[PaperReading] OneSearch A Preliminary Exploration of the Unified End-to-End Generative Framework for E-commerce Search
OneSearch: A Preliminary Exploration of the Unified End-to-End Generative Framework for E-commerce Search
link
时间:2025.10
单位:Kuaishou
相关领域:
作者相关工作:前几作没有google scholar,后面Zihan Liang是OneVision作者,还有一名有Google Sholar的作者是Yufei Ma。
被引次数:8
TL;DR
本文提出了 OneSearch,一个为电商搜索设计的首个工业级部署的端到端生成式检索框架。传统MCA存在计算碎片化和各阶段优化目标冲突的问题,限制了性能上限。关键改进:
- 关键词增强分层量化编码(KHQE):结合RQ-Kmeans和OPQ,同保留分层语义与Item核心属性,增强query-item相关性约束。
- 多视角用户行为序列注入(Mu-Seq):通过行为序列构建用户ID,并融合显式的短期行为序列与隐式的长期行为序列。
- 偏好感知奖励系统(PARS):包含多阶段监督微调(SFT)和自适应奖励加权排序,以捕捉细粒度用户偏好。
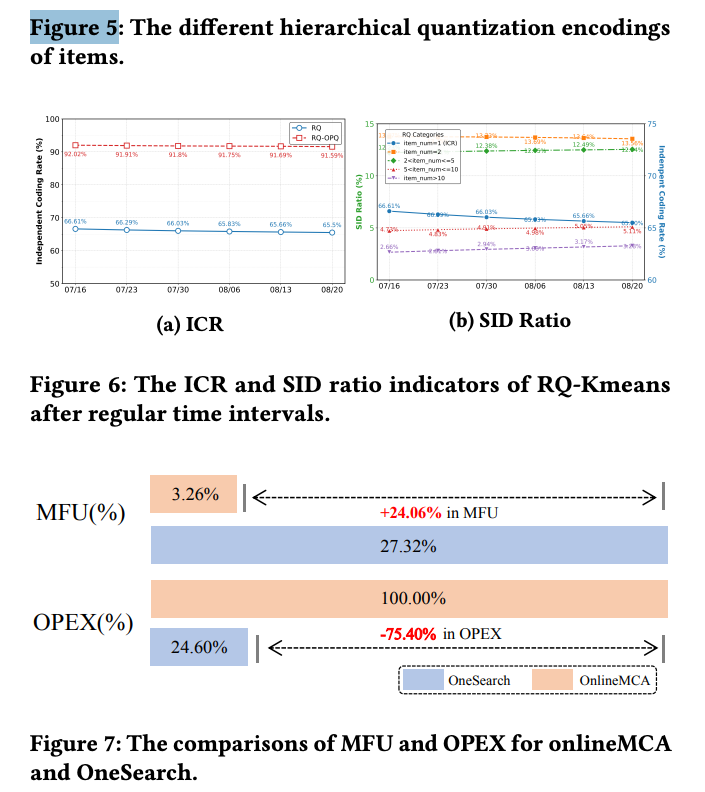
在线A/B测试显示,带来的业务指标提升(Item CTR +1.67%, Order Volume +3.22%),并降低运营成本75.40%,提升模型FLOPs利用率(MFU)从3.26%到27.32%。
Q:为什么说OneSearch算法能降低运营成本(operational expenditure )?
- 消除了多阶段系统的复杂性与开销
- 传统MCA:需要独立维护和部署召回(Recall)、预排序(Pre-ranking)、排序(Ranking) 等多个复杂模块。这些模块之间需要大量的数据通信、存储和调度工作。
- OneSearch:用一个统一的生成式模型替代了上述所有阶段。这极大地简化了系统架构,省去了模块间复杂的通信、数据传输和流水线协调成本。
- 大幅提升了计算效率
- 论文中的关键指标是 Model FLOPs Utilization(MFU,模型浮点运算利用率) 的提升。
- 传统MCA 的MFU仅为 3.26%,意味着绝大部分的计算资源被浪费在了非核心计算(如数据I/O、等待、通信)上。
- OneSearch 将MFU提升至 27.32%,意味着计算资源更多地被用于模型本身的推理计算,硬件利用率更高,从而在完成相同或更优任务时,所需的计算资源更少。
Motivation
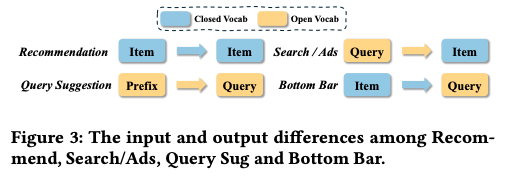
Figure 3 的核心论点是:电商搜索的独特之处在于其输入(查询)是开放的,而输出(商品)是封闭的。这种混合特性使得直接套用为“输入输出全开放”(如查询建议)或“输入输出全封闭”(如推荐)设计的生成式检索方法效果不佳。因此,需要专门设计像OneSearch这样的框架,来处理这种跨模态(文本到ID)的生成任务,并解决其带来的独特挑战(如强相关性约束)。
Method
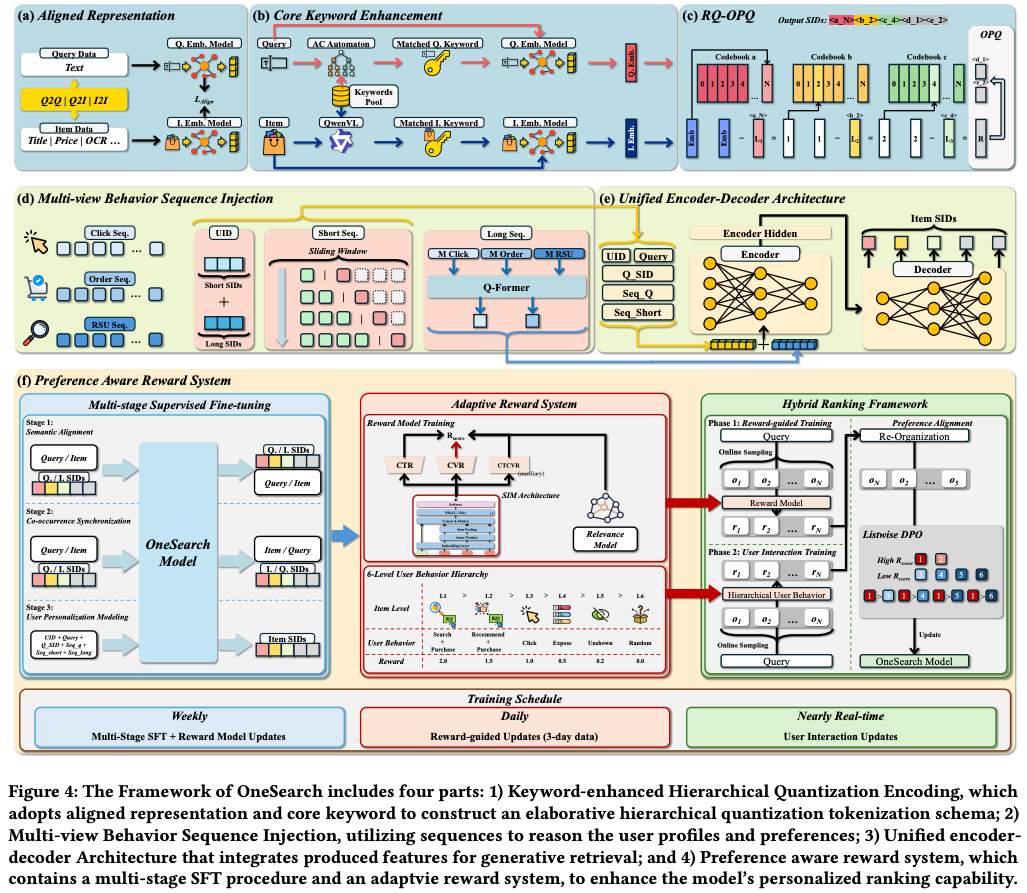
关键词增强分层量化编码 (KHQE)
Aligned collaborative and semantic representation
训练数据构建:从真实的用户搜索日志中,利用现有模型(如ItemCF, Swing)筛选出高质量的样本对,包括:
- query2query pairs:语义或行为上相似的查询对。
- item2item pairs:语义或行为上相似的商品对。
- query2item pairs:有历史交互行为的查询-商品对。
ItemCF(Item-Based Collaborative Filtering,基于物品的协同过滤)
核心思想:一种经典的推荐算法,其基本假设是“喜欢物品A的用户,也可能喜欢与A相似的物品B”。
Swing(一种改进的基于图的协同过滤算法)
原理:如果两个用户u_a和u_b都同时点击了物品i和j,但u_a和u_b除此之外再也没有共同点击过任何其他物品,那么这次“共同点击”对物品i和j相似度的贡献就很低,这可能只是偶然。
反之,如果用户u_a和u_b是一个经常有相似行为的“小圈子”(即他们共同点击过很多物品),那么他们这次对i和j的共同点击,对i和j相似度的贡献就很高,说明i和j确实有强关联。
特征融合:对于每个查询和商品,收集其内容信息(query、title、prices、keywords、OCR)和业务统计特征(点击、加购、购买次数等),使用BGE模型抽出embedding,一并输入模型。
多任务训练:通过设计四种损失函数进行联合训练,
\(L_{q2q}\)和 \(L_{i2i}\)(对比学习损失):目的是让相似的Query或Item在向量空间中也彼此接近。这直接利用了query2query和item2item数据。这确保了编码器能学习到语义和协同的共性,为后续的层次化聚类(RQ-Kmeans)打下基础。如果没有这项,模型可能无法很好地聚合相似商品。
L_q2i(对比学习损失):确保在向量空间中,有交互行为的查询和商品对彼此接近。这使模型能反映真实的业务相关性。
L_rank(排序损失):进一步学习不同交互级别(如曝光、点击、下单)的query2item对之间的细微差异,使得下单对的相似度高于点击对,点击对的相似度高于曝光对。
L_rel(相关性校正损失):对于高相似度但对,使用LLM根据完整上下文信息进行相关性打分,让基础模型去拟合这个更精确的分数,提升相关性判断的准确性。
核心关键词增强(Core Keyword Enhancement)
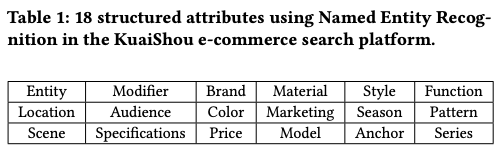
这一步的目的是强化商品核心属性在最终表示中的权重,减少无关文本噪声的干扰。
- 关键词库构建:
利用NER识别出18类电商核心结构化属性(如品牌、材质、风格等,见表1)。
从过去一年的点击日志中挖掘高频词,作为每个属性的核心关键词库。 - 关键词匹配与向量化:
对于Item:使用多模态模型(Qwen-VL)判别商品对应哪些关键词。
对于Query:使用高效的字符串匹配算法(Aho-Corasick Automaton)快速提取关键词。
将这些关键词输入到上一步训练好的基础编码器中,得到关键词向量 e_k,该向量与商品/查询向量的分布是一致的。 - 向量融合:
将商品/查询的原始向量 e_i/ e_q与其对应的所有关键词向量的平均值进行加权平均,得到优化后的向量 \(e_i^o/ e_q^o\)。
公式:\(e_i^o = 1/2 * (e_i + (1/n) * Σ e_k^j)\)
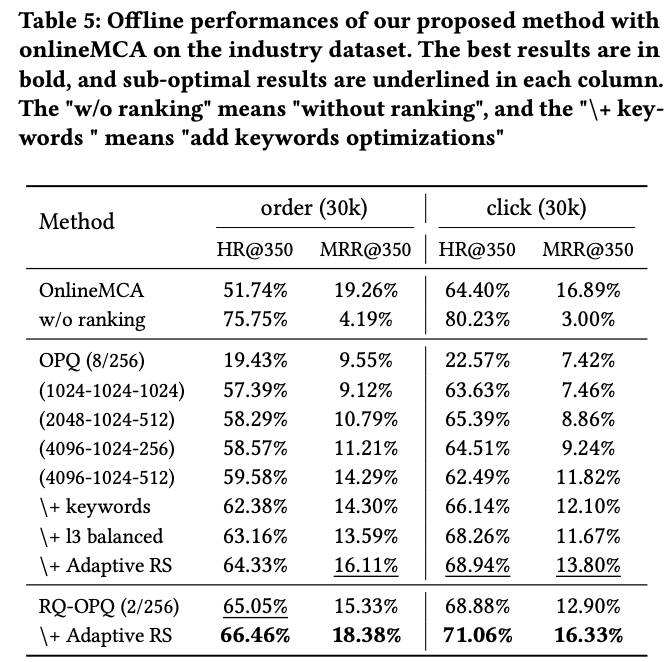
RQ-OPQ Hierarchical Quantization Tokenization
核心方法:3层RQ-Kmeans(4096-1024-512) 后面接 2层RQ-OPQ
Ablation
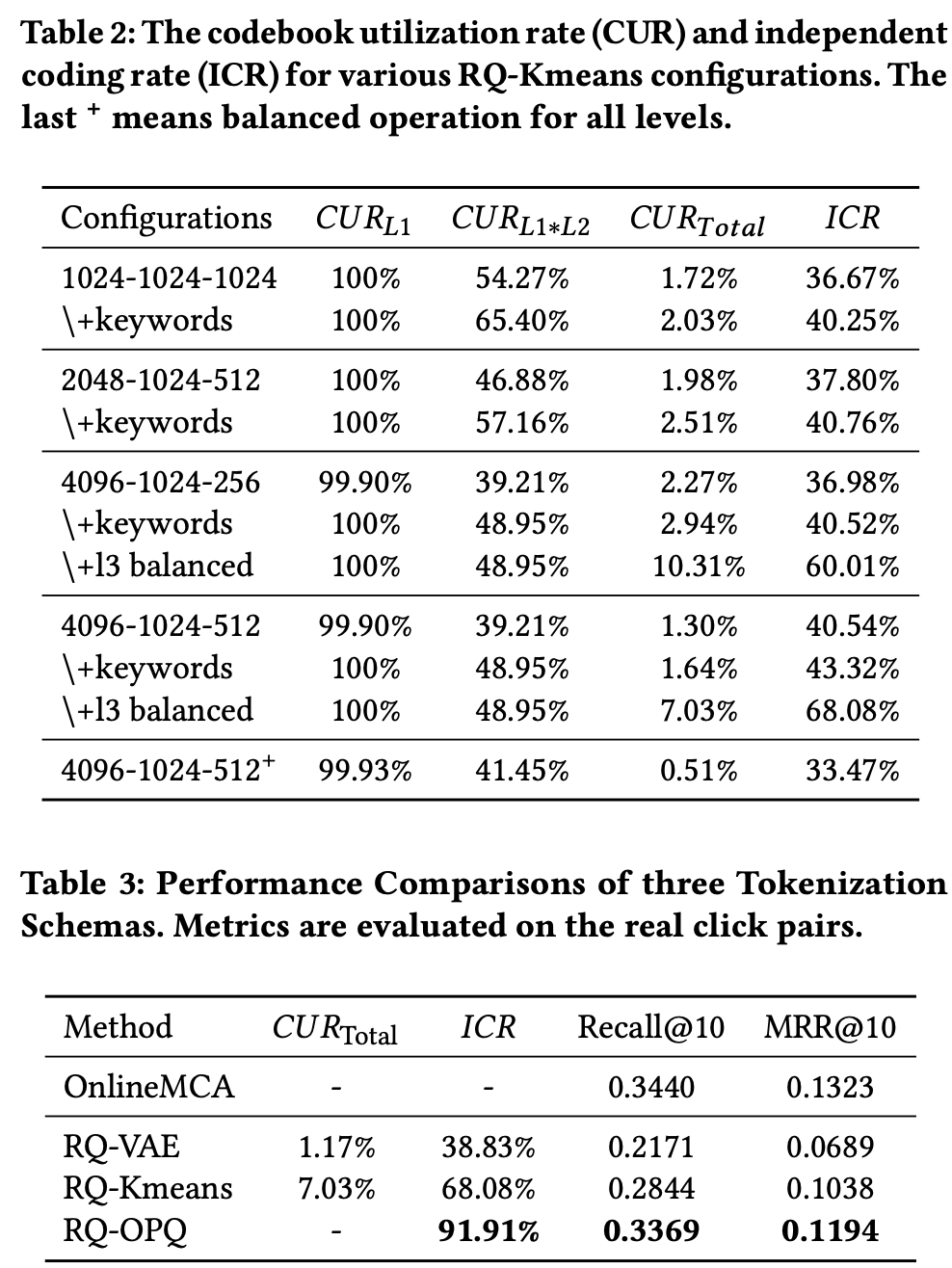
Q: 为什么RQ-Kmeans要使用逐渐减少聚类中心数的方法?
- 容纳更多粗粒度类别:电商商品类别繁多(如服装、电子产品),更宽的L1层能覆盖更多顶层类别,避免相似但不同类别的商品被过早聚合。
- 优化后续层级输入:L1层输出作为L2层的输入,更精确的粗粒度编码为下层细化提供更好基础,整体提升CUR和ICR(如表2中4096-1024-512配置的CUR提升至7.03%)。
Q:RQ-OPQ?
OPQ的全称是 优化乘积量化(Optimized Product Quantization),将L3的残差(包含细粒度特征) 分解为两个128维子向量分别量化
具体步骤:
- 向量旋转:使用预训练的旋转矩阵对残差向量进行线性变换,使维度间相关性最小化
- 独立量化:对每个子向量分别进行Kmeans聚类(码本大小各为256)
- 编码组合:将两个子向量的聚类中心ID组合成最终的OPQ编码
Q:给tokenizer所使用的embedding表征的特征维度是多少?
特征维度:768
多种时序建模
用户ID的短序列建模:用户最近点击过的m个item的tokens的平均
用户ID的长序列建模:用户的长期行为序列(如几年内的点击、购买记录)可能包含成千上万个物品,无法像短期序列那样直接作为文本输入。
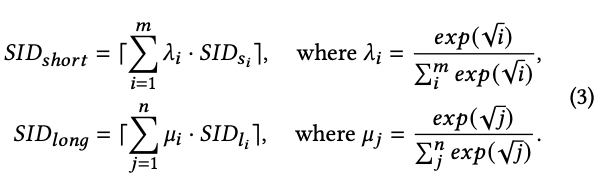
Architecture
参考Fig4中浅绿色底色的部分,是一个Encoder-Decoder的架构
![]()
Reward System
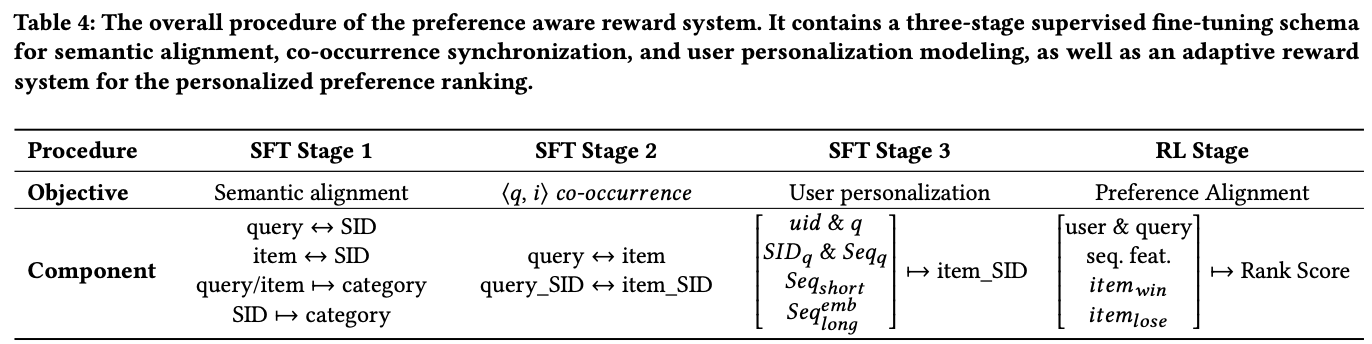
- 多阶段监督微调
在进行复杂的偏好学习之前,先通过三个阶段让模型打好基础:
• 阶段一:语义内容对齐
◦ 目的:让模型理解“语义ID”和真实文本之间的对应关系。因为模型的基本架构是针对自然语言预训练的,而OneSearch的输入输出是语义ID。
◦ 任务:包括 (1)从文本生成对应的语义ID;(2)从语义ID还原出文本;(3)预测查询或物品的类别。这些任务确保了模型底层编码的正确性。
• 阶段二:共现同步
◦ 目的:让模型学习查询和物品之间的内在关联和协同信号。
◦ 任务:进行查询到物品、查询语义ID到物品语义ID的相互预测。
• 阶段三:用户个性化建模
◦ 目的:这是最终推理的模拟阶段,将用户的所有信息(用户ID、查询、长短序列等)整合为输入,学习生成用户可能交互的物品语义ID。
◦ 关键技巧:对短期行为序列使用滑动窗口数据增强,即用逐渐变长的子序列来预测下一个物品。这既能让模型学习兴趣演化,又能更好地处理行为历史较短的新用户。
- 自适应奖励系统
在SFT之后,模型已经能生成相关的物品,但排序可能不是最优的。这部分通过强化学习来精细化排序能力。
• 自适应加权奖励信号:
◦ 将用户行为分为6个等级(如购买、点击、曝光未点击等),并赋予基础奖励权重。
◦ 为了更精确地衡量偏好,引入了经过校准的CTR和CVR指标,避免新物品或高曝光物品的统计偏差。最终的综合奖励分数 r(q, i) 由基础权重和校准后的CTR/CVR共同决定。
• 奖励模型训练:
◦ 训练一个专门的奖励模型来预测用户对物品的偏好分数。该模型采用三塔结构,分别预测CTR、CVR和CTCVR,并额外引入一个离线的相关性分数,强制保证生成结果的相关性约束。
• 混合排名框架:
◦ 首先,用奖励模型对OneSearch生成的物品进行重排,收集那些排名发生变化的样本对(胜出的物品 vs 被击败的物品)。
◦ 然后,使用一种列表式直接偏好优化方法进行训练。其损失函数不仅鼓励模型给“胜出”物品更高的概率,还结合了SFT阶段的似然损失,形成一个混合优化目标。这使模型能学会细微的偏好差异。
◦ 两阶段对齐:首先使用奖励模型(继承了传统排序模型的知识)进行训练;然后直接使用真实的用户交互数据(点击、购买等)进行流式更新,以突破传统模型的天花板。
Experiment
Tokenizer Ablation
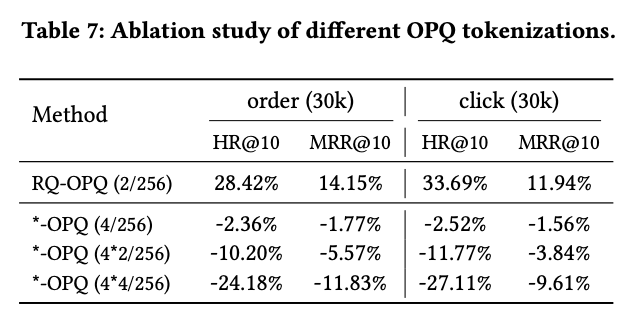
RQ-OPT Ablation
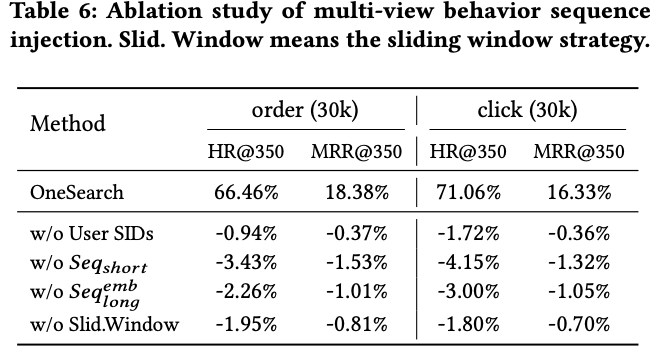
多种序列用户行为特征
相关链接
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/19365905

 浙公网安备 33010602011771号
浙公网安备 33010602011771号