
HBase数仓传智播客课堂笔记
HBase第一天
Hadoop和HBase
- HBase是基于Hadoop集群之上来搭建的
- Hadoop有一些局限性的:
- 做一些批量的数据处理,吞吐量比较高,但是它对随机查询、实时操作性能是不行的
- HBase是NoSQL数据库的一种,它跟传统的RDBMS有很大的差别
- 不支持JOIN的,摒弃了关系型模型,而且在HBase中只有一种数据类型:byte[]
- HBase可以用来存储非常大的表,上亿行的数据、有超过百万列,而且它常用在实时数据处理中。因为它的读写是很快的。
HBase的应用场景
- HBase只要有海量数据存储,而且需要快速的写入以及快速的读取场景,就很适合HBase
- 但要记住NoSQL的特点:对事务的支持性较弱的
- 可以用来存储爬虫的数据、点赞/转发、银行转账订单....
Hbase对于RDBMS对比Hive
- RDBMS是关系型数据库支持join、ACID、有schema(创建表的时候必须要指定有哪些列、列是什么类型)...、支持二级索引
- HBase不支持join的、也不支持ACID、对事务支持有限,无schema(创建表的时候,无需去指定列、列类型)、原生就支持分布式存储的,所以可以用来存储海量数据,同时也兼顾了快速查询、写入的功能
对比Hive:
- Hive主要用于OLAP,HBase主要用于OLTP,HBase是可以直接接入到业务系统的
HBase的安装
注意:
- HBase依赖于:ZooKeeper、HDFS,在启动HBase之前必须要启动ZK、HDFS,否则HBase无法启动
- Webui: http://node1.itcast.cn:16010/master-status#baseStats
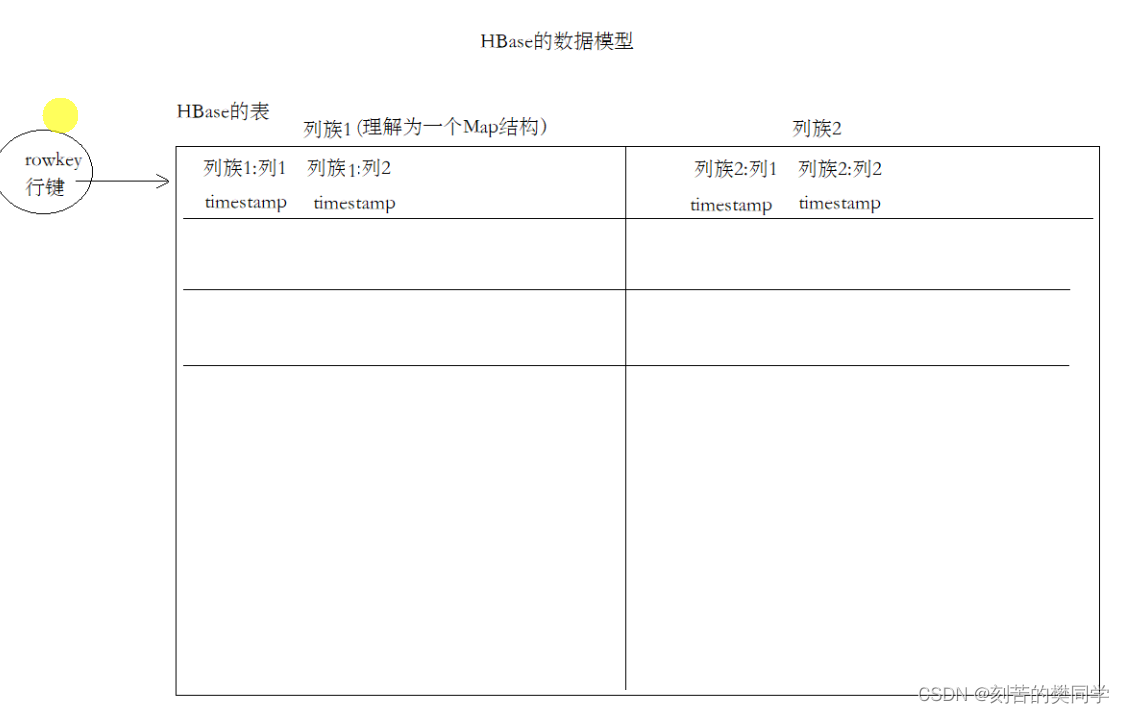
5. HBase的数据模型
- HBase中是有表的概念的
- 一个表中可以包含多个列族
- 一个列族可以包含很多的列
- 每一个列对应的单元格(值、timestamp)
HBase的一些操作
创建表
- HBase是没有schema的,就是在创建表的时候不需要指定表中有哪些列,只需要指定有多少个列蔟
create "表名","列蔟1", "列蔟2"
删除表
-
禁用表
disable "表名"
-
删除表
drop "删除表"
新增数据/更新数据/删除数据/查询数据
-
新增:put "表名", "rowkey", "列蔟:列名", "值"
- 新增一列
-
更新:和新增是一样的
-
删除数据
- delete "表名", "rowkey", "列蔟:列名"
- delete也是删除一个列
- deleteall "表名", "rowkey"
- 删除一行
- delete "表名", "rowkey", "列蔟:列名"
-
查询数据
- get "表名", "rowkey"
- get是查询一行的数据
- get "表名", "rowkey"
-
删除数据的时候,其实HBase不是真的直接把数据删除掉,而是给某个列设置一个标志,然后查询数据的时候,有这个标志的数据,就不显示出来
-
什么时候真正的删除数据呢?
- 后台进程,专门来执行删除数据的操作
执行delete的时候
- 如果表中的某个列有对一个的几次修改,它会删除最近的一次修改
- 默认是保存1个保存的时间戳
- 有一个version属性
计数器和简单scan扫描操作
- 计数器
- count "表名":hbase就会将这个表对应的所有数据都扫描一遍,得到最终的记录条数(慎用)
- 执行HBase提供的基于MR的RowCounter的程序(用于做大批量数据的查询)
- 启动yarn集群
- 启动mr-historyserver
- scan扫描
- 全表扫描:scan "表名"(慎用,效率很低)
- 限定只显示多少条: scan "表名",
- 指定查询某几个列: scan "表名",
- 根据ROWKEY来查询:scan "表名",
使用过滤器的重点
- 语法:
- 其实在hbase shell中,执行的ruby脚本,背后还是调用hbase提供的Java API
- 在HBase中有很多的多过滤器,语法格式看起来会比较复杂,所以重点理解这个语法是什么意思
- 过滤器在hbase shell中是使用一个表达式来描述,在Java里面new各种对象
scan "ORDER_INFO", {FILTER => "RowFilter(=,'binary:02602f66-adc7-40d4-8485-76b5632b5b53')", COLUMNS => ['C1:STATUS', 'C1:PAYWAY'], FORMATTER => 'toString'}
"RowFilter(=,'binary:02602f66-adc7-40d4-8485-76b5632b5b53')"这个就是一个表达式- RowFilter就是Java API中Filter的构造器名称
- 可以理解为RowFilter()就是创建一个过滤器对象
- =是JRuby一个特殊记号,表示是一个比较运算符,还可以是>、<、>=...
- binary:02602f66-adc7-40d4-8485-76b5632b5b53是一个比较器的表达式,为了方便大家理解,可以将比较器理解为配置值的地方,binary:xxxx表示直接和值进行毕节
使用HBase的计数器
- 要使用incr来去初始化一个列,一定不能使用put操作
- 可以使用get_couter的指令来获取计数器的操作,使用get是获取不到计数器的数据的
- incr "表名", "rowkey", "列蔟:列", xxx
HBase一些管理命令
- status:常用命令,可以查看整个集群的运行的节点数
- whoami:查看当前的用户
- disable/enable:禁用/开启表
- drop:删除表
- exists:判断表是否存在
- truncate:清空表
HBase 建表操作
创建连接
- 建立HBase连接
- 创建admin对象
@BeforeTest
public void beforeTest() throws IOException {
// 1. 使用HbaseConfiguration.create()创建Hbase配置
Configuration configuration = HBaseConfiguration.create();
// 2. 使用ConnectionFactory.createConnection()创建Hbase连接
connection = ConnectionFactory.createConnection(configuration);
// 3. 要创建表,需要基于Hbase连接获取admin管理对象
// 要创建表、删除表需要和HMaster连接,所以需要有一个admin对象
admin = connection.getAdmin();
}
创建表
- 调用tableExists判断表是否存在
- 在HBase中,要去创建表,需要构建TableDescriptor(表描述器)、ColumnFamilyDescriptor(列蔟描述器),这两个对象不是直接new出来,是通过builder来创建的
- 将列蔟描述器添加到表描述器中
- 使用admin.createTable创建表
@Test
public void createTableTest() throws IOException {
TableName tableName = TableName.valueOf("WATER_BILL");
// 1. 判断表是否存在
if(admin.tableExists(tableName)) {
// a) 存在,则退出
return;
}
// 构建表
// 2. 使用TableDescriptorBuilder.newBuilder构建表描述构建器
// TableDescriptor: 表描述器,描述这个表有几个列蔟、其他的属性都是在这里可以配置
TableDescriptorBuilder tableDescriptorBuilder = TableDescriptorBuilder.newBuilder(tableName);
// 3. 使用ColumnFamilyDescriptorBuilder.newBuilder构建列蔟描述构建器
// 创建列蔟也需要有列蔟的描述器,需要用一个构建起来构建ColumnFamilyDescriptor
// 经常会使用到一个工具类:Bytes(hbase包下的Bytes工具类)
// 这个工具类可以将字符串、long、double类型转换成byte[]数组
// 也可以将byte[]数组转换为指定类型
ColumnFamilyDescriptorBuilder columnFamilyDescriptorBuilder = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes("C1"));
// 4. 构建列蔟描述,构建表描述
ColumnFamilyDescriptor cfDes = columnFamilyDescriptorBuilder.build();
// 建立表和列蔟的关联
tableDescriptorBuilder.setColumnFamily(cfDes);
TableDescriptor tableDescriptor = tableDescriptorBuilder.build();
// 5. 创建表
admin.createTable(tableDescriptor);
}
在HBase中所有的数据都是以byte[]形式来存储的,所以需要将Java的数据类型进行转换
// 经常会使用到一个工具类:Bytes(hbase包下的Bytes工具类) // 这个工具类可以将字符串、long、double类型转换成byte[]数组 // 也可以将byte[]数组转换为指定类型
插入数据
- 首先要获取一个Table对象,这个对象是要和HRegionServer节点连接,所以将来HRegionServer负载是比较高的
- HBase的connection对象是一个重量级的对象,将来编写代码(Spark、Flink)的时候,避免频繁创建,使用一个对象就OK,因为它是线程安全的
Connection creation is a heavy-weight operation. Connection implementations are thread-safe
- Table这个对象是一个轻量级的,用完Table需要close,因为它是非线程安全的
Lightweight. Get as needed and just close when done.
-
需要构建Put对象,然后往Put对象中添加列蔟、列、值
-
当执行一些繁琐重复的操作用列标记:
- ctrl + shift + ←/→,可以按照单词选择,非常高效
通过ROWKEY获取数据
- 构建一个PUT对象,根据rowkey来查询一行数据
- 遍历单元格,使用Bytes.toString来进行类型转换
@Test
public void getTest() throws IOException {
// 1. 获取HTable
Table table = connection.getTable(TABLE_NAME);
// 2. 使用rowkey构建Get对象
Get get = new Get(Bytes.toBytes("4944191"));
// 3. 执行get请求
Result result = table.get(get);
// 4. 获取所有单元格
// 列出所有的单元格
List<Cell> cellList = result.listCells();
// 5. 打印rowkey
byte[] rowkey = result.getRow();
System.out.println(Bytes.toString(rowkey));
// 6. 迭代单元格列表
for (Cell cell : cellList) {
// 将字节数组转换为字符串
// 获取列蔟的名称
String cf = Bytes.toString(cell.getFamilyArray(), cell.getFamilyOffset(), cell.getFamilyLength());
// 获取列的名称
String columnName = Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength());
// 获取值
String value = Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength());
System.out.println(cf + ":" + columnName + " -> " + value);
}
// 7. 关闭表
table.close();
}
HBase的Java API scan + filter过滤操作
- ResultScanner需要手动关闭,这个操作是比较消耗资源的,用完就应该关掉,不能一直都开着
- 扫描使用的是Scan对象
- SingleColumnValueFilter——过滤单列值的过滤器
- FilterList——是可以用来组合多个过滤器
@Test
public void scanFilterTest() throws IOException {
// 1. 获取表
Table table = connection.getTable(TABLE_NAME);
// 2. 构建scan请求对象
Scan scan = new Scan();
// 3. 构建两个过滤器
// a) 构建两个日期范围过滤器(注意此处请使用RECORD_DATE——抄表日期比较
SingleColumnValueFilter startFilter = new SingleColumnValueFilter(Bytes.toBytes("C1")
, Bytes.toBytes("RECORD_DATE")
, CompareOperator.GREATER_OR_EQUAL
, new BinaryComparator(Bytes.toBytes("2020-06-01")));
SingleColumnValueFilter endFilter = new SingleColumnValueFilter(Bytes.toBytes("C1")
, Bytes.toBytes("RECORD_DATE")
, CompareOperator.LESS_OR_EQUAL
, new BinaryComparator(Bytes.toBytes("2020-06-30")));
// b) 构建过滤器列表
FilterList filterList = new FilterList(FilterList.Operator.MUST_PASS_ALL, startFilter, endFilter);
// 4. 执行scan扫描请求
scan.setFilter(filterList);
ResultScanner resultScanner = table.getScanner(scan);
Iterator<Result> iterator = resultScanner.iterator();
// 5. 迭代打印result
while(iterator.hasNext()) {
Result result = iterator.next();
// 列出所有的单元格
List<Cell> cellList = result.listCells();
// 5. 打印rowkey
byte[] rowkey = result.getRow();
System.out.println(Bytes.toString(rowkey));
// 6. 迭代单元格列表
for (Cell cell : cellList) {
// 将字节数组转换为字符串
// 获取列蔟的名称
String cf = Bytes.toString(cell.getFamilyArray(), cell.getFamilyOffset(), cell.getFamilyLength());
// 获取列的名称
String columnName = Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength());
String value = "";
// 解决乱码问题:
// 思路:
// 如果某个列是以下列中的其中一个,调用toDouble将它认为是一个数值来转换
//1. NUM_CURRENT
//2. NUM_PREVIOUS
//3. NUM_USAGE
//4. TOTAL_MONEY
if(columnName.equals("NUM_CURRENT")
|| columnName.equals("NUM_PREVIOUS")
|| columnName.equals("NUM_USAGE")
|| columnName.equals("TOTAL_MONEY")) {
value = Bytes.toDouble(cell.getValueArray()) + "";
}
else {
// 获取值
value = Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength());
}
System.out.println(cf + ":" + columnName + " -> " + value);
}
}
// 7. 关闭ResultScanner(这玩意把转换成一个个的类似get的操作,注意要关闭释放资源)
resultScanner.close();
// 8. 关闭表
table.close();
}
HBase的HMaster高可用
- HBase的HA也是通过ZK来实现的(临时节点、watch机制)
- 只需要添加一个backup-masters文件,往里面添加要称为Backup master的节点,HBase启动的时候,会自动启动多个HMaster
- HBase配置了HA后,对Java代码没有影响。因为Java代码是通过从ZK中来获取Master的地址的
HBase的存储架构
- 进程角色
- client:客户端,写的Java程序、hbase shell都是客户端(Flink、MapReduce、Spark)
- HMaster:主要是负责表的管理操作(创建表、删除表、Region分配),不负责具体的数据操作
- HRegionServer:负责数据的管理、数据的操作(增删改查)、负责接收客户端的请求来操作数据
- HBase架构的一些关键概念
- Region:一个表由多个Region组成,每个Region保存一定的rowkey范围的数据,Region中的数据一定是有序的,是按照rowkey的字典序来排列的
- Store:存储的是表中每一个列蔟的数据
- MemStore:所有的数据都是先写入到MemStore中,可以让读写操作更快,当MemStore快满的时候,需要有一个线程定期的将数据Flush到磁盘中
- HFile:在HDFS上保存的数据,是HBase独有的一种数据格式(丰富的结构、索引、DataBlock、BloomFilter布隆过滤器...)
- WAL:WAL预写日志,当客户端连接RegionServer写数据的时候,会先写WAL预写日志,put/delete/incr命令写入到WAL,有点类似于之前Redis中的AOF,当某一个RegionServer出现故障时,还可以通过WAL来恢复数据,恢复的就是MemStore的数据。
HBase第二天课堂笔记
名称空间
- namespace:名称空间
- 默认hbase有两个名称空间,default、hbase
- default名称空间是默认创建表的位置,hbase是专门存放系统表的名称空间(namespace、meta)
- 管理命名空间指令
- create_namespace 命名空间名称
- drop_namespace 删除
- list_namespace
- describe_namespace
- 在命名空间中创建表
- create "命名空间:表名"
表的设计
- 列蔟:推荐1-2个,能使用1个就不是使用2个
- 版本的设计:如果我们的项目不需要保存历史的版本,直接按照默认配置VERSIONS=1就OK。如果项目中需要保存历史的变更信息,就可以将VERSIONS设置为>1。但是设置为大于1也就意味着要占用更多的空间
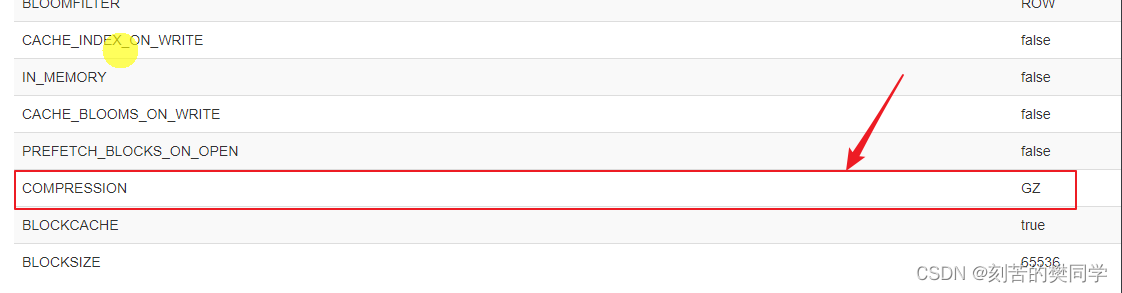
- 数据的压缩:在创建表的时候,可以针对列蔟指定数据压缩方式(GZ、SNAPPY、LZO)。GZ方式是压缩比最高的,13%左右的空间,但是它的压缩和解压缩速度慢一些
避免热点的关键操作
-
预分区
- 在创建表的时候,配置一些策略,让一个table有多个region,分布在不同的HRegionServer中
- HBase会自动进行split,如果一个region过大,HBase会自动split成两个,就是根据rowkey来横向切分
-
rowkey设计
-
反转:举例:手机号码、时间戳,可以将手机号码反转
-
加盐:在rowkey前面加随机数,加了随机数之后,就会导致数据查询不出来,因为HBase默认是没有二级索引的
-
hash:根据rowkey中的某个部分取hash,因为hash每次计算都一样的值。所以,我们可以用hash操作获取数据
-
这几种策略,因为要将数据均匀分布在集群中的每个RegionServer,所以其核心就是把rowkey打散后放入到集群节点中,所以数据不再是有序的存储,会导致scan的效率下降
-
预分区
-
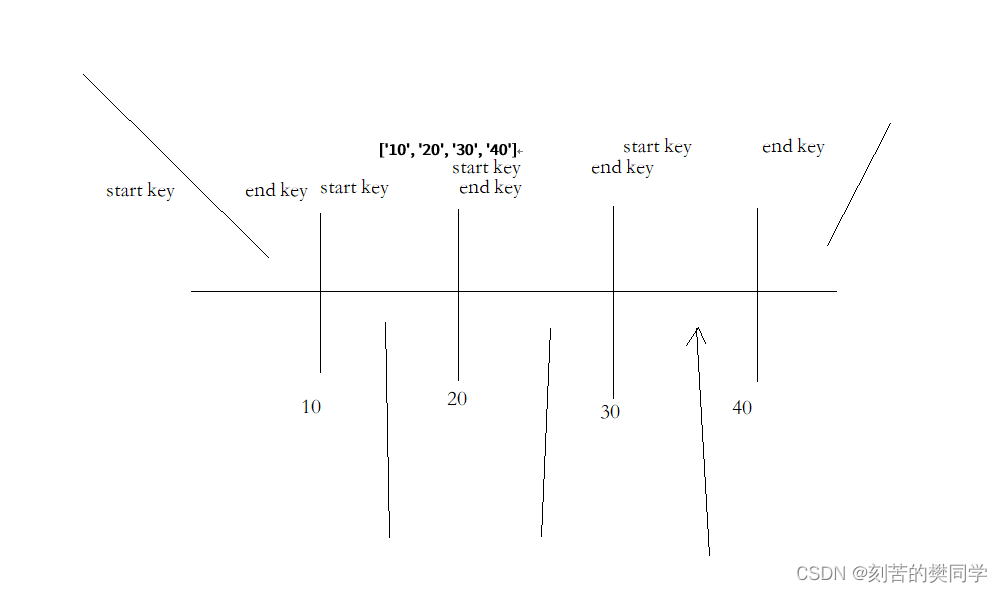
预分区有两种策略
-
startKey、endKey来预分区 [10, 40, 50]
-
直接指定数量,startKey、endKey由hbase自动生成,还需要指定key的算法
-
-
HBase的数据都是存放在HDFS中
- /hbase/data/命名空间/表/列蔟/StoreFiles
陌陌消息项目开发
项目初始化
IDEA如果依赖报错,
- 选择源码文件,执行idea中的rebuild
- 执行maven的compile
- 关掉idea,再打开一次
随机生成一条消息
- 通过ExcelReader工具类从Excel文件中读取数据,放入到一个Map结构中
- key:字段名
- value:List,字段对应的数据列表
- 创建getOneMessage方法,这个方法专门用来根据Excel读取到的数据,随机生成一个Msg实体对象
- 调用ExcelReader.randomColumn方法来随机获取一个列的数据
- 注意:消息使用的是系统当前时间,时间的格式是:年-月-日 小时:分钟:秒
public class MoMoMsgGen {
public static void main(String[] args) {
// 读取Excel文件中的数据
Map<String, List<String>> resultMap =
ExcelReader.readXlsx("D:\\课程研发\\51.V8.0_NoSQL_MQ\\2.HBase\\3.代码\\momo_chat_app\\data\\测试数据集.xlsx", "陌陌数据");
System.out.println(getOneMessage(resultMap));
}
/**
* 基于从Excel表格中读取的数据随机生成一个Msg对象
* @param resultMap Excel读取的数据(Map结构)
* @return 一个Msg对象
*/
public static Msg getOneMessage(Map<String, List<String>> resultMap) {
// 1. 构建Msg实体类对象
Msg msg = new Msg();
// 将当前系统的时间设置为消息的时间,以年月日 时分秒的形式存储
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
// 获取系统时间
Date now = new Date();
msg.setMsg_time(simpleDateFormat.format(now));
// 2. 调用ExcelReader中的randomColumn随机生成一个列的数据
// 初始化sender_nickyname字段,调用randomColumn随机取nick_name设置数据
msg.setSender_nickyname(ExcelReader.randomColumn(resultMap, "sender_nickyname"));
msg.setSender_account(ExcelReader.randomColumn(resultMap, "sender_account"));
msg.setSender_sex(ExcelReader.randomColumn(resultMap, "sender_sex"));
msg.setSender_ip(ExcelReader.randomColumn(resultMap, "sender_ip"));
msg.setSender_os(ExcelReader.randomColumn(resultMap, "sender_os"));
msg.setSender_phone_type(ExcelReader.randomColumn(resultMap, "sender_phone_type"));
msg.setSender_network(ExcelReader.randomColumn(resultMap, "sender_network"));
msg.setSender_gps(ExcelReader.randomColumn(resultMap, "sender_gps"));
msg.setReceiver_nickyname(ExcelReader.randomColumn(resultMap, "receiver_nickyname"));
msg.setReceiver_ip(ExcelReader.randomColumn(resultMap, "receiver_ip"));
msg.setReceiver_account(ExcelReader.randomColumn(resultMap, "receiver_account"));
msg.setReceiver_os(ExcelReader.randomColumn(resultMap, "receiver_os"));
msg.setReceiver_phone_type(ExcelReader.randomColumn(resultMap, "receiver_phone_type"));
msg.setReceiver_network(ExcelReader.randomColumn(resultMap, "receiver_network"));
msg.setReceiver_gps(ExcelReader.randomColumn(resultMap, "receiver_gps"));
msg.setReceiver_sex(ExcelReader.randomColumn(resultMap, "receiver_sex"));
msg.setMsg_type(ExcelReader.randomColumn(resultMap, "msg_type"));
msg.setDistance(ExcelReader.randomColumn(resultMap, "distance"));
msg.setMessage(ExcelReader.randomColumn(resultMap, "message"));
// 3. 注意时间使用系统当前时间
return msg;
}
}
生成rowkey
- ROWKEY = MD5Hash_发件人账号_收件人账号_消息时间戳
- MD5Hash.getMD5AsHex生成MD5值,为了缩短rowkey,取前8位
// 根据Msg实体对象生成rowkey
public static byte[] getRowkey(Msg msg) throws ParseException {
//
// ROWKEY = MD5Hash_发件人账号_收件人账号_消息时间戳
//
// 使用StringBuilder将发件人账号、收件人账号、消息时间戳使用下划线(_)拼接起来
StringBuilder builder = new StringBuilder();
builder.append(msg.getSender_account());
builder.append("_");
builder.append(msg.getReceiver_account());
builder.append("_");
// 获取消息的时间戳
String msgDateTime = msg.getMsg_time();
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Date msgDate = simpleDateFormat.parse(msgDateTime);
long timestamp = msgDate.getTime();
builder.append(timestamp);
// 使用Bytes.toBytes将拼接出来的字符串转换为byte[]数组
// 使用MD5Hash.getMD5AsHex生成MD5值,并取其前8位
String md5AsHex = MD5Hash.getMD5AsHex(builder.toString().getBytes());
String md5Hex8bit = md5AsHex.substring(0, 8);
// 再将MD5值和之前拼接好的发件人账号、收件人账号、消息时间戳,再使用下划线拼接,转换为Bytes数组
String rowkeyString = md5Hex8bit + "_" + builder.toString();
System.out.println(rowkeyString);
return Bytes.toBytes(rowkeyString);
}
将随机生成的数据推入到HBase
public static void main(String[] args) throws ParseException, IOException {
// 读取Excel文件中的数据
Map<String, List<String>> resultMap =
ExcelReader.readXlsx("D:\\课程研发\\51.V8.0_NoSQL_MQ\\2.HBase\\3.代码\\momo_chat_app\\data\\测试数据集.xlsx", "陌陌数据");
// 生成数据到HBase中
// 1. 获取Hbase连接
Configuration config = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(config);
// 2. 获取HBase表MOMO_CHAT:MSG
Table table = connection.getTable(TableName.valueOf("MOMO_CHAT:MSG"));
int i = 0;
int MAX = 100000;
while (i < MAX) {
Msg msg = getOneMessage(resultMap);
// 3. 初始化操作Hbase所需的变量(列蔟、列名)
byte[] rowkey = getRowkey(msg);
String cf = "C1";
String colMsg_time = "msg_time";
String colSender_nickyname = "sender_nickyname";
String colSender_account = "sender_account";
String colSender_sex = "sender_sex";
String colSender_ip = "sender_ip";
String colSender_os = "sender_os";
String colSender_phone_type = "sender_phone_type";
String colSender_network = "sender_network";
String colSender_gps = "sender_gps";
String colReceiver_nickyname = "receiver_nickyname";
String colReceiver_ip = "receiver_ip";
String colReceiver_account = "receiver_account";
String colReceiver_os = "receiver_os";
String colReceiver_phone_type = "receiver_phone_type";
String colReceiver_network = "receiver_network";
String colReceiver_gps = "receiver_gps";
String colReceiver_sex = "receiver_sex";
String colMsg_type = "msg_type";
String colDistance = "distance";
String colMessage = "message";
// 4. 构建put请求
Put put = new Put(rowkey);
// 5. 挨个添加陌陌消息的所有列
put.addColumn(Bytes.toBytes(cf), Bytes.toBytes(colMsg_time), Bytes.toBytes(msg.getMsg_time()));
put.addColumn(Bytes.toBytes(cf), Bytes.toBytes(colSender_nickyname), Bytes.toBytes(msg.getSender_nickyname()));
put.addColumn(Bytes.toBytes(cf), Bytes.toBytes(colSender_account), Bytes.toBytes(msg.getSender_account()));
put.addColumn(Bytes.toBytes(cf), Bytes.toBytes(colSender_sex), Bytes.toBytes(msg.getSender_sex()));
put.addColumn(Bytes.toBytes(cf), Bytes.toBytes(colSender_ip), Bytes.toBytes(msg.getSender_ip()));
put.addColumn(Bytes.toBytes(cf), Bytes.toBytes(colSender_os), Bytes.toBytes(msg.getSender_os()));
put.addColumn(Bytes.toBytes(cf), Bytes.toBytes(colSender_phone_type), Bytes.toBytes(msg.getSender_phone_type()));
put.addColumn(Bytes.toBytes(cf), Bytes.toBytes(colSender_network), Bytes.toBytes(msg.getSender_network()));
put.addColumn(Bytes.toBytes(cf), Bytes.toBytes(colSender_gps), Bytes.toBytes(msg.getSender_gps()));
put.addColumn(Bytes.toBytes(cf), Bytes.toBytes(colReceiver_nickyname), Bytes.toBytes(msg.getReceiver_nickyname()));
put.addColumn(Bytes.toBytes(cf), Bytes.toBytes(colReceiver_ip), Bytes.toBytes(msg.getReceiver_ip()));
put.addColumn(Bytes.toBytes(cf), Bytes.toBytes(colReceiver_account), Bytes.toBytes(msg.getReceiver_account()));
put.addColumn(Bytes.toBytes(cf), Bytes.toBytes(colReceiver_os), Bytes.toBytes(msg.getReceiver_os()));
put.addColumn(Bytes.toBytes(cf), Bytes.toBytes(colReceiver_phone_type), Bytes.toBytes(msg.getReceiver_phone_type()));
put.addColumn(Bytes.toBytes(cf), Bytes.toBytes(colReceiver_network), Bytes.toBytes(msg.getReceiver_network()));
put.addColumn(Bytes.toBytes(cf), Bytes.toBytes(colReceiver_gps), Bytes.toBytes(msg.getReceiver_gps()));
put.addColumn(Bytes.toBytes(cf), Bytes.toBytes(colReceiver_sex), Bytes.toBytes(msg.getReceiver_sex()));
put.addColumn(Bytes.toBytes(cf), Bytes.toBytes(colMsg_type), Bytes.toBytes(msg.getMsg_type()));
put.addColumn(Bytes.toBytes(cf), Bytes.toBytes(colDistance), Bytes.toBytes(msg.getDistance()));
put.addColumn(Bytes.toBytes(cf), Bytes.toBytes(colMessage), Bytes.toBytes(msg.getMessage()));
// 6. 发起put请求
table.put(put);
// 显示进度
++i;
System.out.println(i + " / " + MAX);
}
table.close();
connection.close();
}
实现getMessage数据服务接口
使用scan + filter实现的
- 构建scan对象
- 构建4个filter(开始日期查询、结束日期查询、发件人、收件人)
- 构建一个Msg对象列表
/**
*
* @param date 日期 2020-09-10
* @param sender 发件人
* @param receiver 收件人
* @return
* @throws Exception
*/
@Override
public List<Msg> getMessage(String date, String sender, String receiver) throws Exception {
// 1. 构建scan对象
Scan scan = new Scan();
// 构建两个带时分秒的日期字符串
String startDateStr = date + " 00:00:00";
String endDateStr = date + " 23:59:59";
// 2. 构建用于查询时间的范围,例如:2020-10-05 00:00:00 – 2020-10-05 23:59:59
// 3. 构建查询日期的两个Filter,大于等于、小于等于,此处过滤单个列使用SingleColumnValueFilter即可。
SingleColumnValueFilter startDateFilter = new SingleColumnValueFilter(Bytes.toBytes("C1")
, Bytes.toBytes("msg_time")
, CompareOperator.GREATER_OR_EQUAL
, new BinaryComparator(Bytes.toBytes(startDateStr)));
SingleColumnValueFilter endDateFilter = new SingleColumnValueFilter(Bytes.toBytes("C1")
, Bytes.toBytes("msg_time")
, CompareOperator.LESS_OR_EQUAL
, new BinaryComparator(Bytes.toBytes(endDateStr)));
// 4. 构建发件人Filter
SingleColumnValueFilter senderFilter = new SingleColumnValueFilter(Bytes.toBytes("C1")
, Bytes.toBytes("sender_account")
, CompareOperator.EQUAL
, new BinaryComparator(Bytes.toBytes(sender)));
// 5. 构建收件人Filter
SingleColumnValueFilter receiverFilter = new SingleColumnValueFilter(Bytes.toBytes("C1")
, Bytes.toBytes("receiver_account")
, CompareOperator.EQUAL
, new BinaryComparator(Bytes.toBytes(receiver)));
// 6. 使用FilterList组合所有Filter
FilterList filterList = new FilterList(FilterList.Operator.MUST_PASS_ALL
, startDateFilter
, endDateFilter
, senderFilter
, receiverFilter);
// 7. 设置scan对象filter
scan.setFilter(filterList);
// 8. 获取HTable对象,并调用getScanner执行
Table table = connection.getTable(TableName.valueOf("MOMO_CHAT:MSG"));
ResultScanner resultScanner = table.getScanner(scan);
// 9. 获取迭代器,迭代每一行,同时迭代每一个单元格
Iterator<Result> iterator = resultScanner.iterator();
// 创建一个列表,用于保存查询出来的消息
ArrayList<Msg> msgList = new ArrayList<>();
while(iterator.hasNext()) {
// 每一行查询出来的数据都是一个Msg对象
Result result = iterator.next();
Msg msg = new Msg();
// 获取rowkey
String rowkey = Bytes.toString(result.getRow());
// 单元格列表
List<Cell> cellList = result.listCells();
for (Cell cell : cellList) {
// 根据当前的cell单元格的列名来判断,设置对应的字段
String columnName = Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength());
if(columnName.equals("msg_time")) {
msg.setMsg_time(Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));
}
if(columnName.equals("sender_nickyname")){
msg.setSender_nickyname(Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));
}
if(columnName.equals("sender_account")){
msg.setSender_account(Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));
}
if(columnName.equals("sender_sex")){
msg.setSender_sex(Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));
}
if(columnName.equals("sender_ip")){
msg.setSender_ip(Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));
}
if(columnName.equals("sender_os")){
msg.setSender_os(Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));
}
if(columnName.equals("sender_phone_type")){
msg.setSender_phone_type(Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));
}
if(columnName.equals("sender_network")){
msg.setSender_network(Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));
}
if(columnName.equals("sender_gps")){
msg.setSender_gps(Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));
}
if(columnName.equals("receiver_nickyname")){
msg.setReceiver_nickyname(Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));
}
if(columnName.equals("receiver_ip")){
msg.setReceiver_ip(Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));
}
if(columnName.equals("receiver_account")){
msg.setReceiver_account(Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));
}
if(columnName.equals("receiver_os")){
msg.setReceiver_os(Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));
}
if(columnName.equals("receiver_phone_type")){
msg.setReceiver_phone_type(Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));
}
if(columnName.equals("receiver_network")){
msg.setReceiver_network(Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));
}
if(columnName.equals("receiver_gps")){
msg.setReceiver_gps(Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));
}
if(columnName.equals("receiver_sex")){
msg.setReceiver_sex(Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));
}
if(columnName.equals("msg_type")){
msg.setMsg_type(Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));
}
if(columnName.equals("distance")){
msg.setDistance(Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));
}
if(columnName.equals("message")){
msg.setMessage(Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));
}
}
msgList.add(msg);
}
// 关闭资源
resultScanner.close();
table.close();
return msgList;
}
Apache Phoenix
简介
- Apache Phoenix基于HBase的一个SQL引擎,我们可以使用Phoenix在HBase之上提供SQL语言的支持。
- Phoenix是可以支持二级索引的,而且Phoenix它自动帮助我们管理二级索引,底层是通过HBase的协处理器来实现的,通过配合二级索引和HBase rowkey,可以提升hbase的查询效率
- Phoenix底层还是将SQL语言解析为HBase的原生查询(put/get/scan),所以它的定位还是在随机实时查询——OLTP领域
- Apache Phoenix不是独立运行的,而是提供一些JAR包,扩展了HBase的功能
Phoenix安装
- Phoenix是基于HBase进行扩展的,核心就是一些phoenix开头的jar包,这些jar包实现了很多的协处理器(当执行put/delete/get这些操作的时候,可以执行一段特殊的代码)
- 安装的时候注意:
- 将phoenix开头的jar包复制到每一个hbase的节点
- hbase-site.xml需要复制到每一个节点
Phoenix的建表语法
在Phoenix中,要执行SQL,必须要建立表的结构,然后才能查询。默认Phoenix不会之前在Hbase使用create创建的表加载进来。
create table if not exists ORDER_DTL(
"id" varchar primary key,
"C1"."status" varchar,
"C1"."money" double,
"C1"."pay_way" integer,
"C1"."user_id" varchar,
"C1"."operation_time" varchar,
"C1"."category" varchar
);
注意事项:
- 每个表必须要有rowkey,通过指定某一个列后面的primary key,就表示该列就是rowkey
- 每个除了rowkey的列必须要带列蔟名,Phoenix会自动帮助我们创建列蔟
- 大小写的问题,在Phoenix如果要使用小写,必须得带双引号。否则会自动转换为大小,如果使用小写将来编写的任何SQL语句都得带双引号
Phoenix数据操作
-
插入/更新都是使用upsert
upsert 表名(列蔟.列1, 列蔟.列2,...) values(...) -
删除
delete from 表名 where ... -
查询
select *或列名 from 表名 where
注意大小写问题,如果列名是小写,必须要加上双引号
Phoenix预分区
- 在将来使用Phoenix创建表的时候,也可以指定预分区
- 基于rowkey来进行分区
- 指定分区的数量
-- 1. 使用指定rowkey来进行预分区
drop table if exists ORDER_DTL;
create table if not exists ORDER_DTL(
"id" varchar primary key,
C1."status" varchar,
C1."money" float,
C1."pay_way" integer,
C1."user_id" varchar,
C1."operation_time" varchar,
C1."category" varchar
)
CONPRESSION='GZ'
SPLIT ON ('3','5','7');
-- 2. 直接指定Region的数量来进行预分区
drop table if exists ORDER_DTL;
create table if not exists ORDER_DTL(
"id" varchar primary key,
C1."status" varchar,
C1."money" float,
C1."pay_way" integer,
C1."user_id" varchar,
C1."operation_time" varchar,
C1."category" varchar
)
CONPRESSION='GZ', SALT_BUCKETS=10;
Phoenix创建视图
-
将HBase已经存在的表进行映射
-
名称空间和表名一模一样
-
列蔟名和列名也必须要一一对应
create view "名称空间"."表名"(
rowkey对应列名 varchar primary key,
"列蔟名"."列名" varchar,
);
Phoenix JDBC开发
驱动:PhoenixDriver.class.getName()
JDBC连接URL:jdbc:phoenix:node1.itcast.cn:2181
- 加载JDBC驱动
- 使用DriverManager获取连接
- 准备一个SQL语句
- 准备PrepareStatement
- 设置参数
- 执行语句
- 遍历结果
- 关闭资源
Phoneix索引的分类
- 全局索引
- 针对整个表,在整个HBase集群中,都是有效的,索引数据会分布在全局
- 本地索引
- 索引数据和表数据存储在一起,方便高效查询
- 覆盖索引
- 将数据直接放入在索引中,直接查询索引就可以将数据查询出来,避免再根据rowkey查询数据
- 函数索引
- 基于一个函数表达式来建立索引,例如: where substr(xxx, 0, 10)....,就可以基于substr(xxx, 0, 10)建立索引
全局索引+覆盖索引
全局索引会独立创建一张HBase的表来保存索引数据,一般经常配合覆盖索引使用。将要查询的列、以及索引列全部的数据保存在索引表中,这样,可以有效避免,查索引之后还要去查询数据表。一次查询,全部搞定。
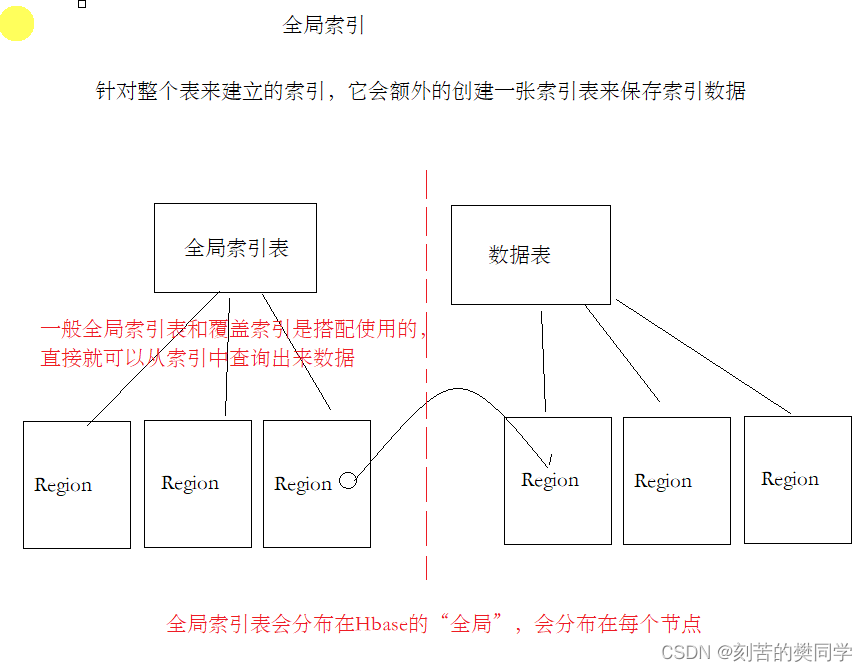
-- 二、在phoenix中创建二级索引
-- 根据用户ID来查询订单的ID以及对应的支付金额
-- 建立一个覆盖索引,加快查询
create index IDX_USER_ID on ORDER_DTL(C1."user_id") include ("id", C1."money");
-- 删除索引
drop index IDX_USER_ID on ORDER_DTL;
-- 强制使用索引查询
explain select /*+ INDEX(ORDER_DTL IDX_USER_ID) */ * from ORDER_DTL where "user_id" = '8237476';
本地索引
- 使用 create local index 索引名称 on 表名(列1, 列2)
- 本地索引对数据是有侵入性的,就是原先的数据会被编码处理,所以只要创建了本地索引,原先的数据就会隐藏起来
- 性能提升几十倍、上百倍
- 当drop掉索引后,数据又可以恢复回来
- 这些都是由Phoenix的协处理器来实现的
HBase第三天课堂笔记
HBase的读流程
- 客户端拿到一个rowkey(首先得要知道这个rowkey存在哪个region中)
- 根据zk获取hbase:meta表,这个表中存放了region的信息,根据namespace、表名,就可以根据rowkey查看是否匹配某个region的startkey、endkey,返回region的信息
- 还需要查询region是在哪个HRegionServer(因为我们是不知道region会在存在什么地方的)
- 读取Store
- 优先读取写缓存(MemStore)
- 读取BlockCache(LRUBlockCache、BucketBlockCache)
- 再读取HFile
HBase的写数据
写数据的流程:
(1-3是和读流程是类似的,都需要找到当前要写入的rowkey,应该存放在哪个region、哪个region server)
- 客户端拿到一个rowkey(首先得要知道这个rowkey存在哪个region中)
- 根据zk获取hbase:meta表,这个表中存放了region的信息,根据namespace、表名,就可以根据rowkey查看是否匹配某个region的startkey、endkey,返回region的信息
- 还需要查询region是在哪个HRegionServer(因为我们是不知道region会在存在什么地方的)
- 首先要将数据写入到MemStore中
- MemStore大小到达128M、MemStore数据已经超出一小时,会自动Flush到HDFS中的HFile
- compaction合并
- 一阶段合并:如果每一个MemStore写满后,都会一溢写到HFile中,这样会有很多的HFile,对将来的读取不利。所以需要将这些小的HFile合并成大一点的HFile
- 二阶段合并:将所有的HFile合并成一个HFile
HBase 2.0+ In memory compaction(总共的流程为三个阶段的合并)
- In memory comapaction主要是延迟flush到磁盘的时间,尽量优先写入到内存中,有一系列的合并优化操作
- 数据都是以segment(段)来保存的,首先数据会写到active segment,active segment写完后会将segment合并到piepline里面,合并pipeline的之后会有一定的策略
- basic:只管存,合并,不会优化重复数据
- eager:会将一些重复数据进行优化
- adaptive:会根据重复度来进行优化合并
- pipeline如果到达一定的阈值,就开始Flush
写数据的两阶段合并
- minor compaction
- 比较轻量级的,耗时比较短。一般一次不用合并太多(推荐:3个文件)
- 每一个memstore写满后,会flush,形成storefiles
- 如果storefiles多了之后,对读取是不利
- 所以storefiles需要合并
- major compaction
- 比较重量级的操作,在HBase读写并发比较高的时候,尽量要避免这类操作。默认是7天一检查,进行major compaction
- 将所有的storefiles合并成1个最终的storefile
<property>
<name>hbase.hregion.majorcompaction</name>
<value>604800000</value>
<source>hbase-default.xml</source>
</property>
Region的管理
- HMaster负责Region的管理
- Region的分配
- HMaster会负责Region的分配,因为当前的集群中有很多的HRegionServer,HMaster得明确不同HRegionServer的负载,然后将Region分配给对应的HRegionServer
- RegionServer的上线
- RegionServer是通过往ZK中写节点,HMaster可以监听节点,发现新上线的RegionServer
- 后续HMaster可以将region分配给新上线的RegionServer
- RegionServer的下线
- RegionServer下线也是通过ZK,HMaster可以监控到某个HRegionServer对应ZK节点的变化,如果节点不存在,认为该RegionServer已经挂了
- 将RegionServer移除
- Region的分裂
- Region的大小达到一定的阈值,HMaster会控制Region进行分裂
- 按照startkey、endkey取一个midkey,来分裂成两个region,原有的region下线
- 自动分区(分裂的过程,一个region分配到不同的HRegionServer中,保证用多台服务器来处理并发请求)
- 如果数据量大,推荐使用手动分区
Master上线和下线
- 一个集群中会存在多个Master的情况,但是只有一个ActiveMaster,其他的Backup Master,监听ZK的节点,如果Active Master crash了,其他的backup master就会进行切换
- Master持有RegionServers,哪些RegionServers是有效的,RegionServer下线Master是可以获取的
- Master如果crash,会导致一些管理性质的工作无法执行,创建表、删除表...会操作失败,但数据型操作是可以继续的
编写Bulkload的MR程序
理解bulkload
- Bulkload是将数据导入的时候可以批量将数据直接生成HFile,放在HDFS中,避免直接和HBase连接,使用put进行操作
- 绕开之前将的写流程
- WAL
- MemStore
- StoreFile合并
- 批量写的时候效果高
如何mapper
- 如果实现一个MR的Mapper
- 实现一个Mapper必须要指定4个数据类型
- 从Mapper继承
- KeyIn:LongWritable
- ValueIn:Text
- KeyOut:自己指定(必须是Hadoop的类型——Hadoop有自己的一套序列化类型)
- ValueOut:自己指定
实现Mapper
- ImmutableBytesWritable——表示在Hbase对MapReduce扩展实现的类型, 对应rowkey
- MapReduceExtendedCell——表示单元格,也是hbase支持MapReduce实现的类型
- 可以使用HBase的KeyValue来构建
public class BankRecordMapper extends Mapper<LongWritable, Text, ImmutableBytesWritable, MapReduceExtendedCell> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 将Mapper获取到Text文本行,转换为TransferRecord实体类
// 7e59c946-b1c6-4b04-a60a-f69c7a9ef0d6,SU8sXYiQgJi8,6225681772493291,杭州银行,丁杰,4896117668090896,
// 卑文彬,老婆,节日快乐,电脑客户端,电子银行转账,转账完成,2020-5-13 21:06:92,11659.0
TransferRecord transferRecord = TransferRecord.parse(value.toString());
// 从实体类中获取ID,并转换为rowkey
String rowkeyString = transferRecord.getId();
byte[] rowkeyByteArray = Bytes.toBytes(rowkeyString);
byte[] columnFamily = Bytes.toBytes("C1");
byte[] colId = Bytes.toBytes("id");
byte[] colCode = Bytes.toBytes("code");
byte[] colRec_account = Bytes.toBytes("rec_account");
byte[] colRec_bank_name = Bytes.toBytes("rec_bank_name");
byte[] colRec_name = Bytes.toBytes("rec_name");
byte[] colPay_account = Bytes.toBytes("pay_account");
byte[] colPay_name = Bytes.toBytes("pay_name");
byte[] colPay_comments = Bytes.toBytes("pay_comments");
byte[] colPay_channel = Bytes.toBytes("pay_channel");
byte[] colPay_way = Bytes.toBytes("pay_way");
byte[] colStatus = Bytes.toBytes("status");
byte[] colTimestamp = Bytes.toBytes("timestamp");
byte[] colMoney = Bytes.toBytes("money");
// 构建输出key:new ImmutableBytesWrite(rowkey)
ImmutableBytesWritable immutableBytesWritable = new ImmutableBytesWritable(rowkeyByteArray);
// 使用KeyValue类构建单元格,每个需要写入到表中的字段都需要构建出来单元格
KeyValue kvId = new KeyValue(rowkeyByteArray, columnFamily, colId, Bytes.toBytes(transferRecord.getId()));
KeyValue kvCode = new KeyValue(rowkeyByteArray, columnFamily, colCode, Bytes.toBytes(transferRecord.getCode()));
KeyValue kvRec_account = new KeyValue(rowkeyByteArray, columnFamily, colRec_account, Bytes.toBytes(transferRecord.getRec_account()));
KeyValue kvRec_bank_name = new KeyValue(rowkeyByteArray, columnFamily, colRec_bank_name, Bytes.toBytes(transferRecord.getRec_bank_name()));
KeyValue kvRec_name = new KeyValue(rowkeyByteArray, columnFamily, colRec_name, Bytes.toBytes(transferRecord.getRec_name()));
KeyValue kvPay_account = new KeyValue(rowkeyByteArray, columnFamily, colPay_account, Bytes.toBytes(transferRecord.getPay_account()));
KeyValue kvPay_name = new KeyValue(rowkeyByteArray, columnFamily, colPay_name, Bytes.toBytes(transferRecord.getPay_name()));
KeyValue kvPay_comments = new KeyValue(rowkeyByteArray, columnFamily, colPay_comments, Bytes.toBytes(transferRecord.getPay_comments()));
KeyValue kvPay_channel = new KeyValue(rowkeyByteArray, columnFamily, colPay_channel, Bytes.toBytes(transferRecord.getPay_channel()));
KeyValue kvPay_way = new KeyValue(rowkeyByteArray, columnFamily, colPay_way, Bytes.toBytes(transferRecord.getPay_way()));
KeyValue kvStatus = new KeyValue(rowkeyByteArray, columnFamily, colStatus, Bytes.toBytes(transferRecord.getStatus()));
KeyValue kvTimestamp = new KeyValue(rowkeyByteArray, columnFamily, colTimestamp, Bytes.toBytes(transferRecord.getTimestamp()));
KeyValue kvMoney = new KeyValue(rowkeyByteArray, columnFamily, colMoney, Bytes.toBytes(transferRecord.getMoney()));
// 使用context.write将输出输出
// 构建输出的value:new MapReduceExtendedCell(keyvalue对象)
context.write(immutableBytesWritable, new MapReduceExtendedCell(kvId));
context.write(immutableBytesWritable, new MapReduceExtendedCell(kvCode));
context.write(immutableBytesWritable, new MapReduceExtendedCell(kvRec_account));
context.write(immutableBytesWritable, new MapReduceExtendedCell(kvRec_bank_name));
context.write(immutableBytesWritable, new MapReduceExtendedCell(kvRec_name));
context.write(immutableBytesWritable, new MapReduceExtendedCell(kvPay_account));
context.write(immutableBytesWritable, new MapReduceExtendedCell(kvPay_name));
context.write(immutableBytesWritable, new MapReduceExtendedCell(kvPay_comments));
context.write(immutableBytesWritable, new MapReduceExtendedCell(kvPay_channel));
context.write(immutableBytesWritable, new MapReduceExtendedCell(kvPay_way));
context.write(immutableBytesWritable, new MapReduceExtendedCell(kvStatus));
context.write(immutableBytesWritable, new MapReduceExtendedCell(kvTimestamp));
context.write(immutableBytesWritable, new MapReduceExtendedCell(kvMoney));
}
}
异常:报错,连接2181失败,仔细看是连接的本地的localhost的zk,本地是没有ZK
解决办法:
- Job.getInstance(configuration)
- 需要把HBaseConfiguration加载的配置文件传到JOB中
INFO - Opening socket connection to server 127.0.0.1/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error)
WARN - Session 0x0 for server null, unexpected error, closing socket connection and attempting reconnect
java.net.ConnectException: Connection refused: no further information
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:717)
at org.apache.zookeeper.ClientCnxnSocketNIO.doTransport(ClientCnxnSocketNIO.java:361)
at org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:1141)
WARN - 0x59321afb to localhost:2181 failed for get of /hbase/hbaseid, code = CONNECTIONLOSS, retries = 1
INFO - Opening socket connection to server 0:0:0:0:0:0:0:1/0:0:0:0:0:0:0:1:2181. Will not attempt to authenticate using SASL (unknown error)
WARN - Session 0x0 for server null, unexpected error, closing socket connection and attempting reconnect
java.net.ConnectException: Connection refused: no further information
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:717)
at org.apache.zookeeper.ClientCnxnSocketNIO.doTransport(ClientCnxnSocketNIO.java:361)
at org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:1141)
MapReduce实现过程
- Mapper<keyin, keyout, valuein, valueout>
- Driver
public class BankRecordBulkLoadDriver {
public static void main(String[] args) throws Exception {
// 1. 使用HBaseConfiguration.create()加载配置文件
Configuration configuration = HBaseConfiguration.create();
// 2. 创建HBase连接
Connection connection = ConnectionFactory.createConnection(configuration);
// 3. 获取HTable
Table table = connection.getTable(TableName.valueOf("ITCAST_BANK:TRANSFER_RECORD"));
// 4. 构建MapReduce JOB
// a) 使用Job.getInstance构建一个Job对象
Job job = Job.getInstance(configuration);
// b) 调用setJarByClass设置要执行JAR包的class
job.setJarByClass(BankRecordBulkLoadDriver.class);
// c) 调用setInputFormatClass为TextInputFormat.class
job.setInputFormatClass(TextInputFormat.class);
// d) 设置MapperClass
job.setMapperClass(BankRecordMapper.class);
// e) 设置输出键Output Key Class
job.setOutputKeyClass(ImmutableBytesWritable.class);
// f) 设置输出值Output Value Class
job.setOutputValueClass(MapReduceExtendedCell.class);
// g) 设置输入输出到HDFS的路径,输入路径/bank/input,输出路径/bank/output
// i. FileInputFormat.setInputPaths
FileInputFormat.setInputPaths(job, new Path("hdfs://node1.itcast.cn:8020/bank/input"));
// ii. FileOutputFormat.setOutputPath
FileOutputFormat.setOutputPath(job, new Path("hdfs://node1.itcast.cn:8020/bank/output"));
// h) 使用connection.getRegionLocator获取HBase Region的分布情况
RegionLocator regionLocator = connection.getRegionLocator(TableName.valueOf("ITCAST_BANK:TRANSFER_RECORD"));
// i) 使用HFileOutputFormat2.configureIncrementalLoad配置HFile输出
HFileOutputFormat2.configureIncrementalLoad(job, table, regionLocator);
// 5. 调用job.waitForCompletion执行MapReduce程序
if(job.waitForCompletion(true)) {
System.exit(0);
}
else {
System.exit(1);
}
}
}
协处理器
理解下RDMS的触发器、存储过程
- 触发器:当执行一些insert/delete/update之类的操作,在操作之前、之后可以执行一些逻辑(这些逻辑就是易于SQL的脚本——PL/SQL,来实现)
- 存储过程:直接在数据库服务器端编写一段逻辑,这个逻辑可以被客户端来调用
HBase的协处理器
- observer:拦截put/get/scan/delete之类的操作,执行协处理器对应的代码(Java实现的——将Java实现好的协处理器直接打成一个JAR包,JAR包可以放在HDFS上,部署到HBase)。例如:Phoenix插入一条数据,同时更新索引
- endpoint:可以使用Java编写一些逻辑,将JAR包部署到HBase,就可以实现一些扩展的功能。例如:Phoenix的select count\max.....
常见数据结构理解
- 跳表
- 链表是单层的,跳表是多层,层数越小,越稀疏
- 可以理解为给有序链表增加稀疏索引,加快查询效率
- 二叉搜索树
- 一个节点最多有两个节点
- 二叉搜索树是一种排序树
- 一般数据库中索引不会用二叉搜索树,因为有两个问题
- 二叉树的高度问题(越高、查询效率下降、IO操作越多)
- 二叉树的平衡问题(如果不平衡,就会导致搜索某些节点的时候,效率很多,有的直属高度很高,有的很低——负载不均衡,如果及其不平衡,退化成链表——老歪脖子树)
- 平衡二叉树
- 要求很严格
- 要求:任意节点的子树的高度差不能超过1
- 要求过于严格,对插入、删除有较大影响,因为每次插入、删除要进行节点的一些旋转一些操作,都要确保树是严格的平衡的
- 红黑树
- 弱平衡要求的二叉树
- 有红色、黑色两种节点,叶子节点都是NIL节点(无特殊意义的节点)
- 每个红色节点都有两个黑色节点
- 要求:任意的红色节点到叶子节点有相同数量的黑色节点
- 在一些Java TreeMap是基于红黑树实现的
- B树
- 多路搜索树,也是平衡的,又多叉的情况存在
- 在基于B树搜索的时候,在每一层分布都有数据节点,只要找到我们想要的数据,就可以直接返回
- B+树
- B+树是B树的升级版本
- 所有的数据节点都在最后一层(叶子节点),而且叶子节点之间彼此是连接的
- 应用场景:MySQL B+tree索引、文件系统
LSM树
-
LSM树:这种树结构是多种结构的组合
-
为了保证写入的效率,对整个结构进行了分层,C0、C1、C2....
-
写入数据的时候,都是写入到C0,就要求C0的写入是很快的,例如:HBase写的就是MemStore——跳表结构(也有其他用红黑树之类的)
-
C0达到一定的阈值,就开始刷写到C1,进行合并,Compaction
-
C1达到一定的条件,也就即席合并到C2
-
存在磁盘中的C1\C2层的数据一般是以B+树方式存储,方便检索
-
WAL预写日志:首先写数据为了避免数据丢失,一定要写日志,WAL会记录所有的put/delete操作之类的,如果出现问题,可以通过回放WAL预写日志来恢复数据
- WAL预写日志:是写入HDFS中,是以SequenceFile来存储的,而且是顺序存储的(为了保证效率),PUT/DELETE操作都是保存一条数据
-
比较适合写多读少的场景,如果读取比较多,需要创建二级索引
布隆过滤器(BloomFilter)
布隆过滤器判断的结果:
- 不存在
- 可能存在
- 布隆过滤器是一种结构,也是一种BitMap结构,因为Bitmap占用的空间小,所以布隆过滤器经常使用在一些海量数据判断元素是否存在的场景,例如:HBase
- 写入key/value键值对的时候,会对这个key进行k个哈希函数取余(取Bitmap的长度),得到k个数值,这个k个数值一定是在这个Bitmap中的,值要么是0、要么是1
- 根据key来进行判断的时候,首先要对这个key进行k个哈希函数取余,判断取余之后的k个值,在Bitmap时候都已经被设置为1,如果说有一个不是1,表示这个key一定是不存在的。如果是全都是1,可能存在。
HBase中StoreFile的结构
- StoreFile是分了不同的层,每一次层存储的数据是不一样
- 主要记住:
- Data Block——保存实际的数据
- Data Block Index——数据块的索引,查数据的时候先查Index,再去查数据
- DataBlock里面的数据也是有一定的结构
- Key的长度
- Value的长度
- Key的数据结构比较丰富:rowkey、family、columnname、keytype(put、delete)
- Value就是使用byte[]存储下来即可
HBase优化
每个集群会有系统配置,社区一定会把一些通用的、适应性强的作为默认配置,有很多都是折中的配置。很多时候,出现问题的时候,我们要考虑优化。
- 通用优化
- 跟硬件有一定的关系,SSD、RAID(给NameNode使用RAID1架构,可以有一定容错能力)
- 操作系统优化
- 最大的开启文件数量(集群规模大之后,写入的速度很快,经常要Flush,会在操作系统上同时打开很多的文件读取)
- 最大允许开启的进程
- HDFS优化
- 副本数
- RPC的最大数量
- 开启的线程数
- HBase优化
- 配置StoreFile大小
- 预分区
- 数据压缩
- 设计ROWKEY
- 开启BLOOMFILER
- 2.X开启In-memory Compaction
- ...
- JVM
- 调整堆内存大小
- 调整GC,并行GC,缩短GC的时间
使用Phoenix创建二级索引的问题
创建二级索引后,发现根据二级索引字段查询不走索引问题。
drop table if exists ORDER_DTL;
create table if not exists ORDER_DTL(
"id" varchar primary key,
C1."status" varchar,
C1."money" float,
C1."pay_way" integer,
C1."user_id" varchar,
C1."operation_time" varchar,
C1."category" varchar
)
CONPRESSION='GZ',
SALT_BUCKETS=10;
问题原因:
- 因为在Phoenix创建表时,指定了SALT_BUCKETS,而Phoenix的二级索引是不支持
SALT_BUCKETS的,所以,如果要想二级索引支持有两种方式- 在HBase中创建表,指定预分区,创建视图映射
- 使用Phoenix通过rowkey进行预分区
Note that if the primary table is salted, then the index is automatically salted in the same way for global indexes. In addition, the MAX_FILESIZE for the index is adjusted down, relative to the size of the primary versus index table. For more on salting see here. With local indexes, on the other hand, specifying SALT_BUCKETS is not allowed.
纠正:创建二级索引后,在hbase shell无法get出来数据
- 这是hbase shell直接执行get时,无法正确打印
- 但其实虽然建立了二级索引,具有一定地侵入性,原有的数据Phoenix会编码后存储。但当我们执行get/put/delete请求时,按正常理解是不能操作数据的。
- 但需要多考虑一个问题:Phoenix建立视图时,会在表上创建若干的协处理器
'MOMO_CHAT:MSG', {TABLE_ATTRIBUTES => {coprocessor$1 => '|org.apache.phoenix.coprocessor.ScanRegionObserver|805306366|', coprocessor$2 => '|org.apache.phoenix.coprocessor.UngroupedAggregateRegionObserver|805306366|', coprocessor$3 => '|org.apache.phoenix.coprocessor.GroupedAggregateRegionObserver|805306366|', coprocessor$4 => '|org.apache.phoenix.coprocessor.ServerCachingEndpointImpl|805306366|', coprocessor$5 => '|org.apache.hadoop.hbase.regionserver.IndexHalfStoreFileReaderGenerator|805306366|', METADATA => {'DATA_TABLE_NAME' => 'MOMO_CHAT.MSG', 'SPLIT_POLICY' => 'org.apache.phoenix.hbase.index.IndexRegionSplitPolicy'}}, {NAME => 'C1', COMPRESSION => 'GZ'}, {NAME => 'L#0', DATA_BLOCK_ENCODING => 'FAST_DIFF', BLOOMFILTER => 'NONE'}
- 协处理会负责接收客户端发来的请求,get/put/delete/scan,然后进行解码操作,最后我们发现仍然可以操作数据
-------------------------------------------
个性签名:独学而无友,则孤陋而寡闻。做一个灵魂有趣的人!
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!
万水千山总是情,打赏一分行不行,所以如果你心情还比较高兴,也是可以扫码打赏博主,哈哈哈(っ•̀ω•́)っ✎⁾⁾!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号