

作业二
| 这个作业属于哪个课程 | 课程链接 |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 | 学习论文查重方法, 接触PSP |
仓库地址
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | 155 | 155 |
| · Analysis | · 需求分析 (包括学习新技术) | 30 | 20 |
| · Design Spec | · 生成设计文档 | 10 | 10 |
| · Design Review | · 设计复审 | 10 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 5 | 5 |
| · Design | · 具体设计 | 30 | 40 |
| · Coding | · 具体编码 | 30 | 30 |
| · Code Review | · 代码复审 | 10 | 10 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 40 | 40 |
| Reporting | 报告 | 45 | 45 |
| · Test Repor | · 测试报告 | 20 | 20 |
| · Size Measurement | · 计算工作量 | 5 | 5 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 20 |
| · 合计 | 220 | 220 |
计算模块接口的设计与实现过程
1. 模块设计目标
计算模块的核心目标是计算两段文本的相似度。为了实现这一目标,模块需要具备以下功能:
- 读取文件内容
- 对文本进行预处理(如去除标点符号、空白字符等)。
- 计算两段文本的最长公共子序列(LCS)
- 根据 LCS 计算相似度
- 将结果写入输出文件。
2. 代码组织
计算模块的代码组织如下:
类设计:
- PlagiarismChecker:主类,负责程序的入口和整体流程控制。
- TextProcessor:负责文本的预处理。
- LCSCalculator:负责计算最长公共子序列(LCS)。
- SimilarityCalculator:负责根据 LCS 计算相似度。
- FileIO:负责文件的读取和写入。
函数设计:
- PlagiarismChecker.main():程序入口,负责调用其他模块完成查重任务。
- TextProcessor.preprocess():对文本进行预处理。
- LCSCalculator.calculateLCS():计算两段文本的 LCS 长度。
- SimilarityCalculator.calculateSimilarity():根据 LCS 长度计算相似度。
- FileIO.readFile():读取文件内容。
- FileIO.writeResult():将结果写入文件。
3. 类与函数的关系
PlagiarismChecker 是主类,负责协调其他类的功能。
FileIO 类负责文件的读写,为 TextProcessor 提供原始文本数据。
TextProcessor 类对原始文本进行预处理,为 LCSCalculator 提供干净的文本数据。
LCSCalculator 类计算两段文本的 LCS 长度,为 SimilarityCalculator 提供基础数据。
SimilarityCalculator 类根据 LCS 长度计算相似度,并将结果返回给 PlagiarismChecker。
4. 算法关键
文本预处理:
使用正则表达式去除标点符号和空白字符,只保留中文、字母和数字。
例如,将 "今天是星期天,天气晴。" 预处理为 "今天是星期天天气晴"。
最长公共子序列(LCS):
使用动态规划算法计算两段文本的 LCS 长度。
动态规划表 dp[i][j] 表示文本 1 的前 i 个字符和文本 2 的前 j 个字符的 LCS 长度。
状态转移方程:
如果 text1[i-1] == text2[j-1],则 dp[i][j] = dp[i-1][j-1] + 1。
否则,dp[i][j] = max(dp[i-1][j], dp[i][j-1])。
相似度计算:
使用对称相似度公式:similarity = (2 * LCS长度) / (文本1长度 + 文本2长度) * 100。
该公式考虑了两种文本的长度差异,避免了单方面偏向较长或较短文本的问题。
5. 独到之处
高效的文本预处理:使用正则表达式快速去除无关字符,确保 LCS 计算的准确性; 支持中英文混合文本的处理。
动态规划优化:使用动态规划算法计算 LCS,时间复杂度为 O(mn),其中 m 和 n 分别是两段文本的长度。对于较长的文本,可以通过滚动数组优化空间复杂度,将空间复杂度从 O(mn) 降低到 O(min(m, n))。
对称相似度公式:采用对称相似度公式,避免了对较长文本或较短文本的偏向性。例如,对于文本 "ABC" 和 "ABCD",相似度为 (23)/(3+4)100 ≈ 85.71%,而不是简单的 3/4*100 = 75%。
模块化设计:将文件读写、文本预处理、LCS 计算和相似度计算分离到不同的类中,便于扩展和维护。例如,如果需要支持其他语言的文本预处理,只需修改 TextProcessor 类,而不影响其他模块。
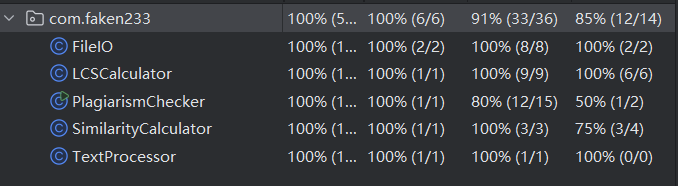
计算模块部分单元测试展示
@Test
void testMain() throws IOException {
// 准备测试文件
String originalFilePath = "original.txt";
String copiedFilePath = "copied.txt";
String outputFilePath = "output.txt";
try (FileWriter writer1 = new FileWriter(originalFilePath);
FileWriter writer2 = new FileWriter(copiedFilePath)) {
writer1.write("今天是星期天,天气晴,今天晚上我要去看电影。");
writer2.write("今天是周天,天气晴朗,我晚上要去看电影。");
}
// 运行主程序
PlagiarismChecker.main(new String[]{originalFilePath, copiedFilePath, outputFilePath});
// 验证输出文件内容
try (BufferedReader reader = new BufferedReader(new FileReader(outputFilePath))) {
String line = reader.readLine();
assertEquals("77.78%", line);
}
// 清理测试文件
new File(originalFilePath).delete();
new File(copiedFilePath).delete();
new File(outputFilePath).delete();
}
@Test
void testCalculateLCS() {
// 测试相同字符串
String text1 = "ABC";
String text2 = "ABC";
assertEquals(3, LCSCalculator.calculateLCS(text1, text2));
// 测试部分相同
text1 = "ABCDEF";
text2 = "AEBDF";
assertEquals(4, LCSCalculator.calculateLCS(text1, text2));
// 测试完全不同
text1 = "ABC";
text2 = "DEF";
assertEquals(0, LCSCalculator.calculateLCS(text1, text2));
// 测试空字符串
assertEquals(0, LCSCalculator.calculateLCS("", "ABC"));
assertEquals(0, LCSCalculator.calculateLCS("ABC", ""));
assertEquals(0, LCSCalculator.calculateLCS("", ""));
}
异常
文件读取异常IOException
处理文件读取过程中可能出现的错误,例如文件不存在、文件权限不足或文件损坏。
处理方式:捕获 IOException,并输出友好的错误信息,避免程序崩溃。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号