[PaperReading] VLM2Vec-V2: Advancing Multimodal Embedding for Videos, Images, and Visual Documents
目录
VLM2Vec-V2: Advancing Multimodal Embedding for Videos, Images, and Visual Documents
link
时间:2025.07
单位:Salesforce Research等
相关领域:多模态表征学习
作者相关工作:Rui Meng、Ziyan Jiang
被引次数:1705
项目主页:https://tiger-ai-lab.github.io/VLM2Vec/
TL;DR
之前的方法主要关注image与text,模态种类太少,未使用到视频与视觉文档模态信息,VLM2VecV2解决了该问题。同时,扩充了MMEB Benchmark,也设计了新的统一模型架构VLM2VecV2。
Method
Q:VLM2Vec-V2与原始VLM2Vec算法有什么区别?
- VLM2Vec仅支持文本与图像两种模态,而V2支持了更多,包括:视频、PDF、网页截图、语音(预留接口);
- Data Sampling Strategies:
- on-the-fly batch mixing: 为每个数据集分配特定采样概率;
- Interleaved Sub-batching: 将大批次划分为更小的子批次,每个子批次独立从单一数据源采样;
- multi-modal data formatting
\(q_{inst}\)=inst+[VISUAL_TOKEN]+q
inst: 构造出来的指令,例如,"Find a video that contains this image
VISUAL_TOKEN:用来声明后续q的类型,具体值可以是 image_pad声明“图像”、video_pad声明“视频” 以及 无 声明“文本”
Benchmark
MMEB-V2 Benchmark与MMEB有什么区别? => 蓝色为V1的,红色为V2相对于V1扩充的。
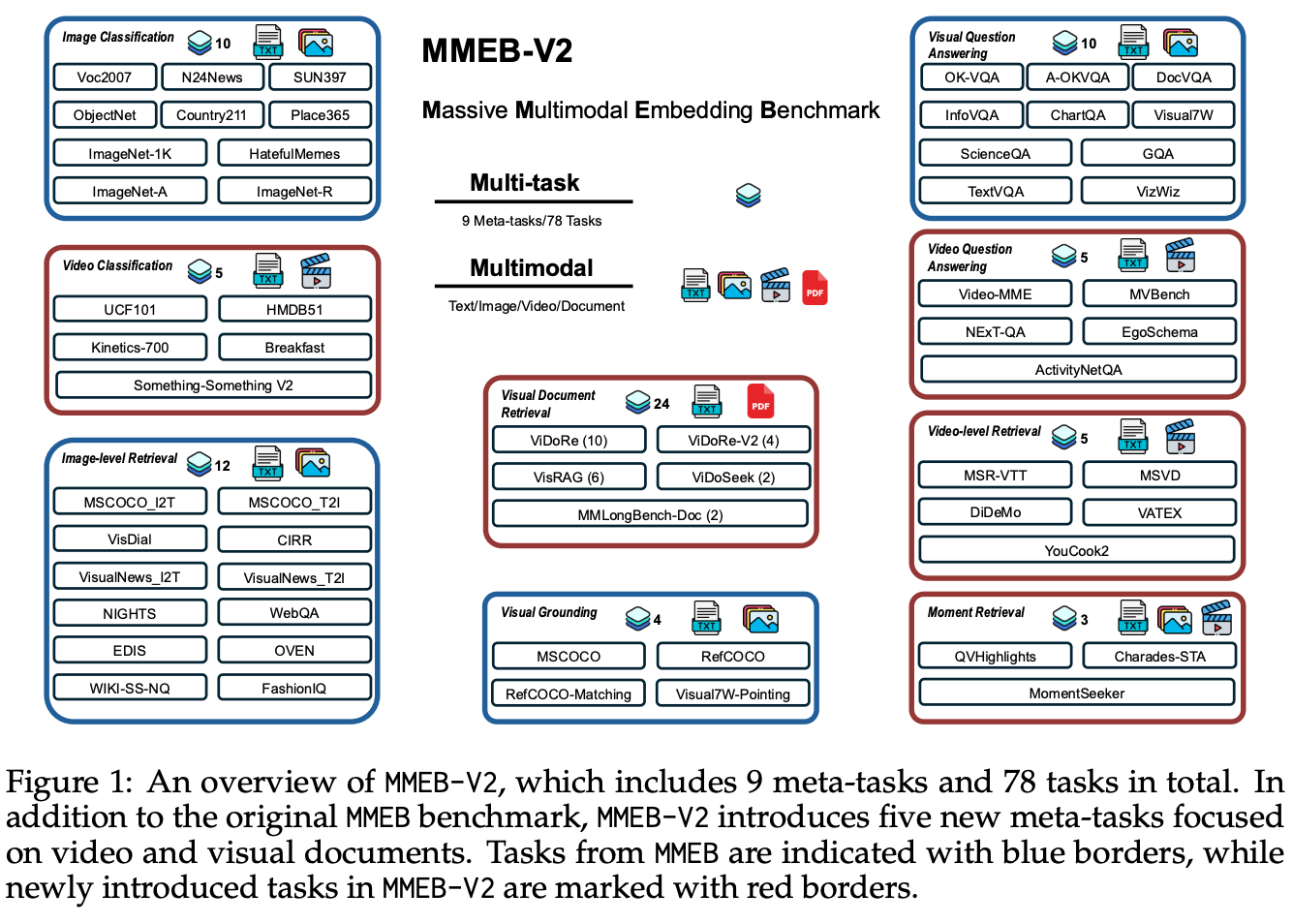
Q&A
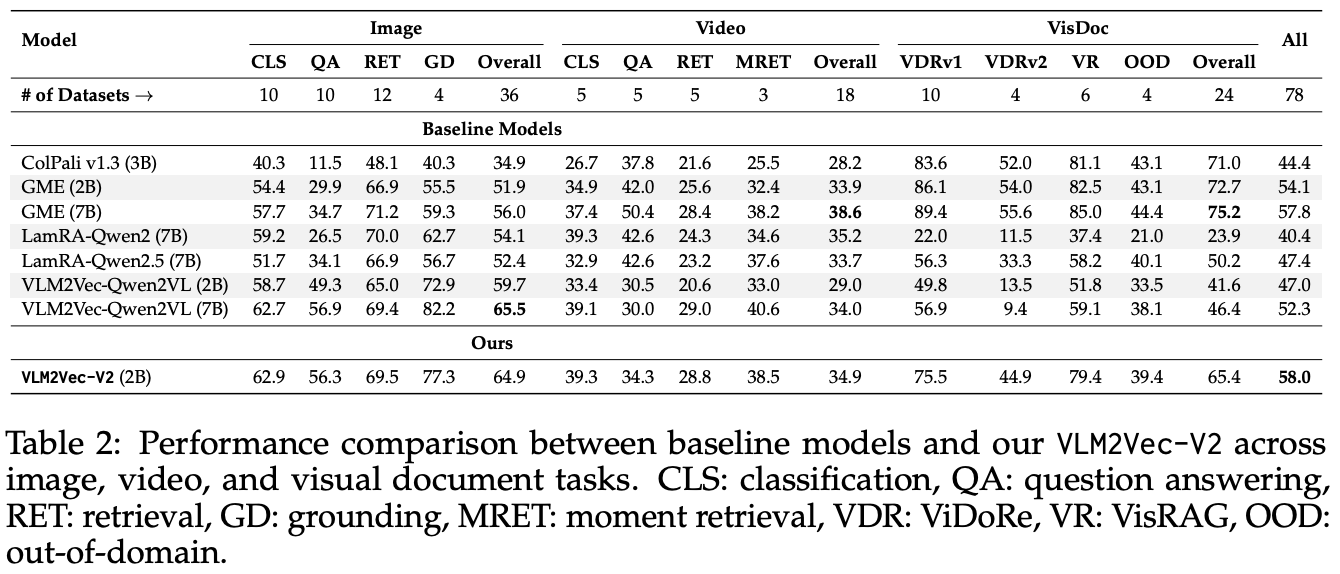
Q:CLS, QA, RET, GD, Overall这些指标是什么含义?
- CLS指标指导特征学习优化
- RET指标指导嵌入空间对齐
- QA指标指导语义理解深化
- GD指标指导细粒度感知提升
Q:训练使用了多少训练集?
Experiment
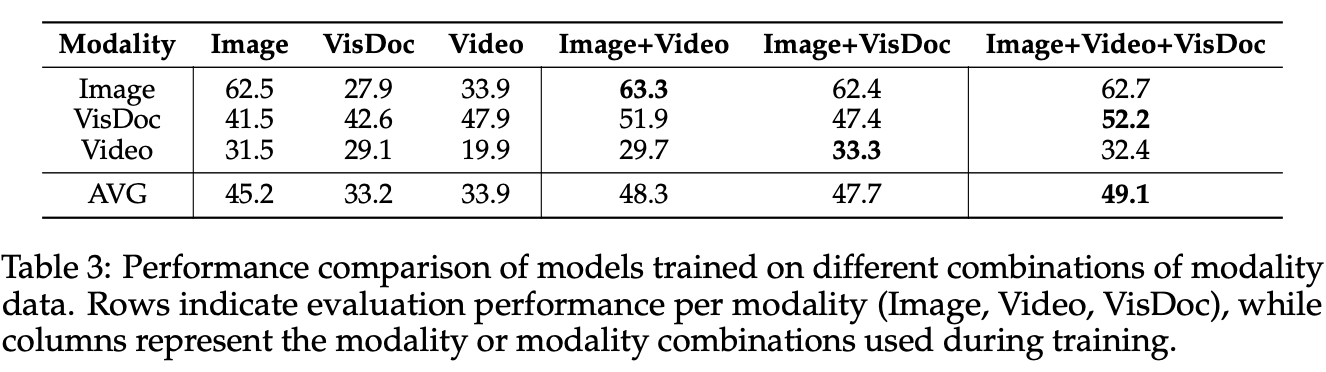
Ablation Study: 增加更多视觉模态是能继续涨点的
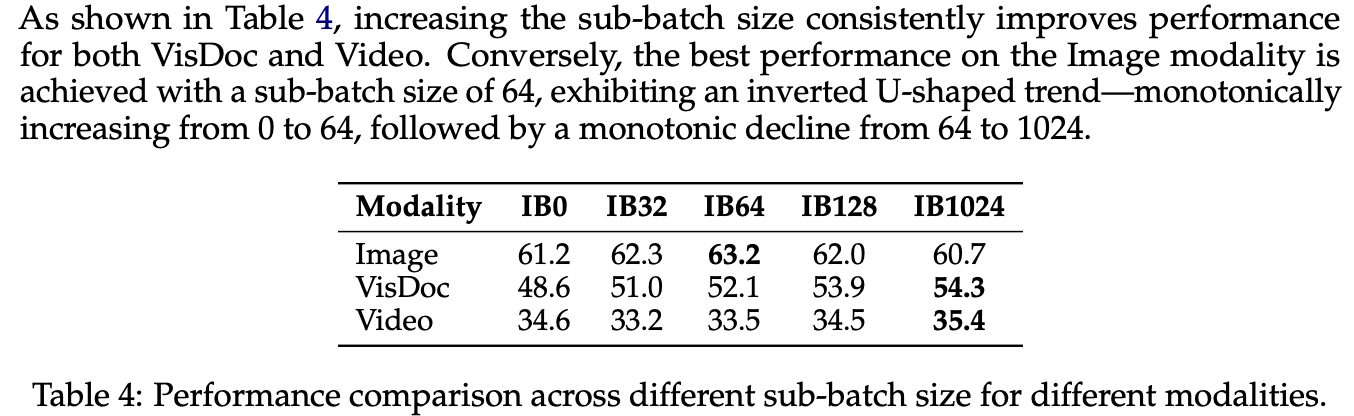
sub-size超参数的Ablation,最佳值为64

参考链接
总结与思考
无
相关链接
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/19148600

 浙公网安备 33010602011771号
浙公网安备 33010602011771号