[Paper Reading] Qwen3-VL-Embedding and Qwen3-VL-Reranker: A Unified Framework for State-of-the-Art Multimodal Retrieval and Ranking
Qwen3-VL-Embedding and Qwen3-VL-Reranker: A Unified Framework for State-of-the-Art Multimodal Retrieval and Ranking
link
时间:26.01
单位:Qwen
相关领域:多模态表征学习
项目主页:https://github.com/QwenLM/Qwen3-VL-Embedding
TL;DR
- 提出Qwen3-VL-Embedding和Qwen3-VL-Reranker两个模型系列,支持文本、图像、文档图像和视频的多模态检索
- 采用多阶段训练:对比预训练→重排模型蒸馏→模型融合,支持32K令牌输入长度
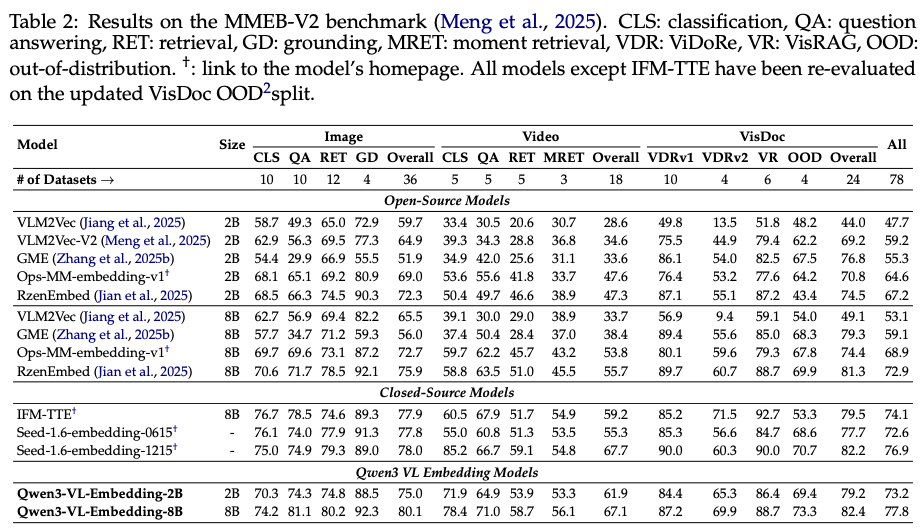
- 8B模型在MMEB-V2基准达到SOTA(77.8分),2B模型达到73.25
Method
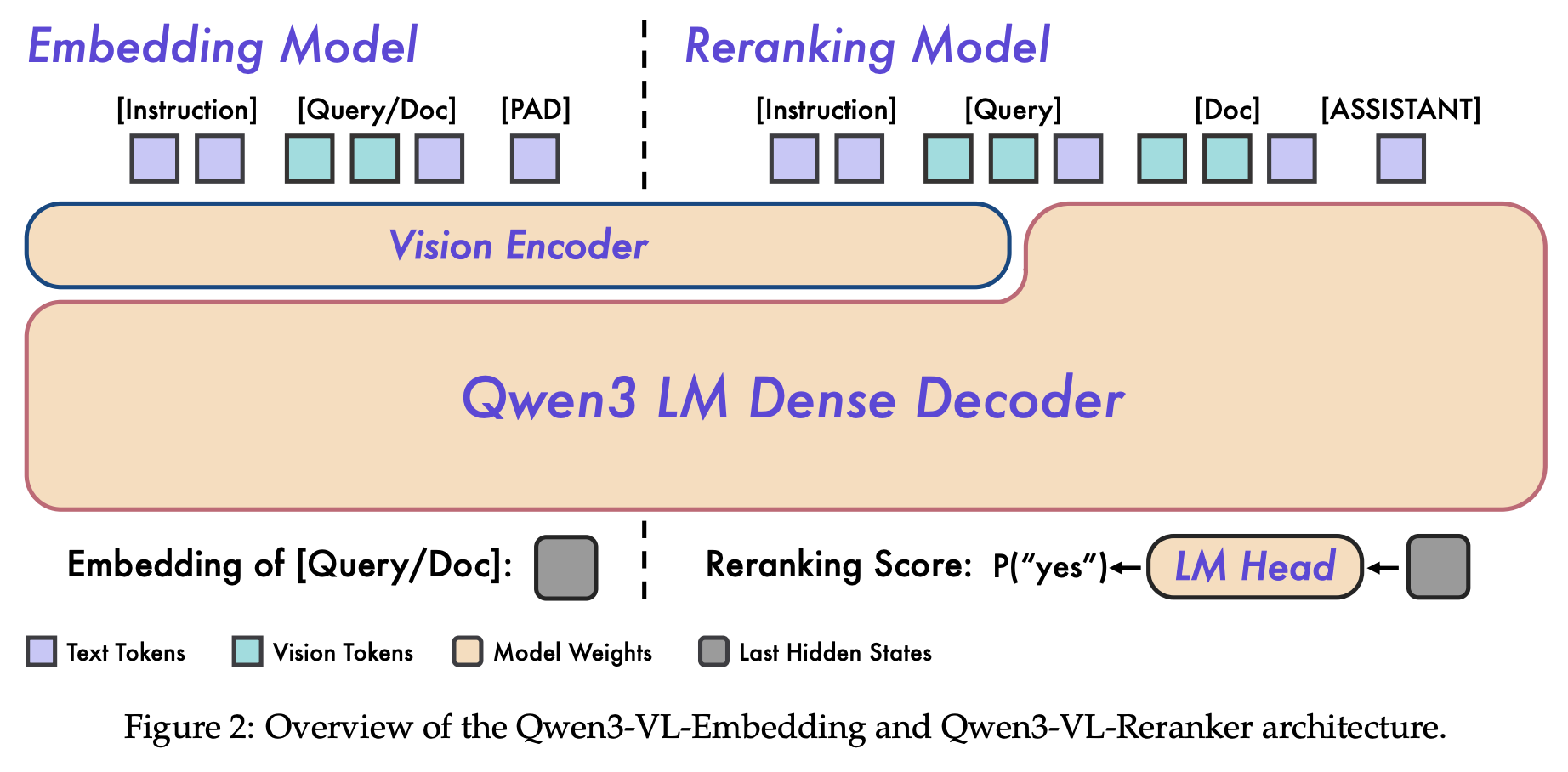
Embedding模型
Embedding Model Template
<|im_start|>system
{Instruction}
<|im_end|>
<|im_start|>user
{Instance}
<|im_end|><|endoftext|>
模型输入:参考上面的Template,其中Instance是样本多模态信息内容,Template最后会拼一个Pad也称为endoftext的特殊Token,用于标识嵌入向量的提取位置。
模型输出:推理一次,endoftext对应的hidden stage作为embedding特征
im_start/end的功能:清晰界定系统指令(System)、用户输入(User)、助手(Assistant)回复的边界
Reranking模型
作用:预测Query与Condidate的yes/no的相关性档位
Reranking Model Template
<|im_start|>system
Judge whether the Document meets the requirements based on the Query and the Instruct provided. Note that the answer can only be "yes" or "no".
<|im_end|>
<|im_start|>user
<Instruct>:{Instruction}
<Query>:{Query}
<Document>:{Document}
<|im_end|>
<|im_start|>assistant
Q:Reranking模型中User提供的Instruction起到什么作用?
A:User Instruction允许用户根据具体需求定义什么是"相关",例如
Instruction: "评估产品图像是否展示的是正品而非宣传图"
Query: "iPhone 15实拍图"
Document: [候选商品图片]
<Instruct>: "确认视频片段是否包含完整的产品演示流程"
<Query>: "智能手机开箱体验"
<Document>: [候选视频内容]
Q:Reranking模型输入输出分别是什么?
不同于Emb模型,Rerank模型是单塔,会同时输入Query与{Doc_{j}};
Reranking模型输出:
- 训练阶段:以二分类任务建模,优化目标是最小化预测标签与真实 0/1 标签的交叉熵损失(公式 4),标签由数据集中的正负样本定义(相关为 1,不相关为 0)。
- 推理阶段:通过计算 “yes” 与 “no” token 的 logits 差值,再经过 sigmoid 函数映射,最终输出 [0, 1] 区间的相关性分数(公式 5),分数越接近 1 表示相关性越强。
Data
数据组织:
\(D_i = (I_i, Q_i, C_i, R_i)\)
\(I_i\):指令集合,说明相关性判断标准与任务目标
\(Q_i\):Query集合,可以是文本、图片、视频、多模态
\(Corpus\):Documents的集合,同Query一样,可以是文本、图片、视频、多模态内容
\(Relevance Labels\):记录query与documents的关系,对于每个query \(qi\),对应一些正样本documents集合 与 一些负样本documents集合。
训练数据分布:
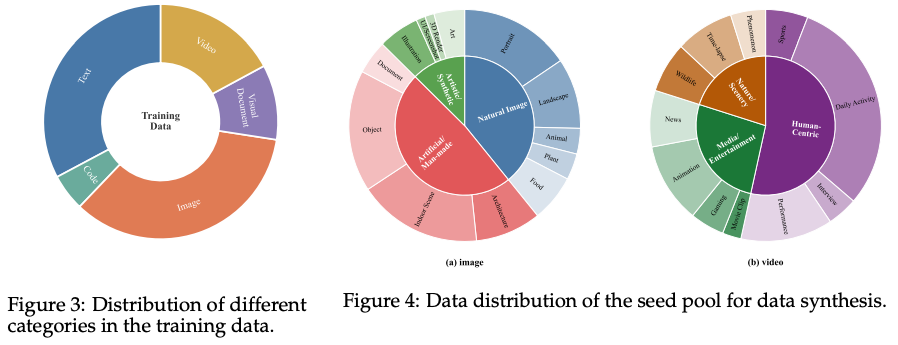
数据合成方法
种子池构建(Seed Pool Construction)
首先构建一个高质量、多样化的原始图像和视频数据集作为合成Seed池,质量控制流程:
- 粗粒度过滤:剔除低分辨率、异常宽高比的素材
- 结构优化:对视频数据进行场景切割检测,移除静态或损坏片段
- 细粒度标注:使用Qwen3-VL-32B为剩余素材生成详细的类别标签
- 跨模态对齐:通过GME嵌入模型计算相似度分数,过滤低置信度或视觉-文本不对齐的样本
多任务标注生成
📸 图像任务合成
- 图像分类任务:
- Query:图像 + 分类指令
- Doc:具体类别标签
- 多样性覆盖:物体识别、地标识别、动作识别等广泛分类任务,为每个样本生成真实类别和语义混淆的负标签
- 图像问答任务:
- Query:图像 + 基于视觉的问题
- Doc:对应答案
- 多样性覆盖:事实识别、视觉推理、OCR数据提取、领域知识查询等任务类型
- 图像检索任务:
- Query:搜索文本
- Doc:候选图像
- 语义层次:从直接视觉描述到抽象叙事场景、组合逻辑约束、知识中心文本定位等多层次检索意图
一个 图像问答任务 的数据合成Prompt示例
![image]()

🎥 视频任务合成
- 视频分类任务:
- Query: 视频 + 分类指令
- Doc: 结果类别
- 多样性覆盖:活动识别、场景识别、事件分类与意图分类等,为每个样本生成真实类别和语义相关负标签
- 视频问答任务:
- Query:视频 + 问题
- Doc:答案
- 多样性覆盖:生成 事实识别、时间定位、主题推理、电影分析等多样化QA对
- 视频检索任务:
- Query:文本描述
- Doc:视频
- 多样性覆盖:时序事件描述、主题/情感发现、教学教程定位等多粒度检索查询
- 一个时序事件描述的例子:一个人在公园里跑步的视频,使用VLM大模型识别视频中实体与动作,生成直接对应的Query
- 时序检索任务:
- Query:文本查询
- Doc:特定视频片段
- 数据作用:针对细粒度时间定位,识别特定目标并定位时间片段
一个 视频分类任务 的数据合成Prompt示例
![image]()

正样本提炼与负样本挖掘
为了提升正样本质量及识别难负样本,本工作实现两阶段难样本挖掘:
Recall:
针对每个Query检索Top-K相似的候选
Relevance Filter:
- 正样本过滤机制
- 超参数\(t^{+}\)作为正样本得分阈值
- 只有当至少一个正样本文档\(t^{+}\)的得分大于\(t^{+}\)时,查询Query才会保留
- 难负样本选择
- 计算精炼后正样本的平均得分\(t^{+}\)
- 选择条件如下,其中$\sigma^{-} $是一个固定的安全边界阈值,越大挑选出来的负样本越难。
![image]()
训练
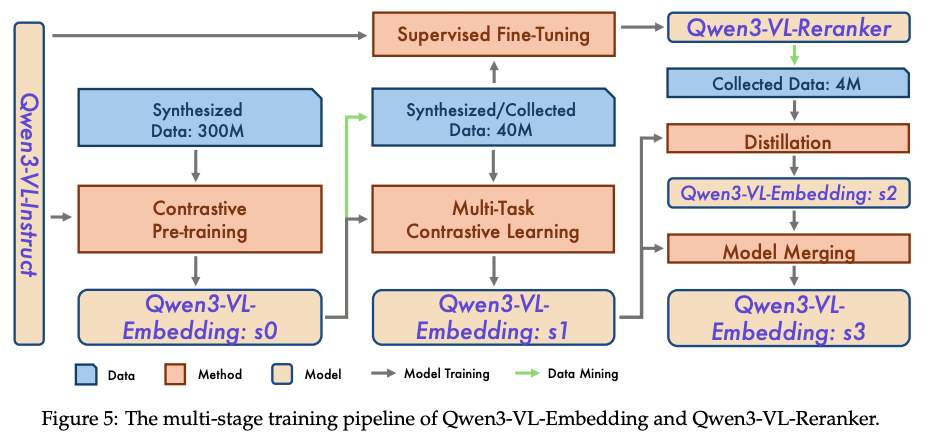
Stage1:对比学习预训练 => Qwen3-VL-Embedding: s0
- 3个亿级别的大规模、多模态、多任务合成数据上预训练
- 训练Loss
Loss:额外加了 In-Batch Doc负采样、In-Batch query负采样、Doc正负样本间学习Loss
![image]()

Stage2: 多任务对比学习与SFT => Qwen3-VL-Embedding: s1
- 公开数据 + 合成数据采样 => 共4000W训练数据量
- 使用Qwen3-VL-Embedding: s0数据挖掘
同时,该阶段的retrival子集会用来训练Reranker模型 - Reranker模型训练阶段Loss:
![image]()
- Reranker模型推理阶段相关性分数
![image]()
Stage3:蒸馏与模型合并
- 数据:400W的公开与私有数据,使用Reranker模型打标相关性分数
- 蒸馏Loss:\(P_{reranker}(d_i, q)\)是离线计算出来的doc的相关性logit,一共K+1个Doc (一个正样本,K个负样本),蒸馏之后得到Qwen3-VL-Embedding: s2。
![image]()
由于Reranker模型是以Retrival任务为主训练的,所以此时蒸馏出来的Embedding模型还是以检索任务为主,将s1与s2模型使用Model Merging合并为s3,增加通用能力。
关于Model Merging:就是两个模型A与B的相同位置的参数进行平均
合成数据的Loss
- 分类数据的Loss:待分类的实例是Query,分类的类别是Doc,正确的类别标签是正样本Doc,错误的类别标签是负样本Doc
- Semantic Textual Similarity (STS) Data
纯文本片段数据,使用下面CoSent Loss训练,核心思想是:保持真实相似度排序与模型预测排序的一致性。
![image]()
其中\(\hat{s}(q_i, dj)\)是标注好的相关性档位
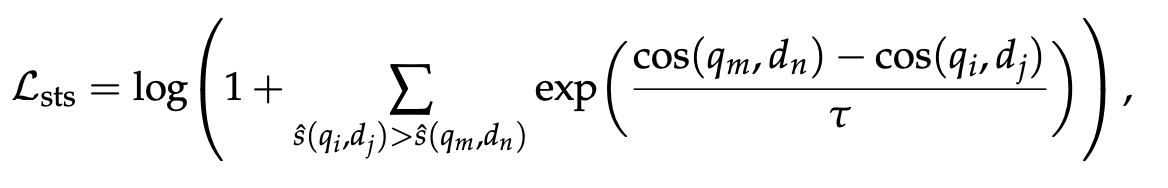
训练实现细节
模型训练采用LoRA微调,具备以下优势:
- 能够大幅降低显存占用,支持更大的有效批量
- 提升模型的泛化性能
- 让超参数搜索和后续模型融合更高效
Experiment
MMEB V2主实验结果:达到Sota效果,2B模型Overall Score达到75,比第二名RzenEmbed高2.7个点。
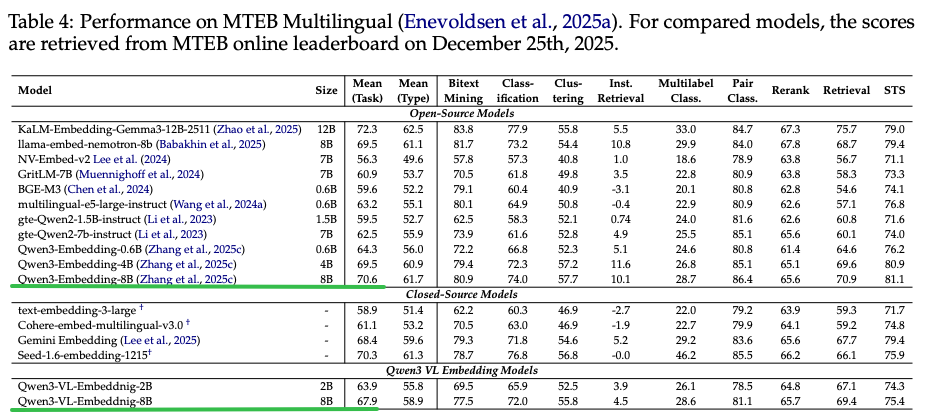
MTEB纯文本Benchmark结果:相对于单模态的Qwen3-Embedding模型仅衰退了2.7个点,代表Qwen3VL-Embedding在学习多模态同时,没有遗忘LLM的纯文本Embedding能力。
Embedding模型与Reranker对比:在MMEB上Benchmark上,相同Size的Reranker模型要比较Embedding模型要更好
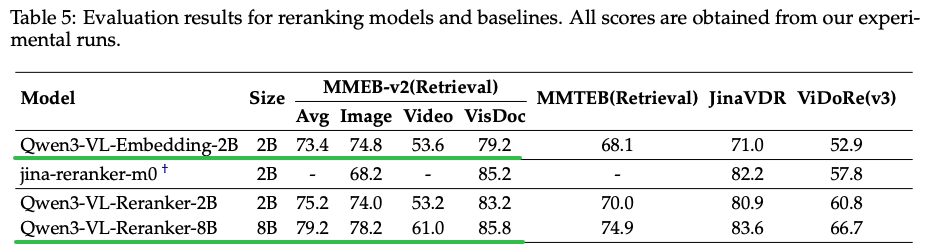
Q:为什么Reranker模型在检索任务上要明显优于Embedding模型?
A: Embedding模型与Reranker模型架构差异:
- Embedding 模型采用双编码器(Bi-Encoder)架构,分别对Query和Doc进行独立编码生成向量,再通过余弦相似度计算相关性,无法捕捉两者间细粒度交互;
- Reranker 采用交叉编码器(Cross-Encoder)架构,通过交叉注意力机制直接建模Query与Doc的逐元素交互,能更精准识别语义关联 (如多模态内容的局部匹配、上下文依赖等)。
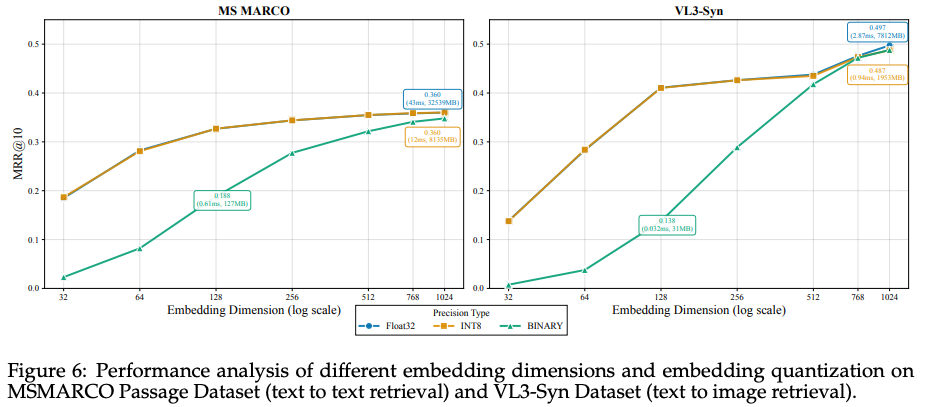
MRL训练后不同维度特征效果差异:在MS MARCO上256维以下才开始明显掉点,在VL3-Sync上128维以下开始明显掉点。例如,在文本检索任务中,将维度从 1024 降至 512,性能仅下降 1.4%,但存储减少 50%,检索速度提升一倍。
![image]()
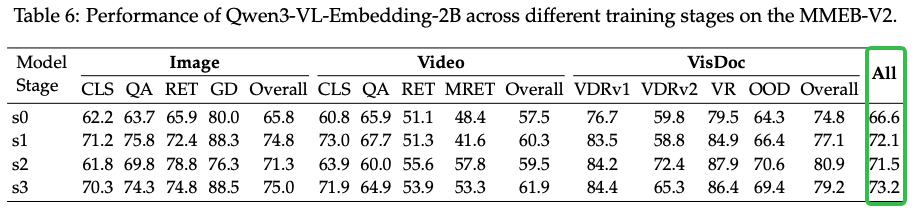
多阶段训练的Ablation分析:第二个阶段(4000W)训练数据训完之后得到的s1模型就已经拿到大部分涨点了。
![image]()
总结与思考
- 数据合成与数据规模非常重要;
- 第一阶段就需要数据清洗与难负样本挖掘;
相关链接
https://zhuanlan.zhihu.com/p/1996537099780904730
https://zhuanlan.zhihu.com/p/1994444951451374764
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/19466057

 浙公网安备 33010602011771号
浙公网安备 33010602011771号