为什么1个Token有时值一分钱,有时值一百块?

前段时间,同事跟我说,整了个龙虾提醒,用了几千万Token。我大为震撼,以为同事必然是一顿操作猛如虎,速速赶去围观。
结果一看,地铁老人手机.jpg
就这?几千万没了??
于是狠狠吐槽:这Token可真不值钱。

打脸来得太快。
最近,各家大模型厂商纷纷开始捂紧口袋,限购/限额了,涨价了,停止续费了。。。
短短几个月,已经到了高攀不起的程度。
“对不起,您的Token使用已达上限”——已经荣登用户最怕看到的提示语。(戒不掉,真的戒不掉

从大手大脚到抠抠搜搜,这说明啥?
用AI的人多了,算力这玩意紧张了,地主家也没有余粮了。
OpenAI的CFO Sarah Friar直白地说:“If you do not have compute, you do not have revenue.”
Anthropic近期签下了好几笔巨额算力协议,只有马斯克家的Colossus 1能迅速到位,算是解了燃眉之急,立马给用户狠狠“放了一波饭”。
那么问题来了:
- Compute算力与Token之间到底是什么关系?
- 一时不值钱,一时又值钱了,Token到底值多少钱?
站在企业/组织角度,咱们再寻思寻思:
- 企业或组织内部应该如何看待AI支出?
- 黄仁勋说以后大家要发Token作为薪酬福利了,那怎么定这个额度?
- Token到底算研发成本还是IT预算?
- Token消耗量这个指标能说明什么?等于生产力吗?(比如“骂AI”的Token怎么算?手动狗头.jpg
让我们回到最初,一切诞生的地方。
01、Token是如何诞生的?
首先,虽然ta的中文名叫“词元”(对这个名字我们持保留态度),但别被带偏了,ta并不是词,也不是字符,更不是数据。
Token只是一个计量单位,是人为定义出来的一种规则。
比如,Anthropic从Opus 4.6升级到Opus 4.7,换了新的Tokenizer,也就是分词器。
你猜怎么着?同样的输入,Token数量就原地增加到原来的1~1.35倍。
每一个Token的生成,本质都是一次计算过程;
是成千上万个GPU核心在电光火石间完成了一次极其复杂的矩阵运算;
是物理世界的一份能量(电能)经过算法磨砺后,变成了一个具有概率意义的数字序列。

在这个过程中,我们投入巨大的物理资源(电力、GPU硬件),经过复杂的计算过程,最终产出具有信息价值和潜在商业价值的“数字产品”(Token)。
如果把GPU集群理解为现代矿井,电力作为能源供应。
谁拥有了算力,等同于拥有了采矿权。
像老黄说的,数据中心的角色正在发生变化:过去TA是存储和计算中心,而未来将成为生产Token的AI工厂。
此处结论是:
Token不是凭空产生的,而是消耗真实资源“生产”出来的。
接下来,我们讨论下一个问题:
02、Token之间的“生而不平等”
知道了Token是怎么来的,现在我们来可以进一步了解Token世界的一个基本法则了。我们可以把Token理解为:AI世界的最小货币单位。
但是,这里有一个关键点:这个单位并不像“米”、“公斤”或者“千瓦时”那样,是通用的统一标准单位。不同厂商,不同模型,不同语言体系,不同模态,都叫Token,但并不相同。
- 厂商A token ≠ 厂商B token
- 模型A token ≠ 模型B token
- GPU token ≠ NPU token
- 文本 token ≠ 视频 token
- 语言A token ≠ 语言B token
如果把token比喻成货币,那么TA不是单一币种,而是一个多币种的“世界货币体系”。每一家大模型厂商都是发行方,甚至一家还能发行好几种。
币种之间是有不同“汇率”的,不同场景有不同的“购买力”。甚至同一币种在不同配置下,也可能存在不同的“购买力”。(比如Opus 4.6默认启用的“adaptive thinking”)

就像在现实世界里,我们去不同国家消费,就必须使用对应国家的货币:
- 中国用人民币
- 美国用美元
- 欧洲用欧元
- 日本用日元
在AI 世界里,也是一样的。不同大模型厂商都有自己的“计价单位”:Token。虽然各家并不统一,但是还是能起到计账的作用,可以支持定价。
当然,各家的账单体系已经从“单一token计费”演进为“以Token为基础、叠加多维因素”的结构,包括调用方式、缓存策略、多模态输入等,而不再只是简单的输入/输出Token线性计价,但本质还是Token*各种系数。
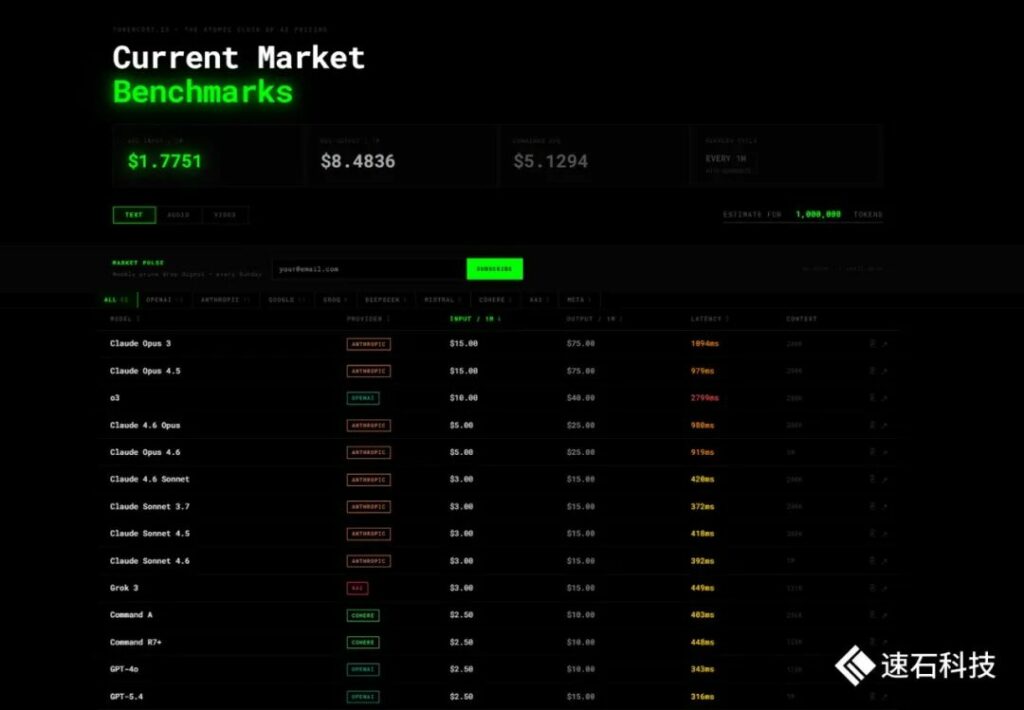
全球大模型小时级“牌价”,来自tokencost.is
要说Token跟货币体系不同的地方:
- AI世界“汇率”波动完全无法与全球外汇市场相比,后者可是毫秒级延迟的量化市场;
- 各家Token之间目前不能互相结算,还是得用真正的货币。当然,未来会不会出现某几家独大,一定程度上成为事实上的结算货币,这我们觉得很难说;
- 现代货币后面已经没有金本位,全靠国家信用托底。但Token后面是有真实的算力和电力作为支撑的;
- 一个国家一般也不会同时发行多种币种。
不同Token发行方的“生而不平等”,目前已经基本形成G2世界格局。用汽车行业来类比最是贴切。
“御三家”(OpenAI、Google DeepMind、Anthropic)的模型Token更像是AI界的“法拉利”,
追求极致性能,有品牌溢价在,深度绑定英伟达高端GPU,智力含金量目前公认最高。
贵有贵的道理,大家会用TA做一些棘手且高难度的事;
国内模型的Token像咱们的“新能源车”,主打一个“好用不贵”,以高配低价、智能座舱来打破传统豪车定价体系。
在长上下文、中文理解、应用落地、成本极低的推理服务等方面卷出了新高度,沿着“国产算力适配 + 模型自研”的道路稳步前进。

江山代有模型出,各领风骚几十天,甚至十几天。
AI世界风云变幻,谁都不能保证自己稳操胜券。
此处的结论是:Token是不等价的,只看数量,不看质量,毫无意义。
最后,我们来到终极问题:
03、Token的”币值”到底由什么来决定?
Token的币值不是简单地由单一因素决定,而是取决于三层联动模型的共同作用。这三层分别是:供给侧(底座)、转换侧(核心)和业务侧(顶层)
第一层:物理世界的供给侧——决定成本
这一层是站在Token诞生的视角来看待这个问题的,以生产一个Token的物理代价,也就是需要消耗的真实世界算力与电力资源作为支撑。
核心变量包括:芯片型号、电力、带宽、显存占用。
Token生产的单位成本,由两部分叠加在一起共同决定:
一部分是计算过程本身,包括能量消耗与设备折旧,也就是“跑一次Token要花多少钱”。
同样的算法,在不同硬件上的功耗和折旧,以及互联带宽导致的通讯时延,决定了Token的理论计算成本。
一部分来自资源占用,即模型对显存等资源的持续占用与锁定,也就是“同一时间能跑多少Token”。一个模型即便不生成内容,只要被加载,就会占用大量显存,从而减少系统可用的计算能力。
随着模型规模和上下文长度的增加,显存不再只是存储数据的地方,而是直接决定系统能同时服务多少请求。
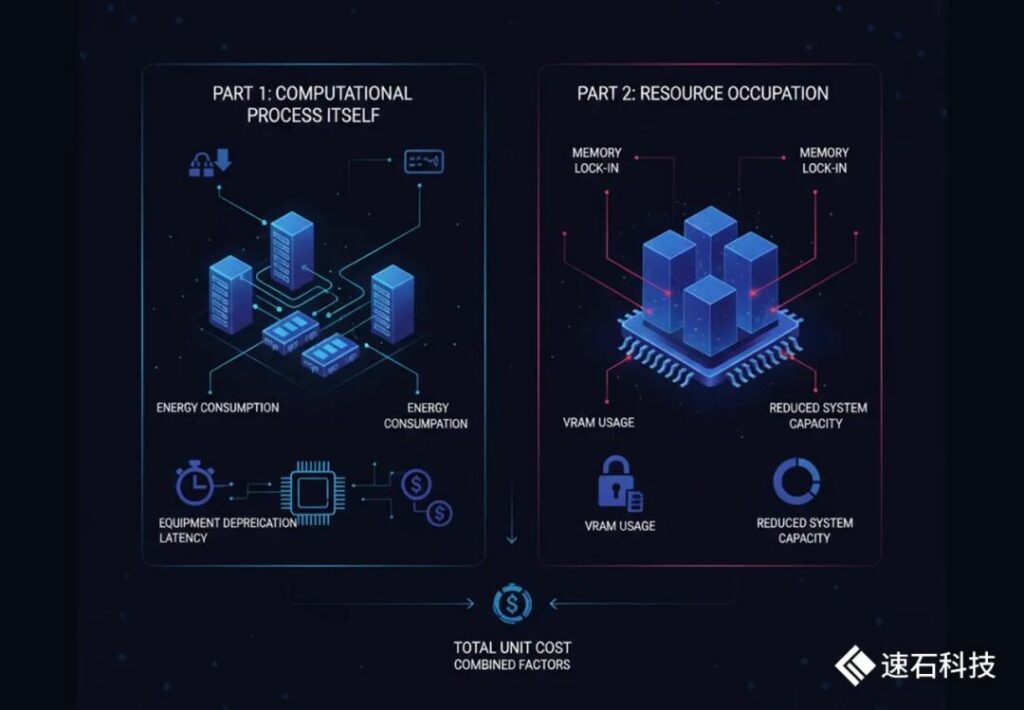
换句话说,显存不再是“辅助资源”,而是“产能本身”。
你猜HBM为什么猛猛涨价?
SK海力士年终奖人均600万震撼全球打工人。

期待已久的DeepSeek最新版V4的发布,开创了一种全新的CSA加HCA混合注意力机制,在Token维度进行压缩,在百万Token上下文处理场景下,将推理时的关键显存占用(KV Cache)降低了一个数量级,将推理计算量从“不可承受之重”拉回到“日常可跑的工作负载”。
再加上对国产厂商的“Day 0”适配,国产AI芯片从此可能拥有自己的一套体系。
让我们call back前面的类比:
法拉利并非“全面领先”,国产新能源也非“只是便宜”。
就像今天的国产新能源车在智能化、电动化上已经形成能力反超,而不仅仅是“够用”。国内大模型与海外头部模型,更像是“智能电轿”与“传统超跑”在两条交错赛道上的竞争。
把AI从“少数人的赛道利器”变成“多数人的通勤工具”,说不定还得看咱们。
第二层:计算过程的转换侧——决定定价
这一层是站在大模型厂商的视角来看待这个问题的,以大模型的智力密度作为支撑,是最复杂的中间过程。
换句话说,就是模型强不强,有多强。
核心变量包括:供应商能力差异、任务复杂度、模态权重、转换时长
这一部分主要解决两个问题:
- 单位算力里面凝结了多少智力?
- 为了得到结果,我们放弃了什么?
1. 模型的能力水平,决定了Token的“智力含金量”
而这种能力,通常由模型架构、训练质量、参数规模、推理能力等共同决定。
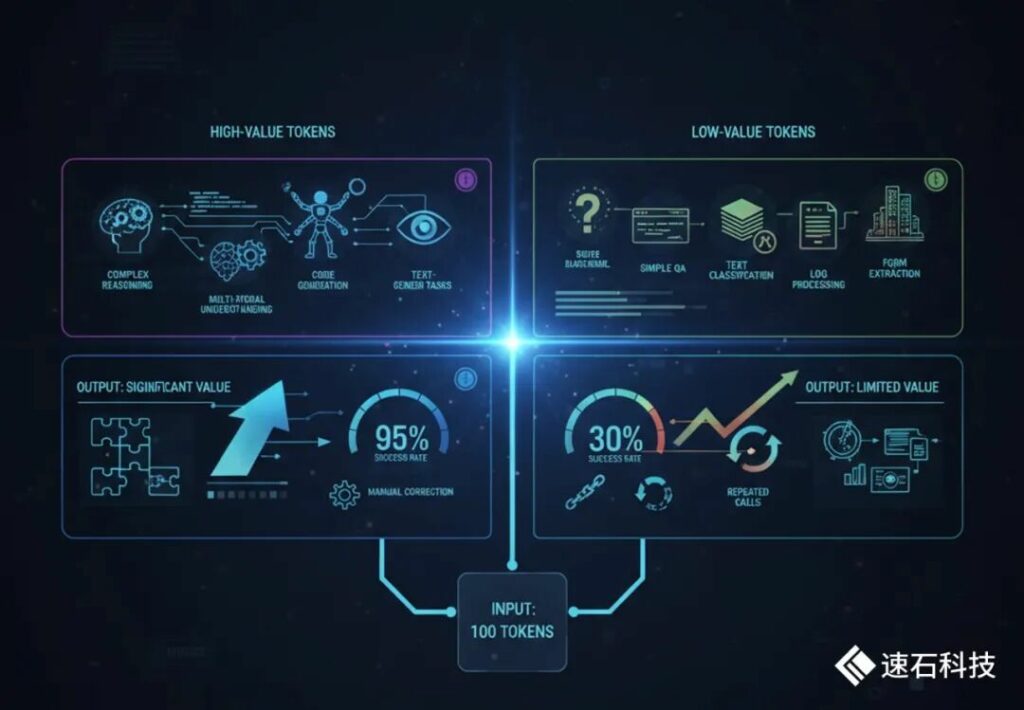
同样输出100个Token,不同模型之间的“有效价值”可能相差数十倍:
高币值Token:
在复杂任务中的“一次性成功率”更高,能够完成复杂推理、代码生成、多步骤Agent任务、多模态理解等高密度工作。
低币值Token:可能只能完成简单问答、文本分类、日志处理、表单提取等基础任务,需要更多补充Prompt、人工修正或重复调用。
总之,强模型能用更少Token、更少轮次、更少人工干预,完成更复杂任务。
2. 不同模态的Token之间存在天然的“汇率”差异
图片和视频Token背后对应的矩阵运算远比文本复杂,其转换效率通常呈指数级下降。单秒视频消耗的算力可能是数千张图片的叠加。
3. 推理时长是一个经常被忽视的隐性成本
模型响应越慢,背后占用的“算力时间”越长,机会成本也就越高。毕竟算了这个就不能算那个了,用户需要做出抉择。
如果更长的推理时间能够换来更强的复杂推理能力、更高的一次性成功率、更少的人工修正与重复调用,对于这种“更慢但更强”的模型,用户依然会愿意支付更高价格。
不同模型厂商的价格竞争策略,不在讨论之列。
第三层:业务世界的价值侧——决定需求
这一层是站在用户视角来看待这个问题,站在业务端看产出的商业价值。
前面两层对用户来说,几乎等于黑箱。
当然,用户可以选择对不合理价格用“脚”投票。
每个用户,不管是个人还是组织,都有自己的一套评价体系,但归根究底,是以业务结果作为最终导向。
核心变量包括:准确率、ROI(投资回报率)、结果时效
这套评价全系:
1. 不能只看成本,要追求产出最大化
只看成本,把Token当资源消耗,追求的唯一目标就是在某种特定结果下“怎么更便宜”,“怎么省钱”,可能会达成“明省实亏”成就。
Token更像“生产要素”,成本和结果不是可预测的线性关系,是可以有放大效应的,影响因素众多。而结果也不是固定的,能代替多少人类有效劳动还在不断进步和尝试的过程中。
这也是大家经常用“抽卡”来调侃的原因。

这时候,应该关注的不是“花了多少Token”,而是:
- 每一枚Token是否创造了产出
- 如何用有限资源换最大产出
同一个业务,使用的人不同,任务不同,模型不同,1000Token的产出可能天差地别。
2. 要关注浪费和系统风险
Token的大部分浪费是“不可见”的。
如果不对Token做使用分析、调用链拆解和成本归因,很难看出问题。

而如果出现某个Agent失控,或人为滥用,导致账单爆炸,这对用户,尤其是企业这种组织来说损失可能极大。
3. 要追求最优资源配置
现实里,不同模型能力是高度分化的,基本不存在“一个模型打天下”。
用户天然会需要使用多种大模型,来完成不同业务:代码开发、内容创作、前端设计、视频生成等等。
不同任务,都有不同的“性价比最优解”,可以说是丰俭由人。
相比个人,企业/组织需要考虑的问题更多,比如:
- 高价值任务,才配高币值Token
- 哪个模型在当前任务下性价比最高
- 内部资源如何在不同部门/用户间分配
- 紧急任务如何定优先级
- 本地资源如何定价
04、一千个哈姆雷特心中的Token
Token不是越贵越好。技术迭代优化就是让成本逐渐拉低,结果模型却越来越聪明。Token也不是越便宜越好,说了要看产出的嘛。
我们在上一篇Hello World~大家好,重新跟大家介绍一下速石科技里就写过了:在这个新时代,第一阶段比拼的是计算的技术水平,比如大模型、算法优化。第二阶段比拼的就是计算的成本和使用效率了。谁能从每一千瓦时电力中获取更多收益,谁可能就是赢家。
Token到底值多少钱?
这个问题没有标准答案,属于一千个哈姆雷特问题。
关键在于能不能拉到一起来比,用户心中有多少数。

企业或组织用户的需求,隐藏在Token的账单里,反映在生产任务一线的现实里,价格已经不是唯一变量。
速石围绕企业或组织的Token/大模型治理,有一个新产品FAAP-fastHub——速石token中枢,把多来源模型与本地资源变成可治理的组织能力。
下一期我们会认真介绍一下TA,敬请关注。
也欢迎扫码直接找我们聊聊~~

END
速石科技致力于成为
一家提供"端到端统一计算解决方案"的公司
半导体/智能制造/能源/新药研发/人工智能
说到计算,统统在我们碗里
而且自下而上全栈适配国产化生态系统
同时,打造高校新质生产力教学科研创新平台
以产业经验赋能高校教学与科研场景
培养实战型人才
扫码免费试用或预约专家1对1沟通~

更多电子书
欢迎扫码关注小F(ID:imfastone)获取

你也许想了解具体的落地场景:
企业级Vibe Coding实践:效率飙升500%——我们中招了一种新型“戒断反应”
如何用AlphaFold2,啪,一键预测100+蛋白质结构
只做Best in Class的必扬医药说:选择速石,是一条捷径
超大内存机器,让你的HFSS电磁仿真解放天性
从“地狱级开局”到全球首款液氧甲烷火箭,我们如何助力蓝箭冲破云霄
普冉半导体逐步布局自主可控,渐次提升研发效率
高校集成电路产教融合实训平台:
高校人才培养如何“化零为整”,对抗集成电路产业碎片化?
小学生算法:我国集成电路设计人才缺口到底有多大??
【案例】远离“纸上谈兵”,深职大打造国内首个EDA远程实训平台
我们的解决方案/产品:
内测邀请】集成电路设计的AI“外挂”?速石IT-CAD在线智能助手
今日上新——FCP
专有D区震撼上市,高性价比的稀缺大机型谁不爱?
从“单打独斗”到“同舟共集”,集群如何成为项目研发、IT和老板的最佳拍档?
国产调度器之光——Fsched到底有多能打?
八大类主流工业仿真平台【心累指数】终极评测
近期动态:
速石科技正式发布新质生产力教学科研创新平台,聚焦跨学科专业教学实训与科研
速石科技携手珠海先进集成电路研究院,正式入驻横琴ICC
速石科技完成龙芯、海光、超云兼容互认证,拓宽信创生态版图
速石科技入驻粤港澳大湾区算力调度平台,参与建设数算用一体化发展新范式
速石科技成NEXT PARK产业合伙人,共同打造全球领先的新兴产业集群


 浙公网安备 33010602011771号
浙公网安备 33010602011771号