树状数组
-
-
第一位大佬的链接:https://zhuanlan.zhihu.com/p/93795692,奶奶喂饭级别教程,强烈推荐!
-
算法训练营,树状数组篇
-
-
简介:
-
名称:树状数组(Binary Index Tree,即BIT)
-
支持的基本操作:
-
单点修改,更改某个元素的值,复杂度O(logn)
-
区间查询,比如求区间元素和,复杂度O(logn)
普通的数组中这两个的操作分别是O(1)和O(n),尽管有前缀和这种操作,可是单点修改之后就需要重新计算,于是改一次查一次,复杂度爆炸,直接gg,但是这里的“破绽”在于单点修改影响了1个节点,区间修改影响了n个节点,我们想要一种数据结构,让两个的影响大致均衡,以达到降低最劣复杂度的效果,树状数组让这两个的影响“节点”均为logn。
-
-
一些abstract:
最牛且亲民的一种数据结构,功能强大且常数较小。
-
-
一些操作:
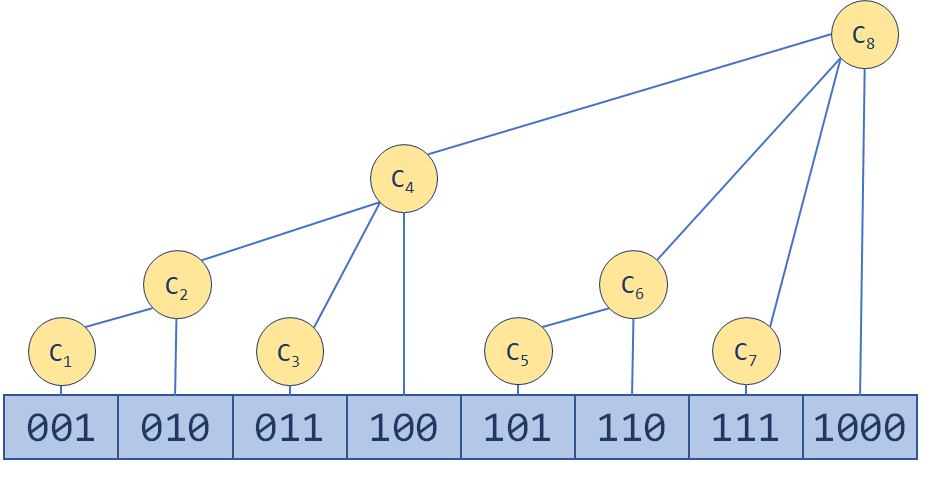
树状数组巧妙利用了二进制,比如11(1)这个数字,我们要求第一项加到第十一项的和,于是树状数组说我可以算(0, 8],(8, 10],(10, 11]。注意到8=(1000)2,10=(1010)2,11=(1011)2,其实就是从左到右每次“吞掉”最左边的1(反过来看就是每次放弃最右边的1),又因为最劣的情况是都是1,这样次数最多,也不会超过logn次计算,也就是说我们只需要维护具有以上特征的区间即可,即区间左边的二进制的1,右边一定有,右边在左边二进制最后一个为1的位之后,还可以将其中一个0改成1。
而一个值的改变会影响哪些区间呢?比如有一个数叫(100110)2,包含它的最小区间为((100100)2, (100110)2],然后右边界要扩张,左边界要抹掉右边界的最后一个1,即大一点的区间变成((100000)2, (101000)2],然后右边界再大一点就是(110000)2,再大一点的区间就是((100000)2, (110000)2],再大一点呢?((0000000)2, (1000000)2],以此类推,知道右边界比最大的n还要大,就没有修改的必要了,显然这样也不会超过logn次。
至于如何算一个数字的最右侧的1在哪,有一个神奇的公式叫lowbit,我们规定lowbit(x) = x&(-x)。为什么成立呢?想象一下,一个数字的组成是:(abcd10000)2,则-x为(!a!b!c!d01111+1)2=(!a!b!c!d10000)2,所以二者取与,前面显然都是0,所以就把最后一个1取出来咯~
然后最开始的数组[1, n],虽然树状数组对应的也是[1, n],但是每个节点,代表刚才提到的那种区间,感觉抽象就看这个图:
![]()
可以看到树状数组和原来的数组的节点个数是一一对应的。
-
单点修改:
int tree[MAXN];
inline void update(int i, int x) // 把i的位置的值增加x
{
for (int pos = i; pos < MAXN; pos += lowbit(pos)) // 比如最开始是100110;每次进一个位,下一次就是101000,然后是110000,然后是1000000...每次都代表区间的右界
tree[pos] += x;
} -
区间查询:
inline int query(int n) // 查询单点前缀和
{
int ans = 0;
for (int pos = n; pos; pos -= lowbit(pos)) // pos代表刚才提到的区间的右端点,每次退还最右边的1 直到
ans += tree[pos];
return ans;
}
inline int query(int a, int b) // 查询区间和
{
return query(b) - query(a - 1);
}
活学活用(基础板子):
-
-
经典例题:
-
逆序对个数:
比如现在给了一堆数字,其实你根本不关心这些数的具体值,有用的只是这些数字到底都是第几大的,然后根据这个rank来判断逆序对的个数。比如现在分别是第3、2、4、5、1大的数字,我们先构造一个全为0的数组,代表位置为i的数字有没有出现,然后遍历这个rank数组,每次遇到rank为i的数,就在新数组中查找1到i的和是多少,即已经出现了多少个比我小的数字,然后把位置为i的值变为1,代表位置为i的数字已经出现了。
搬用大佬1的代码:
-