[PaperReading] KIMI K1.5: SCALING REINFORCEMENT LEARNING WITH LLMS
KIMI K1.5: SCALING REINFORCEMENT LEARNING WITH LLMS
link
时间:25.06
单位:kimi
被引次数:359
项目主页:
https://github.com/MoonshotAI/Kimi-k1.5
TL;DR
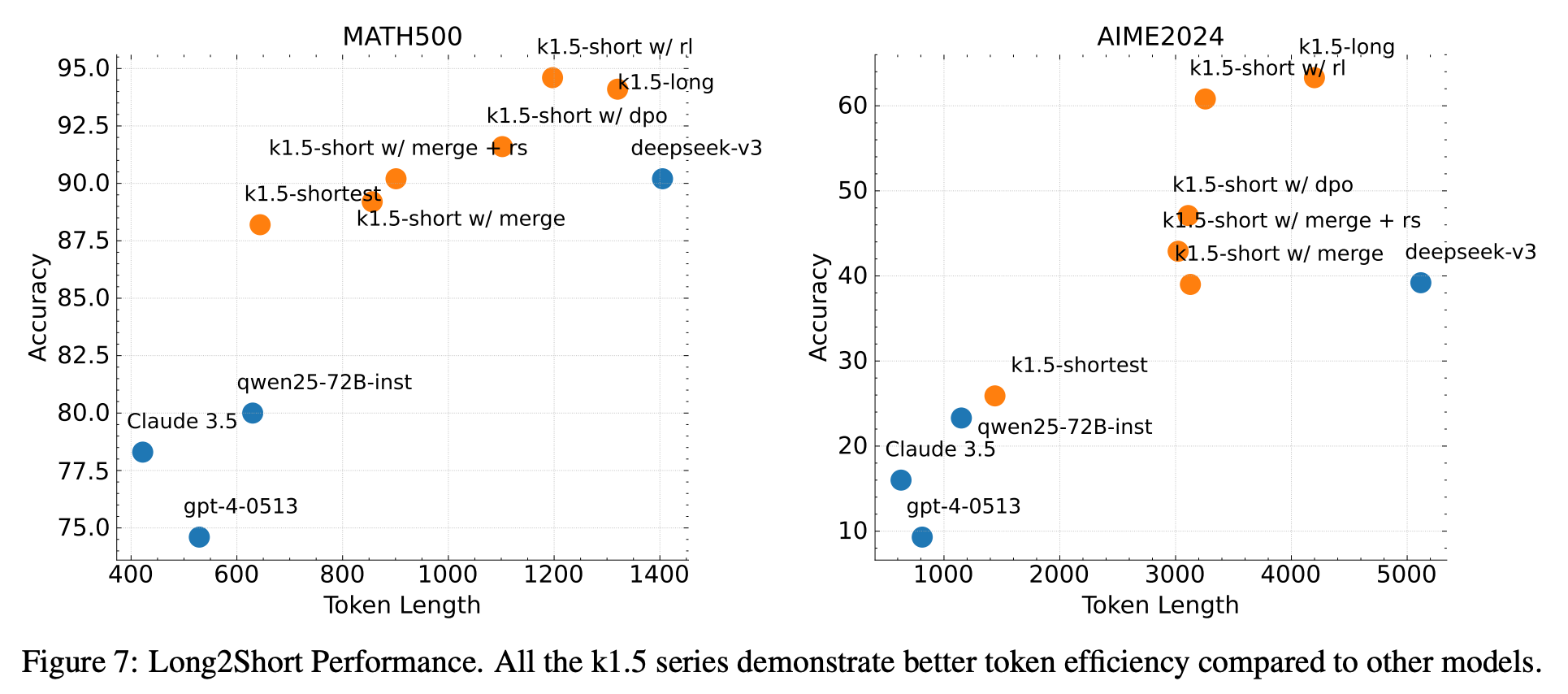
kimi K1.5介绍了RL training techniques, multi-modal data recipes, and infrastructure optimization三方面改进,方法的关键点是Long context scaling and improved policy optimization。效果方面,LongCoT版本在AIME Benchmark上达到77.5的score,在shortCoT推理任务上,AIME也达到60.8的效果。
Method
RL Prompt Set制作
好的prompt set需要考虑以下三方面:
- Diverse Coverage:设置自动过滤机制,并从竞赛、通用推理数据源头上保证prompt覆盖丰富性;
- Balanced Difficulty:将prompt推理10次,根据通过率来判断prompt的难度系数;
- Accurate Evaluability:从推理过程及验证结果两方面判断评估的合理性,避免reward被hack;
Long-CoT Supervised Fine-Tuning
通过Rejection Sampling(人工筛选验证),保留高质量长链思维数据用于SFT监督微调,该过程将人类推理过程(如规划、反思、纠错)编码到模型中,为后续RL训练提供高质量的初始策略。
强化学习算法
相对于GRPO的区别:
- KL散度的表达有些不同(详细参考原文2.3.2小节,公式推导参考 知乎文章)
- \(\bar{r}\)统计自不同prompt奖励的均值,而GRPO中统计自同一个prompt多次output
\(\bar{r}\)统计自不同prompt奖励的依据:We sample a batch of problems from D and update the parameters to θi+1, which subsequently serves as the reference policy for the next iteration.
长度惩罚
同一个prompt会采样多次,统计max_len与min_len来计算每次response的reward,从下面公式来看,如果response命中结果的话,对应的length reward \(\lambda\)介于[-0.5, 0.5]区间,直观上理解就是鼓励短response,惩罚长response。
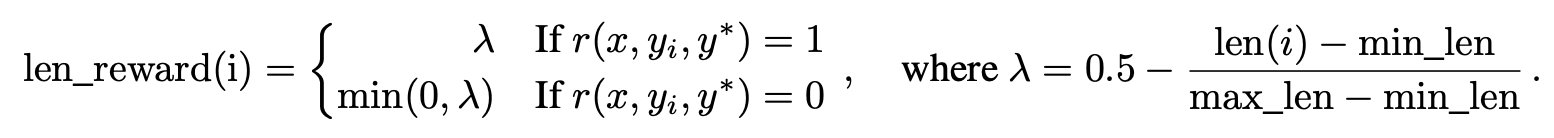
采样策略
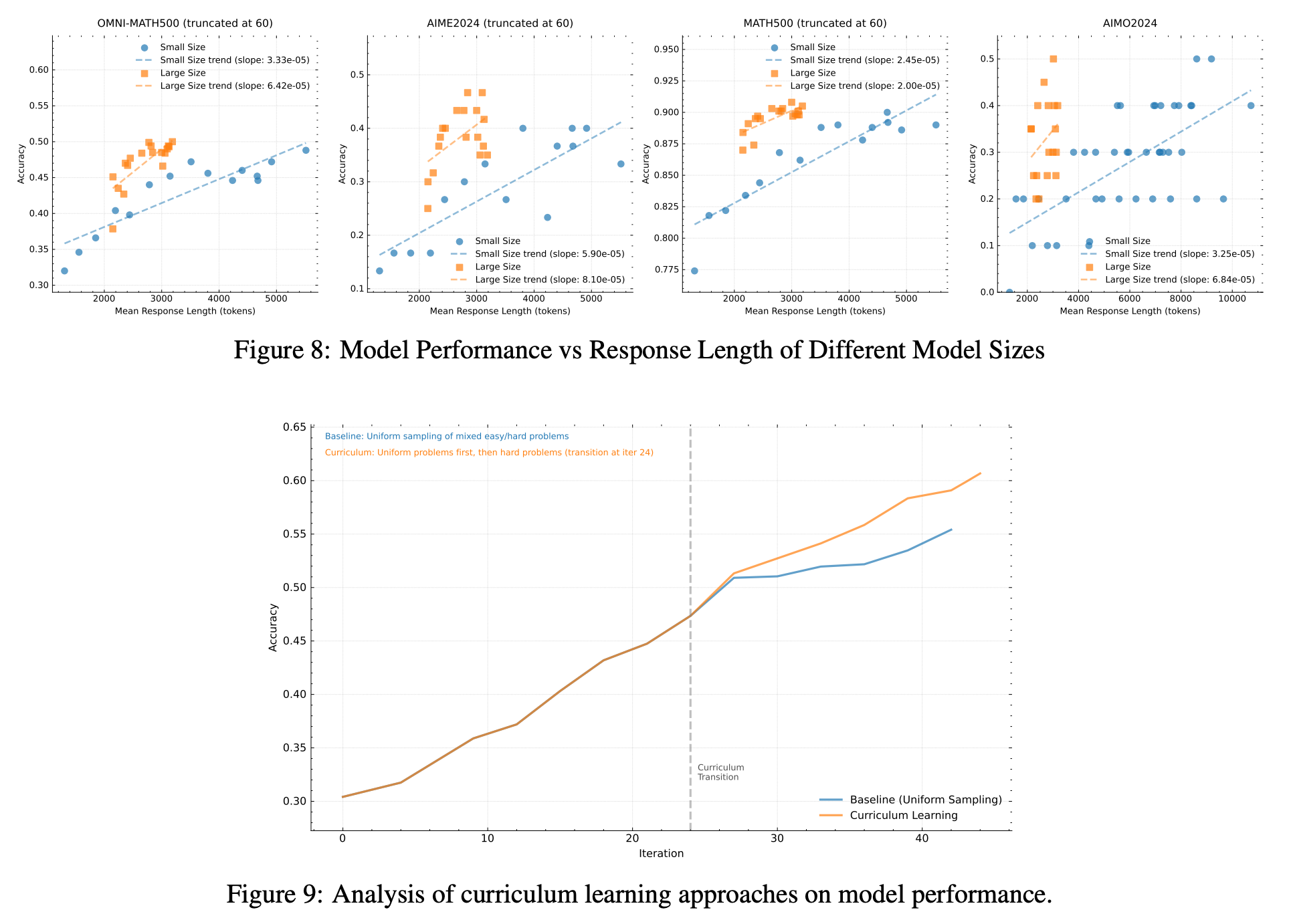
Curriculum Sampling:前面提到,在RL Prompt Set制作过程每个prompt根据多次采样的pass rate及数据来源标注难度等级,这里采样时可以从Easy到Hard采样,提升学习效率;
Prioritized Sampling: 实时维护problem的通过率,根据通过率更新样本的优先级,低通过率的样本被赋予更高的采样概率;
视觉数据
真实数据、合成数据、text render三部分来源
Long2short CoT模型
long-Cot生成比较浪费token,如何降低生成token长度并且保留CoT能力。
Model Merging
将longCoT与shortCoT权重进行简单的平均,该策略不仅能输出合理结果,并且也能保持模型的CoT能力。
Shortest SFT
同一个prompt生成n个response,将最短的正确回答记录下来,用于SFT训练。
DPO
同一个prompt生成n个response,将最短作为正样本,最长的作为负样本,以此来构造DPO训练集。
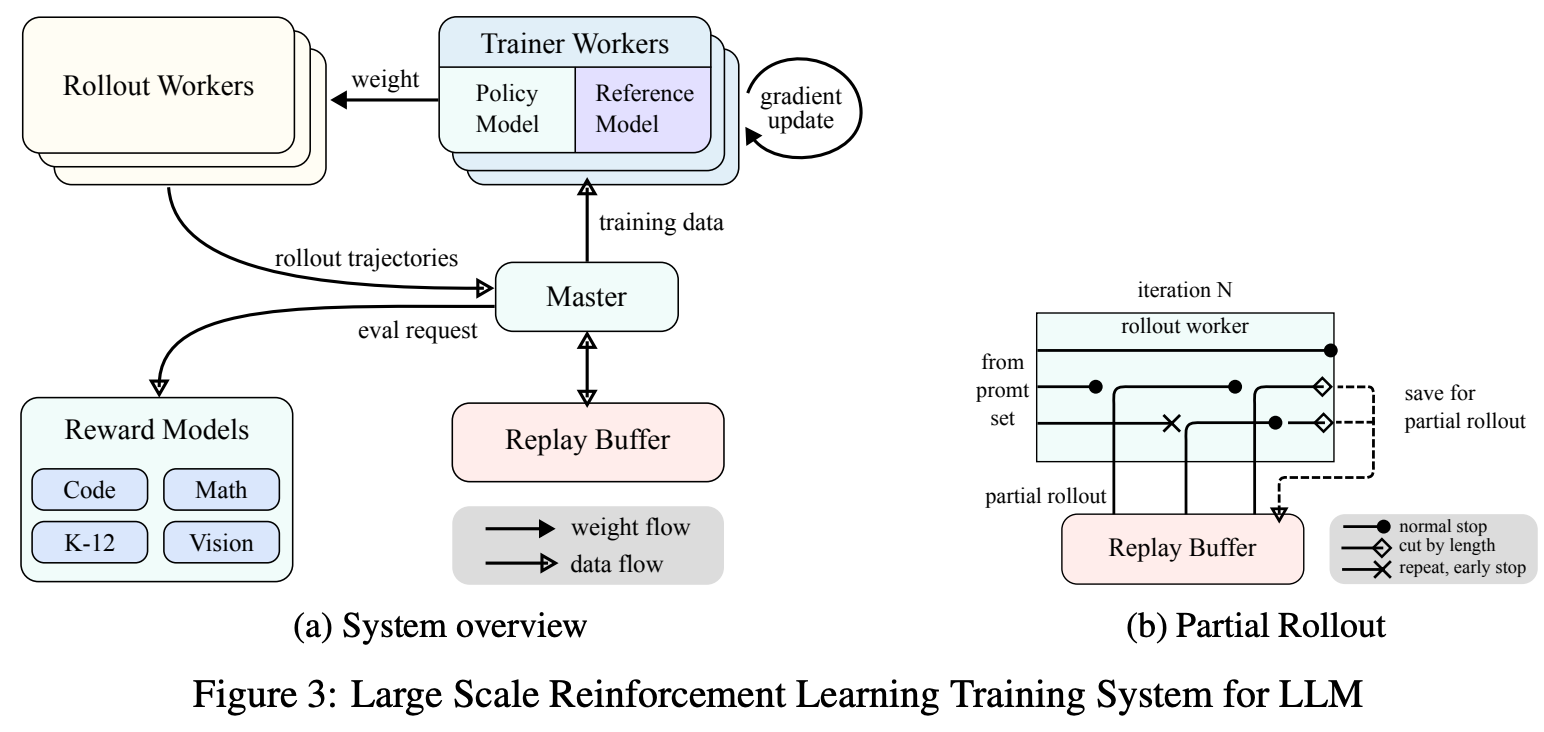
RL Infrastructure
参考原文2.6小节
Experiment
总结与思考
- 2024年12月5日发布o1,kimi摸着o1过河,于半年后发布K1.5,干货挺多的
- kimi作者在思考历程中的很多参考工作值得学习一下
相关链接
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18996336

 浙公网安备 33010602011771号
浙公网安备 33010602011771号