[PaperReading] ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks
简介
- link
- 时间:2019.08.06
- 单位:Georgia Institute of Technology, Facebook AI Research, Oregon State University
- 相关领域:计算机视觉与模式识别、自然语言处理
- 作者相关工作:Jiasen Lu, Dhruv Batra, Devi Parikh, Stefan Lee 等作者在视觉与语言任务、自监督学习、目标检测等领域有深入研究
- 被引次数:截至 2025 年 5 月,Google Scholar 显示该论文被引 1,000+ 次
TL;DR
ViLBERT是一种用于学习图像内容和自然语言任务联合表示的模型。它通过在大规模自动收集的概念描述数据集上进行预训练,然后将预训练模型迁移到多个视觉与语言任务上(例如,VQA),取得了显著的性能提升。为视觉与语言任务提供了一种统一的预训练和迁移学习方法,推动了视觉与语言领域的发展。
Method
核心创新点
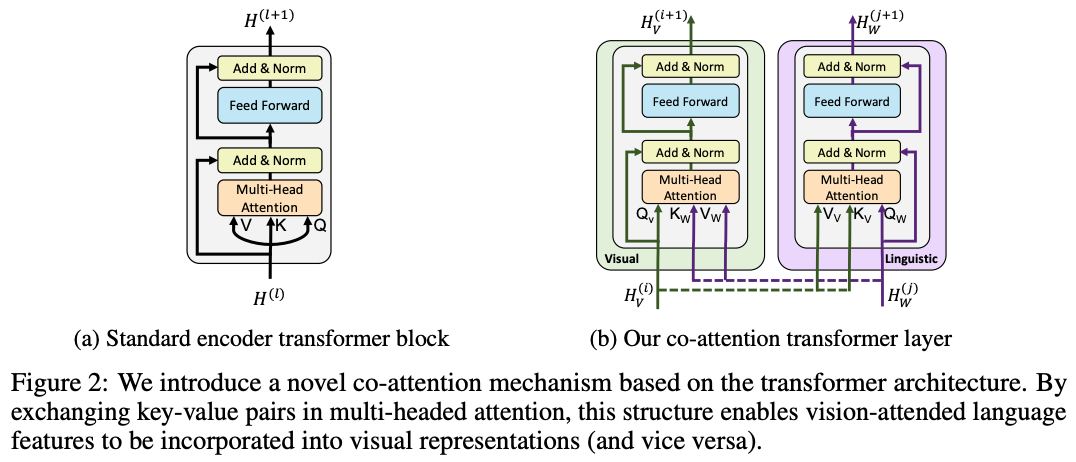
提出了一种能够处理视觉和文本两种模态的双流架构,并通过共注意力机制(co-attention)实现了模态间的有效信息交互,从而学习到任务无关的联合表示,为多种视觉与语言任务提供统一的预训练模型。
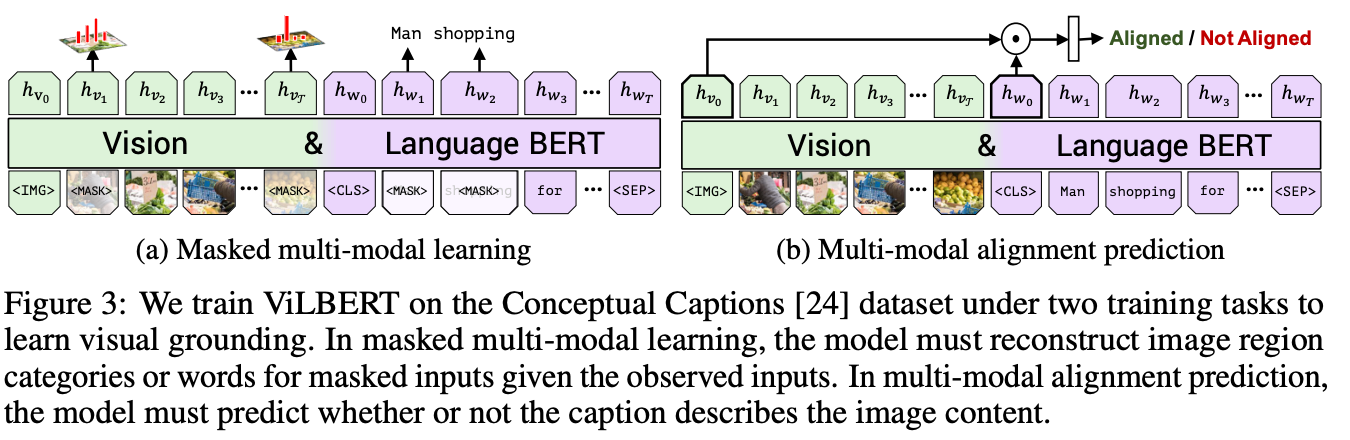
学习方式
任务一:掩码多模态建模(Masked Multi-Modal Modeling),该任务类似于 BERT 中的掩码语言建模,但扩展到了视觉和文本两个模态。
任务二:多模态对齐预测(Multi-Modal Alignment Prediction)任务,模型需要判断给定的图像和文本是否对齐(感觉有点类似于CLIP的训练方式)。
Experiment
- 视觉问答(VQA):ViLBERT 在 VQA 2.0 数据集上取得了 70.55% 的 test-dev 准确率,超过了之前最好的任务特定模型 DFAF 的 70.22%。
- 视觉常识推理(VCR):ViLBERT 在 Q→A 子任务上达到了 72.42% 的准确率。
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18870688

 浙公网安备 33010602011771号
浙公网安备 33010602011771号