视频分割
主要的视频分割算法分为两类:
- OSVOS(one shot video object segmentation)每一帧单独处理
- MaskTrack考虑时序信息
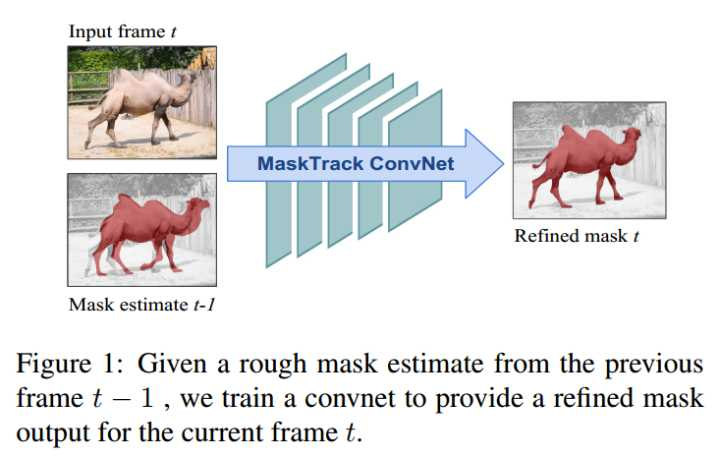
在MaskTrack中,首先使用图像语义分割网络(deeplabv2)得到instance segmentation。但问题是:怎么让网络知道哪一个instance需要分割?MaskTrack 中提出引导式实体分割的思路,将前一帧的预测结果作为掩膜额外输入给网络。输入包含四个通道RGB+Mask。Mask 是提供可能的预测目标,包含大概的位置和形状信息。在此基础上训练pixel labeling convnet,可以看做一个Mask Refinement。
论文的可行性:
- 粗糙的Mask就ok
- 不需要将视频数据怎么训练数据,因为输入只需要多一个通道的Mask。作者通过对标注进行变换(deforming、coarsening)模拟前一帧Mask。其中affine transformations 和non-rigid deformations 模拟相邻帧的运动变换,coarsening 用来模拟测试时前一帧的预测结果。
本篇论文的另一 个亮点是: on-line training的设计
在测试时,使用online training的技巧(在最优的tracking方法中使用)。将第一帧的标注信息作为额外的信息。在每个特定的instance下重新finetuning网络。
网络的变形:
- 可以使用不同的标注数据(box annotation)
- 使用optical flow 作为guidance(epicflow with flow fields matches and convolutional boundaries)
Lucid Data Dreaming数据扩充

 浙公网安备 33010602011771号
浙公网安备 33010602011771号