
2. 深入理解MySQL索引底层数据结构与算法
索引是帮助MySQL高效获取数据的排好序的数据结构
索引的结构有:
- 二叉树
- hash表
- 红黑树
- B树
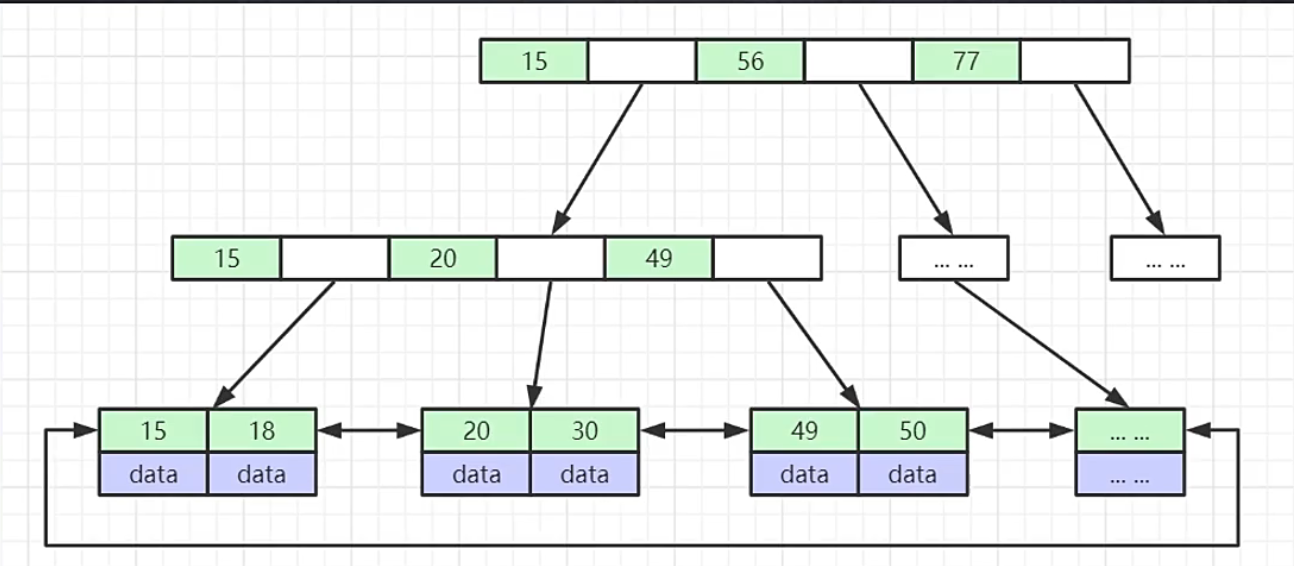
2.1 B+树结构
- 非叶子节点不存储data, 只存储索引, 可以放更多的索引
- 叶子节点包含所有索引字段
- 叶子节点用指针连接, 提高区间访问的性能
2.2 InnoDB索引实现(聚集索引)
- 表数据文件本身就是按照B+树组织的一个索引结构文件
- 聚集索引-叶子节点包含了该索引指向行的所有数据
- 二级索引叶子节点存储的是主键值, 是为了保持数据一致性, 同时节省存储空间
- 为什么建议InnoDB表建主键? 并且推荐使用整型的自增主键?
- 通过主键建立的索引就是聚集索引, 如果不建立主键, 每次查询时就都要从二级索引查到主键索引, 增加时间开销
- 整型: 1. 方便大小比较 2. 占用空间小
- 自增: 是为了避免索引结构重新调整, 重新调整花费时间较长. (自增只会分裂新节点, 非自增可能导致索引结构重新调整)
| 特性维度 | 无显式定义主键 | 整型自增主键 (推荐) | 非自增/非整型主键 (如UUID、字符串) |
|---|---|---|---|
| 存储结构 | InnoDB 会隐式创建 rowid作为主键 |
显式定义,聚簇索引,数据按主键顺序物理存储 | 聚簇索引,但数据物理存储顺序随机 |
| 插入性能 | 依赖隐式操作,性能不可控 | 顺序写入,减少页分裂和碎片,插入效率高 | 随机写入,频繁页分裂和重组,插入性能低 |
| 存储空间 | 隐式主键仍占用空间 |
空间占用小 (整型通常4或8字节),二级索引存储主键值也更小 | 空间占用大 (如UUID为16字节),二级索引也更庞大 |
| 查询效率 | 依赖隐式主键,性能不佳 | 整型比较速度快,B+树结构更紧凑查找效率高,范围查询性能优 (数据物理有序) | 比较效率低 (尤其字符串),范围查询可能效率低 |
| 并发与锁 | 可能增加锁争用 | 顺序插入减少锁竞争(通常只需锁定索引末端的最后一个间隙),高并发下性能更佳 | 随机插入可能导致更频繁的锁竞争 |
| 开发与维护 | 表结构不清晰,可能增加理解成本 | 自动生成唯一值,简化开发,避免手动指定主键的重复问题 | 需业务保证唯一性,可能更复杂 |
2.3 联合索引的底层结构
联合主键索引:
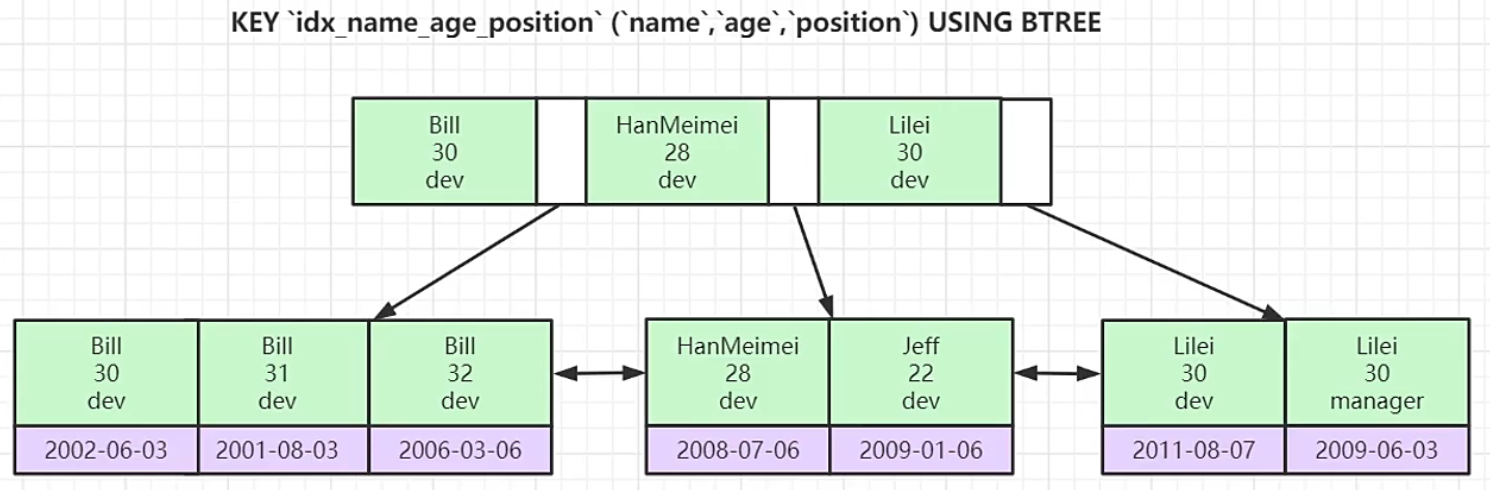
这里的索引是拍好序的, 排序的顺序就是按照建立联合索引时的先后顺序确定的, 所以在使用时必须满足最左前缀法则才会使用到此索引.
create index idx_name_age_position on `user`(name, age, position);
explain select * from user where name = "Bill" and position = "dev"; # key = idx_name_age_position
explain select * from user where name = "Bill" and position = "dev"; # key = None, possible_keys = idx_name_age_position
explain select * from user where age = 23 and position = "研发"; # key = None, possible_keys = None

 浙公网安备 33010602011771号
浙公网安备 33010602011771号