[PaperReading] KIMI K2: OPEN AGENTIC INTELLIGENCE
KIMI K2: OPEN AGENTIC INTELLIGENCE
link
时间:25.07
单位:Moonshot AI
相关领域:大模型、Agent
被引次数:暂无
项目主页:https://moonshotai.github.io/Kimi-K2/
TL;DR
提出MuonClip优化器,使用QKClip技术解决训练不稳定问题。模型Size:原始模型1T参数量,MoE激活参数量为32B。在15.5T tokens上预训练,后训练分存在多个阶段,其中两个关键阶段:大规模agent数据合成pipeline;一个通用的RL学习框架。
Method
QK-Clip
在Transformer Attention中,什么是attention logits爆炸问题?
核心原因:点积的方差会随着维度的增加而增大。
让我们来分析一下。假设 Q 和 K 中的向量元素都来自于一个均值为 0、方差为 1 的分布(这在模型初始化后是很常见的情况)。那么,它们中任意两个向量 q 和 k 的点积 score = q · k = Σ(q_i * k_i) 的性质是什么呢?
均值: E[score] 仍然是 0。
方差: Var(score) 会变成 d_k。
这意味着,d_k 维度越大,点积算出来的 Attention Scores 的波动范围(方差)就越大。 当 d_k 很大时,一些点积的结果绝对值有可能会变得非常大,这就是所谓的“Logits 爆炸”。
负面影响
将上述attention logits送入softmax后,由于softmax函数对非常大的输入值极为敏感。假设我们有一组 Logits:[2, 5, 50]。
经过 softmax 后,由于 e^50 远远大于 e^2 和 e^5,结果会变得非常接近一个 one-hot 向量:[0, 0, 1]。
这会导致:注意力分布过于尖锐,模型对于训练结果非常自信,即使预测错误梯度也无法回传。
Attention is All You Need在设计Attention时便考虑到但该问题,所以输入softmax之前会先除以sqrt(d_k),但这并未根本上解决该问题(实际上Q/K中元素并不一定服从\(N(0, 1)\)。
Attention Weights = softmax( (Q @ K^T) / sqrt(d_k) )
QKClip为什么能解决attention logits爆炸的问题?
![]()
![]()
做法非常直观,将大于某阈值\(\gamma\)的点积进行截断,实际实现是对于这类情况计算出一个系数用来rescale \(W\)。
![]()
Algorithm

Pre-training Data
rephrasing
- 风格和视角多样的提示 (Style- and perspective-diverse prompting):
做法:他们精心设计了各种各样的指令(Prompts),来引导一个大语言模型(可能是 Kimi 自身或其他模型)对原始文本进行改写。
例子:比如,对于一段维基百科的文字,他们可能会用这样的指令:“请将这段文字改写成适合高中生阅读的科普风格”、“请以第一人称的视角复述这段历史事件”、“请用批判性的口吻总结这段文字的观点”。 - 分块自回归生成 (Chunk-wise autoregressive generation):
问题:直接让模型重写一篇很长的文章很困难,它可能会写到后面忘了前面,或者丢失全局的连贯性。
解决方案:他们将长文章切分成小块(chunks),逐块进行改写。在改写每一块时,都会把前面的内容作为上下文,保证衔接自然。最后再把所有改写好的小块拼接成完整的新文章。这是一个非常实用的工程技巧,确保了长文本改写的质量。 - 保真度验证 (Fidelity verification):
目的:这是质量控制步骤。为了防止改写过程中出现事实错误或语义偏差(即“胡说八道”),他们会进行自动检查。
做法:通过对比改写后的文本和原文的语义相似度,确保新版本忠实于原始内容。只有通过验证的高质量改写版本才会被加入到最终的训练数据中。
实验验证:证明“复述”比“重复”更有效
策略一(基准):不复述,直接将原始数据重复训练 10 遍。
策略二:将原始数据复述 1 遍,然后将这个新版本重复训练 10 遍。
策略三:将原始数据复述 10 遍(得到10个不同的版本),每个版本只训练 1 遍。
三个版本的对比实验结果如下:

Model Architecture
与DeepSeekV3结果非常相似,超参数以及对应模型参数量变化如下表所示:
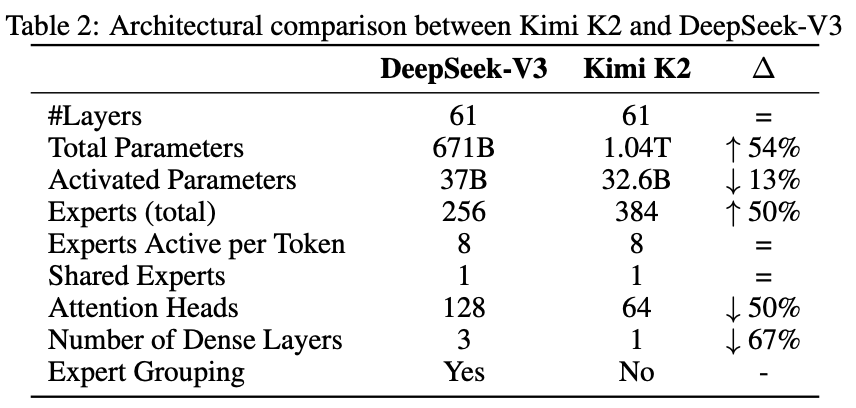
Training Infra
- Parallelism for Model Scaling: 16-way Pipeline Parallelism (具体是Interleaved 1F1B), 16-way Expert Parallelism (EP), ZeRO-1 Data Parallelism
- Activation Reduction: Selective recomputation、FP8 storage for insensitive activations、Activation CPU offload
PostTraining
SFT + RL
大规模agent数据合成pipeline
目标: 建立一个庞大且多样的“工具箱”。
做法:
从真实世界获取: 他们从 GitHub 等代码仓库中收集了超过 3000 个真实的、高质量的工具规格(Tool Specs)。一个“工具规格”就像一个 API 的说明书,定义了工具的名称、功能描述、输入参数和格式等。
用 AI 创造: 他们还使用 LLM 来“进化”和“创造”出超过 20000 个全新的、覆盖金融、医疗、游戏等各种领域的合成工具。
意义: 这一步为后续的训练提供了丰富多样的“原材料”。模型将要学习的,就是如何使用这个包含超过 23000 种工具的庞大工具箱。
目标: 创造出使用工具的“角色”和需要解决的“问题”。
做法:
生成智能体 (Agent): 流水线会从工具箱中抽取一组相关的工具,然后围绕这组工具创造一个“智能体”角色。例如,抽取了“航班查询”和“酒店预订”工具后,就创造一个“旅游规划助手”的角色。他们生成了数千个拥有不同能力、专业领域和行为模式的智能体。
生成任务 (Task): 针对每个智能体和它的工具,流水线会生成一系列从简单到复杂的任务。比如,给“旅游规划助手”生成任务:“帮我找一张下周一从北京到上海的、价格最便宜的机票”。每个任务都配有明确的成功标准(Rubrics),方便后续评估。
意义: 这一步让训练场景变得具体而真实。模型学习的不是孤立的工具调用,而是一个特定角色为了完成一个特定目标而进行的一系列操作。
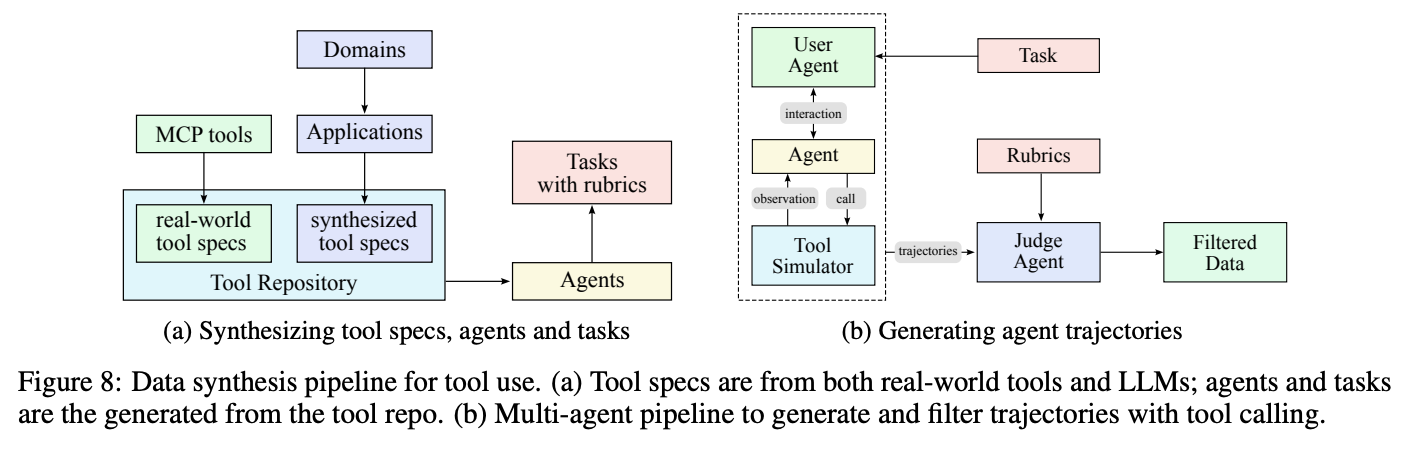
RL算法
RL算法复用K1.5,参考
Reward方面:针对数据、编程等可验证任务,使用Verifiable Rewards;针对于 没有标准答案、依赖主观判断的任务,通过Critic模型来打分,区别与传统RLHF中的Reward机制,这里Actor和Critic 是同一个模型或共享大部分权重,只是在扮演不同角色。
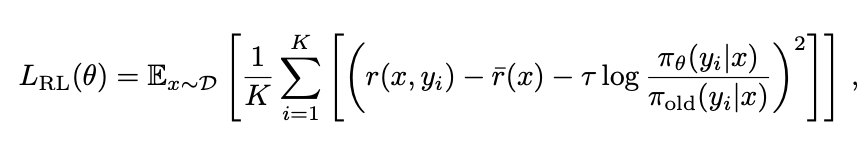
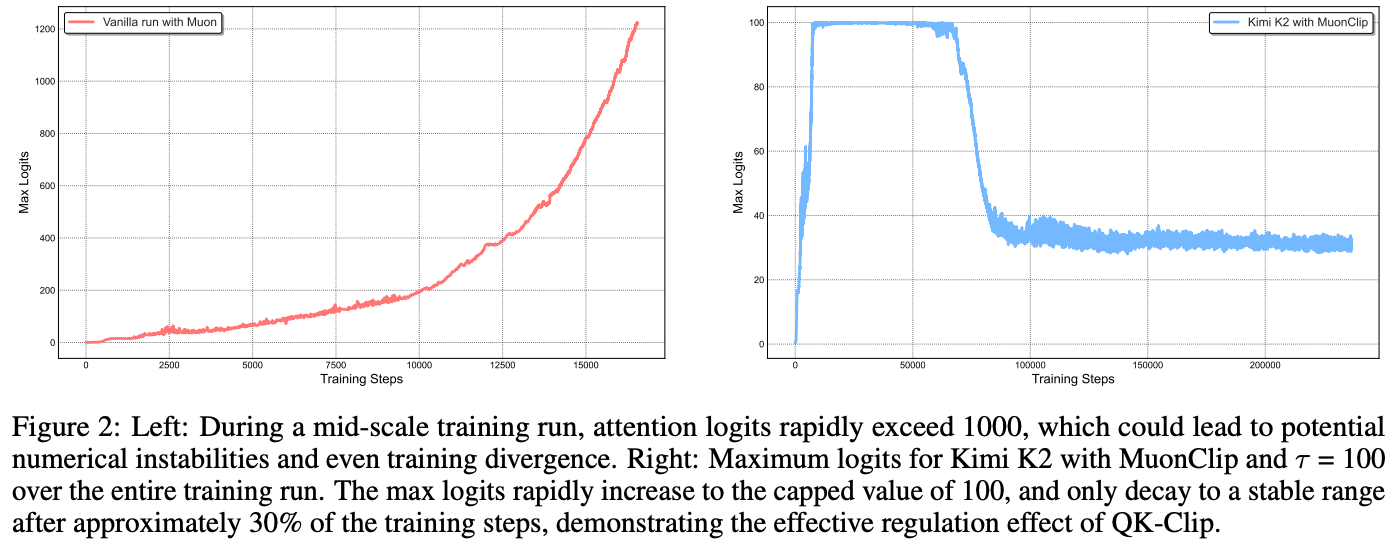
Experiment
QKClip之后,相对于普通Attention,logits爆炸问题确实被截断,并且截断后会逐步恢复到正常。
总结与思考
无
相关链接
https://www.zhihu.com/question/1927140506573435010/answer/1927892108636849910
Related works中值得深挖的工作
资料查询
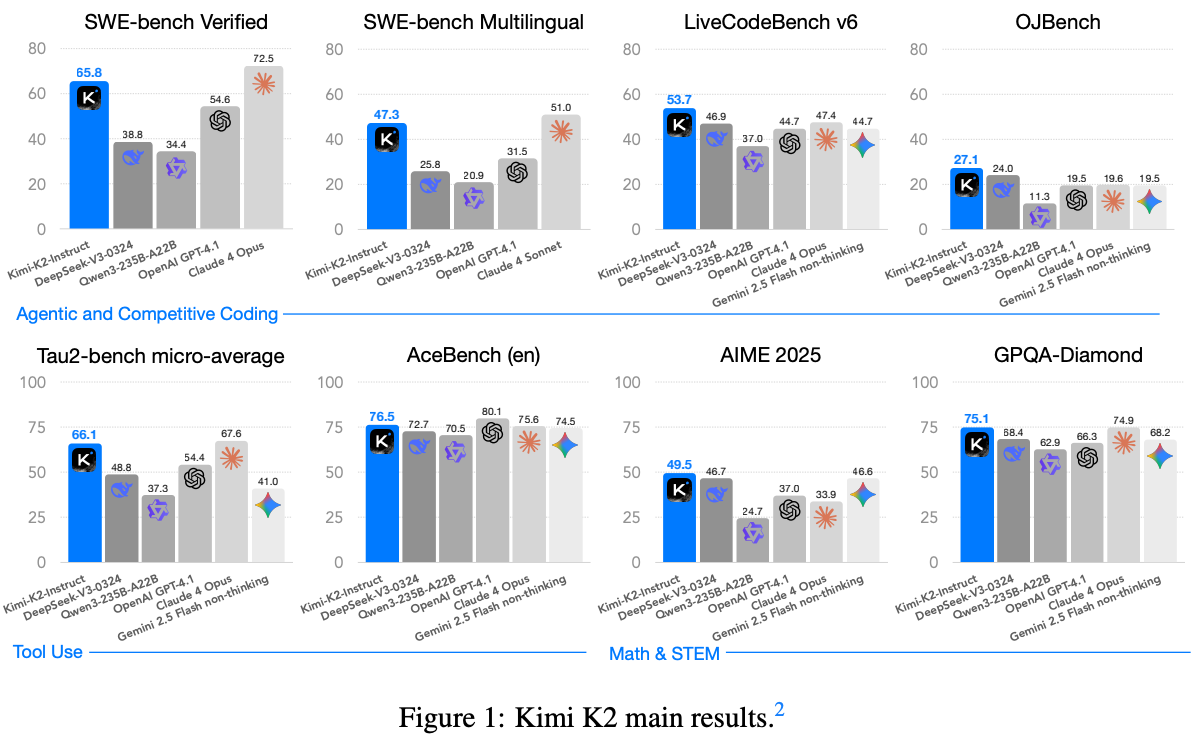
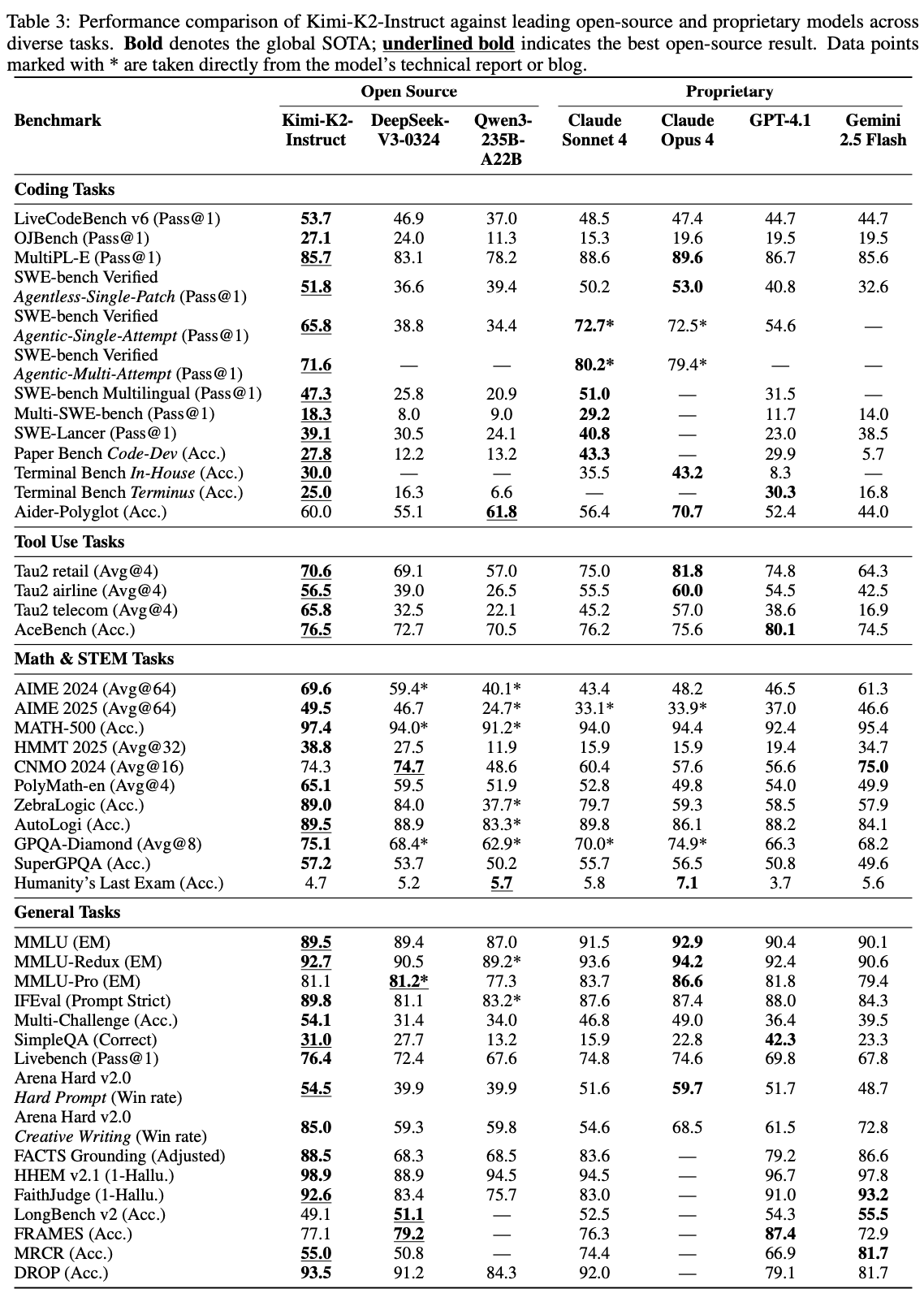
请介绍一下大本文所提到大模型benchmark
类别一:智能体与工具使用 (Agentic & Tool Use)
这类基准的核心是评测模型能否像一个智能体一样,理解复杂任务,制定计划,并调用外部工具(如代码解释器、搜索引擎、计算器)来解决问题。
- Tau2-Bench
评测内容: 专门为评测大模型的工具使用能力而设计。任务通常需要模型决定使用哪个工具、如何调用,并根据工具返回的结果来生成最终答案。
重要性: 这是衡量模型“智能体”能力的核心指标。一个高分意味着模型不仅能“说”,还能“做”。它标志着模型从一个语言生成器向一个可以执行任务的实用助手的转变。
- ACEBench (En)
评测内容: 全称为 "Agentic Capabilities Evaluation Benchmark"(智能体能力评测基准)。它包含了一系列需要多步骤规划和执行的复杂任务,全面评估模型的规划、推理和与环境互动的能力。"(En)" 指的是英文版本。
重要性: 与 Tau2-Bench 类似,但可能更侧重于任务的复杂性和多步骤规划。ACEBench 的高分表明模型具备了解决真实世界复杂问题的潜力,例如自动完成“帮我预订一张明天去上海的机票并加入我的日历”这类任务。
类别二:软件工程与编程 (Software Engineering & Coding)
这类基准评测模型在编程领域的深度能力,从解决算法竞赛题到修复真实世界软件的 Bug。
- SWE-Bench (Verified & Multilingual)
评测内容: “软件工程基准”(Software Engineering Benchmark)。这不是简单的代码生成,而是给模型一个真实的 GitHub 代码仓库中的真实 Issue(Bug 报告),要求模型自动定位问题、编写代码补丁(Patch)来修复它,并成功通过所有测试。
Verified: 指的是测试集中那些被验证过、有明确解决方案的子集,结果更可靠。
Multilingual: 指的是评测模型在多种编程语言(如 Python, Java, C++ 等)的代码库上修复 Bug 的能力。
重要性: 这是目前最接近真实软件开发工作的基准之一,难度极高。在此基准上的优异表现,直接证明了模型作为“AI 程序员”的巨大潜力。
- LiveCodeBench v6
评测内容: 一个“活的”编程基准。它的测试问题来源于最近的、真实的在线编程竞赛(如 LeetCode, Codeforces)。这可以有效避免模型因为在训练数据中见过类似题目而“作弊”。
重要性: 它衡量的是模型真正的、实时的编程和算法推理能力,而不是对已有知识的记忆。v6 代表这是该基准的第六个版本,说明它在持续更新以保持挑战性。
- OJBench
评测内容: “在线评测系统基准”(Online Judge Benchmark)。它整合了来自多个在线编程平台的大量问题,全面覆盖了各种算法和数据结构。
重要性: 这是一个广谱的编程能力测试,可以全面地评估模型算法基础的扎实程度。
类别三:高级推理与数学 (Advanced Reasoning & Math)
这类基准用于评测模型在需要深度、抽象和多步推理的领域(如高等数学、研究生级别的科学问题)的能力。
- AIME 2025
评测内容: AIME 是“美国数学邀请赛”(American Invitational Mathematics Examination)的缩写,是极具挑战性的高中数学竞赛。题目通常需要巧妙的解题思路和严谨的逻辑推理。AIME 2025 基准很可能是指使用了达到此竞赛难度级别的问题集。
重要性: 这是对模型纯数学推理能力的严苛考验。一个高分意味着模型不仅仅是计算器,而是具备了理解抽象数学概念并进行创造性问题解决的能力。
- GPQA-Diamond
评测内容: GPQA 全称是 "Graduate-level, Google-Proof Q&A"(研究生水平、谷歌难题问答)。这些问题专业性极强(覆盖物理、化学、生物等),即使是相关领域的专家也很难直接用搜索引擎找到答案,必须依赖深厚的知识储备和推理能力。
Diamond: 通常指 GPQA 数据集中最困难的一个子集。
重要性: 这是衡量模型是否真正“理解”知识而非仅仅“记忆”信息的黄金标准。它迫使模型进行深度的、基于第一性原理的推理,是迈向通用人工智能(AGI)的关键评测方向。
总结
基准名称 (Benchmark) 主要评测方向 挑战与意义
Tau2-Bench 智能体 - 工具使用 模型能否决定使用何种工具并与之交互来完成任务。
ACEBench (En) 智能体 - 复杂任务规划 模型能否为多步骤的复杂目标制定并执行计划。
SWE-Bench 软件工程 - 真实 Bug 修复 衡量模型在真实、大型代码库中定位和修复问题的能力。
LiveCodeBench v6 编程 - 实时算法竞赛 评估模型面对全新、未见过问题的实时算法推理能力。
OJBench 编程 - 广谱算法能力 全面考察模型对基础算法和数据结构的掌握程度。
AIME 2025 数学 - 高等数学竞赛 考验模型在抽象数学领域的深度逻辑推理能力。
GPQA-Diamond 推理 - 顶尖专家级难题 评估模型能否解决无法被轻易搜索、需要深度知识的难题。
总而言之,Kimi K2 在这些基准上取得的优异成绩,表明它不仅仅是一个强大的语言模型,更是一个在软件工程、智能体任务和高难度推理方面都具备顶尖能力的、非常实用的 AI 工具。
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/19017720

 浙公网安备 33010602011771号
浙公网安备 33010602011771号