
Django基于正则表达式的URL
Django基于正则表达式的URL(2)
1. 关于正则的说明
url(r'^detail-(\d+)-(\d+).html',views.detail), 当客户端输入 127.0.0.1:8000/detail-2-9.html时,Django默认可以得到3个参数,分别是request,
-(\d+)-,-(\d+)-。 所以定义detail函数的时候,需要把这3个参数都接收,否则会报错。当然了是严格按照顺序来写/获取到的。
def detail(request,nid,uid):
print(nid,uid)

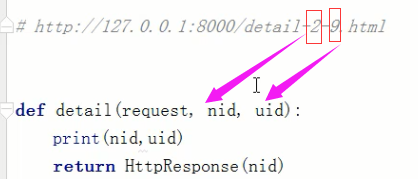
2.默认情况下是严格按照顺序来获取得。但是如果想调整形式参数的时候,就会影响到整个程序。基于此,Django还支持正则表达式的分组。
把第1个匹配的赋值给nid,把第2个匹配的赋值给uid.
url(r'^detail-(?P<nid>\d+)-(?P<uid>\d+).html',views.detail),
分组写的好处是,下列2个函数就无区别了。形式参数的位置不会影响代码的值。
def detail(request,nid,uid)
def detail(request,uid,nid)

3. args:接收的是元组
kwargs:接收的是字典类型的。

4.本节笔记
|
1
2
3
4
5
6
7
8
9
10
11
12
|
一,路由系统,URL 1.一个URL对应一个函数或者对应一个类 url(r'^index/',views.index),url(r'^home/',views.Home.as_view()), 2.一类URL对应一个函数或类 url(r'^detail-(\d+)-(\d+).html',views.index), 严格按照形式参数的位置给它传递的。 3.一类URL对应一个函数或类(用正则表达式的方法来做)推荐使用的。 url(r'^detail-(?P<nid>\d+)-(?P<uid>\d+).html',views.index), 形式参数的位置不影响值。 传递参数的时候,是按照nid=1,uid=9,的样式传递的。 def detail(request,*args,**kwargs) #args元组,kwargs字典。 如果是以url(r'^detail-(\d+)-(\d+).html',views.index)的形式传递的话,则都传到args里面了。因为传递形式是:1,2的格式。 如果是以url(r'^detail-(?P<nid>\d+)-(?P<uid>\d+).html',views.index)的形式的话,都传到kwargs里。因为传递形式是:nid=1,uid=2的格式 |

1. 使用GET请求获得参数时,斜杠(/)、句点(.)一般不可取到字符串参数内。一串“/”隔开的url取参数需要每个单独取。如:

image.png
2. django2.0中,使用正则表达式进行路由的话需要使用re_path()
from django.urls import path, re_path
from . import views
urlpatterns = [
re_path('^hello/$', views.hello),
re_path('^hello/(?P<yy>[0-9]+)/', views.hello),
]
匹配头用尖号^

匹配头
匹配尾用$

匹配尾和匹配变量
匹配变量:
字符串:(?P<prm>\w+)
数字:(?P<int>\d+)
类型、个数匹配:(?P<p>[0-9]{4}) //4个0-9的数字

匹配数字及个数
附:正则表达式用法小结
#正则表达式:
# 元字符: \w \d \s \n \t \W \S \D \b ^ 尖角号 $ . [] [^] () |
# [0-9] \d
# [1-9]
# [\da-zA-Z]
#. :匹配除换行符"\n"以外的任意字符
#\ :转义字符,使后一个字符改变原来的意思.如果字符串中有字符*需要匹配,可以使用\*或者字符集{*}
#[...]:字符集,对应的位置可以是字符集中任意字符.字符集中的字符可以逐个列出,也可以给出范围,如[abc]
#或者是[a-c],第一个字符如果是^,则表示取反,如[^abc]表示不是abc的其他字符.所有的特殊字符在字符集中
# 都失去其原有的特殊含义.在字符集中如果要使用].-或^,可以在前面加上反斜杠,或者把],-放在第一个字符,把^
#放在非第一个字符
#\d 数字:[0-9]
#\D 非数字:[^\d]
#\s 空白字符:[<空格> \t\r\n\f\v]
#\S 非空白字符:[^\s]
#\w 单词字符:[0-9a-zA-Z_]包括了数字字母下划线
#\W 非单词字符:[^\w]
#量词 : {n} {n,} {n,m} * ? +
#* :匹配前一个字符0或无限次 abc*
#+:匹配前一个字符1次货无限次. abc+
#?:匹配前一个字符0次或1次. abc?
#{n}:匹配前一个字符n次 ab{2}c 匹配字符:abbc
#{n,}:至少匹配n次,至无限次
#{n,m}:匹配前一个字符n到m次 ab{1,2}c 匹配字符abc,abbc
#*?, +?, ?? {m,n}?,使* + ? {m,n}变成非贪婪模式
#边界匹配:
#^ :匹配字符串开头,
# 在多行模式中匹配每一行的开头. ^abc 匹配字符abc
#$ :匹配字符串末尾,
# 在多行模式中匹配每一行的末尾. abc$ 匹配字符abc
#\A 仅匹配字符串开头 \Aabc 匹配字符abc
#\Z 仅匹配字符串末尾 abc\Z 匹配字符abc
#\b 匹配\w和\W之间 a\b!bc a!bc
# |:|代表左右表达式任意匹配一个.它总是先尝试匹配左边的表达式
#一旦左边的表达式成功匹配则跳过右边的表达式
#如果|没有被包括在()中,则它的范围是整个正则表达式 abc|def
#(...) :被括起来的表达式将作为分组,从表达式左边开始每遇到
#一个分组的左括号"(",编号+1.另外,分组表达式作为一个整体,可以接数量词.
#表达式中的|仅在该组有效.
#(?P<name>...):分组,除了原有的编号外再指定一个额外的别名.
#\<number>:引用编号为<number>的分组匹配到的字符串. (\d)abc\1
#(?P = name):引用别名为<name>的分组匹配到的字符串
#转义符:
# python str : '\'
# 正则表达式中的'\'到了python中都会变成'\\'
# r'\w' 在python当中\不转义了,在Python中就是一个普通的'\',但是在正则表达式中它还是表示一个转义符
# 贪婪匹配/惰性匹配 :
# .*x 贪婪 匹配任意内容最多次,直到最后一个X停止 回溯算法
# .*?X 惰性 匹配任意内容最少次,遇到第一个X就停止
# re模块
# findall 匹配所有 列表
# search 匹配第一个 变量.group(),没匹配到返回None
# match 从头开始匹配第一个
# split sub subn
# finditer compile
# finditer 返回一个迭代器,所有匹配到的内容需要迭代取到,迭代取到的每一个结果都需要group取具体值
# -- 节省内存空间
# compile 编译,先把一个正则表达式编译,编译之后,在之后多次使用的过程不用重新编译
# -- 节省时间 提高效率
# 分组:()
# 1.给不止一个字符的整体做量词约束的时候 www(\.[\w]+)+ www.baidu.com
# 2.优先显示,当要匹配的内容和不想匹配的内容混在一起的时候,
# 就匹配出所有内容,但是对实际需要的内容进行分组
# 3.分组和re模块中的方法 :
# findall : 分组优先显示 取消(?:正则)
# search :
# 可以通过.group(index)来取分组中的内容
# 可以通过.group(name)来取分组中的内容
# 正则 (?P<name>正则)
# 使用这个分组 ?P=name
# split : 会保留分组内的内容到切割的结果中
 浙公网安备 33010602011771号
浙公网安备 33010602011771号