[PaperReading] Training language models to follow instructions with human feedback
Training language models to follow instructions with human feedback
link
时间:22.03
单位:OpenAI
相关领域:LLM/RL
作者相关工作:GT4 tech report
被引次数:16152
TL;DR
当时的大语言模型输出结果可信度低,对于人类几乎没有帮助。本文使用SFT + RLHF训练一个1.3B小模型称为InstructGPT,效果优于GPT3大模型,证明了使用human feedback后训练大模型的有效性。
Method
整个训练过程分三步 (SFT, RM, RL)
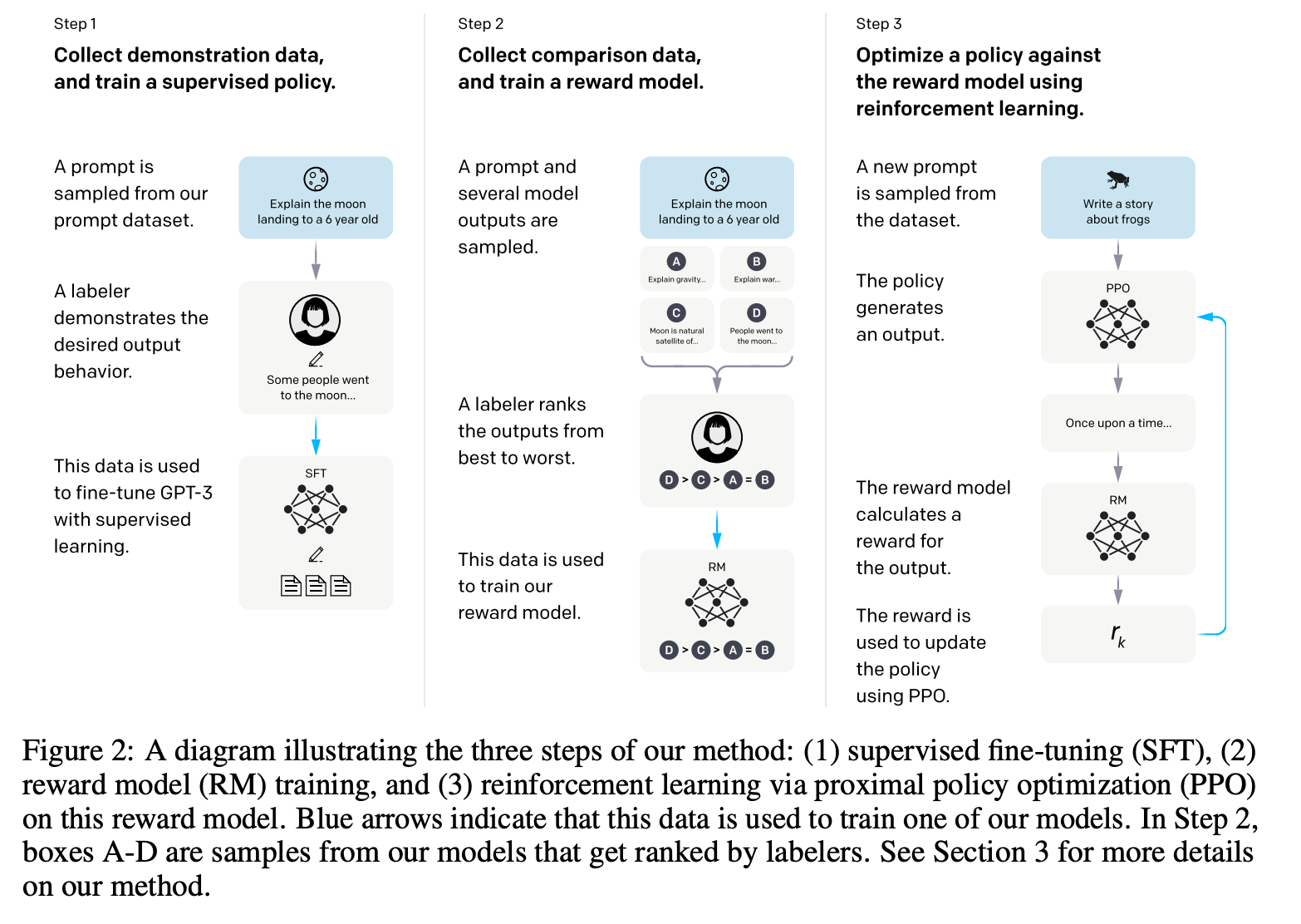
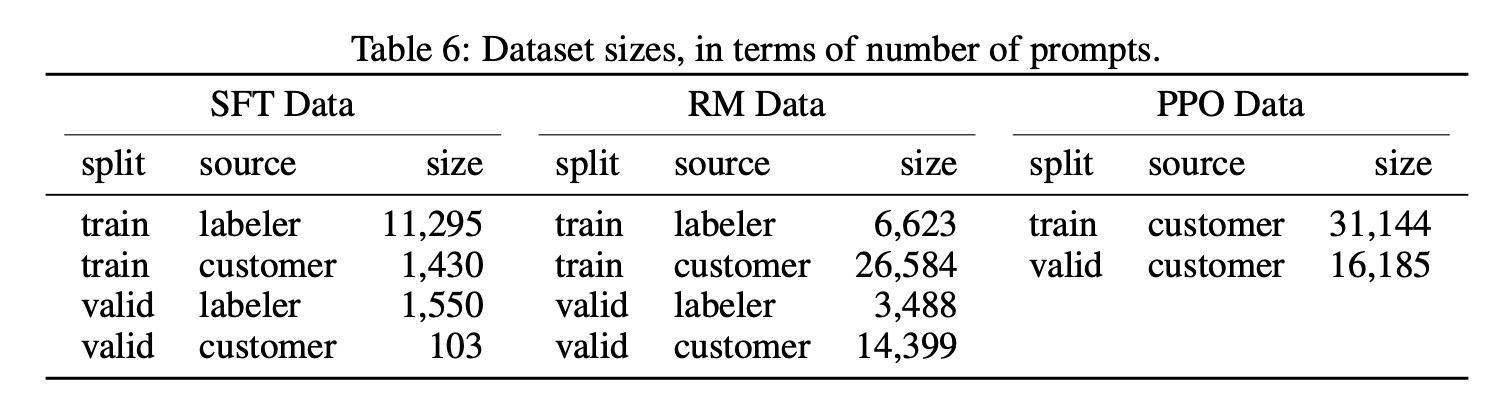
Dataset
三个阶段的训练数据分布
Model
基模:由大量互联网数据训出的GPT-3 (175B)
Supervised fine-tuning
总共Train 16epoch,从第一个epoch开始观察到过拟合,但实验证明长时训练对于RM阶段训练有好处。
Reward modeling(RM)
为了节省资源本文仅训练6B的RM模型,该阶段给定prompt后让SFT模型输出K个resport(通常K[49]),这样每个prompt就对应于\(C^2_K\)个优劣对比结果,但实际节省计算会将同一个prompt产生的response放到组成一个batch来训练(个人理解主要方便训练时复用KVCache)。
训练Loss如下,目标是win的Reward要大于lose的Reward。
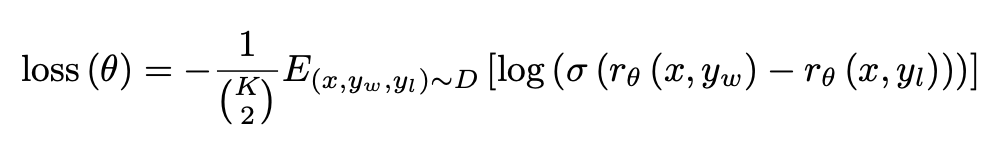
Reinforcement Learning(RL)
Q: 强化学习如何应用到LLM?
A: The environment is a bandit environment which presents a random customer prompt and expects a response to the prompt. Given the prompt and response, it produces a reward determined by the reward model and ends the episode. In addition, we add a per-token KL penalty from the SFT model at each token to mitigate overoptimization of the reward model. The value function is initialized from the RM. We call these models “PPO.”
目标函数:
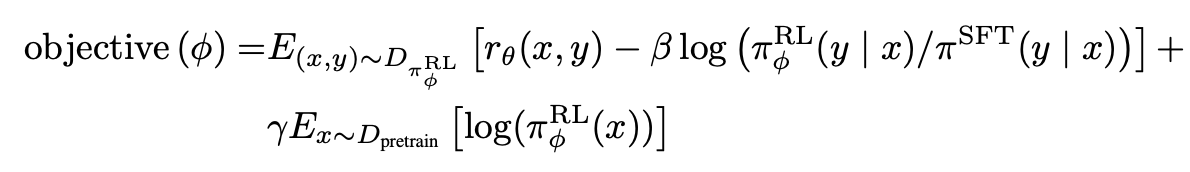
PPO模型架构:
- 监督微调模型(SFT Model):作为RL训练的初始策略(Policy)
- 奖励模型(Reward Model, RM):6B参数的GPT-3变体,用于预测人类偏好的输出
- 价值函数(Value Function):同样为6B参数模型,从RM初始化而来
- RL策略模型(PPO Policy):最终通过PPO算法优化的模型,有1.3B/6B/175B三种规模
这里价值函数与奖励模型的区别:
价值函数由奖励模型初始化,会随着PPO迭代更新。
| 维度 | Reward Model | Value Function |
|---|---|---|
| 评分目标 | 人类偏好(整体response质量) | 状态价值(局部token对未来奖励的预测) |
| 更新频率 | 静态(训练后固定) | 动态(随PPO迭代更新) |
| PPO中的角色 | 提供全局奖励信号 | 计算局部优势函数以降低方差 |
| 文档示例 | 图1中人类对response的偏好评分 | 公式2中需通过时序差分学习更新价值估计 |
Experiment
Pre-train模型、SFT模型、RLHF模型 在不同参数量Size情况下效果对比关系
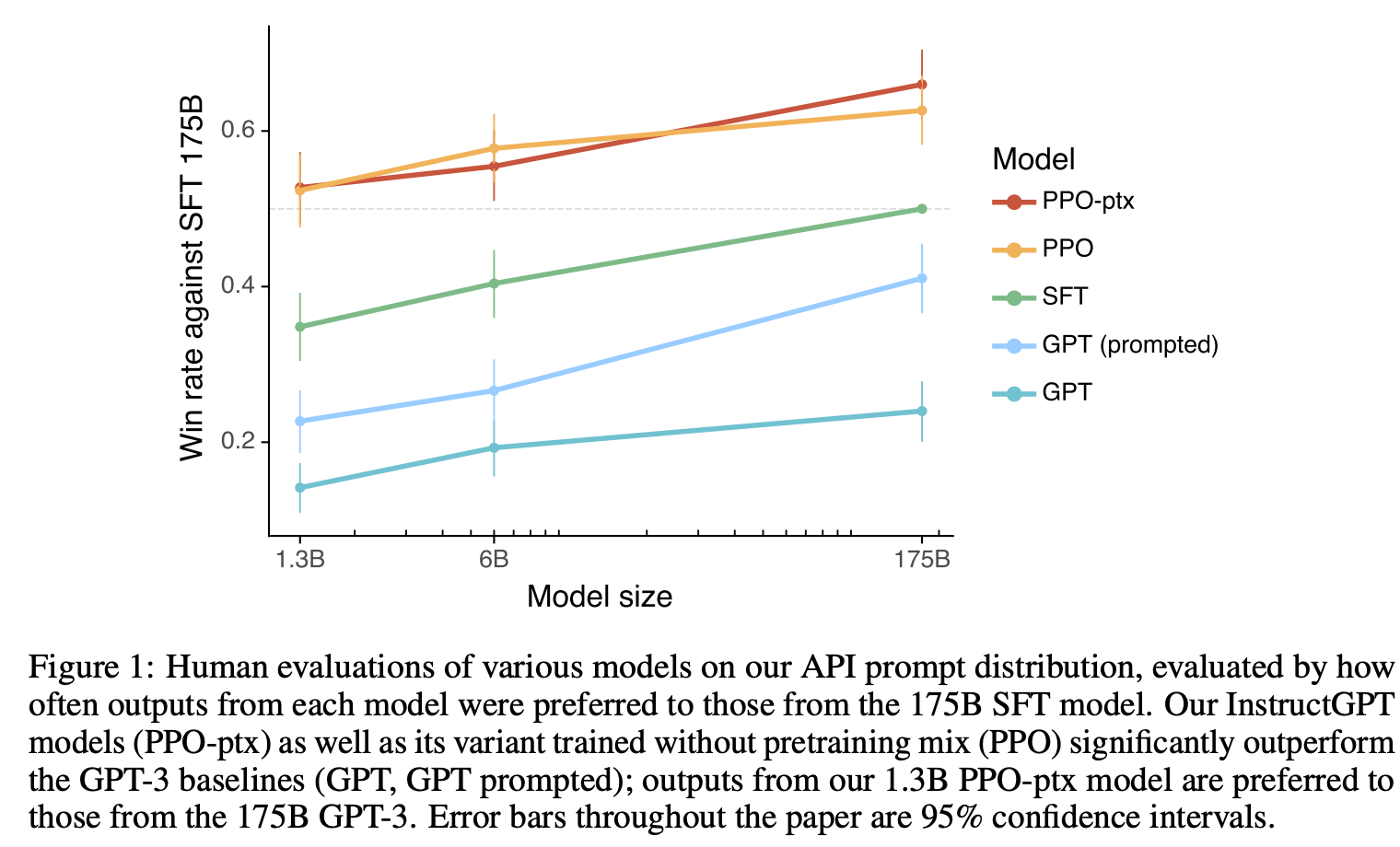
备注:PPO-ptx的含义是RL后训练过程混合了pre-train的梯度 (即加入了next token prediction的loss)
图4:RLHF训练后后幻觉以及指令约束
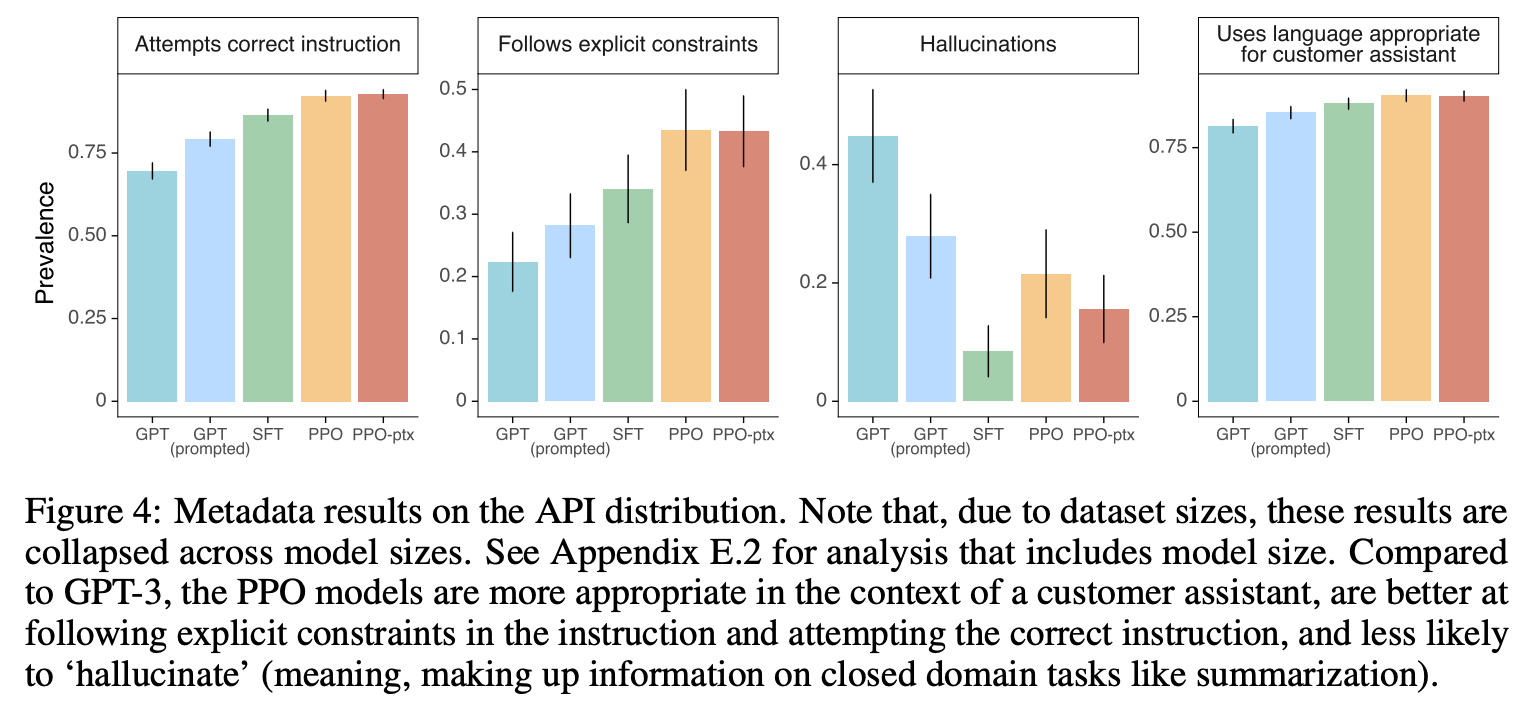
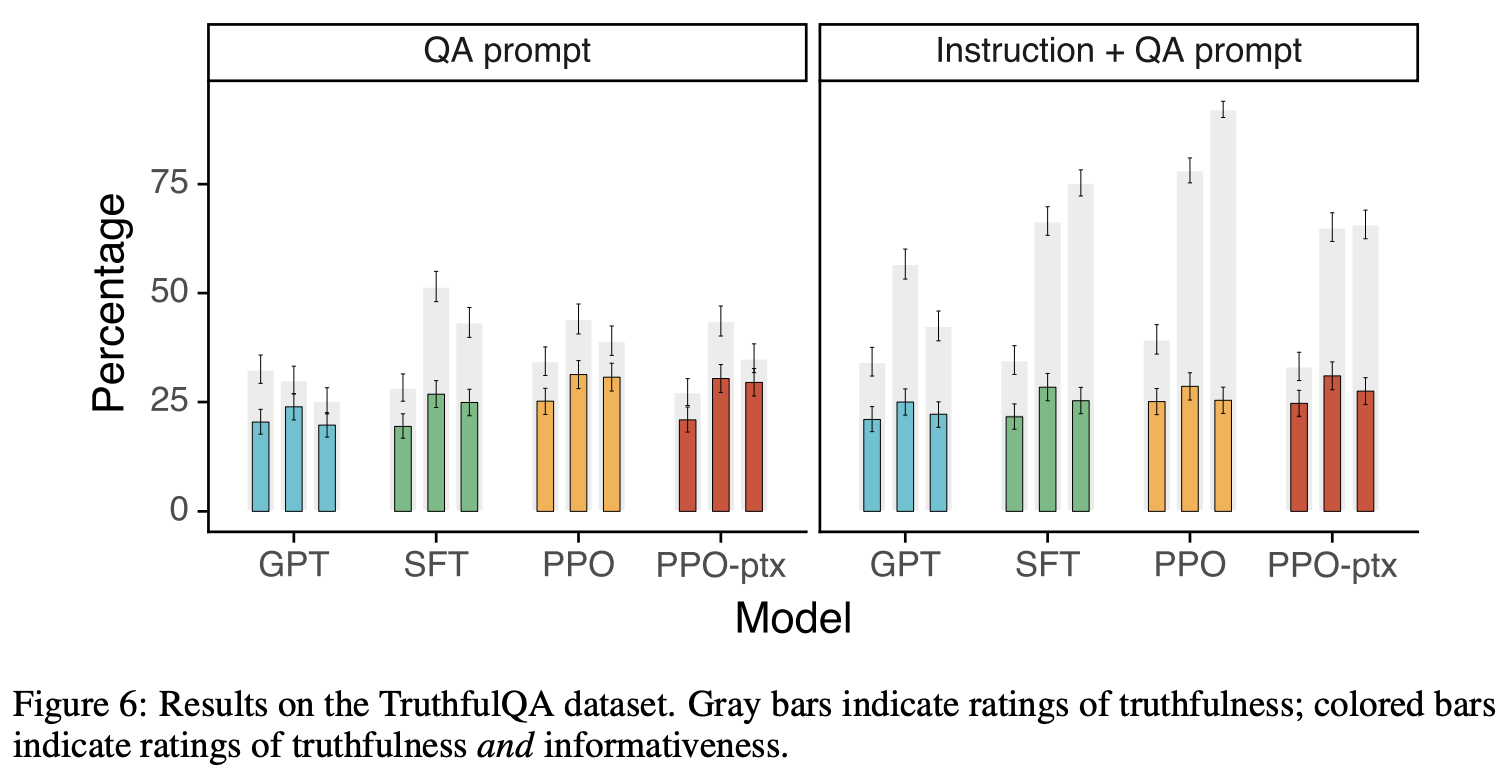
图5:真实性打分更高(灰色)
效果可视化
无
总结与思考
无
相关链接
https://zhuanlan.zhihu.com/p/599303648
Related works中值得深挖的工作
资料查询
折叠Title
FromChatGPT(提示词:XXX)本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18990182

 浙公网安备 33010602011771号
浙公网安备 33010602011771号