

达梦数据库执行计划频繁改变导致系统卡顿优化示例
在某个项目中碰到好几次系统卡顿的问题,原因有条sql执行计划经常发生了改变,导致服务器CPU资源撑爆。该表建了30多个索引,而索引字段数据分布不均衡,现本地模拟相关场景
示例如下
表结构如下,数据量1000000,统计信息等均已经收集。
CREATE TABLE "DOCUMENT"
("ID" NUMBER DEFAULT '0' NOT NULL,
"CREATE_TIME" TIMESTAMP(0),
"TENANT_KEY" VARCHAR2(10 CHAR),
"CONTENT_TYPE" VARCHAR2(500 CHAR),
....
CONSTRAINT "PRIMARY_250_IZYEMG" NOT CLUSTER PRIMARY KEY("ID")) ;
CREATE OR REPLACE INDEX "IDX_DOC_AUTO_PMTWZYCP" ON "DOCUMENT"("CONTENT" ASC)
CREATE OR REPLACE INDEX "IDX_DOC_UU01" ON "DOCUMENT"("TENANT_KEY" ,"CREATE_TIME" DESC) ;
sql执行如下:
select id from ec_doc.document where tenant_key = '1010' and delete_type = 0 and content = 'a' order by create_time desc;
执行计划如下

再次执行之后,执行实际0.02s
执行计划如下

为消除第一次硬解析影响,执行下面sql之后,验证上面的过程
select content,count(*) from ec_doc.document where tenant_key = '1010' and delete_type = 0 group by content order by 2 desc;
再次验证下面的sql,第二次执行效率比第一次快很多,
select id from ec_doc.document where tenant_key = '1010' and delete_type = 0 and content = 'a' order by create_time desc;
还是同样的sql,输入不同的参数值,第一次执行和多次执行都需要好几秒,执行计划走了全表扫描,没走索引
select id from ec_doc.document where tenant_key = '1001' and delete_type = 0 and content = 'aaa' order by create_time desc;


还是同样的sql,输入不同的参数值,下面每次执行都很快,执行计划走了tenant_key字段的索引
select id from ec_doc.document where tenant_key = '1800' and delete_type = 0 and content = 'aaa' order by create_time desc;


问题一:同样的sql,参数一模一样。两次执行计划都是走了content字段的索引,为什么第一次执行慢,再次执行就快?
问题二:同样一条sql,输入不同的值,执行计划不一样导致执行效率差异很大
原因分析一
查看sql真实的执行计划
可以在disql执行如下,查看sql执行计划如下;
ALTER SESSION SET 'MONITOR_SQL_EXEC'=1;
set autotrace traceonly;
第一次执行计划
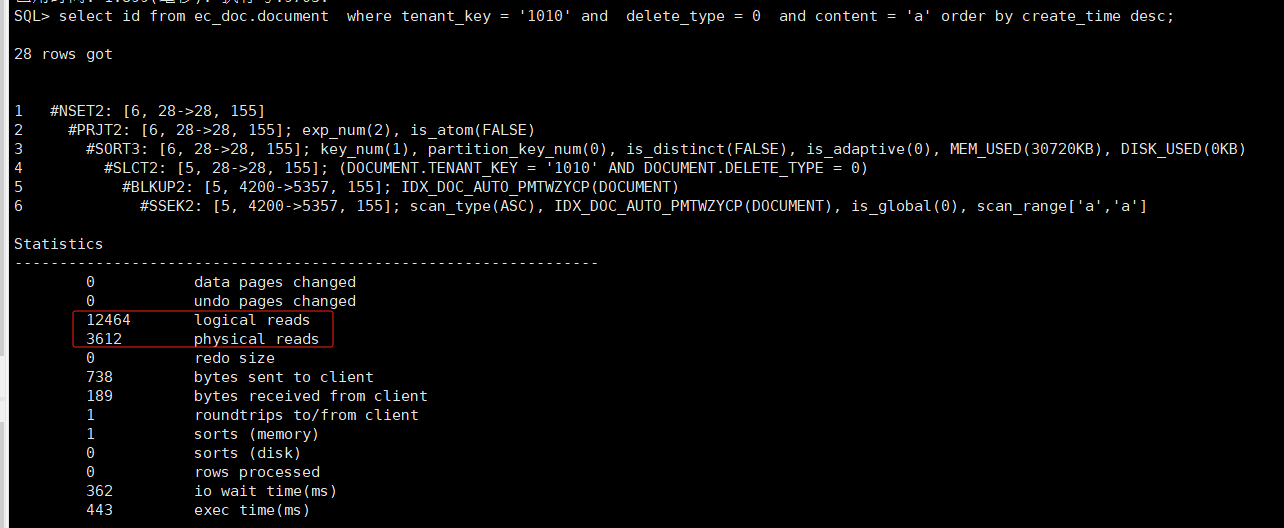
再次执行之后,执行计划
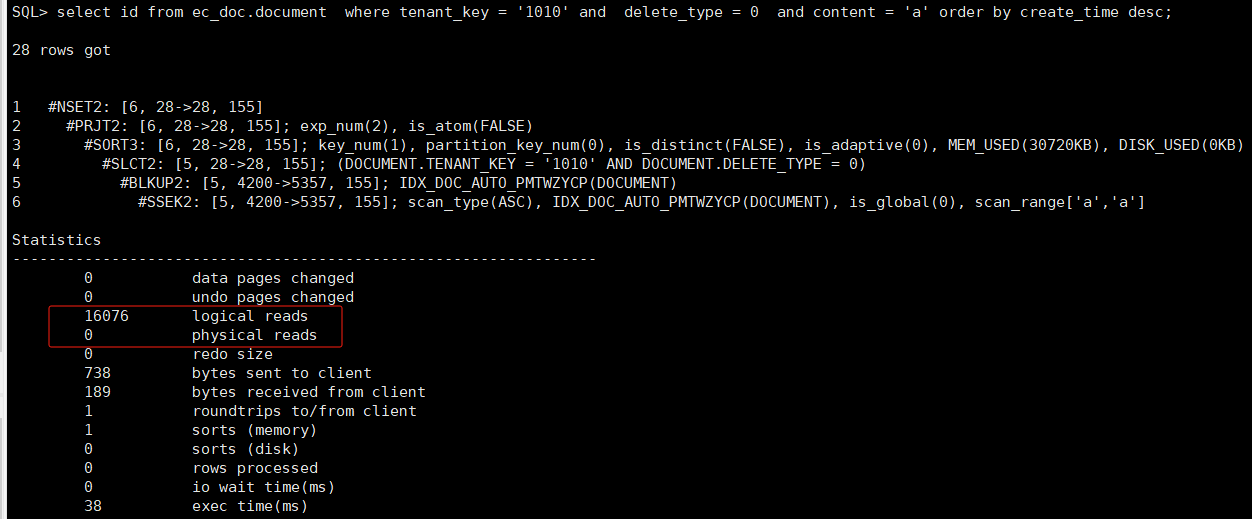
根据对比两个执行计划可以看到,第一次执行有物理读,而第二次都是逻辑读。一般原因是数据缓冲区过小,而本身查询需要读取较多的数据。当执行其他大数据量的sql时会将该表缓存到内存中的数据刷到磁盘中去。再次执行时需要从磁盘中读取数据。
原因分析二:
字段content和content数据分布情况如下;
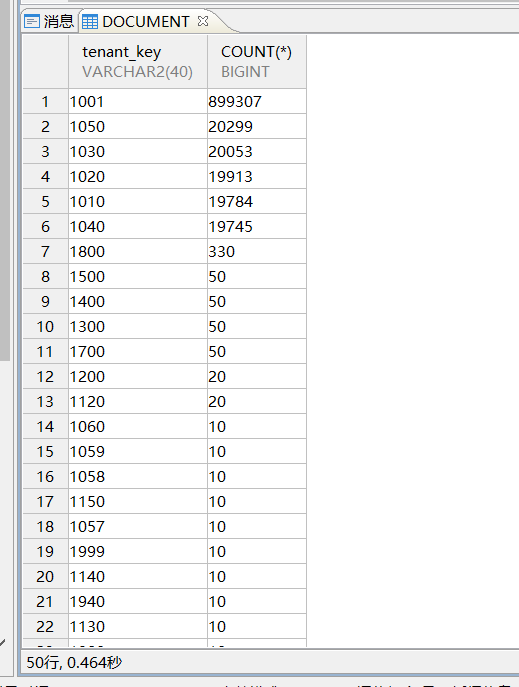
select tenant_key,count(*) from document group by tenant_key ORDER by 2 desc;
select content,count(*) from document group by content ORDER by 2 desc;

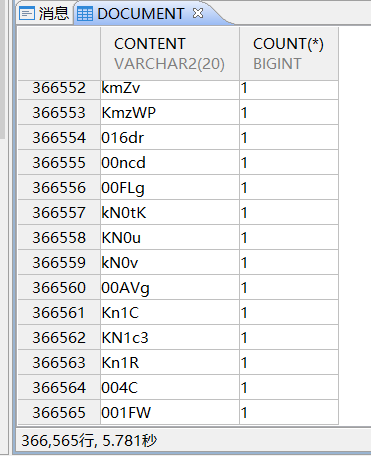
如上所示,字段content和content数据分布非常不均衡,当输入不同参数时优化器会选择不同的索引导致执行计划不一样。
解决方法
该条sql并发量非常高,而上面执行计划里面都包含回表和排序,可以尝试创建组合索引,消除排序和回表
CREATE INDEX "IDX_DOC_UN02" ON "DOCUMENT"("CONTENT","TENANT_KEY","DELETE_TYPE","CREATE_TIME" DESC,"ID")
创建组合索引之后,如下sql执行计划消除了回表和排序,逻辑读大幅减少。这里单独执行时间都很短,可以通过jmeter进行压测来验证影响,并发量低时两者压测看不出区别。当并发量高时,没创建组合索引之前服务器资源已经爆满,系统整体性能严重下降。创建组合索引之后,同样的并发下,cpu资源基本处于较低状态,系统基本没啥影响。

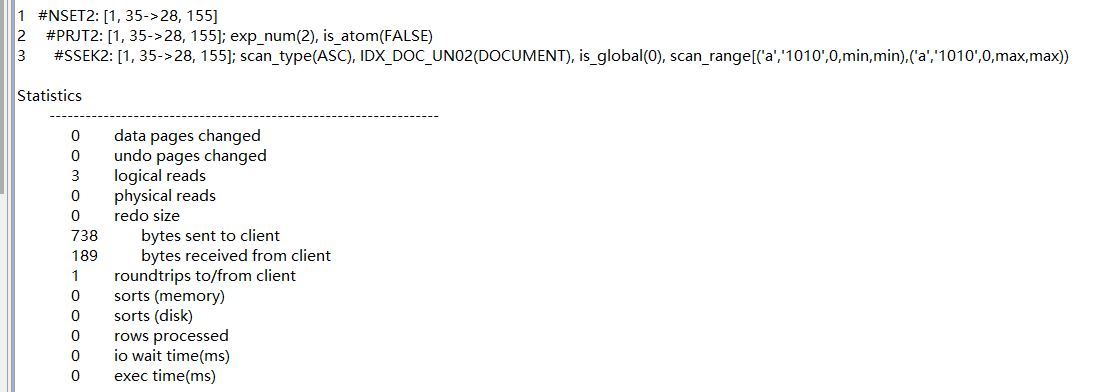
以前全表扫描执行时间需要6s的,创建组合索引之后,执行时间大幅减少
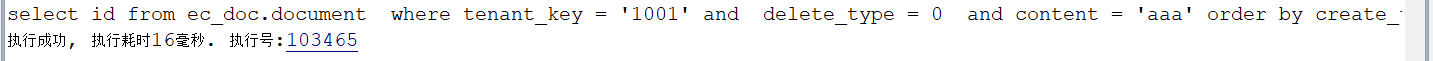


 浙公网安备 33010602011771号
浙公网安备 33010602011771号