
JOB
1、在数据库中,常常会有一些比较复杂的定时批量运行脚本的任务,这些任务的时间通常是非常长的,而且 基本上每天都是定时执行脚本,比如晚上 22 点等,这个时候就要用到数据库的 JOB 了。
Oracle 的 JOB 分为两类,DBMS_JOB 和 DBMS_SCHEDULER,二者都可以完成定时任务。
DECLARE
V_JOB NUMBER;
BEGIN
SYS.DBMS_JOB.SUBMIT(JOB => X,
WHAT => 'begin EXECUTE IMMEDIATE ''DROP PROCEDURE
PRO_STOP_DB_HEALTHCHECK_LHR''; end;',
NEXT_DATE => SYSDATE,
INTERVAL => 'null',
NO_PARSE => FALSE);
COMMIT;
END;
(1) 参数 JOB 是由 SUBMIT()过程返回的 BINARY_INEGER。这个值用来唯一标识一个工作,此参数是个变量,在使用前需要被声明,JOB 号在 DBA_JOBS 视图里可以查到。 (2) WHAT 参数的值是将被 JOB 执行的 PL/SQL 代码块,一般是存储过程的名字,记得存储过程后面一定要加上分号。但是,若 WHAT 的参数为 PL/SQL 匿名块,则需要加上分号,例如,what=>'begin null; end;' (3) NEXT_DATE 参数指示何时运行这个 JOB,NEXT_DATE 需要修改为数据库第一次执行该 JOB的时间,SYSDATE 表示立即执行。 SYSDATE + 10 / (24 * 60 * 60) 表示 10 秒钟之后运行。 (4) INTERVAL 参数表示这个 JOB 什么时候将被再次执行,指定 JOB 的运行周期,INTERVAL为空表示只执行一次。 (5) NO_PARSE 参数表示此 JOB 在提交或执行时是否应进行语法分析,TRUE 代表此 PL/SQL 代码在它第一次执行时应进行语法分析,而 FALSE 代表本 PL/SQL 代码应立即进行语法分析,在创建 JOB时进行检查。
默认值为 FALSE。
需要注意的是,NEXT_DATE 是时间类型,INTERVAL 是字符类型,在调用 SUBMIT 时要指定正确的参数类型
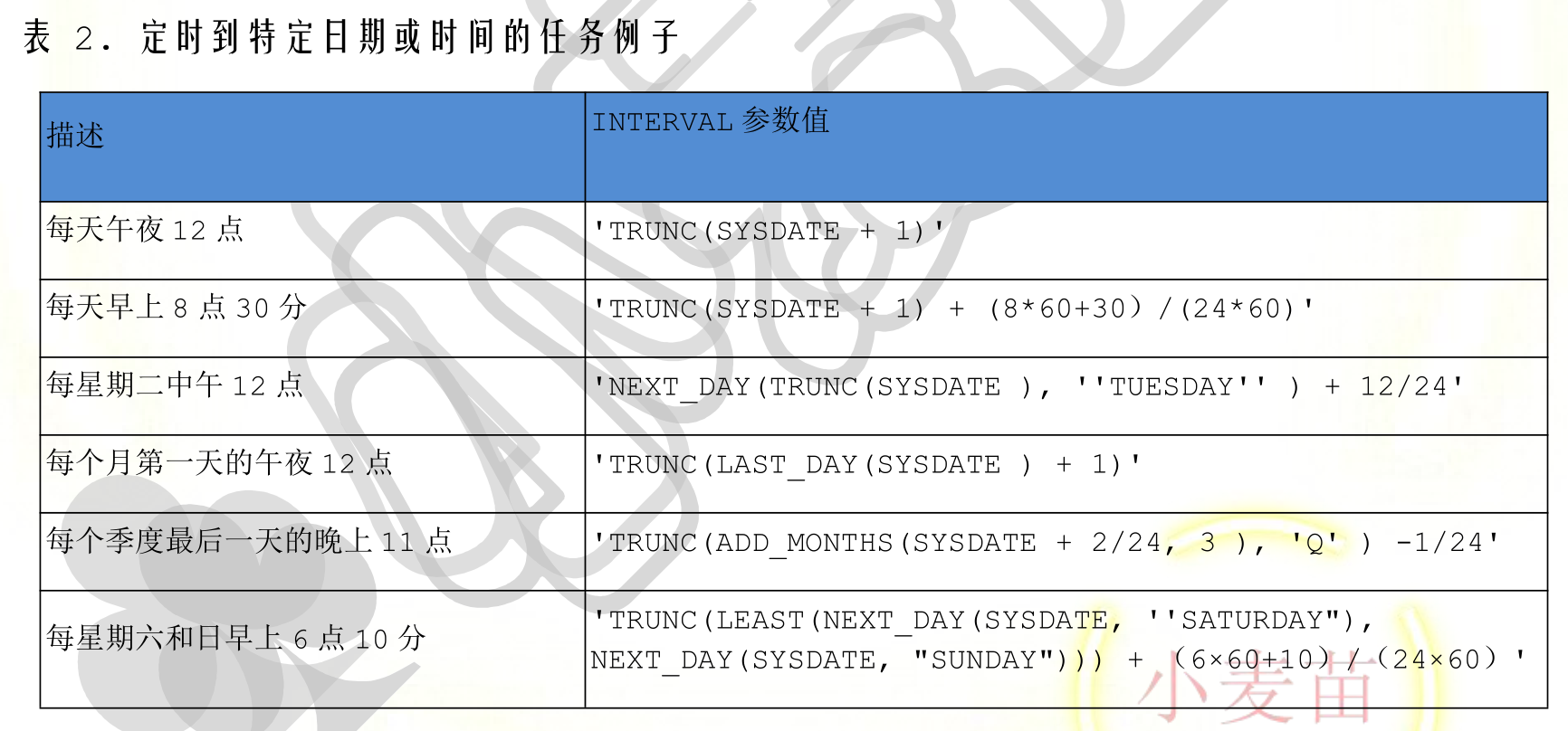
interval 参数设置例子
![]()

注意 1:使用'next_day(sysdate,''TUESDAY'')'时,需要修改设置日期格式。例如:SQL> alter session set nls_date_language='American';
注意 2:使用'next_day(sysdate,''TUESDAY'')'时,必须使用 Monday 到 Sunday 的格式,否则出错(如使用’星期一’,出现隐形错误,显示的值不是周一,而是一个未知值)。
SELECT SYSDATE - 1, trunc(SYSDATE), TRUNC(SYSDATE - 1), SYSDATE + 1, -- 每天运行一次 SYSDATE + 1 / 24, -- 每小时运行一次 SYSDATE + 10 / (60 * 24), -- 每 10 分钟运行一次 SYSDATE + 30 / (60 * 24 * 60), -- 每 30 秒运行一次 SYSDATE + 7, -- 每隔一星期运行一次 trunc(SYSDATE, 'dd'), -- 返回当前年月日 trunc(SYSDATE, 'd'), -- 返回当前星期的第一天。 trunc(SYSDATE, 'mm'), -- 返回当月第一天。 trunc(SYSDATE, 'yyyy'), -- 返回当年第一天。 trunc(SYSDATE, 'mi'), -- 截取到分钟,即秒是以 00 来显示的,可以和 ( SYSDATE - 1 )的时间做比较 TRUNC(SYSDATE, 'mi') + 1 / (24 * 60), -- 每分钟执行 TRUNC(SYSDATE, 'mi') + 1 / 360, -- 每 4 分钟执行 TRUNC(SYSDATE + 1), -- 每天午夜 12 点 TRUNC(SYSDATE + 1) + (8 * 60 + 30) / (24 * 60), -- 每天早上 8 点 30 分 TRUNC(SYSDATE + 1) + 2 / 24, -- 每天的凌晨 2 点执行 NEXT_DAY(TRUNC(SYSDATE), 'TUESDAY') + 12 / 24, -- 每星期二中午 12 点 TRUNC(LEAST(NEXT_DAY(SYSDATE, 'TUESDAY'), NEXT_DAY(SYSDATE, 'TUESDAY'))) +(6 * 60 + 10) / (24 * 60), -- 每星期二和三早上 6 点 10 分 TRUNC(next_day(SYSDATE, 2)) + 2 / 24, -- 每周一凌晨 2 点执行 ( 星期一,一周的第二天 ) TRUNC(LAST_DAY(SYSDATE) + 1), -- 每个月第一天的午夜 12 点 TRUNC(LAST_DAY(SYSDATE)) + 1 + 2 / 24, -- 每月 1 日凌晨 2 点执行 TRUNC(ADD_MONTHS(SYSDATE + 2 / 24, 3), 'Q') - 1 / 24, -- 每个季度最后一天的晚上 11 点 TRUNC(ADD_MONTHS(SYSDATE, 3), 'Q') + 2 / 24, -- 每季度的第一天凌晨 2 点执行 ADD_MONTHS(trunc(SYSDATE, 'yyyy'), 6) + 2 / 24, -- 每年 7 月 1 日和 1 月 1 日凌晨 2 点 ADD_MONTHS(trunc(SYSDATE, 'yyyy'), 12) + 2 / 24, -- 每年 1 月 1 日凌晨 2 点执行 trunc(last_day(to_date(extract(YEAR FROM SYSDATE) || '12' || '01', 'yyyy-mm-dd')) +1) -- 每年 1 月 1 号零时 FROM dual;
---每分钟执行
Interval =>TRUNC(sysdate,'mi') + 1/ (24*60)
如果改成TRUNC(sysdate,'mi')+ 10/ (24*60) 就是每10分钟执行次
---每天定时执行
例如:每天的凌晨1点执行
Interval =>TRUNC(sysdate) + 1 +1/ (24)
---每周定时执行
例如:每周一凌晨1点执行
Interval =>TRUNC(next_day(sysdate,'星期一'))+1/24
---每月定时执行
例如:每月1日凌晨1点执行
Interval=>TRUNC(LAST_DAY(SYSDATE))+1+1/24
---每季度定时执行
例如每季度的第一天凌晨1点执行
Interval =>TRUNC(ADD_MONTHS(SYSDATE,3),'Q') + 1/24
---每半年定时执行
例如:每年7月1日和1月1日凌晨1点
Interval =>ADD_MONTHS(trunc(sysdate,'yyyy'),6)+1/24
---每年定时执行
例如:每年1月1日凌晨1点执行
Interval=>ADD_MONTHS(trunc(sysdate,'yyyy'),12)+1/24
2、dbms_job package 用法介绍
删除 job: ecec dbms_job.remove(jobno);
修改要执行的操作job: dbms_job.what(jobno,what);
修改下次执行时间: dbms_job.next_date(job,next_date);
修改间隔时间: dbms_job.interval(job,interval);
停止 job: dbms.broken(job,broken,nextdate);
启动 job: exec dbms_job.run(jobno);
ISubmit()过程用来用特定的工作号提交一个工作。这个过程有五个参数:job、what、next_date、interval 与 no_parse。
---角色权限:
SQL>GRANT EXECUTE ON DBMS_JOB TO USER;
---后台进程:
select name,description from v$bgprocess;
JOB 相关进程:CJQ0
---broken
job 如果由于某种原因未能成功之行,oracle 将重试 16 次后,还未能成功执行,将被标记 为broken ,重新启动状态为 broken 的 job,有如下两种方式;
a、利用 dbms_job.run()立即执行该 job
begin
dbms_job.run(:jobno); 该 jobno 为 submit 过程提交时返回的 job number
end;
/
b、利用 dbms_job.broken()重新将 broken 标记为 false
begin
dbms_job.broken (:job,false,next_date);
end;
/
---kill jobs
如果正在运行中的 job,执行该过程删除后在 dba_jobs 查询不到了,但是在dba_jobs_running 仍然可以查询到,会话中也存在,这就形成了僵尸 job,有 2 种办法解决:
①待 等待 job 能 执行完,不太可能
②select b.sid,b.serial# from dba_jobs_running a, v$session b where a.sid=b.sid and a.job='1'; ---查询job对应的sid
ALTER SYSTEM KILL SESSION '24,560' IMMEDIATE; 如果这个执行完后还不能杀掉就要 进入服务器去杀掉服务器的进程了(kill -9 spid),最好将不用的 job 置为 broken,不然杀了又自动启动了
用什么用户创建的 job, 就使用什么用户删除该 job, 不然 dbms_job 就会报错..(作业编号 84 在作业队列中不是一个作业)
Oracle 没有对 JOB 设置相应的权限,任何用户都可以使用 DBMS_JOB 包建立自己的 JOB。也正是因为没有权限的限制,所以使用 DBMS_JOB 包无法删除其他用户下的 JOB。
即使是 SYS 用户也无法通过 DBMS_JOB 包删除其他用户下的 JOB。但是可以通过DBMS_IJOB 包来实现。exec sys.dbms_ijob.remove(84);
3、RAC 中定 指定 dbms_job 运行在指定实例
1、目前我们的 rac 数据库是通过查询语句 select job,instance,what from dba_jobs 可以看到 instance=0,这表示该 job 是 db 级,可以运行在任何活动的 instance 上,由 job 的调度机制决定在 哪个实例上运行。也就是说 RAC 会根据两台服务器的运行状态来调度 JOB 在不同的节点实例中运行,一个JOB 可以在 A 机,下一次有可能在 B 机运行; 2、通过在调度中指定 instance 参数,可以指定 job 只在某个特定实例上运行,但是如果该实例的服务器出现故障时,发现 job 在实例 A 上不再运行,也不会切换到其它实例。如果 job 建立时没有指定运行在某 个实例上,在 job 当前运行的实例关掉后,却可以切到其他活动的实例上。

3、一般情况下,建立不要指定 JOB 在特定实例运行,如果对于对于已经在运行的 job,如果想指定其只在某个实例运行。建议先删除此 job,然后重建 job,重建时指定 job 运行的实例。对于有人说可以使用如下
方式修改 job 运行的实例:SQL> exec dbms_job.instance(26,1)。经测试,不好使,此 sql 执行后,job 不再运行,并出现等待事件:enq: TX - row lock contention,查到执行的 sql 是 update sys.job$ setthis_date=:1 where job=:2,也就是在更新 sys 的 sys.job$表,最后只能杀掉此会话,才消除此等待事件。
4、jobs视图
SELECT JOB, NEXT_DATE, NEXT_SEC, FAILURES, BROKEN FROM DBA_JOBS; ---查询job信息 SELECT SID,r.JOB,LOG_USER,r.THIS_DATE,r.THIS_SEC FROM DBA_JOBS_RUNNING r,DBA_JOBS j WHERE r.JOB = j.JOB; ---查询正在运行的jobs
5、DBMS_SCHEDULER
5.1、DBMS_JOB 和 DBMS_SCHEDULER 之间的主要区别如下:
1. DBMS_SCHEDULER 可以执行存储过程、匿名块以及 OS 可执行文件和脚本(包括 linux 系统的shell 脚本),而 DBMS_JOB 只可以执行存储过程或匿名的 PL/SQL 块。
2. 考虑到增强的组件重用,调度程序的程序单元作为模式对象存储。DBMS_JOB 只有一种组件,即作业;而调度程序具有组件层次结构。
3. 可以使用 DBMS_SCHEDULER 更具描述性地定义作业或进度表间隔。DBMS_SCHEDULER 也具有更详细的作业运行状态以及故障处理和报告功能。

BEGIN DBMS_SCHEDULER.CREATE_JOB(JOB_NAME => 'AGENT_LIQUIDATION_JOB', --要创建的 JOB 名称 JOB_TYPE => 'STORED_PROCEDURE', JOB_ACTION => 'AGENT_LIQUIDATION.LIQUIDATION', --存储过程名 START_DATE => SYSDATE, REPEAT_INTERVAL => 'FREQ=MONTHLY; INTERVAL=1; BYMONTHDAY=1;BYHOUR=1;BYMINUTE=0;BYSECOND=0', --按月执行,间隔为 1 个月,每月 1 号,凌晨 1 点执行 COMMENTS => 'SECOND');--JOB 的注释 END;
5.2、组件(components)
各个组件中除了 schedule 默认不是禁用的,其它均是禁用的。
5.2.1作业(job): 一个调度程序作业的实体.可以由 dbms_scheduler.create_job 创建生成.它可以自行指定作业属性,也可以调用我们预先创建的一系列 schedule/ program/ chain/ job_class/ window/
window_group 来匹配其作业属性。
5.2.2 时间表(schedule):-- 默认非禁用 注意这里是 schedule 不是 scheduler。 通过 DBMS_SCHEDULER 包中的过程 CREATE_SCHEDULE 定义调度的开始时间,结束时间以及重复间隔CREATE_EVENT_SCHEDULE 过程用来创建由事件触发的时间表,由一个特定时间段内的一个事件调起一项任务
BEGIN
dbms_scheduler.create_schedule(schedule_name => 'myscheduler',
repeat_interval => 'FREQ=MINUTELY;INTERVAL=2');
END;
---drop
BEGIN
DBMS_SCHEDULER.drop_schedule(schedule_name => 'myscheduler');
END;
1、FREQ 关键字用来指定间隔的时间周期,可选参数有:YEARLY 、MONTHLY 、WEEKLY 、DAILY 、HOURLY 、MINUTELY and SECONDLY,分别表示年、月、周、日、时、分、秒等单位。
2、INTERVAL 关键字用来指定间隔的频繁,可指定的值的范围从 1-99。例如:REPEAT_INTERVAL=>'FREQ=DAILY;INTERVAL=1';表示每天执行一次
(2)每隔一周运行一次,仅在周5运行 REPEAT_INTERVAL => 'FREQ=WEEKLY; INTERVAL=2; BYDAY=FRI’; (3)每月最后一天运行 REPEAT_INTERVAL => 'FREQ=MONTHLY; BYMONTHDAY=-1'; (4)在3月10日运行 REPEAT_INTERVAL => 'FREQ=YEARLY; BYMONTH=MAR; BYMONTHDAY=10’; REPEAT_INTERVAL => 'FREQ=YEARLY; BYDATE=0310'; (5)每10隔天运行 REPEAT_INTERVAL => 'FREQ=DAILY; INTERVAL=10’; (6)每天的下午4、5、6点时运行 REPEAT_INTERVAL => 'FREQ=DAILY; BYHOUR=16,17,18’; (7)每月29日运行 REPEAT_INTERVAL => 'FREQ=MONTHLY; BYMONTHDAY=29’; (8)每年的最后一个周5运行 REPEAT_INTERVAL => 'FREQ=YEARLY; BYDAY=-1FRI’; (9)每隔50个小时运行 REPEAT_INTERVAL => 'FREQ=HOURLY; INTERVAL=50’;
5.2.3 程序(program)
BEGIN
DBMS_SCHEDULER.CREATE_PROGRAM(program_name => 'myprogram1',
program_action => 'update mytest set id=id+1;',
program_type => 'PLSQL_BLOCK',
number_of_arguments => 0,
comments => '',
enabled => TRUE);
END;
//* program_name——程序名称
program_type——程序类型(STORED_PROCEDURE,PLSQL_BLOCK,EXECUTABLE)
STORED_PROCEDURE——ORACLE 中定义好的存储过程
PLSQL_BLOCK——是一段标准的pl/sql 代码
EXECUTABLE——指定外部命令的命令行信息(含路径信息)
program_action——具体对应的执行内容,若为过程则为过程名
enable——若为true则创建后激活反之不激活
comments——注释
select * from user_scheduler_programs; ---查询用户program
----- 修改属性
BEGIN
DBMS_SCHEDULER.SET_ATTRIBUTE(NAME => 'P_1',
attribute => 'PROGRAM_ACTION',
VALUE => '/backup/2.sh');
END;
---删除
BEGIN
dbms_scheduler.drop_program(program_name => 'myprogram',force => TRUE);
END;
SELECT *FROM User_Scheduler_Program_Args; --查看定义的program参数
5.2.4 作业类(job_class):
定义了运行作业的资源使用者组.通过使用窗口中的资源计划,我们可以在不同资源组和不同作业类之间分配资源.可以使用 dbms_scheduler.create_job_class 创建一个作业类.
BEGIN
dbms_scheduler.create_job_class(logging_level => DBMS_SCHEDULER.LOGGING_RUNS,
log_history => 100,
resource_consumer_group => 'AUTO_TASK_CONSUMER_GROUP',
job_class_name => 'MYTEST_JOB_CLASS');
END;
//*resource_consumer_group——指定该jobclass所使用的资源分配方式。具体创建方法见dbms_resource_manager.create_consumer_group。
jobclass与resource_consumer_group为多对1关系;
若为该jobclass指定的resource_consumer_group被删除,则使用默认的resource_consumer_group;
若没为jobclass指定具体的resource_consumer_group,则使用默认的resource_consumer_group;
若为该jobclass指定的resource_consumer_group不存在,则会提示错误;
若为该jobclass指定了resource_consumer_group,则service参数必须设置为空(即这两个参数只能设置其中一个)。
service——一般用于rac环境指定jobclass运行于哪个节点。
logging_level——日志记录级别
DBMS_SCHEDULER.LOGGING_OFF:关闭日志记录功能;
DBMS_SCHEDULER.LOGGING_RUNS:对该 JobClass 下所有任务的运行信息进行记录;
DBMS_SCHEDULER.LOGGING_FULL:记录该 JobClass 下任务的所有相关信息,不仅有任务运行情况,甚至连任务的创建、修改等也均将记入日志。
log_history——日志存放时间,默认30
select * from dba_scheduler_job_classes; ---查询jobs_class
5.2.5 job --不采用program和scheduler直接创建job BEGIN dbms_scheduler.create_job(job_name => 'myjob', job_type => 'STORED_PROCEDURE', job_action => 'p_test1', start_date => '', ---立刻执行 repeat_interval => 'FREQ=DAILY;INTERVAL=2', enabled => TRUE, comments => 'My new job'); END; --根据program和scheduler创建job BEGIN dbms_scheduler.create_job(job_name => 'myjob', program_name => 'myprogram', schedule_name => 'myscheduler'); END;
(1)run_job BEGIN dbms_scheduler.run_job(job_name => 'myjob2'); END;
(2)stop_job BEGIN dbms_scheduler.stop_job(job_name => 'myjob');END;
select * from user_scheduler_jobs where state='RUNNING'; ---查询正在运行的jobs
exec dbms_scheduler.stop_job('上面查询到的job名',force => true); ---强制删除
(3)copy_job BEGIN dbms_scheduler.copy_job(old_job =>'myjob' ,new_job =>'myjob2' );END; (4)drop_job BEGIN dbms_scheduler.drop_job(job_name => 'myjob');END;
SELECT 'EXEC DBMS_SCHEDULER.DROP_JOB(''' || JOB_NAME || ''',TRUE);' FROM USER_SCHEDULER_JOBS T1; ---批量删除jobs
(5)enable_job(默认时false)
exec dbms_scheduler.enable_job(job_name => 'myjob');END;
---查询用户jobs
col job_action for a10
col job_name for a20
col repeat_interval for a20
SELECT job_name,job_type,job_action,to_char(start_date, 'yyyy-mm-dd hh24:mi:ss'),repeat_interval,enabled,state FROM user_scheduler_jobs where job_name like '';
---正在运行执行日志
SELECT JRD.LOG_ID,
JRD.JOB_NAME,
N.JOB_CLASS,
--TO_CHAR(JRD.ACTUAL_START_DATE, 'YYYY-MM-DD HH24:MI:SS') ACTUAL_START_DATE,
TO_CHAR(JRD.LOG_DATE, 'YYYY-MM-DD HH24:MI:SS') LOG_DATE,
JRD.STATUS,
JRD.ERROR#,
JRD.RUN_DURATION 运行时长,
JRD.ADDITIONAL_INFO
FROM DBA_SCHEDULER_JOB_LOG N, DBA_SCHEDULER_JOB_RUN_DETAILS JRD
WHERE N.LOG_ID = JRD.LOG_ID
AND N.JOB_NAME = 'JOB_INSERT_SQL_LHR' --JOB的名称
ORDER BY JRD.LOG_ID DESC;
---已经运行的日志
select j.job_name,j.state,j.job_type,j.job_action,j.schedule_type,j.repeat_interval,j.start_date,rj.session_id,rj.running_instance,rj.cpu_used,(SYSDATE - j.start_date) 已运行时间 FROM dba_scheduler_jobs j,dba_scheduler_running_jobs rj WHERE j.job_name = rj.job_name AND j.job_name = 'JB';
区分 jobs 是用户创建,还是数据库自动创建,可以通过dba_SCHEDULER_JOBS 视图的 SYSTEM 列来确定,如果该列显示为 TRUE ,则表示由系统创建
5.2.6 窗口windows
通过WINDOW设置在此期间,允许jobs使用更多的系统资源,而到了工作时间后,如果job仍未执行完成,为其分配另一个有限的资源,以尽可能降低job执行占用的资源对其它业务的影响。
resource_plan:资源计划,即通过 dbms_resource_manager.create_plan来创建。
schedule_name:调度名称,基于已经创建好的调度创建window。
duration: 时间窗口打开后持续的时间,创建时必须设置该值,因为没有默认值,设置范围从1分钟到99天。
window_priority:window优先级,如果同一时间出现多个window时则根据优先级决定执行哪个。
--创建一个基于调度的window
BEGIN
dbms_scheduler.create_window(window_name =>,
resource_plan =>,
schedule_name =>,
duration =>,
window_priority =>,
comments =>);
END;
---视图
SELECT * FROM dba_scheduler_window_details;
SELECT * FROM dba_scheduler_window_groups;
select * FROM dba_scheduler_window_log;
select * FROM dba_scheduler_windows;
6、PL/SQL工具管理jobs

在10g和11gR1中,将JOB_QUEUE_PROCESSES设置为0只会导致DBMS_JOB作业无法运行,但DBMS_SCHEDULER作业未受影响且仍将运行。
从11gR2开始,将JOB_QUEUE_PROCESSES设置为0会导致DBMS_SCHEDULER和DBMS_JOB作业都无法运行。
oracle 11g中默认的自动维护任务分三类:
---select * from DBA_AUTOTASK_CLIENT; ---查询
Automatic Optimizer Statistics Collection(自动优化器统计信息收集)
Automatic Segment Advisor(自动段指导)
Automatic SQL Tuning Advisor(自动 SQL 优化指导)
要为所有窗口启用或禁用所有自动维护任务,请在不带参数的情况下调用ENABLE或DISABLE过程:
---禁用
EXECUTE DBMS_AUTO_TASK_ADMIN.DISABLE;
---启用
EXECUTE DBMS_AUTO_TASK_ADMIN.DISABLE;
---结果
select * from DBA_AUTOTASK_WINDOW_CLIENTS;
禁用、启用特定的维护窗口:
BEGIN
dbms_auto_task_admin.disable(
client_name => 'sql tuning advisor',
operation => NULL,
window_name => NULL);
END;
/
BEGIN
dbms_auto_task_admin.enable(
client_name => 'sql tuning advisor',
operation => NULL,
window_name => MONDAY_WINDOW);
END;
/
默认使用DEFAULT_MAINTENANCE_PLAN资源计划:
select window_name, resource_plan from dba_scheduler_windows;
修改自动任务的运行时间开始于23点,持续时间60分钟:
exec dbms_scheduler.disable( name => ‘MONDAY_WINDOW’, force => TRUE);
exec dbms_scheduler.set_attribute( name => ‘MONDAY_WINDOW’, attribute => ‘repeat_interval’,value => ‘freq=daily;byday=MON;byhour=23;byminute=0;bysecond=0’);
exec dbms_scheduler.set_attribute( name => ‘MONDAY_WINDOW’, attribute => ‘DURATION’,value => numtodsinterval(60,'minute')));
exec dbms_scheduler.enable( name => ‘MONDAY_WINDOW’);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号