[PaperReading] OneRec Technical Report
OneRec Technical Report
OneRec: Unifying Retrieve and Rank with Generative Recommender and Preference Alignment
OneRec Technical Report
OneRec-V2 Technical Report
时间:25.09
单位:Kuaishou
相关领域:Recommendation
被引次数:25
TL;DR
背景是推荐系统仍依赖多阶段级联架构,而非端到端的方法,这导致了计算碎片化与优化不一致的问题。本工作提出名为OneRec的端到端推荐系统架构取得了一些技术突破:1) 推荐模型的计算浮点运算次数Flops提升了10倍;2) 将RL在推荐系统中做出效果;3) GPU的MFU在训练阶段达到23.7%,推理阶段达到28.8%。线上取得了些收益:1) 运营成本(OPEX, operating expense)仅为传统推荐流程的 10.6%;2) 在25%的流量上,Kuaishou与KuaishouLite APP用户停留时长分别提升了 0.54% 和 1.24%;3) 7 日用户生命周期(LT7,衡量推荐体验的关键指标)等核心指标也实现了显著增长;
Method
OneRec vs 传统多级推荐系统
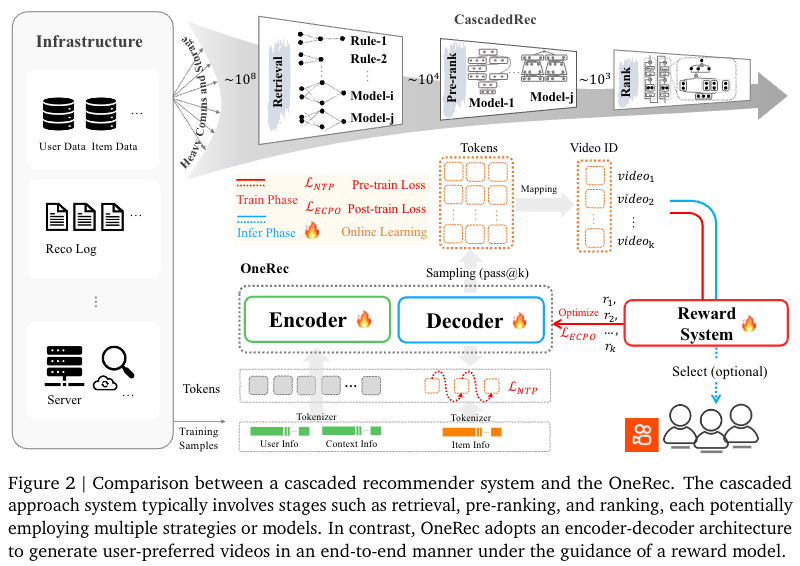
多模态表征
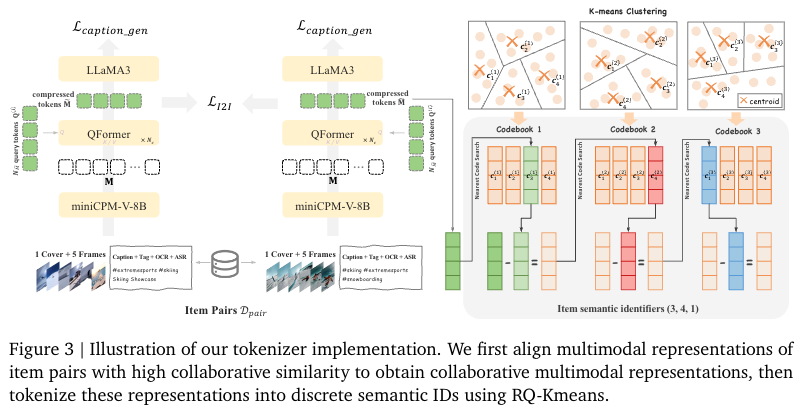
- 输入信息:Caption、ASR、OCR、封面帧、均匀采样的5帧
- Item Pairs:两个存在特定关联关系的物品组成的样本集合,例如:
- 用户行为关联:来自同一用户的高互动行为(如点击、观看),反映 “用户偏好的一致性”;
- 物品自身关联:物品间的内容或属性相似性,反映 “物品语义的相关性”。
Q:为什么需要Item Pairs?
如果对比学习这里仅学习语义之间的相似性,那提取的表征也只有实体类的相似性。如果结合Items Pair构造的正负样本,那表征模型会学到用户偏好的协作信号(用户点击‘红烧肉教程’后,又点击‘糖醋排骨教程),从而生成更有利用Tokenizer的表征。
Loss
- I2I Loss:其实就是Item Pairs下面Item2Item对比学习Loss
- Caption Loss: 保留内容理解能力
![image]()
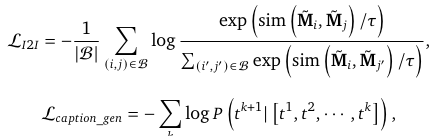
Q:如何理解Aligned Collaborative-Aware Multimodal Representation?

Tokenizer
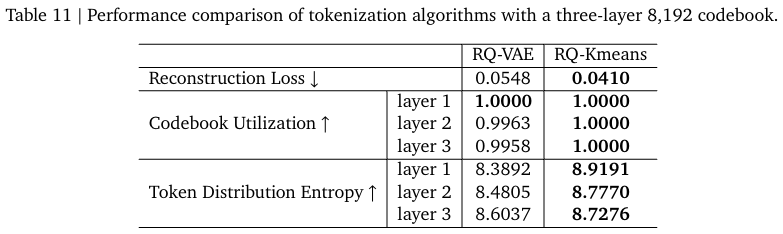
使用三层RQ-Kmeans,每层8192个聚类中心。
- 重建Loss: 评估离散token重建原始输入的能力
- Codebook Utilization(码表利用率):衡量模型利用资源表征数据的效率
- Token Distribution Entropy:Token分布的熵,该指标越大,说明不确定性越高,分布越均匀。
![image]()
从表中可以看出: - 越往深层,CodeBook的利用率越低
- 越往深层,分布熵值越大,不确定越强,分布越均衡
Encoder (用户兴趣建模)
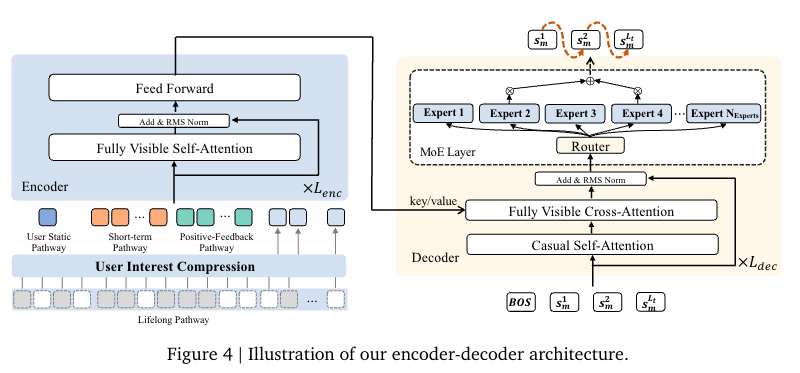
多尺度特征工程:
- 静态通路:用户 ID、年龄等核心特征,输出 1×d_model 向量;
- 短期通路:最近 20 次交互,捕捉即时偏好 (每个短视频的观看时长、是否点赞 等);
- 正反馈通路:256 次高度参与的行为,强化核心兴趣;
- 终身通路:处理 10 万 + 超长期行为,通过分层 K-means 压缩 + QFormer,输出 128×d_model 向量;
统一 Transformer:拼接四通路特征 + 位置嵌入,经 \(L_{enc}\) 层 Transformer(全可见自注意力 + FFN)输出用户兴趣表示 \(z_{enc}\)。
Decoder (新Item SID生成)
- 生成范式:点式生成,输入为 [BOS]+ 物品语义 ID 序列,经 L_dec 层 Transformer 处理;
- 效率优化:引入 MoE 层(如 24 个专家选 2 个激活),在提升模型容量的同时控制计算成本;
- 训练损失:next-token 预测损失(L_NTP),学习语义 ID 序列生成规律。
Reward System
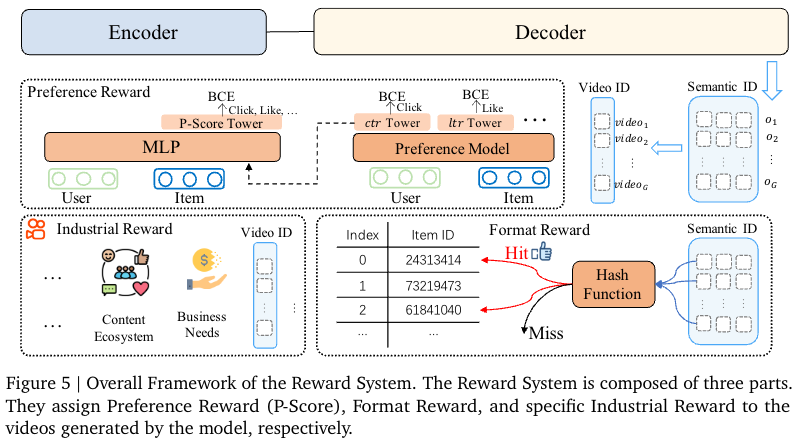
好的,我将根据您的要求,详细讲解 OneRec 技术报告中关于“奖励系统”(Reward System)的章节。
Reward System 章节详细讲解
1. 用户偏好对齐
为了更精准地定义“好推荐”,OneRec 提出了 P-Score,这是一个通过神经网络学习的个性化融合分数。
- 模型架构:P-Score 模型基于搜索兴趣模型(SIM)构建,包含多个塔层,每个塔专门学习一个特定目标(如
ctr,lvtr,ltr等)。在训练时,这些塔使用对应目标的标签计算辅助损失(二元交叉熵损失)。 - 融合机制:各塔的隐藏状态与用户、物品表征一起输入到一个多层感知机(MLP)中,最终由一个单塔输出 P-Score。该分数通过所有目标的标签计算总损失,并通过调整各目标的损失权重 ( w^{xtr} ) 来偏向不同目标,最终实现所有目标 AUC 的提升,接近帕累托最优。
- 优化算法 - ECPO:OneRec 采用了一种改进的强化学习算法 ECPO 来使用 P-Score 进行优化。
- 流程:对用户 ( u ),使用旧策略模型生成 ( G ) 个物品,每个物品输入 P-Score 模型得到奖励 ( r_i )。优化目标是最大化经过裁剪的策略比率与优势函数 ( A_i ) 的乘积。
- 核心改进:ECPO 对原始 GRPO 算法进行了关键修改,对具有负优势度(( A_i < 0 ))的样本也进行了策略比率裁剪,防止其梯度爆炸,从而大大提升了训练稳定性。它移除了 KL 散度损失,因为强化学习和监督微调在 OneRec 中是共同训练的,监督微调损失足以保证模型稳定。
2. 生成格式正则化
在生成式推荐中,合法率 指生成的语义 ID 序列能映射到真实物品 ID 的比例,这对推理的稳定性至关重要。
- 问题根源 - 挤压效应:引入强化学习后,模型为了压低负优势度样本的概率,会将大部分概率质量挤压到当前认为最优的输出上,导致一些合法令牌的概率被压到与非法令牌相近的水平,从而使合法率骤降至 50% 以下。
- 解决方案:在强化学习中引入格式奖励。具体而言,从 ( G ) 个样本中随机选择 ( K ) 个进行合法性强化学习。对于合法样本,设置其优势度 ( A_i = 1 );对于非法样本,直接丢弃以避免挤压效应。实验表明,这种格式奖励不仅能有效提升合法率,还能带来在线指标(如 APP 停留时间)的显著增长。
3. 工业场景对齐
报告以一个非常具体的工业场景——控制“内容农场”视频的曝光比例——来演示这一方法的有效性。
-
问题定义:“内容农场”指大量生产搬运、剪辑内容的内容创作者,其视频质量参差不齐。虽然 OneRec 在核心业务指标上表现优异,但如果没有控制措施,这类内容的曝光率会显著上升,可能损害平台生态。
-
技术实现:OneRec 采用了名为 特定工业奖励(Specific Industrial Reward, SIR) 的方法:
- 设定目标比例:平台可以设定一个病毒内容的最佳曝光比例 ( f )。
- 奖励重塑(Reward Shaping):在强化学习训练过程中,当模型生成的候选物品属于病毒内容集合 ( I_{\text{viral}} ) 时,对其获得的 P-Score 奖励进行降权处理。具体的奖励函数修改如下:
[
r_{i}^{\prime}=\left{\begin{array}{ll}r_{i} & \text { if } o_{i} \notin I_{\text {viral }} \ \alpha r_{i} & \text { if } o_{i} \in I_{\text {viral }}\end{array}\right.
]
其中,( \alpha ) 是一个介于 0 和 1 之间的抑制因子。这意味着,即使一个病毒内容视频本身质量尚可(P-Score 较高),其最终用于优化模型的奖励也会被打折,从而降低了模型生成此类视频的动机。 - 保持质量感知:关键之处在于,这种方法并非简单地将病毒内容“一棍子打死”。模型仍然能感知到这些内容的质量(通过 ( \alpha r_i ) 而非直接设为 0),只是在整体排序上会被抑制。这比在检索阶段直接过滤掉所有病毒内容创作者要精细得多。
-
实验效果:部署 SIR 后,实验结果非常显著:
- 精准控制:病毒内容的曝光量成功降低了 9.59%。
- 性能稳定:核心用户体验指标,如观看时长 和 APP 停留时间 保持了稳定,没有受到负面影响。
Training
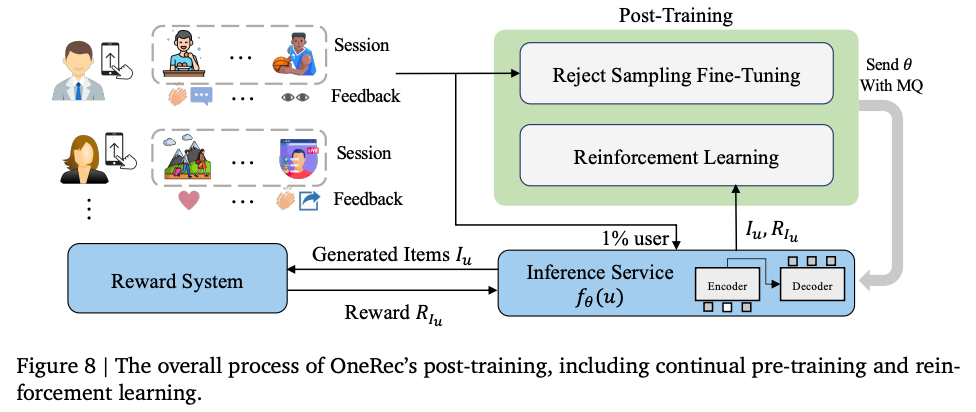
PreTraining
- 硬件:90 台服务器(每台 8 卡旗舰 GPU,400G NVLink/RDMA);
- 优化策略:SKAI 框架 GPU 嵌入加速、ZERO1 数据并行、BF16 混合精度、注意力编译优化;
- 预训练数据:100B 亿样本(300 B token) 收敛 → 后训练(RSFT 拒绝采样微调 + 1% 用户 RL 训练)。
PostTraining
Experiment
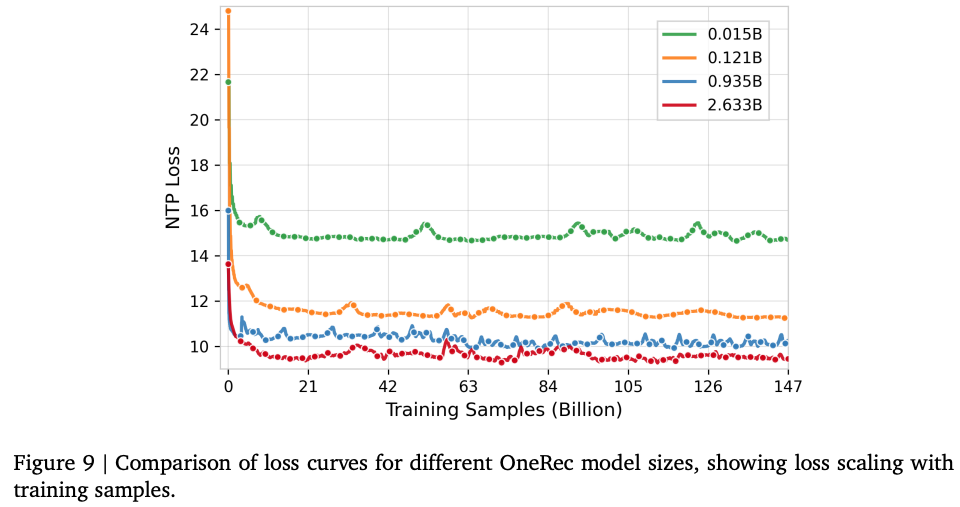
Data/Model Scaling Law
不同模型参数量以及训练样本量对应的Scaling Law曲线
MultiScale特征工程
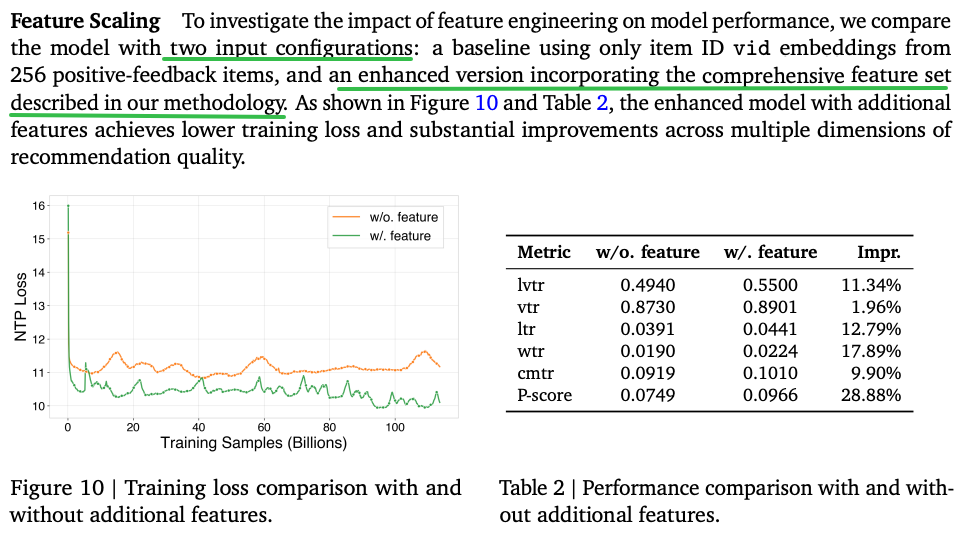
加与不加多尺度特征工程的效果差异
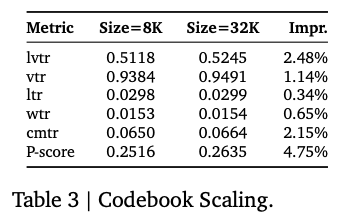
增加codebook从8192->32k能进一步提升效果,但从模型尺寸部署效果角度实际仍然使用8192
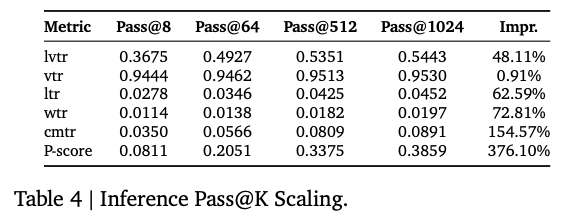
Infer Scaling
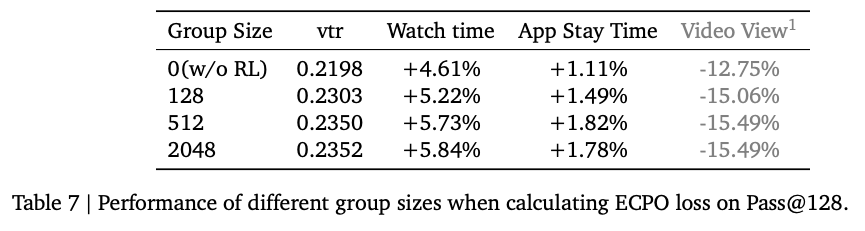
Pass@K基本定义:Pass@K 衡量的是,对于单个查询(或用户请求),模型独立地生成 K 个候选结果,只要这 K 个结果中至少有一个是正确的或高质量的,那么这次查询就被认为是“通过”的。最终,Pass@K 是所有查询中“通过”的比例。
总结:在生成式推荐系统中,推理时生成的候选物品数量(Pass@K)是一个至关重要的超参数,它直接决定了系统效果的上限和计算成本的下限。
- Pass@K 是评估生成式系统“探索能力”的指标,K 值越大,找到优质结果的机会越高。
- OneRec 的实验证明了缩放定律在推理阶段同样成立,但同时也揭示了边际收益递减现象。
- 最终,作者基于对效果与效率的精密权衡,选择了 Pass@512 作为生产环境的部署标准。
![image]()
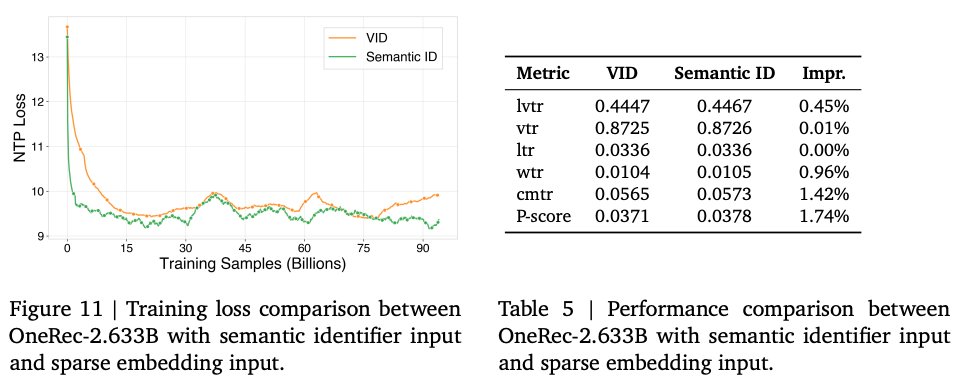
Semantic ID作为Input相对于VID Embedding的提升
Reward System带来的提升Ablation
相对于Pretrain模型
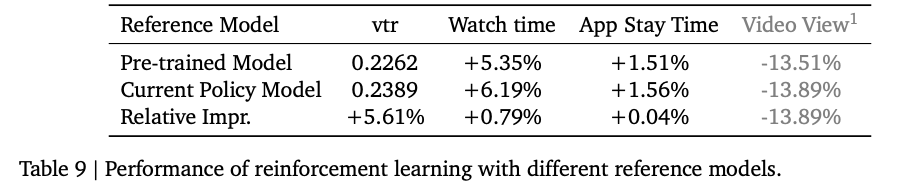
Embedding有没有单独测?
Tokenizer相关测试?
Pretrain的作用?
PostTrain提升多少?
效果可视化
无
总结与思考
无,整体与宏观思考问题
相关链接
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/19325469

 浙公网安备 33010602011771号
浙公网安备 33010602011771号