import jieba
#添加jieba分词
mydict = ['聂小倩',"宁采臣",'燕赤霞','黑山老妖','辛十四娘']
for item in mydict:
jieba.add_word(item)
txt = open('聊斋志异.txt',"r", encoding='utf-8').read()
#注意这里的路径要用\\,因为在python中\r表示表示将光标的位置回退到本行的开头
#定义别名列表
bieming = [["聂小倩","小倩"],[ "宁采臣" ],['燕赤霞'],['黑山老妖'],['辛十四娘']]
words=jieba.lcut(txt)
counts={}
for word in words:
if len(word) ==1:
continue
else:
counts[word] = counts.get(word,0)+1
#计算出场次数(各个别名的合计次数)
lst=list()
for i in range(5):
lt=0
for item in bieming[i]:
lt += counts.get(item,0)
lst.append(lt)
twelvechai= ['聂小倩',"宁采臣",'燕赤霞','黑山老妖','辛十四娘']
items=list()
for i in range(5):
items.append([twelvechai[i],lst[i]])
items.sort(key=lambda x:x[1], reverse=True)
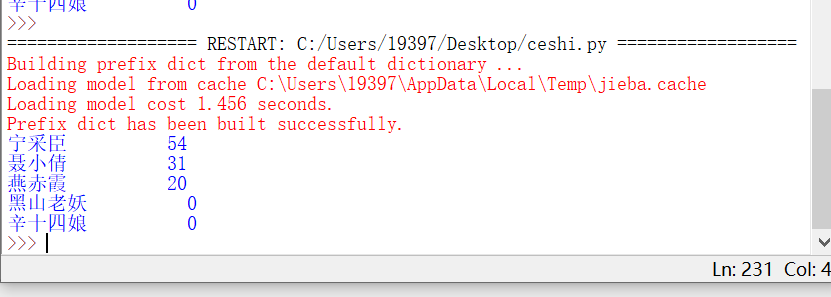
for i in range(5):
word, count = items[i]
print ("{0:<10}{1:>5}".format(word, count))
![]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号