[PaperReading] DeepSpeed Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale
DeepSpeed Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale
link
时间:22.06
单位:Microsoft
作者相关工作:https://scholar.google.com/citations?user=djEdnIkAAAAJ&hl=en&oi=sra
被引次数:420
主页:https://github.com/deepspeedai/DeepSpeed
TL;DR
提供两种大模型推理解决方案,1) multi-GPU inference solution; 2) heterogeneous inference solution that leverages CPU and NVMe。效果:延迟敏感场景下,推理速度加速7.3倍;吞吐量敏感场景下,吞吐量增加1.5倍;ZeRO-Inference能推理25倍以上大模型;
memory
推理优化方法
针对Transformer Kernel优化
Motivation:a.之前无工作专门针对小batch_size优化;b.每一步底层计算调用有开销(core与global memory读、写数据的开销);c.原生的Gemm没有针对小batch_size对应的内存带宽进行调优;
DeepFusion
核心是增加了Tile机制,通常GPU上前后OP之间会默认做global sync将所有block数据都sync到一个完整tensor,即使两个相邻OP都是Element-Wise操作。Tile机制会将数据切成若干个小块,只要小块之间没有数据依赖,则可以连续计算多个OP,甚至这些OP中间不需要将数据写回global mem,只在registor与share mem中保存。
SBI-GeMM
Small Batch Inference,定制版本Gemm,根据输出元素个数据,参考threads block数量及寄存器位宽(需重排内存)进行相应计算。个人理解好像是充分利用硬件超参来降低写入写出IO开销,而大batch-size不需要这么做是因为计算较密集,所以相对于而言这部分开销不明显。

针对Dense Transformer的多GPU优化
难点:a.transformer auto-regressive生成具有前后依赖关系;b.生成模型有两个阶段: prompt处理(吞吐量大)、token生成阶段(吞吐量小但前后有依赖);K, V cache缓存机制的优化;
方案:流水并行(pipeline parallelism,PP)
流水并行指将模型拆成多段,分别放在多个GPU上运算,是用来解决模型大显存小的已有方法。如图2所示,一共四个序列同时处理,每个序列要生成三个token,分布到四个GPU上处理。
混合微批次:
一句总结:动态调整微批次大小 以平衡延迟和吞吐量,最终效果参见Figure3
更大的微批次:
优点:提高计算效率(充分利用GPU并行性),减少流水线气泡(Bubble)比例。
缺点:增加显存占用,可能受限于显存容量(尤其是大模型)。
适用场景:吞吐量优先的任务(如离线批量推理)。
更小的微批次:
优点:降低显存需求,适合延迟敏感场景(如实时生成)。
缺点:计算利用率低,流水线气泡更显著。
自回归生成的特性
Prompt阶段:输入是长文本(如128个token),计算密集,适合大微批次以隐藏流水线气泡。
Token生成阶段:每次仅生成1个新token,计算量小,需小微批次以避免等待依赖(如图2中的灰色气泡)。


Offloading Activations to CPU Memory
每层Attention的K/V cache虽然被缓存避免重复计算,但比较显存,并且直到下个token输入后才会被用上,利用规律先将K/V cache缓存到CPU上可以释放GPU显存。
针对MoE架构多GPU优化
PCC: Parallelism Coordinated Communication
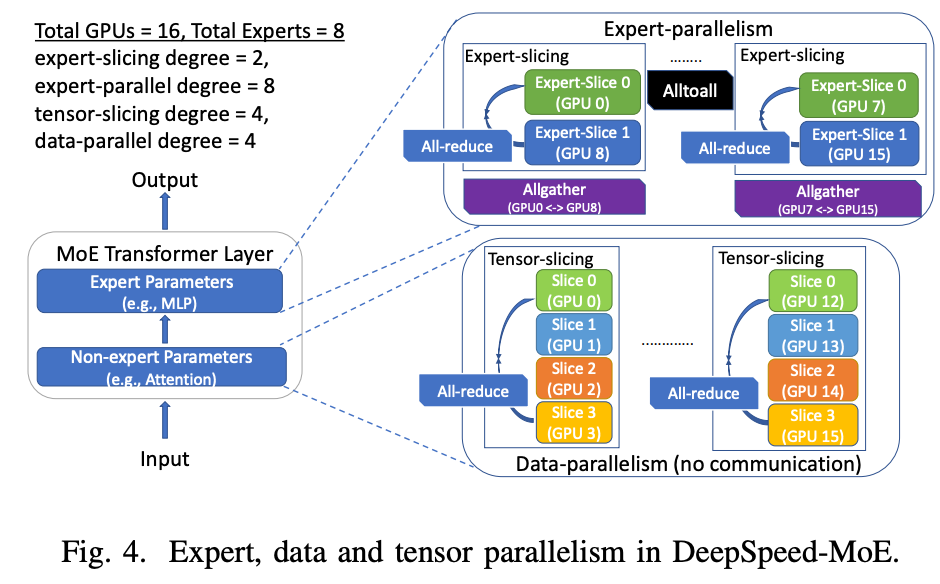
MoE架构模型相对于Dense架构模型通常更大,通常会将DP、TP、EP(expert parallelism)多种方案一起上(参考Fig4)。
专家并行: 将不同的专家(Experts)分布到不同的GPU设备上,每个专家仅处理分配给它的输入Token。这一过程需要 动态路由(Dynamic Routing),即根据Token的内容(通过门控函数计算)决定其应该被发送到哪个专家,而这一路由过程必然引发全局的 All-to-All通信。
由于TP结束后会进行一次All-Reduce通信,而专家并行过程也会有All-to-All通信,整体的通信成本较高。本工作的优化是将专家也划分为TP组,前序的TP结束后不经All-Reduce同步数据,后续的计算分为原始的TP组(切分专家参数,All-Reduce通信),以及EP组(不同专家参数,All-to-All通信)。
额外信息可以参考

请详细解释一下Figure5?
图5分为上下两部分,分别展示 PCC优化后的通信流程 和 传统All-to-All的对比:(1) PCC优化后的通信流程(上半部分)
假设总GPU数 P = TP × EP(例如TP=4,EP=4,共16 GPUs),输入数据为 X:
Step 1: 本地变换与拆分
每个TP组(4 GPUs)内的输入 X 按专家分配结果(Gating输出)在本地重组。
关键点:因TP组内专家参数相同,每个GPU计算的Token-Expert分配结果一致。
操作:将 X 拆分为 X_local,准备发送给目标专家。
Step 2: 组内All-to-All
仅在 EP组内(4 GPUs)执行All-to-All,而非全局16 GPUs。
操作:每个GPU将 X_local 发送给EP组内其他GPU,接收属于自己专家的Token。
复杂度从O(16)降至O(4)(因TP组内无需通信)。
Step 3: 组内AllGather
TP组内通过AllGather聚合部分结果(因专家参数在TP组内复制,只需合并部分计算)。
操作:每个GPU计算本地专家的输出,然后在TP组内共享结果。
Step 4: 本地变换输出
将最终结果按原始Token顺序重新排列,完成计算。
(2) 传统All-to-All的对比(下半部分)
直接全局All-to-All:所有16 GPUs参与通信,每个GPU需与其他15 GPUs交换数据。
问题:
通信复杂度为 O(16),延迟高。
跨节点通信(如InfiniBand)带宽受限,进一步加剧延迟。
备注:TP组、EP组的含义
总GPU数:假设为 P = TP × EP(例如TP=4,EP=4,共16 GPUs)。
TP(Tensor Parallelism)组:将单个专家的计算(如FFN层)拆分到多个GPU上(参数分片)。
EP(Expert Parallelism)组:将不同专家分布到不同GPU上(专家分片)。
优化MoE核心计算
紧凑数据结构:用索引表替代稀疏矩阵,消除零值计算。
数据布局变换:直接拷贝替代稀疏乘法,降低计算复杂度。
内核融合:减少内核启动次数和全局内存访问。
硬件感知优化:共享内存、寄存器缓存和动态负载均衡。
ZeRO-Inference
利用单GPU+ CPU Memory提升系统的吞吐量。Naive的设计是将模型一部分放到GPU,剩余都在CPU上推理,但只能放一小部分。本文动态将需要计算的Layer与数据放到GPU,算完再换其它层。这么做的好处是大模型本身是计算密集性任务,GPT3-175B在batch_size=1时有7 TFlops的计算量,相对而言CPU与GPU之间的数据、参数搬运带来延迟较小。实现时,会将GPU计算与数据搬运时间进行重叠。
Code && Implementation
暂无
Experiment

更多实验参考原文
总结与思考
暂无
相关链接
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18909164

 浙公网安备 33010602011771号
浙公网安备 33010602011771号