[Paper Reading] UniME-V2: MLLM-as-a-Judge for Universal Multimodal Embedding Learning
UniME-V2: MLLM-as-a-Judge for Universal Multimodal Embedding Learning
link
时间:
单位:MiroMind AI、The University of Sydney、M.R.L. Team
相关领域:
作者相关工作:与UniME的一作二作相同:Tiancheng Gu、Kaicheng Yang
被引次数:1
项目主页:https://garygutc.github.io/UniME-v2/
TL;DR
提出UniME-V2多模态embedding学习算法,解决负样本多样性问题。
方法:
1.通过全局检索构建一个潜在的难负样本集合;
2.提出MLLM-as-a-Judge机制,利用多模态大模型获取query-candidate的语义相似性分数,这些分数可以用来过滤错误负样本、难负样本挖掘 以及 提升负样本多样性与质量。并且这样分数还可用来作为soft label,以防止正负样本对非正即负的Hard约束;
3.UniME-V2-Reranker,可以使用joint-wise与list-wise的方式挖掘难负样本;
上述改进的示意图
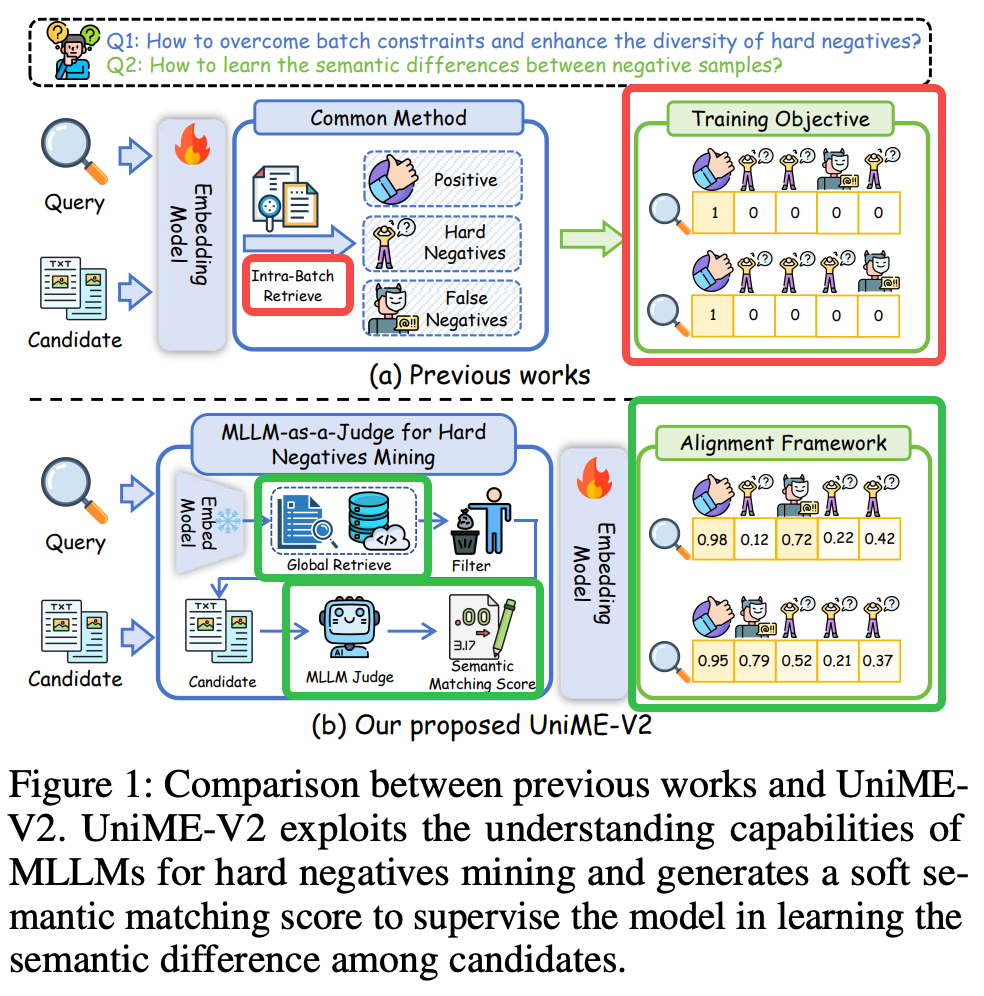
Method
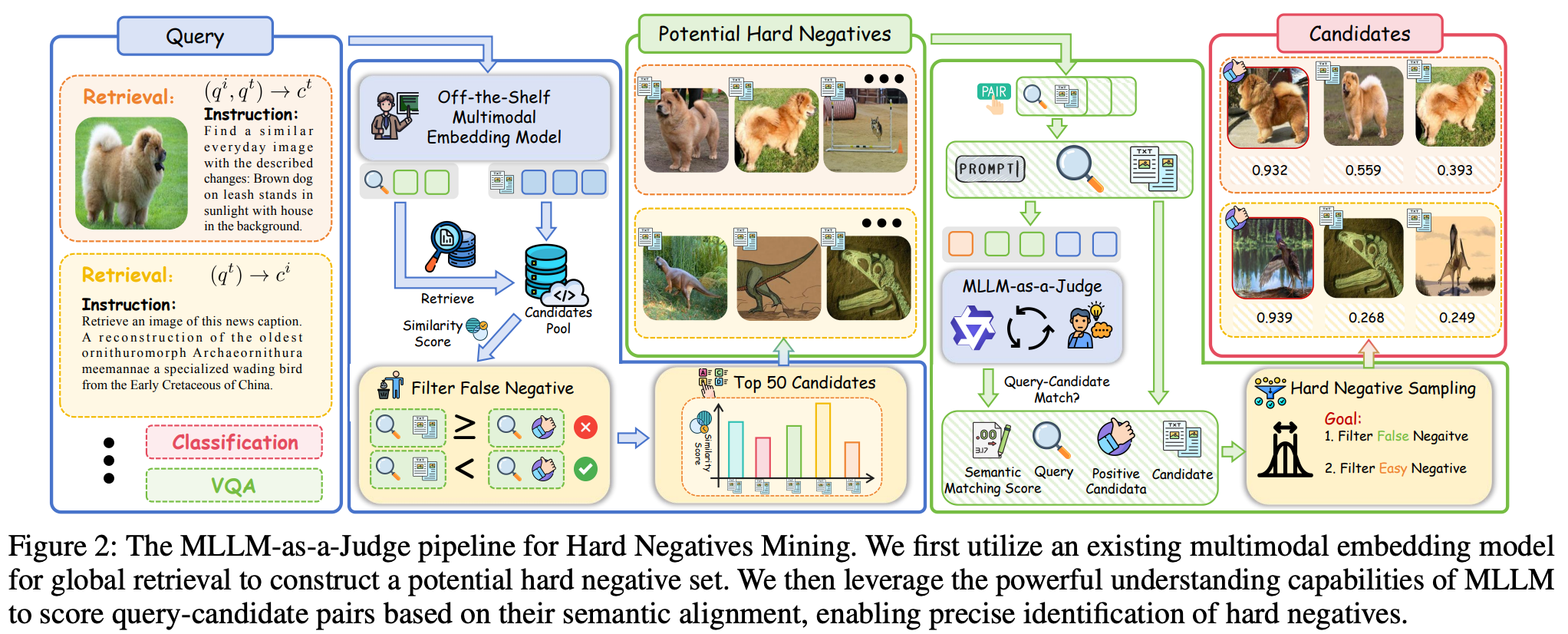
MLLM-as-a-Judge for Hard Negatives Mining
Step1: 构建潜在难负样本集合
使用VLM2Vec模型针对每个query获取candidates中top50的负样本;该过程是一次性离线执行。
Step2: 相似度打分
用Qwen2.5VL-7B的MLLM模型采用下面prompt给每个pair进行相似度打分,该过程MLLM不会被微调,直接拿来用。

Step3: 错误/难负样本采样
- 错误负样本:通过MLLM生成的语义匹配分数(S)来识别。若候选样本的分数超过阈值(\(α = σ_{q,ct - β}\),其中β=0.01),则被判定为错误负样本并排除。
- 难负样本:在排除错误负样本后,剩余的候选样本中,通过循环采样策略(cyclical sampling)选择多样性高的难负样本。若筛选后的样本少于10个,则通过复制或随机选择补充。
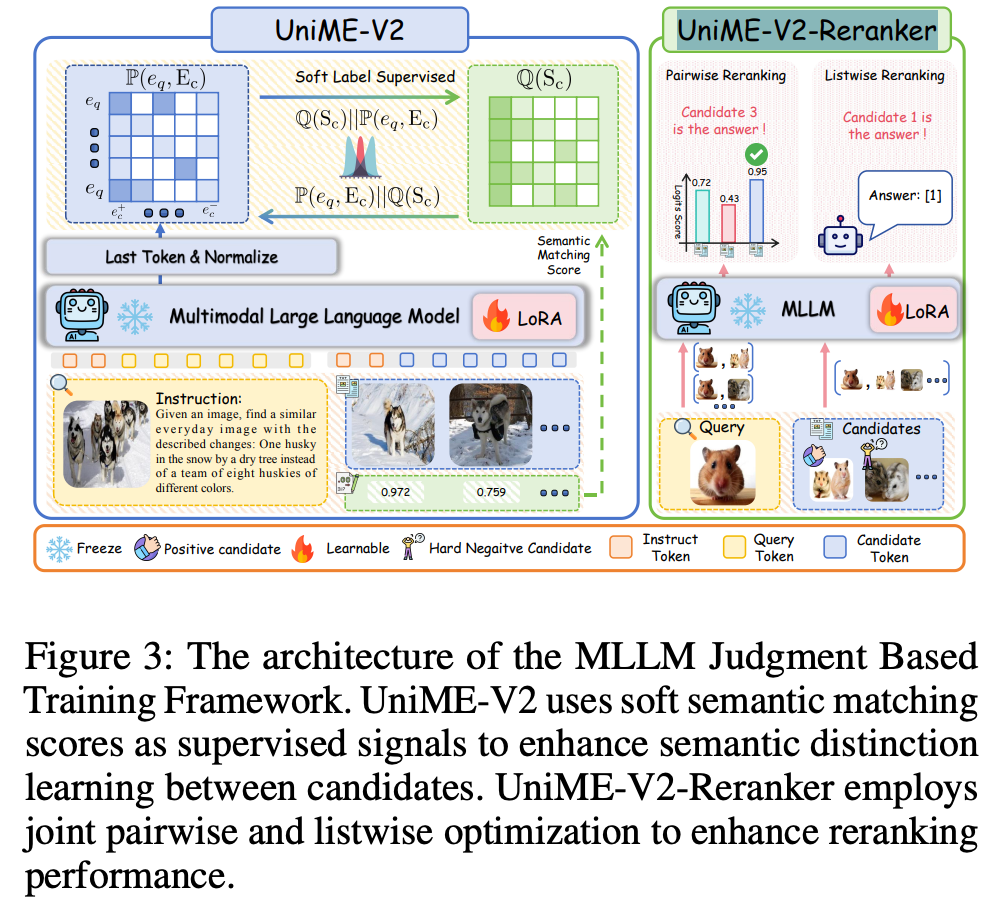
MLLM Judgment Based Training Framework
Loss
使用上一阶段MLLM得到的语义相似度矩阵作为GroundTruth,建立相似度矩阵之间分布的Loss。

UniME-V2-Reranker
- pair-wise loss: query与target样本\(c_t\)间CE Label为1,query与最难的负样本\(c_{h}\)间的CE Label为0。
![image]()
注意pair-wise loss与triplet loss形式比较接近,但两者还是有一些本质区别,例举如下:
![image]()
- list-wise loss: 根据MLLM的相似度分数,提取出top-k的候选,将target随机插入到位置I,让Reranker模型预测对应的位置I。
![image]()
- 总结:
联合 pair-wise(学习基本匹配判别)和 list-wise(学习全局排序)的两种优化方式,提升模型排序能力。最终推理时使用下面prompt提取top1 condidate。
![image]()


Q&A (从上面可以找到答案)
Q: 如何全局检索构建负样本集合?什么样的频率?
Q: MLLM as a judge是什么了什么MLLM模型?错误负样本与难负样本分别如何处理?
Q: UniME-V2-Reranker是一个模型吗?joint-wise与list-wise分别指得是什么?
Q: 整个pipeline有哪些模型需要训练?
a.使用相似度矩阵训练的UniME-V2模型;b.UniME-V2-Reranker模型;
Experiment
主实验

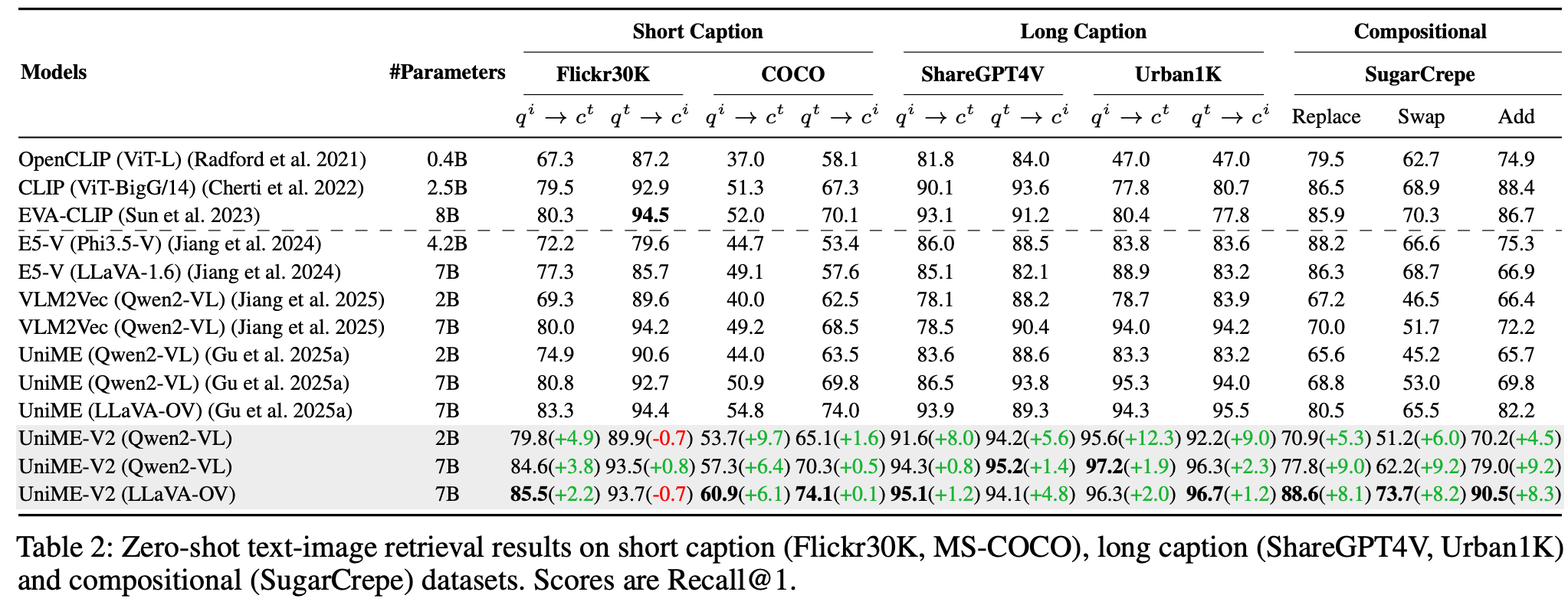
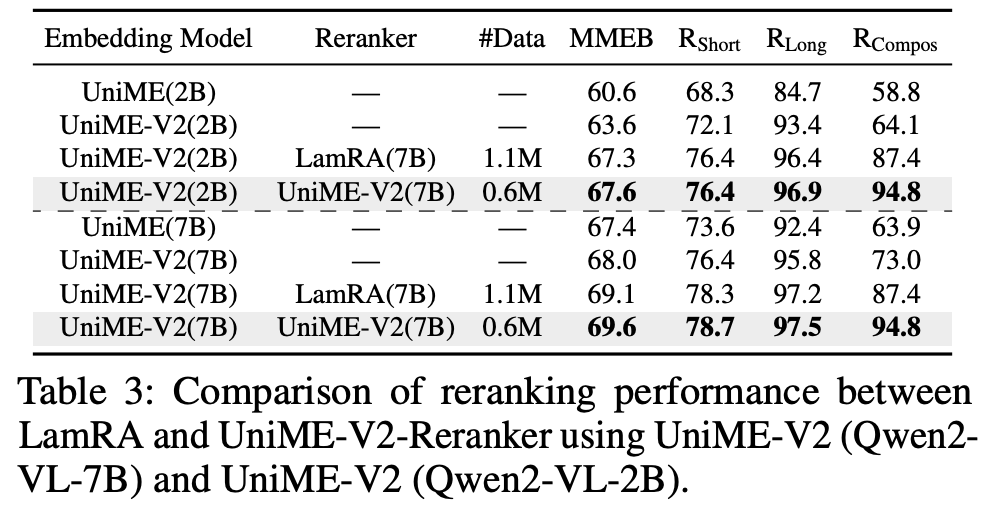
是否用Reranker,用不同Reranker的对比实验
ablation study

不同task

参考链接
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/19173958

 浙公网安备 33010602011771号
浙公网安备 33010602011771号