前端面试常见问题
前端常见问题
- 前端常见问题
- 1. 跨域问题产生的原因以及十种解决方案
- 2 计算机网络面试题
- 2.1 什么是网络协议,为什么要对网络协议分层
- 2.2 计算机网络的各层协议及作用
- 2.3 URI 与 URL 的区别
- 2.4 DNS 工作流程
- 2.5 ARP 协议
- 2.6 有了 IP 地址,为什么还要用 MAC 地址
- 2.7 PING 的过程
- 2.8 路由器和交换机的区别
- 2.9 TCP 与 UDP
- 2.10 TCP协议如何保证可靠传输
- 2.11 TCP的三次握手及四次挥手
- 2.12 HTTP 与 HTTPS 的区别
- 2.13 对称加密与非对称加密
- 2.14 HTTPS的加密过程
- 2.15 常用HTTP状态码
- 2.16 常见的HTTP方法
- 2.17 GET和POST区别
- 2.18 HTTP 1.0、HTTP 1.1及HTTP 2.0和HTTP3的主要区别
- 2.19 Session、Cookie和Token的主要区别
- 2.20 如果客户端禁止 cookie 能实现 session 还能用吗
- 2.21 在浏览器中输⼊url地址到显示主页的过程
- 2.22 http 缓存
- 3. 为什么要用 setTimeout 模拟 setInterval
- 4. HTML & CSS
- 5. 前端安全问题
- 7. 正则表达式
- 8. webpack5
- 8.1 有哪些常见 loader
- 8.2 常见 Plugin
- 8.3 loader 和 plugin 的区别
- 8.4 webpack构建流程
- 8.5 使用 webpack 开发时,用过哪些提高效率的插件
- 8.6 source map 是什么,生产环境怎么用
- 8.7 模块打包原理
- 8.8 文件监听原理
- 8.9 webpack 热更新原理
- 8.10 如何对 bundle 体积进行监控和分析
- 8.11 文件指纹是什么,怎么用?
- 8.12 如何优化 webpack 构建速度
- 8.13 编写 loader 的思路
- 8.14 编写 plugin 的思路
- 8.15 webpack 打包的 hash 码产生原理
- 8.16 webpack 离线缓存静态资源如何实现
- 8.17 webpack 如何实现持久化缓存
- 8.15 babel 原理
- 9. 性能
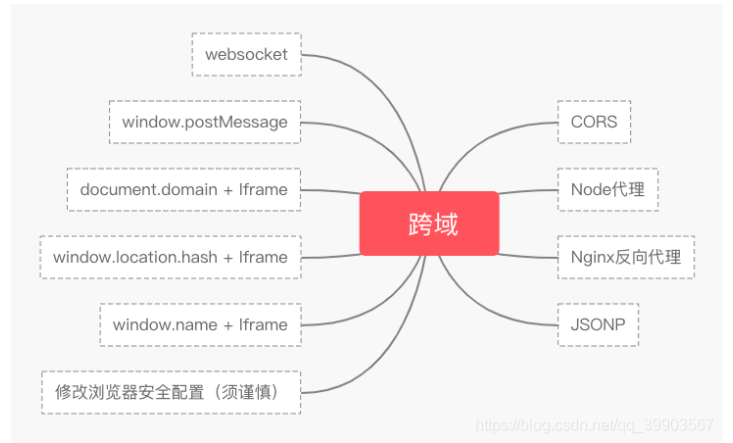
1. 跨域问题产生的原因以及十种解决方案
1.1 跨域的概念
在前端领域中,跨域是指浏览器允许向服务器发送跨域请求,从而克服Ajax只能同源使用的限制。
当跨域时会收到以下错误:

1.2 同源策略
同源策略是一种约定,由Netscape公司1995年引入浏览器,它是浏览器最核心也最基本的安全功能,如果缺少了同源策略,浏览器很容易受到XSS、CSFR等攻击。所谓同源是指"协议+域名+端口"三者相同,即便两个不同的域名指向同一个ip地址,也非同源。
URL组成:

同源策略限制以下几种行为:
- Cookie、LocalStorage 和 IndexDB 无法读取
- DOM和JS对象无法获得
- AJAX 请求不能发送
1.3 解决方案
1.3.1 JSONP 跨域
原理:就是利用 <script> 标签没有跨域限制,通过<script>标签src属性,发送带有callback参数的GET请求,服务端将接口返回数据拼凑到callback函数中,返回给浏览器,浏览器解析执行,从而前端拿到callback函数返回的数据。
缺点:只能发送get一种请求。
-
原生JS实现:
var script = document.createElement('script'); script.type = 'text/javascript'; // 传参一个回调函数名给后端,方便后端返回时执行这个在前端定义的回调函数 script.src = 'http://www.domain2.com:8080/login?user=admin&callback=handleCallback'; document.head.appendChild(script); // 回调执行函数 function handleCallback(res) { alert(JSON.stringify(res)); }服务端返回如下(返回时即执行全局函数):
handleCallback({"success": true, "user": "admin"}) -
jquery Ajax实现:
$.ajax({ url: 'http://www.domain2.com:8080/login', type: 'get', dataType: 'jsonp', // 请求方式为jsonp jsonpCallback: "handleCallback", // 自定义回调函数名 data: {} }); -
Vue axios实现:
this.$http = axios; this.$http.jsonp('http://www.domain2.com:8080/login', { params: {}, jsonp: 'handleCallback' }).then((res) => { console.log(res); }) -
后端node.js代码:
var querystring = require('querystring'); var http = require('http'); var server = http.createServer(); server.on('request', function(req, res) { var params = querystring.parse(req.url.split('?')[1]); var fn = params.callback; // jsonp返回设置 res.writeHead(200, { 'Content-Type': 'text/javascript' }); res.write(fn + '(' + JSON.stringify(params) + ')'); res.end(); }); server.listen('8080'); console.log('Server is running at port 8080...');
1.3.2 跨域资源共享 (CORS)
CORS是一个W3C标准,全称是"跨域资源共享"(Cross-origin resource sharing)。
它允许浏览器向跨源服务器,发出XMLHttpRequest请求,从而克服了AJAX只能同源使用的限制。
CORS需要浏览器和服务器同时支持。目前,所有浏览器都支持该功能,IE浏览器不能低于IE10。
浏览器将CORS跨域请求分为简单请求和非简单请求。
只要同时满足一下两个条件,就属于简单请求
-
使用下列方法之一:
- head
- get
- post
-
请求的Heder是
- Accept
- Accept-Language
- Content-Language
- Content-Type: 只限于三个值:application/x-www-form-urlencoded、multipart/form-data、text/plain
不同时满足上面的两个条件,就属于非简单请求。浏览器对这两种的处理,是不一样的。
-
简单请求 对于简单请求,浏览器直接发出CORS请求。具体来说,就是在头信息之中,增加一个Origin字段
GET /cors HTTP/1.1 Origin: http://api.bob.com Host: api.alice.com Accept-Language: en-US Connection: keep-alive User-Agent: Mozilla/5.0...上面的头信息中,Origin字段用来说明,本次请求来自哪个源(协议 + 域名 + 端口)。服务器根据这个值,决定是否同意这次请求。
-
CORS 跨域示例
-
原生 Ajax
var xhr = new XMLHttpRequest(); // IE8/9需用window.XDomainRequest兼容 // 前端设置是否带cookie xhr.withCredentials = true; xhr.open('post', 'http://www.domain2.com:8080/login', true); xhr.setRequestHeader('Content-Type', 'application/x-www-form-urlencoded'); xhr.send('user=admin'); xhr.onreadystatechange = function() { if (xhr.readyState == 4 && xhr.status == 200) { alert(xhr.responseText); } }; -
jquery ajax
$.ajax({ ... xhrFields: { withCredentials: true // 前端设置是否带cookie }, crossDomain: true, // 会让请求头中包含跨域的额外信息,但不会含cookie ... });
-
1.3.3 nginx 代理跨域
nginx代理跨域,实质和CORS跨域原理一样,通过配置文件设置请求响应头Access-Control-Allow-Origin…等字段。
-
nginx配置解决iconfont跨域
location / { add_header Access-Control-Allow-Origin *; } 浏览器跨域访问js、css、img等常规静态资源被同源策略许可,但iconfont字体文件(eot|otf|ttf|woff|svg)例外,此时可在nginx的静态资源服务器中加入以上配置。
-
nginx反向代理接口跨域
跨域问题:同源策略仅是针对浏览器的安全策略。服务器端调用HTTP接口只是使用HTTP协议,不需要同源策略,也就不存在跨域问题。
实现思路:通过Nginx配置一个代理服务器域名与domain1相同,端口不同)做跳板机,反向代理访问domain2接口,并且可以顺便修改cookie中domain信息,方便当前域cookie写入,实现跨域访问。
nginx 具体配置
#proxy服务器 server { listen 81; server_name www.domain1.com; location / { proxy_pass http://www.domain2.com:8080; #反向代理 proxy_cookie_domain www.domain2.com www.domain1.com; #修改cookie里域名 index index.html index.htm; # 当用webpack-dev-server等中间件代理接口访问nignx时,此时无浏览器参与,故没有同源限制,下面的跨域配置可不启用 add_header Access-Control-Allow-Origin http://www.domain1.com; #当前端只跨域不带cookie时,可为* add_header Access-Control-Allow-Credentials true; } }
1.3.4 nodejs 中间件代理跨域
node中间件实现跨域代理,原理大致与nginx相同,都是通过启一个代理服务器,实现数据的转发,也可以通过设置cookieDomainRewrite参数修改响应头中cookie中域名,实现当前域的cookie写入,方便接口登录认证。
1.3.5 document.domain + iframe 跨域
该方式只能用于二级域名相同的情况下,比如a.test.com和b.test.com适用于该方式。 只需要给页面添加document.domain ='test.com’表示二级域名都相同就可以实现跨域。
www. baidu. com .
三级域 二级域 顶级域 根域
实现原理:两个页面都通过js强制设置document.domain为基础主域,就实现了同域。
1.3.6 location.hash+iframe 跨域
实现原理: a欲与b跨域相互通信,通过中间页c来实现。 三个页面,不同域之间利用iframe的location.hash传值,相同域之间直接js访问来通信。
具体实现:A域:a.html -> B域:b.html -> A域:c.html,a与b不同域只能通过hash值单向通信,b与c也不同域也只能单向通信,但c与a同域,所以c可通过parent.parent访问a页面所有对象。
1.3.7 window.name+iframe 跨域
window.name属性的独特之处:name值在不同的页面(甚至不同域名)加载后依旧存在,并且可以支持非常长的 name 值(2MB)。
通过iframe的src属性由外域转向本地域,跨域数据即由iframe的window.name从外域传递到本地域。这个就巧妙地绕过了浏览器的跨域访问限制,但同时它又是安全操作。
1.3.8 postMessage 跨域
1.3.9 WebSocket 协议跨域
原理:这种方式本质没有使用了 HTTP 的响应头, 因此也没有跨域的限制。
WebSocket protocol是HTML5一种新的协议。它实现了浏览器与服务器全双工通信,同时允许跨域通讯,是server push技术的一种很好的实现。
在网络浏览器和服务器之间建立“套接字”连接。简单地说:客户端和服务器之间存在持久的连接,而且双方都可以随时开始发送数据。
1.3.10 浏览器开启跨域
其实跨域问题是浏览器策略,源头是他,关闭这个功能
1.4 同源策略在防什么
跨域只存在于浏览器端。而浏览器为 web 提供访问入口。我们在可以浏览器内打开很多页面。正是这样的开放形态,所以我们需要对他有所限制。就比如林子大了,什么鸟都有,我们需要有一个统一的规范来进行约定才能保障这个安全性。
- 限制不同源的请求,防止JavaScript代码对非同源页面的各种请求(CSRF攻击)
例如用户登录 a 网站,同时新开 tab 打开了 b 网站,如果不限制同源, b 可以像 a 网站发起任何请求,会让不法分子有机可趁。 - 限制 dom 操作,对其他页面DOM元素(通常包含敏感信息,比如input标签)的读取()
钓鱼网站
1.5 总结
- jsonp(只支持get请求,支持老的IE浏览器)适合加载不同域名的js、css,img等静态资源;
- CORS(支持所有类型的HTTP请求,但浏览器IE10以下不支持)适合做ajax各种跨域请求;
- Nginx代理跨域和nodejs中间件跨域原理都相似,都是搭建一个服务器,直接在服务器端请求HTTP接口,这适合前后端分离的前端项目调后端接口。
- document.domain+iframe适合主域名相同,子域名不同的跨域请求。
- postMessage、websocket都是HTML5新特性,兼容性不是很好,只适用于主流浏览器和IE10+。
2 计算机网络面试题
2.1 什么是网络协议,为什么要对网络协议分层
网络协议 是计算机在通信过程中要遵循的一些约定好的规则。
网络分层的原因:
- 易于实现和维护,因为各层之间是独立的,层与层之间不会收到影响。
- 有利于标准化的制定
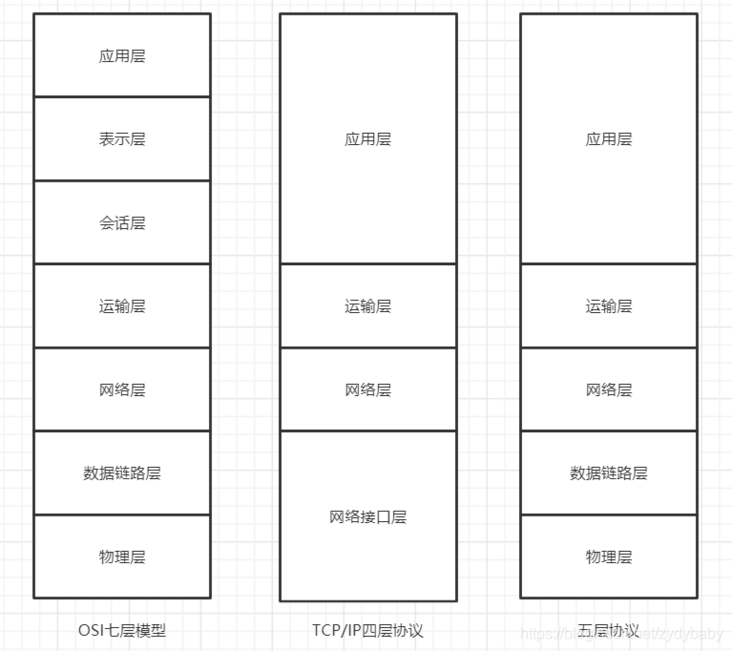
2.2 计算机网络的各层协议及作用
计算机网络体系可以大致分为一下三种,七层模型、五层模型和TCP/IP四层模型,一般面试能流畅回答出五层模型就可以了,表示层和会话层被问到的不多。
-
应用层
应用层的任务是通过应用进程之间的交互来完成特定的网络作用,常见的应用层协议有域名系统DNS,HTTP协议等。
-
表示层
表示层的主要作用是 数据的表示、安全、压缩。可确保一个系统的应用层所发送的信息可以被另一个系统的应用层读取。
-
会话层
会话层的主要作用是建立通信链接,保持会话过程通信链接的畅通,同步两个节点之间的对话,决定通信是否被中断以及通信中断时决定从何处重新发送。。
-
传输层
传输层的主要作用是负责向两台主机进程之间的通信提供数据传输服务。传输层的协议主要有传输控制协议TCP和用户数据协议UDP。
-
网络层
网络层的主要作用是选择合适的网间路由和交换结点,确保数据及时送达。常见的协议有IP协议。
-
数据链路层
数据链路层的作用是在物理层提供比特流服务的基础上,建立相邻结点之间的数据链路,通过差错控制提供数据帧(Frame)在信道上无差错的传输,并进行各电路上的动作系列。 常见的协议有SDLC、HDLC、PPP等。
-
物理层
物理层的主要作用是实现相邻计算机结点之间比特流的透明传输,并尽量屏蔽掉具体传输介质和物理设备的差异。
2.3 URI 与 URL 的区别
-
URI(Uniform Resource Identifier):中文全称为统一资源标志符,主要作用是唯一标识一个资源。通常由三部分组成:
-
访问资源的命名机制
-
存放资源的主机名(地址)
-
资源自身的名称
举个例⼦:https://blog.csdn.net/qq_32595453/article/details/79516787 这是⼀个通过https协议访问的资源,放在了blog.csdn.net主机下,qq_32595453/article/details/79516787是对这个资源唯⼀的标识
注意:URI只是⼀种概念,怎样组成都⽆所谓,只要能够唯⼀标识资源就⾏
-
-
URL(Uniform Resource Location):中文全称为统一资源定位符,主要作用是提供资源的路径。
它是⼀种具体的URI,是URI的⼀个⼦集,即URL可以⽤来标识⼀个资源,⽽且还指明了如何locate这个资源。URL是URI的⼀种具体实现⽅式。URL就是我们使⽤浏览器输⼊的⽹⻚地址,例如: http://baidu.com 。URL主要有三部分组成:
- 第一部分是协议
- 第二部分是存放该资源的主机IP地址
- 第三部分是该资源的具体地址
URI=URL+URN
有个经典的比喻是URI像是身份证,可以唯一标识一个人,而URL更像一个住址,可以通过URL找到这个人
- URI和URL都定义了资源是什么,但是URL还定义了如何访问资源
- URL是URI的⼀个⼦集,URL是URI的⼀种具体实现⽅式。URI是⼀种⾼层级的抽象概念,可以使绝对也可
以是相对,⽽URL则必须提供⾜够的信息来定位,是绝对的
2.4 DNS 工作流程
DNS的定义:DNS的全称是domain name system,即域名系统。DNS是因特网上作为域名和IP地址相互映射的一个分布式数据库,能够使用户更方便的去访问互联网而不用去记住能够被机器直接读取的IP地址。比如大家访问百度,更多地肯定是访问www.baidu.com,而不是访问112.80.248.74,因为这几乎无规则的IP地址实在太难记了。DNS要做的就是将www.baidu.com解析成112.80.248.74。
2.4.1 DNS 是集群式的工作方式还是 单点式的,为什么?
答案是集群式的,很容易想到的一个方案就是只用一个DNS服务器,包含了所有域名和IP地址的映射。尽管这种设计方式看起来很简单,但是缺点显而易见,如果这个唯一的DNS服务器出了故障,那么就全完了,因特网就几乎崩了。为了避免这种情况出现,DNS系统采用的是分布式的层次数据数据库模式,还有缓存的机制也能解决这种问题。
2.4.2 DNS 工作流程
主机向本地域名服务器的查询一般是采用递归查询,而本地域名服务器向根域名的查询一般是采用迭代查询。
递归查询主机向本地域名发送查询请求报文,而本地域名服务器不知道该域名对应的IP地址时,本地域名会继续向根域名发送查询请求报文,不是通知主机自己向根域名发送查询请求报文。迭代查询是,本地域名服务器向根域名发出查询请求报文后,根域名不会继续向顶级域名服务器发送查询请求报文,而是通知本地域名服务器向顶级域名发送查询请求报文。
简单来说,递归查询就是,小明问了小红一个问题,小红不知道,但小红是个热心肠,小红就去问小王了,小王把答案告诉小红后,小红又去把答案告诉了小明。迭代查询就是,小明问了小红一个问题,小红也不知道,然后小红让小明去问小王,小明又去问小王了,小王把答案告诉了小明。
- 在浏览器中输入www.baidu.com域名,操作系统会先检查自己本地的hosts文件是否有这个域名的映射关系,如果有,就先调用这个IP地址映射,完成域名解析。
- 如果hosts文件中没有,则查询本地DNS解析器缓存,如果有,则完成地址解析。
- 如果本地DNS解析器缓存中没有,则去查找本地DNS服务器,如果查到,完成解析。
- 如果没有,则本地服务器会向根域名服务器发起查询请求。根域名服务器会告诉本地域名服务器去查询哪个顶级域名服务器。
- 本地域名服务器向顶级域名服务器发起查询请求,顶级域名服务器会告诉本地域名服务器去查找哪个权限域名服务器。
- 本地域名服务器向权限域名服务器发起查询请求,权限域名服务器告诉本地域名服务器www.baidu.com所对应的IP地址。
- 本地域名服务器告诉主机www.baidu.com所对应的IP地址。
2.5 ARP 协议
ARP协议属于网络层的协议,主要作用是实现从IP地址转换为MAC地址。在每个主机或者路由器中都建有一个ARP缓存表,表中有IP地址及IP地址对应的MAC地址。先来看一下什么时IP地址和MAC地址。
- IP地址:IP地址是指互联网协议地址,IP地址是IP协议提供的一种统一的地址格式,它为互联网上的每一个网络和每一台主机分配一个逻辑地址,以此来屏蔽物理地址的差异。
- MAC地址:MAC地址又称物理地址,由网络设备制造商生产时写在硬件内部,不可更改,并且每个以太网设备的MAC地址都是唯一的。
数据在传输过程中,会先从高层传到底层,然后在通信链路上传输。从下图可以看到TCP报文在网络层会被封装成IP数据报,在数据链路层被封装成MAC帧,然后在通信链路中传输。在网络层使用的是IP地址,在数据据链路层使用的是MAC地址。MAC帧在传送时的源地址和目的地址使用的都是MAC地址,在通信链路上的主机或路由器也都是根据MAC帧首部的MAC地址接收MAC帧。并且在数据链路层是看不到IP地址的,只有当数据传到网络层时去掉MAC帧的首部和尾部时才能在IP数据报的首部中找到源IP地址和目的地址
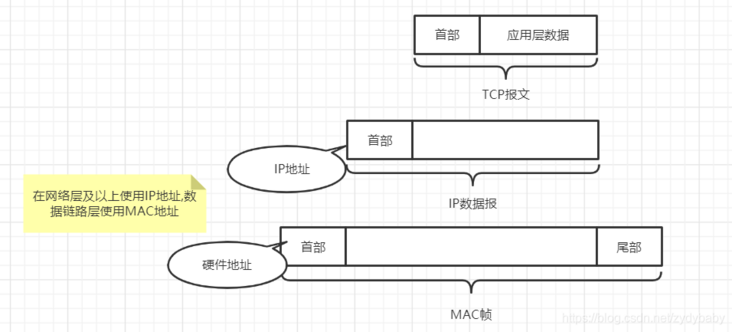
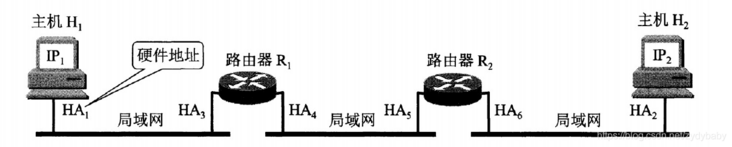
网络层实现的是主机之间的通信,而链路层实现的是链路之间的通信,所以从下图可以看出,在数据传输过程中,IP数据报的源地址(IP1)和目的地址(IP2)是一直不变的,而MAC地址(硬件地址)却一直随着链路的改变而改变。
ARP的工作流程(面试时问ARP协议主要说这个就可以了):
- 在局域网内,主机A要向主机B发送IP数据报时,首先会在主机A的ARP缓存表中查找是否有IP地址及其对应的MAC地址,如果有,则将MAC地址写入到MAC帧的首部,并通过局域网将该MAC帧发送到MAC地址所在的主机B。
- 如果主机A的ARP缓存表中没有主机B的IP地址及所对应的MAC地址,主机A会在局域网内广播发送一个ARP请求分组。局域网内的所有主机都会收到这个ARP请求分组。
- 主机B在看到主机A发送的ARP请求分组中有自己的IP地址,会像主机A以单播的方式发送一个带有自己MAC地址的响应分组。
- 主机A收到主机B的ARP响应分组后,会在ARP缓存表中写入主机B的IP地址及其IP地址对应的MAC地址。
- 如果主机A和主机B不在同一个局域网内,即使知道主机B的MAC地址也是不能直接通信的,必须通过路由器转发到主机B的局域网才可以通过主机B的MAC地址找到主机B。并且主机A和主机B已经可以通信的情况下,主机A的ARP缓存表中寸的并不是主机B的IP地址及主机B的MAC地址,而是主机B的IP地址及该通信链路上的下一跳路由器的MAC地址。这就是上图中的源IP地址和目的IP地址一直不变,而MAC地址却随着链路的不同而改变。
- 如果主机A和主机B不在同一个局域网,参考上图中的主机H1和主机H2,这时主机H1需要先广播找到路由器R1的MAC地址,再由R1广播找到路由器R2的MAC地址,最后R2广播找到主机H2的MAC地址,建立起通信链路。
2.6 有了 IP 地址,为什么还要用 MAC 地址
简单来说,标识网络中的一台计算机,比较常用的就是IP地址和MAC地址,但 计算机的IP地址可由用户自行更改,管理起来相对困难,而MAC地址不可更改,所以一般会把IP地址和MAC地址组合起来使用。具体是如何组合使用的在上面的ARP协议中已经讲的很清楚了。
那只用MAC地址不用IP地址可不可以呢?其实也是不行的,因为在最早就是MAC地址先出现的,并且当时并不用IP地址,只用MAC地址,后来随着网络中的设备越来越多,整个路由过程越来越复杂,便出现了子网的概念。对于目的地址在其他子网的数据包,路由只需要将数据包送到那个子网即可,这个过程就是上面说的ARP协议。
那为什么要用IP地址呢?是因为IP地址是和地域相关的,对于同一个子网上的设备,IP地址的前缀都是一样的,这样路由器通过IP地址的前缀就知道设备在在哪个子网上了,而只用MAC地址的话,路由器则需要记住每个MAC地址在哪个子网,这需要路由器有极大的存储空间,是无法实现的。
IP地址可以比作为地址,MAC地址为收件人,在一次通信过程中,两者是缺一不可的。
2.7 PING 的过程
ping是ICMP(网际控制报文协议)中的一个重要应用,ICMP是网络层的协议。ping的作用是测试两个主机的连通性。
-
机器A ping 机器B
-
同一网段
- ping 通知系统建立一个固定格式的 ICMP 请求数据包
- ICMP 协议打包这个数据包和机器B的IP地址转交给 IP 协议层
- IP 层协议将以机器B 的IP地址为目的地址,本机IP地址为源地址,加上一些其他的控制信息,构建一个IP数据包
- 获取机器B的MAC地址
- IP 层协议通过机器B的IP地址和自己的子网掩码,发现它和自己同于同一网络,就直接在本网络查找这台机器的 MAC
- 若两台机器之前有过通信,在机器A的ARP缓存表应该有机器B的IP和MAC映射关系
- 若没有,则A发送ARP请求广播,得到机器B的MAC地址,一并交给数据链路层
- 数据链路层构建一个数据帧,目的地址是 IP 层传来的MAC地址,源地址是本机A的MAC地址,在附加一个控制信息,依据以太网的介质访问规则,将他们传送出去
- 机器B收到这个数据帧后,先检查目的地址,和本机MAC地址对比
- 符合,接收。介绍后检查改数据帧,将IP数据包从帧中提取出来,交给本机的IP协议层。IP层检查完毕后,将有用的信息提取交给ICMP协议,后者处理后,马上构建一个ICMP应答包,发送给主机A,其过程和主机A发送ICMP请求包到B类似(这时候主机B已经知道主机A的MAC地址,无需再发送ARP请求)
- 不符合,则丢弃
- IP 层协议通过机器B的IP地址和自己的子网掩码,发现它和自己同于同一网络,就直接在本网络查找这台机器的 MAC
-
不同网段
-
ping 通知系统简历一个固定格式的ICMP请求数据包
-
ICMP协议打包这个数据包和机器B的IP地址转交给IP协议层
-
IP层协议将以机器B的IP地址为目的地址,本机IP地址为源地址,加上一些其他的控制信息,构建一个IP数据包
-
获取主机B的MAC地址
- P协议通过计算发现主机B与自己不在同一网段内,就直接交给路由处理,就是将路由的MAC取过来,至于怎么得到路由的MAC地址,和之前一样,先在ARP缓存表中寻找,找不到可以利用广播。路由得到这个数据帧之后,再跟主机B联系,若找不到,就向主机A返回一个超时信息。
-
-
-
-
对ping后返回信息的分析
-
Request timed out
-
对方已关机,或者网络上没有这个地址
-
对方与自己不在同一网段内,通过路由也无法到达
-
对方存在,不过设置了ICMP数据包过滤(比如防火墙设置)
-
错误设置IP地址
-
-
Destination host Unreachable
- 自己未设定默认路由,对方跟自己不在同已网段
- 网线有问题
Request timed out 与 Destination host Unreachable 的区别
所经过的路由器的路由表具有到达目标的路由,而目标因为原因不可到达,这时出现前者。如果路由表中连到达目标的路由都没有,就会出现后者。 -
Bad ip address
- 没有连接到DNS服务器,无法解析IP,也可能是IP不存在
-
Source quench received
- 对方或中途服务器繁忙而无法应答
-
Unknown host
- 远程主机的名字不能被域名服务器转换成IP地址,故障原因可能是DNS服务器有故障,或者名字不正确,或者网络管理员的系统与远程主机之间的通信线路故障。
-
No answer
- 无响应。说明本地系统有一条通向中心主机的路由,但却接收不到它发给该中心主机的人呢和信息。故障原因可能是:中心主机没有工作;本地或中心主机网络配置不正确;本地或中心的路由器没有工作;通信线路有故障;中心主机存在路由选择问题。
-
Ping 127.0.0.1
- 如果ping不通,则表明本地址TCP/IP协议不能正常工作
-
no rout to host
- 网卡工作不正常
-
transmit failed。error code
- 10043网卡驱动不正常
-
unknown host name
- DNS配置不正确
-
2.8 路由器和交换机的区别
| 所属网络模型的层级 | 功能 | |
|---|---|---|
| 路由器 | 网络层 | 识别IP地址并根据IP地址转发数据包,维护数据表并基于数据表进行最佳路径选择 |
| 交换机 | 数据链库层 | 识别MAC地址并根据MAC地址转发数据帧 |
2.9 TCP 与 UDP
2.9.1 TCP 与 UDP 的区别
-
用户数据报协议 UDP(User Datagram Protocol)
是无连接的,尽最大可能交付,没有拥塞控制,面向报文(对于应用程序传下来的报文不合并也不拆分,只是添加 UDP 首部),支持一对一、一对多、多对一和多对多的交互通信。
-
传输控制协议 TCP(Transmission Control Protocol)
是面向连接的,提供可靠交付,有流量控制,拥塞控制,提供全双工通信,面向字节流(把应用层传下来的报文看成字节流,把字节流组织成大小不等的数据块),每一条 TCP 连接只能是点对点的(一对一)。
| 是否面向连接 | 可靠性 | 传输形式 | 传输效率 | 消耗资源 | 应用场景 | 首部字节 | |
|---|---|---|---|---|---|---|---|
| TCP | 面向连接 | 可靠 | 字节流 | 慢 | 多 | 文件/邮件传输 | 20~60 |
| UDP | 无连接 | 不可靠 | 数据报文段 | 快 | 少 | 视频/语音传输 | 8 |
-
TCP是面向 链接 的,而UDP是面向 无连接 的。
-
TCP仅支持 单播传输,UDP 提供了单播,多播,广播的功能。
-
TCP的三次握手保证了连接的 可靠性; UDP是无连接的、不可靠 的一种数据传输协议,首先不可靠性体现在无连接上,通信都不需要建立连接,对接收到的数据也不发送确认信号,发送端不知道数据是否会正确接收。
-
UDP的 头部开销 比TCP的更小,数据 传输速率更高,实时性更好。
-
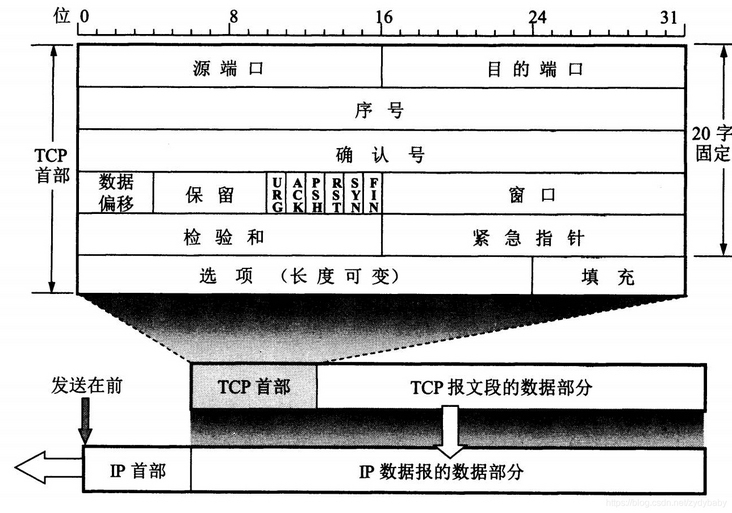
TCP首部(图片来源于网络):
前20个字节是固定的,后面有4n个字节是根据需而增加的选项,所以TCP首部最小长度为20字节。
-
UDP首部
UDP的首部只有8个字节,源端口号、目的端口号、长度和校验和各两个字节。

2.9.2 TCP 短连接与长连接的区别
短连接:Client 向 Server 发送消息,Server 回应 Client,然后一次读写就完成了,这时候双方任何一个都可以发起 close 操作,不过一般都是 Client 先发起 close 操作。短连接一般只会在 Client/Server 间传递一次读写操作。
短连接的优点:管理起来比较简单,建立存在的连接都是有用的连接,不需要额外的控制手段。
长连接:Client 与 Server 完成一次读写之后,它们之间的 连接并不会主动关闭,后续的读写操作会继续使用这个连接。
在长连接的应用场景下,Client 端一般不会主动关闭它们之间的连接,Client 与 Server 之间的连接如果一直不关闭的话,随着客户端连接越来越多,Server 压力也越来越大,这时候 Server 端需要采取一些策略,如关闭一些长时间没有读写事件发生的连接,这样可以避免一些恶意连接导致 Server 端服务受损;如果条件再允许可以以客户端为颗粒度,限制每个客户端的最大长连接数,从而避免某个客户端连累后端的服务。
长连接和短连接的产生在于 Client 和 Server 采取的 关闭策略,具体的应用场景采用具体的策略。
2.9.3 TCP 粘包、拆包及解决办法
-
为什么常说 TCP 有粘包和拆包的问题而不说 UDP ?
-
UDP 是基于报文发送的,UDP首部采用了 16bit 来指示 UDP 数据报文的长度,因此在应用层能很好的将不同的数据报文区分开,从而避免粘包和拆包的问题。
-
而 TCP 是基于字节流的,虽然应用层和 TCP 传输层之间的数据交互是大小不等的数据块,但是 TCP 并没有把这些数据块区分边界,仅仅是一连串没有结构的字节流;另外从 TCP 的帧结构也可以看出,在 TCP 的首部没有表示数据长度的字段,基于上面两点,在使用 TCP 传输数据时,才有粘包或者拆包现象发生的可能。
-
-
什么是粘包、拆包?
假设 Client 向 Server 连续发送了两个数据包,用 packet1 和 packet2 来表示,那么服务端收到的数据可以分为三种情况,现列举如下:
-
第一种情况,接收端正常收到两个数据包,即没有发生拆包和粘包的现象。

-
第二种情况,接收端只收到一个数据包,但是这一个数据包中包含了发送端发送的两个数据包的信息,这种现象即为粘包。这种情况由于接收端不知道这两个数据包的界限,所以对于接收端来说很难处理。

-
第三种情况,这种情况有两种表现形式,如下图。接收端收到了两个数据包,但是这两个数据包要么是不完整的,要么就是多出来一块,这种情况即发生了拆包和粘包。这两种情况如果不加特殊处理,对于接收端同样是不好处理的。

-
-
为什么会发生 TCP 粘包、拆包?
- 要发送的数据大于 TCP 发送缓冲区剩余空间大小,将会发生拆包。
- 待发送数据大于 MSS(最大报文长度),TCP 在传输前将进行拆包。
- 要发送的数据小于 TCP 发送缓冲区的大小,TCP 将多次写入缓冲区的数据一次发送出去,将会发生粘包。
- 接收数据端的应用层没有及时读取接收缓冲区中的数据,将发生粘包。
-
粘包、拆包解决办法
由于 TCP 本身是面向字节流的,无法理解上层的业务数据,所以 在底层是无法保证数据包不被拆分和重组的,这个问题 只能通过上层的应用协议栈设计来解决,根据业界的主流协议的解决方案,归纳如下:
- 消息定长:发送端将每个数据包封装为固定长度(不够的可以通过补 0 填充),这样接收端每次接收缓冲区中读取固定长度的数据就自然而然的把每个数据包拆分开来。
- 设置消息边界:服务端从网络流中按消息边界分离出消息内容。在包尾增加回车换行符进行分割,例如 FTP 协议。
- 将消息分为消息头和消息体:消息头中包含表示消息总长度(或者消息体长度)的字段。
- 更复杂的应用层协议比如 Netty 中实现的一些协议都对粘包、拆包做了很好的处理。
2.10 TCP协议如何保证可靠传输
主要有校验和、序列号、超时重传、流量控制及拥塞避免等几种方法。
-
校验和:在发送端和接收端分别计算数据的校验和,如果两者不一致,则说明数据在传输过程中出现了差错,TCP将丢弃和不确认此报文段。
-
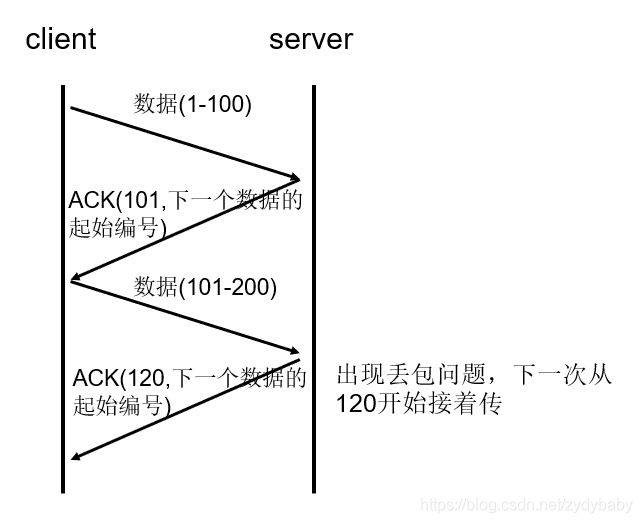
序列号:TCP会对每一个发送的字节进行编号,接收方接到数据后,会对发送方发送确认应答(ACK报文),并且这个ACK报文中带有相应的确认编号,告诉发送方,下一次发送的数据从编号多少开始发。如果发送方发送相同的数据,接收端也可以通过序列号判断出,直接将数据丢弃
-
超时重传:在上面说了序列号的作用,但如果发送方在发送数据后一段时间内(可以设置重传计时器规定这段时间)没有收到确认序号ACK,那么发送方就会重新发送数据。
这里发送方没有收到ACK可以分两种情况,如果是发送方发送的数据包丢失了,接收方收到发送方重新发送的数据包后会马上给发送方发送ACK;
如果是接收方之前接收到了发送方发送的数据包,而返回给发送方的ACK丢失了,这种情况,发送方重传后,接收方会直接丢弃发送方冲重传的数据包,然后再次发送ACK响应报文。
如果数据被重发之后还是没有收到接收方的确认应答,则进行再次发送。此时,等待确认应答的时间将会以2倍、4倍的指数函数延长,直到最后关闭连接。
-
流量控制:如果发送端发送的数据太快,接收端来不及接收就会出现丢包问题。为了解决这个问题,TCP协议利用了滑动窗口进行了流量控制。在TCP首部有一个16位字段大小的窗口,窗口的大小就是接收端接收数据缓冲区的剩余大小。接收端会在收到数据包后发送ACK报文时,将自己的窗口大小填入ACK中,发送方会根据ACK报文中的窗口大小进而控制发送速度。如果窗口大小为零,发送方会停止发送数据。
-
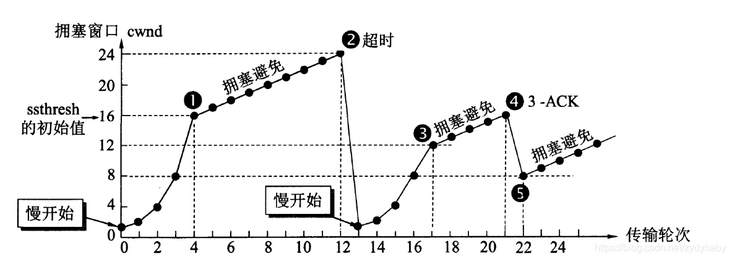
拥塞控制:如果网络出现拥塞,则会产生丢包等问题,这时发送方会将丢失的数据包继续重传,网络拥塞会更加严重,所以在网络出现拥塞时应注意控制发送方的发送数据,降低整个网络的拥塞程度。拥塞控制主要有四部分组成:慢开始、拥塞避免、快重传、快恢复,如下图(图片来源于网络)。
2.11 TCP的三次握手及四次挥手
TCP头部的一些常用字段。
- 顺序号:seq(Sequence number),占32位,用来标识从发送端到接收端发送的字节流。
- 确认号:ack(Acknowledge number),占32位,只有ACK标志位为1时,确认序号字段才有效,ack=seq+1。
- 标志位:
- SYN(synchronous):发起一个新连接。
- FIN(finish):释放一个连接。
- ACK(acknowledgement):确认序号有效。
2.11.1 三次握手
三次握手的本质就是确定发送端和接收端具备收发信息的能力,在能流畅描述三次握手的流程及其中的字段含义作用的同时还需要记住每次握手时 接收端和发送端的状态。这个比较容易忽略
先看一张很经典的图(图片来源于网络),发送端有CLOSED、SYN-SENT、ESTABLISHED三种状态,接收端有CLOSED、LISTEN、SYN-RCVD、ESTABLISHED四种状态。
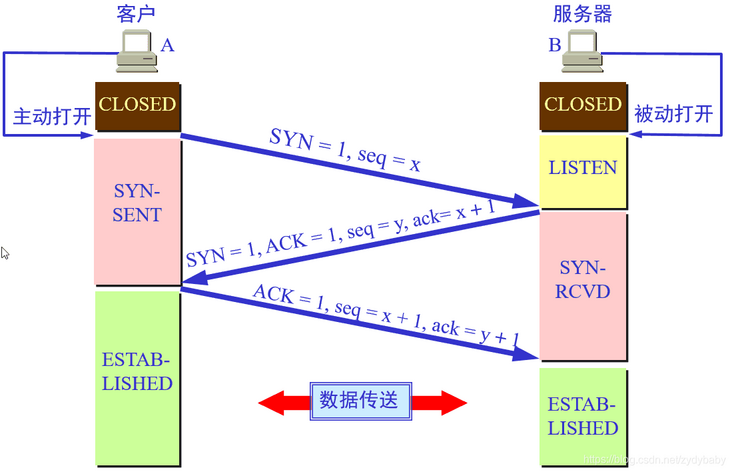
假设发送端为客户端,接收端为服务端。开始时客户端和服务端的状态都是CLOSE。
- 第一次握手:客户端向服务端发起建立连接请求,客户端会随机生成一个起始序列号x,客户端向服务端发送的字段中包含标志位SYN=1,序列号seq=x。第一次握手前客户端的状态为CLOSE,第一次握手后客户端的状态为SYN-SENT。此时服务端的状态为LISTEN
- 第二次握手:服务端在收到客户端发来的报文后,会随机生成一个服务端的起始序列号y,然后给客户端回复一段报文,其中包括标志位SYN=1,ACK=1,序列号seq=y,确认号ack=x+1。第二次握手前服务端的状态为LISTEN,第二次握手后服务端的状态为SYN-RCVD,此时客户端的状态为SYN-SENT。(其中SYN=1表示要和客户端建立一个连接,ACK=1表示确认序号有效)
- 第三次握手:客户端收到服务端发来的报文后,会再向服务端发送报文,其中包含标志位ACK=1,序列号seq=x+1,确认号ack=y+1。第三次握手前客户端的状态为SYN-SENT,第三次握手后客户端和服务端的状态都为ESTABLISHED
需要注意的一点是,第一次握手,客户端向服务端发起建立连接报文,会占一个序列号。但是第三次握手,同样是客户端向服务端发送报文,这次却不占序列号,所以建立连接后,客户端向服务端发送的第一个数据的序列号为x+1
2.11.2 四次挥手
和三次握手一样,先看一张非常经典的图(图片来源于网络),客户端在四次挥手过程中有ESTABLISHED、FIN-WAIT-1、FIN-WAIT-2、TIME-WAIT、CLOSED等五个状态,服务端有ESTABLISHED、CLOSE-WAIT、LAST-ACK、CLOSED等四种状态。最好记住每次挥手时服务端和客户端的状态。
假设客户端首先发起的断开连接请求:
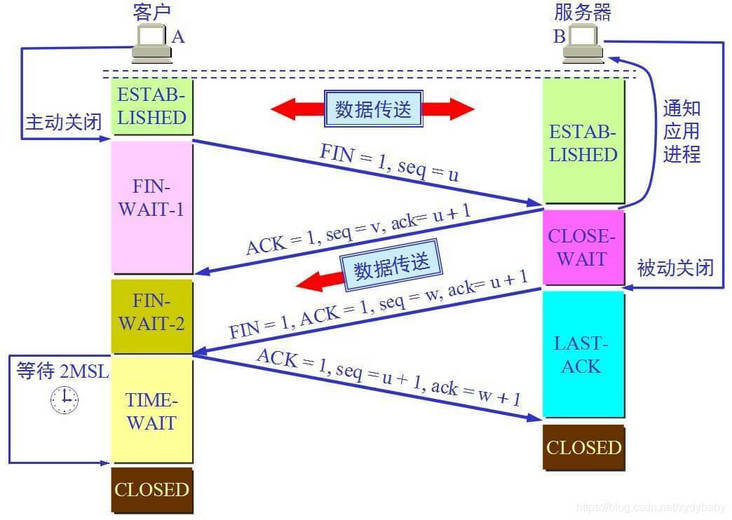
-
客户端Client进程发出连接释放报文,并且停止发送数据。其中FIN=1,顺序号为seq=u(等于前面已经传送过来的数据的最后一个字节的序号加1),此时,客户端Client进入FIN-WAIT-1(终止等待1)状态。 TCP规定,FIN报文段即使不携带数据,也要消耗一个序号。
-
服务器Server收到连接释放报文,发出确认报文,ACK=1,ack=u+1,并且带上自己的顺序号seq=v,此时,服务器Server就进入了CLOSE-WAIT(关闭等待)状态。TCP服务器通知高层的应用进程,客户端Client向服务器的方向就释放了,这时候处于半关闭状态,即客户端Client已经没有数据要发送了,但是服务器Server若发送数据,客户端Client依然要接受。这个状态还要持续一段时间,也就是整个CLOSE-WAIT状态持续的时间。
-
客户端Client收到服务器Server的确认信息后,此时,客户端Client就进入FIN-WAIT-2(终止等待2)状态,等待服务器Server发送连接释放报文(在这之前还需要接受服务器Server发送的最后的数据)。
-
服务器Server将最后的数据发送完毕后,就向客户端发送连接释放报文,FIN=1,ack=u+1,由于在半关闭状态,服务器Server很可能又发送了一些数据,假定此时的顺序号为seq=w,此时,服务器Server就进入了LAST-ACK(最后确认)状态,等待客户端Client的确认。
-
客户端Client收到服务器Server的连接释放报文后,必须发出确认,ACK=1,ack=w+1,而自己的顺序号是seq=u+1,此时,客户端Client就进入了TIME-WAIT(时间等待)状态。注意此时TCP连接还没有释放,必须经过2*MSL(最长报文段寿命)的时间后,当客户端Client撤销相应的TCB(保护程序)后,才进入CLOSED状态。
-
服务器Server只要收到了客户端Client发出的确认,立即进入CLOSED状态。同样,撤销TCB后,就结束了这次的TCP连接。可以看到,服务器Server结束TCP连接的时间要比客户端Client早一些。
- 第一次挥手:客户端向服务端发送的数据完成后,向服务端发起释放连接报文,报文包含标志位FIN=1,序列号seq=u。此时客户端只能接收数据,不能向服务端发送数据。
- 第二次挥手:服务端收到客户端的释放连接报文后,向客户端发送确认报文,包含标志位ACK=1,序列号seq=v,确认号ack=u+1。此时客户端到服务端的连接已经释放掉,客户端不能像服务端发送数据,服务端也不能向客户端发送数据。但服务端到客户端的单向连接还能正常传输数据。
- 第三次挥手:服务端发送完数据后向客户端发出连接释放报文,报文包含标志位FIN=1,标志位ACK=1,序列号seq=w,确认号ack=u+1。
- 第四次挥手:客户端收到服务端发送的释放连接请求,向服务端发送确认报文,包含标志位ACK=1,序列号seq=u+1,确认号ack=w+1。
2.11.3 为什么TCP连接的时候是3次?两次是否可以?
不可以,主要从以下两方面考虑(假设客户端是首先发起连接请求):
- 假设建立TCP连接仅需要两次握手,那么如果第二次握手时,服务端返回给客户端的确认报文丢失了,客户端这边认为服务端没有和他建立连接,而服务端却以为已经和客户端建立了连接,并且可能向服务端已经开始向客户端发送数据,但客户端并不会接收这些数据,浪费了资源。如果是三次握手,不会出现双方连接还未完全建立成功就开始发送数据的情况。
- 如果服务端接收到了一个早已失效的来自客户端的连接请求报文,会向客户端发送确认报文同意建立TCP连接。但因为客户端并不需要向服务端发送数据,所以此次TCP连接没有意义并且浪费了资源。
2.11.4 为什么TCP连接的时候是3次,关闭的时候却是4次?
因为需要确保通信双方都能通知对方释放连接,假设客服端发送完数据向服务端发送释放连接请求,当客服端并不知道,服务端是否已经发送完数据,所以此次断开的是客服端到服务端的单向连接,服务端返回给客户端确认报文后,服务端还能继续单向给客户端发送数据。当服务端发送完数据后还需要向客户端发送释放连接请求,客户端返回确认报文,TCP连接彻底关闭。所以断开TCP连接需要客户端和服务端分别通知对方并分别收到确认报文,一共需要四次。
2.11.5 TIME_WAIT和CLOSE_WAIT的区别在哪?
默认客户端首先发起断开连接请求
- 从上图可以看出,CLOSE_WAIT是被动关闭形成的,当客户端发送FIN报文,服务端返回ACK报文后进入CLOSE_WAIT。
- TIME_WAIT是主动关闭形成的,当第四次挥手完成后,客户端进入TIME_WAIT状态。
2.11.6 为什么客户端发出第四次挥手的确认报文后要等2MSL的时间才能释放TCP连接?
MSL的意思是报文的最长寿命,可以从两方面考虑:
- 客户端发送第四次挥手中的报文后,再经过2MSL,可使本次TCP连接中的所有报文全部消失,不会出现在下一个TCP连接中。
- 考虑丢包问题,如果第四挥手发送的报文在传输过程中丢失了,那么服务端没收到确认ack报文就会重发第三次挥手的报文。如果客户端发送完第四次挥手的确认报文后直接关闭,而这次报文又恰好丢失,则会造成服务端无法正常关闭
2.11.7 如果已经建立了连接,但是客户端突然出现故障了怎么办?
如果TCP连接已经建立,在通信过程中,客户端突然故障,那么服务端不会一直等下去,过一段时间就关闭连接了。具体原理是TCP有一个保活机制,主要用在服务器端,用于检测已建立TCP链接的客户端的状态,防止因客户端崩溃或者客户端网络不可达,而服务器端一直保持该TCP链接,占用服务器端的大量资源(因为Linux系统中可以创建的总TCP链接数是有限制的)。
保活机制原理:设置TCP保活机制的保活时间 keepIdle,即在TCP链接超过该时间没有任何数据交互时,发送保活探测报文;设置保活探测报文的发送时间间隔keepInterval;设置保活探测报文的总发送次数keepCount。如果在keepCount次的保活探测报文均没有收到客户端的回应,则服务器端即关闭与客户端的TCP链接。
2.12 HTTP 与 HTTPS 的区别
- http: 是一个客户端和服务器端请求和应答的标准(TCP),用于从 WWW 服务器传输超文本到本地浏览器的超文本传输协议。
- https:是以安全为目标的 HTTP 通道,即 HTTP 下 加入 SSL 层进行加密。其作用是:建立一个信息安全通道,来确保数据的传输,确保网站的真实性。
| HTTP | HTTPS | |
|---|---|---|
| 端口 | 80 | 443 |
| 安全性 | 无加密,安全性较差 | 有加密机制,安全性较高 |
| 资源消耗 | 较少 | 由于加密处理,资源消耗更多 |
| 是否需要证书 | 不需要 | 需要 |
| 协议 | 运行在TCP协议之上 | 运行在SSL协议之上,SSL运行在TCP协议之上 |
- http 是超文本传输协议,信息是明文传输,HTTPS 协议要比 http 协议 安全,https 是具有安全性的 ssl 加密传输协议,可防止数据在传输过程中被窃取、改变,确保数据的完整性(当然这种安全性并非绝对的,对于更深入的 Web 安全问题,此处暂且不表)。
- http 协议的 默认端口 为 80,https 的默认端口为 443。
- http 的连接很简单,是 无状态的。https 握手阶段比较 费时,会使页面加载时间延长 50%,增加 10%~20%的耗电。
- https 缓存 不如 http 高效,会增加数据开销。
- Https 协议需要 ca 证书,费用较高,功能越强大的
证书费用越高。 - SSL 证书需要绑定 IP,不能再同一个 IP 上绑定多个域名,IPV4 资源支持不了这种消耗。
2.13 对称加密与非对称加密
-
对称加密
对称加密指加密和解密使用同一密钥,优点是运算速度快,缺点是如何安全将密钥传输给另一方。常见的对称加密算法有DES、AES等等。
-
非对称加密
非对称加密指的是加密和解密 使用不同的密钥,一把公开的公钥,一把私有的私钥。公钥加密的信息只有私钥才能解密,私钥加密的信息只有公钥才能解密。优点解决了对称加密中存在的问题。缺点是运算速度较慢。常见的非对称加密算法有RSA、DSA、ECC等等。
非对称加密的工作流程:A生成一对非对称密钥,将公钥向所有人公开,B拿到A的公钥后使用A的公钥对信息加密后发送给A,经过加密的信息只有A手中的私钥能解密。这样B可以通过这种方式将自己的公钥加密后发送给A,两方建立起通信,可以通过对方的公钥加密要发送的信息,接收方用自己的私钥解密信息。
2.14 HTTPS的加密过程
HTTPS是将两者结合起来,使用的对称加密和非对称加密的混合加密算法。具体做法就是使用非对称加密来传输对称密钥来保证安全性,使用对称加密来保证通信的效率。
简化的工作流程:服务端生成一对非对称密钥,将公钥发给客户端。客户端生成对称密钥,用服务端发来的公钥进行加密,加密后发给服务端。服务端收到后用私钥进行解密,得到客户端发送的对称密钥。通信双方就可以通过对称密钥进行高效地通信了。
但是仔细想想这其中存在一个很大地问题,就是客户端最开始如何判断收到的这个公钥就是来自服务端而不是其他人冒充的?
这就需要证书上场了,服务端会向一个权威机构申请一个证书来证明自己的身份,到时候将证书(证书中包含了公钥)发给客户端就可以了,客户端收到证书后既证明了服务端的身份又拿到了公钥就可以进行下一步操作了。
HTTPS的加密过程:
- 客户端向服务端发起第一次握手请求,告诉服务端客户端所支持的SSL的指定版本、加密算法及密钥长度等信息。
- 服务端将自己的公钥发给数字证书认证机构,数字证书认证机构利用自己的私钥对服务器的公钥进行数字签名,并给服务器颁发公钥证书。
- 服务端将证书发给客服端。
- 客服端利用数字认证机构的公钥,向数字证书认证机构验证公钥证书上的数字签名,确认服务器公开密钥的真实性。
- 客服端使用服务端的公开密钥加密自己生成的对称密钥,发给服务端。
- 服务端收到后利用私钥解密信息,获得客户端发来的对称密钥。
- 通信双方可用对称密钥来加密解密信息。
上述流程存在的一个问题是客户端哪里来的数字认证机构的公钥,其实,在很多浏览器开发时,会内置常用数字证书认证机构的公钥。
流程图如下:

2.15 常用HTTP状态码
| 状态码 | 类别 |
|---|---|
| 1XX | 信息性状态码 |
| 2XX | 成功状态码 |
| 3XX | 重定向状态码 |
| 4XX | 客户端错误状态码 |
| 5XX | 服务端错误状态码 |
常见的HTTP状态码
1XX 信息性状态码
- 100 Continue:表示正常,客户端可以继续发送请求
- 101 Switching Protocols:切换协议,服务器根据客户端的请求切换协议。
2XX 成功状态码
- 200 OK:请求成功
- 201 Created:已创建,表示成功请求并创建了新的资源
- 202 Accepted:已接受,已接受请求,但未处理完成。
- 204 No Content:无内容,服务器成功处理,但未返回内容。
- 205 Reset Content:重置内容,服务器处理成功,客户端应重置文档视图。
- 206 Partial Content:表示客户端进行了范围请求,响应报文应包含Content-Range指定范围的实体内容
3XX 重定向状态码
- 301 Moved Permanently:永久性重定向
- 302 Found:临时重定向
- 303 See Other:和301功能类似,但要求客户端采用get方法获取资源
- 304 Not Modified:所请求的资源未修改,服务器返回此状态码时,不会返回任何资源。
- 305 Use Proxy:所请求的资源必须通过代理访问
- 307 Temporary Redirect: 临时重定向,与302类似,要求使用get请求重定向。
4XX 客户端错误状态码
- 400 Bad Request:客户端请求的语法错误,服务器无法理解。
- 401 Unauthorized:表示发送的请求需要有认证信息。
- 403 Forbidden:服务器理解用户的请求,但是拒绝执行该请求
- 404 Not Found:服务器无法根据客户端的请求找到资源。
- 405 Method Not Allowed:客户端请求中的方法被禁止
- 406 Not Acceptable:服务器无法根据客户端请求的内容特性完成请求
- 408 Request Time-out:服务器等待客户端发送的请求时间过长,超时
5XX 服务端错误状态码
- 500 Internal Server Error:服务器内部错误,无法完成请求
- 501 Not Implemented:服务器不支持请求的功能,无法完成请求
2.16 常见的HTTP方法
| 方法 | 作用 |
|---|---|
| GET | 获取资源 |
| POST | 传输实体主体 |
| PUT | 上传文件 |
| DELETE | 删除文件 |
| HEAD | 和GET方法类似,但只返回报文首部,不返回报文实体主体部分 |
| PATCH | 对资源进行部分修改 |
| OPTIONS | 查询指定的URL支持的方法 |
| CONNECT | 要求用隧道协议连接代理 |
| TRACE | 服务器会将通信路径返回给客户端 |
为了方便记忆,可以将PUT、DELETE、POST、GET理解为客户端对服务端的增删改查。
- PUT:上传文件,向服务器添加数据,可以看作增
- DELETE:删除文件
- POST:传输数据,向服务器提交数据,对服务器数据进行更新。
- GET:获取资源,查询服务器资源
2.17 GET和POST区别
- 作用
GET用于 获取资源,POST用于 传输实体主体
- 参数位置
GET的参数放在URL中,POST的参数存储在实体主体中,并且 GET方法提交的请求的URL中的数据做多是2048字节,POST请求没有大小限制。
- 安全性
GET方法因为参数放在URL中,安全性相对于POST较差一些
- 幂等性
GET方法是具有幂等性的,而POST方法不具有幂等性。这里幂等性指客户端连续发出多次请求,收到的结果都是一样的
从w3schools得到的标准答案的区别如下:
- GET在浏览器回退时是无害的,而POST会再次提交请求。
- GET产生的URL地址可以被Bookmark,而POST不可以。
- GET请求会被浏览器主动cache,而POST不会,除非手动设置。
- GET请求只能进行url编码,而POST支持多种编码方式。
- GET请求参数会被完整保留在浏览器历史记录里,而POST中的参数不会被保留。
- GET请求在URL中传送的参数是有长度限制的,而POST没有。
- 对参数的数据类型,GET只接受ASCII字符,而POST没有限制。
- GET比POST更不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息。
- GET参数通过URL传递,POST放在Request body中
2.18 HTTP 1.0、HTTP 1.1及HTTP 2.0和HTTP3的主要区别
HTTP 1.0 和HTTP 1.1的区别
-
长连接
HTTP 1.1支持长连接和请求的流水线操作。长连接是指不在需要每次请求都重新建立一次连接,HTTP 1.0 默认使用短连接,每次请求都要重新建立一次TCP连接,资源消耗较大。请求的流水线操作是指客户端在收到HTTP的响应报文之前可以先发送新的请求报文,不支持请求的流水线操作需要等到收到HTTP的响应报文后才能继续发送新的请求报文。
-
缓存处理
在HTTP 1.0中主要使用header中的If-Modified-Since,Expires作为缓存判断的标准,HTTP 1.1引入了Entity tag,If-Unmodified-Since, If-Match等更多可供选择的缓存头来控制缓存策略。
-
错误状态码
在HTTP 1.1新增了24个错误状态响应码
-
HOST域
在HTTP 1.0 中认为每台服务器都会绑定唯一的IP地址,所以,请求中的URL并没有传递主机名。但后来一台服务器上可能存在多个虚拟机,它们共享一个IP地址,所以HTTP 1.1中请求消息和响应消息都应该支持Host域。
-
带宽优化及网络连接的使用
在HTTP 1.0中会存在浪费带宽的现象,主要是因为不支持断点续传功能,客户端只是需要某个对象的一部分,服务端却将整个对象都传了过来。在HTTP 1.1中请求头引入了range头域,它支持只请求资源的某个部分,返回的状态码为206。
HTTP 2.0的新特性
- 新的二进制格式:HTTP 1.x的解析是基于文本,HTTP 2.0的解析采用二进制,实现方便,健壮性更好。
- 多路复用:每一个request对应一个id,一个连接上可以有多个request,每个连接的request可以随机混在一起,这样接收方可以根据request的id将request归属到各自不同的服务端请求里。
- header压缩:在HTTP 1.x中,header携带大量信息,并且每次都需要重新发送,HTTP 2.0采用编码的方式减小了header的大小,同时通信双方各自缓存一份header fields表,避免了header的重复传输。
- 服务端推送:客户端在请求一个资源时,会把相关资源一起发给客户端,这样客户端就不需要再次发起请求
HTTP/2 和 TCP 的缺陷
HTTP/2 使⽤⼆进制传输、 Header 压缩(HPACK)、多路复⽤等,相较于 HTTP/1.1 ⼤幅提⾼了数据传输效率,但它仍然存在着以下⼏个致命问题(主要由底层⽀撑的 TCP 协议造成):
- 建⽴连接时间⻓
- 队头阻塞问题相较于 HTTP/1.1 更严重
HTTP/3 和 QUIC 新特性
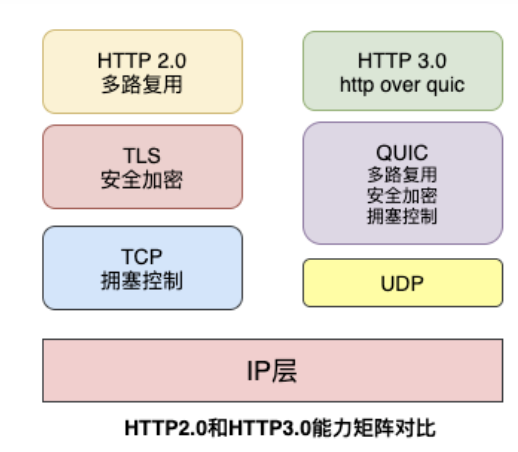
QUIC 虽然基于 UDP,但是在原本的基础上新增了很多功能,⽐如多路复⽤、 0-RTT、使⽤ TLS1.3 加密、流量控制、有序交付、重传等等功能。
2.19 Session、Cookie和Token的主要区别
HTTP协议是无状态的,即服务器无法判断用户身份。Session和Cookie可以用来进行身份辨认。
-
相同点
- 是都存储在客户端
-
不同点
- Cookie数据大小不能超过4k,超过最大限制,该cookie会被静默删除;sessionStorage和localStorage的存储比cookie大得多,可以达到5M+
- cookie设置的过期时间之前一直有效;localStorage永久存储,浏览器关闭后数据不丢失除非主动删除数据;sessionStorage数据在当前浏览器窗口关闭后自动删除
- cookie的数据会自动的传递到服务器;sessionStorage和localStorage数据保存在本地
-
Cookie
Cookie是保存在客户端一个小数据块,其中包含了用户信息。当客户端向服务端发起请求,服务端会像客户端浏览器发送一个Cookie,客户端会把Cookie存起来,当下次客户端再次请求服务端时,会携带上这个Cookie,服务端会通过这个Cookie来确定身份。
**Cookie 的缺陷在于: **
-
IE6或更低版本最多20个cookie
-
IE7和之后的版本最多50个cookie
-
Firefox最多50个cookie
-
Chrome和Safari没有硬性限制
-
IE和Opera会清理掉近期最少使用的cookie而Firefox会随机清理掉一些cookie
-
Cookie的最大大约为4096字节,为了兼容性,一般不能超过4095字节。
-
-
Session
Session是通过Cookie实现的,和Cookie不同的是,Session是存在服务端的。当客户端浏览器第一次访问服务器时,服务器会为浏览器创建一个sessionid,将sessionid放到Cookie中,存在客户端浏览器。比如浏览器访问的是购物网站,将一本《图解HTTP》放到了购物车,当浏览器再次访问服务器时,服务器会取出Cookie中的sessionid,并根据sessionid获取会话中的存储的信息,确认浏览器的身份是上次将《图解HTTP》放入到购物车那个用户。
-
Token
客户端在浏览器第一次访问服务端时,服务端生成的一串字符串作为Token发给客户端浏览器,下次浏览器在访问服务端时携带token即可无需验证用户名和密码,省下来大量的资源开销
| 存放位置 | 占用空间 | 安全性 | 应用场景 | |
|---|---|---|---|---|
| Cookie | 客户端浏览器 | 小 | 较低 | 一般存放配置信息 |
| Session | 服务端 | 多 | 较高 | 存放较为重要的信息 |
cookie,localStorage,sessionStorage,indexDB
| 特性 | cookie | localStorage | sessionStorage | indexDB |
|---|---|---|---|---|
| 数据生命周期 | 一般由服务器生成,可以设置过期时间 | 除非被清理,否则一直存在 | 页面关闭就清理 | 除非被清理,否则一直存在 |
| 数据存储大小 | 4K | 5M | 5M | 无限 |
| 与服务端通信 | 每次都会携带在 header 中,对于请求性能影响 | 不参与 | 不参与 | 不参与 |
从上表可以看到,cookie 已经不建议用于存储。如果没有大量数据存储需求的话,可以使用 localStorage 和 sessionStorage 。对于不怎么改变的数据尽量使用 localStorage 存储,否则可以用 sessionStorage 存储。
对于 cookie,我们还需要注意安全性。
| 属性 | 作用 |
|---|---|
| value | 如果用于保存用户登录态,应该将该值加密,不能使用明文的用户标识 |
| http-only | 不能通过 JS 访问 Cookie,减少 XSS 攻击 |
| secure | 只能在协议为 HTTPS 的请求中携带 |
| same-site | 规定浏览器不能在跨域请求中携带 Cookie,减少 CSRF 攻击 |
2.20 如果客户端禁止 cookie 能实现 session 还能用吗
可以,Session的作用是在服务端来保持状态,通过sessionid来进行确认身份,但sessionid一般是通过Cookie来进行传递的。如果Cooike被禁用了,可以通过在URL中传递sessionid。
2.21 在浏览器中输⼊url地址到显示主页的过程
- 对输入到浏览器的url进行DNS解析,将域名转换为IP地址。
- 和目的服务器建立TCP连接
- 向目的服务器发送HTTP请求
- 服务器处理请求并返回HTTP报文
- 浏览器解析并渲染页面
上面为笼统的回答
从输入URL到页面加载的全过程:
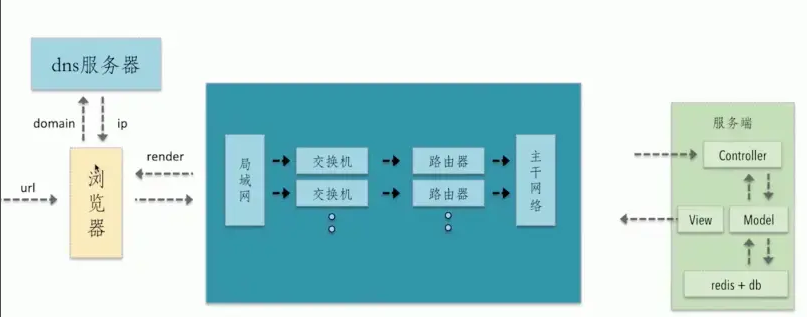
-
首先在浏览器中输入URL
-
查找缓存:浏览器先查看浏览器缓存-系统缓存-路由缓存中是否有该地址页面,如果有则显示页面内容。如果没有则进行下一步。
- 浏览器缓存:浏览器会记录DNS一段时间,因此,只是第一个地方解析DNS请求;
- 操作系统缓存:如果在浏览器缓存中不包含这个记录,则会使系统调用操作系统, 获取操作系统的记录(保存最近的DNS查询缓存);
- 路由器缓存:如果上述两个步骤均不能成功获取DNS记录,继续搜索路由器缓存;
- ISP缓存:若上述均失败,继续向ISP搜索
-
DNS域名解析:浏览器向DNS服务器发起请求,解析该URL中的域名对应的IP地址。
DNS服务器是基于UDP的,因此会用到UDP协议 -
建立TCP连接:解析出IP地址后,根据IP地址和默认80端口,和服务器建立TCP连接
-
发起HTTP请求:浏览器发起读取文件的HTTP请求,,该请求报文作为TCP三次握手的第三次数据发送给服务器
-
服务器响应请求并返回结果:服务器对浏览器请求做出响应,并把对应的html文件发送给浏览器
-
关闭TCP连接:通过四次挥手释放TCP连接
-
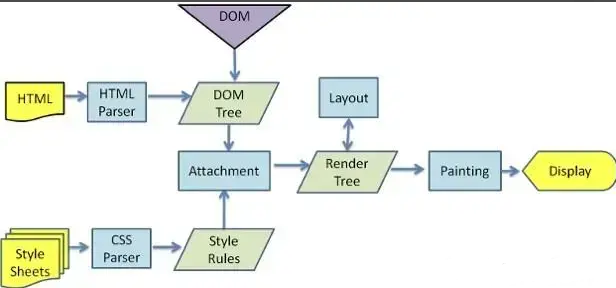
浏览器渲染:客户端(浏览器)解析HTML内容并渲染出来,浏览器接收到数据包后的解析流程为:
- 构建DOM树:词法分析然后解析成DOM树(dom tree),是由dom元素及属性节点组成,树的根是document对象
- 构建CSS规则树:生成CSS规则树(CSS Rule Tree)
- 构建render树:Web浏览器将DOM和CSS结合,并构建出渲染树(render tree)
- 布局(Layout):计算出每个节点在屏幕中的位置
- 绘制(Painting):即遍历render树,并使用UI后端层绘制每个节点。
-
JS引擎解析过程:调用JS引擎执行JS代码(JS的解释阶段,预处理阶段,执行阶段生成执行上下文,VO,作用域链、回收机制等等)
-
创建window对象:window对象也叫全局执行环境,当页面产生时就被创建,所有的全局变量和函数都属于window的属性和方法,而DOM Tree也会映射在window的doucment对象上。当关闭网页或者关闭浏览器时,全局执行环境会被销毁。
-
加载文件:完成js引擎分析它的语法与词法是否合法,如果合法进入预编译
-
预编译:在预编译的过程中,浏览器会寻找全局变量声明,把它作为window的属性加入到window对象中,并给变量赋值为'undefined';寻找全局函数声明,把它作为window的方法加入到window对象中,并将函数体赋值给他(匿名函数是不参与预编译的,因为它是变量)。而变量提升作为不合理的地方在ES6中已经解决了,函数提升还存在。
-
解释执行:执行到变量就赋值,如果变量没有被定义,也就没有被预编译直接赋值,在ES5非严格模式下这个变量会成为window的一个属性,也就是成为全局变量。string、int这样的值就是直接把值放在变量的存储空间里,object对象就是把指针指向变量的存储空间。函数执行,就将函数的环境推入一个环境的栈中,执行完成后再弹出,控制权交还给之前的环境。JS作用域其实就是这样的执行流机制实现的
-
2.22 http 缓存
-
概念
什么是缓存? 把一些不需要重新获取的内容再重新获取一次
为什么需要缓存? 网络请求相比于 CPU 的计算和页面渲染是非常非常慢的。
哪些资源可以被缓存? 静态资源,比如 js css img。
-
强制缓存
Cache-Control:
- 在 Response Headers 中。
- 控制强制缓存的逻辑。
- 例如 Cache-Control: max-age=3153600(单位是秒)
Cache-Control 有哪些值:
- max-age:缓存最大过期时间。
- no-cache:可以在客户端存储资源,每次都必须去服务端做新鲜度校验,来决定从服务端获取新的资源(200)还是使用客户端缓存(304)。
- no-store:永远都不要在客户端存储资源,永远都去原始服务器去获取资源。
-
协商缓存(对比缓存)
- 服务端缓存策略。
- 服务端判断客户端资源,是否和服务端资源一样。
- 一致则返回 304,否则返回 200 和最新的资源。

3. 为什么要用 setTimeout 模拟 setInterval
setInterval 是一个宏任务
使用 setInterval 的两个缺点:
- 某些间隔会被跳过
- 可能多个定时器会连续执行
每个 setTimeout 产生的任务会直接 push 到任务队列中;而 setInterval 在每次把任务 push 到任务队列前,都要进行一次判断(看上次的任务是否仍然在队列中,如果有则不添加,没有则添加)
用 setTimeout 模拟 setInterval
综上所述,在某些情况下,setInterval 缺点是很明显的,为了解决这些弊端,可以使用 setTimeout() 代替。
- 在前一个定时器执行完前,不会向队列插入新的定时器(解决缺点一)
- 保证定时器间隔(解决缺点二)
具体实现:
-
写一个
interval方法let timer = null; function interval(func, wait) { let interv = function() { func.call(null); timer = setTimeout(interv, wait); }; timer = setTimeout(interv, wait); } -
和
setInterval一样使用它interval(function() { console.log(count++) }, 1000); -
终止定时器
if (timer) { window.clearSetTimeout(timer); timer = null; }
4. HTML & CSS
4.1 重绘与重排
4.1.1 浏览器重绘与重排的区别
-
重排/回流(Reflow):当
DOM的变化影响了元素的几何信息,浏览器需要重新计算元素的几何属性,将其安放在界面中的正确位置,这个过程叫做重排。表现为重新生成布局,重新排列元素。 -
重绘(Repaint): 当一个元素的外观发生改变,但没有改变布局,重新把元素外观绘制出来的过程,叫做重绘。表现为某些元素的外观被改变
单单改变元素的外观,肯定不会引起网页重新生成布局,但当浏览器完成重排之后,将会重新绘制受到此次重排影响的部分
重排和重绘代价是高昂的,它们会破坏用户体验,并且让UI展示非常迟缓,而相比之下重排的性能影响更大,在两者无法避免的情况下,一般我们宁可选择代价更小的重绘。
『重绘』不一定会出现『重排』,『重排』必然会出现『重绘』
4.1.2 如何触发重排和重绘
任何改变用来构建渲染树的信息都会导致一次重排或重绘:
- 添加、删除、更新DOM节点
- 通过display: none隐藏一个DOM节点-触发重排和重绘
- 通过visibility: hidden隐藏一个DOM节点-只触发重绘,因为没有几何变化
- 移动或者给页面中的DOM节点添加动画
- 添加一个样式表,调整样式属性
- 用户行为,例如调整窗口大小,改变字号,或者滚动。
任何会改变元素几何信息(元素的位置和尺寸大小)的操作,都会触发重排,下面列一些栗子:
- 添加或者删除可见的DOM元素;
- 元素尺寸改变——边距、填充、边框、宽度和高度
- 内容变化,比如用户在input框中输入文字
- 浏览器窗口尺寸改变——resize事件发生时
- 计算 offsetWidth 和 offsetHeight 属性
- 设置 style 属性的值
| 常见引起重排属性和方法 | |||
|---|---|---|---|
| width | height | margin | padding |
| display | border | position | overflow |
| clientWidth | clientHeight | clientTop | clientLeft |
| offsetWidth | offsetHeight | offsetTop | offsetLeft |
| scrollWidth | scrollHeight | scrollTop | scrollLeft |
| scrollIntoView() | scrollTo() | getComputedStyle() | |
| getBoundingClientRect() | scrollIntoViewIfNeeded() |
重排影响的范围:
由于浏览器渲染界面是基于流失布局模型的,所以触发重排时会对周围DOM重新排列,影响的范围有两种:
- 全局范围:从根节点
html开始对整个渲染树进行重新布局。 - 局部范围:对渲染树的某部分或某一个渲染对象进行重新布局
当一个元素的外观发生改变,但没有改变布局,重新把元素外观绘制出来的过程,叫做重绘。
常见的引起重绘的属性:
| color | border-style | visibility | background |
| text-decoration | background-image | background-position | background-repeat |
| outline-color | outline | outline-style | border-radius |
| outline-width | box-shadow | background-size |
强制刷新队列的style样式请求:
- offsetTop, offsetLeft, offsetWidth, offsetHeight
- scrollTop, scrollLeft, scrollWidth, scrollHeight
- clientTop, clientLeft, clientWidth, clientHeight
- getComputedStyle(), 或者 IE的 currentStyle
我们在开发中,应该谨慎的使用这些style请求,注意上下文关系,避免一行代码一个重排,这对性能是个巨大的消耗
div.style.left = '10px';
console.log(div.offsetLeft);
div.style.top = '10px';
console.log(div.offsetTop);
div.style.width = '20px';
console.log(div.offsetWidth);
div.style.height = '20px';
console.log(div.offsetHeight);
这段代码会触发4次重排+重绘,因为在console中你请求的这几个样式信息,无论何时浏览器都会立即执行渲染队列的任务,即使该值与你操作中修改的值没关联。
因为队列中,可能会有影响到这些值的操作,为了给我们最精确的值,浏览器会立即重排+重绘。
4.1.3 如何避免重绘和重排
-
集中改变样式,不要一条一条地修改 DOM 的样式。
-
不要把 DOM 结点的属性值放在循环里当成循环里的变量。
-
为动画的 HTML 元件使用
fixed或absoult的position,那么修改他们的 CSS 是不会 reflow 的。 -
不使用 table 布局。因为可能很小的一个小改动会造成整个 table 的重新布局。
-
尽量只修改
position:absolute或fixed元素,对其他元素影响不大 -
动画开始
GPU加速,translate使用3D变化 -
提升为合成层
将元素提升为合成层有以下优点:
-
合成层的位图,会交由 GPU 合成,比 CPU 处理要快
-
当需要 repaint 时,只需要 repaint 本身,不会影响到其他的层
-
对于 transform 和 opacity 效果,不会触发 layout 和 paint
提升合成层的最好方式是使用 CSS 的 will-change 属性:
#target { will-change: transform; } -
will-change 为web开发者提供了一种告知浏览器该元素会有哪些变化的方法,这样浏览器可以在元素属性真正发生变化之前提前 做好对应的优化准备工作。 这种优化可以将一部分复杂的计算工作提前准备好,使页面的反应更为快速灵敏。
重绘和回流其实和 Event loop 有关。
- 当 Event loop 执行完 Microtasks 后,会判断 document 是否需要更新。因为浏览器是 60Hz 的刷新率,每 16ms 才会更新一次。
- 然后判断是否有
resize或者scroll,有的话会去触发事件,所以resize和scroll事件也是至少 16ms 才会触发一次,并且自带节流功能。 - 判断是否触发了 media query
- 更新动画并且发送事件
- 判断是否有全屏操作事件
- 执行
requestAnimationFrame回调 - 执行
IntersectionObserver回调,该方法用于判断元素是否可见,可以用于懒加载上,但是兼容性不好 - 更新界面
- 以上就是一帧中可能会做的事情。如果在一帧中有空闲时间,就会去执行
requestIdleCallback回调。
4.2 CSS 选择器和优先级
-
选择器
- id选择器(#myid)
- 类选择器(.myclass)
- 属性选择器(a[rel="external"])
- 伪类选择器(a:hover, li:nth-child)
- 标签选择器(div, h1,p)
- 相邻选择器(h1 + p)
- 子选择器(ul > li)
- 后代选择器(li a)
- 通配符选择器(*)
-
优先级
!important- 内联样式(1000)
- ID选择器(0100)
- 类选择器/属性选择器/伪类选择器(0010)
- 元素选择器/伪元素选择器(0001)
- 关系选择器/通配符选择器(0000)
带!important 标记的样式属性优先级最高; 样式表的来源相同时:!important > 行内样式>ID选择器 > 类选择器 > 标签 > 通配符 > 继承 > 浏览器默认属性
4.3 position 属性的值有哪些及其区别
- 固定定位 fixed: 元素的位置相对于浏览器窗口是固定位置,即使窗口是滚动的它也不会移动。Fixed 定 位使元素的位置与文档流无关,因此不占据空间。 Fixed 定位的元素和其他元素重叠。
- 相对定位 relative: 如果对一个元素进行相对定位,它将出现在它所在的位置上。然后,可以通过设置垂直或水平位置,让这个元素“相对于”它的起点进行移动。 在使用相对定位时,无论是否进行移动,元素仍然占据原来的空间。因此,移动元素会导致它覆盖其它框。
- 绝对定位 absolute: 绝对定位的元素的位置相对于最近的已定位父元素,如果元素没有已定位的父元素,那 么它的位置相对于。absolute 定位使元素的位置与文档流无关,因此不占据空间。 absolute 定位的元素和其他元素重叠。
- 粘性定位 sticky: 元素先按照普通文档流定位,然后相对于该元素在流中的 flow root(BFC)和 containing block(最近的块级祖先元素)定位。而后,元素定位表现为在跨越特定阈值前为相对定 位,之后为固定定位。
- 默认定位 Static: 默认值。没有定位,元素出现在正常的流中(忽略 top, bottom, left, right 或者 z-index 声 明)。
inherit: 规定应该从父元素继承 position 属性的值
4.4 CSS 盒子模型
CSS 盒模型本质上是一个盒子,它包括:边距,边框,填充和实际内容。CSS 中的盒子模型包括 IE 盒子模型和标准的 W3C 盒子模型。
在标准的盒子模型中,width 指 content 部分的宽, 即 box-sizing: conten-box,。
在 IE 盒子模型中,width 表示 content+padding+border 这三个部分的宽度, 即 box-sizing: border-box*。
故在计算盒子的宽度时存在差异:
标准盒模型: 一个块的总宽度 = width+margin(左右)+padding(左右)+border(左右)
怪异盒模型: 一个块的总宽度 = width+margin(左右)(既 width 已经包含了 padding 和 border 值)
4.5 BFC 块级格式上下文
4.5.1 BFC的概念
BFC 是 Block Formatting Context 的缩写,即块级格式化上下文。BFC是CSS布局的一个概念,是一个独立的渲染区域,规定了内部box如何布局, 并且这个区域的子元素不会影响到外面的元素,其中比较重要的布局规则有内部 box 垂直放置,计算 BFC 的高度的时候,浮动元素也参与计算。
-
BFC是一个独立的布局环境,其中的元素布局是不受外界的影响,并且在一个BFC中,块盒与行盒(行盒由一行中所有的内联元素所组成)都会垂直的沿着其父元素的边框排列。
-
可以把 BFC 理解为一个封闭的大箱子,箱子内部的元素无论如何翻江倒海,都不会影响到外部。
-
浮动元素和绝对定位元素,非块级盒子的块级容器(例如
inline-blocks table-cells和table-captions),以及overflow值不为visiable的块级盒子,都会为他们的内容创建BFC(块级格式化上下文)。
4.5.2 BFC的原理布局规则
- 内部的Box会在 垂直方向,一个接一个地放置
- Box 垂直方向的距离由margin决定。属于同一个BFC的两个相邻Box的margin会发生重叠
- 每个元素的margin box的左边, 与包含块border box的左边相接触(对于从左往右的格式化,否则相反
- BFC的区域 不会与float box重叠
- BFC是一个独立容器,容器里面的 子元素不会影响到外面的元素
- 计算BFC的高度时,浮动元素也参与计算高度
- 元素的类型和 display属性,决定了这个Box的类型。不同类型的Box会参与不同的
Formatting Context。
4.5.3 如何创建BFC?
- 根元素,即HTML元素
- float的值不为none
- position为absolute或fixed
- display的值为inline-block、table-cell、table-caption
- overflow的值不为visible
4.5.4 BFC的使用场景
- 去除边距重叠现象 外边距折叠
- 清除浮动(让父元素的高度包含子浮动元素)
- 避免某元素被浮动元素覆盖
- 避免多列布局由于宽度计算四舍五入而自动换行
4.6 让一个元素水平垂直居中
-
水平居中
-
对于 行内元素 :
text-align: center,设置父元素; -
对于确定宽度的块级元素:
(1)width和margin实现。
margin: 0 auto;(2)绝对定位和
margin-left: (父width - 子width)/2, 前提是父元素position: relative -
对于宽度未知的块级元素
(1)table标签配合margin左右auto实现水平居中。使用table标签(或直接将块级元素设值为
display:table),再通过给该标签添加左右margin为auto<div class="table">使用 table 标签配合 margin 左右 auto 实现水平居中</div>div { height: 200px; background: #ccc; } .table { display: table; margin: 0 auto; }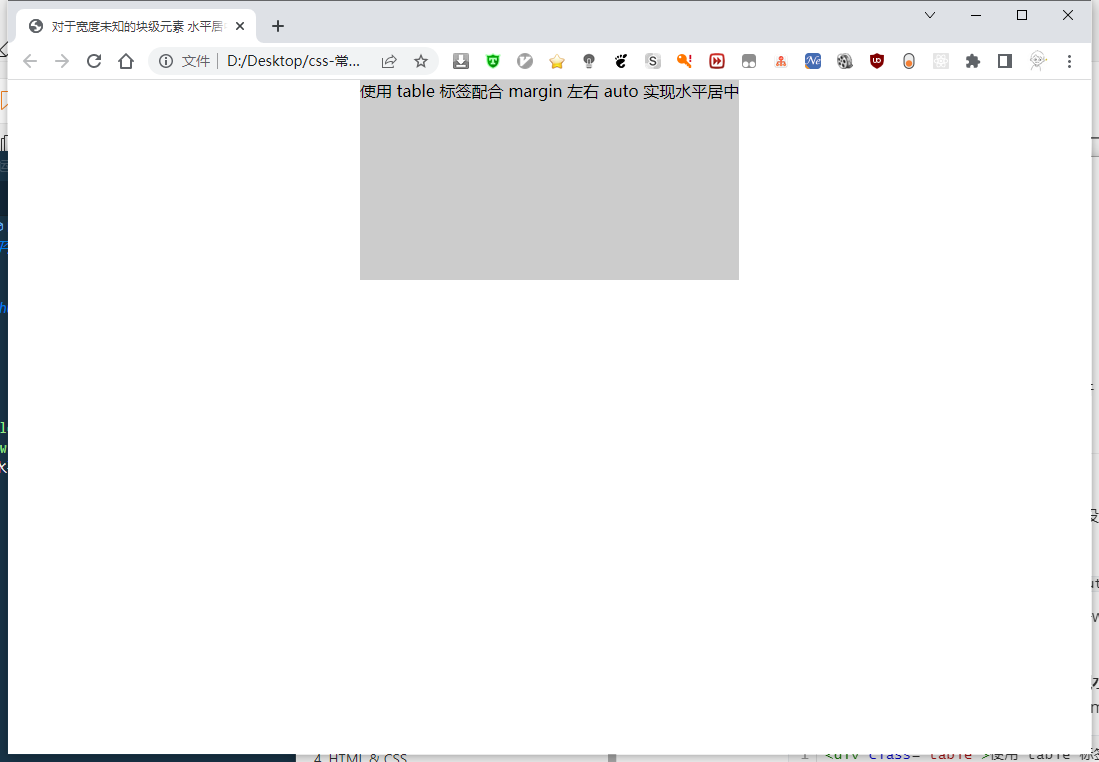
(2)
inline-block实现水平居中方法。display:inline-block和text-align:center(设置父元素) 实现水平居中。<div class="inline-block-parent"> <div class="inline-block"> 使用display:inline-block 和 text-align:center 实现水平居中 </div> </div>.inline-block-parent { text-align: center; } .inline-block { display: inline-block; background-color: rebeccapurple; }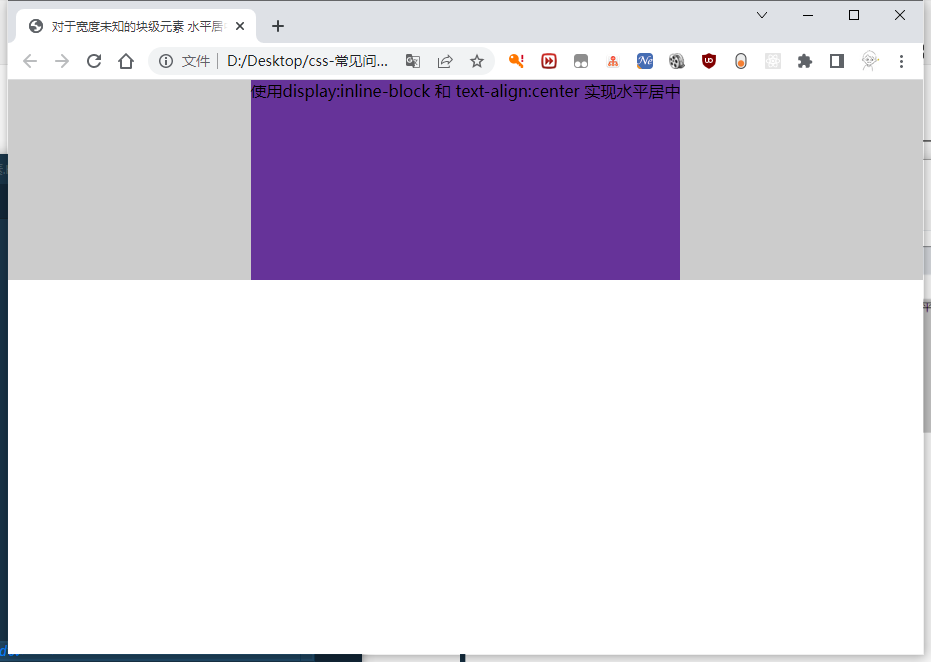
(3)绝对定位+transform,translateX可以移动本身元素的50%。
<div class="absolute">使用绝对定位+transformX</div>.absolute { position: absolute; left: 50%; transform: translateX(-50%); background-color: red; }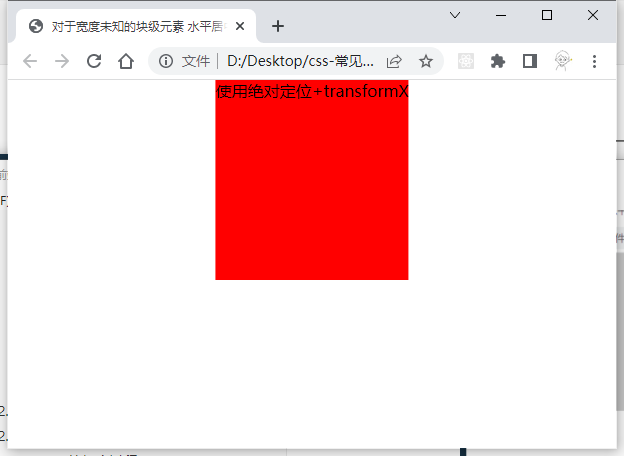
同理这里可以设置垂直方向的 transformY(-50%) 可以实现垂直居中
(4)flex布局使用
justify-content:center
-
-
垂直居中
-
利用
line-height实现居中,这种方法适合纯文字类<!-- css 样式 --> <style rel="stylesheet" type="text/css"> .text{ width: 200px; height: 200px; text-align: center; line-height: 200px; background: skyblue; } </style> <!-- html 结构 --> <div class="text">文本垂直居中</div>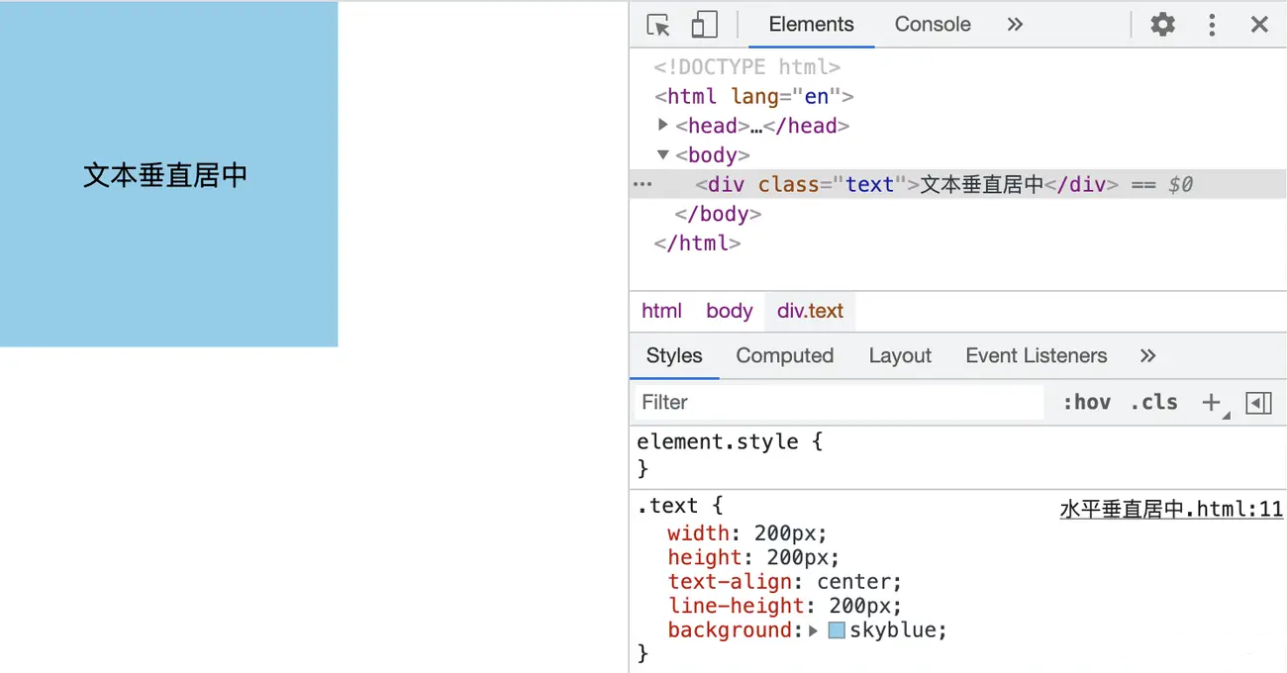
-
通过设置父容器 相对定位 ,子级设置 绝对定位,标签通过margin实现自适应居中
<!-- css 样式 --> <style rel="stylesheet" type="text/css"> /* 绝对性定位 */ .div { width:200px; height:200px; position:absolute; top:0; right:0; bottom:0; left:0; margin: auto; background: skyblue; } </style> <!-- html 结构 --> <div class="div">margin: auto;元素垂直居中</div>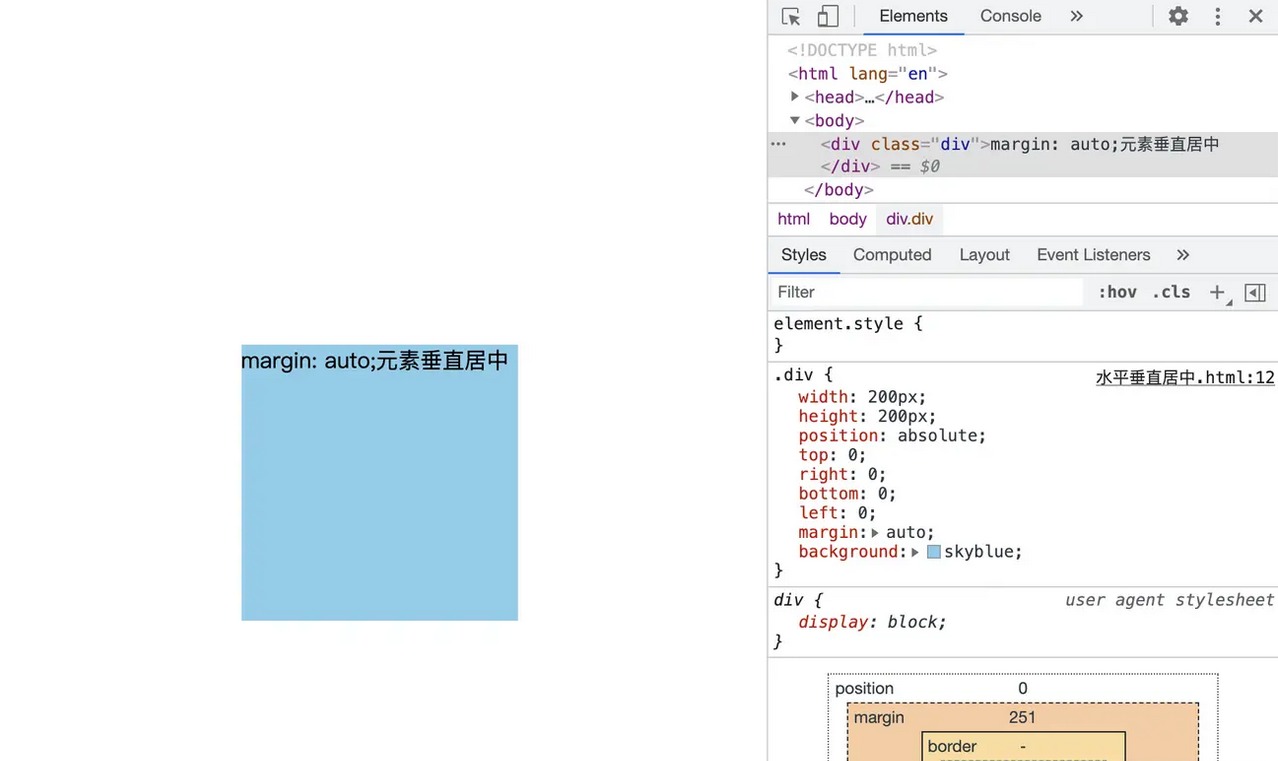
-
弹性布局 flex 父级设置display: flex; 子级设置margin为auto实现自适应居中
使用Flex布局,利用
align-items: center;与justify-content: center;属性,对未知宽高的盒子进行自动偏移定位,父元素需要设置高度📌<!-- css 样式 --> <style rel="stylesheet" type="text/css"> /* 利用 flex 布局 不需要盒子本身宽高 但需要父级盒子高度*/ .container { display: flex; align-items: center;/* 垂直居中 */ justify-content: center; /* 水平居中 */ height:100vh; /* 父元素高度需设置 */ } .container div { width: 200px; /* 宽高可以不设置 */ height: 200px; background-color: greenyellow; } </style> <!-- html 结构 --> <div class="container"> <div>利用 flex 布局进行水平垂直居中</div> </div>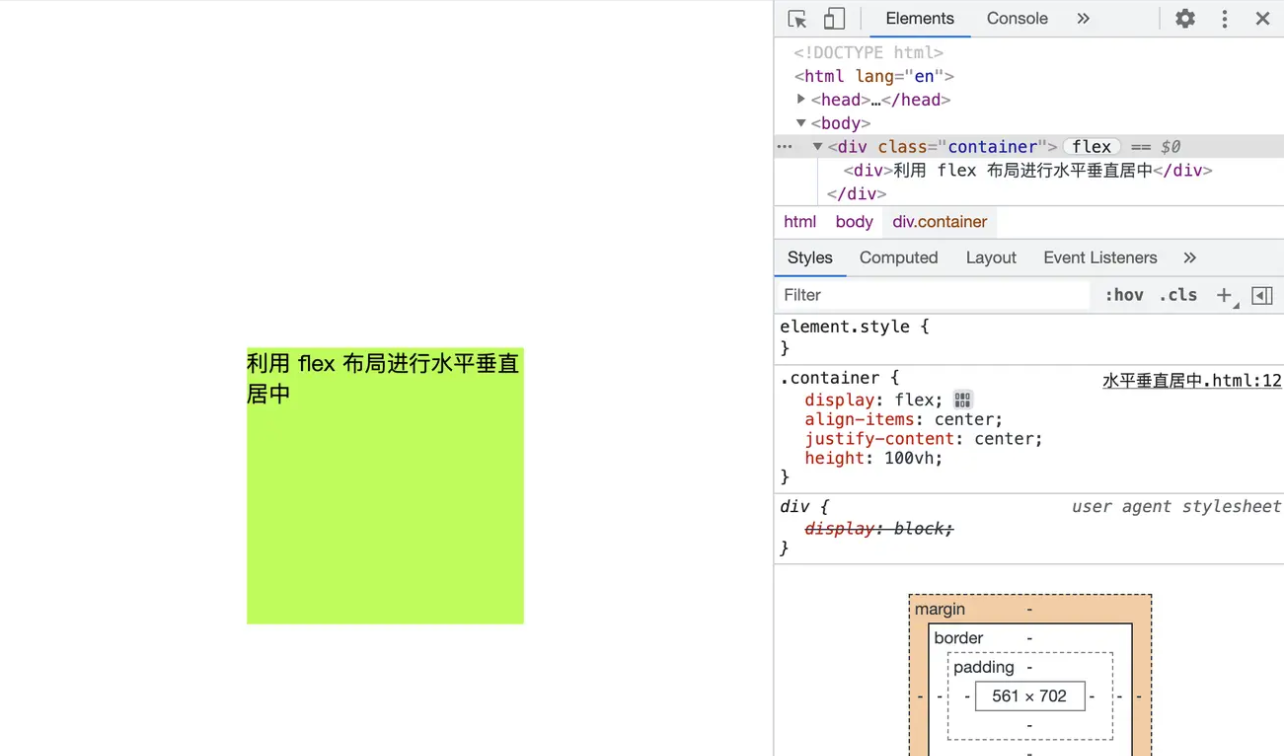
-
父级设置相对定位,子级设置绝对定位,并且通过位移 transform 实现
<!-- css 样式 --> <style rel="stylesheet" type="text/css"> .div { position: absolute; /* 相对定位或绝对定位均可 */ width:200px; height:200px; top: 50%; left: 50%; transform: translate(-50%,-50%); background-color: pink; } </style> <!-- html 结构 --> <div class="div">利用 transform 进行垂直居中</div>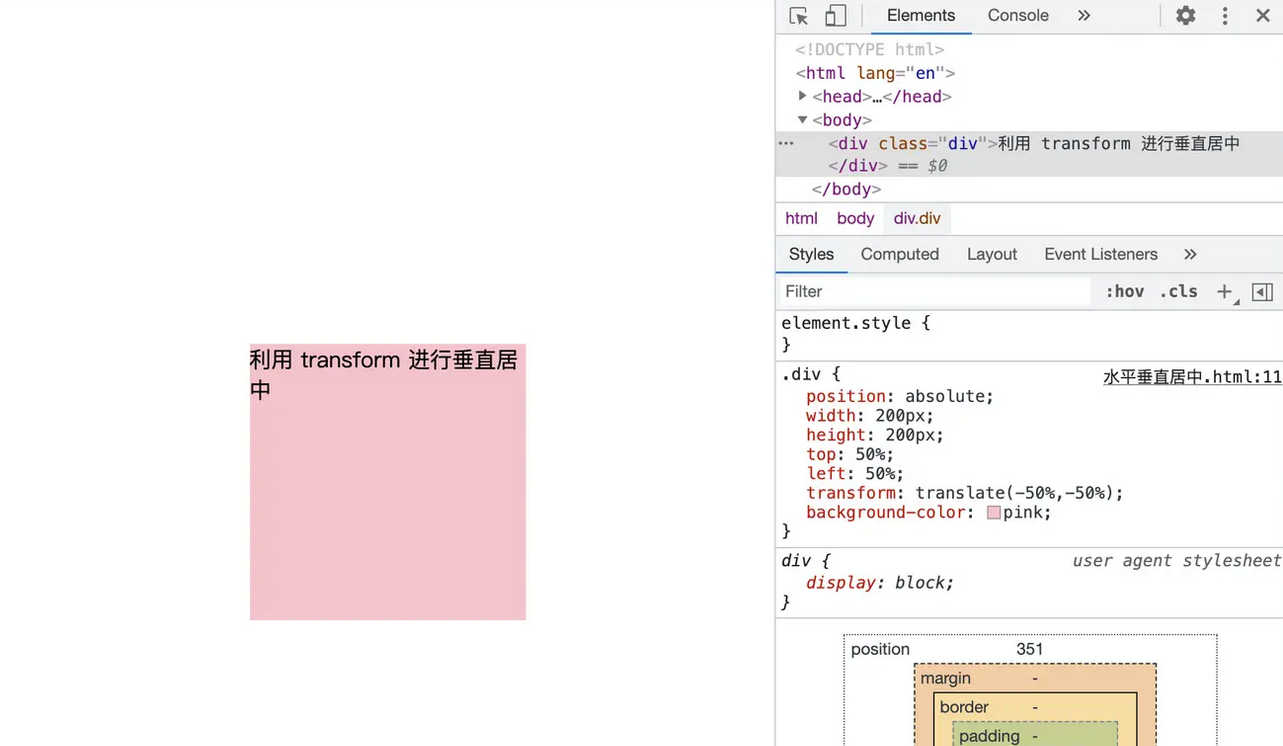
-
table 布局,父级通过转换成表格形式,然后子级设置 vertical-align 实现。(需要注意的是:vertical-align: middle使用的前提条件是内联元素以及display值为table-cell的元素)。
-
4.7 页面布局
4.7.1 Flex 布局
布局的传统解决方案,基于盒状模型,依赖 display 属性 + position 属性 + float 属性。它对于那些特殊布局非常不方便,比如,垂直居中就不容易实现。
Flex 是 Flexible Box 的缩写,意为"弹性布局",用来为盒状模型提供最大的灵活性。指定容器 display: flex 即可。 简单的分为容器属性和元素属性。
容器的属性:
- flex-direction:决定主轴的方向(即子 item 的排列方法)flex-direction: row | row-reverse | column | column-reverse;
- flex-wrap:决定换行规则 flex-wrap: nowrap | wrap | wrap-reverse;
- flex-flow:(flex-direction||flex-wrap) 是 flex-direction 和 flex-wrap 的简写
- justify-content:对其方式,水平主轴对齐方式
- align-items:对齐方式,竖直轴线方向
- align-content 设置了浏览器如何沿着 弹性盒子布局 的纵轴和 网格布局 的主轴在内容项之间和周围分配空间。
项目的属性(元素的属性):
- order 属性:定义项目的排列顺序,顺序越小,排列越靠前,默认为 0
- flex-grow 属性:定义项目的放大比例,即使存在空间,也不会放大
- flex-shrink 属性:定义了项目的缩小比例,当空间不足的情况下会等比例的缩小,如果 定义个 item 的 flow-shrink 为 0,则为不缩小
- flex-basis 属性:定义了在分配多余的空间,项目占据的空间。
- flex:是 flex-grow 和 flex-shrink、flex-basis 的简写,默认值为 0 1 auto。
- align-self:允许单个项目与其他项目不一样的对齐方式,可以覆盖
- align-items,默认属 性为 auto,表示继承父元素的 align-items 比如说,用 flex 实现圣杯布局
4.7.2 Rem 布局
首先 Rem 相对于根(html)的 font-size 大小来计算。简单的说它就是一个相对单例 如:font-size:10px;,那么(1rem = 10px)了解计算原理后首先解决怎么在不同设备上设置 html 的 font-size 大小。其实 rem 布局的本质是等比缩放,一般是基于宽度。
优点:可以快速适用移动端布局,字体,图片高度
缺点:
① 目前 ie 不支持,对 pc 页面来讲使用次数不多;
② 数据量大:所有的图片,盒子都需要我们去给一个准确的值;才能保证不同机型的适配;
③ 在响应式布局中,必须通过 js 来动态控制根元素 font-size 的大小。也就是说 css 样式和 js 代码有一定的耦合性。且必须将改变 font-size 的代码放在 css 样式之前。
4.7.3 百分比布局
通过百分比单位 " % " 来实现响应式的效果。通过百分比单位可以使得浏览器中的组件的宽和高随着浏览器的变化而变化,从而实现响应式的效果。 直观的理解,我们可能会认为子元素的百分比完全相对于直接父元素,height 百分比相 对于 height,width 百分比相对于 width。 padding、border、margin 等等不论是垂直方向还是水平方向,都相对于直接父元素的 width。 除了 border-radius 外,还有比如 translate、background-size 等都是相对于自身的。
缺点:
(1)计算困难
(2)各个属性中如果使用百分比,相对父元素的属性并不是唯一的。造成我们使用百分比单位容易使布局问题变得复杂。
4.7.4 浮动布局
浮动布局:当元素浮动以后可以向左或向右移动,直到它的外边缘碰到包含它的框或者另外一个浮动元素的边框为止。元素浮动以后会脱离正常的文档流,所以文档的普通流中的框就变的好像浮动元素不存在一样。
优点
这样做的优点就是在图文混排的时候可以很好的使文字环绕在图片周围。另外当元素浮动了起来之后,它有着块级元素的一些性质例如可以设置宽高等,但它与inline-block还是有一些区别的,第一个就是关于横向排序的时候,float可以设置方向而inline-block方向是固定的;还有一个就是inline-block在使用时有时会有空白间隙的问题
缺点
最明显的缺点就是浮动元素一旦脱离了文档流,就无法撑起父元素,会造成父级元素高度塌陷。
4.8 浏览器中的事件循环 Event Loop
事件环的运行机制是,先会执行栈中的内容,栈中的内容执行后执行微任务,微任务清空后再执行宏任务,先取出一个宏任务,再去执行微任务,然后在取宏任务清微任务这样不停的循环。
-
eventLoop 是由JS的宿主环境(浏览器)来实现的;
-
事件循环可以简单的描述为以下四个步骤:
- 函数入栈,当Stack中执行到异步任务的时候,就将他丢给WebAPIs,接着执行同步任务,直到Stack为空;
- 此期间WebAPIs完成这个事件,把回调函数放入队列中等待执行(微任务放到微任务队列,宏任务放到宏任务队列)
- 执行栈为空时,Event Loop把微任务队列执行清空;
- 微任务队列清空后,进入宏任务队列,取队列的第一项任务放入Stack(栈)中执行,执行完成后,查看微任务队列是否有任务,有的话,清空微任务队列。重复4,继续从宏任务中取任务执行,执行完成之后,继续清空微任务,如此反复循环,直至清空所有的任务
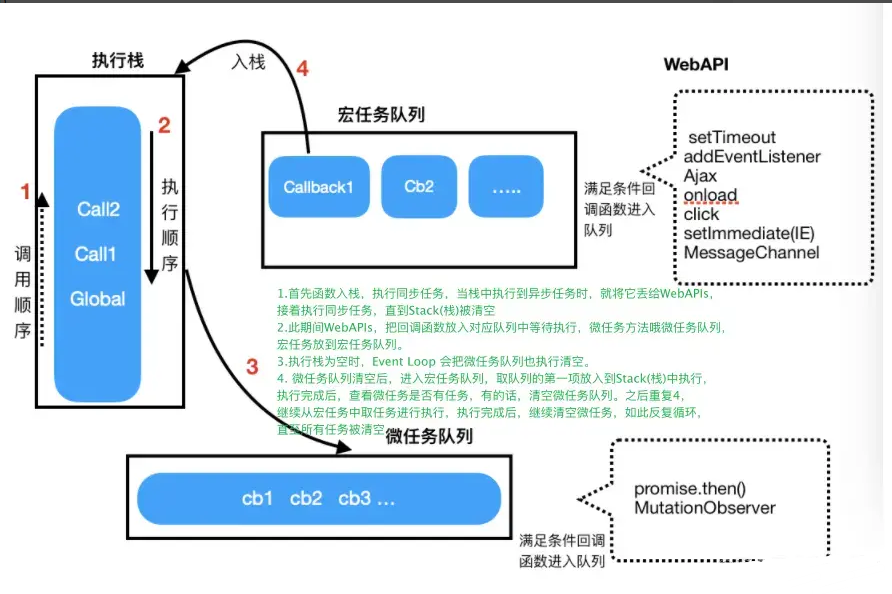
浏览器中的任务源(task):
宏任务(macrotask):
宿主环境提供的,比如浏览器
ajax、setTimeout、setInterval、setTmmediate(只兼容ie)、script、requestAnimationFrame、messageChannel、UI渲染、一些浏览器api微任务(microtask):
语言本身提供的,比如promise.then、queueMicrotask(基于then)、mutationObserver(浏览器提供)、
4.9 CSS 的负 margin
与设置正值不同,margin 设置负值需要根据设置的方向以及元素是否浮动以及其定位方式来判断最终的行为。
-
第一种情况:元素没有设置浮动且没有设置定位或者
position为static如果元素没有设置浮动并且没有设置定位或者
position属性为static的情况下,对元素的 margin 设置负值会有以下的效果:-
设置的 margin 的方向为 top 或者 left
当设置负值的 margin 的方向为 top 或者 left 的时候,元素会按照设置的方向移动相应的距离。
比如,设置
margin-left: -100px;。 那么,元素会往左移动 100px。对于设置margin-top也是一样的道理。 -
设置的 margin 的方向为 bottom 或者 right
当设置负值的 margin 的方向为 bottom 或者 right 的时候,元素本身并不会移动,元素后面的其他元素会往该元素的方向移动相应的距离,并且覆盖在该元素上面。
比如,设置
margin-right: -100px;。那么,元素本身并不会移动,后面的元素会向左移动 100px 到该元素上。对于设置margin-bottom也是同样的道理。同时,在元素不指定宽度的情况下,如果设置
margin-left或者margin-right为负值的话,会在元素对应的方向上增加其宽度。效果就和设置padding-left或者padding-right一样。
-
-
第二种情况:元素没有设置浮动且
position为relative如果元素没有设置浮动,但是设置了相对定位,设置 margin 为负值的时候,表现如下:
-
设置的 margin 的方向为 top 或者 left
当设置负值的 margin 的方向为 top 或者 left 的时候,元素也会按照设置的方向移动相应的距离。
-
设置的 margin 的方向为 bottom 或者 right
当设置
margin-bottom/left的时候,元素本身也不会移动,元素后面的其他元素也会往该元素的方向移动相应的距离,但是,该元素会覆盖在后面的元素上面 (当然,此处说的情况肯定是后面的元素没有设置定位以及z-index的情况)。
-
-
第三种情况:元素没有设置浮动且
position为absolute如果元素没有设置浮动,但是设置了绝对定位,设置 margin 为负值的时候,表现如下:
-
设置的 margin 的方向为 top 或者 left
当设置负值的 margin 的方向为 top 或者 left 的时候,元素也会按照设置的方向移动相应的距离。
-
设置的 margin 的方向为 bottom 或者 right
由于设置绝对定位的元素已经脱离了标准文档流,所以,设置
margin-right/bottom对后面的元素并没有影响。
-
-
第四种情况:元素设置了浮动
肯定没有既设置了浮动又设置绝对定位的情况,那样太荒唐了。
设置了浮动的元素,再设置postion: relative;的话,元素的行为和单独设置float是一样的。对于设置了浮动的元素,设置 margin 为负值的时候,表现如下:
如果设置的 margin 的方向与浮动的方向相同,那么,元素会往对应的方向移动对应的距离。
比如:
.elem { float: right; margin-right: -100px; }该元素则会向右移动 100px。
如果设置 margin 的方向与浮动的方向相反,则元素本身不动,元素之前或者之后的元素会向该元素的方向移动相应的距离。
比如:
.elem { float: right; margin-left: -100px; }位于该元素左边的元素则会向右移动 100px,同时覆盖在该元素上。
如果后面的元素也设置了浮动的话,我们以一个具体的例子来说明。
<div class="container"> <div class="left"></div> <div class="right"></div> </div>.container { min-height: 300px; margin: 30px auto; overflow: hidden; border: 1px solid #000000; .left { float: left; width: 400px; height: 200px; margin-right: -300px; background: purple; } .right { float: left; width: 300px; height: 200px; background: #cccccc; } }.left和.right都设置了浮动,在.left上设置了margin-right: -300px;,那么,.right会向左移动 300px,从而覆盖在.left上。这种行为与没有既没有设置浮动也没有设置定位的表现类似。
4.10 如何理解 HTML 语义化
- 让人更容易读懂(增加代码可读性)。
- 让搜索引擎更容易读懂,有助于爬虫抓取更多的有效信息,爬虫依赖于标签来确定上下文和各个关键字的权重(SEO)。
- 在没有 CSS 样式下,页面也能呈现出很好地内容结构、代码结构。
4.11 script 标签中 defer 和 async 的区别
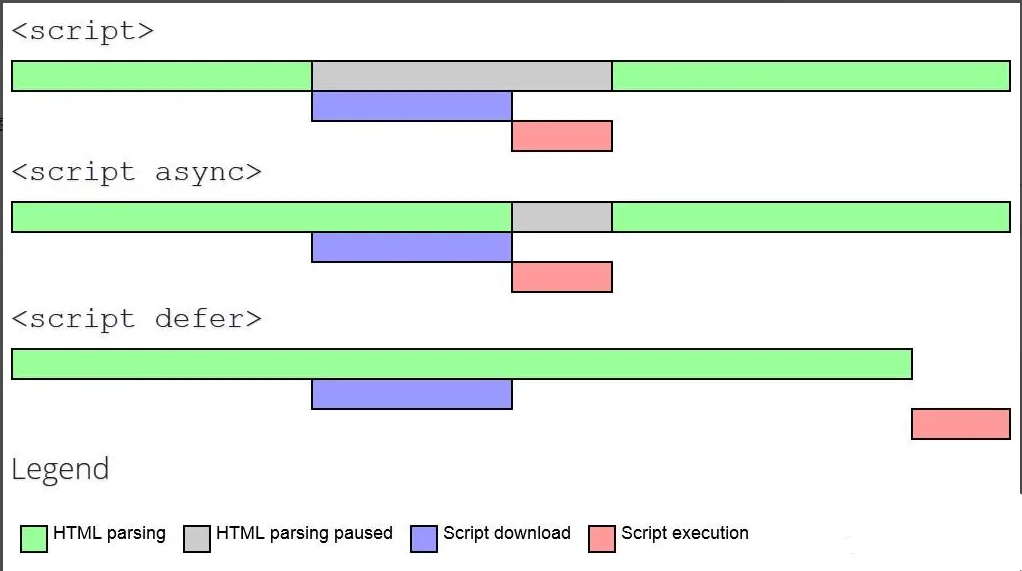
script:会阻碍 HTML 解析,只有下载好并执行完脚本才会继续解析 HTML。async script:解析 HTML 过程中进行脚本的异步下载,下载成功立马执行,有可能会阻断 HTML 的解析。defer script:完全不会阻碍 HTML 的解析,解析完成之后再按照顺序执行脚本。
下图清晰地展示了三种 script 的过程:
4.12 渲染机制
浏览器的渲染机制一般分为以下几个步骤
- 处理 HTML 并构建 DOM 树。
- 处理 CSS 构建 CSSOM 树。
- 将 DOM 与 CSSOM 合并成一个渲染树。
- 根据渲染树来布局,计算每个节点的位置。
- 调用 GPU 绘制,合成图层,显示在屏幕上。

在构建 CSSOM 树时,会阻塞渲染,直至 CSSOM 树构建完成。并且构建 CSSOM 树是一个十分消耗性能的过程,所以应该尽量保证层级扁平,减少过度层叠,越是具体的 CSS 选择器,执行速度越慢。
当 HTML 解析到 script 标签时,会暂停构建 DOM,完成后才会从暂停的地方重新开始。也就是说,如果你想首屏渲染的越快,就越不应该在首屏就加载 JS 文件。并且 CSS 也会影响 JS 的执行,只有当解析完样式表才会执行 JS,所以也可以认为这种情况下,CSS 也会暂停构建 DOM。
Load 和 DOMContentLoaded 区别
-
Load 事件触发代表页面中的 DOM,CSS,JS,图片已经全部加载完毕。
-
DOMContentLoaded 事件触发代表初始的 HTML 被完全加载和解析,不需要等待 CSS,JS,图片加载
图层
一般来说,可以把普通文档流看成一个图层。特定的属性可以生成一个新的图层。不同的图层渲染互不影响,所以对于某些频繁需要渲染的建议单独生成一个新图层,提高性能。但也不能生成过多的图层,会引起反作用。
通过以下几个常用属性可以生成新图层
- 3D 变换:
translate3d、translateZ will-changevideo、iframe标签- 通过动画实现的
opacity动画转换 position: fixed
5. 前端安全问题
5.1 sql 注入攻击
SQL注⼊是⼀种⾮常常⻅的数据库攻击⼿段,也是⽹络世界中最普遍的漏洞之⼀,它其实就是⿊客在表单中填写包含 SQL 关键字的数据,表单数据提交给服务器时让数据库执⾏恶意 SQL 的过程。例如 ' OR '1'='1 ',当我们输如⽤户名 admin ,然后密码输如 ' OR '1'=1='1 的时候,我们在查询⽤户名和密码是否正确的时候,本来要执⾏的是 SELECT * FROM user WHEREusername='' and password='' ,经过参数拼接后,会执⾏ SQL语句 SELECT * FROM userWHERE username='' and password='' OR '1'='1' ,这个时候1=1是成⽴,⾃然就跳过验证了。
就是通过把SQL命令插入到Web表单递交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的SQL命令。
总的来说有以下几点:
- 永远不要信任用户的输入,要对用户的输入进行校验,可以通过正则表达式,或限制长度,对单引号和双"-"进行转换等。
- 永远不要使用动态拼装SQL,可以使用参数化的SQL或者直接使用存储过程进行数据查询存取。
- 永远不要使用管理员权限的数据库连接,为每个应用使用单独的权限有限的数据库连接。
- 不要把机密信息明文存放,请加密或者hash掉密码和敏感的信息。
5.2 XSS 原理及防范
Xss(cross-site scripting) 跨网站指令码 攻击指的是攻击者往Web页面里插入恶意html标签或者javascript代码。比如:攻击者在论坛中放一个看似安全的链接,骗取用户点击后,窃取cookie中的用户私密信息;或者攻击者在论坛中加一个恶意表单,当用户提交表单的时候,却把信息传送到攻击者的服务器中,而不是用户原本以为的信任站点。
XSS 分为三种:反射型,存储型和 DOM-based
5.2.1 XSS防范方法
-
转义输入输出的内容 代码里对用户输入的地方和变量都需要仔细检查长度和对
”<”,”>”,”;”,”’”等字符做过滤;其次任何内容写到页面之前都必须加以encode,避免不小心把html tag弄出来。这一个层面做好,至少可以堵住超过一半的XSS攻击。 -
避免直接在
cookie中泄露用户隐私,例如email、密码等等。 -
通过使cookie 和系统ip 绑定来降低
cookie泄露后的危险。这样攻击者得到的cookie 没有实际价值,不可能拿来重放。 -
尽量采用POST 而非GET 提交表单
5.2.2 XSS与CSRF有什么区别吗?
XSS是获取信息,不需要提前知道其他用户页面的代码和数据包。CSRF是代替用户完成指定的动作,需要知道其他用户页面的代码和数据包。
要完成一次CSRF攻击,受害者必须依次完成两个步骤:
-
登录受信任网站A,并在本地生成Cookie。
-
在不登出A的情况下,访问危险网站B。
5.3 CSRF
CSRF(Cross-site request forgery)跨站请求伪造,是指攻击者诱导受害者进⼊第三⽅⽹站,在第三⽅⽹站中,向被攻击⽹站发送跨站请求。利⽤受害者在被攻击⽹站已经获取的注册凭证,绕过后台的⽤户验证,达到冒充⽤户对被攻击的⽹站执⾏某项操作的⽬的
简单点说,CSRF 就是利用用户的登录态发起恶意请求。
几种 常见的 CSRF 攻击
- ⾃动发起 GET 请求的 CSRF
- ⾃动发起 POST 请求的 CSRF
- 引诱⽤户点击链接的 CSRF
防护方法
- 利⽤ Cookie 的 SameSite 属性
- Get 请求不对数据进行修改
- 利用同源策略
- Token 验证
5.4 DDos 攻击
Dos 拒绝服务攻击(Denial of Service attack)是⼀种能够让服务器呈现静⽌状态的攻击⽅式。其原理就是发送⼤量的合法请求到服务器,服务器⽆法分辨这些请求是正常请求还是攻击请求,所以会照单全收。海量的请求造成服务器进⼊停⽌⼯作或拒绝服务的状态。
DDoS:分布式拒绝服务攻击(Distributed Denial of Service), DDos攻击是在 DOS 攻击基础上的,可以通俗理解, dos 是单挑,⽽ ddos 是群殴,因为现代技术的发展, dos攻击的杀伤⼒降低,所以出现了DDOS,攻击者借助公共⽹络,将⼤数量的计算机设备联合起来,向⼀个或多个⽬标进⾏攻击。
防御方法
为了防御 DDoS 攻击,阿⾥巴巴的安全团队在实战中发现,需要做的就是检测技术和清洗技术,检测
技术就是检测⽹站是否正在遭受 DDoS 攻击,⽽清洗技术就是清洗掉异常流量。
5.5 DNS 查询攻击
DNS 查询攻击就是攻击者通过精⼼构造 DNS报⽂ ,在 DNS 查询解析某个域名时,冒充真正的权威DNS 做出回应,使得⽤户访问得到⼀个虚假响应。⼀旦本地接受了这个虚假响应并写⼊缓存, DNS就会被攻击,⽤户也不清楚⾃⼰正在访问错误的地址或数据
关于防御的话,就是限制DNS解析器仅响应来⾃可信源的查询或者关闭DNS服务器的递归查询等
7. 正则表达式
**正则表达式是匹配模式,要么匹配字符,要么匹配位置 **
7.1 正则表达式字符匹配
7.1.1 两种模糊匹配
如果正则只有精确匹配是没多大意义的,比如 /hello/,也只能匹配字符串中的 "hello" 这个子串
var regex = /hello/;
console.log( regex.test("hello") );
// => true
正则表达式之所以强大,是因为其能实现模糊匹配。
而模糊匹配,有两个方向上的“模糊”:横向模糊和纵向模糊
7.1.1.1 横向模糊匹配
横向模糊指的是,一个正则可匹配得字符串的长度是不固定的,可以是多种情况。
其实现的方式是使用量词。例如 {m,n} ,表示连续出现最少 m 次,最多 n 次。
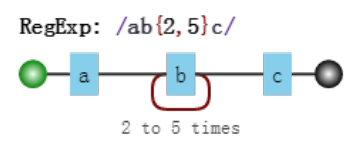
比如正则 /ab{2,5}c/ 表示匹配这样一个字符串:第一个字符串是 “a” ,接下来是 2 到 5 个 “b”,最后是 “c”。
其可视化如下:
测试如下:
var regex = /ab{2,5}c/g;
var string = "abc abbc abbbc abbbbc abbbbbc abbbbbbc";
console.log( string.match(regex) );
// => ["abbc", "abbbc", "abbbbc", "abbbbbc"]
上面正则表达式末尾的修饰符 g 表示全局匹配
7.1.1.2 纵向模糊匹配
纵向模糊指的是,一个正则匹配的字符串,具体到某一位字符时,它可以不是某个确定的字符,可以有多种
可能 。
其实现的方式是使用字符组。譬如 [abc],表示该字符是可以字符 "a"、"b"、"c" 中的任何一个。
比如 /a[123]b/ 可以匹配如下三种字符串: "a1b"、"a2b"、"a3b"
其可视化形式如下 :
![/a[123]b/ 可视化](https://s2.loli.net/2022/03/28/tqs4c5wgBkpFE81.png)
var regex = /a[123]b/g;
var string = "a0b a1b a2b a3b a4b";
console.log( string.match(regex) );
// => ["a1b", "a2b", "a3b"]
7.1.2 字符组
需要强调的是,虽叫字符组(字符类),但只是其中一个字符
例如 [abc],表示匹配一个字符,它可以是 "a"、"b"、"c" 之一。
7.1.2.1 范围表示法
如果字符组里的字符特别多的话,怎么办?可以使用范围表示法。
比如 [123456abcdefGHIJKLM],可以写成 [1-6a-fG-M]。用连字符 - 来省略和简写。
因为连字符有特殊用途,那么要匹配 "a"、"-"、"z" 这三者中任意一个字符,该怎么做呢?
不能写成 [a-z],因为其表示小写字符中的任何一个字符。
可以写成如下的方式:[-az] 或 [az-] 或 [a-z]。
即要么放在开头,要么放在结尾,要么转义。总之不会让引擎认为是范围表示法就行了。
7.1.2.2 排除字符组
纵向模糊匹配,还有一种情形就是,某位字符可以是任何东西,但就不能是 "a"、"b"、"c"。
此时就是排除字符组(反义字符组)的概念。例如 [^abc],表示是一个除 "a"、"b"、"c"之外的任意一个字符。字符组的第一位放 ^(脱字符),表示求反的概念。
当然,也有相应的范围表示法。
7.1.2.3 常见的简写形式
有了字符组的概念后,一些常见的符号我们也就理解了。因为它们都是系统自带的简写形式
| 字符组 | 具体含义 |
|---|---|
| \d | 表示 [0-9] ,表示是一位数字 |
| \D | 表示 [^0-9],表示除数字外的任意字符 |
| \w | [0-9a-zA-Z_] 表示数字、大小写字母和下划线 |
| \W | 表示 [^0-9a-zA-Z_] 非单词字符 |
| \s | 表示 [ \t\v\n\r\f] 表示空白符,包括空格、水平制表符、垂直制表符、换行符、回车符 |
| \S | 表示 [^ \t\v\n\r\f] 非空白符 |
| . | 表示 [^\n\r\u2028\u2089] 通配符,表示任意字符,换行符、回车符、行分隔符和段分隔符除外 |
匹配任意字符: [\d\D] [\w\W] [\s\S] [^] 中的任何一个
7.1.3 量词
量词也称重复。掌握 {m,n} 的准确含义后,只需要记住一些简写形式
7.1.3.1 简写形式
| 量词 | 具体含义 |
|---|---|
| 表示至少出现 m 次 | |
| 等价于 {m, m} ,表示出现 m 次 | |
| ? | 等价与 |
| + | |
| * |
7.1.3.2 贪婪匹配与惰性匹配
看如下例子:
var regex = /\d{2,5}/g;
var string = "123 1234 12345 123456";
console.log( string.match(regex) );
// => ["123", "1234", "12345", "12345"]
其中正则 /\d{2,5}/,表示数字连续出现 2 到 5 次。会匹配 2 位、3 位、4 位、5 位连续数字。
但是其是贪婪的,它会尽可能多的匹配。你能给我 6 个,我就要 5 个。你能给我 3 个,我就要 3 个。反正只要在能力范围内,越多越好。
我们知道有时贪婪不是一件好事(请看文章最后一个例子)。而惰性匹配,就是尽可能少的匹配:
var regex = /\d{2,5}?/g;
var string = "123 1234 12345 123456";
console.log( string.match(regex) );
// => ["12", "12", "34", "12", "34", "12", "34", "56"]
其中 /\d{2,5}?/ 表示,虽然 2 到 5 次都行,当 2 个就够的时候,就不再往下尝试了
通过在量词后面加个问号就能实现惰性匹配,因此所有惰性匹配情形如下:
| 惰性量词 | 贪婪量词 |
|---|---|
| {m, n}? | |
| {m, }? | |
| ?? | ? |
| +? | + |
| *? | * |
对惰性匹配的记忆方式是:量词后面加个问号
7.1.4 多选分支
一个模式可以实现横向和纵向模糊匹配。而多选分支可以支持多个子模式任选其一。
具体形式如下:(p1|p2|p3),其中 p1、p2 和 p3 是子模式,用 |(管道符)分隔,表示其中任何之一
例如要匹配字符串 "good" 和 "nice" 可以使用 /good|nice/。
var regex = /good|nice/g;
var string = "good idea, nice try.";
console.log( string.match(regex) );
// => ["good", "nice"]
但有个事实我们应该注意,比如我用 /good|goodbye/,去匹配 "goodbye" 字符串时,结果是 "good":
var regex = /good|goodbye/g;
var string = "goodbye";
console.log( string.match(regex) );
// => ["good"]
而把正则改成 /goodbye|good/,结果是:
var regex = /goodbye|good/g;
var string = "goodbye";
console.log( string.match(regex) );
// => ["goodbye"]
也就是说,分支结构也是惰性的,即当前面的匹配上了,后面的就不再尝试了。
7.1.5 案例分析
匹配字符,无非就是字符组、量词和分支结构的组合使用罢了。
7.1.5.1 匹配 16 进制颜色值
要求匹配 :
#ffbbad
#Fc01DF
#FFF
#ffE
分析:
-
表示一个 16 进制字符,可以用字符组 [0-9a-fA-F]。
-
其中字符可以出现 3 或 6 次,需要是用量词和分支结构。
-
使用分支结构时,需要注意顺序。
正则如下:
var regex = /#([\da-fA-F]{3}|[\da-fA-F]{6})/g
var string = "#ffbbad #Fc01DF #FFF #ffE";
console.log( string.match(regex) );
// => ["#ffbbad", "#Fc01DF", "#FFF", "#ffE"]
7.1.5.2 匹配时间
以 24 小时为例:
要求匹配:
23:59
02:07
分析:
-
共 4 位数字,第一位数字可以为 [0-2]。
-
当第 1 位为 "2" 时,第 2 位可以为 [0-3],其他情况时,第 2 位为 [0-9]。
-
第 3 位数字为 [0-5],第4位为 [0-9]。
正则如下:
var regex = /^([01]\d|[2][0-3]):[0-5]\d$/
console.log( regex.test("23:59") );
console.log( regex.test("02:07") );
如果也要求匹配 "7:9",也就是说时分前面的 "0" 可以省略。
此时正则变成:
var regex = /^(0?\d|1\d|[2][0-3]):(0?\d|[1-5]\d$)/
console.log( regex.test("23:59") );
console.log( regex.test("02:07") );
console.log( regex.test("7:9") );
// => true
// => true
// => true
7.1.5.3 匹配日期
比如 yyyy-mm-dd 格式为例:
要求匹配:
2017-06-10
- 年,四位数字即可,可用 [0-9]{4}。
- 月,共 12 个月,分两种情况 "01"、"02"、…、"09" 和 "10"、"11"、"12",可用 (0[1-9]|1[0-2])。
- 日,最大 31 天,可用 (0[1-9]|[12][0-9]|3[01])。
正则如下:
var regex = /\d{4}-(0\d|1[0-2])-(0\d|[12]\d|3[01])/g
console.log( regex.test("2017-06-10") );
// => true
7.1.5.4 windows 操作系统文件路径
要求匹配:
F:\study\javascript\regex\regular expression.pdf
F:\study\javascript\regex\
F:\study\javascript
F:\
分析:
整体模式是:
盘符:\文件夹\文件夹\文件夹\
-
其中匹配 "F:",需要使用
[a-zA-Z]:\\, 其中盘符不区分大小写,注意\字符需要转义 -
文件名或者文件夹名,不能包含一些特殊字符,此时我们需要排除字符组
[^\\:*<>|"?\r\n/]来表示合法
字符 -
另外它们的名字不能为空名,至少有一个字符,也就是要使用量词
+。因此匹配 文件夹\,可用[^\\:*<>|"?\r\n/]+\\ -
另外 文件夹
\,可以出现任意次 ,也就是([^\\:*<>|"?\r\n/]+\\)*其中括号表示其内部正则是一个整体 -
路径的最后一部分可以是 文件夹,没有 \,因此需要添加
([^\\:*<>|"?\r\n/]+)?
最后拼接成了一个看起来比较复杂的正则:
var regex = /^[a-zA-Z]:\\([^\\:*<>|"?\r\n/]+\\)*([^\\:*<>|"?\r\n/]+)?$/;
console.log( regex.test("F:\\study\\javascript\\regex\\regular expression.pdf") );
console.log( regex.test("F:\\study\\javascript\\regex\\") );
console.log( regex.test("F:\\study\\javascript") );
console.log( regex.test("F:\\") );
其中,在 JavaScript 中字符串要表示字符 \ 时,也需要转义
7.1.5.5 匹配 id
要求从:
<div id="container" class="main"></div>
提取出 id="container"。
可能最开始想到的正则是:
var regex = /id=".*"/
var string = '<div id="container" class="main"></div>';
console.log(string.match(regex)[0]);
// => id="container" class="main"
因为 . 是通配符,本身就匹配双引号的,而量词 * 又是贪婪的,当遇到 container 后面双引号时,是不会停下来,会继续匹配,直到遇到最后一个双引号为止。
解决之道,可以使用惰性匹配:
var regex = /id=".*?"/
var string = '<div id="container" class="main"></div>';
console.log(string.match(regex)[0]);
// => id="container"
当然,这样也会有个问题。效率比较低,因为其匹配原理会涉及到“回溯”这个概念,可以优化如下:
var regex = /id="[^"]*"/
var string = '<div id="container" class="main"></div>';
console.log(string.match(regex)[0]);
// => id="container"
7.2 位置匹配
正则表达式是匹配模式,要么匹配字符,要么匹配位置。
7.2.1 什么是位置 ?
位置(锚)是相邻字符之间的位置。比如,下图中箭头所指的地方:

7.2.2 如何匹配位置
在 ES5 中,共有 6 个锚:
^、$、\b、\B、(?=p)、(?!p)
-
^ 匹配开头,在多行匹配中匹配行开头
-
$ 匹配结尾,在多行匹配中匹配行结尾
比如我们把字符串的开头和结尾用 "#" 替换(位置可以替换成字符的!):
var result = "hello".replace(/^|$/g, '#') console.log(result); // => "#hello#"多行匹配模式(即有修饰符 m)时,二者是行的概念,这一点需要我们注意:
var result = "I\nlove\njavascript".replace(/^|$/gm, '#'); console.log(result); /* #I# #love# #javascript# */ -
\b 单词边界,具体就是 \w 与 \W 之间的位置,也包括 \w 与 ^ 之间的位置,和 \w 和 $ 之间的位置
例如考察文件名 "[JS] Lesson_01.mp4" 中的 \b,如下 :
var result = "[JS] Lesson_01.mp4".replace(/\b/g, '#'); console.log(result); // => "[#JS#] #Lesson_01#.#mp4#" -
\B 就是 \b 方面的意思,非单词边界
例如在字符串中所有位置中,扣掉 \b,剩下的都是 \B 的。具体说来就是 \w 与 \w、 \W 与 \W、^ 与 \W,\W 与 $ 之间的位置
比如上面的例子,把所有 \B 替换成 "#":
var result = "[JS] Lesson_01.mp4".replace(/\B/g, '#'); console.log(result); // => "#[J#S]# L#e#s#s#o#n#_#0#1.m#p#4" -
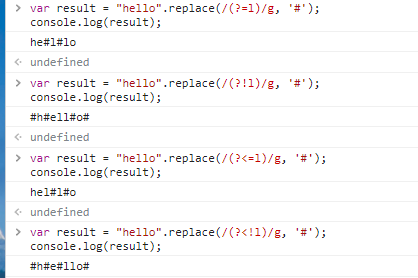
(?=p) 正向先行断言 其中 p 是一个子模式,即 p 前面的位置,或者说,该位置后面的字符要匹配 p
比如 (?=l),表示 "l" 字符前面的位置,例如:
var result = "hello".replace(/(?=l)/g, '#'); console.log(result); // => "he#l#lo" -
(?!p) 负向先行断言 就是 (?!p) 反面的意思
例如:
var result = "hello".replace(/(?!l)/g, '#'); console.log(result); // => "#h#ell#o#"二者的学名分别是 positive lookahead 和 negative lookahead
-
(?<=p) positive lookbehind
-
(?<!p) negative lookbehind
7.2.3 位置的特性
对于位置的理解,我们可以理解成空字符 " "。
比如 "hello" 字符串等价于如下的形式:
"hello" == "" + "h" + "" + "e" + "" + "l" + "" + "l" + "" + "o" + "";
也等价于:
"hello" == "" + "" + "hello"
因此,把 /^hello$ / 写成 /^^hello$$$/,是没有任何问题的
var result = /^^hello$$$/.test("hello");
console.log(result);
// => true
也就是说字符之间的位置,可以写成多个。
7.2.4 相关案例
-
不匹配任何东西的正则
var regex = /.^/因为此正则要求只有一个字符,但该字符后面是开头,而这样的字符串是不存在的
-
数字的千位分隔表示法
比如把 "12345678",变成 "12,345,678"。
-
弄出最后一个逗号
使用
(?=\d{3}$)就可以做到var result = "12345678".replace(/(?=\d{3}$)/g, ',') console.log(result); // => "12345,678" -
弄出所有逗号
因为逗号出现的位置,要求后面 3 个数字一组,也就是 \d{3} 至少出现一次。
此时可以使用量词 +:
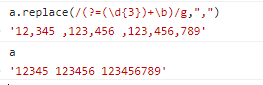
上面的正则,仅仅表示把从结尾向前数,一但是 3 的倍数,就把其前面的位置替换成逗号。因此才会出
现这个问题怎么解决呢?我们要求匹配的到这个位置不能是开头。
我们知道匹配开头可以使用 ^,但要求这个位置不是开头怎么办 -
去除第一个逗号
var regex=/(?!\b)(?=(\d{3})+\b)/g var a = '12345 123456 123456789' a.replace(regex, ","); => '12,345 123,456 123,456,789' -
格式化
千分符表示法一个常见的应用就是货币格式化。
比如把下面字符串:
1888格式化为:
$ 1888.00function format (num) { return num.toFixed(2).replace(/\B(?=(\d{3})+\b)/g, ",").replace(/^/, "$$ "); }; console.log( format(1888) ); // => "$ 1,888.00"
-
7.3 正则表达式括号的使用
不管哪门语言中都有括号。正则表达式也是一门语言,而括号的存在使这门语言更为强大。
对括号的使用是否得心应手,是衡量对正则的掌握水平的一个侧面标准。
括号的作用,其实三言两语就能说明白,括号提供了分组,便于我们引用它。
引用某个分组,会有两种情形:在 JavaScript 里引用它,在正则表达式里引用它
7.3.1 分组和分支结构
这二者是括号最直觉的作用,也是最原始的功能,强调括号内的正则是一个整体,即提供子表达式。
7.3.1.1 分组
我们知道 /a+/ 匹配连续出现的 "a",而要匹配连续出现的 "ab" 时,需要使用 /(ab)+/。
其中括号是提供分组功能,使量词 + 作用于 "ab" 这个整体,测试如下:
var regex = /(ab)+/g;
var string = "ababa abbb ababab";
console.log( string.match(regex) );
// => ["abab", "ab", "ababab"]
7.3.1.2 分支结构
而在多选分支结构 (p1|p2) 中,此处括号的作用也是不言而喻的,提供了分支表达式的所有可能。
比如,要匹配如下的字符串:
I love JavaScript
I love Regular Expression
var regex = /^I love (JavaScript|Regular Expression)$/;
console.log( regex.test("I love JavaScript") );
console.log( regex.test("I love Regular Expression") );
// => true
// => true
7.3.2 分组引用
这是括号一个重要的作用,有了它,我们就可以进行数据提取,以及更强大的替换操作。
而要使用它带来的好处,必须配合使用实现环境的 API。
以日期为例。假设格式是 yyyy-mm-dd 的,简单版的正则:
var regex = /\d{4}-\d{2}-\d{2}/
可视化形式:
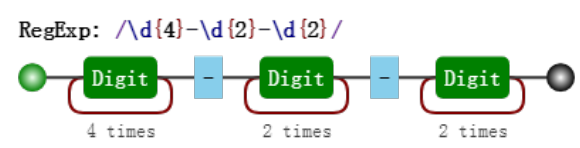
括号版:
var regex = /(\d{4})-(\d{2}-(\d{2}))/
可视化形式:
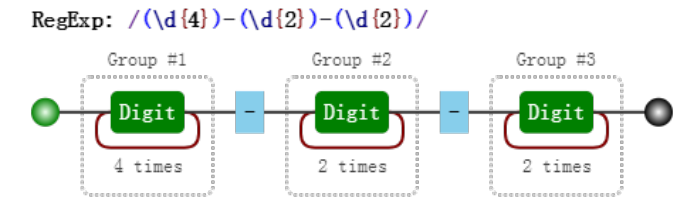
对比这两个可视化图片,我们发现,与前者相比,后者多了分组编号,如 Group #1。
其实正则引擎也是这么做的,在匹配过程中,给每一个分组都开辟一个空间,用来存储每一个分组匹配到的
数据。
既然分组可以捕获数据,那么我们就可以使用它们。
7.3.2.1 提取数据
比如提取出年、月、日,可以这么做:
var regex = /(\d{4})-(\d{2}-(\d{2}))/
var string = "2017-06-12";
console.log( string.match(regex) );
// => ["2017-06-12", "2017", "06", "12", index: 0, input: "2017-06-12"]
match 返回的一个数组,第一个元素是整体匹配结果,然后是各个分组(括号里)匹配的内容,然后是匹配下标,最后是输入的文本。另外,正则表达式是否有修饰符 g,match返回的数组格式是不一样的。
另外也可以使用正则实例对象的 exec 方法 :
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
console.log( regex.exec(string) );
// => ["2017-06-12", "2017", "06", "12", index: 0, input: "2017-06-12"]
同时,也可以使用构造函数的全局属性 $1 至 $9 来获取:
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
regex.test(string); // 正则操作即可,例如
// regex.exec(string);
// string.match(regex);
console.log(RegExp.$1); // "2017"
console.log(RegExp.$2); // "06"
console.log(RegExp.$3); // "12"
7.3.2.2 替换
比如,想把 yyyy-mm-dd 格式,替换成 mm/dd/yyyy 怎么做?
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
var result = string.replace(regex, "$2/$3/$1");
console.log(result);
// => "06/12/2017"
其中 replace 中的,第二个参数里用 $1、$2、$3 指代相应的分组。等价于如下的形式:
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
var result = string.replace(regex, function () {
return RegExp.$2 + "/" + RegExp.$3 + "/" + RegExp.$1;
});
console.log(result);
// => "06/12/2017"
也等价于:
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
var result = string.replace(regex, function (match, year, month, day) {
return month + "/" + day + "/" + year;
});
console.log(result);
// => "06/12/2017"
7.3.3 反向引用
除了使用相应 API 来引用分组,也可以在正则本身里引用分组。但只能引用之前出现的分组,即反向引用。
还是以日期为例。
比如要写一个正则支持匹配如下三种格式 :
2016-06-12
2016/06/12
2016.06.12
最先可能想到的正则是:
var regex = /\d{4}(-|\/|\.)\d{2}(-|\/|\.)\d{2}/;
var string1 = "2017-06-12";
var string2 = "2017/06/12";
var string3 = "2017.06.12";
var string4 = "2016-06/12";
console.log( regex.test(string1) ); // true
console.log( regex.test(string2) ); // true
console.log( regex.test(string3) ); // true
console.log( regex.test(string4) ); // true
其中 / 和 . 需要转义。虽然匹配了要求的情况,但也匹配 "2016-06/12" 这样的数据。
假设我们想要求分割符前后一致怎么办?此时需要使用反向引用:
var regex = /\d{4}(-|\/|\.)\d{2}\1\d{2}/;
var string1 = "2017-06-12";
var string2 = "2017/06/12";
var string3 = "2017.06.12";
var string4 = "2016-06/12";
console.log( regex.test(string1) ); // true
console.log( regex.test(string2) ); // true
console.log( regex.test(string3) ); // true
console.log( regex.test(string4) ); // false
注意里面的 \1,表示的引用之前的那个分组 (-|/|.)。不管它匹配到什么(比如 -),\1 都匹配那个同样的具体某个字符。
我们知道了 \1 的含义后,那么 \2 和 \3 的概念也就理解了,即分别指代第二个和第三个分组。
7.3.3.1 括号嵌套怎么办
以左括号(开括号)为准。比如:
var regex = /^((\d)(\d(\d)))\1\2\3\4$/;
var string = "1231231233";
console.log( regex.test(string) ); // true
console.log( RegExp.$1 ); // 123
console.log( RegExp.$2 ); // 1
console.log( RegExp.$3 ); // 23
console.log( RegExp.$4 ); // 3
我们可以看看这个正则匹配模式:
- 第一个字符是数字,比如说 "1",
- 第二个字符是数字,比如说 "2",
- 第三个字符是数字,比如说 "3",
- 接下来的是 \1,是第一个分组内容,那么看第一个开括号对应的分组是什么,是 "123",
- 接下来的是 \2,找到第2个开括号,对应的分组,匹配的内容是 "1",
- 接下来的是 \3,找到第3个开括号,对应的分组,匹配的内容是 "23",
- 最后的是 \4,找到第3个开括号,对应的分组,匹配的内容是 "3"。
此正则的可视化形式是:
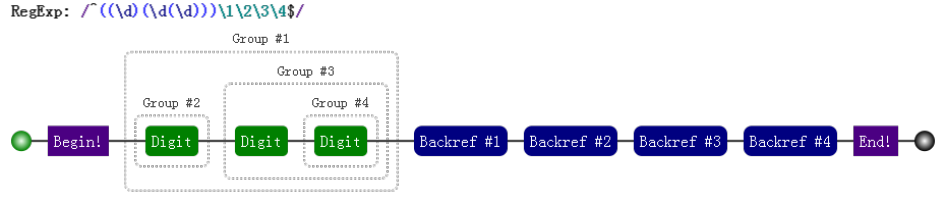
7.3.3.2 \10 表示什么
另外一个疑问可能是,即 \10 是表示第 10 个分组,还是 \1 和 0 呢?
答案是前者,虽然一个正则里出现 \10 比较罕见。测试如下
var regex = /(1)(2)(3)(4)(5)(6)(7)(8)(9)(#) \10+/;
var string = "123456789# ######"
console.log( regex.test(string) );
// => true
**如果真要匹配 \1 和 0 的话,请使用 (?:\1)0 或者 \1(?:0)。 **
8. webpack5
webpack的作用其实有以下几点:
- 模块打包。可以将不同模块的文件打包整合在一起,并且保证它们之间的引用正确,执行有序。利用打包我们就可以在开发的时候根据我们自己的业务自由划分文件模块,保证项目结构的清晰和可读性。
- 编译兼容。在前端的“上古时期”,手写一堆浏览器兼容代码一直是令前端工程师头皮发麻的事情,而在今天这个问题被大大的弱化了,通过
webpack的Loader机制,不仅仅可以帮助我们对代码做polyfill,还可以编译转换诸如.less, .vue, .jsx这类在浏览器无法识别的格式文件,让我们在开发的时候可以使用新特性和新语法做开发,提高开发效率。 - 能力扩展。通过
webpack的Plugin机制,我们在实现模块化打包和编译兼容的基础上,可以进一步实现诸如按需加载,代码压缩等一系列功能,帮助我们进一步提高自动化程度,工程效率以及打包输出的质量。
8.1 有哪些常见 loader
raw-loader:加载文件原始内容(utf-8)file-loader:把文件输出到一个文件夹中,在代码中通过相对 URL 去引用输出的文件 (处理图片和字体)url-loader:与 file-loader 类似,区别是用户可以设置一个阈值,大于阈值会交给 file-loader 处理,小于阈值时返回文件 base64 形式编码 (处理图片和字体)source-map-loader:加载额外的 Source Map 文件,以方便断点调试svg-inline-loader:将压缩后的 SVG 内容注入代码中image-loader:加载并且压缩图片文件json-loader加载 JSON 文件(默认包含)handlebars-loader: 将 Handlebars 模版编译成函数并返回babel-loader:把 ES6 转换成 ES5ts-loader: 将 TypeScript 转换成 JavaScriptawesome-typescript-loader:将 TypeScript 转换成 JavaScript,性能优于 ts-loadersass-loader:将SCSS/SASS代码转换成CSScss-loader:加载 CSS,支持模块化、压缩、文件导入等特性style-loader:把 CSS 代码注入到 JavaScript 中,通过 DOM 操作去加载 CSSpostcss-loader:扩展 CSS 语法,使用下一代 CSS,可以配合 autoprefixer 插件自动补齐 CSS3 前缀eslint-loader:通过 ESLint 检查 JavaScript 代码tslint-loader:通过 TSLint检查 TypeScript 代码mocha-loader:加载 Mocha 测试用例的代码coverjs-loader:计算测试的覆盖率vue-loader:加载 Vue.js 单文件组件i18n-loader: 国际化cache-loader: 可以在一些性能开销较大的 Loader 之前添加,目的是将结果缓存到磁盘里
8.2 常见 Plugin
-
ProvidePlugin:自动加载模块,代替require和import -
define-plugin:定义环境变量 (Webpack4 之后指定 mode 会自动配置) -
ignore-plugin:忽略部分文件 -
html-webpack-plugin:简化 HTML 文件创建 (依赖于 html-loader),可以根据模板自动生成 html 代码,并自动引入 css 和 js 文件 -
web-webpack-plugin:可方便地为单页应用输出 HTML,比 html-webpack-plugin 好用 -
uglifyjs-webpack-plugin:不支持 ES6 压缩 (Webpack4 以前) -
terser-webpack-plugin: 支持压缩 ES6 (Webpack4) -
webpack-parallel-uglify-plugin: 多进程执行代码压缩,提升构建速度 -
mini-css-extract-plugin: 分离样式文件,CSS 提取为独立文件,支持按需加载 (替代extract-text-webpack-plugin) -
serviceworker-webpack-plugin:为网页应用增加离线缓存功能 -
clean-webpack-plugin: 目录清理 -
ModuleConcatenationPlugin: 开启 Scope Hoisting -
speed-measure-webpack-plugin: 可以看到每个 Loader 和 Plugin 执行耗时 (整个打包耗时、每个 Plugin 和 Loader 耗时) -
webpack-bundle-analyzer: 可视化 Webpack 输出文件的体积 (业务组件、依赖第三方模块)
8.3 loader 和 plugin 的区别
Loader本质就是一个 函数,在该函数中对接收到的内容进行转换,返回转换后的结果。 因为 Webpack 只认识 JavaScript,所以 Loader 就成了翻译官,对其他类型的资源进行转译的预处理工作。Plugin就是插件,基于事件流框架Tapable,插件可以扩展 Webpack 的功能,在 Webpack 运行的生命周期中会广播出许多事件,Plugin 可以监听这些事件,在合适的时机通过 Webpack 提供的 API 改变输出结果。Loader在 module.rules 中配置,作为模块的解析规则,类型为数组。每一项都是一个 Object,内部包含了 test(类型文件)、loader、options (参数)等属性。Plugin在 plugins 中单独配置,类型为数组,每一项是一个 Plugin 的实例,参数都通过构造函数传入。
8.4 webpack构建流程
Webpack 的运行流程是一个串行的过程,从启动到结束会依次执行以下流程:
- 初始化参数:从配置文件
webpack.config.js和 Shell 语句中读取与合并参数,得出最终的参数 - 开始编译:用上一步得到的参数初始化 Compiler 对象,注册加载所有配置的插件,监听 webpack 构建生命周期的事件节点,执行对象的 run 方法开始执行编译
- 确定入口:根据配置中的 entry 找出所有的入口文件,开始解析文件构建 AST 语法树,找出依赖,递归往下
- 编译模块:从入口文件出发,调用所有配置的 Loader 对模块进行翻译,再找出该模块依赖的模块,再递归本步骤直到所有入口依赖的文件都经过了本步骤的处理
- 完成模块编译:在经过第4步使用 Loader 翻译完所有模块后,得到了每个模块被翻译后的最终内容以及它们之间的依赖关系
- 输出资源:根据入口和模块之间的依赖关系,组装成一个个包含多个模块的 Chunk,再把每个 Chunk 转换成一个单独的文件加入到输出列表,这步是可以修改输出内容的最后机会
- 输出完成:在确定好输出内容后,根据配置确定输出的路径和文件名,把文件内容写入到文件系统
在以上过程中,Webpack 会在特定的时间点广播出特定的事件,插件在监听到感兴趣的事件后会执行特定的逻辑,并且插件可以调用 Webpack 提供的 API 改变 Webpack 的运行结果。
简单说
- 初始化:启动构建,读取与合并配置参数,加载 Plugin,实例化 Compiler
- 编译:从 Entry 出发,针对每个 Module 串行调用对应的 Loader 去翻译文件的内容,再找到该 Module 依赖的 Module,递归地进行编译处理
- 输出:将编译后的 Module 组合成 Chunk,将 Chunk 转换成文件,输出到文件系统中
8.5 使用 webpack 开发时,用过哪些提高效率的插件
webpack-dashboard:可以更友好的展示相关打包信息。webpack-merge:提取公共配置,减少重复配置代码speed-measure-webpack-plugin:简称 SMP,分析出 Webpack 打包过程中 Loader 和 Plugin 的耗时,有助于找到构建过程中的性能瓶颈。size-plugin:监控资源体积变化,尽早发现问题HotModuleReplacementPlugin:模块热替换
8.6 source map 是什么,生产环境怎么用
source map 是将编译、打包、压缩后的代码映射回源代码的过程。打包压缩后的代码不具备良好的可读性,想要调试源码就需要 soucre map。
map文件只要不打开开发者工具,浏览器是不会加载的。
线上环境一般有三种处理方案:
hidden-source-map:借助第三方错误监控平台 Sentry 使用nosources-source-map:只会显示具体行数以及查看源代码的错误栈。安全性比 sourcemap 高sourcemap:通过 nginx 设置将 .map 文件只对白名单开放(公司内网)
注意:避免在生产中使用 inline- 和 eval-,因为它们会增加 bundle 体积大小,并降低整体性能。
8.7 模块打包原理
Webpack 实际上为每个模块创造了一个可以导出和导入的环境,本质上并没有修改 代码的执行逻辑,代码执行顺序与模块加载顺序也完全一致。
8.8 文件监听原理
在发现源码发生变化时,自动重新构建出新的输出文件。
Webpack开启监听模式,有两种方式:
- 启动 webpack 命令时,带上 --watch 参数
- 在配置 webpack.config.js 中设置 watch:true
缺点:每次需要手动刷新浏览器
原理:轮询判断文件的最后编辑时间是否变化,如果某个文件发生了变化,并不会立刻告诉监听者,而是先缓存起来,等 aggregateTimeout 后再执行。
module.export = {
// 默认false,也就是不开启
watch: true,
// 只有开启监听模式时,watchOptions才有意义
watchOptions: {
// 默认为空,不监听的文件或者文件夹,支持正则匹配
ignored: /node_modules/,
// 监听到变化发生后会等300ms再去执行,默认300ms
aggregateTimeout:300,
// 判断文件是否发生变化是通过不停询问系统指定文件有没有变化实现的,默认每秒问1000次 poll:1000
}
}
8.9 webpack 热更新原理
Webpack 的热更新又称热替换(Hot Module Replacement),缩写为 HMR。 这个机制可以做到不用刷新浏览器而将新变更的模块替换掉旧的模块。
HMR的 核心就是客户端从服务端拉去更新后的文件,准确的说是 chunk diff (chunk 需要更新的部分),实际上 WDS 与浏览器之间维护了一个 Websocket,当本地资源发生变化时,WDS 会向浏览器推送更新,并带上构建时的 hash,让客户端与上一次资源进行对比。客户端对比出差异后会向 WDS 发起 Ajax 请求来获取更改内容(文件列表、hash),这样客户端就可以再借助这些信息继续向 WDS 发起 jsonp 请求获取该chunk的增量更新。
后续的部分(拿到增量更新之后如何处理?哪些状态该保留?哪些又需要更新?)由 HotModulePlugin 来完成,提供了相关 API 以供开发者针对自身场景进行处理,像react-hot-loader 和 vue-loader 都是借助这些 API 实现 HMR。
Tag 2
其实是自己开启了express应用,添加了对webpack编译的监听,添加了和浏览器的websocket长连接,当文件变化触发webpack进行编译并完成后,会通过sokcet消息告诉浏览器准备刷新。而为了减少刷新的代价,就是 不用刷新网页,而是 刷新某个模块,webpack-dev-server可以支持热更新,通过生成 文件的hash值来比对需要更新的模块,浏览器再进行热替换
服务端
- 启动 webpack-dev-server服务器
- 创建webpack实例
- 创建server服务器
- 添加webpack的done事件回调
- 编译完成向客户端发送消息
- 创建express应用app
- 设置文件系统为内存文件系统
- 添加 webpack-dev-middleware 中间件
- 中间件负责返回生成的文件
- 启动webpack编译
- 创建http服务器并启动服务
- 使用sockjs在浏览器端和服务端之间建立一个websocket长连接
- 创建socket服务器
客户端
- webpack-dev-server/client端会监听到此hash消息
- 客户端收到ok消息后会执行reloadApp方法进行更新
- 在reloadApp中会进行判断,是否支持热更新,如果支持的话发生 webpackHotUpdate事件,如果不支持就直接刷新浏览器
- 在 webpack/hot/dev-server.js 会监听 webpackHotUpdate 事件
- 在check方法里会调用module.hot.check方法
- HotModuleReplacement.runtime请求Manifest
- 通过调用 JsonpMainTemplate.runtime 的 hotDownloadManifest方法
- 调用JsonpMainTemplate.runtime的hotDownloadUpdateChunk方法通过JSONP请求获取最新的模块代码
- 补丁js取回来或会调用 JsonpMainTemplate.runtime.js 的 webpackHotUpdate 方法
- 然后会调用 HotModuleReplacement.runtime.js 的 hotAddUpdateChunk方法动态更新 模块代码
- 然后调用hotApply方法进行热更新
8.10 如何对 bundle 体积进行监控和分析
VSCode 中有一个插件 Import Cost 可以帮助我们对引入模块的大小进行实时监测,还可以使用 webpack-bundle-analyzer 生成 bundle 的模块组成图,显示所占体积。
bundlesize 工具包可以进行自动化资源体积监控。
8.11 文件指纹是什么,怎么用?
文件指纹是打包后输出的文件名的后缀。
Hash:和整个项目的构建相关,只要项目文件有修改,整个项目构建的 hash 值就会更改Chunkhash:和 Webpack 打包的 chunk 有关,不同的 entry 会生出不同的 chunkhashContenthash:根据文件内容来定义 hash,文件内容不变,则 contenthash 不变
8.11.1 JS 的文件指纹位置
设置 output 的 filename,用 chunkhash。
module.exports = {
entry: {
app: './scr/app.js',
search: './src/search.js'
},
output: {
filename: '[name][chunkhash:8].js',
path:__dirname + '/dist'
}
}
8.11.2 CSS 的文件指纹位置
设置 MiniCssExtractPlugin 的 filename,使用 contenthash。
module.exports = {
entry: {
app: './scr/app.js',
search: './src/search.js' },
output: {
filename: '[name][chunkhash:8].js',
path:__dirname + '/dist'
},
plugins:[
new MiniCssExtractPlugin({
filename: `[name][contenthash:8].css`
})
]
}
8.11.3 图片的文件指纹位置
设置file-loader的name,使用hash。
占位符名称及含义
- ext 资源后缀名
- name 文件名称
- path 文件的相对路径
- folder 文件所在的文件夹
- contenthash 文件的内容hash,默认是md5生成
- hash 文件内容的hash,默认是md5生成
- emoji 一个随机的指代文件内容的emoj
const path = require('path');
module.exports = {
entry: './src/index.js',
output: {
filename:'bundle.js',
path:path.resolve(__dirname, 'dist')
},
module:{
rules:[{
test:/\.(png|svg|jpg|gif)$/,
use:[{
loader:'file-loader',
options:{
name:'img/[name][hash:8].[ext]'
}
}]
}]
}
}
8.12 如何优化 webpack 构建速度
(这个问题就像能不能说一说「从URL输入到页面显示发生了什么」一样)
(我只想说:您希望我讲多长时间呢?)
(面试官:。。。)
- 使用
高版本的 Webpack 和 Node.js 多进程/多实例构建:HappyPack(不维护了)、thread-loader压缩代码- 多进程并行压缩
- webpack-paralle-uglify-plugin
- uglifyjs-webpack-plugin 开启 parallel 参数 (不支持ES6)
- terser-webpack-plugin 开启 parallel 参数
- 通过 mini-css-extract-plugin 提取 Chunk 中的 CSS 代码到单独文件,通过 css-loader 的 minimize 选项开启 cssnano 压缩 CSS。
- 多进程并行压缩
图片压缩- 使用基于 Node 库的 imagemin (很多定制选项、可以处理多种图片格式)
- 配置 image-webpack-loader
缩小打包作用域:- exclude/include (确定 loader 规则范围)
- resolve.modules 指明第三方模块的绝对路径 (减少不必要的查找)
- resolve.mainFields 只采用 main 字段作为入口文件描述字段 (减少搜索步骤,需要考虑到所有运行时依赖的第三方模块的入口文件描述字段)
- resolve.extensions 尽可能减少后缀尝试的可能性
- noParse 对完全不需要解析的库进行忽略 (不去解析但仍会打包到 bundle 中,注意被忽略掉的文件里不应该包含 import、require、define 等模块化语句)
- IgnorePlugin (完全排除模块)
- 合理使用alias
提取页面公共资源:- 基础包分离:
- 使用 html-webpack-externals-plugin,将基础包通过 CDN 引入,不打入 bundle 中
- 使用 SplitChunksPlugin 进行(公共脚本、基础包、页面公共文件)分离(Webpack4内置) ,替代了 CommonsChunkPlugin 插件
- 基础包分离:
DLL:- 使用 DllPlugin 进行分包,使用 DllReferencePlugin(索引链接) 对 manifest.json 引用,让一些基本不会改动的代码先打包成静态资源,避免反复编译浪费时间。
- HashedModuleIdsPlugin 可以解决模块数字id问题
充分利用缓存提升二次构建速度:- babel-loader 开启缓存
- terser-webpack-plugin 开启缓存
- 使用 cache-loader 或者 hard-source-webpack-plugin
Tree shaking- 打包过程中检测工程中没有引用过的模块并进行标记,在资源压缩时将它们从最终的bundle中去掉(只能对ES6 Modlue生效) 开发中尽可能使用ES6 Module的模块,提高tree shaking效率
- 禁用 babel-loader 的模块依赖解析,否则 Webpack 接收到的就都是转换过的 CommonJS 形式的模块,无法进行 tree-shaking
- 使用 PurifyCSS(不在维护) 或者 uncss 去除无用 CSS 代码
- purgecss-webpack-plugin 和 mini-css-extract-plugin配合使用(建议)
Scope hoisting- 构建后的代码会存在大量闭包,造成体积增大,运行代码时创建的函数作用域变多,内存开销变大。Scope hoisting 将所有模块的代码按照引用顺序放在一个函数作用域里,然后适当的重命名一些变量以防止变量名冲突
- 必须是ES6的语法,因为有很多第三方库仍采用 CommonJS 语法,为了充分发挥 Scope hoisting 的作用,需要配置 mainFields 对第三方模块优先采用 jsnext:main 中指向的ES6模块化语法
动态Polyfill- 建议采用 polyfill-service 只给用户返回需要的polyfill,社区维护。 (部分国内奇葩浏览器UA可能无法识别,但可以降级返回所需全部polyfill)
8.13 编写 loader 的思路
Loader 支持链式调用,所以开发上需要严格遵循“单一职责”,每个 Loader 只负责自己需要负责的事情。
Loader的API 可以去官网查阅
- Loader 运行在 Node.js 中,我们可以调用任意 Node.js 自带的 API 或者安装第三方模块进行调用
- Webpack 传给 Loader 的原内容都是 UTF-8 格式编码的字符串,当某些场景下 Loader 处理二进制文件时,需要通过 exports.raw = true 告诉 Webpack 该 Loader 是否需要二进制数据
- 尽可能的异步化 Loader,如果计算量很小,同步也可以
- Loader 是无状态的,我们不应该在 Loader 中保留状态
- 使用 loader-utils 和 schema-utils 为我们提供的实用工具
- 加载本地 Loader 方法
- Npm link
- ResolveLoader
8.14 编写 plugin 的思路
webpack在运行的生命周期中会广播出许多事件,Plugin 可以监听这些事件,在特定的阶段钩入想要添加的自定义功能。Webpack 的 Tapable 事件流机制保证了插件的有序性,使得整个系统扩展性良好。
Plugin的API 可以去官网查阅
- compiler 暴露了和 Webpack 整个生命周期相关的钩子
- compilation 暴露了与模块和依赖有关的粒度更小的事件钩子
- 插件需要在其原型上绑定apply方法,才能访问 compiler 实例
- 传给每个插件的 compiler 和 compilation对象都是同一个引用,若在一个插件中修改了它们身上的属性,会影响后面的插件
- 找出合适的事件点去完成想要的功能
- emit 事件发生时,可以读取到最终输出的资源、代码块、模块及其依赖,并进行修改(emit 事件是修改 Webpack 输出资源的最后时机)
- watch-run 当依赖的文件发生变化时会触发
- 异步的事件需要在插件处理完任务时调用回调函数通知 Webpack 进入下一个流程,不然会卡住
8.15 webpack 打包的 hash 码产生原理
1.webpack生态中存在多种计算hash的方式
hashchunkhashcontenthash
hash代表每次webpack编译中生成的hash值,所有使用这种方式的文件hash都相同。每次构建都会使webpack计算新的hash。chunkhash基于入口文件及其关联的chunk形成,某个文件的改动只会影响与它有关联的chunk的hash值,不会影响其他文件contenthash根据文件内容创建。当文件内容发生变化时,contenthash发生变化
2.避免相同随机值
- webpack在 计算hash后分割chunk。产生相同随机值可能是因为这些文件属于同一个chunk,可以将某个文件提到独立的chunk(如放入entry)
8.16 webpack 离线缓存静态资源如何实现
- 在配置webpack时,我们可以使用html-webpack-plugin来注入到和html一段脚本来实现将第三方或者共用资源进行 静态化存储在html中注入一段标识,例如
<% HtmlWebpackPlugin.options.loading.html %>,在 html-webpack-plugin 中即可通过配置html属性,将script注入进去 - 利用 webpack-manifest-plugin 并通过配置 webpack-manifest-plugin ,生成 manifestjson 文件,用来对比js资源的差异,做到是否替换,当然,也要写缓存script
- 在我们做Cl以及CD的时候,也可以通过编辑文件流来实现静态化脚本的注入,来降低服务器的压力,提高性能
- 可以通过自定义plugin或者html-webpack-plugin等周期函数,动态注入前端静态化存储script
8.17 webpack 如何实现持久化缓存
- 服务端设置 http 缓存头
cache-control - 打包依赖和运行时到不同的 chunk 即 splitchunk
- 延迟加载 使用
import()方式 ,可以动态加载的文件分别到独立的 chunk,以得到自己的 chunkhash - 保持 hash 值得稳定 编译过程和文件内通的更改尽量不影响其他文件hash的计算,对于低版本webpack生成的增量数字id不稳定问题,可用hashedModuleIdsPlugin基于文件路径生成解决
8.15 babel 原理
大多数JavaScript Parser遵循 estree 规范,Babel 最初基于 acorn 项目(轻量级现代 JavaScript 解析器) Babel大概分为三大部分:
- 解析:将代码转换成 AST
- 词法分析:将代码(字符串)分割为token流,即语法单元成的数组
- 语法分析:分析token流(上面生成的数组)并生成 AST
- 转换:访问 AST 的节点进行变换操作生产新的 AST
- Taro就是利用 babel 完成的小程序语法转换
- 生成:以新的 AST 为基础生成代码
想了解如何一步一步实现一个编译器的同学可以移步 Babel 官网曾经推荐的开源项目 the-super-tiny-compiler
9. 性能
9.1 网络相关
-
DNS 预解析
DNS 解析也是需要时间的,可以通过预解析的方式来预先获得域名所对应的 IP。
<link rel="dns-prefetch" href="//yuchengkai.cn" /> -
缓存
缓存对于前端性能优化来说是个很重要的点,良好的缓存策略可以降低资源的重复加载提高网页的整体加载速度。
通常浏览器缓存策略分为两种:强缓存和协商缓存。
-
强缓存
实现强缓存可以通过两种响应头实现:
Expires和Cache-Control。强缓存表示在缓存期间不需要请求,state code为 200Expires: Wed, 22 Oct 2018 08:41:00 GMTExpires是 HTTP / 1.0 的产物,表示资源会在Wed, 22 Oct 2018 08:41:00 GMT后过期,需要再次请求。并且Expires受限于本地时间,如果修改了本地时间,可能会造成缓存失效。Cache-control: max-age=30Cache-Control出现于 HTTP / 1.1,优先级高于Expires。该属性表示资源会在 30 秒后过期,需要再次请求 -
协商缓存
如果缓存过期了,我们就可以使用协商缓存来解决问题。协商缓存需要请求,如果缓存有效会返回 304。
协商缓存需要客户端和服务端共同实现,和强缓存一样,也有两种实现方式
-
Last-Modified 和 If-Modified-Since
Last-Modified表示本地文件最后修改日期,If-Modified-Since会将Last-Modified的值发送给服务器,询问服务器在该日期后资源是否有更新,有更新的话就会将新的资源发送回来。但是如果在本地打开缓存文件,就会造成
Last-Modified被修改,所以在 HTTP / 1.1 出现了ETag -
ETag 和 If-None-Match
ETag类似于文件指纹,If-None-Match会将当前ETag发送给服务器,询问该资源ETag是否变动,有变动的话就将新的资源发送回来。并且ETag优先级比Last-Modified高
-
-
选择合适的缓存策略
对于大部分的场景都可以使用强缓存配合协商缓存解决,但是在一些特殊的地方可能需要选择特殊的缓存策略
- 对于某些不需要缓存的资源,可以使用
Cache-control: no-store,表示该资源不需要缓存 - 对于频繁变动的资源,可以使用
Cache-Control: no-cache并配合ETag使用,表示该资源已被缓存,但是每次都会发送请求询问资源是否更新。 - 对于代码文件来说,通常使用
Cache-Control: max-age=31536000并配合策略缓存使用,然后对文件进行指纹处理,一旦文件名变动就会立刻下载新的文件
- 对于某些不需要缓存的资源,可以使用
-
-
使用 HTTP /2.0
因为浏览器会有并发请求限制,在 HTTP / 1.1 时代,每个请求都需要建立和断开,消耗了好几个 RTT 时间,并且由于 TCP 慢启动的原因,加载体积大的文件会需要更多的时间。
在 HTTP / 2.0 中引入了 多路复用,能够让多个请求使用同一个 TCP 链接,极大的加快了网页的加载速度。并且还支持 Header 压缩,进一步的减少了请求的数据大小。
-
预加载
在开发中,可能会遇到这样的情况。有些资源不需要马上用到,但是希望尽早获取,这时候就可以使用预加载。
预加载其实是声明式的
fetch,强制浏览器请求资源,并且不会阻塞onload事件,可以使用以下代码开启预加载<link rel="preload" href="http://example.com" />预加载可以一定程度上降低首屏的加载时间,因为可以将一些不影响首屏但重要的文件延后加载,唯一缺点就是兼容性不好。
-
预渲染
可以通过预渲染将下载的文件预先在后台渲染,可以使用以下代码开启预渲染
<link rel="prerender" href="http://example.com" />预渲染虽然可以提高页面的加载速度,但是要确保该页面百分百会被用户在之后打开,否则就白白浪费资源去渲染
9.2 优化渲染过程
-
懒加载
懒加载就是将不关键的资源延后加载。
懒加载的原理就是只加载自定义区域(通常是可视区域,但也可以是即将进入可视区域)内需要加载的东西。对于图片来说,先设置图片标签的
src属性为一张占位图,将真实的图片资源放入一个自定义属性中,当进入自定义区域时,就将自定义属性替换为src属性,这样图片就会去下载资源,实现了图片懒加载。懒加载不仅可以用于图片,也可以使用在别的资源上。比如进入可视区域才开始播放视频等等
-
懒执行
懒执行就是将某些逻辑延迟到使用时再计算。该技术可以用于首屏优化,对于某些耗时逻辑并不需要在首屏就使用的,就可以使用懒执行。懒执行需要唤醒,一般可以通过定时器或者事件的调用来唤醒。
9.3 文件优化
-
图片优化
-
计算图片大小
对于一张 \(100 \times 100\) 像素的图片来说,图像上有 10000 个像素点,如果每个像素的值是 RGBA 存储的话,那么也就是说每个像素有 4 个通道,每个通道 1 个字节(8 位 = 1 个字节),所以该图片大小大概为 39KB(\(10000 \times 1 \times 4 \div 1024\))。
但是在实际项目中,一张图片可能并不需要使用那么多颜色去显示,我们可以通过减少每个像素的调色板来相应缩小图片的大小。
了解了如何计算图片大小的知识,那么对于如何优化图片,想必大家已经有 2 个思路了:
- 减少像素点
- 减少每个像素点能够显示的颜色
-
图片加载优化
- 不用图片。很多时候会使用到很多修饰类图片,其实这类修饰图片完全可以用 CSS 去代替。
- 对于移动端来说,屏幕宽度就那么点,完全没有必要去加载原图浪费带宽。一般图片都用 CDN 加载,可以计算出适配屏幕的宽度,然后去请求相应裁剪好的图片。
- 小图使用 base64 格式
- 将多个图标文件整合到一张图片中(雪碧图)
- 选择正确的图片格式:
- 对于能够显示 WebP 格式的浏览器尽量使用 WebP 格式。因为 WebP 格式具有更好的图像数据压缩算法,能带来更小的图片体积,而且拥有肉眼识别无差异的图像质量,缺点就是兼容性并不好
- 小图使用 PNG,其实对于大部分图标这类图片,完全可以使用 SVG 代替
- 照片使用 JPEG
-
其它文件优化
- CSS 文件放在
head中 - 服务端开启文件压缩功能
- 将
script标签放在body底部,因为 JS 文件执行会阻塞渲染。当然也可以把script标签放在任意位置然后加上defer,表示该文件会并行下载,但是会放到 HTML 解析完成后顺序执行。对于没有任何依赖的 JS 文件可以加上async,表示加载和渲染后续文档元素的过程将和 JS 文件的加载与执行并行无序进行。 - 执行 JS 代码过长会卡住渲染,对于需要很多时间计算的代码可以考虑使用
Webworker。Webworker可以让我们另开一个线程执行脚本而不影响渲染。
- CSS 文件放在
-
CDN
静态资源尽量使用 CDN 加载,由于浏览器对于单个域名有并发请求上限,可以考虑使用多个 CDN 域名。对于 CDN 加载静态资源需要注意 CDN 域名要与主站不同,否则每次请求都会带上主站的 Cookie
9.4 其它
-
使用 Webpack 优化项目
- 对于 Webpack,打包项目使用 production 模式,这样会自动开启代码压缩
- 使用 ES6 模块来开启 tree shaking,这个技术可以移除没有使用的代码
- 优化图片,对于小图可以使用 base64 的方式写入文件中
- 按照路由拆分代码,实现按需加载
- 给打包出来的文件名添加哈希,实现浏览器缓存文件
-
监控
对于代码运行错误,通常的办法是使用
window.onerror拦截报错。该方法能拦截到大部分的详细报错信息,但是也有例外- 对于跨域的代码运行错误会显示
Script error.对于这种情况我们需要给script标签添加crossorigin属性 - 对于某些浏览器可能不会显示调用栈信息,这种情况可以通过
arguments.callee.caller来做栈递归
对于异步代码来说,可以使用
catch的方式捕获错误。比如Promise可以直接使用catch函数,async await可以使用try catch但是要注意线上运行的代码都是压缩过的,需要在打包时生成 sourceMap 文件便于 debug。
对于捕获的错误需要上传给服务器,通常可以通过
img标签的src发起一个请求 - 对于跨域的代码运行错误会显示

 浙公网安备 33010602011771号
浙公网安备 33010602011771号