Unicode字符集和UTF-8, UTF-16, UTF-32编码
2018-03-09 23:40 faunjoe88 阅读(1510) 评论(0) 收藏 举报ASCII
在过去的计算中,ASCII码被用来表示字符。英语只有26个字母和其他一些特殊字符和符号。
下表提供了ASCII字符及其相应的十进制和十六进制值。
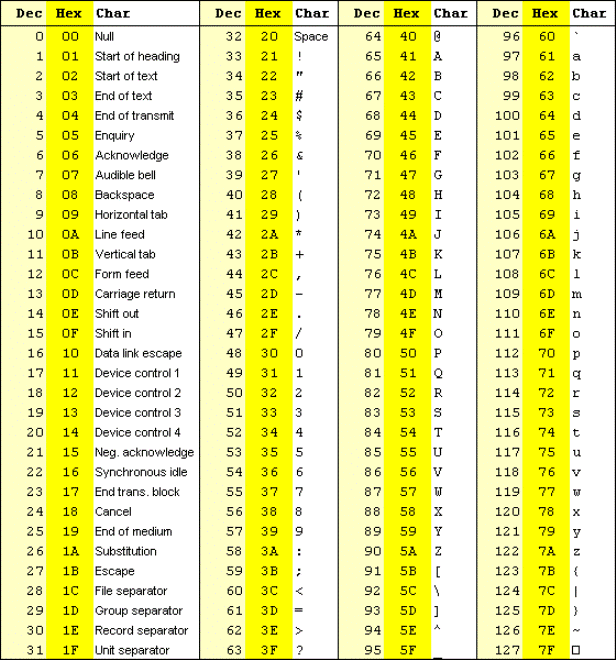
可以从上面的表中推断,在十进制数系统中,ASCII值可以表示为0到127。
让我们看一下0和127的二进制表示形式,在8位字节中。
0表示为
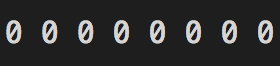
127表示为

可以从上面的二进制表示中推断出,0到127的十进制值可以用7位表示,而不是8位。
这就是事情开始变得混乱的地方。
人们想出了不同的方法来使用剩下的8位,它代表了从128到255的十进制值,并且开始发生碰撞。
例如使用的十进制值182在越南代表越南字母ờ而相同的值182被印第安人代表印地语字母घ。
如果电子邮件写的一个印度包含字母表घ如果是阅读一个人在越南似乎ờ。不打算出现的方法。
这就是Unicode字符集来保存这一天的地方。
Unicode和代码点
Unicode字符集将世界上的每个字符映射到一个唯一的数字。这确保了不同语言的字母表之间没有冲突。这些数字是平台无关的。
这些独特的数字被称为unicode术语中的代码点。
让我们看看它们是如何被引用的。
拉丁字符ṍ被称为使用代码点
U+1E4D
U +表示unicode和1 e4d十六进制值分配给角色ṍ
英文字母A被表示为U+0041。
请访问http://www.unicode.org/charts/了解代码点对所有语言和世界的字母
utf - 8编码
现在我们知道了什么是unicode,以及如何将世界上的每个字母表分配给一个惟一的代码点,我们需要一种方法来表示计算机内存中的这些代码点。这就是角色编码进入画面的地方。一个这样的编码方案是UTF-8。
UTF-8编码是一种可变大小的编码方案,用于表示内存中的unicode代码点。可变大小的编码意味着代码点使用1、2、3或4字节表示,这取决于它们的大小。
utf - 8 1字节编码
一个1字节的编码是通过在第一个比特中出现0来确定的。
![]()
英文字母A有unicode码点U+0041。它的二进制表示是1000001。
A用UTF-8编码表示。
![]()
红色0位表示使用1字节编码,其余的位表示代码点。
utf - 8 2字节编码
带有代码点U+00F1的拉丁字母n有二进制值11110001。这个值大于使用1字节编码格式表示的最大值,因此这个字母表将使用UTF-8 2字节编码表示。
2字节编码是由位序列110在第1位和第10位在第2位中出现。
![]()
unicode代码点U+00F1的二进制值为1111 0001。将这些位填充到2字节编码格式中,我们得到了如下所示的UTF-8 2字节编码表示。
填充是先从最不重要的代码点开始,然后将其映射到第二个字节中最不重要的部分。
![]()
蓝色11110001中的二进制数字表示代码点U+00F1的二进制值,红色的是2字节编码标识符。黑颜色的零被用来填充字节中的空比特。
utf - 8 3字节编码
ṍ的拉丁字符的代码点U + 1 e4d表示使用3字节编码是大于最大值,可以使用2字节编码表示。
一个3字节的编码是通过在第一个字节中出现的位序列1110和第二个和第三个字节中的10来标识的。
![]()
十六进制代码点0x1E4D的二进制值是1111001001101。填充这些位在上面的编码格式给我们的utf - 8 3字节编码表示ṍ显示如下。
开始填充的时候,最不重要的代码点映射到第三个字节中最不重要的部分。
![]()
红色位表示3字节编码,黑色表示填充位,蓝色表示代码点。
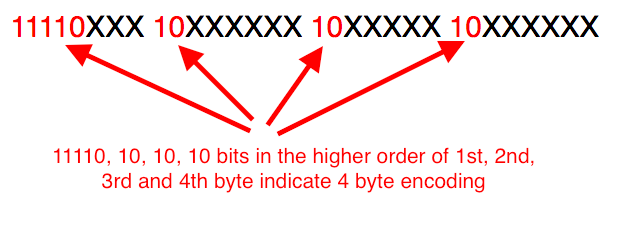
utf - 8 4字节编码
的Emoji😭U+1F62D. unicode代码点这比使用3字节编码表示的最大值要大,因此将用4字节编码表示。
4字节编码通过在第一个字节中出现11110,在随后的第二、第三和第四字节中识别。
![]()
U+1F62D的二进制表示是11111011000101101。
填充这些位在上面的编码格式给我们😭.的utf - 8 4字节编码代码点最不重要的部分被映射到第四个字节的最不重要的位,以此类推。
![]()
红色位表示4字节编码格式,蓝色的是实际的代码点,黑色的是填充位。
utf - 16编码
UTF-16编码是一种可变字节编码方案,它使用2字节或4字节来表示unicode编码点。所有现代语言的大多数字符都用2个字节表示。
用UTF-16编码表示的拉丁字母n与代码点U+00F1和二进制值11110001。
![]()
上面的表示是在大的Endian字节顺序模式(最重要的一点)。
utf - 32编码
UTF-32编码是一个固定的字节编码方案,它使用4个字节来表示所有的代码点。
英文字母A有unicode码点U+0041。它的二进制表示是1000001。
它以UTF-32编码表示,如下所示,
![]()
蓝色位是代码点的二进制表示形式。以上假定为大的Endian字节顺序模式。

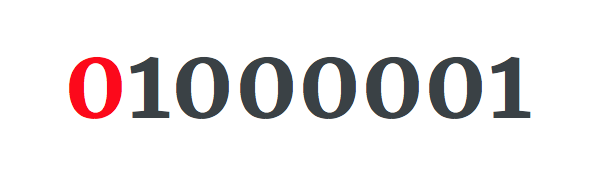


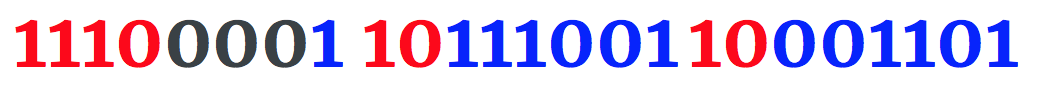

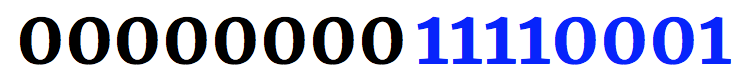
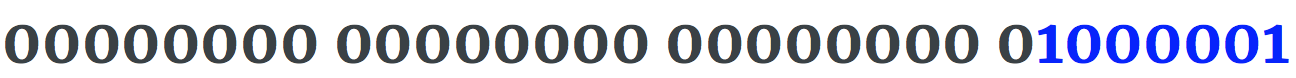

 浙公网安备 33010602011771号
浙公网安备 33010602011771号