[PaperReading] LXMERT: Learning Cross-Modality Encoder Representations from Transformers
简介
LXMERT: Learning Cross-Modality Encoder Representations from Transformers
时间:2019.08(EMNLP 2019)
单位:UNC Chapel Hill
相关领域:跨模态学习/视觉语言推理
作者相关工作:BERT式跨模态预训练的先驱工作
被引次数:3k
主页:https://github.com/airsplay/lxmert
TL;DR
提出首个大规模跨模态Transformer框架LXMERT,通过五类预训练任务(掩码语言建模、物体特征回归、物体标签分类、跨模态匹配、视觉问答)在180K图片-文本对上预训练。创新点包括:
- 三编码器架构(物体关系/Language/跨模态编码器)
- 跨模态注意力机制(图1交叉注意力层)
- 混合预训练策略(表4显示QA预训练提升2.1% NLVR2精度)
影响力:首次在VQA/GQA/NLVR2三任务同时达到SOTA,启发了后续ViLBERT、VisualBERT等工作。
Method
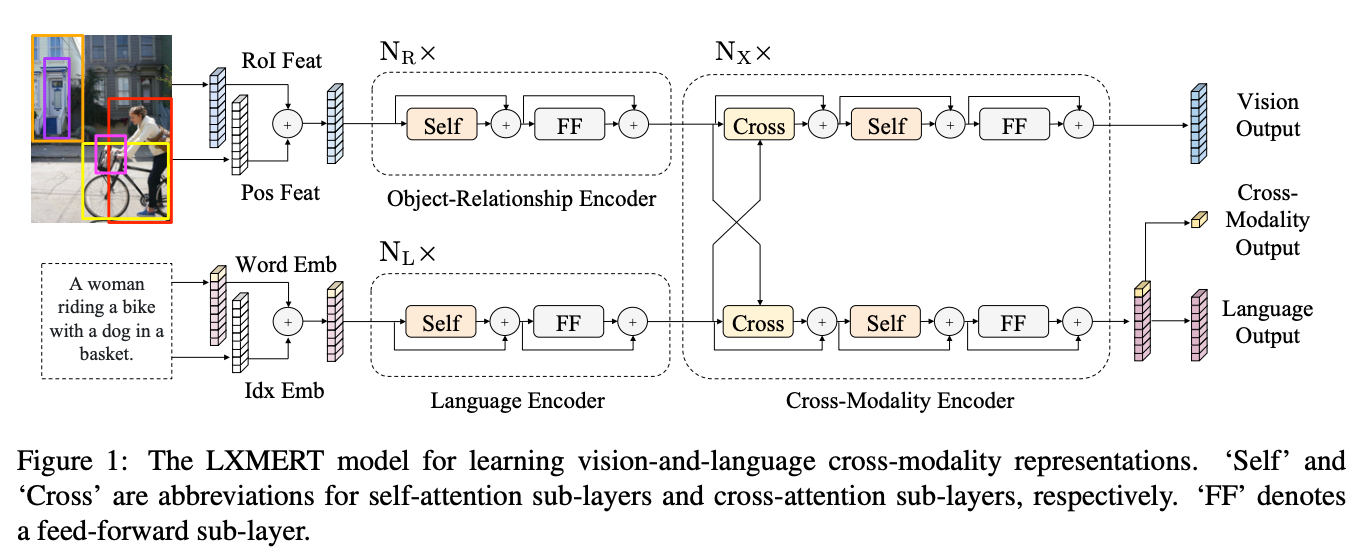
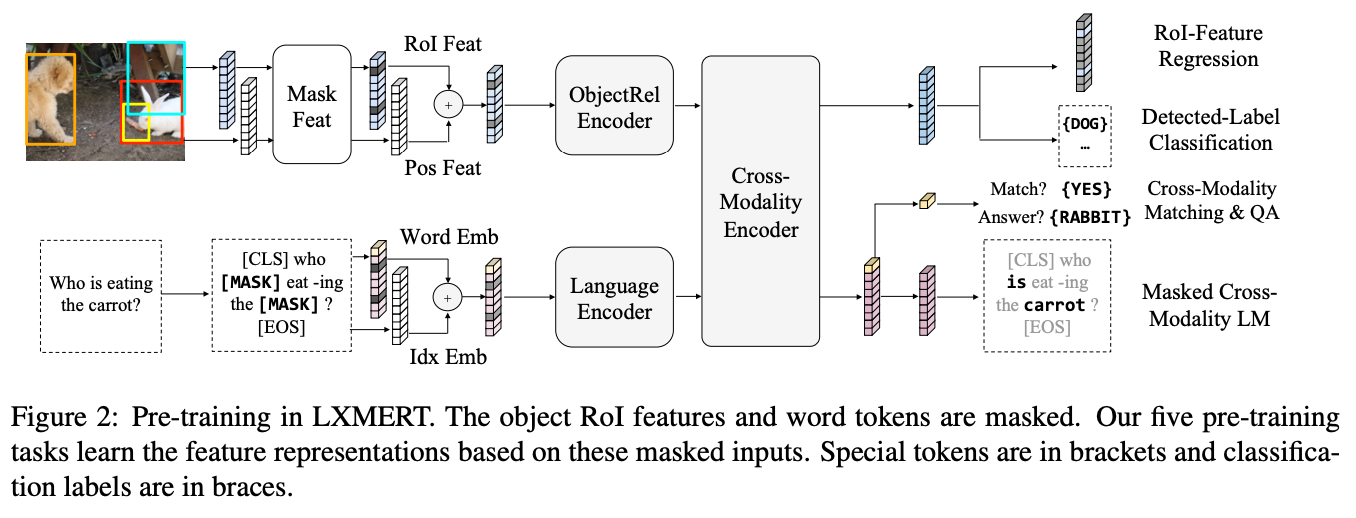
核心模块:
- 物体关系编码器(5层Transformer):学习物体间空间关系
- 语言编码器(9层Transformer):学习语言上下文
- 跨模态编码器(5层):双向交叉注意力机制(式3-5)
Dataset
训练集(表1):
• 180K图片(MS COCO 72K + VG 108K)
• 9.18M图文对(含5.39M VG描述 + 1.44M VQA问题)
推理速度:
• Titan Xp GPU单张图片推理时间≈120ms
• 预训练耗时:4卡10天
Experiment
10min
主要结果(表2):
| 任务 | VQA | GQA | NLVR2 |
|---|---|---|---|
| 准确率 | 72.5% | 60.3% | 76.2% |
| 提升幅度 | +2.1% | +3.2% | +22% |
关键分析实验:
- vs BERT(表3):跨模态预训练比单纯BERT+视觉提升15% NLVR2
- QA预训练效果(表4):加入QA任务使GQA提升1.8%
- 物体预测任务(表5):特征回归+标签分类联合最优
总结与思考
命名逻辑:Learning Cross-Modality Encoder Representations from Transformers的缩写,强调跨模态编码器的Transformer架构。
个人思考:
- 多任务预训练是关键,不同任务互补性强
- 物体关系编码器有效建模空间关系(图4可视化)
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18870702

 浙公网安备 33010602011771号
浙公网安备 33010602011771号