
【故障处理】序列cache值过小导致CPU利用率过高
1、故障发生现象及报错信息
早上同事过来跟我说昨天有一套数据库做测试的时候,CPU利用率很高,他已经抓取了CPU和AWR,让我帮忙分析分析,首先发生问题的时间段是19点到23点,nmon数据截图如下:

可以看到CPU的利用率是非常高的,下边我们来看看AWR中的数据:
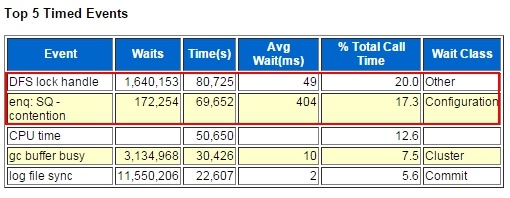
其它的项目就不列出了,从等待事件中可以很明显的看出enq: SQ - contention和DFS lock handle这2个等待事件异常。Top 5 Timed Events这个部分也是AWR报告中非常重要的部分,从这里可以看出等待时间在前五位的是什么事件,基本上就可以判断出性能瓶颈在什么地方。通常,在没有问题的数据库中,CPU time总是列在第一个。在这里,enq: SQ - contention等待了172254次,等待时间为69652秒,平均等待时间为69652/172254=404毫秒,等待类别为Configuration即配置上的等待问题。
2、故障分析
根据AWR报告的内容,我们知道只要解决了enq: SQ - contention和DFS lock handle这2个等待事件即可解决问题。那么我们首先来了解一些关于这2个等待事件的知识。
SELECT *
FROM V$EVENT_NAME
WHERE NAME IN
('row cache lock', 'enq: SQ - contention', 'DFS lock handle');查询到锁的名称和请求的MODE,表的mode值参考表格:
select chr(bitand(p1,-16777216)/16777215)||
chr(bitand(p1, 16711680)/65535) "Lock",
bitand(p1, 65535) "Mode"
from v$session_wait
where event = 'DFS enqueue lock acquisition';
SELECT * FROM V$LOCK_TYPE D WHERE D.TYPE IN ('SV','SQ');

oracle 为了管理sequence 使用了以下三种锁。
- row cache lock:在调用SEQUNECE.NEXTVAL过程中,将数据字典信息进行物理修改时获取。赋予了NOCACHE属性的SEQUENCE上发生,等待事件为row cache lock。
- SQ锁:在内存上缓存(CACHE)的范围内,调用SEQUENCE.NEXTVAL 期间拥有此锁。赋予了CACHE 属性的SEQUENCE 上发生。赋予了CACHE 属性的SEQUENCE 调用NEXTVAL 期间,应该以SSX 模式获得SQ 锁。许多会话同时为了获取SQ 锁而发生争用过程中,若发生争用,则等待enq: SQ - contention事件。enq: SQ - contention 事件的P2 值是Sequence 的OBJECT ID。因此,若利用P2 值与DBA_OBJECTS 的结合,就可以知道对哪个SEQUENCE 发生了等待现象。
- SV锁:RAC上节点之间顺序得到保障的情况下,调用SEQUENCE.NEXTVAL期间拥有。赋予CACHE + ORDER属性的SEQUENCE 上发生,等待事件为DFS lock handle,解决办法为:尽量设置为NOORDER并增大其CACHE值。
根据创建Sequence时赋予的属性,整理等待事件的结果如下:
- NOCACHE: row cache lock
- CACHE + NOORDER: enq: SQ - contention
- CACHE + ORDER(RAC): DFS lock handle
创建SEQUENCE赋予的CACHE 值较小时,有enq: SQ - contention等待增加的趋势。CACHE值较小时,内存上事先CACHE的值很快被耗尽,这时需要将数据字典信息物理修改后,再次执行CACHE的工作。在此期间,因为一直拥有SQ 锁,相应的enq: SQ - contention 事件的等待时间也会延长。很不幸的是,在创建SEQUENCE 时,将CACHE 值的缺省值设定为较小的20。因此创建使用量多的SEQUENCE 时,CACHE 值应该取1000 以上的较大值。
另外,偶尔一次性同时创建许多会话时,有时会发生enq: SQ - contention 等待事件。其理由是V$SESSION.AUDSID(auditing session id)列值是利用Sequence创建的。Oracle 在创建新的会话后,利用名为SYS.AUDSES$的Sequence 的nextval,创建AUDSID 值。SYS.AUDSES$ Sequence 的CACHE 大小的缺省值设定为20。许多会话同时连接时,可以将SYS.AUDSES$ Sequence 的CACHE大小扩大至1000,以此可以解决enq: SQ - contention 等待问题。 10g下默认20,11g下默认为10000,通过如下的SQL可以查询:
SELECT * FROM dba_sequences d WHERE d.sequence_name ='AUDSES$';RAC 上创建SEQUENCE 时,在赋予了CACHE属性的状态下,若没有赋予ORDER 属性,则各节点将会把不同范围的SEQUENCE 值CACHE 到内存上。比如,拥有两个节点的RAC 环境下,创建CACHE 值为100 的SEQUENCE 时,1号节点使用1~100,2 号节点使用101~200(noorder)。若两个节点之间都通过递增方式使用SEQUENCE,必须赋予如下ORDER 属性。
SQL> CREATE SEQUENCE ORDERED_SEQUENCE CACHE 100 ORDER;如果是已赋予了CACHE+ORDER 属性的SEQUENCE,Oracle 使用SV 锁进行行同步。即,对赋予了ORDER 属性的Sequence 调用nextval 时,应该以SSX模式拥有SV 锁。在获取SV 锁过程中,如果发生争用时,不是等待row cache lock 事件或enq: SQ - contention 事件,而是等待名为DFS lock handle 事件。正因如此,V$EVENT_NAME 视图上不存在类似"enq:SV-contention"的事件。DFS lock handle 事件是在OPS 或RAC 环境下,除了高速缓冲区同步之外,还有行高速缓冲区或库高速缓冲区的为了同步获取锁的过程中等待的事件。若要保障多个节点之间Sequence顺序,应该在全局范围内获得锁,在此过程中会发生DFS lock handle 等待。在获取SV 锁的过程中发生的DFS lock handle等待事件的P1 、P2 值与enq: SQ - contention 等待事件相同( P1=mode+namespace、P2=object#)。因此从P1 值能确认是否是SV 锁,通过P2值可以确认对哪些Sequence 发生过等待。SV 锁争用问题发生时的解决方法与SQ 锁的情况相同,就是将CACHE 值进行适当调整,这也是唯一的方法。
有一点必须要注意,没有赋予CACHE属性时,不管ORDER 属性使用与否或RAC 环境与否,一直等待row cache lock 事件。row cache lock是可以在全局范围内使用的锁,单实例环境或多实例环境同样可以发生。
oracle sequence默认是NOORDER,如果设置为ORDER;在单实例环境没有影响,在RAC环境此时,多实例实际缓存相同的序列,此时在多个实例并发取该序列的时候,会有短暂的资源竞争来在多实例之间进行同步。因次性能相比noorder要差,所以RAC环境非必须的情况下不要使用ORDER,尤其要避免NOCACHE ORDER组合。
但是如果使用了Cache,如果此时DB 崩溃了,那么sequence会从cache之后重新开始,在cache中没有使用的sequence会被跳过。即sequence不连续。所以只有在多节点高峰并发量很大的情况且对连续性要求不高的情况下,才使用:noorder + cache。
有了以上的知识,我们知道,目前只需要找到产生等待的序列名称,然后设置其CACHE为比较大的一个值即可解决问题。
3、解决故障
3.1 enq: SQ - contention等待事件
我们查询出现问题时间段的ASH视图DBA_HIST_ACTIVE_SESS_HISTORY来找到我们需要的序列名称。
SELECT D.SQL_ID, COUNT(1)
FROM DBA_HIST_ACTIVE_SESS_HISTORY D
WHERE D.SAMPLE_TIME BETWEEN TO_DATE('20160823170000', 'YYYYMMDDHH24MISS') AND
TO_DATE('20160823230000', 'YYYYMMDDHH24MISS')
AND D.EVENT = 'enq: SQ - contention'
GROUP BY D.SQL_ID;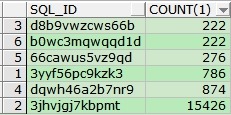
可以看到SQL_ID为3jhvjgj7kbpmt的SQL最多,我们查看具体SQL内容:
SELECT * FROM V$SQL A WHERE A.SQL_ID IN ('3jhvjgj7kbpmt') ;
第二种方式:
DBA_HIST_ACTIVE_SESS_HISTORY视图的P2值获取到序列的名称,如下:
SELECT D.EVENT,
D.P1TEXT,
D.P1,
D.P2TEXT,
D.P2,
CHR(BITAND(P1, -16777216) / 16777215) || CHR(BITAND(P1, 16711680) / 65535) "Lock",
BITAND(P1, 65535) "Mode",
D.BLOCKING_SESSION,
D.BLOCKING_SESSION_STATUS,
D.BLOCKING_SESSION_SERIAL#, D.SQL_ID, TO_CHAR(D.SAMPLE_TIME, 'YYYYMMDDHH24MISS') SAMPLE_TIME, D.*
FROM DBA_HIST_ACTIVE_SESS_HISTORY D
WHERE D.SAMPLE_TIME
BETWEEN TO_DATE('20160823170000', 'YYYYMMDDHH24MISS')
AND TO_DATE('20160823230000', 'YYYYMMDDHH24MISS')
AND D.EVENT = 'enq: SQ - contention';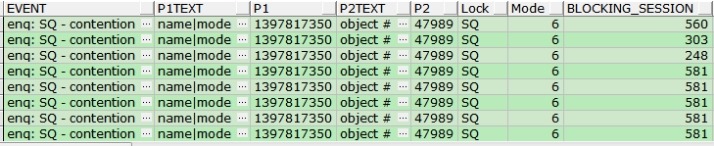
由以上的查询结果可知,序列的object_id为47989,由此也可以知道序列名称如下,另外,lock为SQ代表的是序列的cache锁(Sequence Cache),mode为6代表Exclusive排他锁。
SELECT * FROM DBA_OBJECTS D WHERE D.object_id='47989';知道了序列名称后,我们就可以查询序列的属性了:
SELECT * FROM DBA_SEQUENCES D WHERE D.sequence_name='ONLNID' ;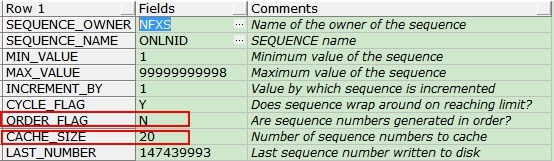
可以看到,该序列是NOORDER属性,CACHE值为默认的20,对于并发值很高的系统而言,该默认值太低,所以需要调整到1000,我们执行SQL:ALTER SEQUENCE NFXS.ONLNID CACHE 1000; 调整其cache值即可解决该问题。
DFS lock handle等待事件
我们查询出现问题时间段的ASH视图DBA_HIST_ACTIVE_SESS_HISTORY来找到我们需要的序列名称。
SELECT D.SQL_ID, COUNT(1)
FROM DBA_HIST_ACTIVE_SESS_HISTORY D
WHERE D.SAMPLE_TIME BETWEEN TO_DATE('20160823170000', 'YYYYMMDDHH24MISS') AND
TO_DATE('20160823230000', 'YYYYMMDDHH24MISS')
AND D.EVENT = 'DFS lock handle'
GROUP BY D.SQL_ID;
可以看到SQL_ID为"67vjwqswg2zvy"的SQL最多,我们查看具体SQL内容:
SELECT * FROM V$SQL A WHERE A.SQL_ID IN ('67vjwqswg2zvy'); 
很奇怪,这是个系统视图,为啥会有DFS lock handle的等待事件产生呢?
SELECT D.EVENT,
D.P1TEXT,
D.P1,
D.P2TEXT,
D.P2,
CHR(BITAND(P1, -16777216) / 16777215) ||
CHR(BITAND(P1, 16711680) / 65535) "Lock",
BITAND(P1, 65535) "Mode",
D.BLOCKING_SESSION,
D.BLOCKING_SESSION_STATUS,
D.BLOCKING_SESSION_SERIAL#,
D.SQL_ID,
TO_CHAR(D.SAMPLE_TIME, 'YYYYMMDDHH24MISS') SAMPLE_TIME,
D.*
FROM DBA_HIST_ACTIVE_SESS_HISTORY D
WHERE D.SAMPLE_TIME BETWEEN TO_DATE('20160823170000', 'YYYYMMDDHH24MISS') AND
TO_DATE('20160823230000', 'YYYYMMDDHH24MISS')
AND D.EVENT = 'DFS lock handle'; 
由以上的查询结果可知,lock为CI代表的是交叉实例功能调用实例,而并不是我们期望的SV锁,mode为5代表Share/Sub-Exclusive。
SELECT * FROM V$LOCK_TYPE D WHERE D.TYPE ='CI';
查了metalink可知,该问题是由bug引起。该库的版本为10.2.0.5的基础版本,并没有打任何的PSU。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号