

第一次个人编程作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience |
|---|---|
| GitHub地址 | https://github.com/fc0822/fc/tree/main/3123004226 |
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience/homework/13477 |
| 这个作业的目标 | 完成个人项目,实现查重功能 |
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 20 | 30 |
| Development | 开发 | ||
| · Analysis | · 需求分析(包括学习新技术) | 30 | 45 |
| · Design Spec | · 生成设计文档 | 25 | 35 |
| · Design Review | · 设计复审 | 15 | 20 |
| · Coding Standard | · 代码规范(为目前的开发制定合适的规范) | 10 | 15 |
| · Design | · 具体设计 | 35 | 40 |
| · Coding | · 具体编码 | 90 | 130 |
| · Code Review | · 代码复审 | 25 | 35 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 45 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 15 | 25 |
| · Size Measurement | · 计算工作量 | 10 | 15 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 15 | 15 |
| · 合计 | 300 | 450 |
二、模块结构分析
核心功能与实现逻辑
- 文本读取:通过
readFile方法读取文件内容,使用UTF-8编码确保中文正确处理 - 文本预处理:标准化文本格式,包括转换小写、去除标点符号等
- 分词处理:分别实现中英文分词逻辑
- 相似度计算:基于词频向量的余弦相似度算法
- 结果输出:将相似度结果以百分比形式写入指定文件
代码结构分析
1. 文本预处理模块
preprocessText方法负责文本清洗:- 将文本转为小写,实现大小写不敏感比较
- 使用正则表达式
PUNCTUATION_PATTERN去除所有标点符号 - 合并多个空格为一个,统一文本格式
2. 分词模块
-
segmentText:根据文本是否包含中文自动选择分词策略 -
segmentChinese:中文分词(简单实现为单字分词) -
segmentEnglish:英文分词(按空格分割)注意:当前中文分词是简单实现,实际应用中建议替换为专业分词库如IKAnalyzer,以获得更准确的词语分割结果。
3. 相似度计算模块
实现了余弦相似度算法:
- 计算两篇文本的词频映射(
getFrequencyMap) - 构建包含所有独特词的集合
- 计算两个词频向量的点积和模长
- 通过公式
点积/(模长1×模长2)计算余弦相似度
4. 文件操作模块
readFile:读取指定路径文件内容writeResult:将相似度结果格式化(保留两位小数的百分比)后写入文件
5. 主程序入口
- 验证命令行参数格式(需要3个参数:原文路径、抄袭文路径、结果路径)
- 调用各模块完成整个查重流程
- 异常处理:捕获并处理文件操作可能出现的IO异常
优点与特点
- 多语言支持:同时支持中文和英文文本的相似度检测
- 编码处理:明确使用UTF-8编码,确保中文等多语言文本正确处理
- 异常处理:包含基本的错误处理和参数验证
- 可扩展性:分词模块设计为独立方法,便于替换为更专业的分词实现
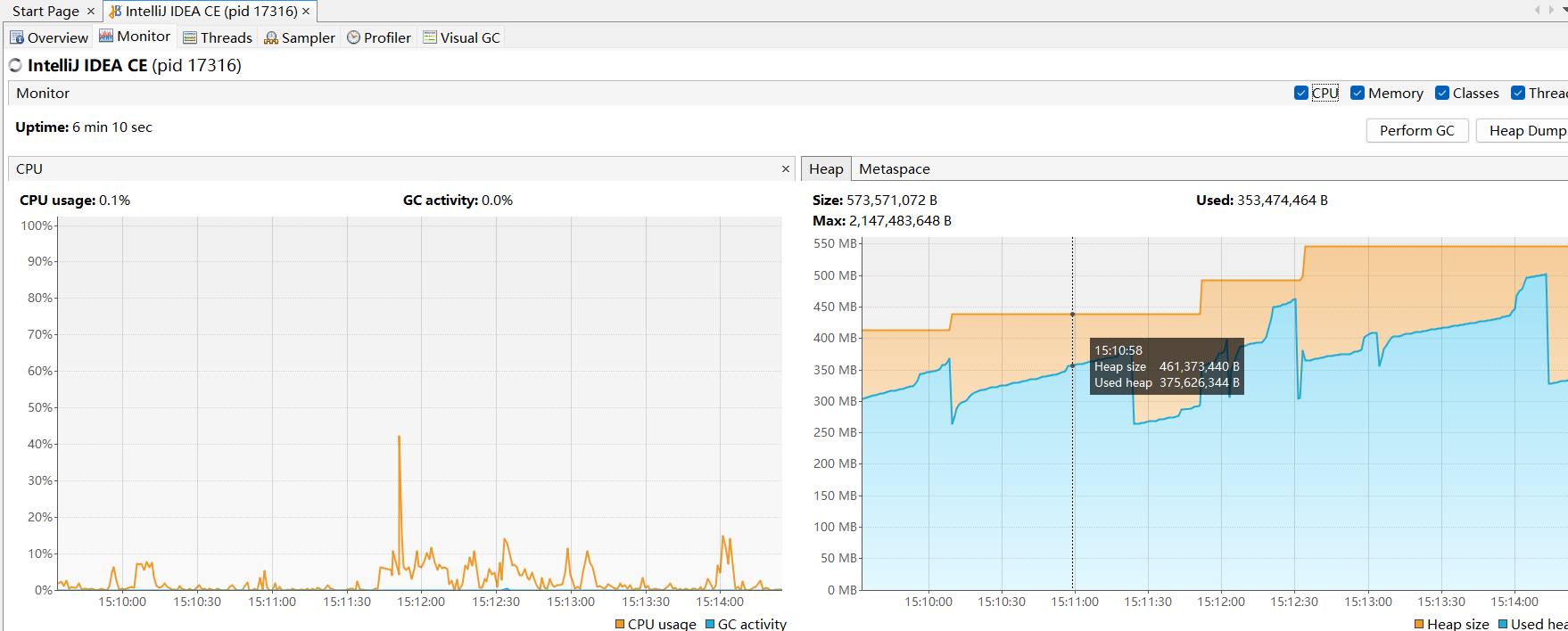
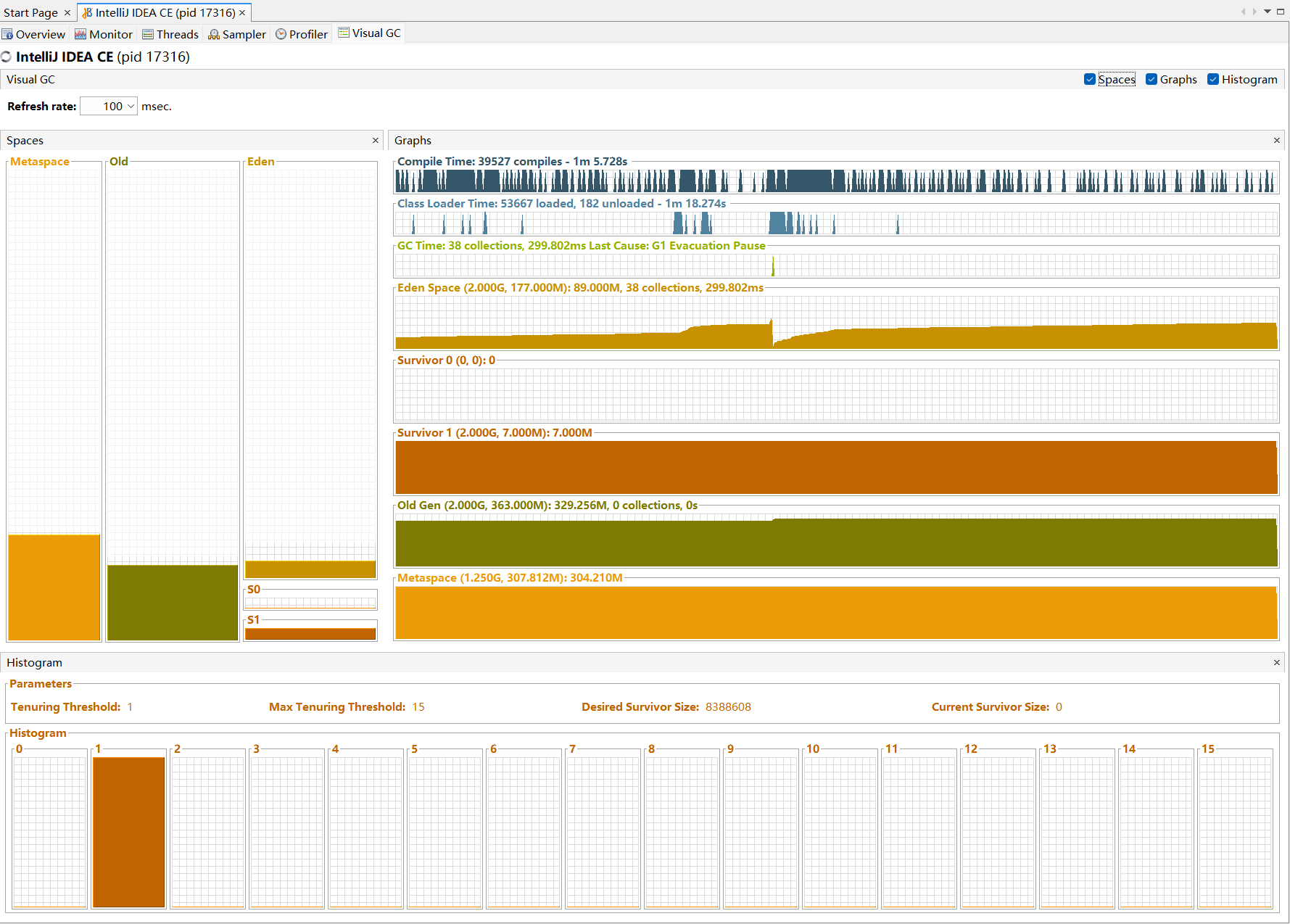
性能分析
三、关系图分析
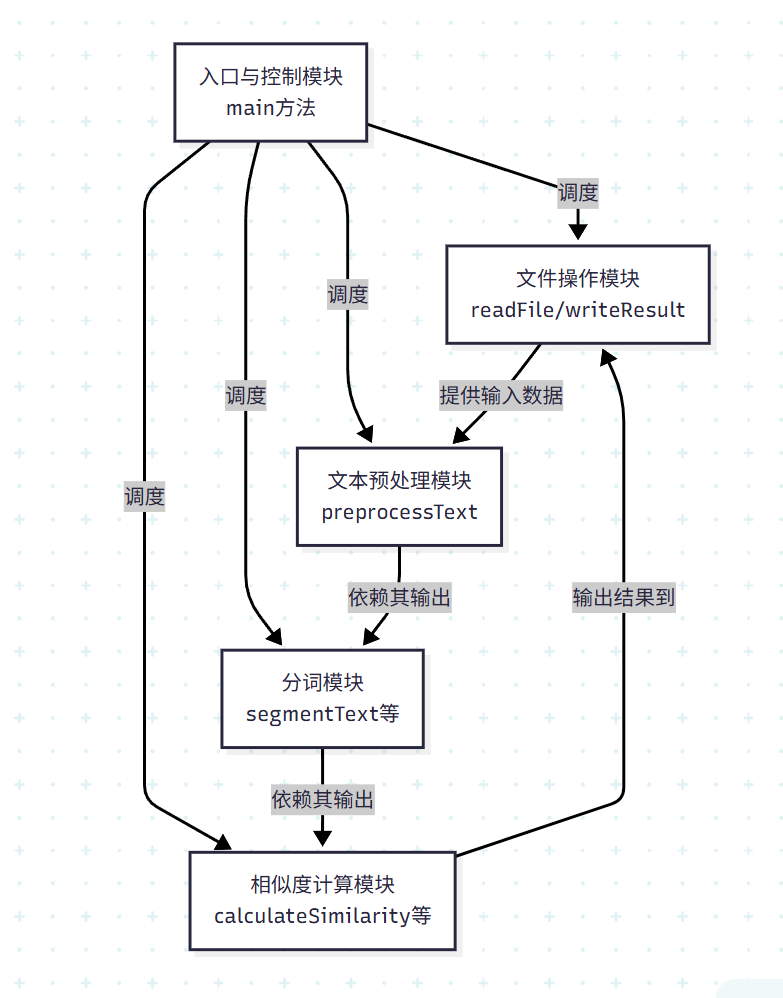
一、模块关系图(组件关联)
5个核心模块,模块间通过“调用”或“数据传递”形成依赖关系,具体如下:
| 核心模块 | 包含的关键方法 | 主要功能 | 依赖的其他模块 |
|---|---|---|---|
| 1. 入口与控制模块 | main |
参数验证、流程调度、异常捕获 | 所有其他模块 |
| 2. 文件操作模块 | readFile、writeResult |
读取文本文件、写入相似度结果 | 无(基础工具模块) |
| 3. 文本预处理模块 | preprocessText |
文本小写化、去标点、合并空格 | 无(基础工具模块) |
| 4. 分词模块 | segmentText、segmentChinese、segmentEnglish |
自动选择分词策略、中英文分词 | 文本预处理模块(依赖预处理后的文本) |
| 5. 相似度计算模块 | calculateSimilarity、getFrequencyMap |
词频统计、余弦相似度计算 | 分词模块(依赖分词结果) |
模块关系可视化
二、数据流程图(核心逻辑链路)
以“输入文件 → 输出相似度结果”为核心,数据在各模块间的流转过程如下,关键节点已标注数据格式:
-
输入阶段
- 触发:
main方法接收命令行参数(原文路径、抄袭文路径、结果路径) - 执行:调用
readFile读取文件,返回String类型的文本内容(如原文内容origContent、抄袭文内容copyContent)
- 触发:
-
预处理阶段
- 输入:原始文本
String - 执行:
preprocessText处理文本,输出标准化文本(小写、无标点、单空格分隔,如“hello world”)
- 输入:原始文本
-
分词阶段
- 输入:标准化文本
String - 执行:
segmentText判断文本语言(含中文则调用segmentChinese,否则调用segmentEnglish)- 输出:
List<String>类型的分词结果(中文为单字列表,如["我","爱","编","程"];英文为单词列表,如["hello","world"])
- 输入:标准化文本
-
相似度计算阶段
- 输入:两篇文本的分词结果
List<String> - 执行:
getFrequencyMap将分词列表转为Map<String, Integer>(词频映射,如{"我":1,"爱":1})- 构建“所有独特词集合”,计算词频向量的点积和模长
- 用余弦公式计算相似度,返回
double类型结果(如0.85表示85%相似)
- 输入:两篇文本的分词结果
-
输出阶段
- 输入:
double类型的相似度结果 - 执行:
writeResult将结果格式化为“百分比字符串”(如“85.00%”),写入指定路径的文件
- 输入:
数据流程可视化

四、测试代码分析
1. 测试目标
测试类围绕 Main 的主程序展开,验证其核心功能包括:
- 参数合法性校验
- 文件读取(支持UTF-8编码)
- 文本预处理(清洗、标准化)
- 分词(中英文处理)
- 余弦相似度计算
- 结果写入(百分比格式)
- 完整流程的正确性
2. 核心测试方法解析
(1)testParameterValidation:参数验证测试
- 测试场景:检查程序对命令行参数的合法性校验。
- 参数不足(2个参数,预期应为3个:原始文件、复制文件、结果文件)。
- 参数过多(4个参数)。
- 验证方式:捕获程序输出的错误信息,确认包含“参数错误!正确格式”提示。
(2)testReadFile:文件读取功能测试
- 测试场景:验证文件读取的正确性,尤其是UTF-8编码的支持。
- 创建含中英文、特殊字符的临时文件(内容:
测试UTF-8编码:Hello World! 123@#$%)。 - 调用
Main.readFile读取文件,验证读取内容与写入内容一致(含换行符)。
- 创建含中英文、特殊字符的临时文件(内容:
(3)testReadNonExistentFile:异常场景测试
- 测试场景:读取不存在的文件时,是否正确抛出
IOException。 - 验证方式:通过
@Test(expected = IOException.class)注解确认异常抛出。
(4)testTextPreprocessing:文本预处理测试
- 测试场景:验证文本清洗逻辑(标点符号、大小写、空白字符处理)。
- 标点符号:去除
, ! 。 ...等,英文转为小写(如Hello!→hello)。 - 空白字符:合并多个空格、制表符、换行符为单个空格(如
\tJava\nPython C++→java python c++)。
- 标点符号:去除
(5)testWordSegmentation:分词功能测试
- 测试场景:验证中英文分词逻辑(通过相似度计算间接验证)。
- 中文:按单字分词(如
我爱中国与我 爱 中 国相似度为1.0)。 - 英文:按空格分词(忽略多余空白,如
hello world与hello world相似度为1.0)。 - 混合文本:中英文分别按各自规则分词(如
Java编程与java 编 程相似度为1.0)。
- 中文:按单字分词(如
(6)testCalculateSimilarity:余弦相似度计算测试
- 测试场景:验证基于词频向量的余弦相似度计算逻辑。
- 完全相同文本:相似度为1.0。
- 完全不同文本:相似度为0.0。
- 部分相似文本:
- 中文示例:
我爱中国北京与我爱中国上海共享4个词,相似度约为0.6667。 - 英文示例:
a b c d e与a b c共享3个词,相似度约为0.7746。
- 中文示例:
- 边界情况:空文本与任何文本的相似度为0.0;标点和大小写不影响结果(如
Hello, World!与hello world相似度为1.0)。
(7)testWriteResult:结果写入功能测试
- 测试场景:验证相似度结果是否按百分比格式写入文件(保留两位小数)。
- 输入相似度
0.8567,验证写入内容为85.67%。
- 输入相似度
(8)testFullProcess:完整流程测试
- 测试场景:模拟真实使用场景,验证从文件读取、处理到结果输出的全流程。
- 创建原始文件和复制文件(内容高度相似,仅大小写和少数词不同)。
- 调用
Main.main执行完整逻辑,验证结果文件中相似度百分比>90%(符合预期)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号