

Excel与SQL之间的数据导入和导出(unfinished)
一、数据从Excel导入到SQL
我们要导入的Excels数据源如下图所示:
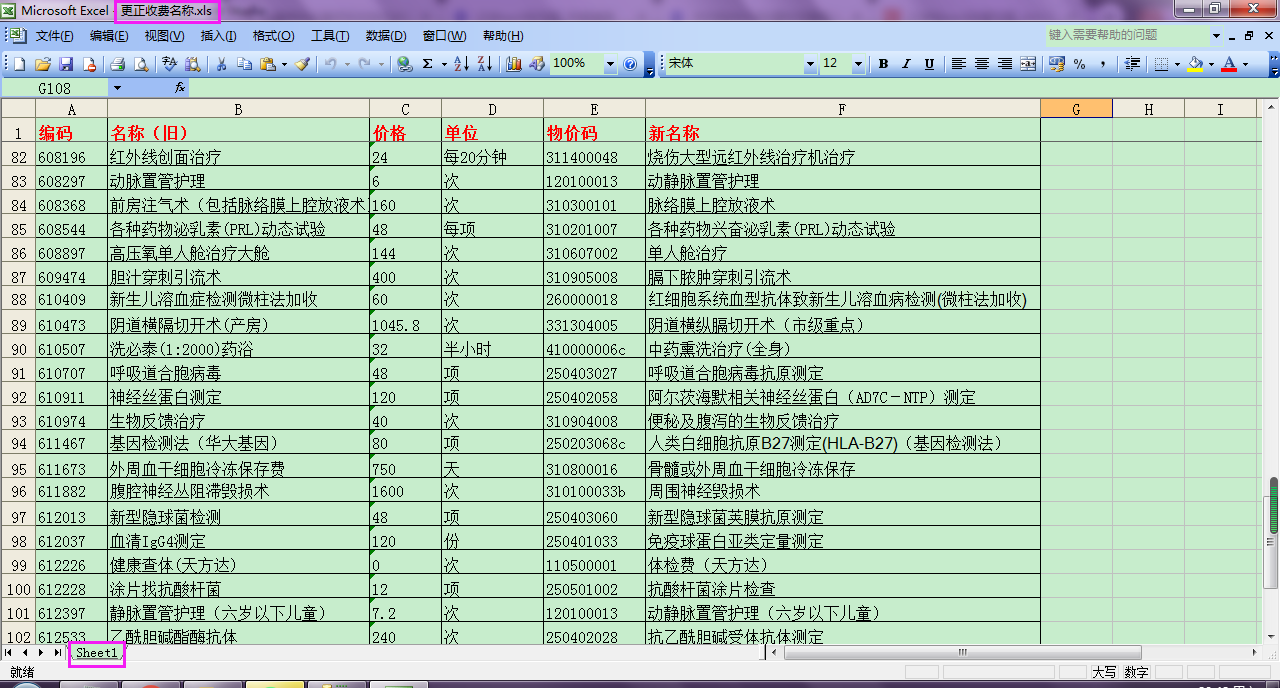
这个Excel数据源的文件名叫【更正收费名称】,工作表的名字叫做【Sheet1】,我们知道文件名和工作表的名字,在Excel中均可以更改。
在Excel文件工作表中,有两列【编码】和【物价码】数字,【编码】都是数字,但是,【物价码】却不全是数字。
比如,Excel文件工作表的第90行数据,编码 = '610507' 的这行数据,对应的【物价码】= '410000006c'。
导入到SQL表中,会是什么景象呢?我们先搁置一下这个问题,先把数据导进去,看看结果如何。
下面,我们将其导入到SQL中,导入步骤如下:
1.先在SQL中创建一个名为a_ExcelToSql的数据库(数据库名自拟,本文为叙述方便取名a_ExcelToSql);
创建数据库的语句为: 1 create database a_ExcelToSql
2.右键单击数据库a_ExcelToSql,依次选择【任务】、【导入数据】
3.弹出下图所示对话框,单击【下一步】
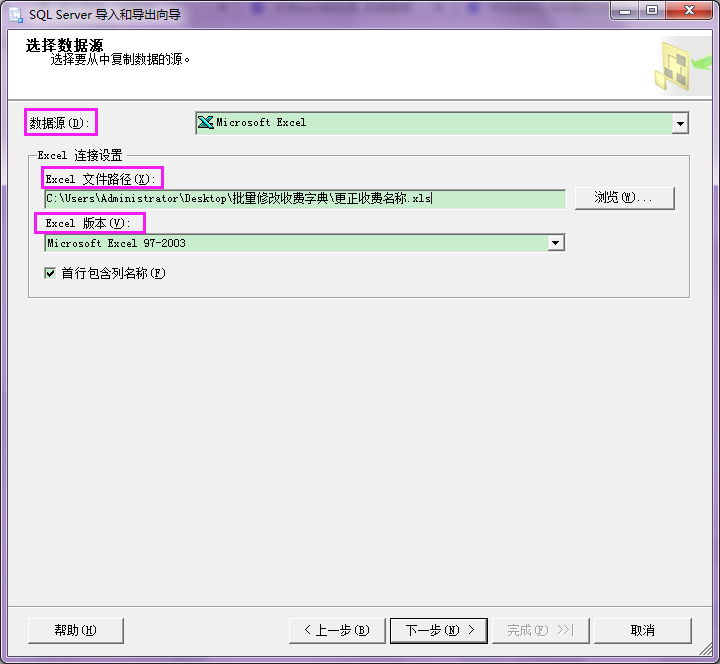
4.弹出如下对话框中,数据源(D)选择【Microsoft Excel】、Excel文件路径根据文件存放位置选择、Excel版本根据电脑配置的版本选择。
这个首行包含列名称,勾选后,最后导入数据库的数据表的列名称就是Excel文件工作表中的列名称(共6列);
如果不勾选,列名称就以 F1、F2、F3、F4、F5、F6标注。所以,我们勾选,然后点击【下一步】。
5.弹出下图所示对话框,目标(D)选择【Microsoft OLE DB Probider for SQL Server】,其他字段根据实际情况选择。
然后点击【下一步】。
6.弹出下图所示对话框,选择【复制一个或多个表或视图的数据】,点击【下一步】。
7.弹出下图所示对话框,其中,【源】下面的名称【Sheet1$】,就是Excel文件工作表的名字。
【目标】下面的【dbo.[Sheet1$]】就是数据导入SQL后的表名。
这个表名,根据Excel文件工作表名字自动生成,跟Excel文件工作表名字一样,在此处可以自定义修改。
修改方法:
假如,我们将表命名为zd_charge_item_20220527,
可以直接将【目标】下面的 [dbo].[Sheet1$] 替换为zd_charge_item_20220527,
也可以只将Sheet1$替换为zd_charge_item_20220527。替换完成后,点击【下一步】
8.弹出下图对话框,继续单击【下一步】
9.弹出下图所示对话框,点击【完成】
10.弹出下图所示对话框,导入成功,点击【关闭】。
好了,至此,我们回头再来验证下开头那个搁置的问题。
查询语句: 1 select * from zd_charge_item_20220527
查询结果:
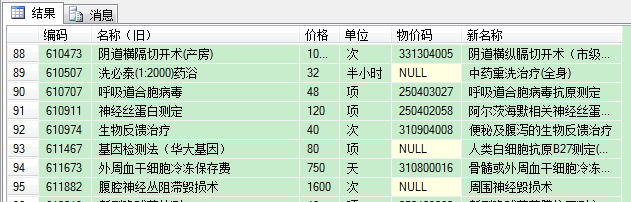
我们看到,原Excel文件工作表第90行(SQL是第89行,因为Excel中第一行在SQL中成了列名)、编码 = '610507'的数据的物价码成了NULL。
而且,不光这一行,凡是Excel文件工作表中物价码是【数字+字母】的,导入到SQL后,都成了NULL空值。
空值造成导入的数据跟源数据不一致,肯定不行。
问题的原因是什么呢?
查看SQL中zd_charge_item_20220527的列属性,发现【编码】和【物价码】这两列是数据类型是float(如下图所示),其它4列是NVARCHAR类型。
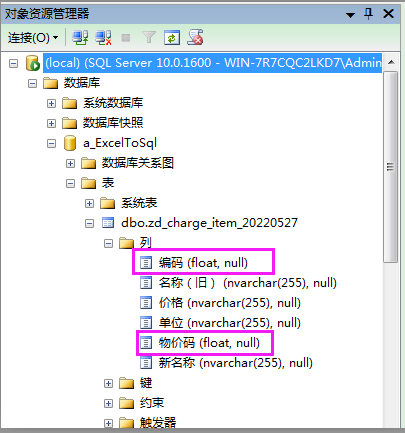
看来是SQL认为包含字母的那些物价码无法转换成数字,所以是无效的数据,从而采用NULL来代替。
对于这个问题的解释,我搜集到下面一段描述:
“通过查询微软网站,发现MS大意如是说:SQL在导入Excel混合数据列的时候,由于数据类型不唯一,导致SQL无法确定数据类型(看来SQL也有犯糊涂的时候)。SQL的应对之道就是统计该数据列的前8行数据中出现最多的类型,并以此类型做为默认类型。而在我的Excel文件中,“内部电话”列的前8行中的确要数纯数字格式的电话号码最多,所以SQL就把这列认为是float型的(为什么不是int型?不解)。至于此列其它格式的数据,SQL的办法是——直接扔了(汗一个。。)
MS原文:
……Excel 不会像关系数据库那样为 ADO 提供有关其数据的详细架构信息。因此,驱动程序必须至少扫描几行现有数据,才能有根据地猜测各列的数据类型。“要扫描的行数”的默认值为八 (8) 行。可以指定从一 (1) 行到十六 (16) 行的整数值,或指定零 (0),扫描所有现有行。这可通过向连接字符串添加可选的 MaxScanRows= 设置,或在 DSN 配置对话框中更改要扫描的行数设置来完成。
但是,由于 ODBC 驱动程序中存在一个错误,所以目前指定“要扫描的行数”(MaxScanRows) 设置不起作用。换句话说,Excel ODBC 驱动程序(MDAC 2.1 和更高版本)始终扫描指定数据源中的前 8 行,以确定各列的数据类型。”
问题的原因,基本捋清了(实际上没有百分百捋清),但是,该如何解决呢?
上述文章文末给出了答案。
“以Excel2007(Excel2003 也一样)操作(下文将此步骤简称分列处理):
1、选择想要转换的单元格,设置属性为文本格式(此步骤可忽略,不过建议操作一次)
2、用Excel选择一列数字(好像只能是选择一列),选择数据--分列--下一步--下一步--选择文本--完成。”
即,对于本案例来说,先对Excel文件工作表中的【编码】和【物价码】两个数字列(准确地说是含有数字的列)进行分列处理。
然后再导入SQL,就没问题了。
我们验证一下。
1.先对Excel文件中的工作表【编码】和【物价码】两列进行分列处理,保存文件。
2.依次按照上述步骤再次将Excel文件工作表中数据导入到SQL中,这次将导入的数据表命名为zd_charge_item_20220527_b
执行查询: 1 select * from zd_charge_item_20220527_b
执行结果:
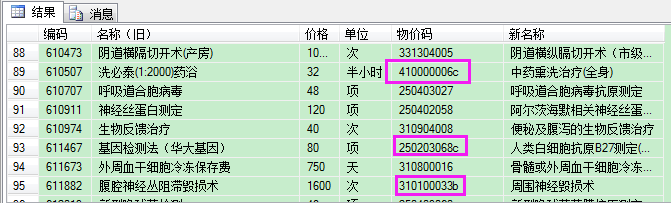
从结果可以看出,问题解决。我们再来看一下zd_charge_item_20220527_b表的列属性,并与zd_charge_item_20220527做下对比。
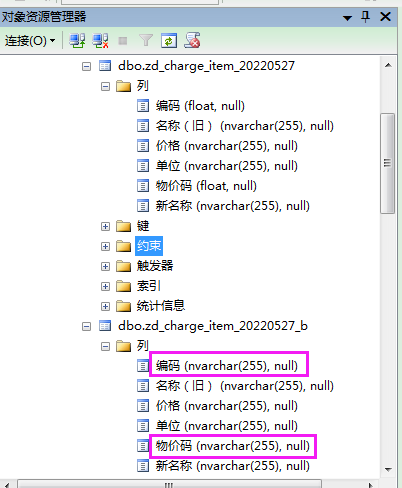
可以看出,在对Excel数据源文件进行分列处理后导入SQL后,原来数据类型是float的变为nvarchar类型了。
总结一下就是:在Excel往SQL导入数据时,对于数字列、(数字+其他字符)列,先进行分列处理,再行导入。
二、数据从SQL导入到Excel

 浙公网安备 33010602011771号
浙公网安备 33010602011771号