java爬取读者文摘杂志
java爬虫入门实战练习
此代码仅用于学习研究
此次练习选择了读者文摘杂志网站进行文章爬取
练习中用到的都只是一些简单的方法,不过过程中复习了输入流输出流的使用以及文件的创建写入等知识,对自己还是有所帮助的
经小伙伴提醒,部分文章存在乱码,我们将这两个地方修改一下就可以了
代码可以直接运行(需要Jsoup包),唯一需要在E盘下创建一个名为FileTest的文件夹存储下载的文件或者修改一下代码中的存储路径
第一处(第52行)修改为:
OutputStreamWriter fileOutputStream = new OutputStreamWriter(new FileOutputStream(file,true),"UTF-8");
第二处(第55行)修改为:
fileOutputStream.write(Content.toString());
原代码:
1 import java.io.File; 2 import java.io.FileOutputStream; 3 4 import org.jsoup.Jsoup; 5 import org.jsoup.nodes.Document; 6 import org.jsoup.select.Elements; 7 8 9 public class testDUZHE { 10 11 public static void main(String[] args) throws Exception { 12 // 第一步:访问读者首页 13 String url = "https://www.dzwzzz.com/"; 14 Document document = Jsoup.connect(url).get(); 15 16 // 第二步:解析页面 17 Elements datatime = document.select("a"); 18 //获取a标签 19 for(int num=0;num<datatime.size();num++) { 20 //判断文章链接 21 if(datatime.get(num).attr("href").charAt(4)=='_') { 22 //获取a标签中href属性的值 23 String deHref = datatime.get(num).attr("href"); 24 System.out.println("==================\n\n\n"); 25 System.out.println("开始获取"+deHref.substring(0, 4)+"年第"+deHref.substring(5,7)+"期"); 26 System.out.println("\n\n\n=================="); 27 //根据a标签的值创建不同年份期刊的文件夹 28 File fileTest = new File("E:/FileTest/"+datatime.get(num).text()); 29 fileTest.mkdirs();//创建文件夹 30 //访问不同期刊页面 31 String DuZhe = "https://www.dzwzzz.com/"+deHref; 32 Document newdocu = Jsoup.connect(DuZhe).get(); 33 //获取a标签 34 Elements a_Elements = newdocu.select("a"); 35 for(int i=0;i<a_Elements.size();i++) { 36 //判断是否是文章链接 37 if (a_Elements.get(i).attr("href").charAt(0)=='d' 38 &&a_Elements.get(i).attr("href").charAt(1)=='u') 39 { 40 //访问文章所在页 41 String purpose = "https://www.dzwzzz.com/"+deHref.substring(0, 8)+a_Elements.get(i).attr("href"); 42 Document finaldocu = Jsoup.connect(purpose).get(); 43 //获取文章标题 44 Elements h1_elements = finaldocu.select("h1"); 45 String title = h1_elements.text(); 46 //获取文章内容 47 Elements p_Elements = finaldocu.select("p"); 48 String Content = p_Elements.text(); 49 //创建txt文件 50 File file = new File("E:/FileTest/"+datatime.get(num).text()+"/"+title+".txt"); 51 //创建文件输出流 52 FileOutputStream fileOutputStream = new FileOutputStream(file,true); 53 //这里的true功能是不覆盖原有内容,所以多次运行程序会造成重复 54 //将文章内容写入文件 55 fileOutputStream.write(Content.getBytes()); 56 fileOutputStream.close(); 57 System.out.println("文章地址"+purpose); 58 System.out.println(title+" 下载成功!"); 59 } 60 } 61 } 62 } 63 64 } 65 66 }
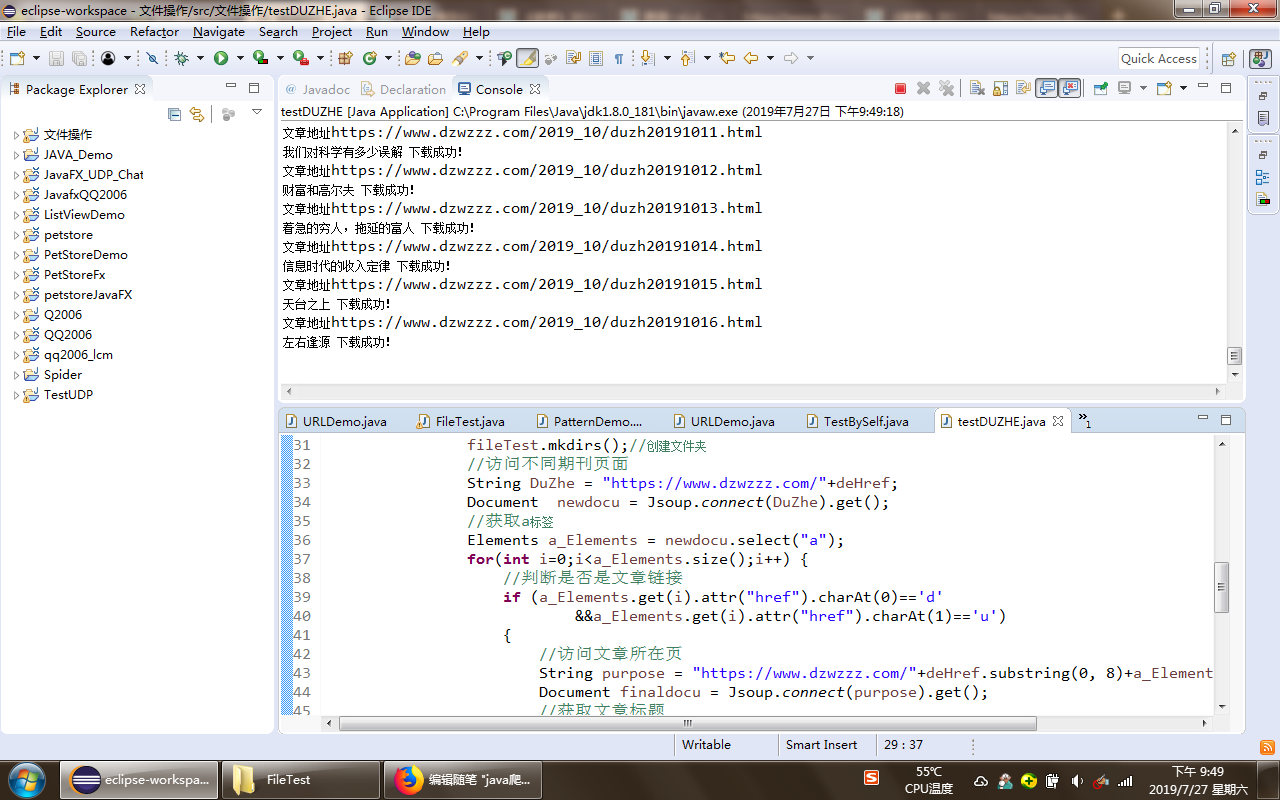
运行截图:
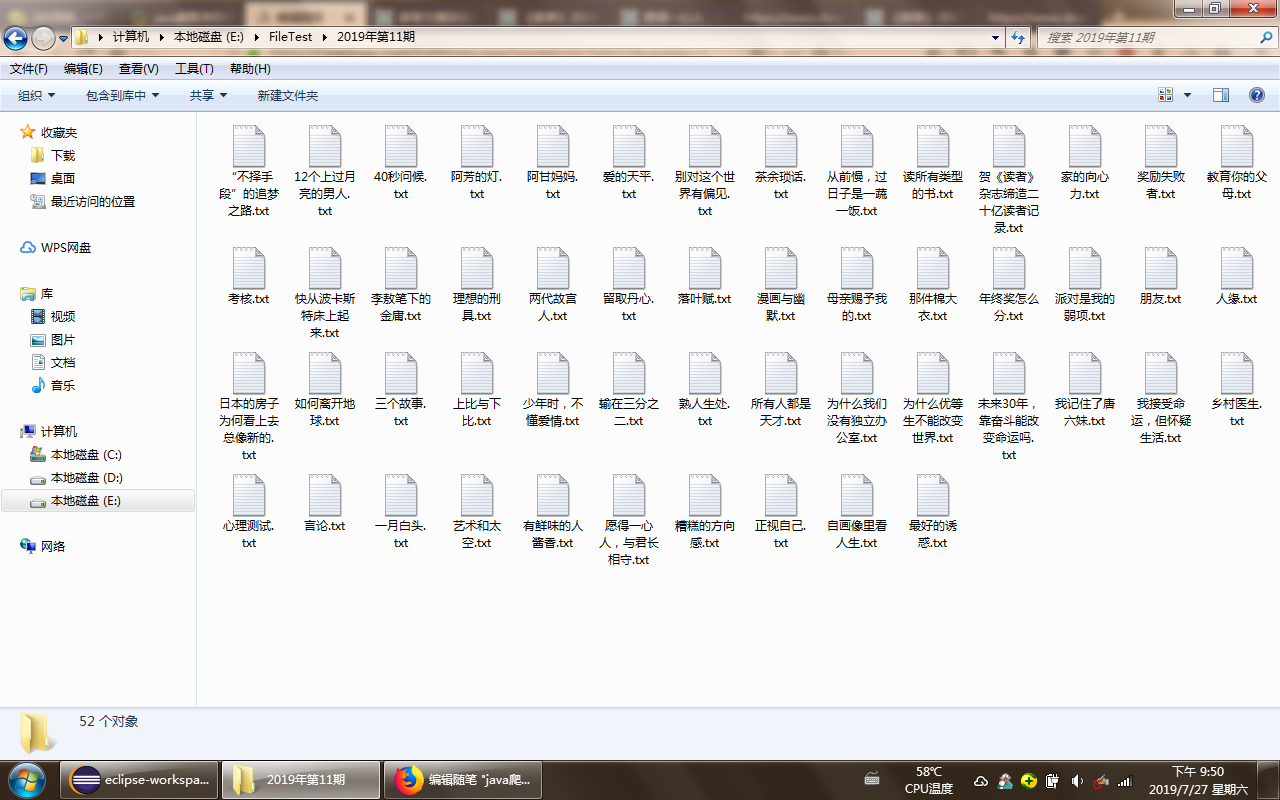
下载成功文件示例:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号