[PaperReading] Flamingo: a Visual Language Model for Few-Shot Learning
Flamingo: a Visual Language Model for Few-Shot Learning
link
时间:22.04 (NeurIPS 2022)
单位:DeepMind
相关领域:Visual Understanding
作者相关工作:gemini
被引次数:5161
TL;DR
DeepMind提出一种VLM方法,将视觉与text pretrain预训练模型融合起来,能够无缝将视觉与文本token融合,在VQA/Captioning/Few-shot等多个Benchmark上超过在对应数据集Finetune的方法。
Method
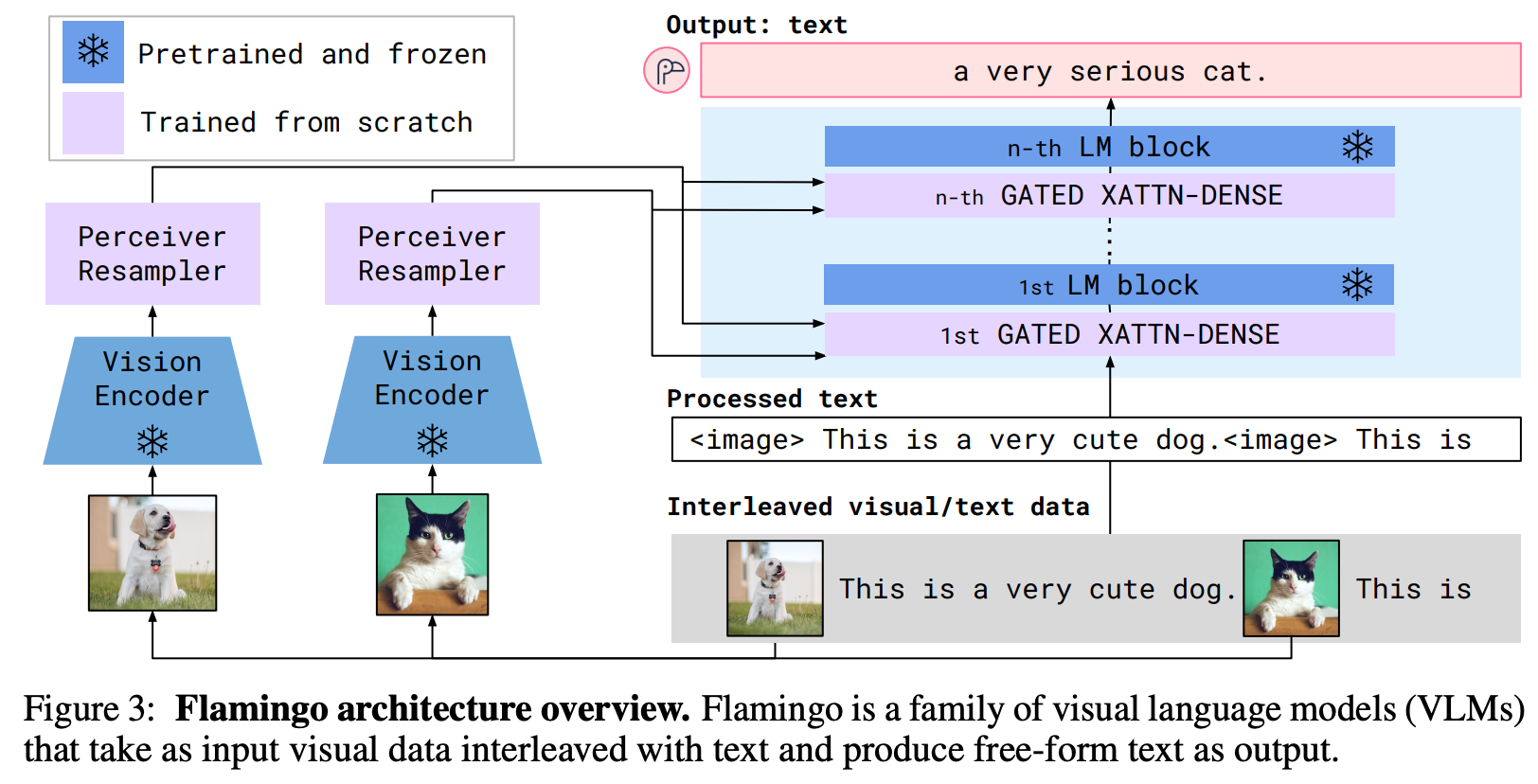
Visual processing and Perceiver Resampler
Visual processing: 使用CLIP预训练的visual-encoder来抽取图像特征,如果是视频模态,则以1FPS帧率出取逐帧的视觉特征。视觉Backbone使用的ResNet,LM使用的 Chinchilla model(分别使用了1.4B/7B/70B版本)语言模型。
Perceiver Resampler: 将上述视觉特征转换为visual token sequence(有点类似于Adapter),一方面可以减少计算量,另外也在Ablation Study中证明了可提升效果。同时,类似于DETR或者ViT的class token,预定义了latent token来交叉融合视觉特征。
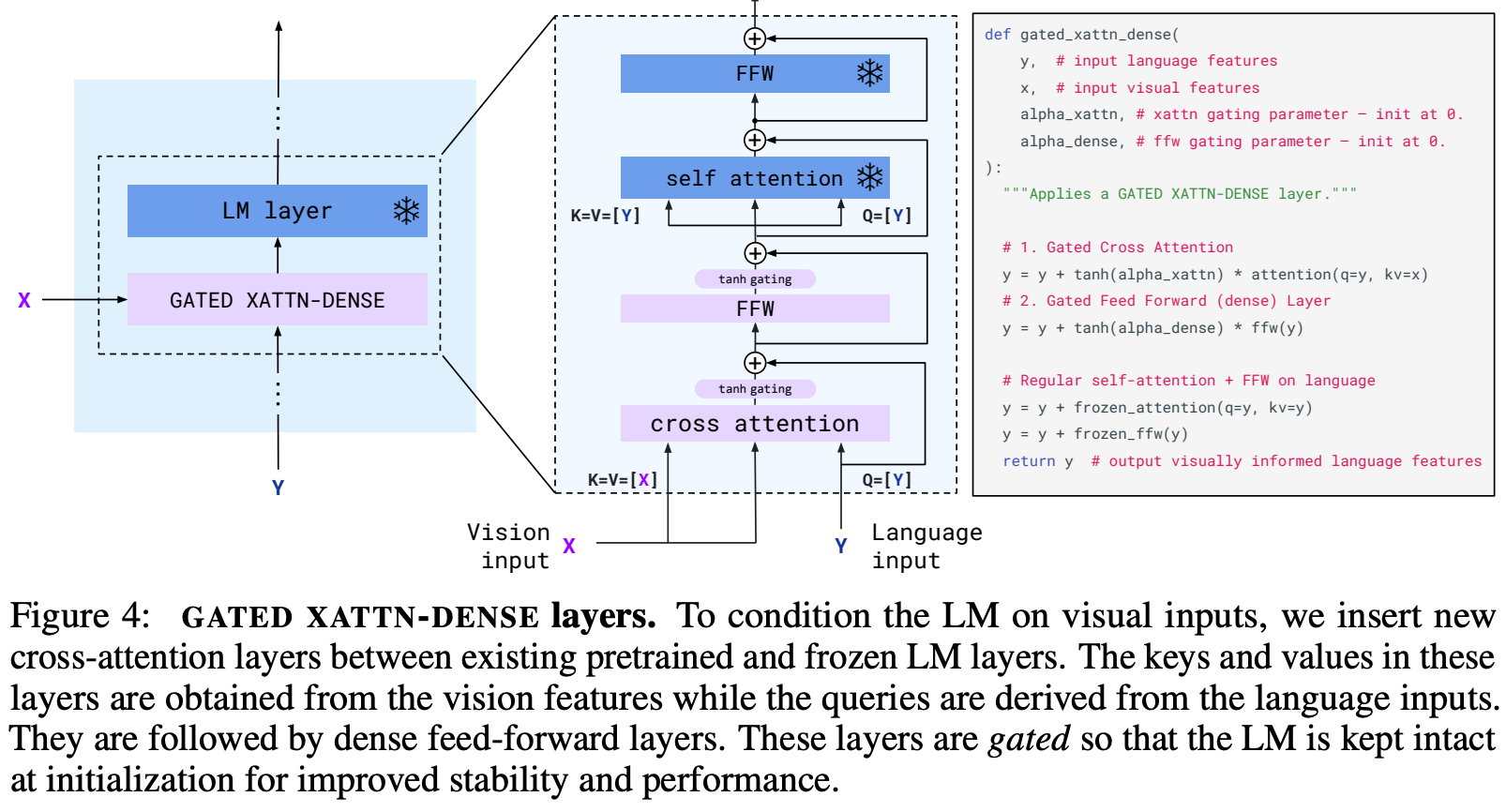
GATED XATTN-DENSE layers
模型架构图中关键模块是GATED XATTN-DENSE layers,其模块结构如下。该模块用来将vision特征作为condition使用cross-attention融合入LM中。具体而言,visual tokens作为K/V,text token作为query,cross-attention融合得到多模态特征,该特征经过\(tanh(\alpha)\)的加权再与原始纯LM tokens融合。\(\alpha\)是可学习的并且从零初始化,这么做的好处是训练刚开始多模态特征还不稳定,训练结果更依赖于LM输出,增加训练初期的稳定性(有点类似于ControlNet中的ZeroInit)。
Mixture of Vision and Language Datasets
M3W: Interleaved image and text dataset: 自建的43M网页数据集M3W(MultiModal MassiveWeb),过滤了低质量文本数据 以及 图太小的数据。
Pairs of image/video and text:使用ALIGN数据集,包含1.8M图文样本对,在此基础上补充了312M的自建图文样本对,区别于原始ALIGN数据,自建数据中的text为Long Text文本。
Multi-Dataset Training:如下公式所示,在不同数据集前加入了固定权重系数\(\lambda_m\),实验证明该系数对于效果很重要。
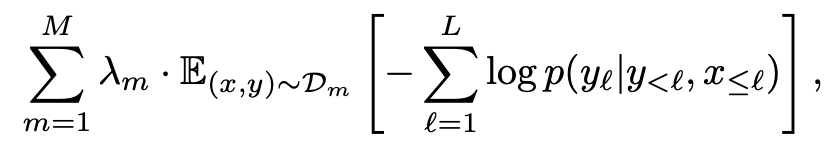
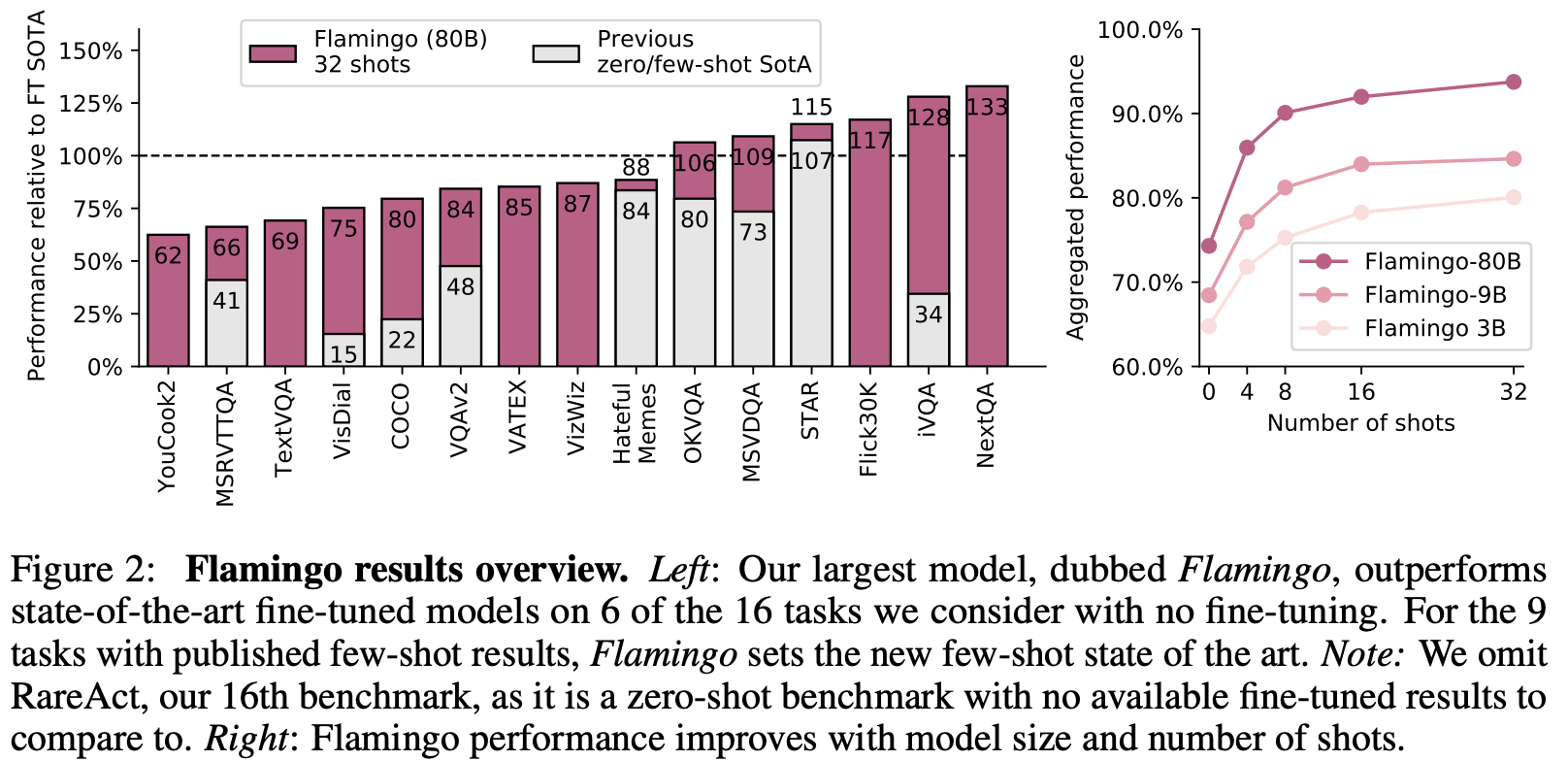
Experiment
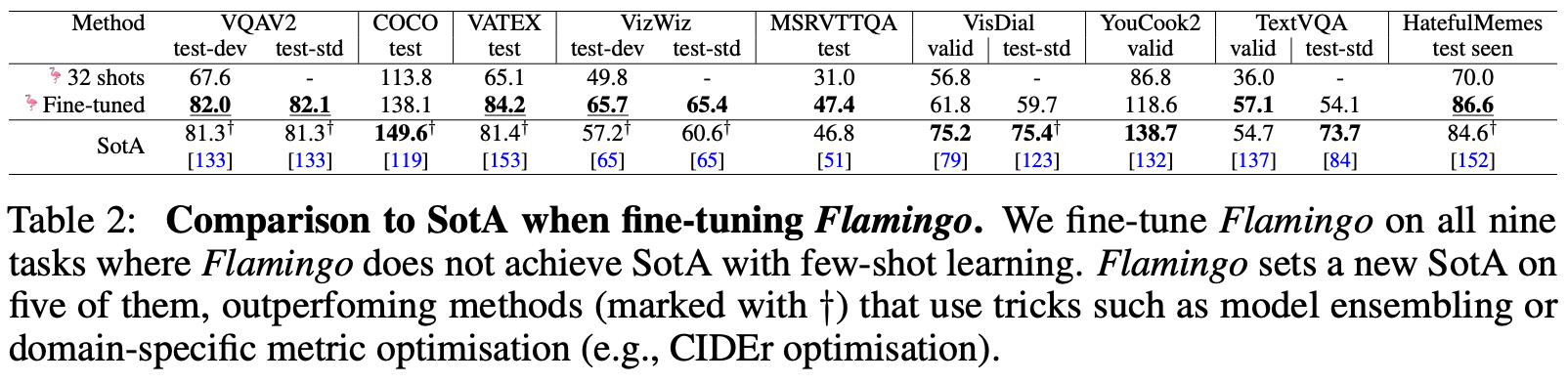
Ablation Study
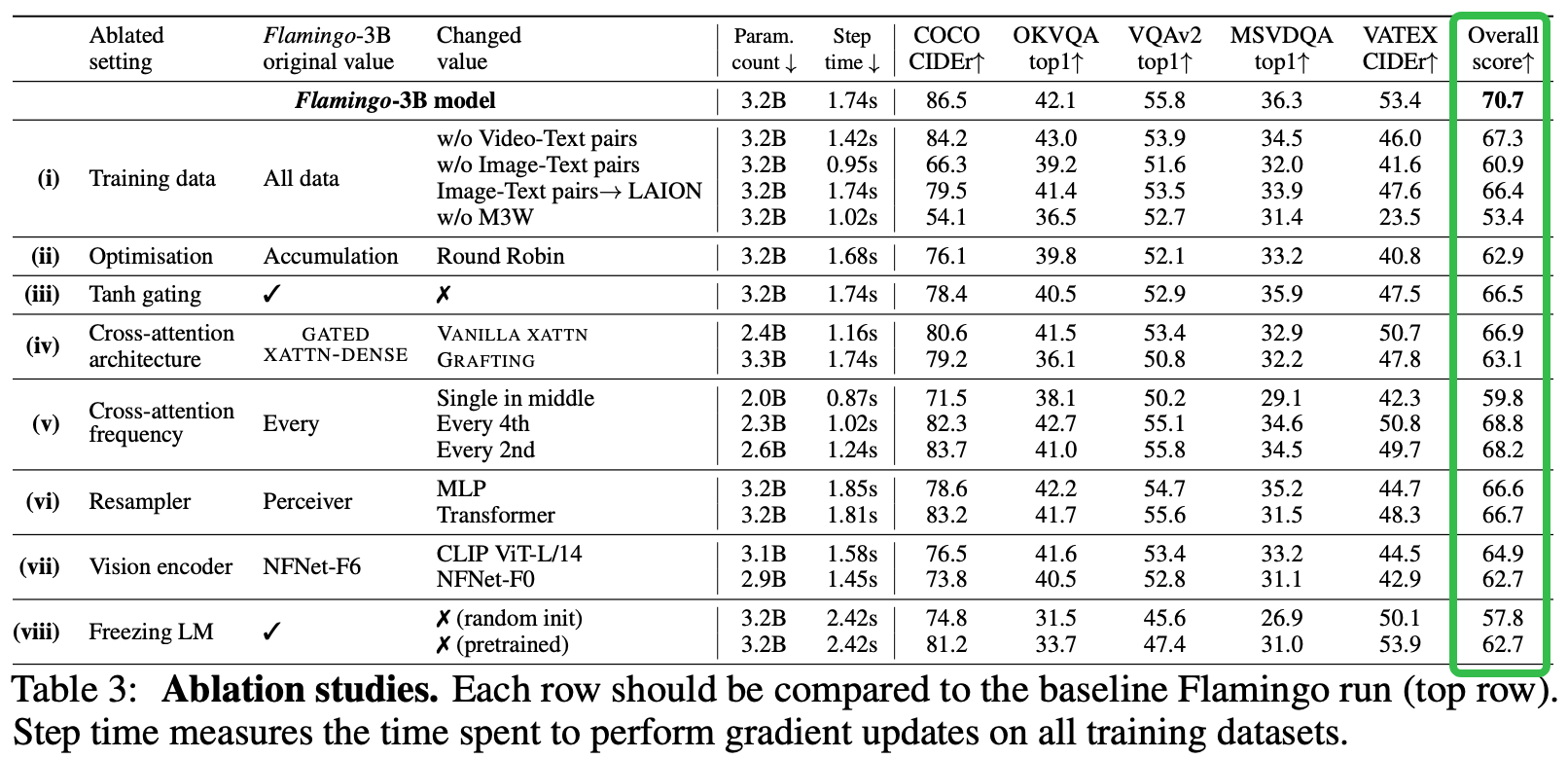
Q&A
Q: 文中所说的open-ended与close-ended分别指得是什么?
A:
Open-ended(开放式任务)
定义:模型需要自由生成文本作为答案,没有预设的选项限制。
特点:
- 适用于需要创造性或描述性回答的任务,如图像描述(captioning)、开放式视觉问答等。
- 模型通过自回归文本生成(如beam search)产生完整句子。
- 评估时通常比较生成文本与人工标注的参考答案(如CIDEr分数用于captioning)。
Close-ended(封闭式任务)
定义:模型从给定的有限选项中选择答案,类似分类或选择题。
特点:
- 适用于有明确候选答案的任务,如分类、多项选择问答等。
- 模型通过计算每个选项的log-likelihood评分,选择概率最高的答案。
- 评估直接比较预测选项与标准答案(如准确率)。
Q: 为什么说该工作可以处理任意交错的图文对数据?
A:
(1) 序列建模的通用性:
输入表示:将图像/视频和文本统一视为序列中的元素,通过特殊标记(如和
图片1
图片2
(2) 单图像因果注意力:
规则:文本token仅允许关注其最近的前一个视觉输入(通过交叉注意力掩码实现)。
(3) 训练时的随机关联增强:
策略:以概率p_next=0.5随机选择文本关联前一张或后一张图像(附录A.3.2)。
可视化效果

总结与思考
在预训练的Visual与text Encoder基础上,增加多模态融合模块,核心模块是GATED XATTN-DENSE layers,能够实现VQA/Captioning/FewShot等多个任务,效果在当时比较好。
相关链接
https://zhuanlan.zhihu.com/p/685233706
https://zhuanlan.zhihu.com/p/11261122900
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/19006207

 浙公网安备 33010602011771号
浙公网安备 33010602011771号