[PaperReading] R1-Omni: Explainable Omni-Multimodal Emotion Recognition with Reinforcement Learning
目录
R1-Omni: Explainable Omni-Multimodal Emotion Recognition with Reinforcement Learning
link
时间:xx.xx
单位:Tongyi Lab
作者相关工作:Jiaxing Zhao Xihan Wei Liefeng Bo
被引次数:15
github主页:
https://github.com/HumanMLLM/R1-Omni?tab=readme-ov-file
TL;DR
将RLVR成功应用于Omni多模态(视觉+音频)大模型表情识别任务,提升了该任务推理能力、识别精度、泛化性。RLVR的全称是Reinforcement Learning with Verifiable Reward。
Method
Verifiable Reward
定义为任务的结果是可被验证的,例如 mathematical problem-solving, coding challenges等易定义对错的任务。DeepSeekR1中Rule Based Reward就属于Verifiable Reward。RLVR的相对概念是RLHF,在RLHF中需要先根据人工标注的偏好训练Reward模型,再根据Reward模型来产生Reward。
表情识别任务的Reward定义:
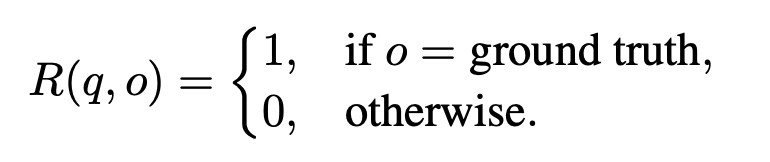
RLVR
强化学习框架参考GRPO,Reward由Accuracy Reward与Format Reward,其中Accuracy Reward使用上述定义Verifiable Reward, Format Reward鼓励模型按照specified HTML格式输出。
Experiment
RLVR作用主要从实验精度与推理结果逻辑性来体现:
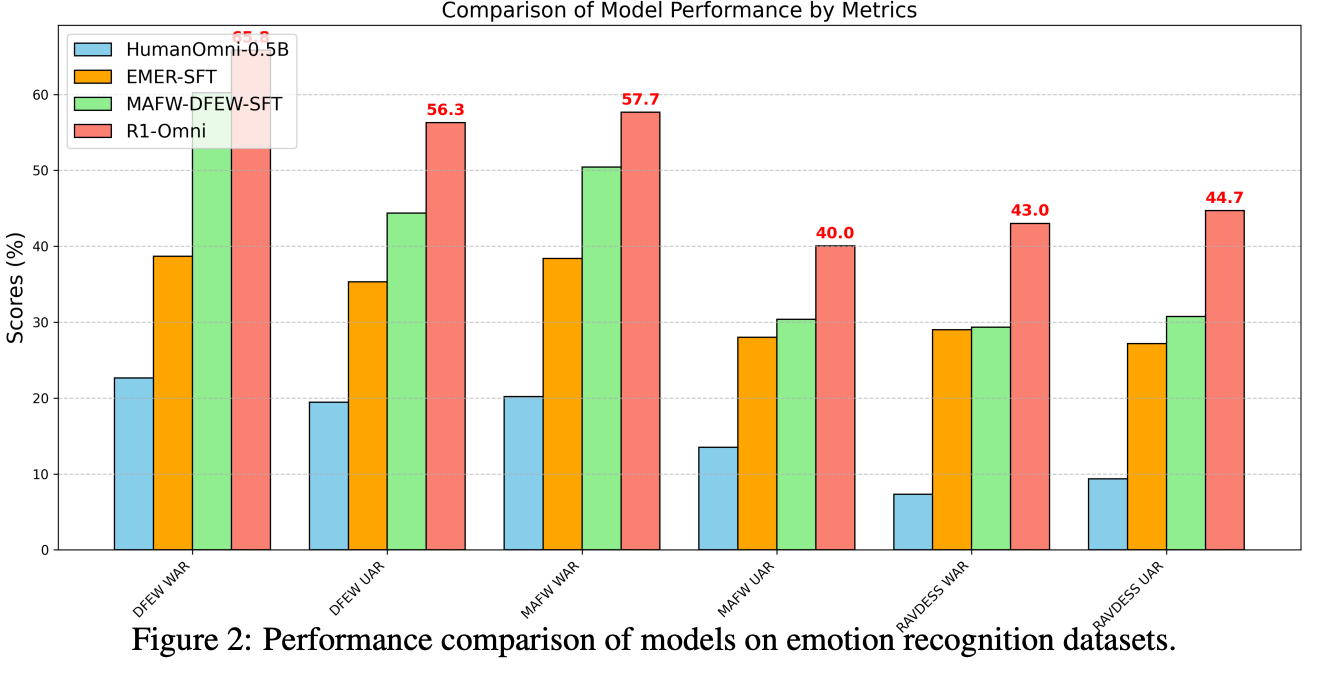
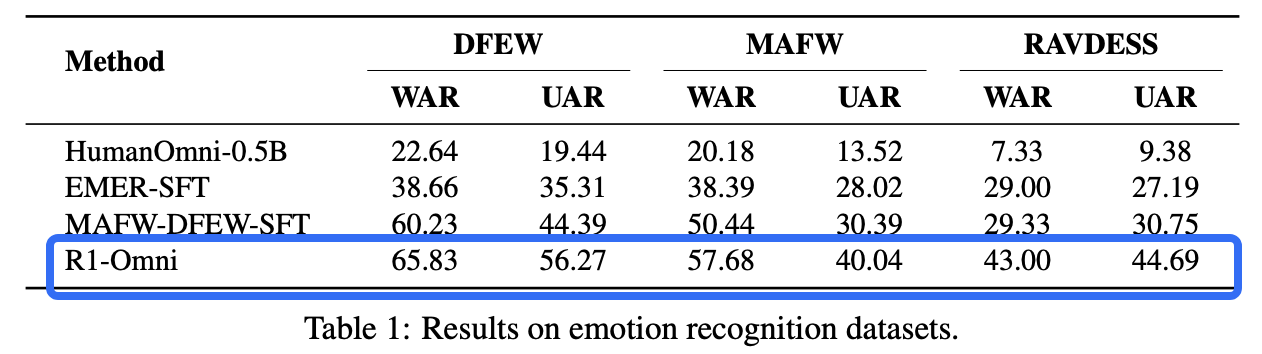

总结与思考
无
相关链接
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18986388

 浙公网安备 33010602011771号
浙公网安备 33010602011771号