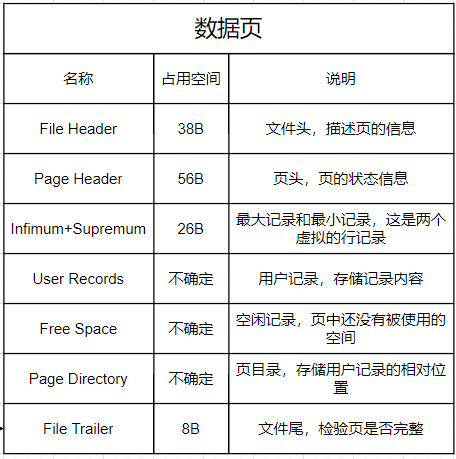
一、数据页
![]()
(1)文件头和文件尾
1)文件头
| 名称 |
占用空间 |
说明 |
| FIL_PAGE_OFFSET |
4B |
页号 |
| FIL_PAGE_TYPE |
2B |
页类型,数据页就是其中一种页类型 |
| FIL_PAGE_PREV |
4B |
上一页 |
| FIL_PAGE_NEXT |
4B |
下一页 |
| FIL_PAGE_SPACE_OR_CHKSUM |
4B |
校验和 |
| FIL_PAGE_LSN |
8B |
页面被最后修改时对应的日志序列位置 |
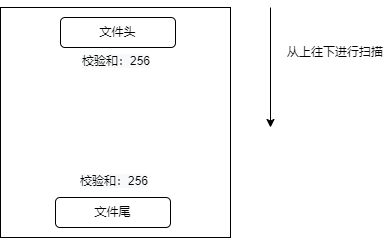
数据页和数据页之间是通过双向链表进行关联的,在文件头里保存了上一页的地址偏移量和下一页地址的偏移量。
![]()
文件头的日志序列位置和检验和对应**文件尾**的日志序列位置和校验和,用于检查数据页的完整性。完整的存储一个数据页的话,一定会把文件头的信息和文件尾信息保存下来。也就是比较文件头和文件尾的校验和是否相等来检查数据页的完整性。
2)文件尾
| 名称 |
占用空间 |
说明 |
| CHKSUM |
4B |
校验和 |
| LSN |
4B |
页面被最后修改时对应的日志序列位置 |
文件尾的日志序列位置和校验和也是用于检验数据页的完整性。
(2)用户记录和最大最小记录以及空闲空间
1)用户记录
用户记录是有指定的**行格式**形成一个单链表结构。单链表结构是由行格式的记录头信息的next_record确定,next_record记录者下一条记录的地址偏移量。
行格式(Compact):
| 名称 |
占用空间 |
说明 |
| 变长字段长度列表 |
变长字段的个数 * 2B |
记录表中变长字段的实际长度大小,倒序 |
| NULL列表 |
字段个数 * 1B |
记录表中字段的NULL状态:0表示为非NULL,1表示为NULL,倒序 |
| 记录头信息 |
5B |
见记录头信息表 |
| 记录真实数据 |
不确定 |
除了表字段的列值,还有3个隐藏列:row_id、transaction_id、roll_pointer;其中row_id是有可能作为隐藏主键出现的:因为一般是以主键作为聚集索引,如果一个表没有手动定义主键,则会选取一个unique键作为主键,如果连unique键都没有定义的话,则会为表默认添加一个名为row_id的隐藏列作为主键。 |
![]()
4种行格式
![]()
在处理**行溢出**问题上,Dynamic和Compressed采用完全行溢出,也就是说把溢出字段的完整数据放到另一个页中,原来的地方只要存一个地址就行;Compact和Redundant是将一部分数据保存到本页中,溢出的数据才另起一页进行存储,同样原来的地方也要保存溢出数据存放的地址。
行溢出
一个页的大小是16KB,对于大文本字段,16KB是远远不够的,此时就会出现行溢出。为了解决这个问题,就需要将数据存储到另一个页当中,同时记录存储地址。
记录头信息:
| 名称 |
占用空间 |
说明 |
| delete_mask |
|
删除标记 |
| min_rec_mask |
|
是否是每层非叶子节点的最小记录 |
| record_type |
|
记录类型(0代表普通记录、1代表非叶子节点记录、2代表最小记录、3代表最大记录) |
| heap_no |
|
当前记录在本页中的位置(其中0被最小记录使用,1被最大记录使用,所以用户记录只能从2开始计数) |
| n_owned |
|
当前记录所在组的总记录数(当前组的最后一条记录才需要记录这个值) |
| next_record |
|
下一条记录的地址偏移量 |
delete_mask的作用是避免在做删除记录操作时,大量移动后面的记录;在记录数据时,记录与记录之间是紧密排列,但是他们之间的关系仍然是通过next_record进行维护;同时,为了能够使被标记为delete_mask的记录能够被重复利用,会将这些记录构建出一个单独的“垃圾链表”,垃圾链表的头位置保存在页头的PAGE_FREE中。
隐藏列:
| 名称 |
占用空间 |
说明 |
是否必须 |
| row_id |
6B |
行ID,唯一标识一条记录 |
否 |
| transaction_id |
6B |
事务ID |
是 |
| roll_pointer |
7B |
回滚指针 |
是 |
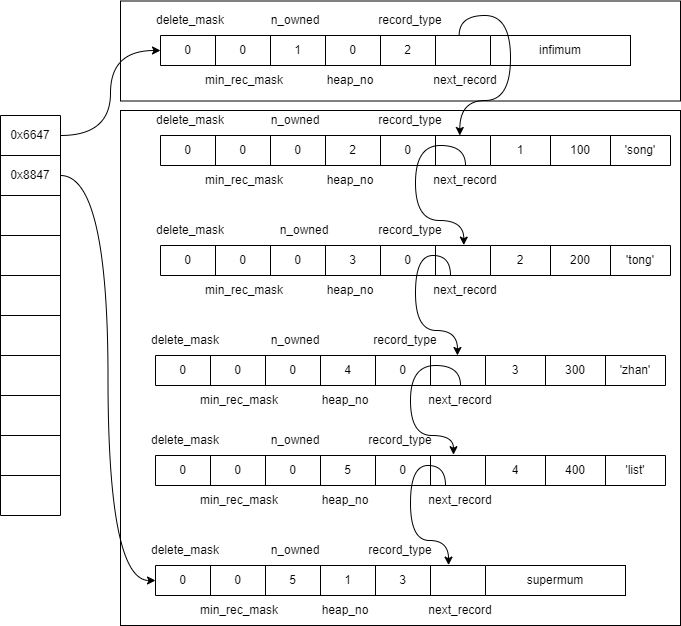
2) 最大最小记录
![]()
最大最小记录,并不存数据,只保存记录头信息和一个**固定值**(supermum代表最大记录,infimum代表最小记录)。最小记录的record_type等于2、heap_no等于0、next_record指向最小的用户记录;最大记录的record_type等于3、heap_no等于1、next_record指向NULL,最大的用户记录的next_record会指向最大记录。
3) 空闲空间
(3)页目录和页头
1)页目录
页目录用来存储每组最后一条记录的地址偏移量。
为什么需要页目录?
因为用户记录是链表结构,查询效率低,所以需要构造页目录(数组),然后就可以采用二分法进行查找了。
为什么页目录需要分组?
因为为每一条记录建立一个目录,成本太大了,所以需要对记录进行分组,然后将该组里的最后一条记录作为目录项就行了。
如何分组?为什么这样子分组?
第一组,就是最小记录单独一组;最后一组,就是最大记录所在的分组,会有1-8条记录,超过8条就会将这组分为两组:4和5;其余的组记录数量在4-8条之间。目的是为了尽可能让每个分组的记录数相同。
![]()
2)页头
| 名称 |
占用空间 |
说明 |
| PAGE_N_DIR_SLOTS |
2B |
页目录中的槽数量 |
| PAGE_HEAP_TOP |
2B |
还未使用的空间的最小地址,也就是说从该地址之后就是Free Space |
| PAGE_N_HEAP |
2B |
本页中的记录数量 |
| PAGE_FREE |
2B |
第一个已经标记为删除的记录地址(各个已删除的记录通过next_record也会组成一个单链表,这个单链表中的记录是可以被重新利用的) |
| PAGE_GARBAGE |
2B |
已删除记录占用的字节数 |
| PAGE_LAST_INSERT |
2B |
最后插入记录的位置 |
| PAGE_DIRECTION |
2B |
记录插入的方向 |
| PAGE_N_DIRECTION |
2B |
一个方向连续插入的记录数量 |
| PAGE_N_RECS |
2B |
本页中的记录数量(不包括最大最小记录和删除记录) |
| PAGE_MAX_TRX_ID |
8B |
修改当前页的最大事务ID,该值仅在二级索引中定义 |
| PAGE_LEVEL |
2B |
当前页所处的层级 |
| PAGE_INDEX_ID |
8B |
索引ID,表示当前页属于哪个索引 |
| PAGE_BTR_SEG_LEAF |
10B |
B+树叶子段的头部信息,仅在B+树的Root页定义 |
| PAGE_BTR_SEG_TOP |
10B |
B+树非叶子段的头部信息,仅在B+树的Root页定义 |
二、区、段、碎片区、表空间
1、为什么要有区?
2、为什么要有段?
3、为什么要有碎片区?
4、表空间:系统表空间和独立表空间
![]()



 浙公网安备 33010602011771号
浙公网安备 33010602011771号