Redis(四)面试题
Redis和memcached区别?
Redis支持更多的数据结构和支持更丰富的数据操作


Redis线程模型?
文件事件处理器

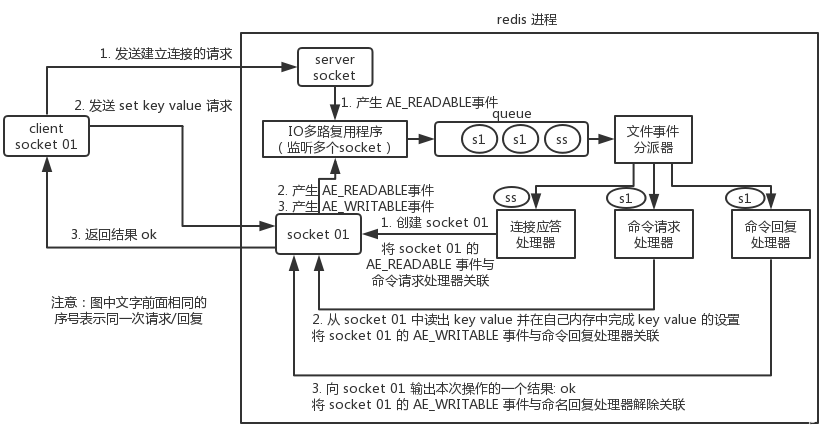
为什么单线程的Redis比多线程的memcached效率要高得多(为什么reids是单线程的还可以支持高并发)?
- 存内存操作
- 核心是基于非阻塞的IO多路复用操作(监听Socket连接,将连接放入队列,不做其他操作)
- 单线程反而避免了多线程频繁上下文切换问题
- 1秒可以处理几万条数据
Redis分布式锁和ZK锁区别?

一般缓存使用模式? Cache Aside Pattern
1.读的时候,先读缓存,缓存没有,读数据库,同时将数据放入缓存,同时响应返回
2.更新的时候,先删除缓存,然后在更新数据库
为什么不更新缓存,而直接删除缓存?
可能缓存里面存的数据需要好几个表复杂的计算出来存进去的,有可能这个数据被修改了1分钟内被修改了100次,而1分钟内查询确执行了一次,这样就更耗性能了。
懒加载思想,用的时候在加载
缓存与数据库双写不一致?
1.先删除缓存,在更新数据库,如果数据库更新失败,数据库一样是原数据,而缓存为空再次读取的时候会设置缓存没有不一致的情况。
并发情况导致数据不一致?(只有在并发的时候才会发生)
先删除缓存,在更新数据库,并发
伪代码
del 缓存
update 数据库
线程1 del缓存,然后线程被挂起,线程2 读取缓存,没有读取到,读取数据库填充缓存 数据为1000
线程1 继续执行,将数据更新为999,此时数据库和缓存不一致 缓存为1000,而数据库为999
更新与读取进行串行化?
将请求操作放入队列里面:如 线程1来 更新数据,del 入队了,update 数据库入队列,线程2来读缓存,读缓存入队列,根据实际情况测试,是否会有大量的读取操作直接读取数据库。这样吞吐量不高!
Redis是怎么部署的?
10台机器 5台master ,每个master 有一个slave,任何一个 主实例宕机,都会自动故障迁移,Redis从实例自动变成主,提供继续读写服务。
Redis存储的是什么数据?每条数据的大小?
Redis机器是什么配置?
32G+8核cpu+1T磁盘,分配给Redis进程的是10g内存,5台机器对外提供读写,所有总内存是50G
Redis淘汰策略有哪些?
Redis设置key过期策略是如何删除的?
定期删除+惰性删除(两种方案结合保证过期的key一定会被删除掉)
定期删除:Redis每隔一段时间随机抽取设置过期时间的key,检查是否过期,过期就删除。(会导致很多过期的key到了时间没有被删除)
惰性删除:在获取key的时候,Redis会检查一下,判断key是否设置了过期时间,如果key过期就删除
如果定期删除,遗漏了很多key,而这个key并没有被查询,会导致大量key留存在内存中,导致Redis内存耗尽?内存淘汰机制
从库的过期策略
从库不会进行过期扫描,从库对过期的处理是被动的。主库在 key 到期时,会在 AOF 文件里增加一条 del 指令,同步到所有的从库,从库通过执行这条 del 指令来删除过期的 key。
因为指令同步是异步进行的,所以主库过期的 key 的 del 指令没有及时同步到从库的话,会出现主从数据的不一致,主库没有的数据在从库里还存在。
内存淘汰机制
Redis的内存占用过多的时候,Redis会进行内存淘汰
淘汰策略:
- noeviction:当内存不足以容纳新写入数据时,新写入操作会报错
- allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key(这个是最常用的)
- allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key,
- volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key
- volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key
- volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除
手写LRU?
public class LRUCache<K,V>extends LinkedHashMap<K,V>{ private final int CACHE_SIZE=20; public LRUCache(int cacheSize){ //设置一个hashmap的初始大小,同时最后一个ture指的是让linkhashmap按照访问顺序来进行排序,最近访问的放在头,最老访问的在末尾。
//LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder)
super(int)Math.cell(cacheSize/0.75)+1,0.75f,true);
} @Override protected boolean removeEldestEntry(Map.Entry eldest){ // 当map中的数据量大于指定的缓存个数时,自动删除最老的数据 return size()>CACHE_SIZE } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号