redis 五种数据结构剖析
我的脑袋不是空的。我是要大作为的人,只是混沌初开。
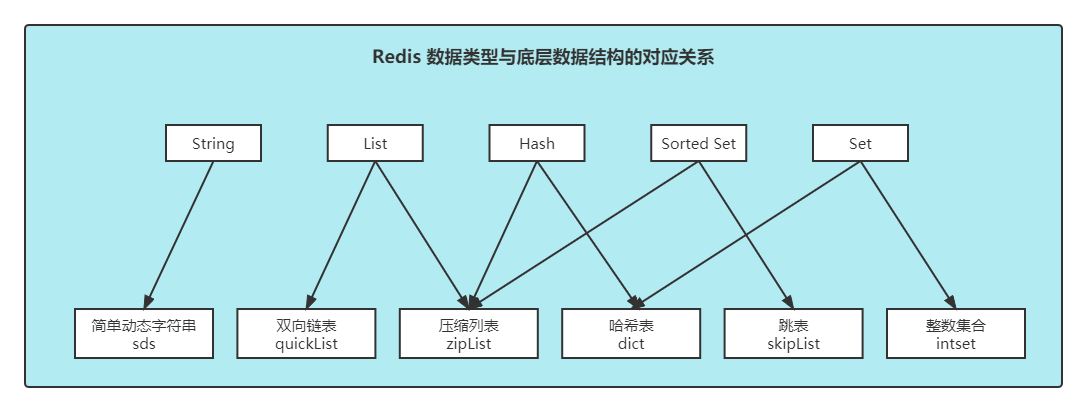
redis 五种数据类型
1、字符串 String - 字符串,整数,浮点数:做简单的键值对缓存
String是redis最基本的数据类型,一个key对应一个value。redis的String可以表示任何数据。比如jpg图像或者序列化对象,String的最大储存值为512MB。c
底层实现方式:动态字符串(SDS) 或者 long(String的内部存储结构一般是sds(Simple Dynamic String),但是如果一个String类型的value的值是数字,那么Redis内部会把它转成long类型来存储,从而减少内存的使用)
应用场景:微博数,粉丝数
2、哈希 HASH:(包含键值对的无序散列表)结构化的数据
底层实现方式:压缩列表ziplist 或者 字典dict
当数据量较少的情况下,hash底层会使用压缩列表ziplist进行存储数据,也就是同时满足下面两个条件的时候:
1)hash-max-ziplist-entries 512:当hash中的数据项(即filed-value对)的数目小于512时; 2)hash-max-ziplist-value 64:当hash中插入的任意一个value的长度小于64字节;
(注意)当不能同时满足上面两个条件的时候,底层的ziplist就会转成dict,之所以这样设计,是因为当ziplist变得很大的时候,它有如下几个缺点:
- 每次插入或修改引发的realloc操作会有更大的概率造成内存拷贝,从而降低性能。
- 一旦发生内存拷贝,内存拷贝的成本也相应增加,因为要拷贝更大的一块数据。
- 当ziplist数据项过多的时候,在它上面查找指定的数据项就会性能变得很低,因为ziplist上的查找需要进行遍历。
3、列表 List:储存一些列表类型的数据结构( list 的实现为一个双向链表,经常被用作队列使用,支持在链表两端进行push和pop操作,时间复杂度为O(1);同时也支持在链表中的任意位置的存取操作,但是需要对list进行遍历,时间复杂度为O(n))
底层实现方式:双向链表
1)Redis3.2之前的底层实现方式:压缩列表ziplist 或者 双向循环链表linkedlist - 当list存储的数据量较少时,会使用ziplist存储数据,也就是同时满足同等上面的两个条件
2)Redis3.2及之后的底层实现方式:quicklist - quicklist是一个双向链表,而且是一个基于ziplist的双向链表,quicklist的每个节点都是一个ziplist,结合了双向链表和ziplist的优点
4、Set 集合:交集,并集,差集的操作
set是一个存放不重复值的无序集合,可做全局去重的功能,提供了判断某个元素是否在set集合内的功能,这个也是list所不能提供的。基于set可以实现交集、并集、差集的操作,计算共同喜好,全部的喜好,自己独有的喜好等功能。
底层实现方式:有序整数集合intset 或者 字典dict
当存储的数据同时满足下面这样两个条件的时候,Redis 就采用整数集合intset来实现set这种数据类型:
1)存储的数据都是整数; 2)存储的数据元素个数小于512个
5、Zset有序集合:去重同时也可以排序
Sorted set 相比 set 多了一个权重参数score,集合中的元素能够按score进行排列。可以做排行榜应用,取TOP N操作。另外,sorted set可以用来做延时任务。最后一个应用就是可以做范围查找。
底层实现方式:压缩列表ziplist 或者 zset
当 sorted set 的数据同时满足下面这两个条件的时候,就使用压缩列表ziplist实现sorted set:
1)元素个数要小于 128 个,也就是ziplist数据项小于256个;2)集合中每个数据大小都小于 64 字节
当不能同时满足这两个条件的时候,Redis 就使用zset来实现sorted set,这个zset包含一个dict + 一个skiplist。dict用来查询数据到分数(score)的对应关系,而skiplist- 跳表 用来根据分数查询数据(可能是范围查找)。
对应映射关系:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号