


python爬取数据分析
一.python爬虫使用的模块
1.import requests
2.from bs4 import BeautifulSoup
3.pandas 数据分析高级接口模块
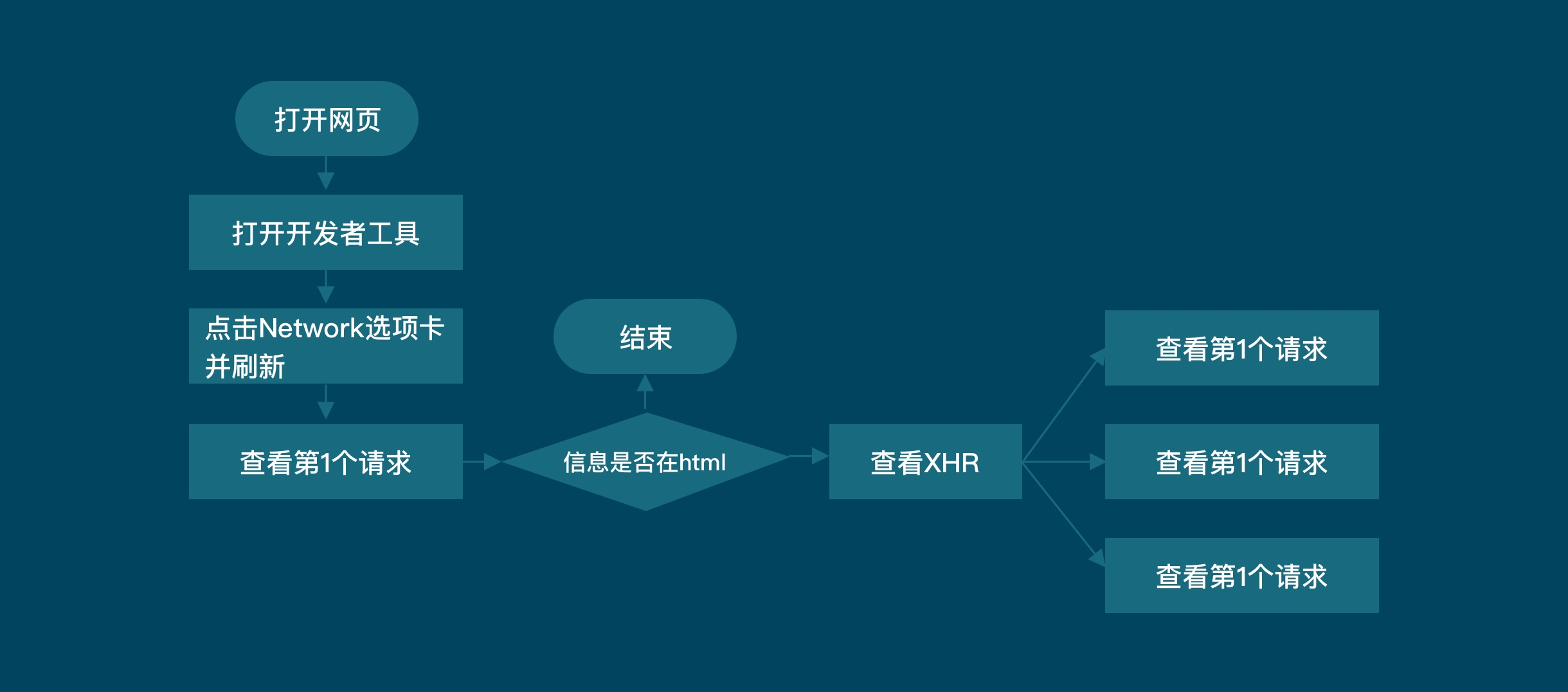
二. 爬取数据在第一个请求中时, 使用BeautifulSoup
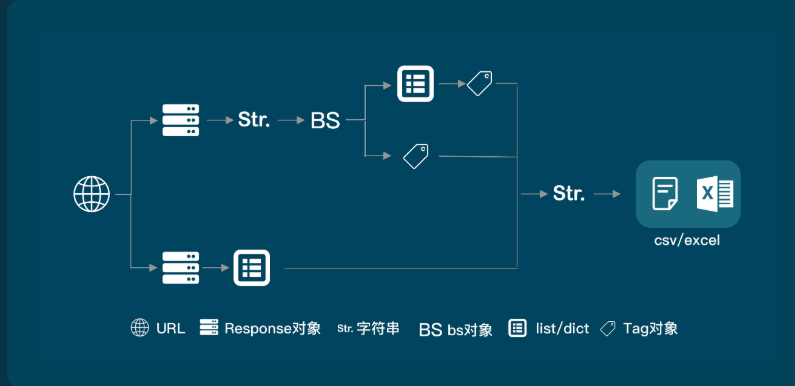
import requests
# 引用requests库
from bs4 import BeautifulSoup
# 引用BeautifulSoup库
res_movies = requests.get('https://movie.douban.com/chart')
# 获取数据
bs_movies = BeautifulSoup(res_movies.text,'html.parser')
# 解析数据
list_movies= bs_movies.find_all('div',class_='pl2')
# 查找最小父级标签
list_all = []
# 创建一个空列表,用于存储信息
for movie in list_movies:
tag_a = movie.find('a')
# 提取第0个父级标签中的<a>标签
name = tag_a.text.replace(' ', '').replace('\n', '')
# 电影名,使用replace方法去掉多余的空格及换行符
url = tag_a['href']
# 电影详情页的链接
tag_p = movie.find('p', class_='pl')
# 提取父级标签中的<p>标签
information = tag_p.text.replace(' ', '').replace('\n', '')
# 电影基本信息,使用replace方法去掉多余的空格及换行符
tag_div = movie.find('div', class_='star clearfix')
# 提取父级标签中的<div>标签
rating = tag_div.text.replace(' ', '').replace('\n', '')
# 电影评分信息,使用replace方法去掉多余的空格及换行符
list_all.append([name,url,information,rating])
# 将电影名、URL、电影基本信息和电影评分信息,封装为列表,用append方法添加进list_all
print(list_all)
# 打印
三.当数据不在第一个请求中时, 使用network获取数据
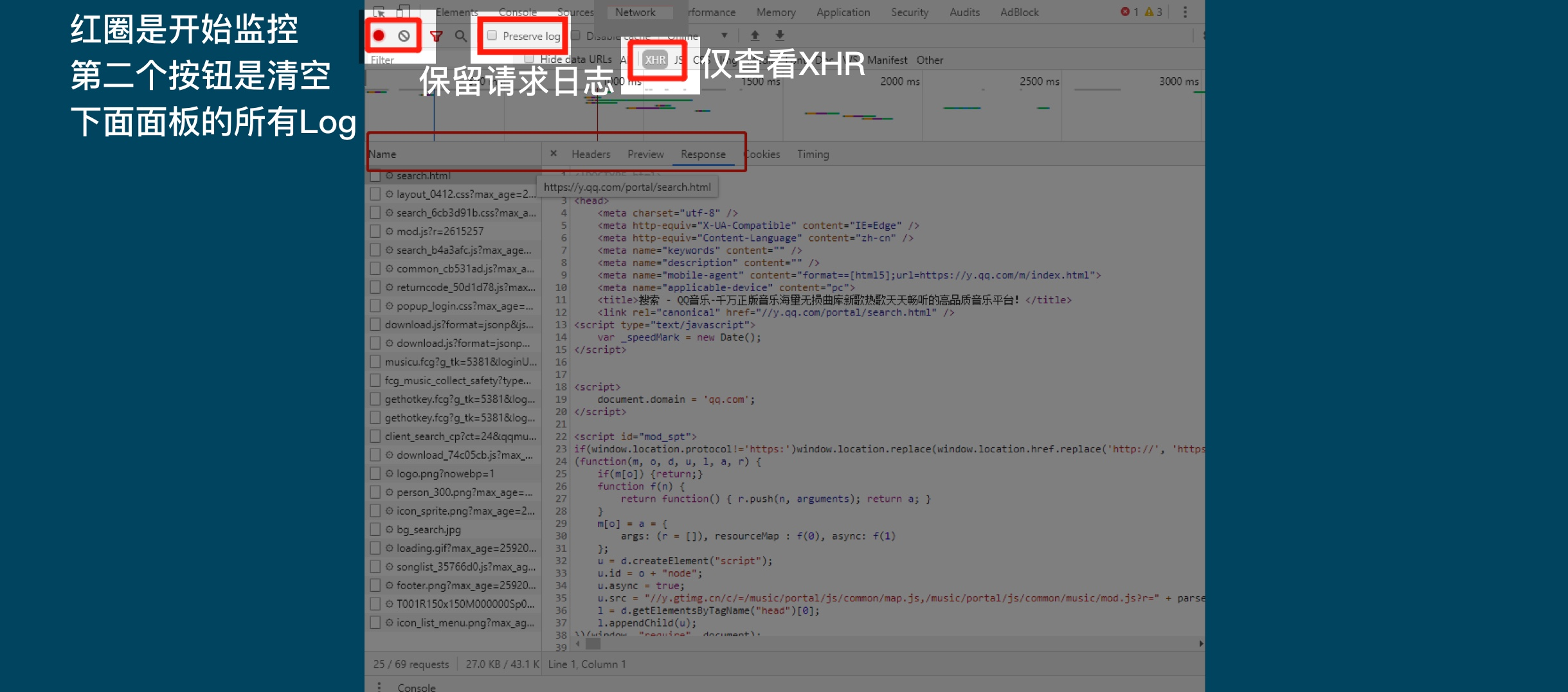

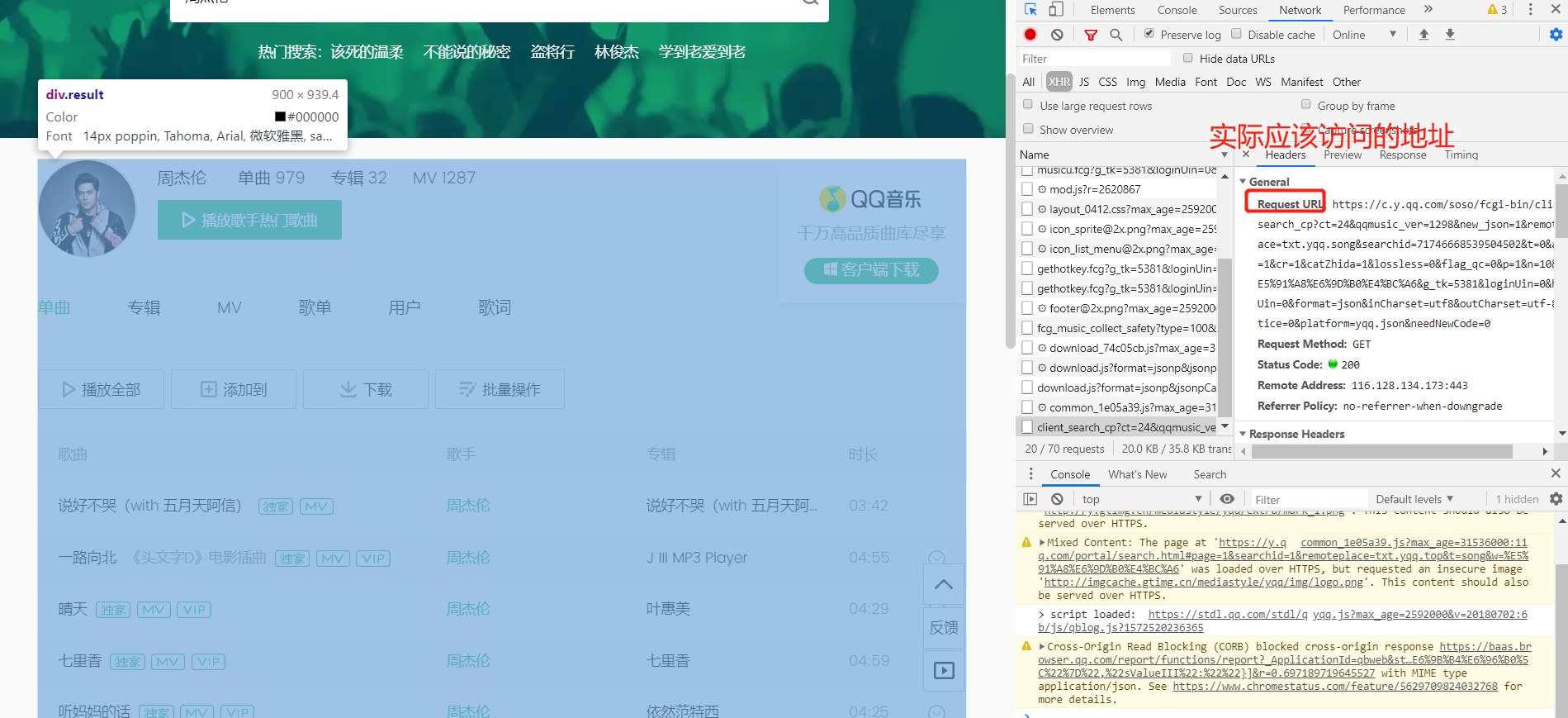
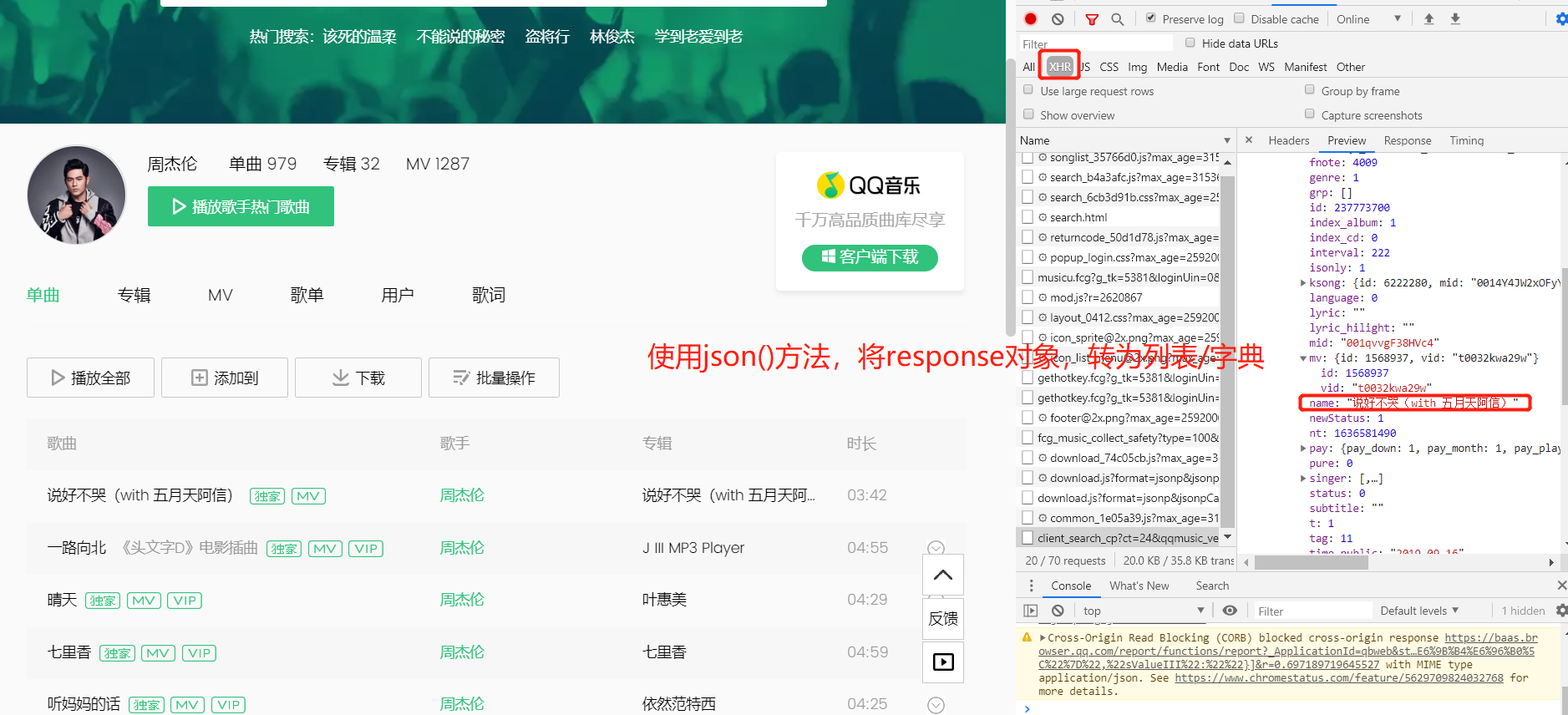
例如:
import requests
from bs4 import BeautifulSoup
res = requests.get('https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=71746668539504502&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=10&w=%E5%91%A8%E6%9D%B0%E4%BC%A6&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0')
res_json = res.json()
songs = res_json['data']['song']['list']
for i in range(len(songs)):
print(songs[i]['name'])
四. 带参数param可以请求不同数据, 带header可以伪装为浏览器
import requests
# 引用requests模块
for i in range(0,3):
url = 'https://movie.douban.com/j/search_subjects'
header = {
'Origin': 'https://y.qq.com',
'Referer': 'https://y.qq.com/portal/search.html',
'Sec-Fetch-Mode': 'cors',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'
}
param = {'type': 'movie',
'tag': '热门',
'sort': 'recommend',
'page_limit': '20',
'page_start': i*20}
# print(param)
res_movie = requests.get(url,params=param, headers=header)
# 调用get方法,下载电影列表
json_movie = res_movie.json()
# 使用json()方法,将response对象,转为列表/字典
# print(json_movie)
list_movies = json_movie['subjects']
# 一层一层地取字典,获取电影名称
for comment in list_movies:
# list_movies,comment是它里面的元素
print(comment['title'])
# 输出电影名名称
五.保存数据



 浙公网安备 33010602011771号
浙公网安备 33010602011771号