[PaperReading] Frozen-DETR: Enhancing DETR with Image Understanding from Frozen Foundation Models
Frozen-DETR: Enhancing DETR with Image Understanding from Frozen Foundation Models
时间:2024.10.25
作者与单位:
Shenghao Fu1,3,4, Junkai Yan1,3,4, Qize Yang3†, Xihan Wei3, Xiaohua Xie1,4,5∗, Wei-Shi Zheng1,2,4,6∗
1School of Computer Science and Engineering, Sun Yat-sen University, China
2Peng Cheng Laboratory, Shenzhen, 518055, China
3Tongyi Lab, Alibaba Group
4Key Laboratory of Machine Intelligence and Advanced Computing, Ministry of Education, China
5Guangdong Province Key Laboratory of Information Security Technology, China
6Pazhou Laboratory (Huangpu), Guangzhou, Guangdong 510555, China
Shenghao Fu目标检测
Xiaohua Xie, Wei-Shi Zheng之前研究ReID
相关领域:计算机视觉、目标检测、Transformer模型、基础模型应用
作者相关工作:Shenghao Fu和Junkai Yan在目标检测和Transformer模型方面有研究经验,Wei-Shi Zheng在计算机视觉领域有多项研究成果
被引次数: 1
主页:https://github.com/iSEE-Laboratory/Frozen-DETR
TL;DR
本文提出了一种名为Frozen-DETR的新方法,通过将冻结的基础模型作为插件模块,增强DETR类目标检测器的性能。该方法利用基础模型的全局图像理解能力和细粒度语义信息,显著提升了检测器在多种数据集上的表现,尤其是在具有挑战性的场景中。这种方法不仅提高了检测精度,还展示了良好的通用性和可扩展性。
Method
方法框图说明
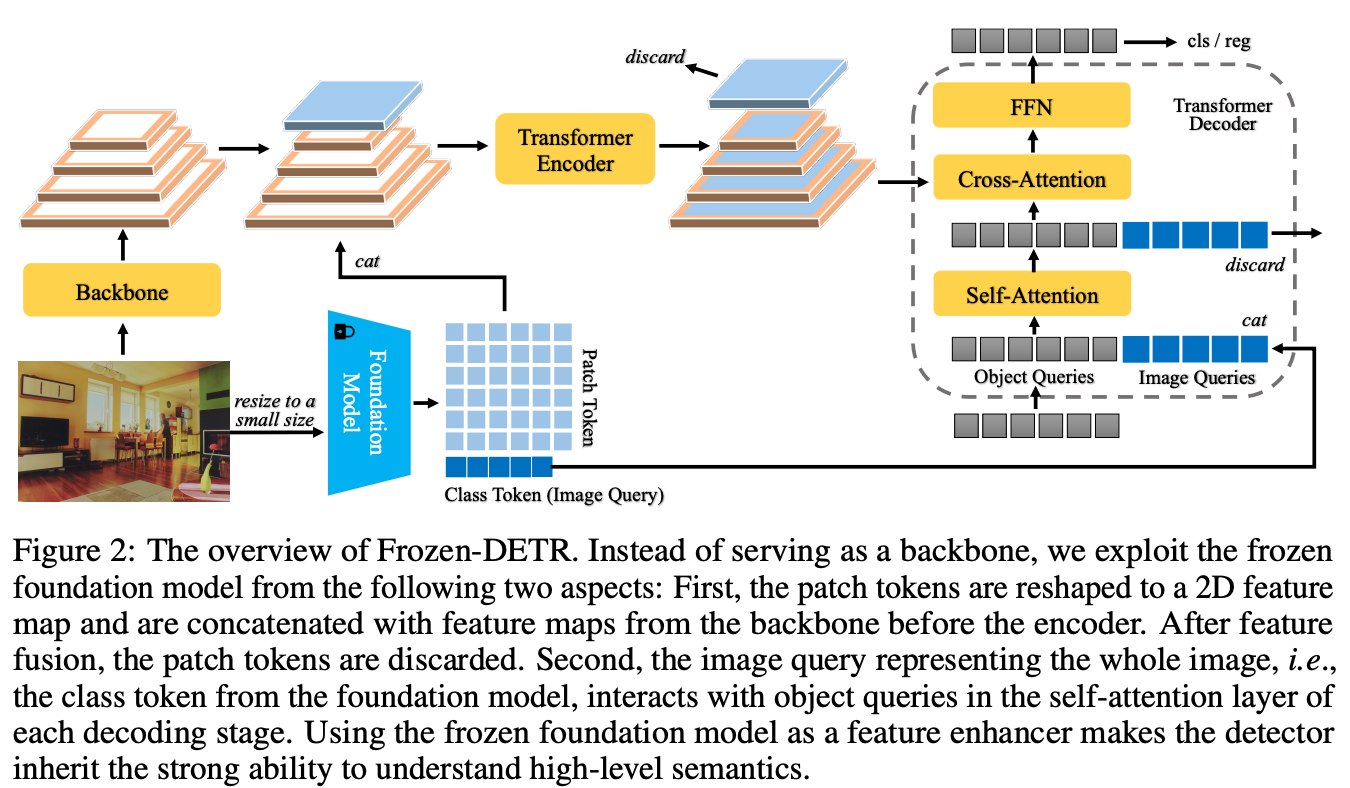
Frozen-DETR的核心思想是将冻结的基础模型(如CLIP)作为插件模块,与检测器结合。具体来说:
- 类 token 作为图像查询:从基础模型中提取类 token,将其作为整个图像的表示(图像查询),并与目标查询一起输入到检测器的解码器中。这为解码器提供了复杂的场景上下文,有助于目标查询的解码。
- 补丁 token 作为特征金字塔的增强:将基础模型中的补丁 token 视为特征金字塔的另一层,通过编码器层与检测器的特征金字塔融合。这为检测器的编码器注入了丰富的语义细节。
创新点解释
- 冻结基础模型作为特征增强器:与传统方法不同,本文不将基础模型作为可训练的骨干网络,而是将其作为冻结的特征增强模块。这样可以避免架构不匹配问题,同时保持基础模型的预训练表示能力。
- 多尺度图像查询:通过将图像分割成多个子图像,并为每个子图像提取图像查询,方法能够捕捉更细致的局部上下文信息。
- 高效的实现方式:提出快速实现方法(如均值补丁 token 和多类 token),在单次前向传播中获取全局和局部图像查询,显著降低计算成本。
关键Code
# 提取类 token 作为图像查询
image_query = foundation_model.get_class_token(image)
# 补丁 token 重塑为2D特征图
patch_tokens = foundation_model.get_patch_tokens(image)
patch_feature_map = reshape_to_2d(patch_tokens)
# 特征融合
fused_features = torch.cat([backbone_features, patch_feature_map], dim=1)
# 解码器中图像查询与目标查询的交互
combined_queries = torch.cat([object_queries, image_query], dim=1)
attention_output = self_attention(combined_queries)
Code && Implementation
使用的训练集
- COCO数据集:用于主要的实验和性能评估
- LVIS数据集:用于验证在大词汇量和长尾分布场景下的性能
推理速度
- 模型大小CLIP ViT-L-14-336: 400 GFLOPs
- 在V100 GPU上,Frozen-DETR (DINO-det-4scale)的推理速度为6.5 FPS
- 当结合多个基础模型时,推理速度会有所下降,但仍然保持在可接受范围内
Experiment
效果怎么样?
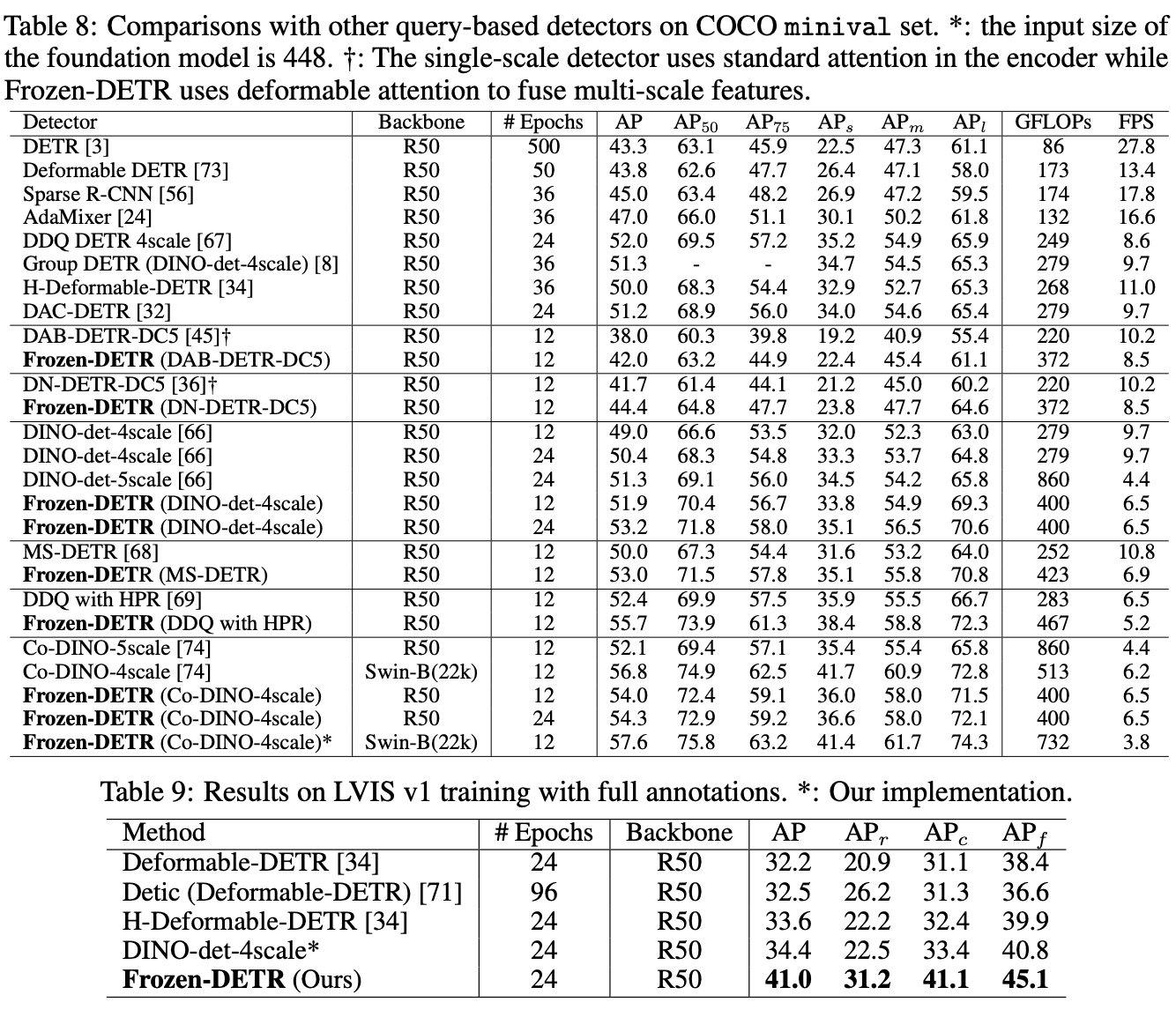
- 在COCO验证集上,Frozen-DETR将DINO的性能从49.0% AP提升到51.9% AP(+2.9% AP),进一步结合两个基础模型后提升到53.8% AP(+4.8% AP)
- 在LVIS数据集上,Frozen-DETR取得了显著的性能提升,提升了7.5%
- 在开放词汇场景下,Frozen-DETR在罕见类别上的性能提升了8.8% novel AP
有启发意义的分析实验
- 图像查询的消融研究:验证了图像查询对不同尺度目标检测的积极作用,特别是对小目标和大目标的检测精度提升
- 不同基础模型的比较:展示了不同预训练方法得到的基础模型在提取图像查询方面的性能差异,表明监督预训练的基础模型(如CLIP)优于自监督预训练的模型
- 特征融合的消融实验:证明了将补丁 token 注入编码器特征金字塔的有效性,进一步提升了检测器的性能
总结与思考
论文为什么取这个名字?
这个名字直接反映了论文的核心贡献:通过冻结的基础模型(Frozen Foundation Models)来增强DETR类目标检测器(Enhancing DETR),强调了方法的创新点和应用场景。
个人的理解,发散思考
本文提出的方法为利用预训练基础模型提升目标检测性能提供了新的思路。通过将冻结的基础模型作为插件模块,避免了复杂的微调过程和架构匹配问题,同时充分利用了基础模型的强大表示能力。这种方法在计算成本和性能提升之间取得了良好的平衡,具有很强的实用价值。未来可以进一步探索如何更高效地结合多个基础模型,以及如何将这种方法扩展到其他计算机视觉任务中。
第三方信息总结
本文的核心创新在于将冻结的基础模型作为特征增强模块,而不是传统的骨干网络,用于提升DETR类目标检测器的性能。通过利用基础模型的全局图像理解和细粒度语义信息,方法在多个数据集上取得了显著的性能提升,并展示了良好的通用性和可扩展性。
相关链接
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18767660

 浙公网安备 33010602011771号
浙公网安备 33010602011771号