

【论文笔记】S3FD:Single Shot Scale-invariant Face Detection
&论文概述
题目:Single Shot Scale-invariant Face Detection
作者及单位:Shifeng Zhang, Xiangyu Zhu, Zhen Lei, Hailin Shi, Xiaobo Wang, Stan Z. Li. CBSR & NLPR, Institute of Automation, Chinese Academy of Sciences, Beijing, China University of Chinese Academy of Sciences, Beijing, China
获取地址:https://arxiv.org/abs/1708.05237
&总结与个人观点
S3FD是针对人脸检测提出的,通过解决基于anchor设计的检测方法的常见问题:当目标变小,检测器的性能急剧降低,设计了一个新颖的人脸检测器。提出了1)在更多层上提取anchor以及选取一系列合理的anchor尺度以解决人脸的不同尺度问题的尺度平衡网络;2)提高小人脸的召回率的尺度补偿anchor匹配策略;3)降低小人脸的false positive的背景标签的最大输出方法。
我认为这篇论文在人脸检测领域种很有创新,而且提出的解决方案都不难理解,值得一看。
&贡献
1) 提出scale-equitable的人脸监测框架来处理不同尺度的人脸。其中包括设计了基于effective receptive field以及equal-proportion interval principle的anchor尺度以及将anchor应用于更多的层上;
2) 通过scale compensation anchor matching strategy来提高小人脸的recall;
3) 通过max-out background label以减少小人脸的false positive的比例。
&拟解决的问题
问题:基于anchor设计的检测器,当目标变得更小,性能急剧变糟
分析:
1) 目前基于anchor的检测框架往往会miss小的及中等大小的的人脸。在最低的提取anchor的层中步长太大,以至于小人脸在检测层的特征很少,如下图中(a)所示;且anchor尺度误匹配了感受野(感受野或者anchor太大)以至于无法适应小人脸,如下图中(b)所示。
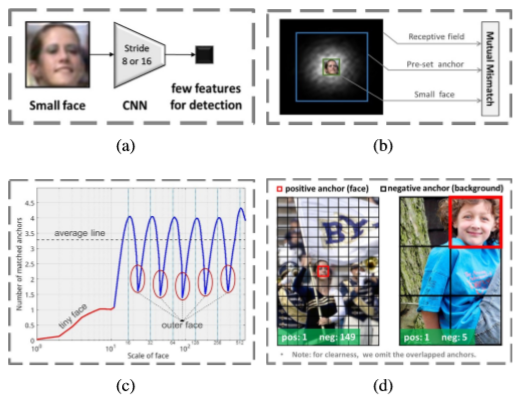
2) 在基于anchor的检测框架中,anchor的尺度是离散的,而人脸的尺度却是连续的,以至于尺度游离在anchor尺度之外的人脸无法匹配到足够的anchor,如上图(c)所示,在anchor尺度上的人脸匹配到的anchor的数量明显高于平均水平。
3) 为了检测到小人脸,需要在图片中使用大量的较小的anchor,导致背景中的negative anchor的数量急剧增加,造成更多的false positive,如上图(d)所示,在图片中,使用小尺度的anchor得到的anchor数量比大尺度anchor的数量多得多。
&重要的方法及应用
1、Effective Receptive Field
CNN中的一个单元有两种类型的感受野:1) Theoretical Receptive Field,即输入区域中能够影响到这个单元的理论区域;但并非理论区域上的每个像素对最终的输出有着同等的贡献,如下图(左)所示,整个图片是理论上的感受野,其中白色的是对最终输出产生影响的像素位置。可以看出中心像素的影响明显比外围大了很多,说明只有这个区域的一部分有着有效的影响,即2)Effective/Valid Receptive Field。


可以参考:
论文名称:Understanding the Effective Receptive Field in Deep Convolutiona lNeura lNetworks
论文地址:https://arxiv.org/abs/1701.04128
因此,anchor可以变得更小来匹配有效的感受野。当然,此时将anchor变得更小,带来的是anchor数量的暴增,同样也会有更多的false positive。之后也会提到解决这个问题的方法。可以看下图所示,anchor的尺度选的更小,同时也能应用在更多的层上。

对上表数据的解释:其中RF表示整体的理论感受野,Anchor是当前感受野下选择的anchor的尺度,通过上图有效感受野的示意图可以看出,第二幅图片整体是48×48大小(黑色圆点围成的范围),其中有效感受野为蓝色圆点围成的区域,内部红色线条表示设置的anchor的尺度,可以看出,使用更小的anchor尺度更符合有效感受野的区域变化。
2、Equal-proportion interval principle
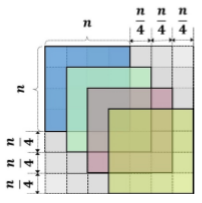
根据作者的介绍,这里使用的等比例原则就是anchor的尺度与步长的比值是一个定值,此论文中取4。该方法的目的是为了确保不同尺度的anchor在图像中也能有相同的密度。如下图所示,n为anchor的尺度,n/4是当前尺度下anchor的间隔,同时也是提取这个尺度的anchor所在的层的步长。
3、Scale compensation anchor matching strategy
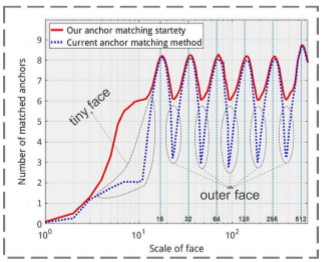
当前的anchor匹配策略都是先计算所有的人脸与anchor之间的IoU,然后从中选择大于threshold的anchor。针对分析2)中提到的问题,本文使用了尺度补偿的anchor匹配策略:首先仍然选用当前的anchor匹配策略,但将阈值调低,从0.5降到0.3,以增加匹配的anchor的平均数量;接着,对那些未匹配到足够anchor的人脸,再次选取与这些人脸匹配IoU大于0.1的anchor,选取其中的top-N个,N为匹配到的anchor的平均数量。
结果如下图所示,之前游离在anchor尺度之外的人脸尺度,此时匹配到的anchor的数量提升不少。
4、Maxout Background Label
根据数据结果显示,超过99.8%的预设的anchor属于negative anchor,这就造成了二分类(negative, positive)过程中极度的不平衡,而这种不平衡的根源是对小人脸的检测。因为在小人脸检测中需要更小的anchor。
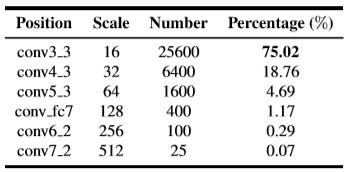
下图为每个anchor提取层提取出的anchor的数量及其占比,可见在最底层提取的anchor的数量超过总体anchor的75%,因此小anchor中negative anchor的可能性更高。
论文中在conv3_3层后使用maxout background label:对每个anchor,预测Nm个背景标签的分数,然后选择最高的作为最终分数。可以预见,使用这种方法,可以刷掉很多的negative anchor。
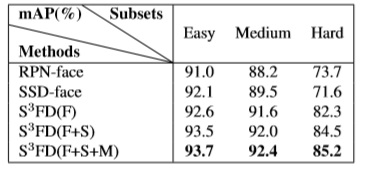
下图为论文实验中的消融实验的结果:F是第1、2种方法,S是第3种方法,M是第4种方法。从表格中可以看出,每增加一种方法,效果都在增强。
&尚待学习的问题
关于等比例间隔原则,还存在一些问题,在卷积层上的所有提取anchor的层中,只要anchor的尺度在当前层上是相同的,那么就相当于是等比例间隔原则。但是怎么实现的不同尺度的anchor在图像中也能有着相同的密度,这个密度是什么意思?显然不是指数量,毕竟大的anchor的数量肯定少。那么有着相同的密度似乎不太合理。
对于等比例原则概念,先前的理解有点问题,所谓等比例原则应当是在每一特征层上选择的anchor尺度与使用的每个anchor相隔的stride的比例是相同的。但是从整体的处理来看,因为anchor映射到对应层级上后,在每一层上的间隔都是相同的,也即等比例原则。从表中的数据可以看出,每个层级对应的anchor都是4×4的大小,每次滑动n/4的位移,对应到每一层上就是1个像素点,因此相当于对每个特征层上的每一个像素点都划一个anchor。
&思考与启发
本文最主要的创新点在于考虑每个目标能够匹配的anchor的数量,从而一定程度上增加召回率,以增强检测目标的精度,同时使用最大化背景概率来降低整体的虚警。其实本文中的创新点处理起来并不难,主要是没有在这种个方向上进行思考,对问题的根源没有了解的很清楚,这篇论文给人的感觉就是原来这么简单就可以提升性能,要学会从另一个角度看问题,从而找到解决方案。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号