Storm介绍&实际开发注意事项
一、使用组件的并行度代替线程池
Storm 自身是一个分布式、多线程的框架,对每个Spout 和Bolt,我们都可以设置其并发度;它也支持通过rebalance 命令来动态调整并发度,把负载分摊到多个Worker 上。
如果自己在组件内部采用线程池做一些计算密集型的任务,比如JSON 解析,有可能使得某些组件的资源消耗特别高,其他组件又很低,导致Worker 之间资源消耗不均衡,这种情况在组件并行度比较低的时候更明显。
比如某个Bolt 设置了1 个并行度,但在Bolt 中又启动了线程池,这样导致的一种后果就是,集群中分配了这个Bolt 的Worker 进程可能会把机器的资源都给消耗光了,影响到其他Topology 在这台机器上的任务的运行。如果真有计算密集型的任务,我们可以把组件的并发度设大,Worker 的数量也相应提高,让计算分配到多个节点上。
为了避免某个Topology 的某些组件把整个机器的资源都消耗光的情况,除了不在组件内部启动线程池来做计算以外,也可以通过CGroup 控制每个Worker 的资源使用量。
二、不要用DRPC 批量处理大数据
RPC 提供了应用程序和Storm Topology 之间交互的接口,可供其他应用直接调用,使用Storm 的并发性来处理数据,然后将结果返回给调用的客户端。这种方式在数据量不大的情况下,通常不会有问题,而当需要处理批量大数据的时候,问题就比较明显了。
(1)处理数据的Topology 在超时之前可能无法返回计算的结果。
(2)批量处理数据,可能使得集群的负载短暂偏高,处理完毕后,又降低回来,负载均衡性差。
批量处理大数据不是Storm 设计的初衷,Storm 考虑的是时效性和批量之间的均衡,更多地看中前者。需要准实时地处理大数据量,可以考虑Spark Stream 等批量框架。
三、不要在Spout 中处理耗时的操作
Spout 中nextTuple 方法会发射数据流,在启用Ack 的情况下,fail 方法和ack 方法会被触发。
需要明确一点,在Storm 中Spout 是单线程(JStorm 的Spout 分了3 个线程,分别执行nextTuple 方法、fail 方法和ack 方法)。如果nextTuple 方法非常耗时,某个消息被成功执行完毕后,Acker 会给Spout 发送消息,Spout 若无法及时消费,可能造成ACK 消息超时后被丢弃,然后Spout 反而认为这个消息执行失败了,造成逻辑错误。反之若fail 方法或者ack方法的操作耗时较多,则会影响Spout 发射数据的量,造成Topology 吞吐量降低。
四、注意fieldsGrouping 的数据均衡性
fieldsGrouping 是根据一个或者多个Field 对数据进行分组,不同的目标Task 收到不同
的数据,而同一个Task 收到的数据会相同。
假设某个Bolt 根据用户ID 对数据进行fieldsGrouping,如果某一些用户的数据特别多,而另外一些用户的数据又比较少,那么就可能使得下一级处理Bolt 收到的数据不均衡,整个处理的性能就会受制于某些数据量大的节点。可以加入更多的分组条件或者更换分组策略,使得数据具有均衡性。
五、优先使用localOrShuffleGrouping
localOrShuffleGrouping 是指如果目标Bolt 中的一个或者多个Task 和当前产生数据的Task 在同一个Worker 进程里面,那么就走内部的线程间通信,将Tuple 直接发给在当前Worker 进程的目的Task。否则,同shuffleGrouping。
localOrShuffleGrouping 的数据传输性能优于shuffleGrouping,因为在Worker 内部传输,只需要通过Disruptor 队列就可以完成,没有网络开销和序列化开销。因此在数据处理的复杂度不高, 而网络开销和序列化开销占主要地位的情况下, 可以优先使用localOrShuffleGrouping 来代替shuffleGrouping。
六、设置合理的MaxSpoutPending 值
在启用Ack 的情况下,Spout 中有个RotatingMap 用来保存Spout 已经发送出去,但还没有等到Ack 结果的消息。RotatingMap 的最大个数是有限制的,为p*num-tasks。其中p 是topology.max.spout.pending 值,也就是MaxSpoutPending(也可以由TopologyBuilder 在setSpout 通过setMaxSpoutPending 方法来设定),num-tasks 是Spout 的Task 数。如果不设置MaxSpoutPending 的大小或者设置得太大,可能消耗掉过多的内存导致内存溢出,设置太小则会影响Spout 发射Tuple 的速度。
七、设置合理的Worker 数
Worker 数越多,性能越好?先看一张Worker 数量和吞吐量对比的曲线(来源于JStorm文档:https://github.com/alibaba/jstorm/tree/master/docs/ 0.9.4.1jstorm https://github.com/alibaba/jstorm/tree/master/docs/ 0.9.4.1jstorm 性能测试.docx)。、
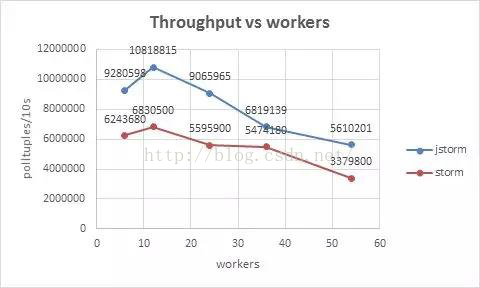
从图可以看出,在12 个Worker 的情况下,吞吐量最大,整体性能最优。这是由于一方面,每新增加一个Worker 进程,都会将一些原本线程间的内存通信变为进程间的网络通信,这些进程间的网络通信还需要进行序列化与反序列化操作,这些降低了吞吐率。
另一方面,每新增加一个Worker 进程,都会额外地增加多个线程(Netty 发送和接收线程、心跳线程、SystemBolt 线程以及其他系统组件对应的线程等),这些线程切换消耗了不少CPU,sys 系统CPU 消耗占比增加,在CPU 总使用率受限的情况下,降低了业务线程的使用效率。
八、平衡吞吐量和时效性
Storm 的数据传输默认使用Netty。在数据传输性能方面,有如下的参数可以调整:
(1)storm.messaging.netty.server_worker_threads:为接收消息线程;
(2)storm.messaging.netty.client_worker_threads:发送消息线程的数量;
(3)netty.transfer.batch.size:是指每次Netty Client 向Netty Server 发送的数据的大小,
如果需要发送的Tuple 消息大于netty.transfer.batch.size , 则Tuple 消息会按照netty.transfer.batch.size 进行切分,然后多次发送。
(4)storm.messaging.netty.buffer_size:为每次批量发送的Tuple 序列化之后的Task
Message 消息的大小。
(5)storm.messaging.netty.flush.check.interval.ms:表示当有TaskMessage 需要发送的时候, Netty Client 检查可以发送数据的频率。
降低storm.messaging.netty.flush.check.interval.ms 的值, 可以提高时效性。增加netty.transfer.batch.size 和storm.messaging.netty.buffer_size 的值,可以提升网络传输的吐吞量,使得网络的有效载荷提升(减少TCP 包的数量,并且TCP 包中的有效数据量增加),通常时效性就会降低一些。因此需要根据自身的业务情况,合理在吞吐量和时效性直接的平衡。
实际上woker的实际运行数量受限于setworker配置和supervisor.slots.ports两个配置
在Storm 的UI中,对没过topology都提供了相应的统计信息,其中有三个参数对性能来说参考意义比较明显,包括Execute latency,Process latency和Capacity。
分别看一下三个参数的含义哈!
·Execute latency:消息的平均处理时间,单位是毫秒。
·Process latency:消息从收到到被ack掉所花费的时间,单位为毫秒。如果没有启用Acker机制,那么Process latency的值为0。
·Capacity:计算公式为Capacity = Bolt 或者 Executor 调用 execute 方法处理的消息数量 × 消息平均执行时间/时间区间。如果这个值越接近1,说明Bolt或者 Executor 基本一直在调用 execute 方法,因此并行度不够,需要扩展这个组件的 Executor数量。
Execute latency,Process latency是处理消息的时效性,而Capacity则表示处理能力是否已经饱和。从这3个参数可以知道Topology的瓶颈所在。
如果使用异步kafka/meta客户端(listener方式)时,当增加/重启meta时,均需要重启topology
如果使用trasaction时,增加kafka/meta时, brokerId要按顺序,即新增机器brokerId要比之前的都要大,这样reassign spout消费brokerId时就不会发生错位。
非事务环境中,尽量使用IBasicBolt
计算并发度时,
spout 按单task每秒500的QPS计算并发
全内存操作的task,按单task 每秒2000个QPS计算并发
有向外部输出结果的task,按外部系统承受能力进行计算并发。
对于MetaQ 和 Kafka推荐一个worker运行2个task
拉取的频率不要太小,低于100ms时,容易造成MetaQ/Kafka 空转次数偏多
一次获取数据Block大小推荐是2M或1M,太大内存GC压力比较大,太小效率比较低。
将storm的消息打包后发送将极大的提升storm的吞吐量,减少emit次数 单机环境下平均每多一次emit,速率降低6%
设定一个合理的spout的ack等待队列的长度 通过topology.max.spout.pending进行配置大小
当pending满时,spout将不会再向bolt发射数据,防止雪崩的发生
设置合理的executor的传输配置 topology.transfer.buffer.size=32
topology.executor.receive.buffer.size=16384
topology.executor.send.buffer.size=16384
http://www.michael-noll.com/blog/2013/06/21/understanding-storm-internal-message-buffers/
这篇文章有较好的说明
配置合理的jvm参数 storm的topology默认只给768M的最大容量,实际生产环境中可能不够 应该设置合理的新生代和老年代大小,尽可能的减少全局gc 当storm分配的内存过大时(比如8G),可以使用cms回收器进行回收 远程调试storm和jmx监测
由于可能会有多个拓扑运行在storm上所以通过直接指定端口的方式会造成端口占用的问题 解决方法有两个
1) 直接修改storm.yaml
加入 需要重启nimbus worker.childopts: “-Xmx1024m
-Dcom.sun.management.jmxremote
-Dcom.sun.management.jmxremote.ssl=false
-Dcom.sun.management.jmxremote.authenticate=false
-Dcom.sun.management.jmxremote.port=1%ID%
storm api中的注释:
/*
The jvm opts provided to workers launched by this supervisor. All “%ID%”, “%WORKER-ID%”, “%TOPOLOGY-ID%”
and “%WORKER-PORT%” substrings are replaced with:
%ID% -> port (for backward compatibility),
%WORKER-ID% -> worker-id,
%TOPOLOGY-ID% -> topology-id,
%WORKER-PORT% -> port.
*/
2) 通过在topology的config中配置topology.worker.childopts为需要的jvm参数 对于一些System.properties也是通过这个方法设置,这个不需要重启storm,
注意topology中设置worker.childopts并不会生效,中topology的main方法中进行System.setProperty也是无效的,必须通过这种方式进行设置
----------------------------------------------------------------------------------------------------------------------------------------------------------------------
在介绍 Storm 的性能调优方法之前,假设一个场景:
项目组部署了3台机器,计划运行且仅运行 Storm(1.0.1) + Kafka(0.9.0.1) + Redis(3.2.1) 的小规模实验集群,集群的配置情况如下表:

现有一个任务,需要实时计算订单的各项汇总统计信息。订单数据通过 kafka 传输。在 Storm 中创建了一个 topology 来执行此项任务,并采用 Storm kafkaSpout 读取该 topic 的数据。kafka 和 Storm topology 的基本信息如下:
kafka topic partitions = 3
topology 的配置情况:
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(“kafkaSpout”, new kafkaSpout(), 3);
builder.setBolt(“filter”, new FilterBolt(), 3).shuffleGrouping(“kafkaSpout”);
builder.setBolt(“alert”, new AlertBolt(), 3).fieldsGrouping(“filter”, new Fields(“order”));
Config conf = new Config();
conf.setNumWorkers(2);
StormSubmitter.submitTopologyWithProgressBar(“topology-name”, conf, builder.createTopology());
那么,在此假设下,Storm topology 的数据怎么分发?性能如何调优?这就是下文要讨论的内容,其中性能调优是最终目的,数据分发即 Storm 的消息机制,则是进行调优前的知识储备。
调优步骤和方法
Storm topology 的性能优化方法,整体来说,可依次划分为以下几个步骤:
1.硬件配置的优化
2.代码层面的优化
3.topology 并行度的优化
4.Storm 集群配置参数和 topology 运行参数的优化
其中第一点不是讨论的重点,无外乎增加机器的硬件资源,提高机器的硬件配置等,但是这一步却也不能忽略,因为机器配置太低,很可能后面的步骤怎么调优都无济于事。
Storm 的一些特性和原理,是进行调优的必要知识储备
Storm 的部分特性
目前 Storm 的最新版本为 2.0.0-SNAPSHOT。该版本太新,未经过大量验证和测试,因此本文的讨论都基于 2.0 以前的版本。Storm 有如下几个重要的特性:
DAG
常驻内存,topology 启动后除非 kill 掉否则一直运行
提供 DRPC 服务
Pacemaker(1.0以后的新特性)心跳守护进程,常驻内存,比ZooKeeper性能更好
采用了 ZeroMQ 和 Netty 作为底层框架
采用了 ACK/fail 方式的 tuple 追踪机制
并且 ack/fail 只能由创建该tuple的task所承载的spout触发
了解这些机制对优化 Storm 的运行性能有一定帮助
Storm 并行度
Storm 是一个分布式的实时计算软件,各节点,各组件间的通信依赖于 zookeeper。从组件的角度看,Storm 运作机制构建在 nimbus, supervisor, woker, executor, task, spout/bolt 之上,如果再加上 topology,有时也可以称这些组件为 Concepts(概念)。详见官网介绍文章 http://storm.apache.org/releases/2.0.0-SNAPSHOT/Concepts.html 和
http://storm.apache.org/releases/current/Tutorial.html
在介绍 Storm 并行度之前,先概括地了解下 Storm 的几个概念,此处假定读者有一定的 Storm 背景知识,至少曾经跑过一个 topology 实例。
nimbus 和 supervisor
nimbus 是 Storm 集群的管理和调度进程,一个集群启动一个 nimbus,主要用于管理 topology,执行rebalance,管理 supervisor,分发 task,监控集群的健康状况等。nimbus 依赖 zookeeper 来实现上述职责,nimbus 与 supervisor 等其他组件并没有直接的沟通。运行 nimbus 的节点成为主节点,运行 supervisor 的节点成为工作节点,nimbus 向 supervisor 分派任务,因此 Storm 集群也是一个 master/slave 集群。简单来说,nimbus 就是工头,supervisor 就是工人,nimbus 通过 zookeeper 来管理 supervisor。
supervisor 是一个工作进程,负责监听 nimbus 分派的任务。当它接到任务后,会启动一个 worker 进程,由 worker 运行 topology 的一个子集。为什么说是子集呢?因为当一个 topology 提交到集群后,nimbus 便会根据该 topology 的配置(此处假定 numWorker=3),将 topology 分配给3个 worker 并行执行(正常情况下是这样,也有不是均匀分配的,比如有一个 supervisor 节点内存不足了)。如果刚好集群有3个 supervisor,则每个 supervisor 会启动1个 worker,即一个节点启动一个 worker(一个节点只能有一个 supervisor 有效运行)。因此,worker 进程运行的是 topology 的一个子集。supervisor 同样通过 zookeeper 与 nimbus 进行交流,因此 nimbus 和 supervisor 都可以快速失败/停止,因为所有的状态信息都保存在本地文件系统的 zookeeper 中, 当失败停止运行后,只需要重新启动 nimbus 或 supervisor 进程以快速恢复。当然,如果集群中正在工作的 supervisor 停止了,其上运行着的 topology 子集也会跟着停止,不过一旦 supervisor 启动起来,topology 子集又立刻恢复正常了。

nimbus 和 supervisor 的协作关系
worker
worker 是一个JVM进程,由 supervisor 启动和关闭。当 supervisor 接到任务后,会根据 topology 的配置启动若干 worker,实际的任务执行便由 worker 进行。worker 进程会占用固定的可由配置进行修改的内存空间(默认768M)。通常使用 conf.setNumWorkers() 函数来指定一个 topolgoy 的 worker 数量。
executor
executor 是一个线程,由 worker 进程派生(spawned)。executor 线程负责根据配置派生 task 线程,默认一个 executor 创建一个 task,可通过 setNumTask() 函数指定每个 executor 的 task 数量。executor 将实例化后的 spout/bolt 传递给 task。
task
task 可以说是 topology 最终的实际的任务执行者,每个 task 承载一个 spout 或 bolt 的实例,并调用其中的 spout.nexTuple(),bolt.execute() 等方法,而 spout.nexTuple() 是数据的发射器,bolt.execute() 则是数据的接收方,业务逻辑的代码基本上都在这两个函数里面处理了,因此可以说 task 是最终搬砖的苦逼。
topology
topology 中文翻译为拓扑,类似于 hdfs 上的一个 mapreduce 任务。一个 topology 定义了运行一个 Storm 任务的所有必要元件,主要包括 spout 和 bolt,以及 spout 和 bolt 之间的流向关系。
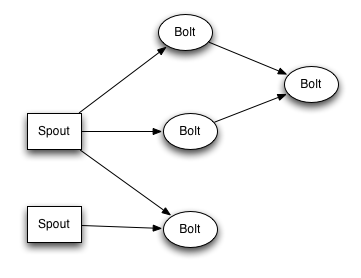
topology 结构
并行度
什么是并行度?在 Storm 的设定里,并行度大体分为3个方面:
一个 topology 指定多少个 worker 进程并行运行;
一个 worker 进程指定多少个 executor 线程并行运行;
一个 executor 线程指定多少个 task 并行运行。
一般来说,并行度设置越高,topology 运行的效率就越高,但是也不能一股脑地给出一个很高的值,还得考虑给每个 worker 分配的内存的大小,还得平衡系统的硬件资源,以避免浪费。
Storm 集群可以运行一个或多个 topology,而每个 topology 包含一个或多个 worker 进程,每个 worer 进程可派生一个或多个 executor 线程,而每个 executor 线程则派生一个或多个 task,task 是实际的数据处理单元,也是 Storm 概念里最小的工作单元, spout 或 bolt 的实例便是由 task 承载。
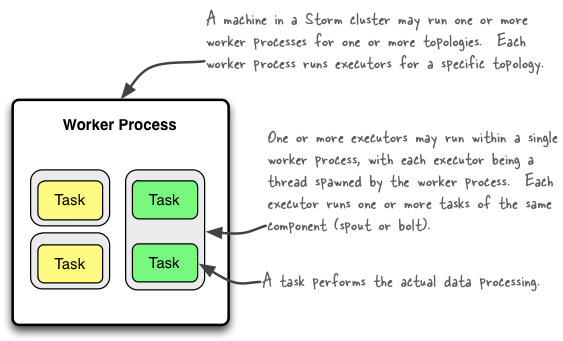
worker executor task 的关系
为了更好地解释 worker、executor 和 task 之间的工作机制,我们用官网的一个简单 topology 示例来介绍。先看此 topology 的配置:
Config conf = new Config();
conf.setNumWorkers(2); // 为此 topology 配置两个 worker 进程
topologyBuilder.setSpout(“blue-spout”, new BlueSpout(), 2); // blue-spout 并行度=2
topologyBuilder.setBolt(“green-bolt”, new GreenBolt(), 2) // green-bolt 并行度=2
.setNumTasks(4) // 为此 green-bolt 配置 4 个 task
.shuffleGrouping(“blue-spout”);
topologyBuilder.setBolt(“yellow-bolt”, new YellowBolt(), 6) // yellow-bolt 并行度=6
.shuffleGrouping(“green-bolt”);
StormSubmitter.submitTopology(
“mytopology”,
conf,
topologyBuilder.createTopology()
);
从上面的代码可以知道:
这个 topology 装备了2个 worker 进程,也就是同样的工作会有 2 个进程并行进行,可以肯定地说,2个 worker 肯定比1个 worker 执行效率要高很多,但是并没有2倍的差距;
配置了一个 blue-spout,并且为其指定了 2 个 executor,即并行度为2;
配置了一个 green-bolt,并且为其指定了 2 个 executor,即并行度为2;
配置了一个 yellow-bolt,并且为其指定了 6 个 executor,即并行度为6;
大家看官方给出的下图:
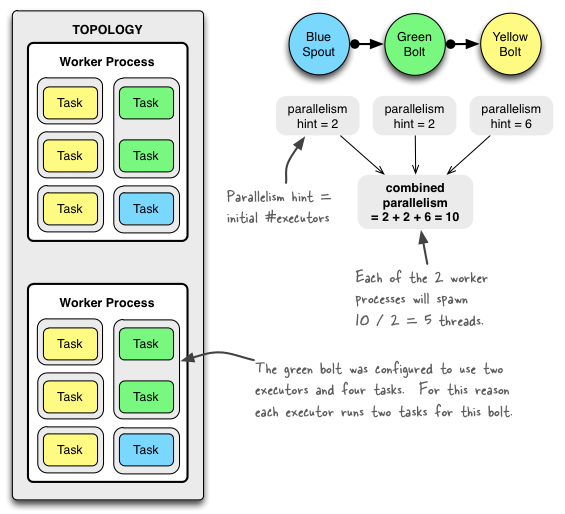
一个 topology 的结构图示
可以看出,这个图片完整无缺地还原了代码里设定的 topology 结构:
图左最大的灰色方框,表示这个 topology;
topology 里面刚好有两个白色方框,表示2个 worker 进程;
每个 worker 里面的灰色方框表示 executor 线程,可以看到2个 worker 方框里各有5个 executor,为什么呢?因为代码里面指定的 spout 并行度=2,green-bolt并行度=2,yellow-bolt并行度=6,加起来刚好是10,而配置的 worker 数量为2,那么自然地,这10个 executor 会均匀地分配到2个 worker 里面;
每个 executor 里面的黄蓝绿(写着Task)的方框,就是最小的处理单元 task 了。大家仔细看绿色的 Task 方框,与其他 Task 不同的是,两个绿色方框同时出现在一个 executor 方框内。为什么会这样呢?大家回到上文看 topology 的定义代码,topologyBuilder.setBolt(“green-bolt”, new GreenBolt(), 2).setNumTasks(4),这里面的 setNumTasks(4) 表示为该 green-bolt 指定了4个 task,且 executor 的并行度为2,那么自然地,这4个 task 会均匀地分配到2个 executor 里面;
图右的三个圆圈,依次是蓝色的 blue-spout,绿色的 green-bolt 和黄色的 yellow-bolt,并且用箭头指示了三个组件之间的关系。spout 是数据的产生元件,而 green-bolt 则是数据的中间接收节点,yellow-bolt 则是数据的最后接收节点。这也是 DAG 的体现,有向的(箭头不能往回走)无环图。
参考
http://storm.apache.org/releases/1.0.1/Understanding-the-parallelism-of-a-Storm-topology.html
http://www.michael-noll.com/blog/2012/10/16/understanding-the-parallelism-of-a-storm-topology/
一个 topology 的代码较完整例子
TopologyBuilder builder = new TopologyBuilder();
BrokerHosts hosts = new ZkHosts(zkConns);
SpoutConfig spoutConfig = new SpoutConfig(hosts, topic, zkRoot, clintId);
spoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme());
/* 指示 kafkaSpout 从 kafka topic 最后记录的 ofsset 开始读取数据 /
spoutConfig.startOffsetTime = kafka.api.OffsetRequest.LatestTime();
KafkaSpout kafkaSpout = new KafkaSpout(spoutConfig);
builder.setSpout(“kafkaSpout”, kafkaSpout, 3); // spout 并行度=3
builder.setBolt(“filter”, new FilterBolt(), 3).shuffleGrouping(“kafkaSpout”); // FilterBolt 并行度=3
builder.setBolt(“alert”, new AlertBolt(), 3).fieldsGrouping(“filter”, new Fields(“order”)); // AlertBolt 并行度=3
Config conf = new Config();
conf.setDebug(false);
conf.setNumWorkers(3); // 为此 topology 配置3个 worker 进程
conf.setMaxSpoutPending(10000);
try {
StormSubmitter.submitTopologyWithProgressBar(topology, conf, builder.createTopology());
} catch (Exception e) {
e.printStackTrace();
}
Storm 消息机制
Storm 主要提供了两种消息保证机制(Message Processing Guarantee)
至少一次 At least once
仅且一次 exactly once
其中 exactly once 是通过 Trident 方式实现的(exactly once through Trident)。两种模式的选择要视业务情况而定,有些场景要求精确的仅且一次消费,比如订单处理,决不能允许重复的处理订单,因为很可能会导致订单金额、交易手数等计算错误;有些场景允许一定的重复,比如页面点击统计,访客统计等。总之,不管何种模式,Storm 都能保证数据不会丢失,开发者需要关心的是,如何保证数据不会重复消费。
At least once 的消息处理机制,在运用时需要格外小心,Storm 采用 ack/fail 机制来追踪消息的流向,当一个消息(tuple)发送到下游时,如果超时未通知 spout,或者发送失败,Storm 默认会根据配置策略进行重发,可通过调节重发策略来尽量减少消息的重复发送。一个常见情况是,Storm 集群经常会超负载运行,导致下游的 bolt 未能及时 ack,从而导致 spout 不断的重发一个 tuple,进而导致消息大量的重复消费。
在与 Kafka 集成时,常用 Storm 提供的 kafkaSpout 作为 spout 消费 kafka 中的消息。Storm 提供的 kafkaSpout 默认有两种实现方式:至少一次消费的 core Storm spouts 和仅且一次消费的 Trident spouts :(We support both Trident and core Storm spouts)。
在 Storm 里面,消息的处理,通过两个组件进行:spout 和 bolt。其中 spout 负责产生数据,bolt 负责接收并处理数据,业务逻辑代码一般都写入 bolt 中。可以定义多个 bolt ,bolt 与 bolt 之间可以指定单向链接关系。通常的作法是,在 spout 里面读取诸如 kafka,mysql,redis,elasticsearch 等数据源的数据,并发射(emit)给下游的 bolt,定义多个 bolt,分别进行多个不同阶段的数据处理,比如第一个 bolt 负责过滤清洗数据,第二个 bolt 负责逻辑计算,并产生最终运算结果,写入 redis,mysql,hdfs 等目标源。
Storm 将消息封装在一个 Tuple 对象里,Tuple 对象经由 spout 产生后通过 emit() 方法发送给下游 bolt,下游的所有 bolt 也同样通过 emit() 方法将 tuple 传递下去。一个 tuple 可能是一行 mysql 记录,也可能是一行文件内容,具体视 spout 如何读入数据源,并如何发射给下游。
如下图,是一个 spout/bolt 的执行过程:
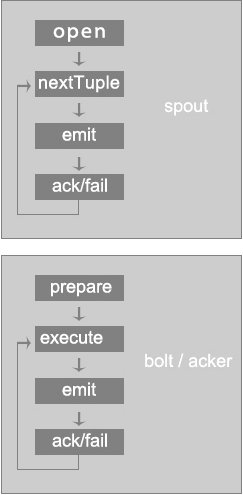
spout/bolt 的执行过程
spout -> open(pending状态) -> nextTuple -> emit -> bolt -> execute -> ack(spout) / fail(spout) -> message-provider 将该消息移除队列(complete) / 将消息重新压回队列
ACK/Fail
上文说到,Storm 保证了数据不会丢失,ack/fail 机制便是实现此机制的法宝。Storm 在内部构建了一个 tuple tree 来表示每一个 tuple 的流向,当一个 tuple 被 spout 发射给下游 bolt 时,默认会带上一个 messageId,可以由代码指定但默认是自动生成的,当下游的 bolt 成功处理 tuple 后,会通过 acker 进程通知 spout 调用 ack 方法,当处理超时或处理失败,则会调用 fail 方法。当 fail 方法被调用,消息可能被重发,具体取决于重发策略的配置,和所使用的 spout。
对于一个消息,Storm 提出了『完全处理』的概念。即一个消息是否被完全处理,取决于这个消息是否被 tuple tree 里的每一个 bolt 完全处理,当 tuple tree 中的所有 bolt 都完全处理了这条消息后,才会通知 acker 进程并调用该消息的原始发射 spout 的 ack 方法,否则会调用 fail 方法。
ack/fail 只能由创建该 tuple 的 task 所承载的 spout 触发
默认情况下,Storm 会在每个 worker 进程里面启动1个 acker 线程,以为 spout/bolt 提供 ack/fail 服务,该线程通常不太耗费资源,因此也无须配置过多,大多数情况下1个就足够了。

ack/fail 示意
Worker 间通信
上文所说是在一个 worker 内的情况,但是 Storm 是一个分布式的并行计算框架,而实现并行的一个关键方式,便是一个 topology 可以由多个 worker 进程分布在多个 supervisor 节点并行地执行。那么,多个 worker 之间必然是会有通信机制的。nimbus 和 supervsor 之间仅靠 zookeeper 进行沟通,那么为何 worker 之间不通过 zookeeper 之类的中间件进行沟通呢?其中的一个原因我想,应该是组件隔离的原则。worker 是 supervisor 管理下的一个进程,那么 worker 如果也采用 zookeeper 进行沟通,那么就有一种越级操作的嫌疑了。
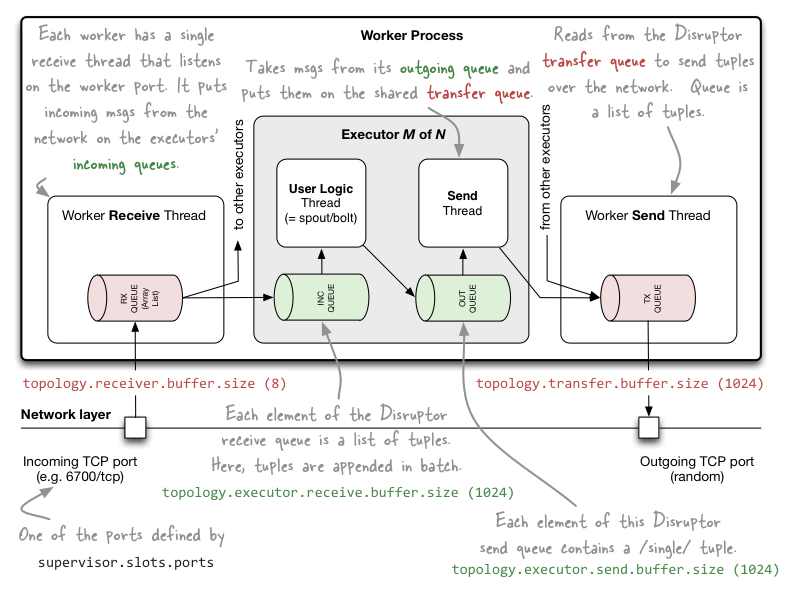
Worker 间通信
大家看上图,一个 worker 进程装配了如下几个元件:
一个 receive 线程,该线程维护了一个 ArrayList,负责接收其他 worker 的 sent 线程发送过来的数据,并将数据存储到 ArrayList 中。数据首先存入 receive 线程的一个缓冲区,可通过 topology.receiver.buffer.size (此项配置在 Storm 1.0 版本以后被删除了)来配置该缓冲区存储消息的最大数量,默认为8(个数,并且得是2的倍数),然后才被推送到 ArrayList 中。receive 线程接收数据,是通过监听 TCP的端口,该端口有 storm 配置文件中 supervisor.slots.prots 来配置,比如 6700;
一个 sent 线程,该线程维护了一个消息队列,负责将队里中的消息发送给其他 worker 的 receive 线程。同样具有缓冲区,可通过 topology.transfer.buffer.size 来配置缓冲区存储消息的最大数量,默认为1024(个数,并且得是2的倍数)。当消息达到此阈值时,便会被发送到 receive 线程中。sent 线程发送数据,是通过一个随机分配的TCP端口来进行的。
一个或多个 executor 线程。executor 内部同样拥有一个 receive buffer 和一个 sent buffer,其中 receive buffer 接收来自 receive 线程的的数据,sent buffer 向 sent 线程发送数据;而 task 线程则介于 receive buffer 和 sent buffer 之间。receive buffer 的大小可通过 Conf.TOPOLOGY_EXECUTOR_RECEIVE_BUFFER_SIZE 参数配置,sent buffer 的大小可通过 Config.TOPOLOGY_EXECUTOR_SEND_BUFFER_SIZE 配置,两个参数默认都是 1024(个数,并且得是2的倍数)。
Config conf = new Config();
conf.put(Config.TOPOLOGY_RECEIVER_BUFFER_SIZE, 16); // 默认8
conf.put(Config.TOPOLOGY_TRANSFER_BUFFER_SIZE, 32);
conf.put(Config.TOPOLOGY_EXECUTOR_RECEIVE_BUFFER_SIZE, 16384);
conf.put(Config.TOPOLOGY_EXECUTOR_SEND_BUFFER_SIZE, 16384);
参考
http://storm.apache.org/releases/1.0.1/Guaranteeing-message-processing.html
http://www.michael-noll.com/blog/2013/06/21/understanding-storm-internal-message-buffers/
Storm UI 解析
首页

Cluster Summary

Nimbus Summary
比较简单,就略过了
Topology Summary
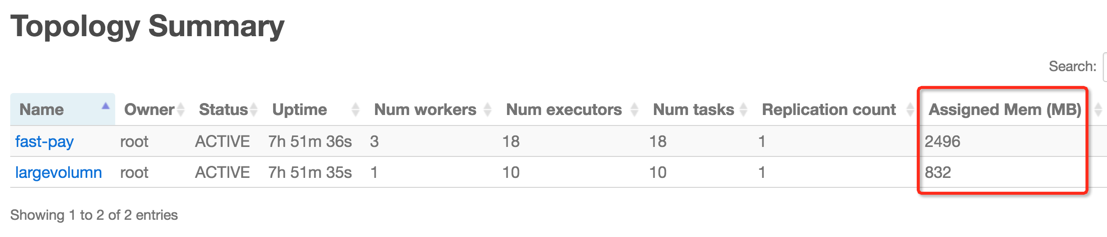
这部分也比较简单,值得注意的是 Assigned Mem (MB),这里值得是分配给该 topolgoy 下所有 worker 工作内存之和,单个 worker 的内存配置可由 Config.WORKER_HEAP_MEMORY_MB 和 Config.TOPOLOGY_WORKER_MAX_HEAP_SIZE_MB 指定,默认为 768M,另外再加上默认 64M 的 logwritter 进程内存空间,则有 832M。
此处 fast-pay 的值为 2496M = 3*832
Supervisor Summary

此处也比较简单,值得注意的是 slot 和 used slot 分别表示当前节点总的可用 worker 数,及已用掉的 worker 数。
Nimbus Configuration
可搜索和查看当前 topology 的各项配置参数
topology 页面

Topology summary
此处的大部分配置与上文中出现的意义一样,值得注意的是:
Num executors 和 Num tasks 的值。其中 Num executors 的数量等于当前 topology 下所有 spout/bolt 的并行度总和,再加上所有 worker 下的 acker executor 线程总数(默认情况下一个 worker 派生一个 acker executor)。
Topology actions

按钮 说明
Activate 激活此 topology
Deactivate 暂停此 topology 运行
Rebalance 调整并行度并重新平衡资源
Kill 关闭并删除此 topology
Debug 调试此 topology 运行,需要设置 topology.eventlogger.executors 数量 > 0
Stop Debug 停止调试
Change Log Level 调整日志级别
- Topology stats

Spouts (All time)
Bolts (All time)
spout 页面
这个页面,大部分都比较简单,就不一一说明了,值得注意的是下面这个 Tab:
Executors (All time)
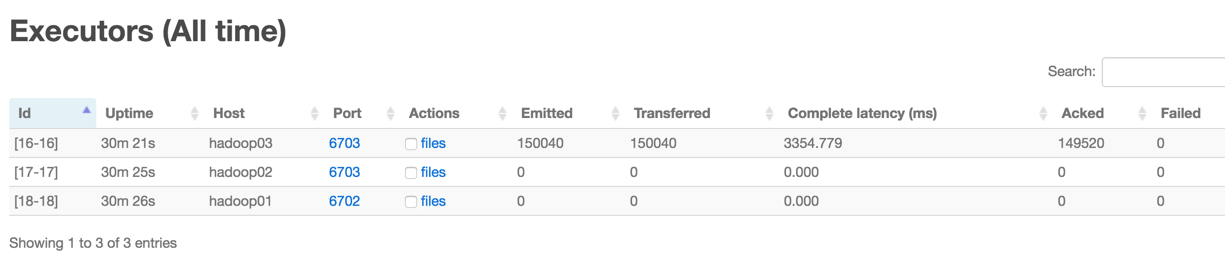
这个Tab的参数,应该不用解释了,但是要注意看,Emitted,Transferred 和 Acked 这几个参数,看看是否所有的 executor 都均匀地分担了 tuple 的处理工作。
bolt 页面
这个页面与 spout 页面类似,也不赘述了。
参考:这个页面通过 API 的方式,对 UI 界面的参数做了一些解释
http://storm.apache.org/releases/1.0.1/STORM-UI-REST-API.html
Storm debug
Storm 提供了良好的 debug 措施,许多操作可以再 UI 上完成,也可以在命令行完成。比如 Change log level 在不重启 topology 的情况下动态修改日志记录的级别,在 UI 界面上查看某个 bolt 的日志等,当然也可以在命令行上操作。
下面的参考文章写的很详细,大家有兴趣可以去阅读一下,本文就不再讨论了。
参考
https://community.hortonworks.com/articles/36151/debugging-an-apache-storm-topology.html
性能调优
上文说了这么多,这才进入主题。
1、合理地配置硬件资源
此处暂不讨论
2、优化代码的执行性能
要优化代码的性能,如果严谨一点,首先要有一个衡量代码执行效率的方式。在数学上,通常使用大O函数来衡量一个算法的时间复杂度。我们可以考虑使用大O函数来近似地估计一个代码片段的执行时间:假定一行代码花费1个单位时间,那么代码片段的时间复杂度可以近似地用大O表示为 O(n),其中n表示代码的行数或执行次数。当然,如果代码里引入了其他的类和函数,或者处于循环体内,那么其他类、函数的代码行数,以及循环体内代码的重复执行次数也需要统计在内。这里说到大O函数的概念,在实际中也很少用到,我们往往会用第三方工具来较为准确地计算代码的实际执行时间,但是理解这个概念有助于优化我们的代码。有兴趣的同学可以阅读《算法概论》这本书。
这里顺便举一个斐波那契数列的例子:
/* C代码:用递归实现的斐波那契数列 /
int fibonacci(unsigned int n)
{
if (n <= 0) return 0;
if (n == 1) return 1;
return fibonacci(n - 1) + fibonacci(n - 2);
}
/* C代码:用循环实现的斐波那契数列 /
int fibonacci(unsigned int n)
{
int r, a, b;
int i;
int result[2] = {0, 1};
if (n < 2) return result[n];
a = 0;
b = 1;
r = 0;
for (i = 2; i <= n; i++)
{
r = a + b;
a = b;
b = r;
}
return r;
}
观看两个不同实现的例子,第一种递归的方式,当传入的n很大时,代码执行的时间将会呈指数级增长,这时T(n)接近于 O(2^n);第二种循环的方式,即使传入很大的n,代码也可以在较短的时间内执行完毕,这时T(n)接近于O(n),为什么是O(n)呢,比如说n=1000,那么整个算法的执行时间基本集中在那个 for 循环里了,相当于执行了 for 循环内3行代码1000多次,所以差不多是n。这其实就是一种用空间换时间的概念,利用循环代替递归的方式,从而大大地优化了代码的执行效率。
回到我们的 Storm。代码优化,归结起来,应该有这几种:
在算法层面进行优化
在业务逻辑层面进行优化
在技术层面进行优化
特定于 Storm,合理地规划 topology,即安排多少个 bolt,每个 bolt 做什么,链接关系如何
在技术层面进行优化,手法就非常多了,比如连接数据库时,运用连接池,常用的连接池有 alibaba 的 druid,还有 redis 的连接池;比如合理地使用多线程,合理地优化JVM参数等等。这里举一个工作中可能会遇到的例子来介绍一下:
在配置了多个并行度的 bolt 中,存取 redis 数据时,如果不使用 redis 线程池,那么很可能会遇到 topology 运行缓慢,spout 不断重发,甚至直接挂掉的情况。首先 redis 的单个实例并不是线程安全的,其次在不使用 redis-pool 的情况下,每次读取 redis 都创建一个 redis 连接,同创建一个 mysql 连接一样,在连接 redis 时所耗费的时间相较于 get/set 本身是非常巨大的。
/**
* redis-cli 操作工具类
*/
package net.mtide.dbtool;
import java.util.List;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public class RedisCli {
private static JedisPool pool = null;
private final static Logger logger = LoggerFactory.getLogger(FilterBolt.class);
/**
* 同步初始化 JedisPool
*/
private static synchronized void initPool() {
if (pool == null) {
String hosts = "HOST";
String port = "PORT";
String pass = "PASS";
pool = new JedisPool(new JedisPoolConfig(), hosts, Integer.parseInt(port), 2000, pass);
}
}
/**
* 将连接 put back to pool
*
* @param jedis
*/
private static void returnResource(final Jedis jedis) {
if (pool != null && jedis != null) {
pool.returnResource(jedis);
}
}
/**
* 同步获取 Jedis 实例
*
* @return Jedis
*/
public synchronized static Jedis getJedis() {
if (pool == null) {
initPool();
}
return pool.getResource();
}
public static void set(final String key, final String value) {
Jedis jedis = getJedis();
try {
jedis.set(key, value);
}
catch (Exception e) {
logger.error(e.toString());
}
finally {
returnResource(jedis);
}
}
public static void set(final String key, final String value, final int seconds) {
Jedis jedis = getJedis();
try {
jedis.set(key, value);
jedis.expire(key, seconds);
}
catch (Exception e) {
logger.error(e.toString());
}
finally {
returnResource(jedis);
}
}
public static String get(final String key) {
String value = null;
Jedis jedis = getJedis();
try {
value = jedis.get(key);
}
catch (Exception e) {
logger.error(e.toString());
}
finally {
returnResource(jedis);
}
return value;
}
public static List<String> mget(final String... keys) {
List<String> value = null;
Jedis jedis = getJedis();
try {
value = jedis.mget(keys);
}
catch (Exception e) {
logger.error(e.toString());
}
finally {
returnResource(jedis);
}
return value;
}
public static Long del(final String key) {
Long value = null;
Jedis jedis = getJedis();
try {
value = jedis.del(key);
}
catch (Exception e) {
logger.error(e.toString());
}
finally {
returnResource(jedis);
}
return value;
}
public static Long expire(final String key, final int seconds) {
Long value = null;
Jedis jedis = getJedis();
try {
value = jedis.expire(key, seconds);
}
catch (Exception e) {
logger.error(e.toString());
}
finally {
returnResource(jedis);
}
return value;
}
public static Long incr(final String key) {
Long value = null;
Jedis jedis = getJedis();
try {
value = jedis.incr(key);
}
catch (Exception e) {
logger.error(e.toString());
}
finally {
returnResource(jedis);
}
return value;
}
}
当一个配置了多个并行度的 topology 运行在集群上时,如果 redis 操作不当,很可能会造成运行该 redis 的 bolt 长时间阻塞,从而造成 tuple 传递超时,默认情况下 spout 在 fail 后会重发该 tuple,然而 redis 阻塞的问题没有解决,重发不仅不能解决问题,反而会加重集群的运行负担,那么 spout 重发越来越多,fail 的次数也越来越多, 最终导致数据重复消费越来越严重。上面贴出来的 RedisCli 工具类,可以在多线程的环境下安全的使用 redis,从而解决了阻塞的问题。
3、合理的配置并行度
有几个手段可以配置 topology 的并行度:
conf.setNumWorkers() 配置 worker 的数量
builder.setBolt(“NAME”, new Bolt(), 并行度) 设置 executor 数量
spout/bolt.setNumTask() 设置 spout/bolt 的 task 数量
现在回到我们的一开始的场景假设:
项目组部署了3台机器,计划运行一个 Storm(1.0.1) + Kafka(0.9.0.1) + Redis(3.2.1) 的小规模实验集群,每台机器的配置为 2CPUs,4G RAM
/* 初始配置 /
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(“kafkaSpout”, new kafkaSpout(), 3);
builder.setBolt(“filter”, new FilterBolt(), 3).shuffleGrouping(“kafkaSpout”);
builder.setBolt(“alert”, new AlertBolt(), 3).fieldsGrouping(“filter”, new Fields(“order”));
Config conf = new Config();
conf.setNumWorkers(2);
StormSubmitter.submitTopologyWithProgressBar(“topology-name”, conf, builder.createTopology());
那么问题是:
setNumWorkers 应该取多少?取决于哪些因素?
kafkaSpout 的并行度应该取多少?取决于哪些因素?
FilterBolt 的并行度应该取多少?取决于哪些因素?
AlertBolt 的并行度应该取多少?取决于哪些因素?
FilterBolt 用 shuffleGrouping 是最好的吗?
AlertBolt 用 fieldsGrouping 是最好的吗?
回答如下:
第一个问题:关于 worker 的并行度:worker 可以分配到不同的 supervisor 节点,这也是 Storm 实现多节点并行计算的主要配置手段。据此, workers 的数量,可以说是越多越好,但也不能造成浪费,而且也要看硬件资源是否足够。所以主要考虑集群各节点的内存情况:默认情况下,一个 worker 分配 768M 的内存,外加 64M 给 logwriter 进程;因此一个 worker 会耗费 832M 内存;题设的集群有3个节点,每个节点4G内存,除去 linux 系统、kafka、zookeeper 等的消耗,保守估计仅有2G内存可用来运行 topology,由此可知,当集群只有一个 topology 在运行的情况下,最多可以配置6个 worker。
另外,我们还可以调节 worker 的内存空间。这取决于流过 topology 的数据量的大小以及各 bolt 单元的业务代码的执行时间。如果数据量特别大,代码执行时间较长,那么可以考虑增加单个 worker 的工作内存。有一点需要注意的是,一个 worker 下的所有 executor 和 task 都是共享这个 worker 的内存的,也就是假如一个 worker 分配了 768M 内存,3个 executor,6个 task,那么这个 3 executor 和 6 task 其实是共用这 768M 内存的,但是好处是可以充分利用多核 CPU 的运算性能。
总结起来,worker 的数量,取值因素有:
节点数量,及其内存容量
数据量的大小和代码执行时间
机器的CPU、带宽、磁盘性能等也会对 Storm 性能有影响,但是这些外在因素一般不影响 worker 数量的决策。
需要注意的是,Storm 在默认情况下,每个 supervisor 节点只允许最多4个 worker(slot)进程运行;如果所配置的 worker 数量超过这个限制,则需要在 storm 配置文件中修改。
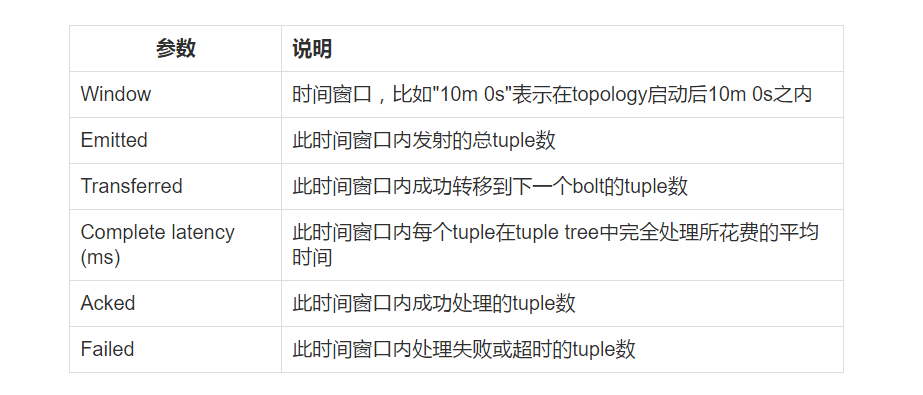
第二个问题:关于 FilterBolt 的并行度:如果 spout 读取的是 kafka 的数据,那么正常情况下,设置为 topic 的分区数量即可。计算 kafkaSpout 的最佳取值,有一个最简单的办法,就是在 Storm UI里面,点开 topology 的首页,在 Spouts (All time) 下,查看以下几个参数的值:
Emitted 已发射出去的tuple数
Transferred 已转移到下一个bolt的tuple数
Complete latency (ms) 每个tuple在tuple tree中完全处理所花费的平均时间
Acked 成功处理的tuple数
Failed 处理失败或超时的tuple数
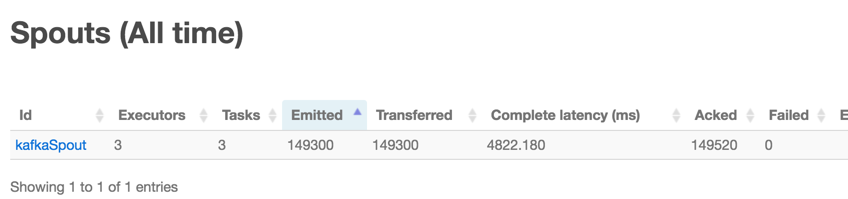
怎么看这几个参数呢?有几个技巧:
正常情况下 Failed 值为0,如果不为0,考虑增加该 spout 的并行度。这是最重要的一个判断依据;
正常情况下,Emitted、Transferred和Acked这三个值应该是相等或大致相等的,如果相差太远,要么该 spout
负载太重,要么下游负载过重,需要调节该 spout 的并行度,或下游 bolt 的并行度;
Complete latency (ms) 时间,如果很长,十秒以上就已经算很长的了。当然具体时间取决于代码逻辑,bolt
的结构,机器的性能等。
kafka 只能保证同一分区下消息的顺序性,当 spout 配置了多个 executor 的时候,不同分区的消息会均匀的分发到不同的 executor 上消费,那么消息的整体顺序性就难以保证了,除非将 spout 并行度设为 1
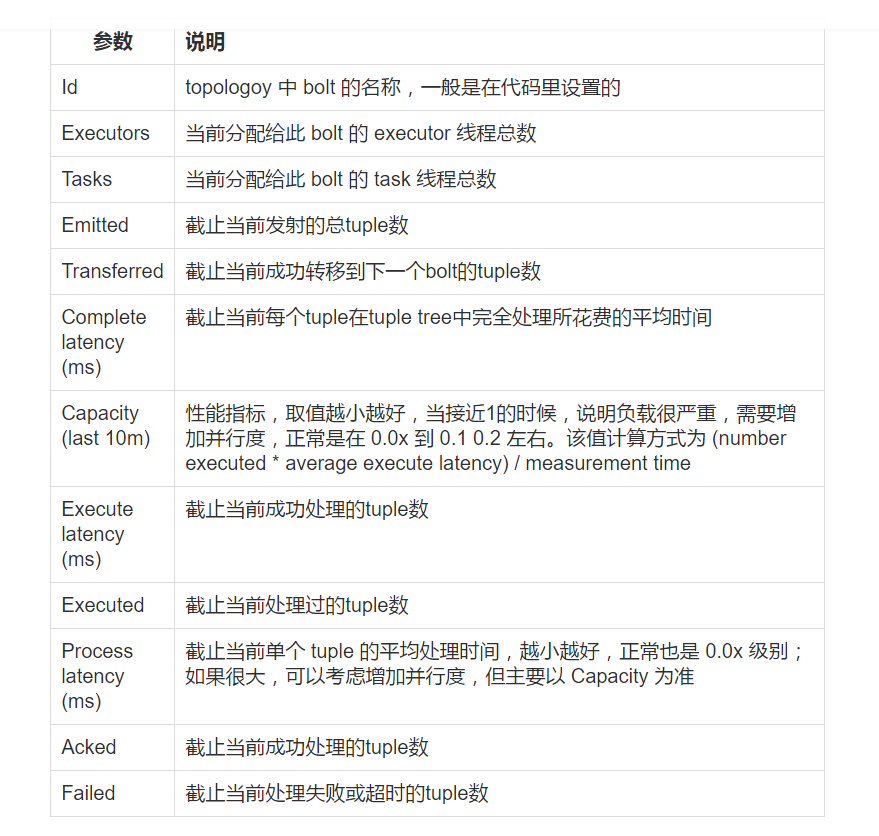
第三个问题:关于 FilterBolt 的并行度:其取值也有一个简单办法,就是在 Storm UI里面,点开 topology 的首页,在 Bolts (All time) 下,查看以下几个参数的值:
Capacity (last 10m) 取值越小越好,当接近1的时候,说明负载很严重,需要增加并行度,正常是在 0.0x 到 0.1
0.2 左右
Process latency (ms) 单个 tuple 的平均处理时间,越小越好,正常也是 0.0x
级别;如果很大,可以考虑增加并行度,但主要以 Capacity 为准
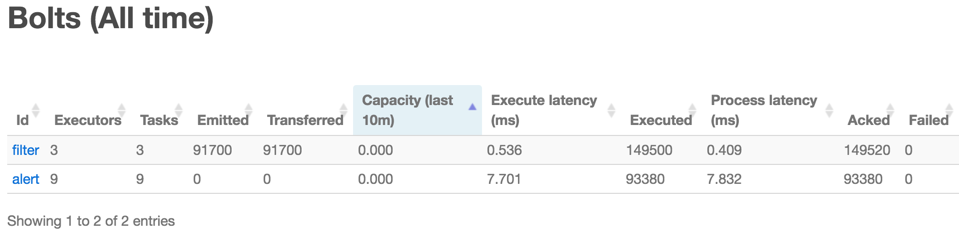
一般情况下,按照该 bolt 的代码时间复杂度,设置一个 spout 并行度的 1-3倍即可。
第四个问题:AlertBolt 的并行度同 FilterBolt。
第五个问题:shuffleGrouping 会将 tuple 均匀地随机分发给下游 bolt,一般情况下用它就是最好的了。
总之,要找出并行度的最佳取值,主要结合 Storm UI 来做决策。
4、优化配置参数
/* tuple发送失败重试策略,一般情况下不需要调整 /
spoutConfig.retryInitialDelayMs = 0;
spoutConfig.retryDelayMultiplier = 1.0;
spoutConfig.retryDelayMaxMs = 60 * 1000;
/* 此参数比较重要,可适当调大一点 /
/* 通常情况下 spout 的发射速度会快于下游的 bolt 的消费速度,当下游的 bolt 还有 TOPOLOGY_MAX_SPOUT_PENDING 个 tuple 没有消费完时,spout 会停下来等待,该配置作用于 spout 的每个 task。 /
conf.put(Config.TOPOLOGY_MAX_SPOUT_PENDING, 10000)
/* 调整分配给每个 worker 的内存,关于内存的调节,上文已有描述 /
conf.put(Config.WORKER_HEAP_MEMORY_MB, 768);
conf.put(Config.TOPOLOGY_WORKER_MAX_HEAP_SIZE_MB, 768);
/* 调整 worker 间通信相关的缓冲参数,以下是一种推荐的配置 /
conf.put(Config.TOPOLOGY_RECEIVER_BUFFER_SIZE, 8); // 1.0 以上已移除
conf.put(Config.TOPOLOGY_TRANSFER_BUFFER_SIZE, 32);
conf.put(Config.TOPOLOGY_EXECUTOR_RECEIVE_BUFFER_SIZE, 16384);
conf.put(Config.TOPOLOGY_EXECUTOR_SEND_BUFFER_SIZE, 16384);
可以在 Storm UI 上查看当前集群的 Topology Configuration
5、rebalance
可以直接采用 rebalance 命令(也可以在 Storm UI上操作)重新配置 topology 的并行度:
storm rebalance TOPOLOGY-NAME -n 5 -e SPOUT/BOLT1-NAME=3 -e SPOUT/BOLT2-NAME=10
原文:https://blog.csdn.net/qq_36864672/article/details/86068356

 浙公网安备 33010602011771号
浙公网安备 33010602011771号