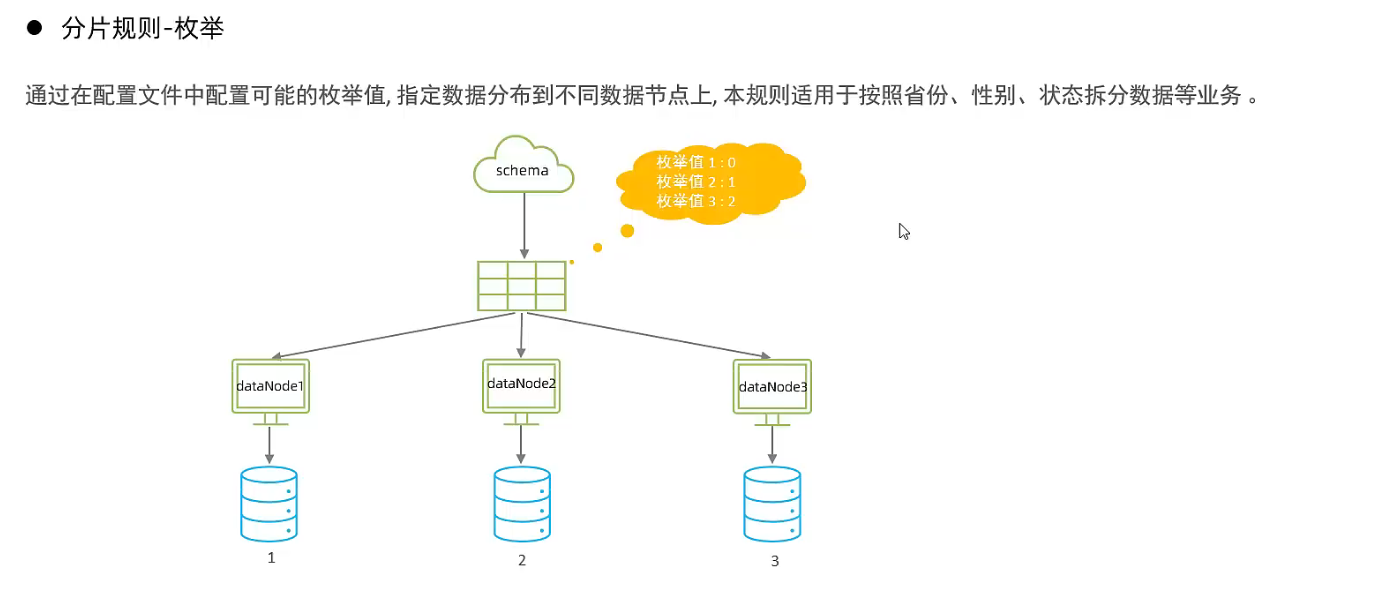

- 应用指定分片算法
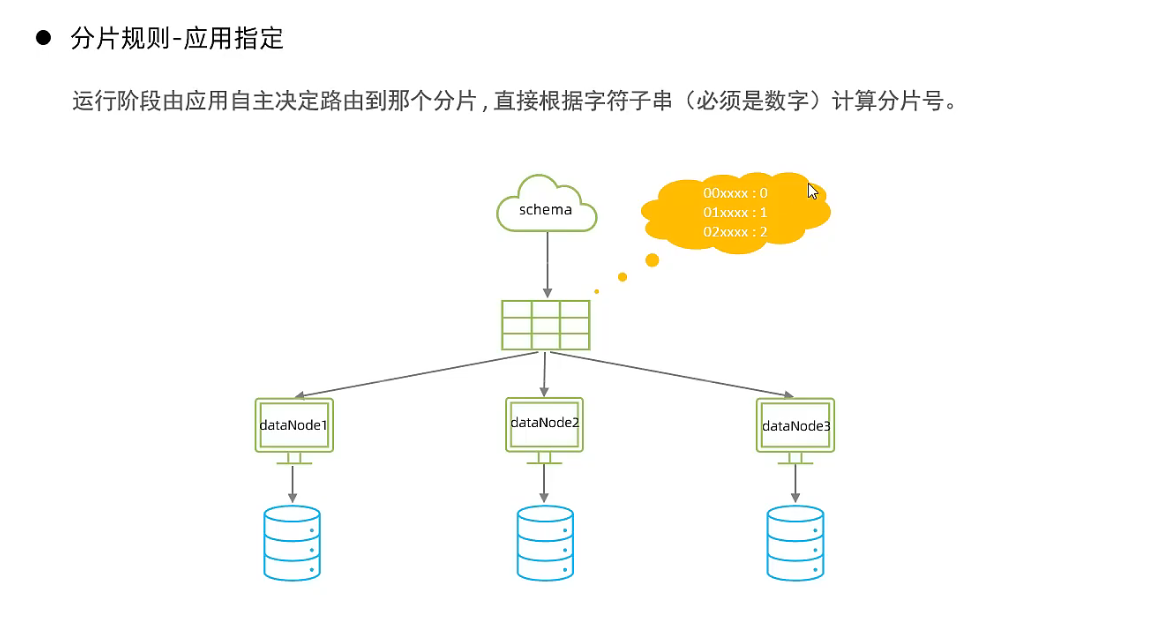

- 固定分片hash算法
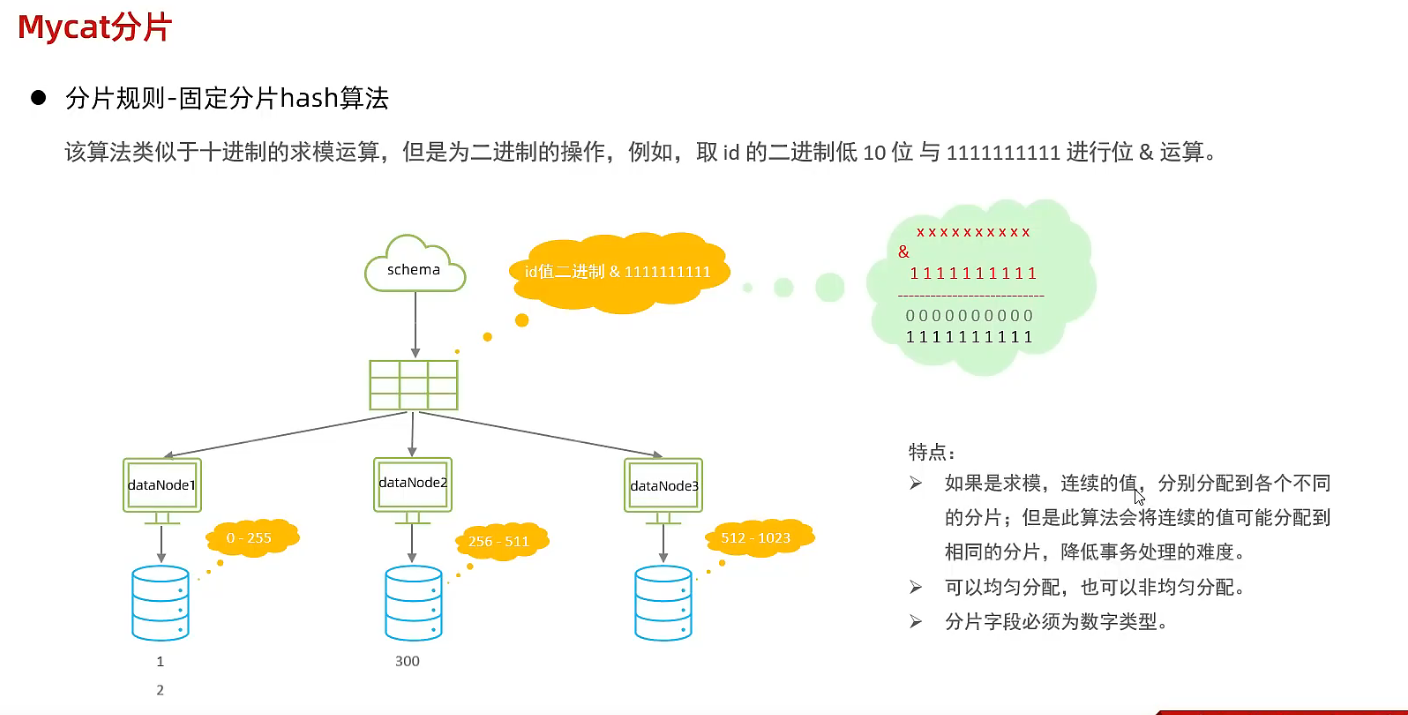
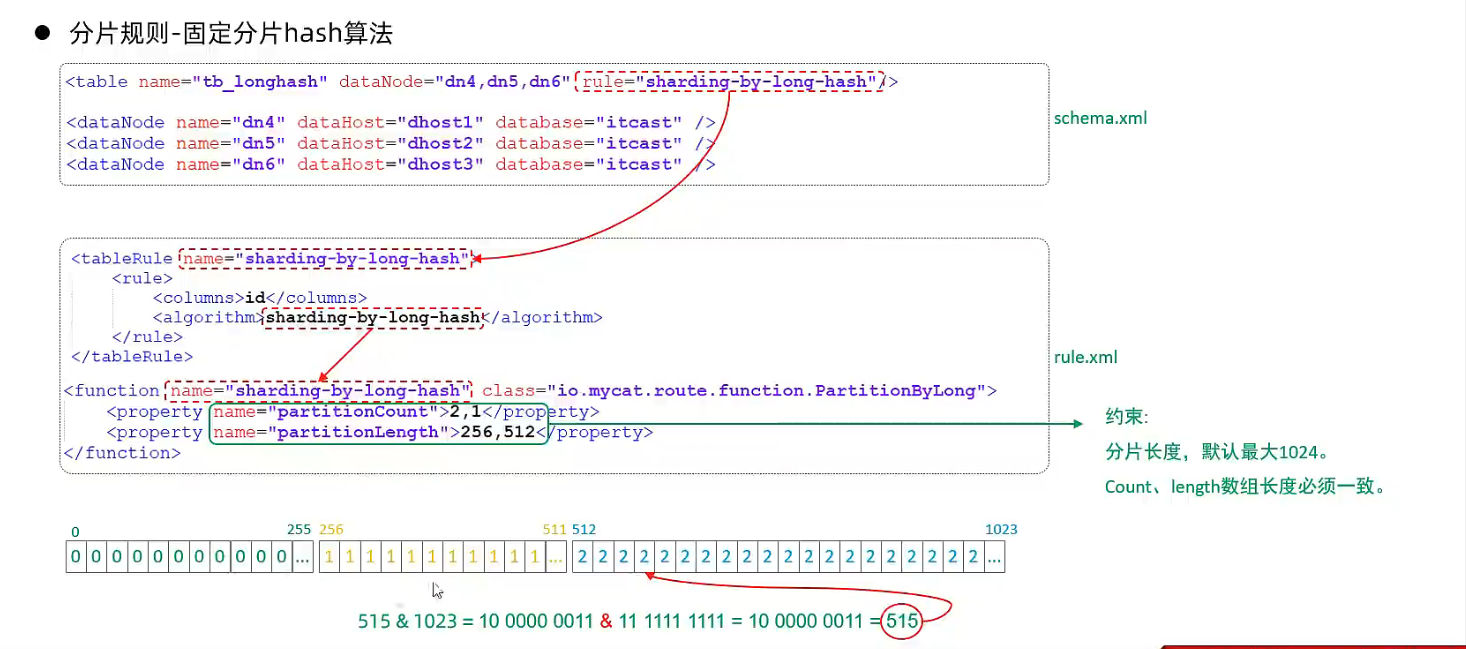
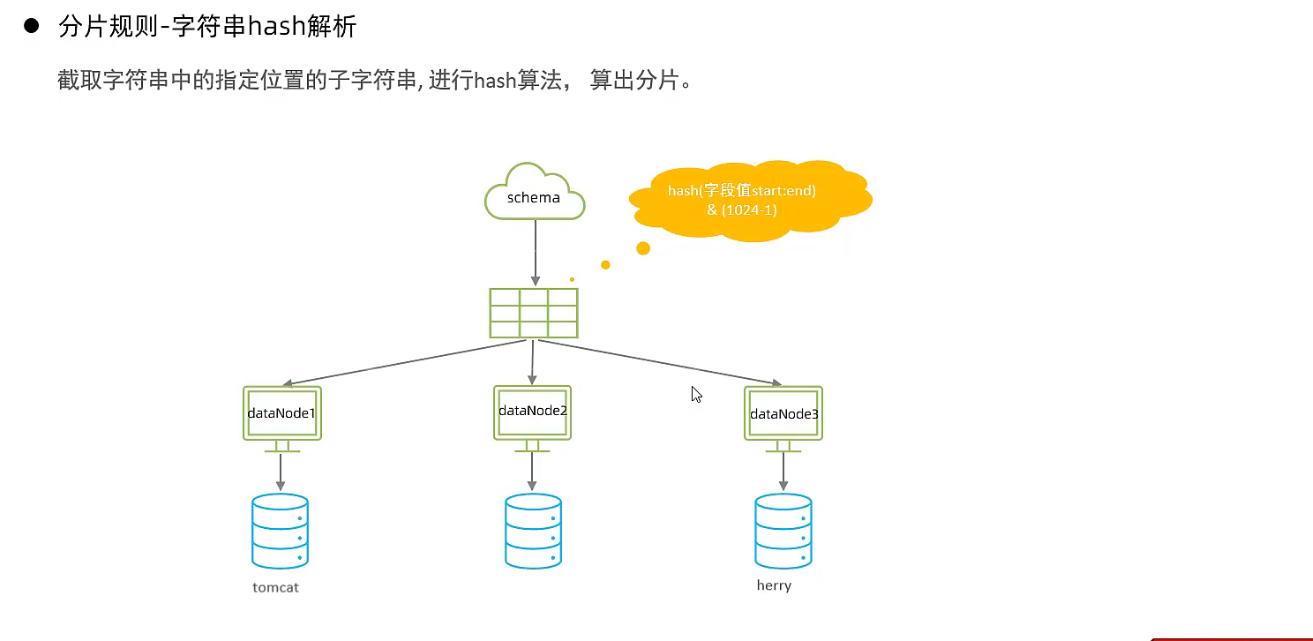
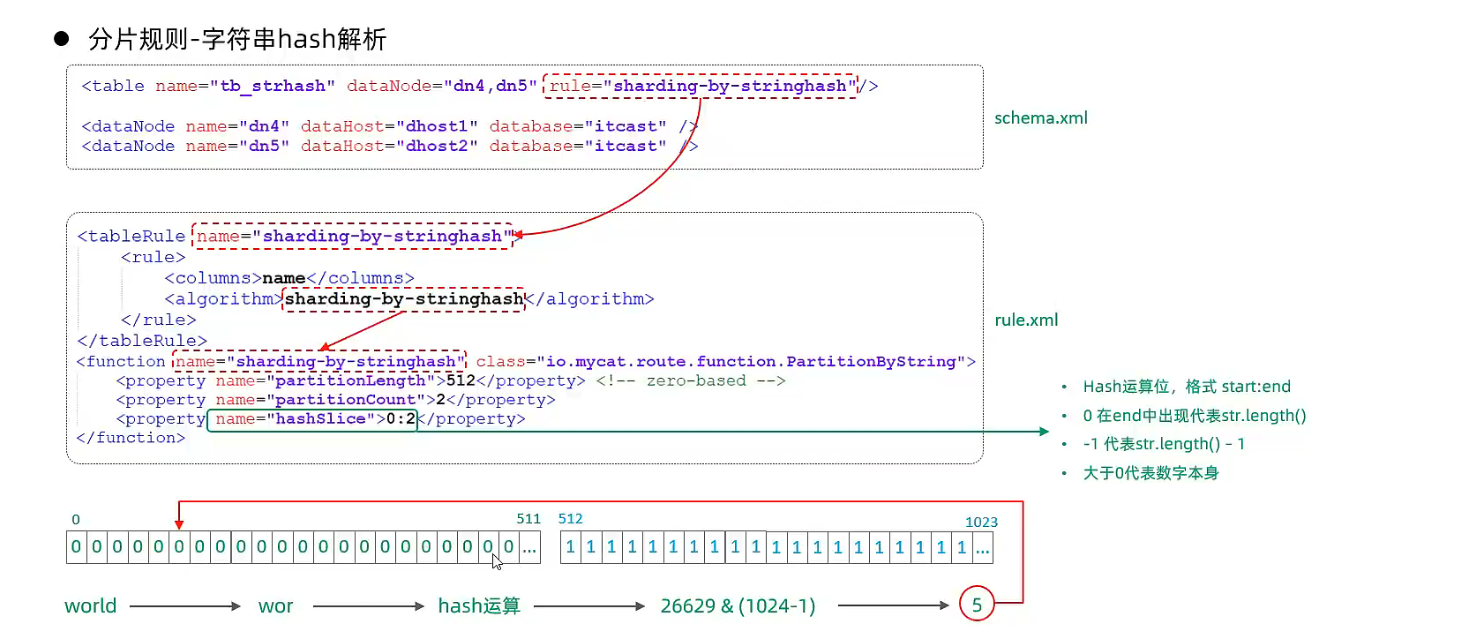
- 字符串hash解析
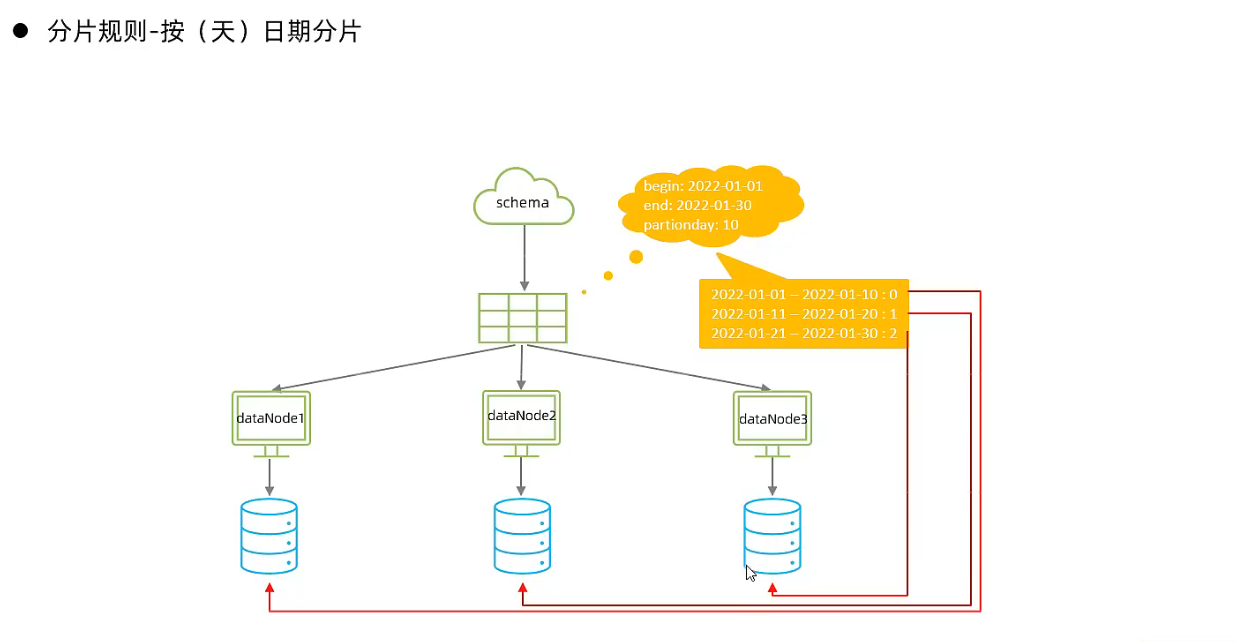
- 按日期分片

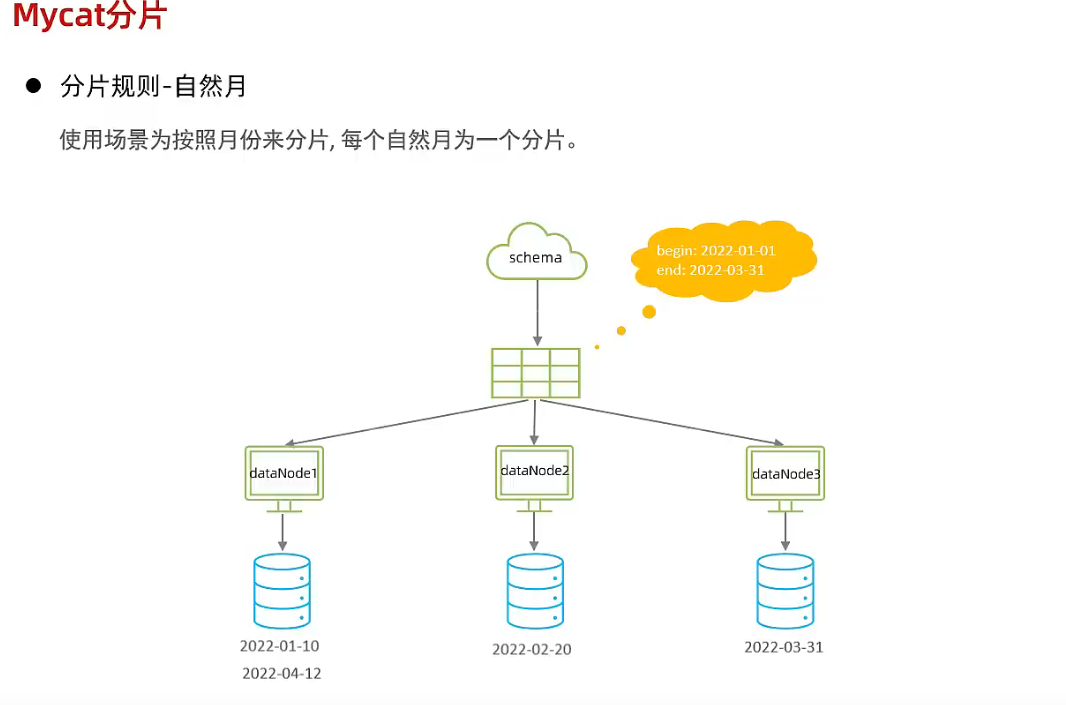

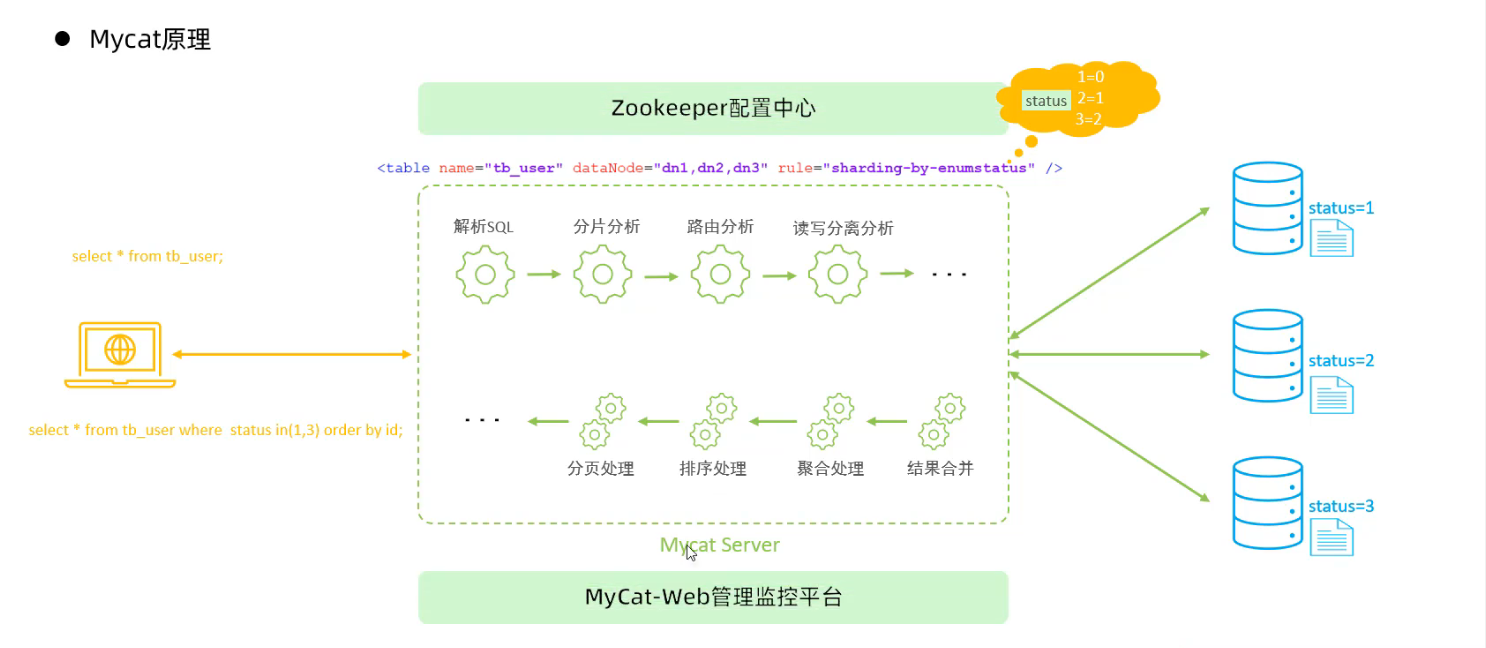
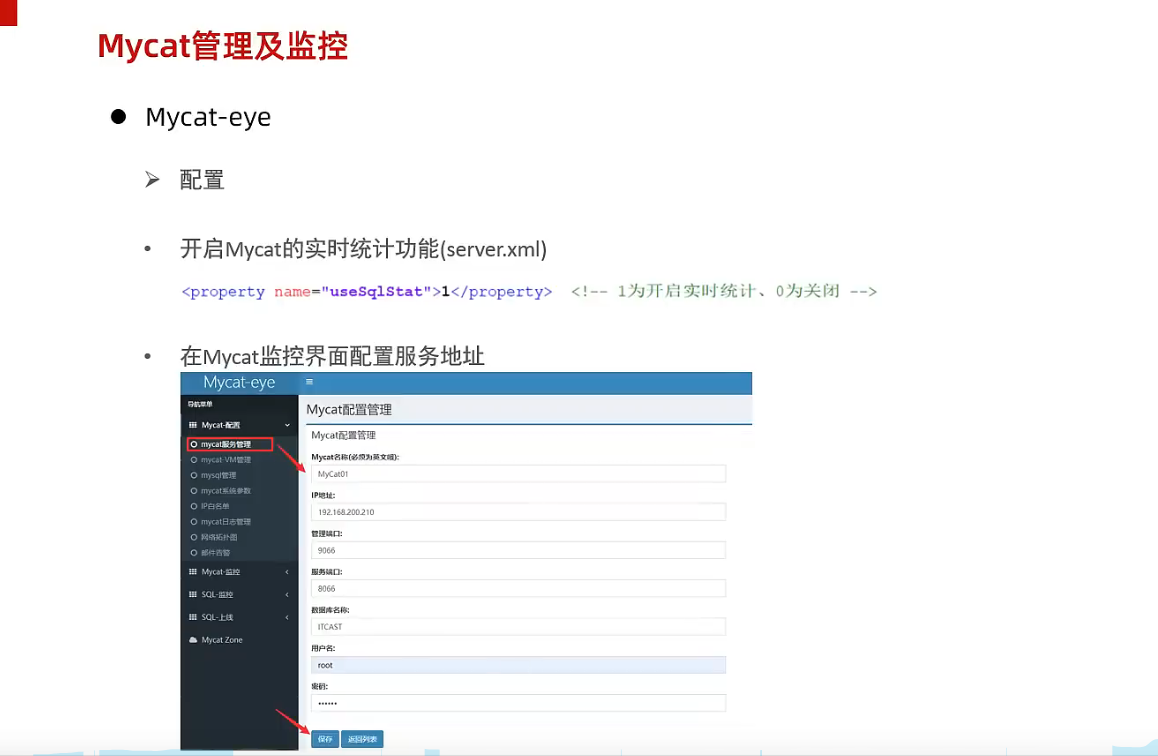
3.6 Mycat管理及监控




4. 读写分离
4.1 介绍
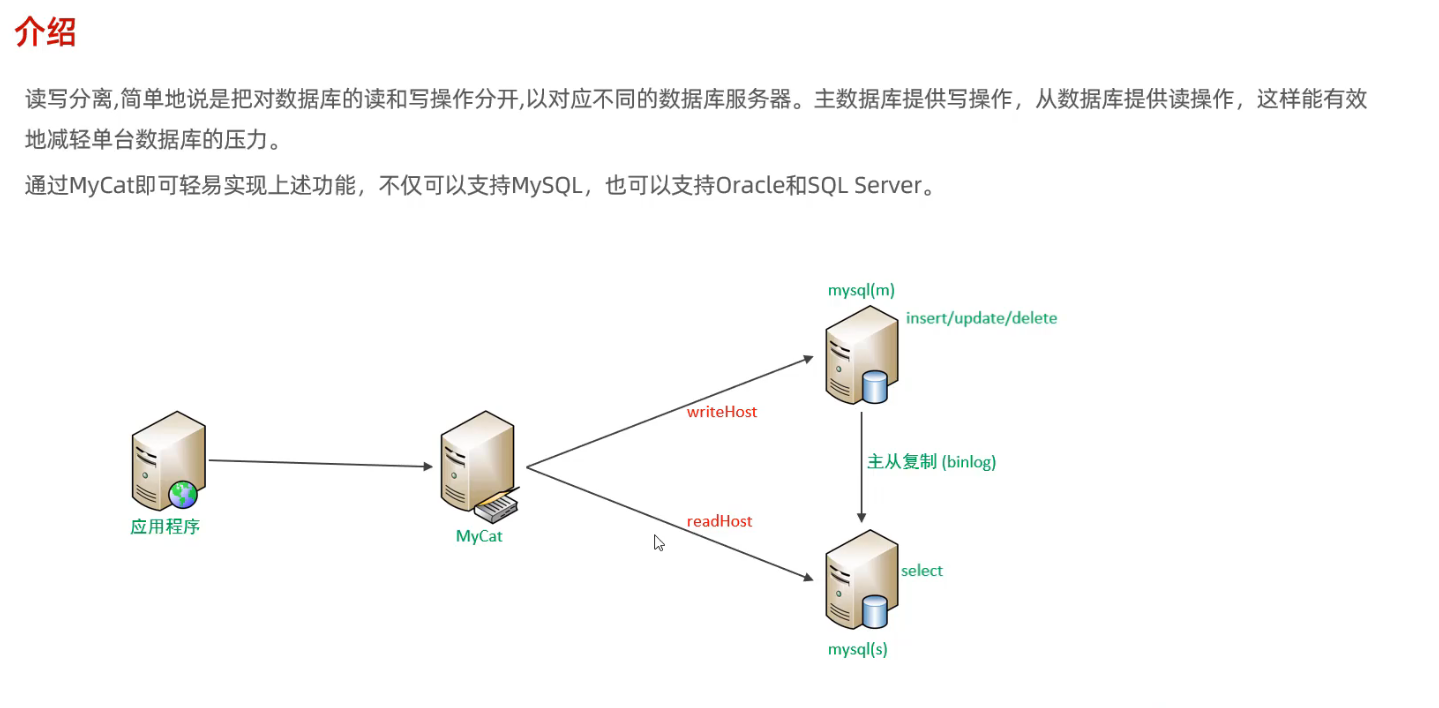
4.2 一主一从


4.3 双主双从
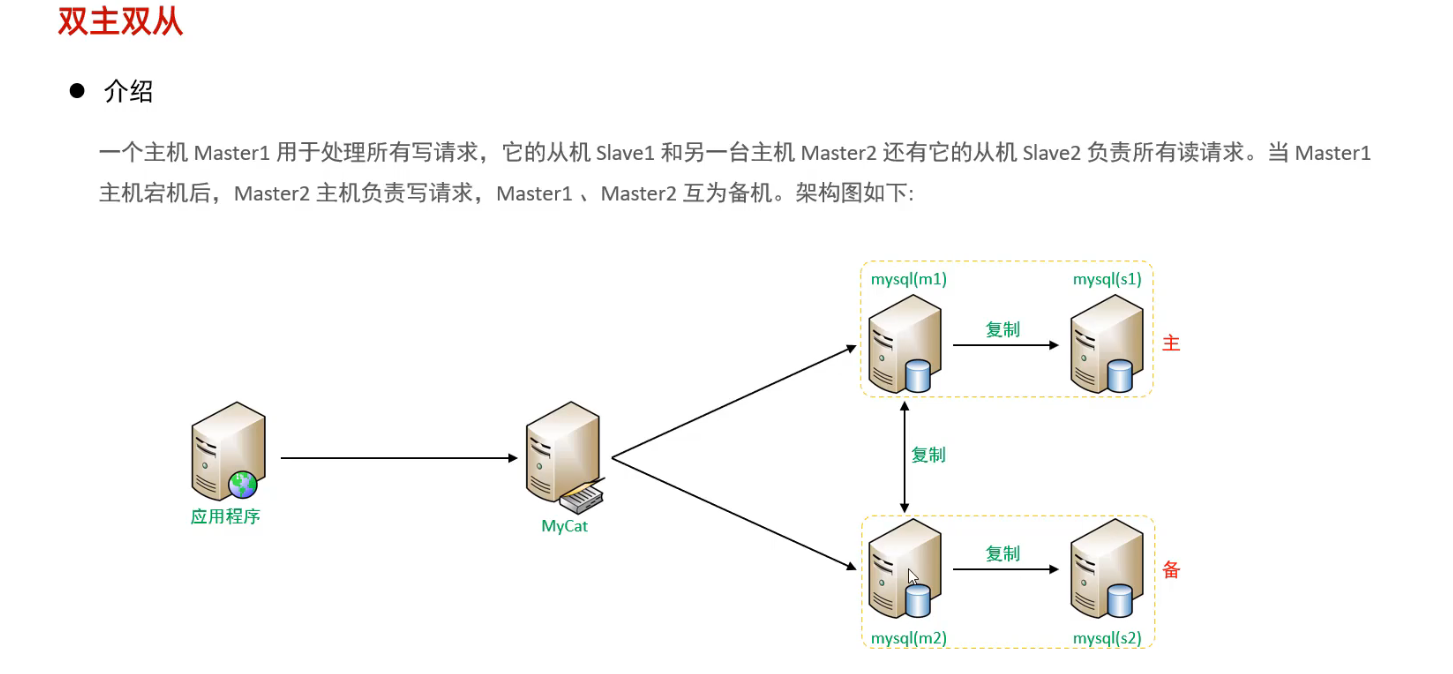
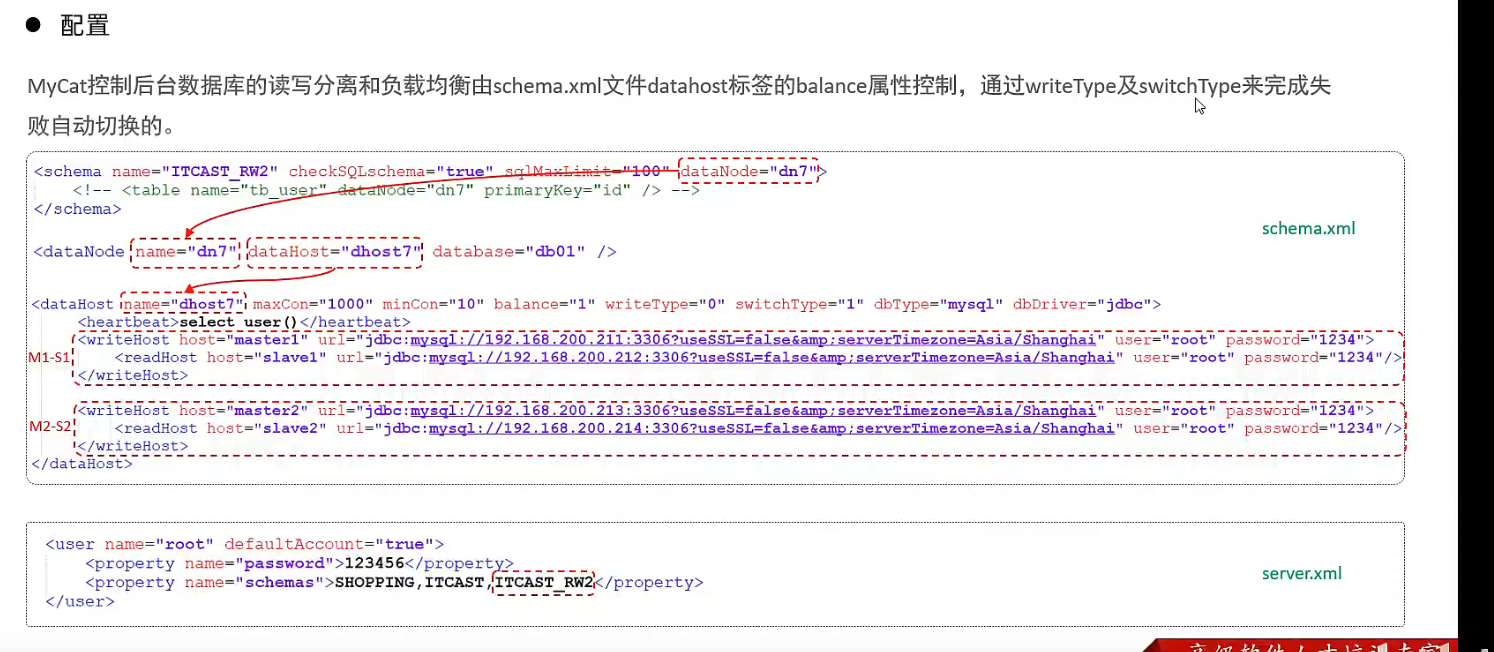
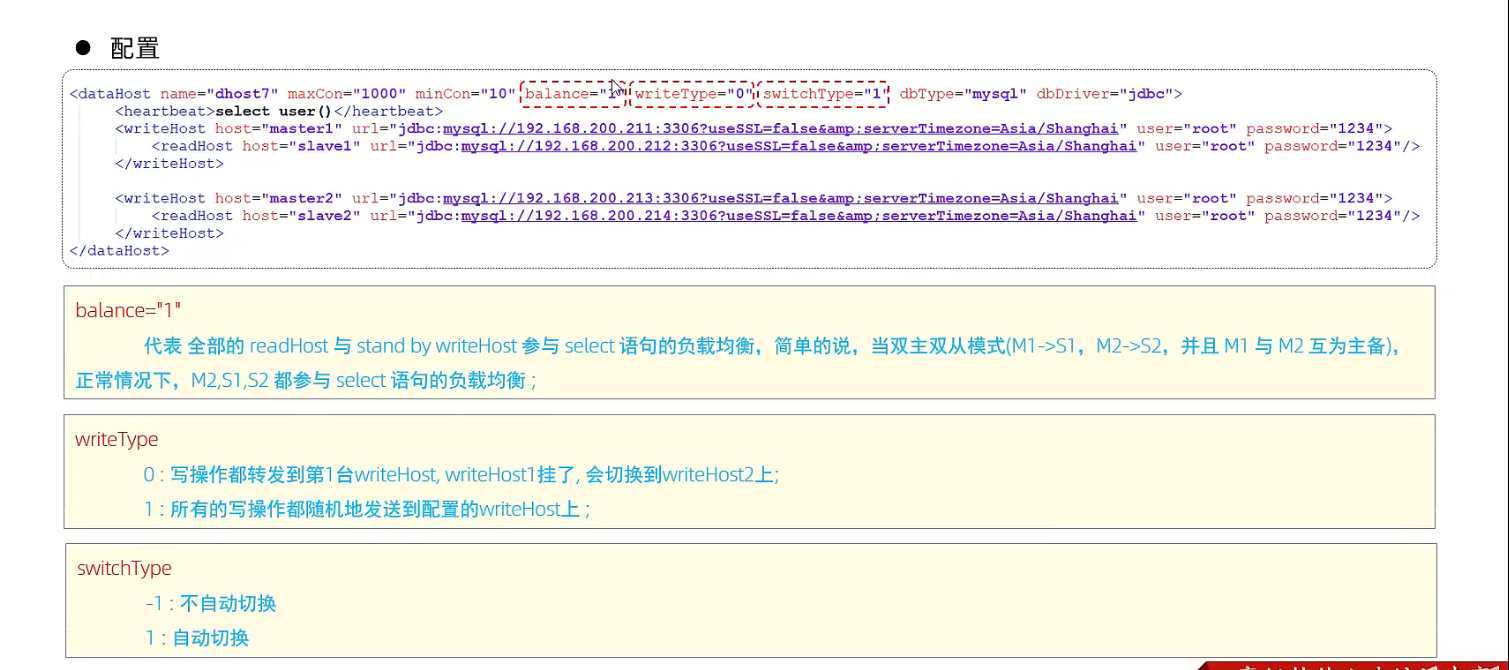
案例:
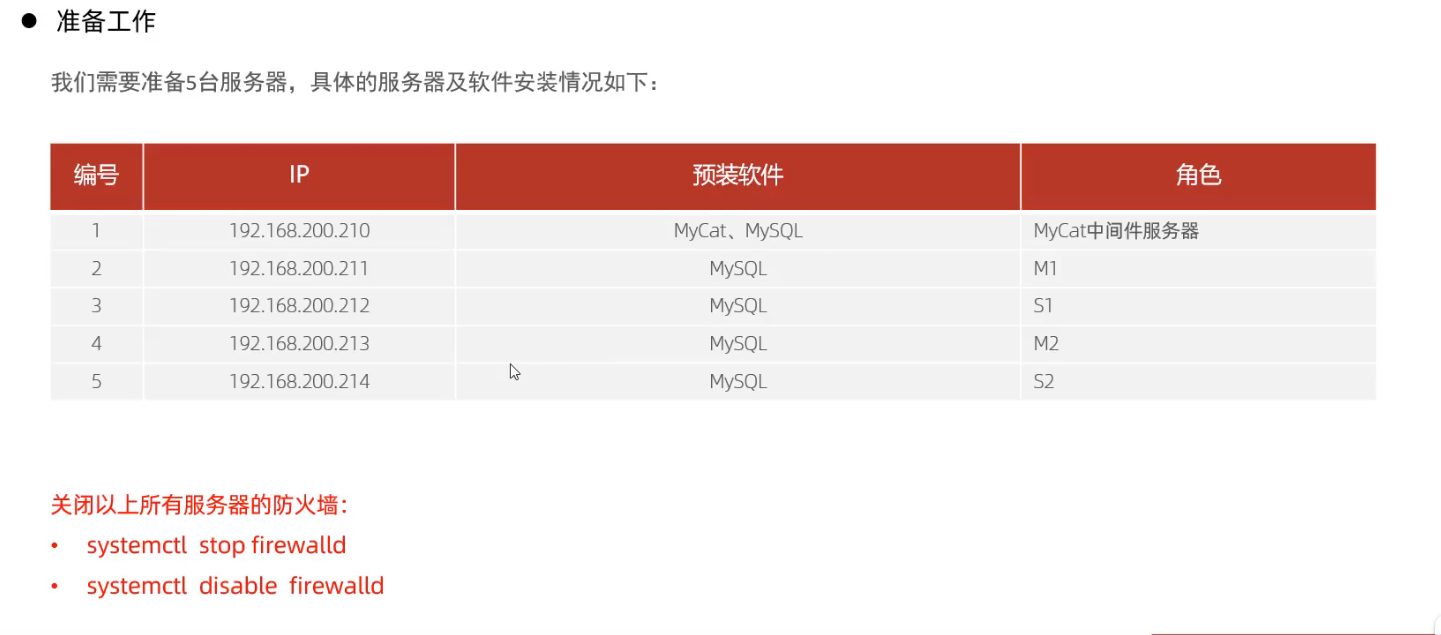
M1,M2
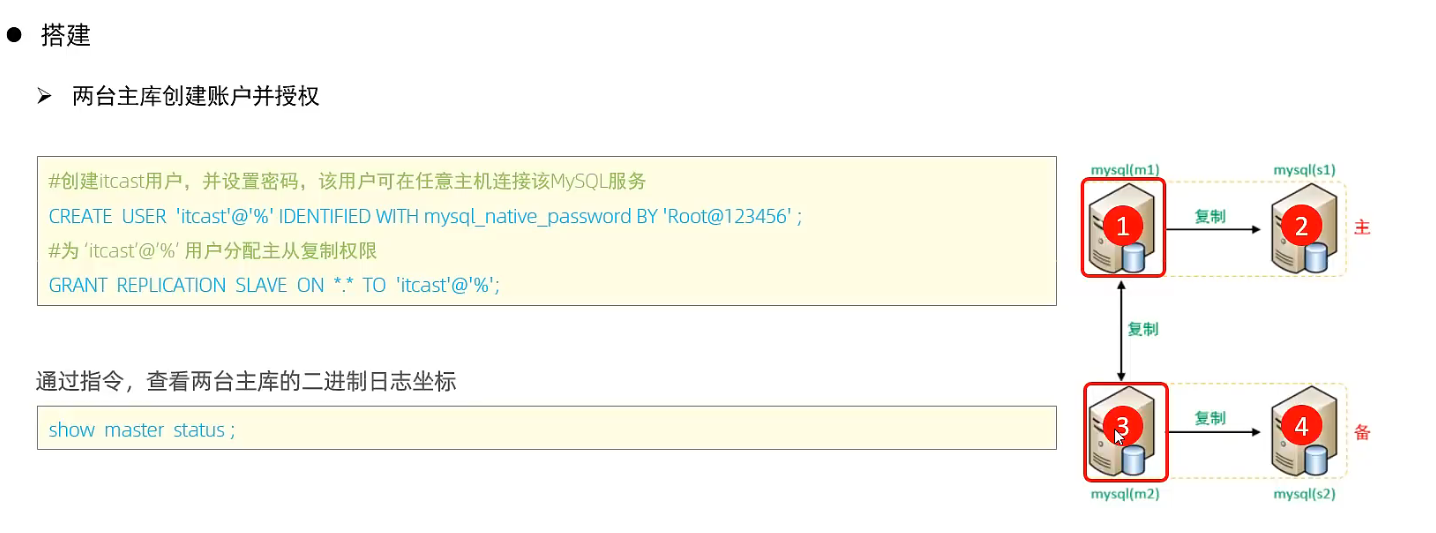
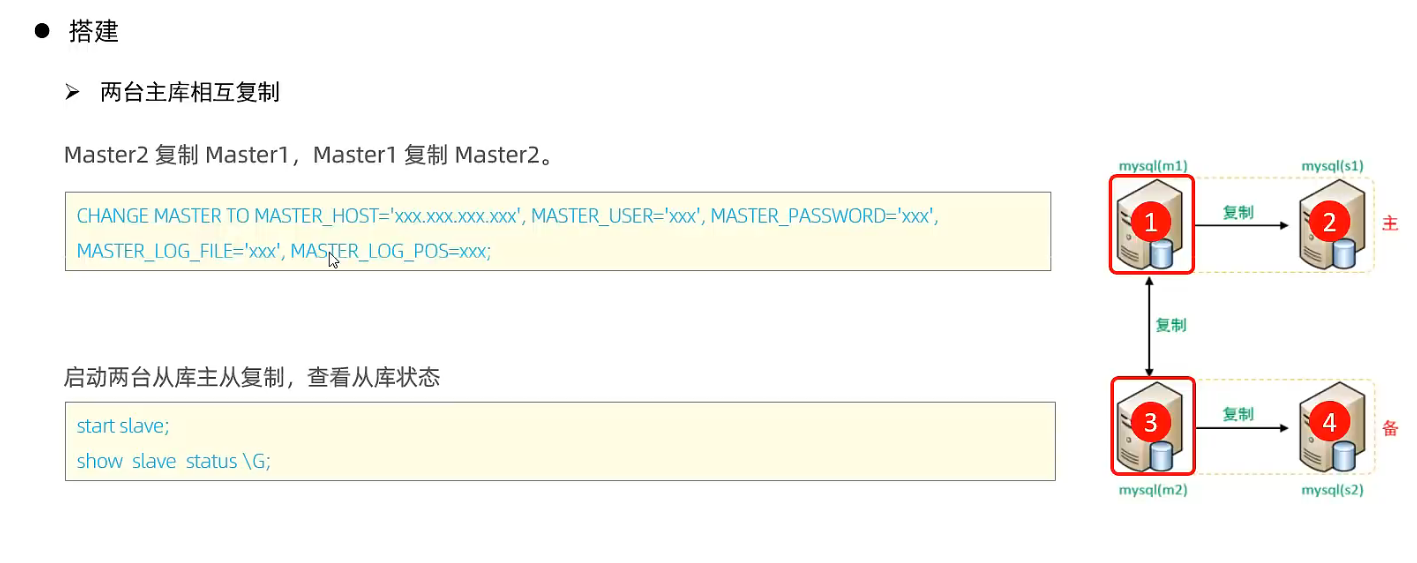
S1, S2
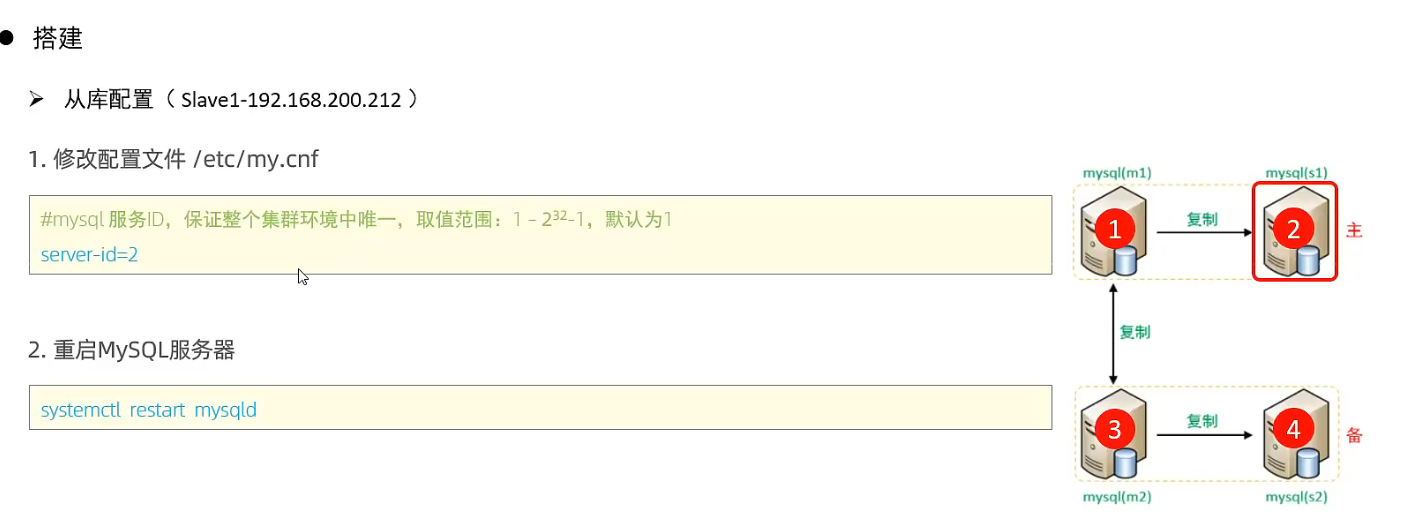
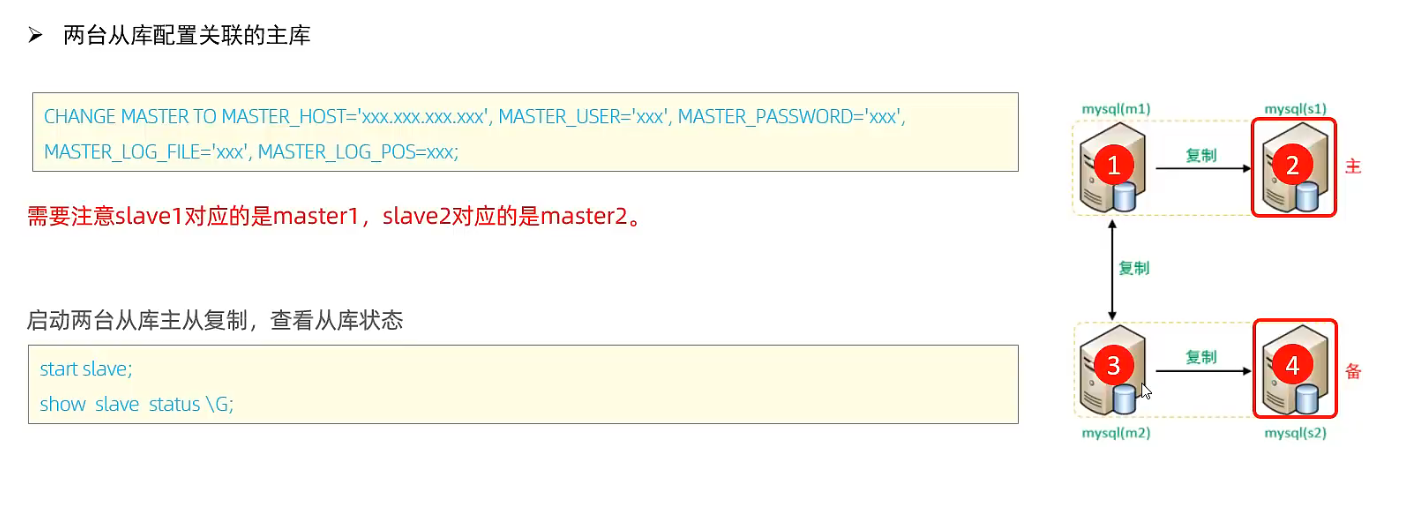
4.4 双主双从读写分离



 浙公网安备 33010602011771号
浙公网安备 33010602011771号