BUAA OO UNIT 4 UML解析器单元总结
BUAA OO UNIT4 UML解析器单元总结
架构设计
总的思路就是以id为key,以uml元素的相关信息为value,用一个HashMap做数据结构,再以此为基础实现所需功能。
hw13
通过加入 Info 类来存储有关信息,进而实现所有功能,为通用性而适度牺牲了空间利用率。所有uml元素存储在同一个HashMap里。
由于数据量较小,解析器类在初始化时仅负责建图,所有功能均为在线计算。
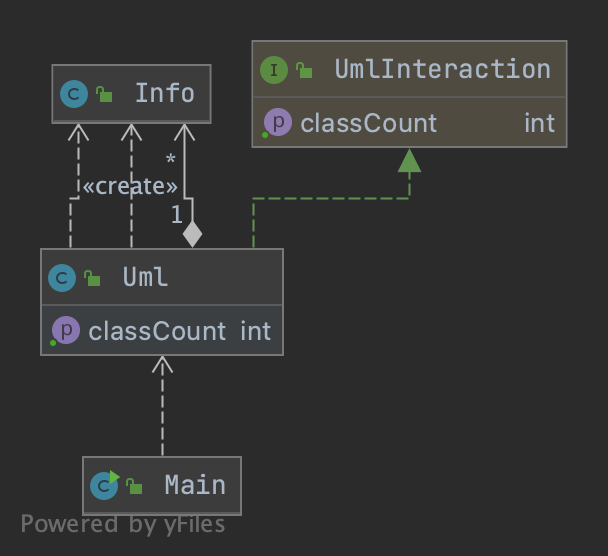
hw14
将解析器拆成类图解析器、时序图解析器、状态机解析器,在顶层合并为统一的UML解析器。仍然使用同一个共享的HashMap,初始化时使用建造者模式,每个子解析器各自建图。时序图和状态机复用了类图解析器所使用的 Info 类。
仍然在线计算。
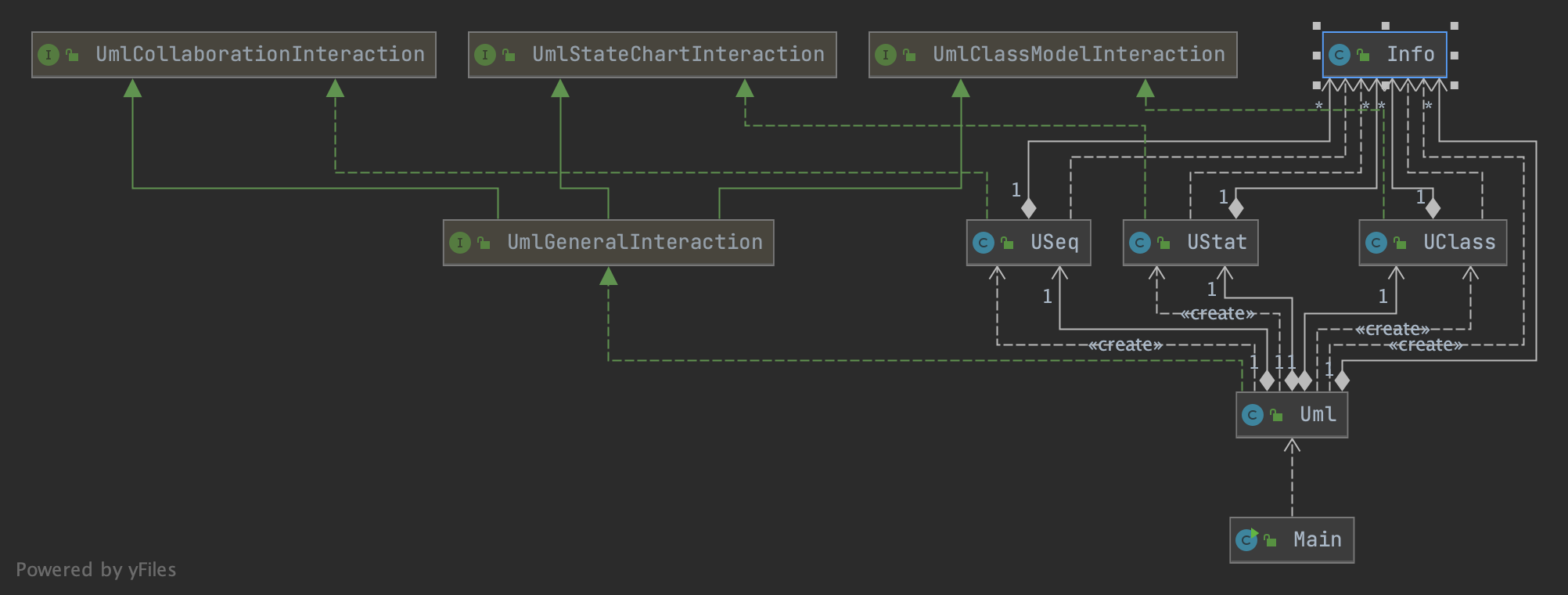
hw15
在顶层UML解析器中实现R001~R008的检查,其中R002使用了tarjan算法。
仍然在线计算。
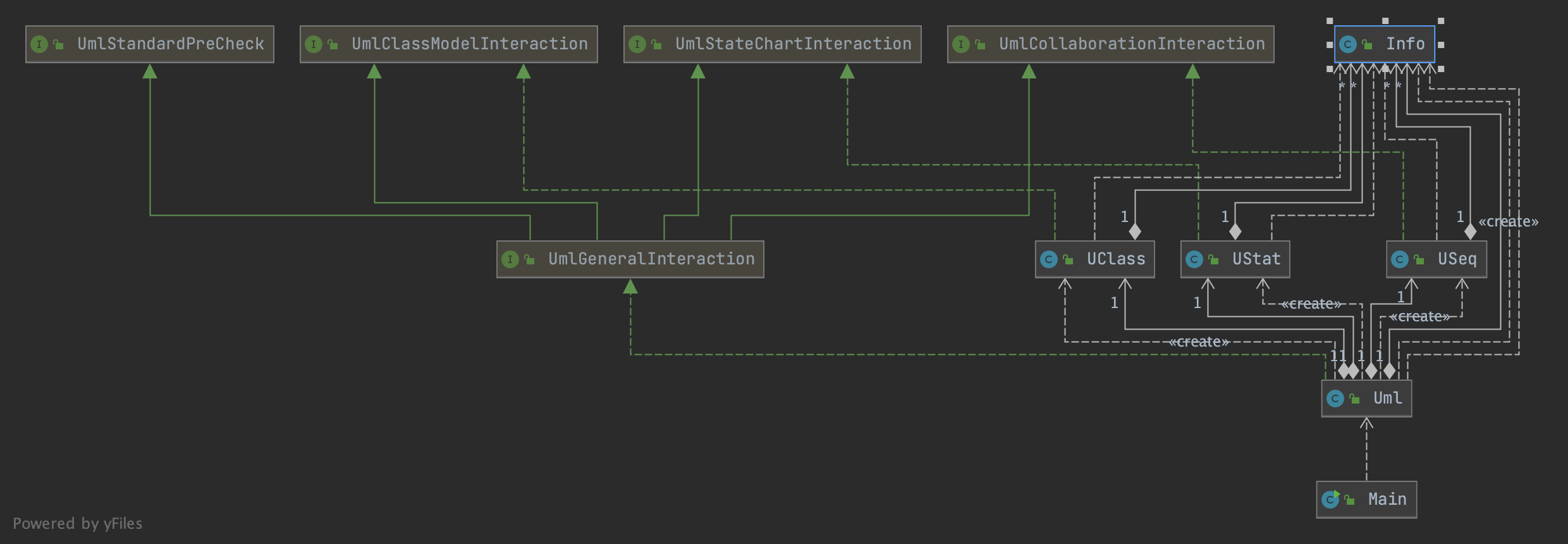
架构与OO方法
- UNIT 1
- 开学第一课:第一次作业省事的后果非常严重
- 可以利用数据自身的性质简化架构,提升性能:利用加法和乘法的交换律,以累加和、连乘积替代加法和乘法,用很小的工作量就实现了较好的化简效果
- UNIT 2
- 九九归一,原来可以一个算法打天下:通过一些对贪心算法的修改,使得它在每种模式下都逼近该模式下的最优解。或者说,使它具备了每种模式的优点。
- 好的架构需要对编程语言的深入了解:我的架构实现需要依靠trylock(),在知道有trylock()之前存在线程安全问题
- UNIT 3
- JML是OO课里最友好的语言,没有之一!!!
(破音) - JML显著提高了助教们的写作水平,让架构设计更轻松,正确性更容易保证。所有的方法只需按JML实现,并维护一些数据以免重复计算即可。
- JML是OO课里最友好的语言,没有之一!!!
- UNIT 4
没有了JML助教们的写作水平瞬间变回原形……- 简单通用的架构可以行之有效,为此牺牲一些性能、产生一些冗余可以接受
总的来说,与其简单地把问题归结为结构和性能,我更愿意具体问题具体分析,考虑哪些具体的实现是方便快捷简洁的。在四个单元的作业中,OO的思想和方法总是自然地、逐渐地体现在代码中。
测试
血的教训表明,提交前做足测试是活过强测和互测的关键。
自动评测机
四个单元的任务中,我和其他几个同学一起攒了自动评测机,并随着课程推进而不断完善,最终形成了支持多包编译、多进程运行、多人答案比对、自动邮件报文等特性的完成度较高的评测机。
- 多包编译 Since UNIT 1
- 使用GitHub开源项目_Windows-BudgetGrep_作为文件搜索引擎,遍历仓库中的所有java文件,通过正则表达式匹配实现自动找主类。
实际运行中还发现并向原作者反馈了一个bug - 在第二、三单元中进一步完善了对依赖的支持。
- 使用GitHub开源项目_Windows-BudgetGrep_作为文件搜索引擎,遍历仓库中的所有java文件,通过正则表达式匹配实现自动找主类。
- 多进程 Since UNIT 2
- 这一部分在第二单元是室友完成的,我在第三单元做了一些改造,使它更适合单线程程序的运行,并修复了疑似杀TLE失败的bug。
- 答案比对 Since UNIT 3
- 后两个单元难以通过简单手段生成标准答案,但对拍却很容易,因此我们实现了对拍器。由于一起攒评测机的另一位同学的对拍器比我的更完善,所以采用了她的。
- 邮件报文 Since UNIT 4
- 第三单元的时候我们就已经形成了军理课前开评测机,军理课后回寝室查看结果的节奏,我就想能不能更进一步,支持邮件报文,省去回寝室然后通知大家的步骤。这实际上是第一单元就有的想法,只不过到最后一单元才真正得到实施。
- 邮件报文并不难实现,主要的难点在于如何不让网易把报文识别成垃圾邮件导致退信。在查找了一些资料后我解决了这个问题,现在,邮件系统可以在每跑完4k个测试点后发送报文,报告WA掉的测试点编号和答案分布。同时,我加入了自动署名机制,通过获取当前电脑用户名,使我们得以辨别一组测试点来自谁的电脑。
最终实现了像挖矿一样 把电脑丢在寝室即可的自动化测试,有效提升了代码质量,有效降低了作业完成用时。
数据生成器
一直以来,在怎么写数据生成器上,我跟我室友走的是旗帜鲜明的两条道路:我尝试增大生成器随机到各种数据的概率,而我室友则试图手工枚举所有的情况。
这两条路线互有优劣,他的生成器在第三单元能快速暴露被测代码的大量问题,而我的生成器则常常在第四单元的后半夜给人带来惊喜。第15次作业中,我们甚至出现过在测试点15652中第一次暴露的bug。
具体而言,我的思路是定向构造一些特定的结构,使得出现强数据的可能性升高。第一单元我的生成器先生成不带括号的多项式,再向里面随机添加括号,实现高强度。第三单元生成测dijktra算法的数据时,我先生成数个彼此独立的连通块,再随机在连通块之间加几条边,实现了多路径、长路径的结合。第四单元构造继承关系时先构造一条长链,再让后来的类随机连接到当前的图里,形成保证有一棵深度很大的树的森林,接口也是同理,只不过继承的方向调换一下。生成错误数据时只需要向其中随机加入一些边或者随机修改一些边即可。
课程收获
很难说我到底收获了什么。
我可能收获了朋友关系,一起攒评测机一起对拍体验很好。
我可能收获了git的熟练度,从一开始啥都不会到现在 git reset --soft 稀松平常。
我可能收获了一个评测机,四个博客和一堆代码。
可是然后呢?
OO课耗费了我太多时间
也许这么大的投入能够让OO方法、架构思维或是单元测试在我脑海里留下更深的印象?
也许这么多的付出能够在将来的不知道某一天得到或多或少的回报?
很难说,也许吧
三个建议
1. 使用更清晰明确的措辞
尽管助教们可能是为了模拟真实的需求场景而故意写得模棱两可叫人雾里看花,但无可否认的是,这样的指导书并没有让我们更好地学习和思考OO方法和架构设计,反而因为大量的待确认点而给我们增添了不必要的麻烦。例如,在刚刚过去的第15次作业中,指导书出现了这样一句话:
其成员属性(UMLAttribute)和关联对端所连接的UMLAssociationEnd 均不能有重名
这句话隐含两重语义:
UMLAttribute不能重名,且UMLAssociationEnd不能重名
UMLAttribute不能重名,且UMLAssociationEnd不能重名,
且UMLAttribute不能与UMLAssociationEnd重名
我不认为为了这样一句话而去讨论区为了助教的仍然可能是模棱两可的回答而等待几个小时应该成为OO课程的一部分,在这种事情上耗费宝贵的精力无疑挤压了本应花在其他课程上的时间。
2. 缩短互测数据的刷新周期
互测数据的评测不太可能是以半小时为周期统一评测的,因此缩短刷新周期没有技术障碍;要更新互测数据,服务器只需要发送非常少的文本信息,不会产生多大的压力,也不会增加很多成本。但更快的刷新频率能够使同学更及时地知道测试用例是否有效,减少了重复构造数据的负担,同时降低因刷新周期原因而重复hack的概率。
3. 缩减互测时间
设计互测环节的本意是希望同学们通过互相阅读代码来相互学习共同进步,然而事实上互测已经几乎变成了大型内卷现场和自动评测机的狂欢。通过缩减互测时间,而互测结束后允许下载其他同学代码的时长不变,或许能让互测回归原本的目的。
当然,如果课程组原本的用意就在于通过互测环节增大内卷程度,那就当我没说好了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号