安装Spark与Python练习
一、安装Spark
- 检查基础环境hadoop,jdk
- 下载spark
- 解压,文件夹重命名、权限
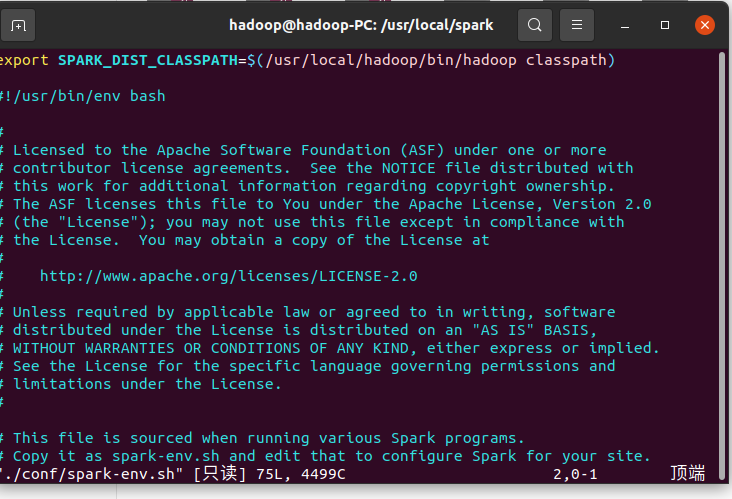
- 配置文件
![]()
2.
![]()
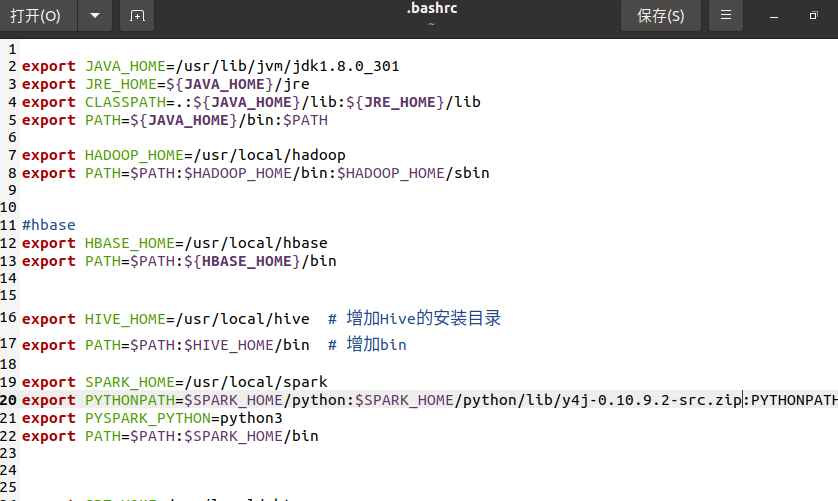
- 环境变量
-
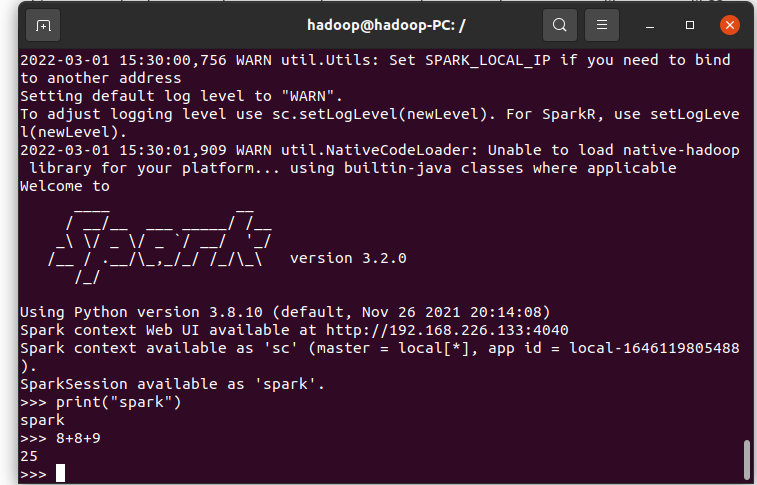
- 试运行Python代码
-
![]()
二、Python编程练习:英文文本的词频统计
- 准备文本文件
- 读文件
- 预处理:大小写,标点符号,停用词
- 分词
- 统计每个单词出现的次数
- 按词频大小排序
- 结果写文件
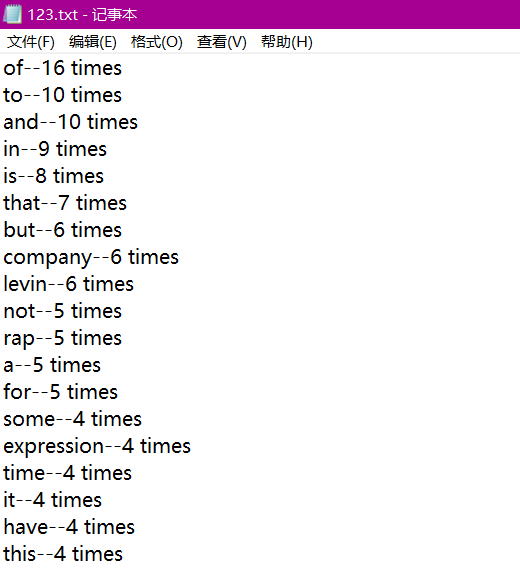
![]()
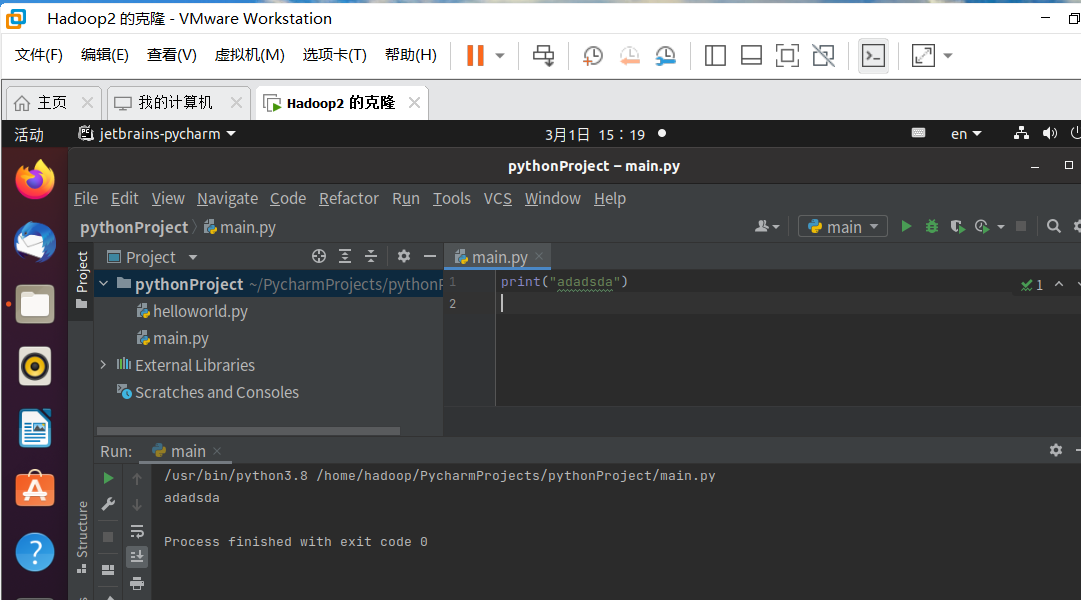
- 运行代码
-
import string
from os import path
with open(r'H:\大三\大数据实操\实验二\123.txt','rb') as input_text:
words = [word.strip(string.punctuation).lower() for word in str(input_text.read()).split()]
words_index = set(words)
count_dict = {index:words.count(index) for index in words_index}
with open(r'H:\大三\大数据实操\实验二\123.txt','a+') as output_text:
output_text.writelines('词频统计的结果为:' + '\n')
for word in sorted(count_dict,key=lambda x:count_dict[x],reverse=True):
output_text.writelines('{}--{} times'.format(word,count_dict[word]) + '\n')
input_text.close()
output_text.close()
-
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号