
Python 之正则、Xpath 、BeautifulSoup
好久之前就研究过正则与Xpath ,一直也没做记录
今天记录下,以备随时查阅
上代码片段,抓取的是 豆瓣的TOP250 电影信息,网址为
https://movie.douban.com/top250?start=0&filter=
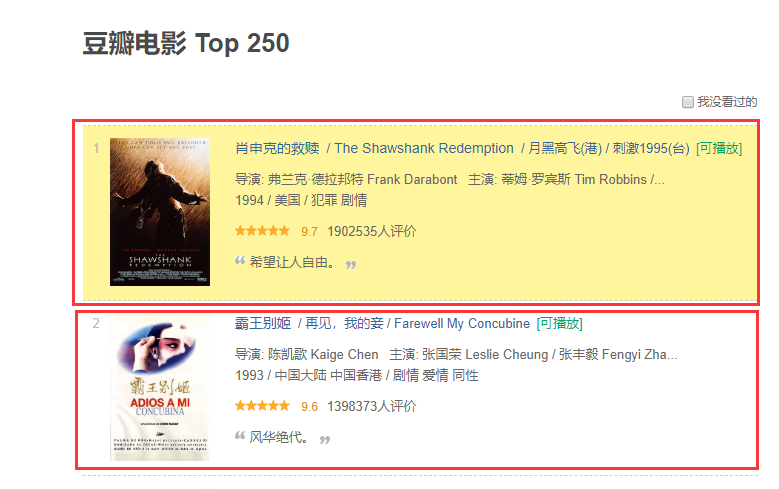
今天主要说一下一个问题,之前遇到的 当通过正则抓取这种豆瓣的TOP250 电影信息的时候,会遇到一种情况,网页的一些代码不太规范,举个例子
看图片

看出问题了吧。
如果抓取就 两次 <span class="title"> 和一次 <span class="other"> 就会漏掉 霸王别姬
如果抓取就 一次 <span class="title"> 和一次 <span class="other"> 就会只抓取 霸王别姬
所以通过正则或者Xpath 先分块,在抓取,就会按照顺序正常抓取到两个 或者一个 <span class="title"> 在抓取 <span class="other">
问题就解决了。
有朋友问我怎么分块,我上图就看懂了
上图,上图,这就是分块
后面上代码吧!不废话!
正则:
def spider(self,html):
pa_id = re.compile('<em class.*?>(.*?)</em>', re.S)
#抓取ID号(另一种写法)
pa_url = re.compile('<div.*?hd.*?href="(.*?)"', re.S)
#抓取RUL(正则标准写法)
pa_pic = re.compile('<img.*?100.*?src="(.*?)".*?', re.S)
#抓取封面图(正则标准写法)
pa_title=re.compile('<div class="hd">(.*?)</a>',re.S)
#抓取电影名(另一种写法,跟上面几个不一样)
#发现没,第一个和第四个,好简单,直接复制代码就能抓取,有点像Xpath 的抓取方式
print(re.findall(pa_title,html))
我这里是测试,如果想顺序输出,可以像其他人一样吧正则写在一起用(.*?)这种方式,
都放一起我看不太清楚,就拆分开了,像上面一样,不明白的可以看下面的全部源码,
Xpath:
def spider(self,html):
html1=etree.HTML(html)
li_list=html1.xpath("//ol[@class='grid_view']/li")
for i in li_list:
movies_title=i.xpath(".//span[@class='title']/text()")
movies_director1 = i.xpath(".//div[@class='bd']/p/text()")
str1=str(movies_director1).replace("\\n", "").split()
testobj.append((movies_title,str1))
print(testobj)
BeautifulSoup:
def spider(self, html):
html1 = BeautifulSoup(html,"lxml")
li_list = html1.find_all("div",class_="item")
for i in li_list:
title = str(i.find('div', class_='hd').get_text(strip=True)).replace("\xa0","")
movies_director1 =list(i.find('p',class_='').strings)[0].strip().replace('\xa0','')
testobj.append((title,movies_director1))
print(testobj)
通过BeautifulSoup 可以成段抓取text值
像 title = str(i.find('div', class_='hd')
把下面这段代码的所有text 全抓取了,
[可播放] 这个可以通过 replace("[可播放]","") 替换掉
<div class="hd"> <a href="https://movie.douban.com/subject/1292052/" class=""> <span class="title">肖申克的救赎</span> <span class="title"> / The Shawshank Redemption</span> <span class="other"> / 月黑高飞(港) / 刺激1995(台)</span> </a> <span class="playable">[可播放]</span> </div>
----------------------------分割线--------------------------------------------------
正则源码,250个可全部抓取
1 import requests,re 2 headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"} 3 testobj=[] 4 class douban(object): 5 def __init__(self): 6 pass 7 def get_url(self,url): 8 rer = requests.request("get", url, headers=headers) 9 if rer.status_code==200: 10 return rer.text 11 return None 12 def spider(self,html): 13 li_list=re.compile('<div class="item">(.*?)</p>.*?</div>.*?</div>.*?</div>.*?</li>',re.S) 14 # pa_content3=re.compile('<span class="title">(.*?)</span>.*?<span class="title">(.*?)</span>.*?"other">(.*?)</span>',re.S) 15 li_list1=re.findall(li_list, html) 16 17 for i in li_list1: 18 title_i=re.compile('<span class="title">(.*?)</span>',re.S) 19 content_i = re.compile('<span class="other">(.*?)</span>', re.S) 20 title = str(re.findall(title_i, i)).strip().replace(' / ','') 21 content=str(re.findall(content_i,i)).strip().replace(' / ','') 22 testobj.append((title,content)) 23 24 print(testobj) 25 def url(self,num): 26 url = f"https://movie.douban.com/top250?start={num}&filter=" 27 return url 28 29 if __name__ == '__main__': 30 douban = douban() 31 for i in range(10): 32 url=douban.url(i) 33 html=douban.get_url(url) 34 douban.spider(html)
Xpath源码,250个可全部抓取
1 from lxml import etree 2 import requests 3 headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"} 4 testobj=[] 5 class douban(object): 6 def __init__(self): 7 pass 8 def get_url(self,url): 9 rer = requests.request("get", url, headers=headers) 10 if rer.status_code==200: 11 return rer.text 12 return None 13 def spider(self,html): 14 html1=etree.HTML(html) 15 li_list=html1.xpath("//ol[@class='grid_view']/li") 16 for i in li_list: 17 movies_title=i.xpath(".//span[@class='title']/text()") 18 movies_director1 = i.xpath(".//div[@class='bd']/p/text()") 19 str1=str(movies_director1).replace("\\n", "").split() 20 testobj.append((movies_title,str1)) 21 print(testobj) 22 23 def url(self,num): 24 url = f"https://movie.douban.com/top250?start={num}&filter=" 25 return url 26 27 if __name__ == '__main__': 28 douban = douban() 29 for i in range(10): 30 url=douban.url(i) 31 html=douban.get_url(url) 32 douban.spider(html)
BeautifulSoup源码,250个可全部抓取
from bs4 import BeautifulSoup import requests headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"} testobj = [] class douban(object): def get_url(self, url): rer = requests.request("get", url, headers=headers) if rer.status_code == 200: return rer.text return None def spider(self, html): html1 = BeautifulSoup(html,"lxml") li_list = html1.find_all("div",class_="item") for i in li_list: title = str(i.find('div', class_='hd').get_text(strip=True)).replace("\xa0","") movies_director1 =list(i.find('p',class_='').strings)[0].strip().replace('\xa0','') testobj.append((title,movies_director1)) print(testobj) def url(self, num): url = f"https://movie.douban.com/top250?start={num}&filter=" return url if __name__ == '__main__': douban = douban() for i in range(10): url = douban.url(i) html = douban.get_url(url) douban.spider(html)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号