Spark实验
1. 环境配置(Spark伪分布式安装)
1.1 虚拟机配置
处理器:4核
内存:4G
硬盘:40G
用户名:spark
主机名:ubuntu-vm
操作系统:Ubuntu 22.04.5-desktop
1.2 apt换源
sudo mv /etc/apt/sources.list /etc/apt/sources.list.bak
sudo gedit /etc/apt/sources.list
备份原来的源,然后编辑文件添加新源,镜像源见附件。
换源后更新软件
sudo apt-get update
sudo apt-get upgrade
1.3 Java安装
sudo apt install openjdk-8-jdk
java -version
# 查找Java安装路径
sudo update-alternatives --config java
JAVA_HOME需指向JDK根目录,而非jre/bin/java,因此需截取路径至/usr/lib/jvm/java-8-openjdk-amd64。
使用gedit ~/.bashrc编辑~/.bashrc,添加Java相关环境变量,然后使用source ~/.bashrc加载配置。
# Java
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=$PATH:$JAVA_HOME/bin
1.4 安装SSH并配置免密登录
#安装SSH Server
sudo apt install openssh-server
# 启动ssh
sudo service ssh start
# 设置开机⾃启
sudo systemctl enable ssh
# 确认是否设置开机⾃启成功
sudo systemctl is-enabled ssh
安装好后使用ssh localhost登录,默认需要密码,执行下面的命令后可免密登录。
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
1.5 Hadoop安装
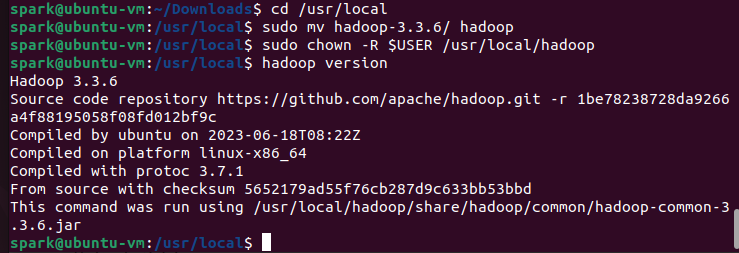
从https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz下载hadoop-3.1.3.tar.gz到~/Downloads,解压到/usr/local后改名并修改权限。
cd ~/Downloads
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
sudo tar -zxvf hadoop-3.3.6.tar.gz -C /usr/local #解压到/usr/local
cd /usr/local
sudo mv hadoop-3.3.6/ hadoop #修改文件夹名称
sudo chown -R $USER /usr/local/hadoop/ # 修改文件夹权限
接着执行gedit ~/.bashrc,在文件末尾添加Hadoop相关环境变量,然后执行source ~/.bashrc加载变量。
# Hadoop
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
执行hadoop version查看Hadoop版本,检查可用性。
接着cd到/usr/local/hadoop,编辑Hadoop相关配置文件。
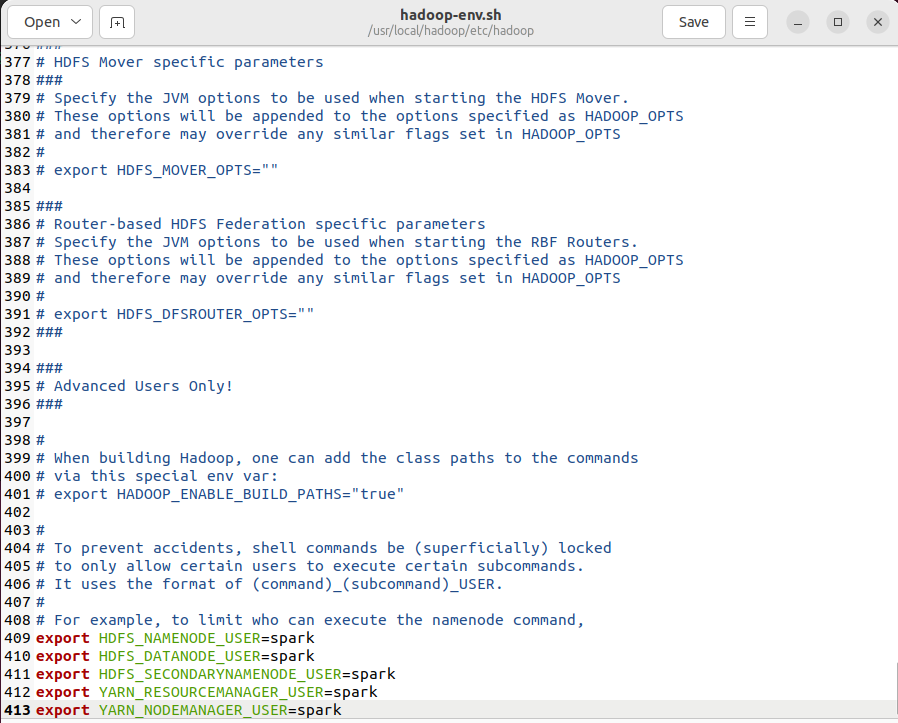
执行gedit etc/hadoop/hadoop-env.sh,添加附件内容。
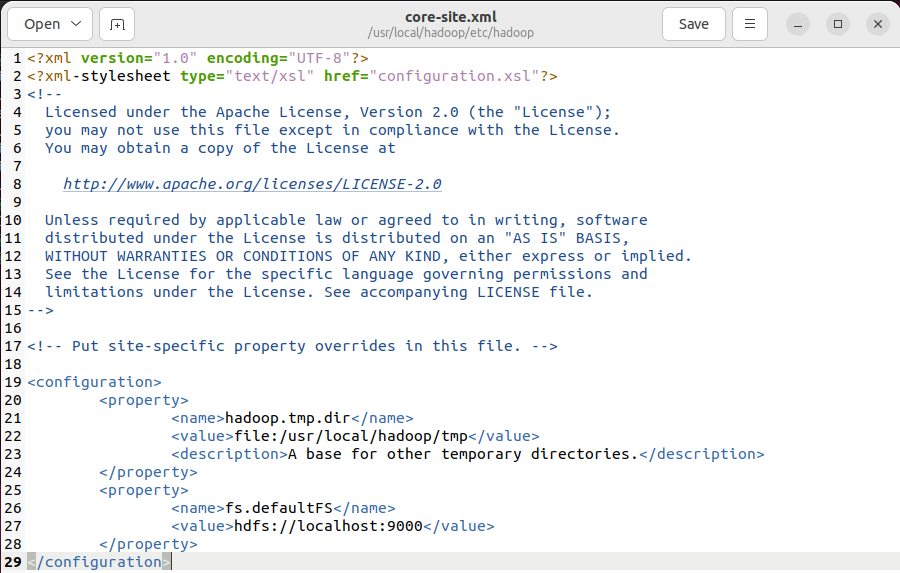
执行gedit etc/hadoop/core-site.xml,添加附件内容。
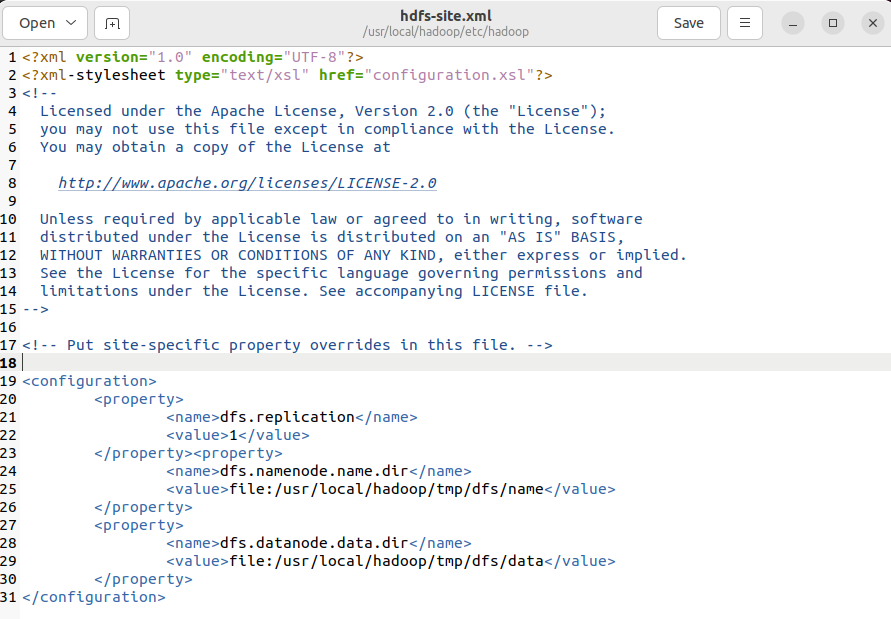
执行gedit etc/hadoop/hdfs-site.xml,添加附件内容。
执行gedit etc/hadoop/yarn-site.xml,添加附件内容。
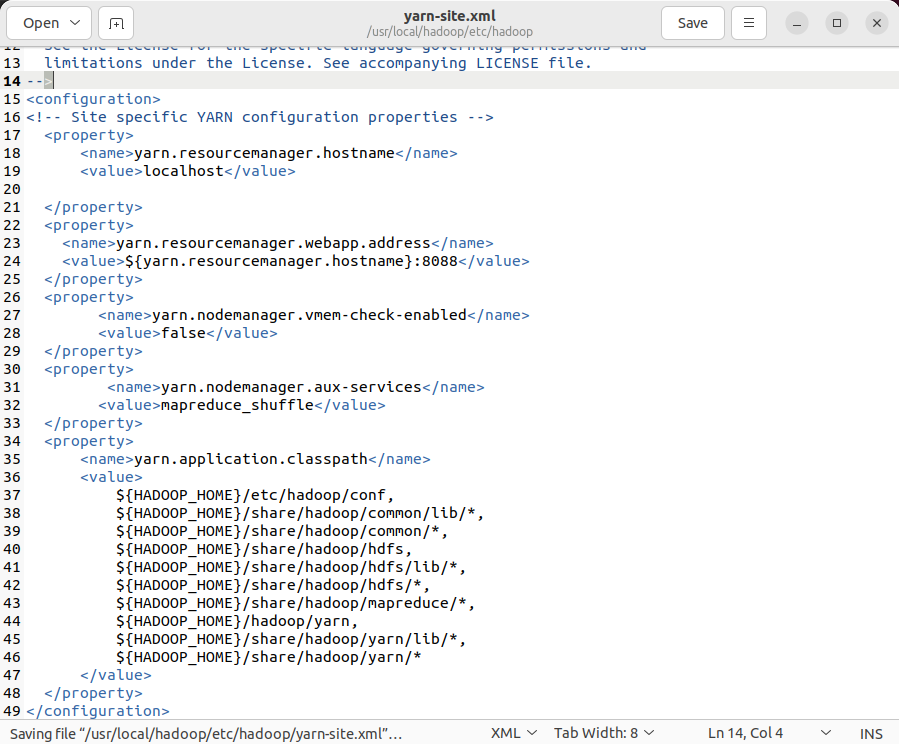
执行gedit etc/hadoop/mapred-site.xml,添加附件内容。
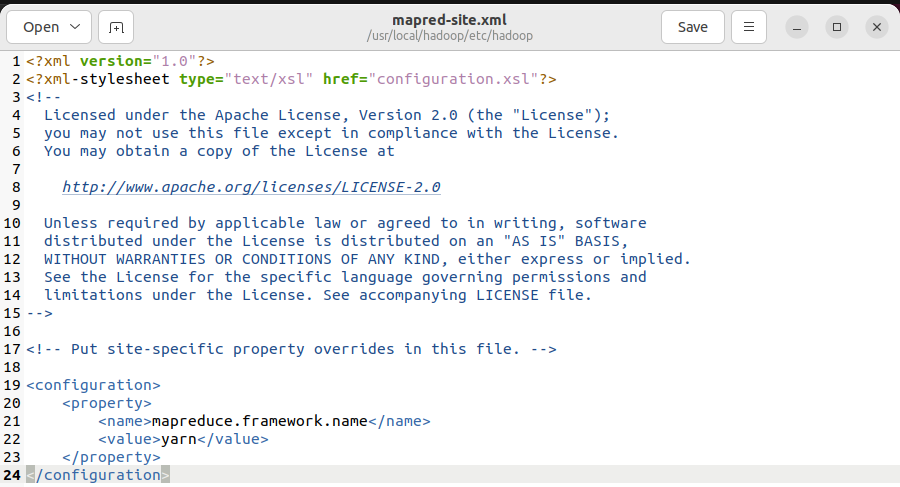
格式化分布式文件系统并启动Hadoop:
hdfs namenode -format #格式化分布式文件系统
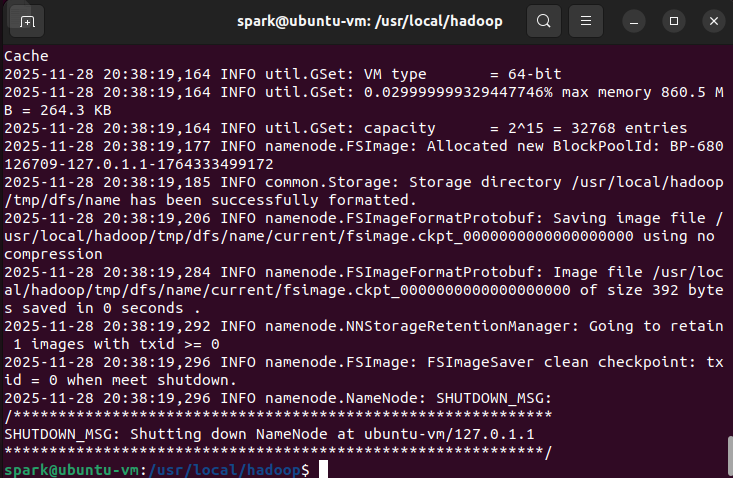
start-dfs.sh #启动hadoop进程
start-yarn.sh #启动yarn进程
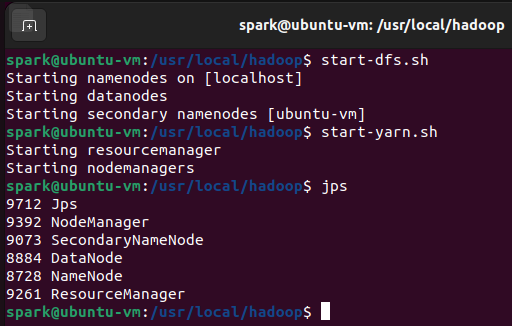
jps #查看进程
可以通过localhost:9870和localhost:8088访问Web UI。
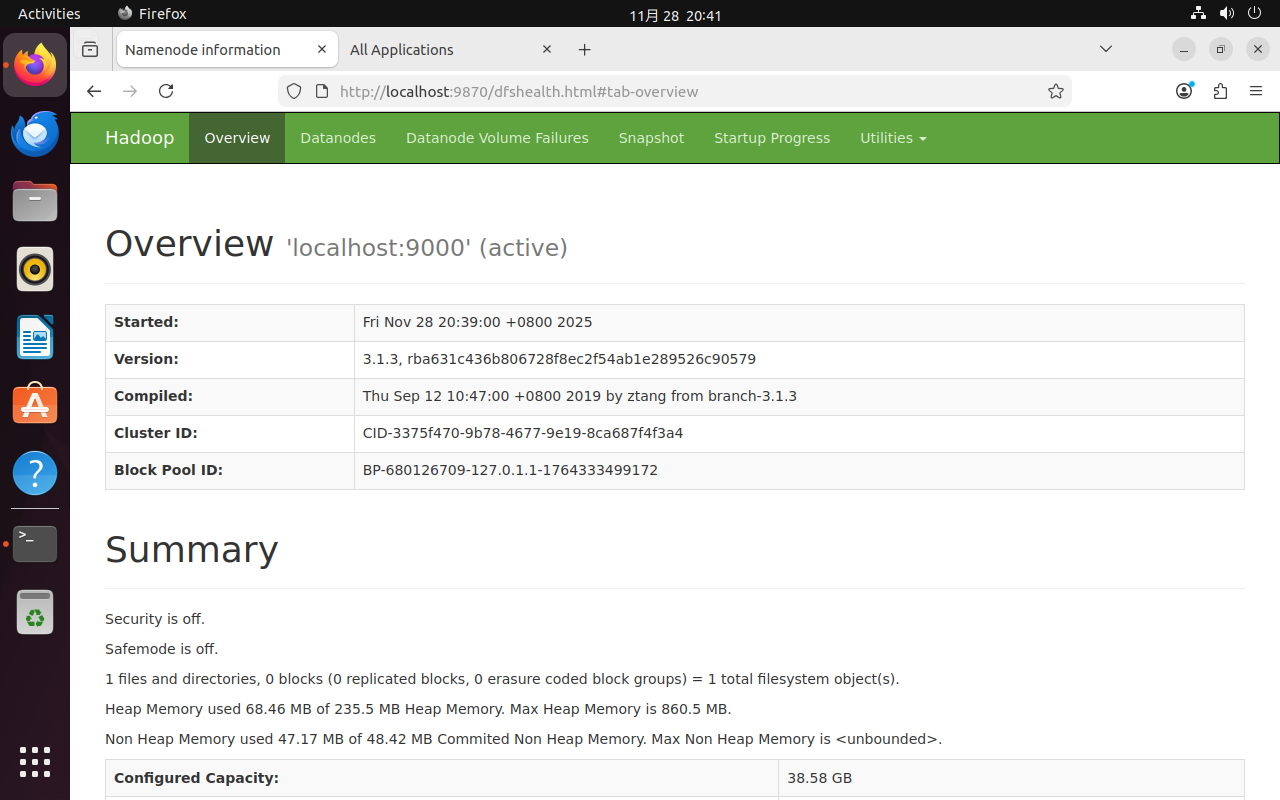
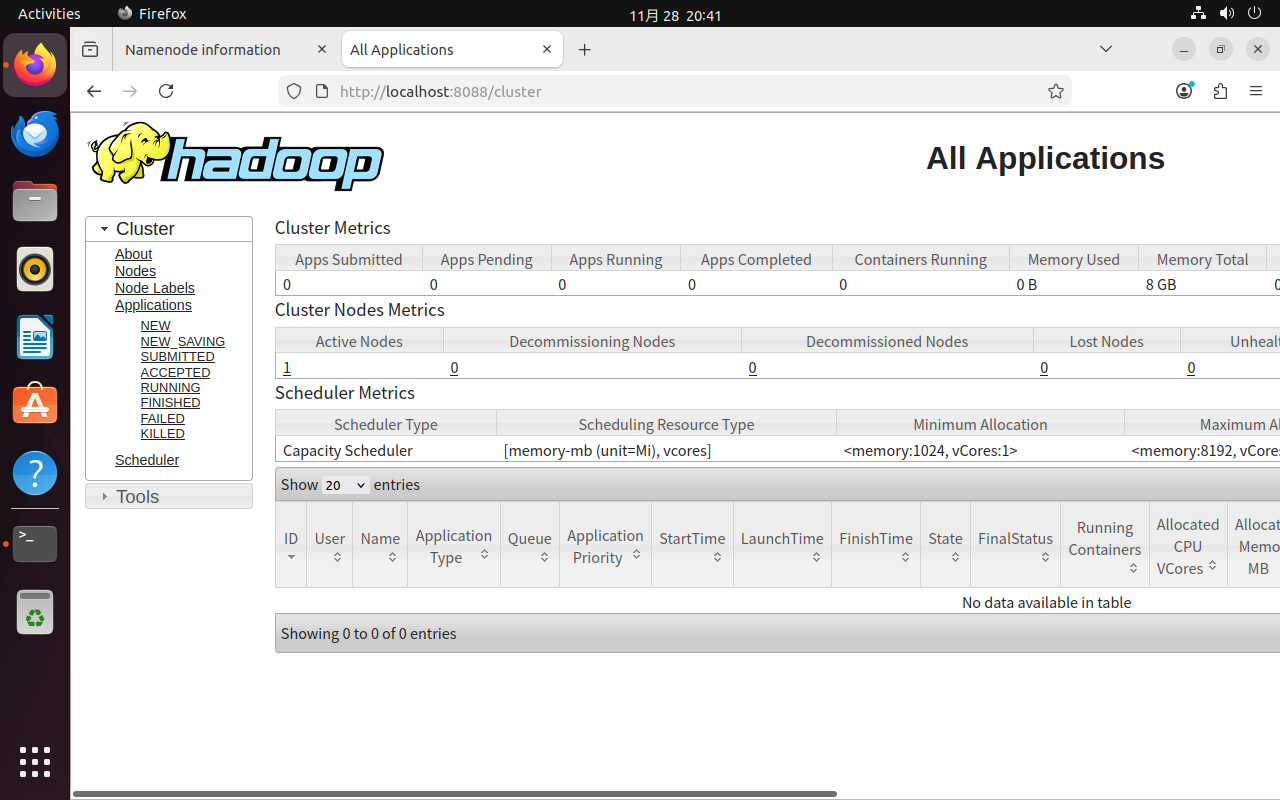
关机前需先关闭Hadoop,防止节点丢失,关闭Hadoop的顺序为:
stop-yarn.sh
stop-dfs.sh
此时jps查看只显示jps
1.6 Spark安装
可从官网下载,在官网选项中可以看到Spark3.5.7对应适配的Hadoop版本是3.3,因此上一步安装Hadoop3.3.6。但在安装spark时不下载预装有Hadoop的版本,而是后续通过配置文件指定使用我们自己安装的Hadoop。
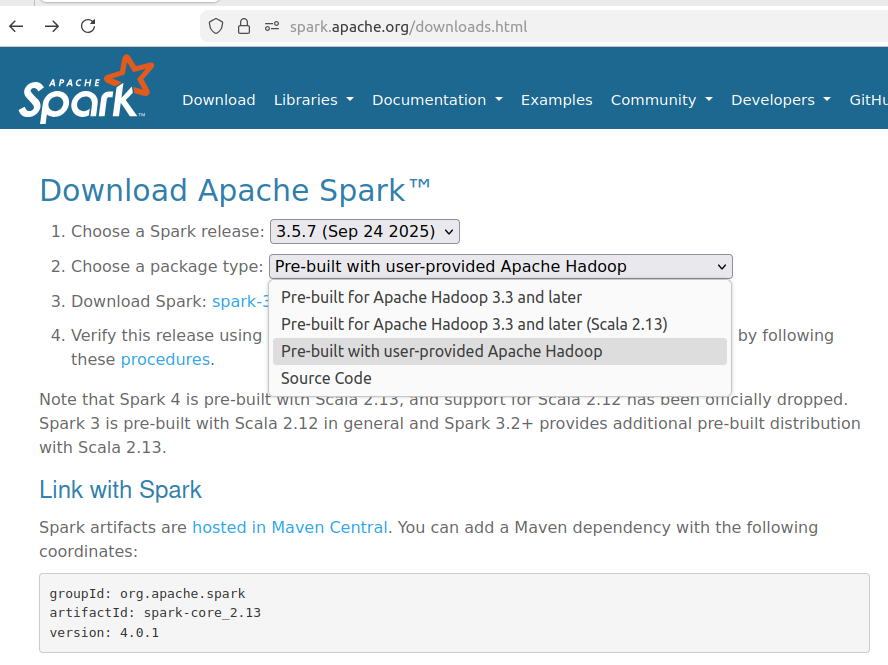
为了快速下载,可以选择从清华镜像源下载,从https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-3.5.7/下载spark-3.5.7-bin-without-hadoop.tgz到~/Downloads,解压到/usr/local后改名并修改权限。
cd ~/Downloads
wget https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-3.5.7/spark-3.5.7-bin-without-hadoop.tgz
sudo tar -zxvf spark-3.5.7-bin-without-hadoop.tgz -C /usr/local #解压
sudo mv /usr/local/spark-3.5.7-bin-without-hadoop/ /usr/local/spark #更改文件名
sudo chown -R $USER /usr/local/spark/ #修改文件夹权限
编辑配置文件:
cd /usr/local/spark/conf
cp spark-env.sh.template spark-env.sh
# 指定使用自己配置的Hadoop,实现Spark和Hadoop的交互
echo 'export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)' >> spark-env.sh #单引号不会执行文本中的命令
Spark uses Hadoop client libraries for HDFS and YARN. Starting in version Spark 1.4, the project packages “Hadoop free” builds that lets you more easily connect a single Spark binary to any Hadoop version. To use these builds, you need to modify SPARK_DIST_CLASSPATH to include Hadoop’s package jars. The most convenient place to do this is by adding an entry in conf/spark-env.sh.
执行gedit spark-env.sh继续编辑,添加伪分布式安装Spark所需变量。
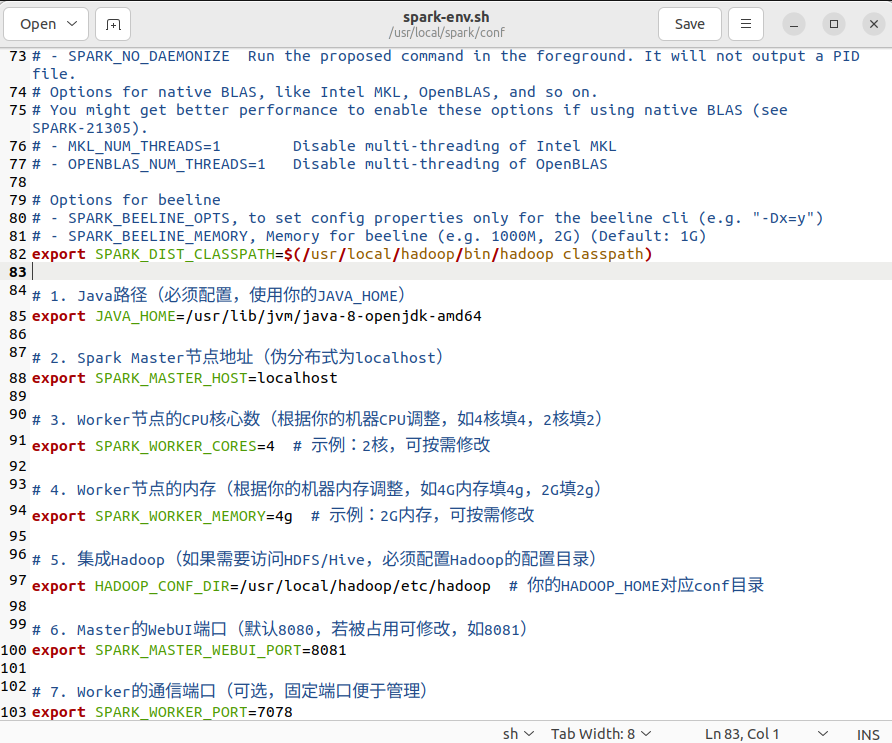
编辑~/.bashrc,添加如下内容,然后执行source ~/.bashrc使其生效。
# Spark
export SPARK_HOME=/usr/local/spark
export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.9.7-src.zip:$PYTHONPATH
export PYSPARK_PYTHON=python3
export PATH=$SPARK_HOME/bin:$PATH
最后验证是否安装成功。
run-example SparkPi 2>&1 | grep "Pi is" #验证是否安装成功
cd /usr/local/spark
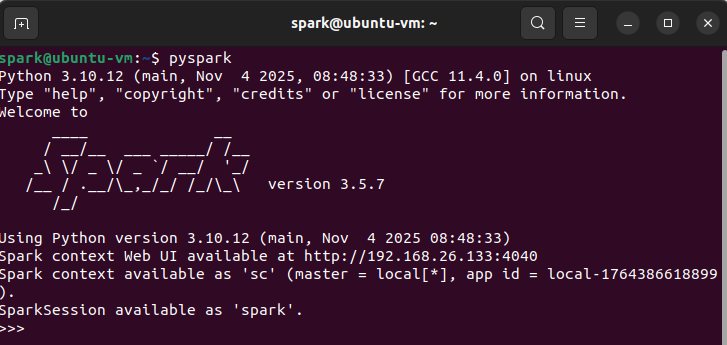
pyspark #启动pyspark,可简单测试一下样例,退出为exit()

1.7 Scala安装
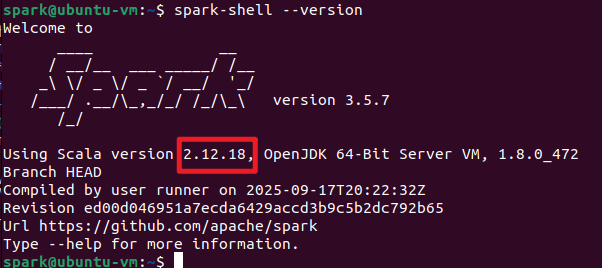
执行spark-shell --version,查看使用的Scala版本进行安装。
可从https://www.scala-lang.org/download/all.html查找下载所需版本。
cd ~/Downloads
wget https://v6.gh-proxy.org/https://github.com/scala/scala/releases/download/v2.12.18/scala-2.12.18.tgz
sudo tar -zxvf scala-2.12.18.tgz -C /usr/local #解压
然后将Scala所需环境变量添加到~/.bashrc。
# Scala
export SCALA_HOME=/usr/local/scala-2.12.18
export PATH=$PATH:$SCALA_HOME/bin
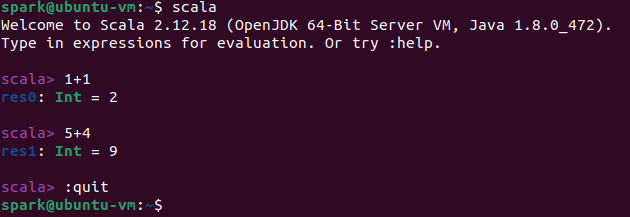
验证安装是否成功:
1.8 sbt安装
sbt is built for Scala and Java projects. It is the build tool of choice for 84.7% of the Scala developers (2023). One of the examples of Scala-specific feature is the ability to cross build your project against multiple Scala versions.
cd ~/Downloads
wget https://v6.gh-proxy.org/https://github.com/sbt/sbt/releases/download/v1.11.7/sbt-1.11.7.tgz # 镜像下载
sudo tar -zxvf sbt-1.11.7.tgz -C /usr/local
然后将Scala所需环境变量添加到~/.bashrc。
# sbt
export SBT_HOME=/usr/local/sbt
export PATH=$PATH:$SBT_HOME/bin
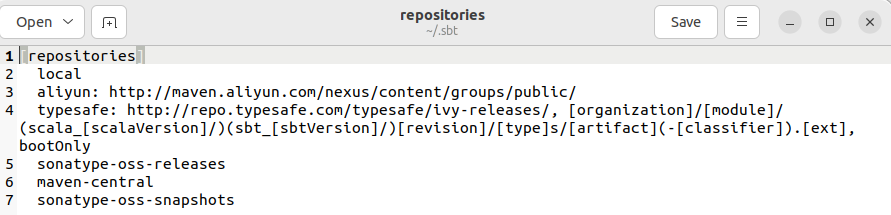
配置sbt镜像,执行下面指令创建文件,然后添加附件内容。
mkdir -p ~/.sbt/
gedit ~/.sbt/repositories
1.9 启动集群
cd /usr/local/spark/sbin/
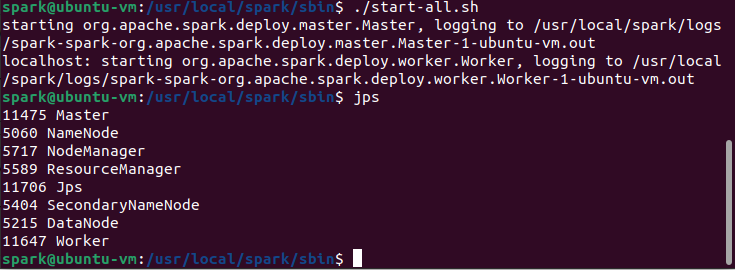
./start-all.sh #启动集群
jps #查看进程,既有Master也有Worker进程,说明启动成功。
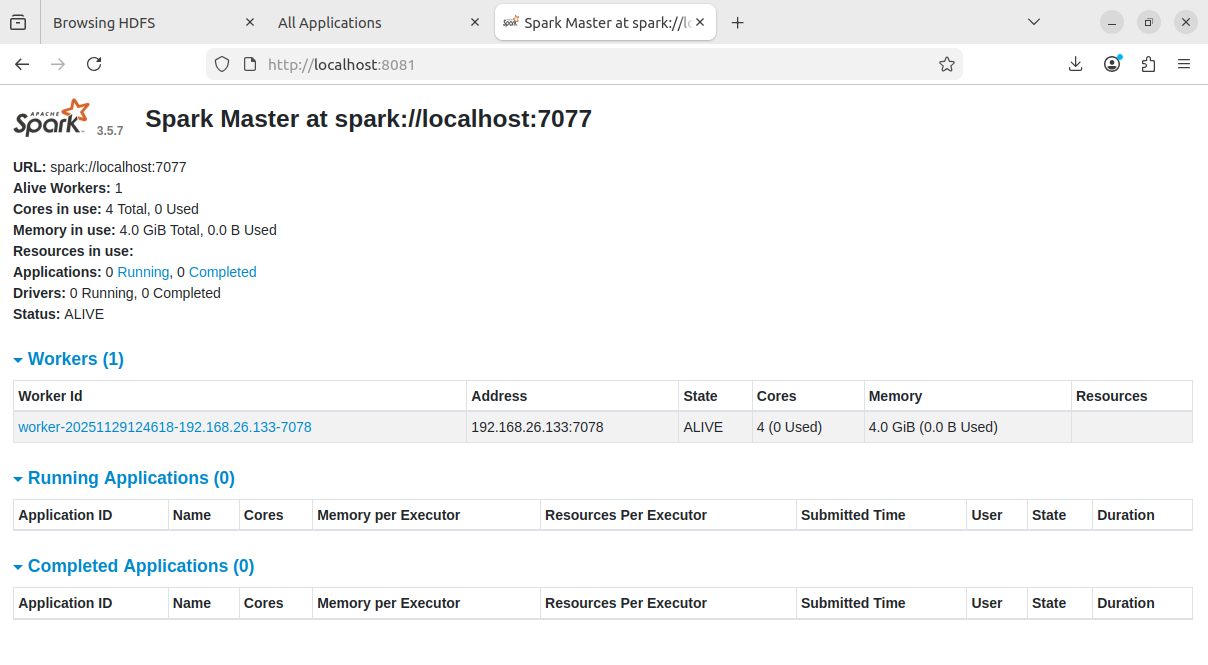
打开浏览器输入localhost:8081显示如下:
2. Spark应用开发(逻辑回归任务)
2.1 项目搭建
#创建项目路径
mkdir -p spark-logistic-regression/src/main/scala
cd spark-logistic-regression
gedit build.sbt #配置文件
build.sbt添加以下内容:
name := "LogisticRegressionDemo"
version := "1.0"
scalaVersion := "2.12.18" // 需与你的Scala版本一致
// 引入Spark MLlib依赖(机器学习库)
libraryDependencies += "org.apache.spark" %% "spark-mllib" % "3.5.7" % "provided" // 与Spark版本一致
2.2 spark-submit 运行程序
LogisticRegressionDemo.scala的代码见附件,注意第125行输出文件路径在用户目录而不是root。
gedit src/main/scala/LogisticRegressionDemo.scala #具体代码见附件
sbt package #安装依赖并编译打包
#打包运行,如果再次运行使用sbt clean清理掉上次编译文件
spark-submit \
--class LogisticRegressionDemo \
target/scala-2.12/logisticregressiondemo_2.12-1.0.jar #终端执行以下命令,提交jar包运行程序
ls -l target/scala-2.12/ #查找jar包

2.3 日志设置(可选)
#此处修改日志输出等级,取消info,可跳过
cd /usr/local/spark/conf #切换工作目录
cp log4j2.properties.template log4j2.properties
gedit log4j2.properties
# 将rootLogger.level = info 修改为 rootLogger.level = error即可
2.4 结果可视化
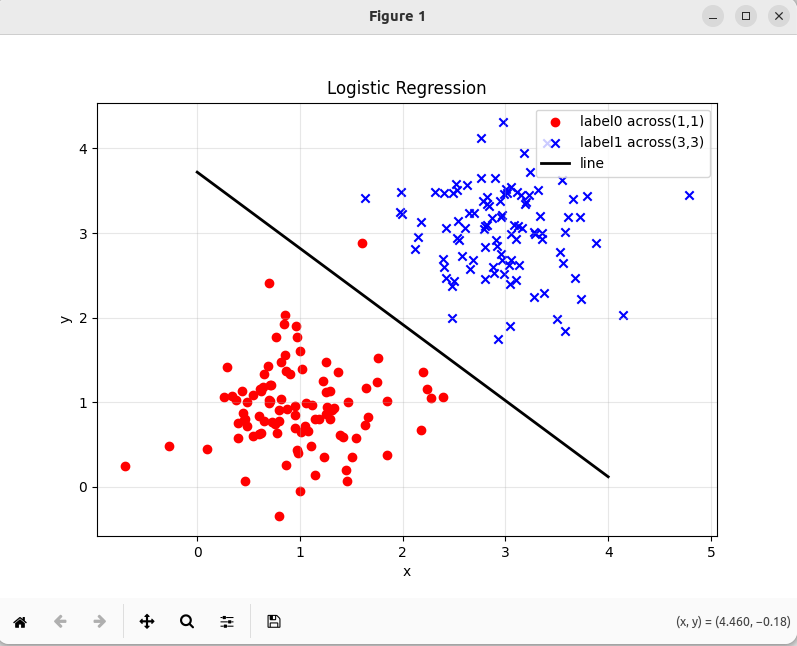
添加附件的Python可视化逻辑回归,plot_result.py的代码见附件。注意第11行文件路径需要自己运行的结果文件。注意第4行注释掉,因为在Ubuntu桌面系统可以显示,若是在SSH等无图形界面使用,则要取消注释。
cd ~/spark-logistic-regression/
ls data_points/
gedit plot_result.py # 具体代码见附件
python3 plot_result.py # 需先pip install matplotlib
3. DataFrame 操作
3.1 项目搭建
#创建项目路径
mkdir -p ~/DataFrameOperations/src/main/scala/ && cd ~/DataFrameOperations/
gedit build.sbt #配置文件
build.sbt添加以下内容:
name := "DataFrameOperations"
version := "1.0"
scalaVersion := "2.12.18" // 需与你的Scala版本一致
// Spark 核心依赖(必须)
libraryDependencies += "org.apache.spark" %% "spark-core" % "3.5.7" % "provided"
libraryDependencies += "org.apache.spark" %% "spark-sql" % "3.5.7" % "provided"
// 日志依赖(可选)
libraryDependencies += "log4j" % "log4j" % "1.2.17" % "provided"
编写DataFrameOperations.scala,代码见附件。
gedit src/main/scala/DataFrameOperations.scala #代码见附件
打包并执行程序。
sbt package # 安装依赖并编译打包
#打包运行,如果再次运行使用sbt clean清理掉上次编译文件
ls -l target/scala-2.12/ #查找jar包
spark-submit \
--class DataFrameOperations \
target/scala-2.12/dataframeoperations_2.12-1.0.jar #终端执行以下命令,提交jar包运行程序

3.2 原有DataFrame操作
3.3 Spark SQL 操作
4. Spark Streaming 操作
mkdir -p ~/SparkStreaming/ && cd ~/SparkStreaming/
4.1 利用Spark Streaming对文件流进行处理
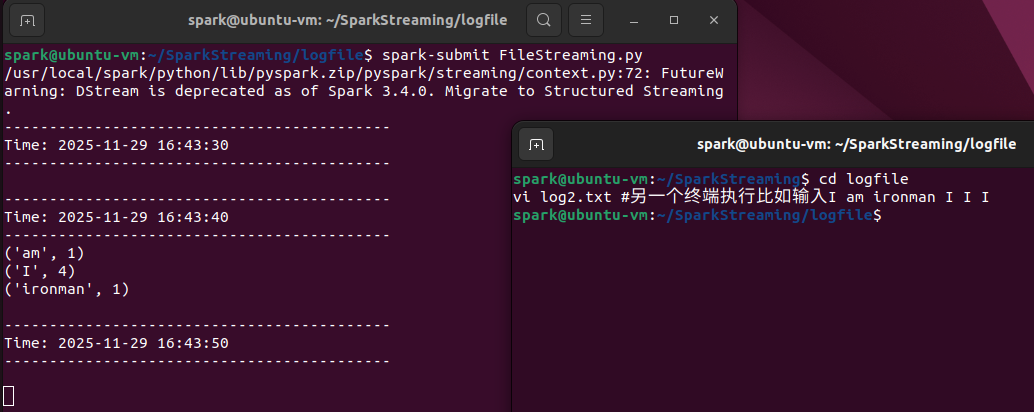
打开两个终端,均cd到~/SparkStreaming/,第一个终端执行下面的命令,FileStreaming.py文件内容见附件,注意修改第17行的文件夹位置。
mkdir ~/SparkStreaming/logfile && cd ~/SparkStreaming/logfile
gedit FileStreaming.py #代码见附件
spark-submit FileStreaming.py #第一个终端执行
在第二个终端执行并输入:
cd ~/SparkStreaming/logfile
vi log2.txt #另一个终端执行比如输入I am ironman I I I
4.2 利用Spark Streaming对套接字进行处理
打开两个终端,第一个终端作为流计算终端,执行下面的命令,NetworkWordCount.py文件内容见附件。
mkdir ~/SparkStreaming/socket && cd ~/SparkStreaming/socket
gedit NetworkWordCount.py #代码见附件。
第二个终端作为数据流终端,执行下面的命令:
cd ~/SparkStreaming/socket
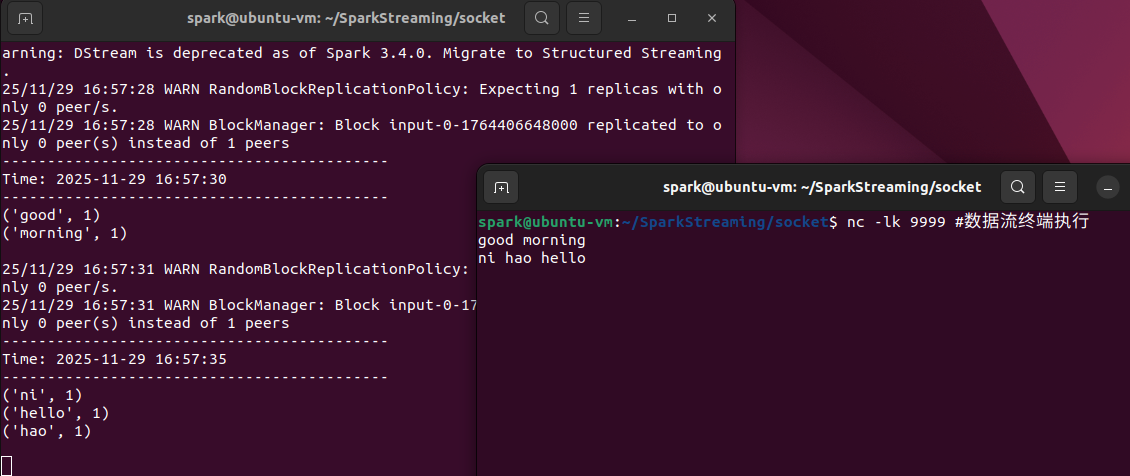
nc -lk 9999 #数据流终端执行
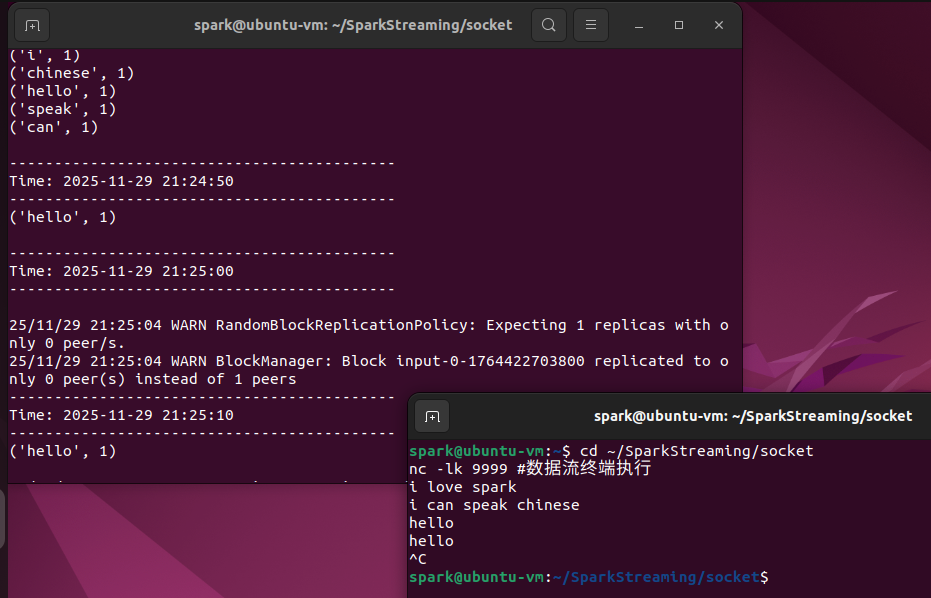
程序执行顺序为先数据流执行再流计算终端执行命令,然后数据流输入,流计算输出。流计算终端执行下面的命令启动程序:
spark-submit NetworkWordCount.py localhost 9999 #流计算终端执行
然后在数据流终端输入数据:
good morning
ni hao hello
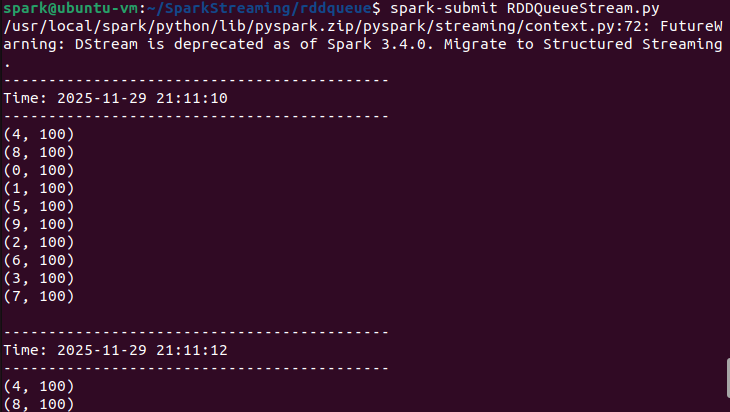
4.3 利用Spark Streaming对RDD队列流进行处理
编写RDDQueueStream.py,代码见附件。之后使用spark-submit执行。
mkdir ~/SparkStreaming/rddqueue && cd ~/SparkStreaming/rddqueue
gedit RDDQueueStream.py #代码见附件
spark-submit RDDQueueStream.py
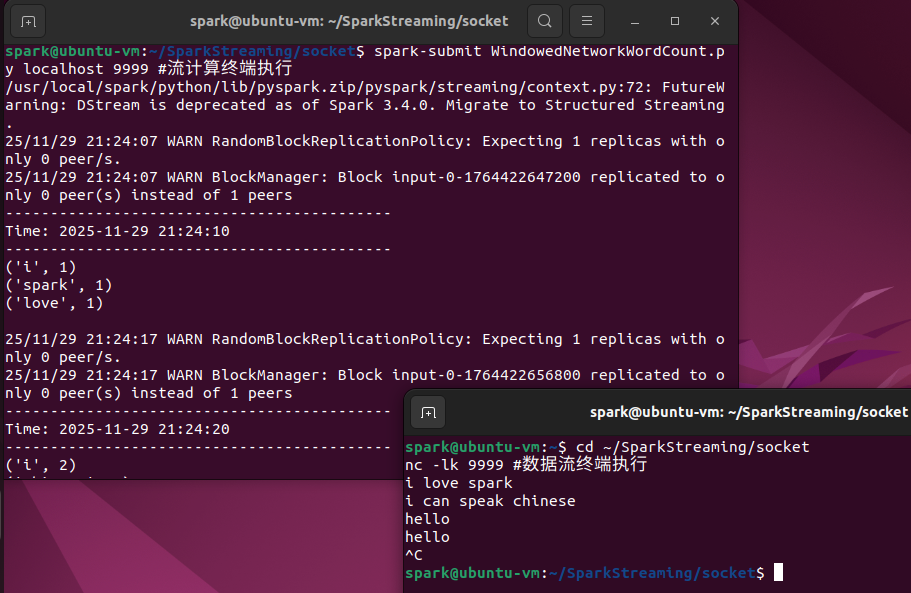
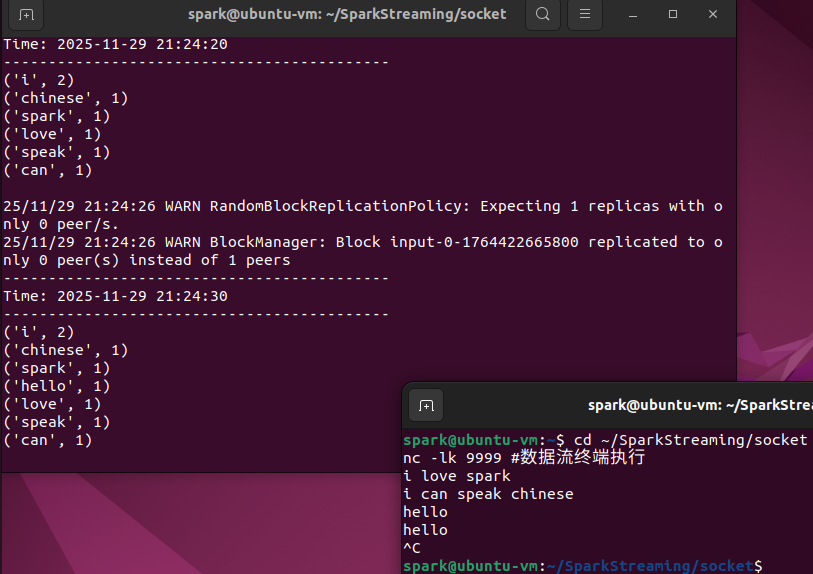
4.4 进阶:滑动窗口操作
之前的NetworkWordCount.py无状态,不保留历史数据。简单的批处理,每个批次独立计算。
本节的WindowedNetworkWordCount.py则每10秒显示过去30秒的累计结果,数据有重叠和连续性。
打开两个终端,第一个终端作为流计算终端,执行下面的命令,WindowedNetworkWordCount.py文件内容见附件,注意修改第22行路径。
cd ~/SparkStreaming/socket
gedit WindowedNetworkWordCount.py #代码见附件。
第二个终端作为数据流终端,执行下面的命令:
cd ~/SparkStreaming/socket
nc -lk 9999 #数据流终端执行
程序执行顺序为先数据流执行再流计算终端执行命令,然后数据流输入,流计算输出。流计算终端执行下面的命令启动程序:
spark-submit WindowedNetworkWordCount.py localhost 9999 #流计算终端执行
然后在数据流终端输入数据:
i love spark
i can speak chinese
hello
hello # 间隔30秒再输入
附件
apt镜像源
deb https://mirrors.ustc.edu.cn/ubuntu/ jammy main restricted universe multivers
e
deb-src https://mirrors.ustc.edu.cn/ubuntu/ jammy main restricted universe multi
verse
deb https://mirrors.ustc.edu.cn/ubuntu/ jammy-updates main restricted universe m
ultiverse
deb-src https://mirrors.ustc.edu.cn/ubuntu/ jammy-updates main restricted univer
se multiverse
deb https://mirrors.ustc.edu.cn/ubuntu/ jammy-backports main restricted universe
multiverse
deb-src https://mirrors.ustc.edu.cn/ubuntu/ jammy-backports main restricted univ
erse multiverse
deb https://mirrors.ustc.edu.cn/ubuntu/ jammy-security main restricted universe
multiverse
deb-src https://mirrors.ustc.edu.cn/ubuntu/ jammy-security main restricted unive
rse multiverse
deb https://mirrors.ustc.edu.cn/ubuntu/ jammy-proposed main restricted universe
multiverse
deb-src https://mirrors.ustc.edu.cn/ubuntu/ jammy-proposed main restricted unive
rse multiverse
hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HDFS_NAMENODE_USER=spark
export HDFS_DATANODE_USER=spark
export HDFS_SECONDARYNAMENODE_USER=spark
export YARN_RESOURCEMANAGER_USER=spark
export YARN_NODEMANAGER_USER=spark
core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property><property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>
${HADOOP_HOME}/etc/hadoop/conf,
${HADOOP_HOME}/share/hadoop/common/lib/*,
${HADOOP_HOME}/share/hadoop/common/*,
${HADOOP_HOME}/share/hadoop/hdfs,
${HADOOP_HOME}/share/hadoop/hdfs/lib/*,
${HADOOP_HOME}/share/hadoop/hdfs/*,
${HADOOP_HOME}/share/hadoop/mapreduce/*,
${HADOOP_HOME}/hadoop/yarn,
${HADOOP_HOME}/share/hadoop/yarn/lib/*,
${HADOOP_HOME}/share/hadoop/yarn/*
</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
sbt镜像
[repositories]
local
aliyun: https://maven.aliyun.com/nexus/content/groups/public/
typesafe: https://repo.typesafe.com/typesafe/ivy-releases/, [organization]/[module]/(scala_[scalaVersion]/)(sbt_[sbtVersion]/)[revision]/[type]s/[artifact](-[classifier]).[ext], bootOnly
sonatype-oss-releases
maven-central
sonatype-oss-snapshots
spark-env.sh
# 1. Java路径(必须配置,使用你的JAVA_HOME)
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
# 2. Spark Master节点地址(伪分布式为localhost)
export SPARK_MASTER_HOST=localhost
# 3. Worker节点的CPU核心数(根据你的机器CPU调整,如4核填4,2核填2)
export SPARK_WORKER_CORES=4 # 示例:2核,可按需修改
# 4. Worker节点的内存(根据你的机器内存调整,如4G内存填4g,2G填2g)
export SPARK_WORKER_MEMORY=4g # 示例:2G内存,可按需修改
# 5. 集成Hadoop(如果需要访问HDFS/Hive,必须配置Hadoop的配置目录)
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop # 你的HADOOP_HOME对应conf目录
# 6. Master的WebUI端口(默认8080,若被占用可修改,如8081)
export SPARK_MASTER_WEBUI_PORT=8081
# 7. Worker的通信端口(可选,固定端口便于管理)
export SPARK_WORKER_PORT=7078
LogisticRegressionDemo.scala
注意125行输出文件地址是/home/spark而不是/root。
// 导入Spark相关类(使用ML新API,确保稳定性)
import org.apache.spark.sql.SparkSession
import org.apache.spark.ml.feature.{VectorAssembler, StandardScaler}
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.evaluation.{BinaryClassificationEvaluator, MulticlassClassificationEvaluator}
import org.apache.spark.mllib.evaluation.MulticlassMetrics
import org.apache.spark.sql.functions._
// 类名统一为LogisticRegressionDemo,与提交命令中的--class参数匹配
object LogisticRegressionDemo {
def main(args: Array[String]): Unit = {
// 1. 初始化Spark环境(本地模式,适合新手测试)
val spark = SparkSession.builder()
.appName("最佳分离直线-优化版")
.master("local[*]") // 本地模式,集群运行时删除此行
.config("spark.sql.shuffle.partitions", "4") // 小数据集优化,减少分区
.getOrCreate()
import spark.implicits._ // 隐式转换,支持DataFrame操作
// 2. 生成模拟数据(两组可线性分离的点)
// 第一组(标签0):围绕(1,1)随机分布
val group0 = (1 to 100).map { _ =>
val x = 1 + scala.util.Random.nextGaussian() * 0.5 // x坐标:均值1,波动0.5
val y = 1 + scala.util.Random.nextGaussian() * 0.5 // y坐标:均值1,波动0.5
(0.0, x, y) // (标签, x, y)
}.toDF("label", "x", "y")
// 第二组(标签1):围绕(3,3)随机分布
val group1 = (1 to 100).map { _ =>
val x = 3 + scala.util.Random.nextGaussian() * 0.5 // x坐标:均值3,波动0.5
val y = 3 + scala.util.Random.nextGaussian() * 0.5 // y坐标:均值3,波动0.5
(1.0, x, y) // (标签, x, y)
}.toDF("label", "x", "y")
// 合并两组数据
val data = group0.union(group1)
// 3. 特征处理(标准化提升模型效果)
// 3.1 将x和y合并为特征向量
val assembler = new VectorAssembler()
.setInputCols(Array("x", "y")) // 输入列:x和y坐标
.setOutputCol("rawFeatures") // 输出列:原始特征向量
val featureData = assembler.transform(data)
// 3.2 特征标准化(均值0,方差1,加速模型收敛)
val scaler = new StandardScaler()
.setInputCol("rawFeatures")
.setOutputCol("features")
.setWithStd(true) // 标准化标准差
.setWithMean(true) // 标准化均值
val scalerModel = scaler.fit(featureData)
val scaledData = scalerModel.transform(featureData)
// 4. 划分训练集(80%)和测试集(20%)
val Array(trainData, testData) = scaledData.randomSplit(Array(0.8, 0.2), seed = 42) // 固定seed确保结果可复现
// 5. 训练逻辑回归模型
val lr = new LogisticRegression()
.setLabelCol("label") // 标签列名
.setFeaturesCol("features") // 特征列名
.setMaxIter(100) // 迭代次数(确保收敛)
.setRegParam(0.01) // 正则化参数(防止过拟合)
.setFamily("binomial") // 二分类任务
println("\n=== 开始训练模型 ===")
val model = lr.fit(trainData)
println("模型训练完成")
// 6. 模型评估(多指标验证)
val predictions = model.transform(testData) // 生成测试集预测结果
// 6.1 准确率(正确预测比例)
val correct = predictions.filter($"prediction" === $"label").count()
val total = predictions.count()
val accuracy = correct.toDouble / total
// 6.2 AUC值(二分类评估指标,越接近1越好)
val binaryEvaluator = new BinaryClassificationEvaluator()
.setLabelCol("label")
.setRawPredictionCol("rawPrediction")
.setMetricName("areaUnderROC")
val auc = binaryEvaluator.evaluate(predictions)
// 6.3 混淆矩阵(展示分类细节)
val predictionRDD = predictions.select("prediction", "label")
.as[(Double, Double)]
.rdd
val metrics = new MulticlassMetrics(predictionRDD)
val confusionMatrix = metrics.confusionMatrix
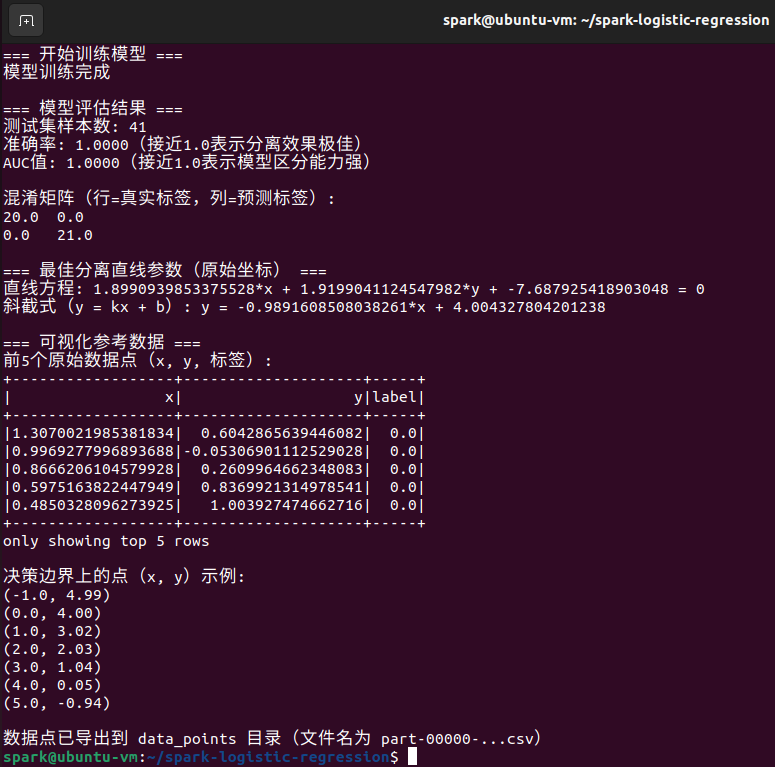
println("\n=== 模型评估结果 ===")
println(s"测试集样本数: $total")
println(s"准确率: ${"%.4f".format(accuracy)}(接近1.0表示分离效果极佳)")
println(s"AUC值: ${"%.4f".format(auc)}(接近1.0表示模型区分能力强)")
println("\n混淆矩阵(行=真实标签,列=预测标签):")
println(confusionMatrix)
// 7. 提取最佳分离直线参数(转换回原始坐标空间)
val weights = model.coefficients // 标准化后的权重
val intercept = model.intercept // 标准化后的截距
// 反标准化:将参数转换为原始x、y坐标的直线方程
val scalerMean = scalerModel.mean.toArray // 特征均值
val scalerStd = scalerModel.std.toArray // 特征标准差
val rawWeights = (0 until weights.size).map(i => weights(i) / scalerStd(i)).toArray // 原始权重
val rawIntercept = intercept - (0 until weights.size).map(i => weights(i) * scalerMean(i) / scalerStd(i)).sum // 原始截距
println("\n=== 最佳分离直线参数(原始坐标) ===")
println(s"直线方程: ${rawWeights(0)}*x + ${rawWeights(1)}*y + $rawIntercept = 0")
println(s"斜截式(y = kx + b): y = ${-rawWeights(0)/rawWeights(1)}*x + ${-rawIntercept/rawWeights(1)}")
// 8. 输出示例点(用于外部可视化,如Python绘图)
println("\n=== 可视化参考数据 ===")
println("前5个原始数据点(x, y, 标签):")
data.select("x", "y", "label").show(5)
println("决策边界上的点(x, y)示例:")
(-1 to 5).map(x => (x.toDouble, (-rawIntercept - rawWeights(0)*x)/rawWeights(1))).foreach { case (x, y) =>
println(f"($x, $y%.2f)")
}
// 导出所有数据点到本地文件(x, y, 标签)
data.select("x", "y", "label")
.coalesce(1) // 合并为一个文件
.write
.mode("overwrite")
.csv("file:///home/spark/spark-logistic-regression/data_points")
println("\n数据点已导出到 data_points 目录(文件名为 part-00000-...csv)")
// 9. 停止Spark,释放资源
spark.stop()
}
}
plot_result.py
注意第4行注释掉,因为在Ubuntu桌面系统可以显示,若是在SSH等无图形界面使用,则要取消注释。
注意第11行文件路径需要自己运行的结果文件。
# -*- coding: utf-8 -*-
import matplotlib
# 指定Agg后端(无图形界面时生成图像文件)
# matplotlib.use('Agg')
import matplotlib.pyplot as plt
import matplotlib.pyplot as plt
import csv
# 1. 读取数据点(从Spark导出的CSV文件)
# 替换为你的CSV文件路径(在data_points目录下)
csv_path = "/home/spark/spark-logistic-regression/data_points/part-00000-34999d70-69a0-4753-b25c-5690990994d8-c000.csv" # 以你的文件名为准
group0_x, group0_y = [], [] # 标签0的点
group1_x, group1_y = [], [] # 标签1的点
with open(csv_path, 'r') as f:
reader = csv.reader(f)
next(reader) # 跳过表头(如果有的话)
for row in reader:
x = float(row[0])
y = float(row[1])
label = float(row[2])
if label == 0:
group0_x.append(x)
group0_y.append(y)
else:
group1_x.append(x)
group1_y.append(y)
# 2. 定义最佳分离直线(替换为你的Spark输出的k和b)
# 例如:Spark输出的斜截式为 y = -0.96x + 3.8,则k=-0.96, b=3.8
k = -0.9 # 替换为你的直线斜率
b = 3.72 # 替换为你的直线截距
x_line = [0, 4] # x轴范围(覆盖数据点的x范围)
y_line = [k*x + b for x in x_line] # 直线上的y值
# 3. 绘图
plt.figure(figsize=(8, 6))# 绘制两组点(不同颜色和标记)
plt.scatter(group0_x, group0_y, c='red', marker='o', label='label0 across(1,1)')
plt.scatter(group1_x, group1_y, c='blue', marker='x', label='label1 across(3,3)')
# 绘制最佳分离直线
plt.plot(x_line, y_line, 'black', linewidth=2, label='line')
# 添加标签和标题
plt.xlabel('x')
plt.ylabel('y')
plt.title('Logistic Regression')
plt.legend() # 显示图例
plt.grid(alpha=0.3) # 网格线
# 3. 绘图
plt.figure(figsize=(8, 6))
# 绘制两组点(不同颜色和标记)
plt.scatter(group0_x, group0_y, c='red', marker='o', label='label0 across(1,1)')
plt.scatter(group1_x, group1_y, c='blue', marker='x', label='label1 across(3,3)')
# 绘制最佳分离直线
plt.plot(x_line, y_line, 'black', linewidth=2, label='line')
# 添加标签和标题
plt.xlabel('x-axis')
plt.ylabel('y-axis')
plt.title('Logistic Regression')
plt.legend() # 显示图例
plt.grid(alpha=0.3) # 网格线
# 保存图片
plt.savefig('result_plot.png', dpi=300) # 保存为PNG文件,清晰度300dpi
# 显示图片
plt.show()
DataFrameOperations.scala
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
import org.apache.log4j.{Level, Logger} // 新增日志控制
object DataFrameOperations {
def main(args: Array[String]): Unit = {
// 关闭冗余日志
Logger.getLogger("org").setLevel(Level.WARN)
Logger.getLogger("akka").setLevel(Level.WARN)
// 1. 初始化SparkSession
val spark = SparkSession.builder()
.appName("DataFrame+SparkSQL操作示例")
.master("local[*]")
.getOrCreate()
import spark.implicits._
// 2. 生成基础数据
val group0 = (1 to 100).map { _ =>
val x = 1 + scala.util.Random.nextGaussian() * 0.5
val y = 1 + scala.util.Random.nextGaussian() * 0.5
(0.0, x, y)
}.toDF("label", "x", "y")
val group1 = (1 to 100).map { _ =>
val x = 3 + scala.util.Random.nextGaussian() * 0.5
val y = 3 + scala.util.Random.nextGaussian() * 0.5
(1.0, x, y)
}.toDF("label", "x", "y")
val df = group0.union(group1)
println("=== 原始DataFrame创建完成 ===")
// 3. 原有DataFrame操作
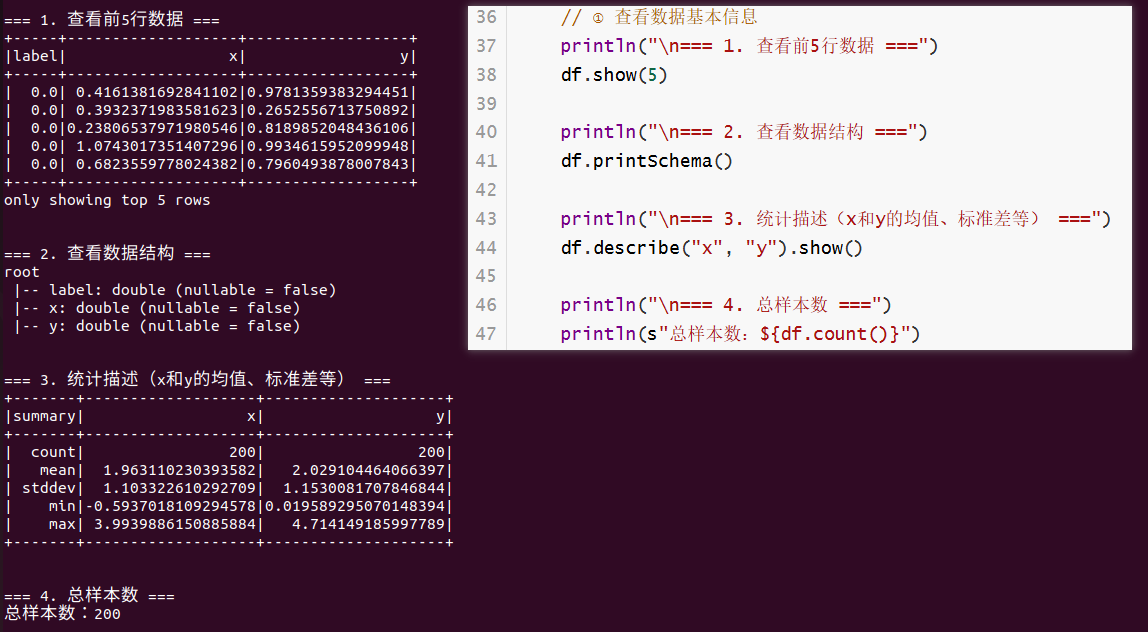
// ① 查看数据基本信息
println("\n=== 1. 查看前5行数据 ===")
df.show(5)
println("\n=== 2. 查看数据结构 ===")
df.printSchema()
println("\n=== 3. 统计描述(x和y的均值、标准差等) ===")
df.describe("x", "y").show()
println("\n=== 4. 总样本数 ===")
println(s"总样本数:${df.count()}")
// ② 筛选数据
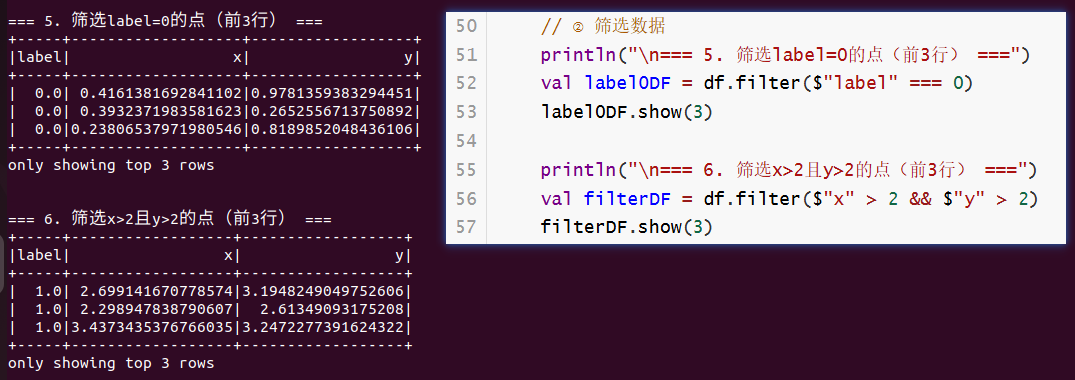
println("\n=== 5. 筛选label=0的点(前3行) ===")
val label0DF = df.filter($"label" === 0)
label0DF.show(3)
println("\n=== 6. 筛选x>2且y>2的点(前3行) ===")
val filterDF = df.filter($"x" > 2 && $"y" > 2)
filterDF.show(3)
// ③ 新增/修改列
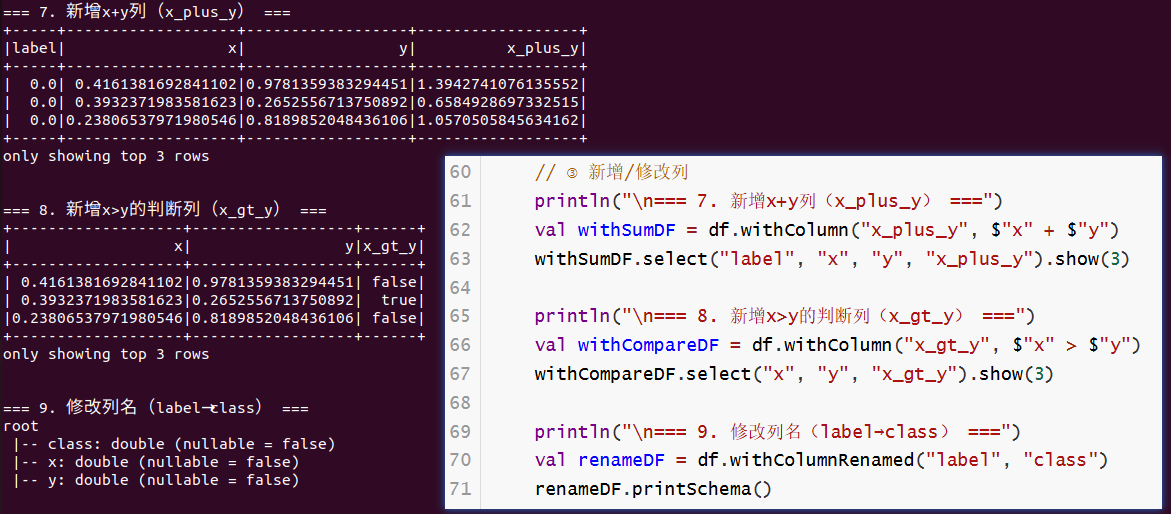
println("\n=== 7. 新增x+y列(x_plus_y) ===")
val withSumDF = df.withColumn("x_plus_y", $"x" + $"y")
withSumDF.select("label", "x", "y", "x_plus_y").show(3)
println("\n=== 8. 新增x>y的判断列(x_gt_y) ===")
val withCompareDF = df.withColumn("x_gt_y", $"x" > $"y")
withCompareDF.select("x", "y", "x_gt_y").show(3)
println("\n=== 9. 修改列名(label→class) ===")
val renameDF = df.withColumnRenamed("label", "class")
renameDF.printSchema()
// ④ 分组统计
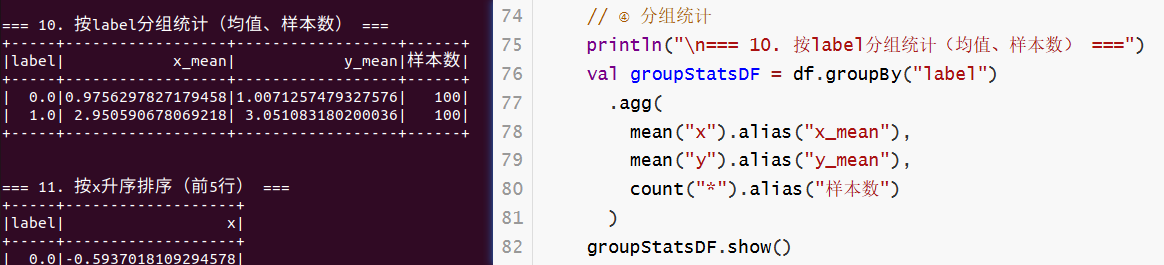
println("\n=== 10. 按label分组统计(均值、样本数) ===")
val groupStatsDF = df.groupBy("label")
.agg(
mean("x").alias("x_mean"),
mean("y").alias("y_mean"),
count("*").alias("样本数")
)
groupStatsDF.show()
// ⑤ 排序
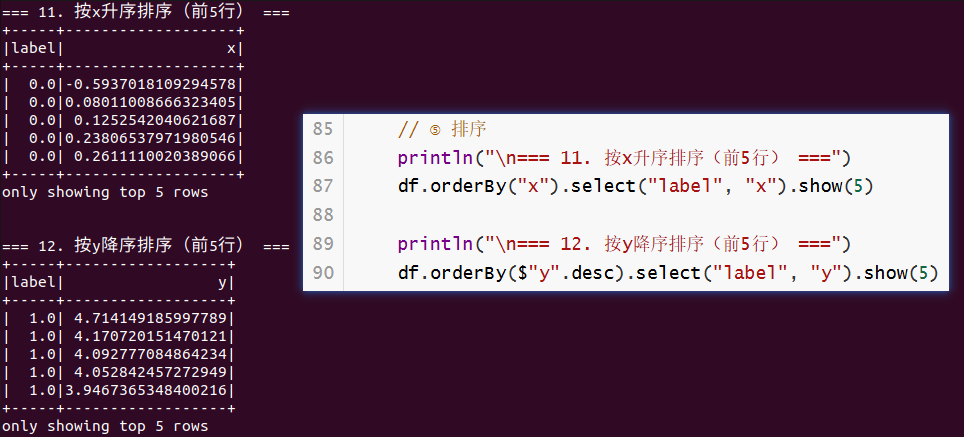
println("\n=== 11. 按x升序排序(前5行) ===")
df.orderBy("x").select("label", "x").show(5)
println("\n=== 12. 按y降序排序(前5行) ===")
df.orderBy($"y".desc).select("label", "y").show(5)
// ⑥ 选择列(投影)
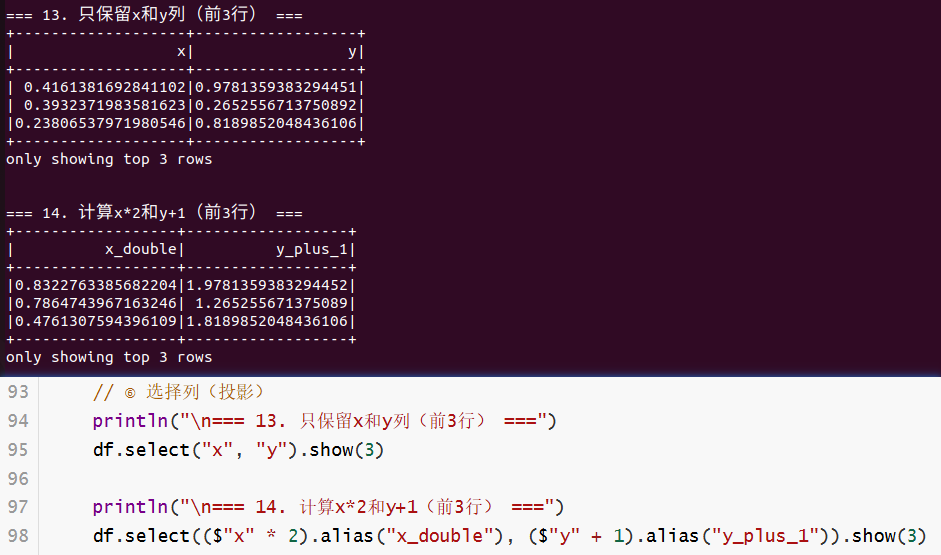
println("\n=== 13. 只保留x和y列(前3行) ===")
df.select("x", "y").show(3)
println("\n=== 14. 计算x*2和y+1(前3行) ===")
df.select(($"x" * 2).alias("x_double"), ($"y" + 1).alias("y_plus_1")).show(3)
// ⑦ 连接操作
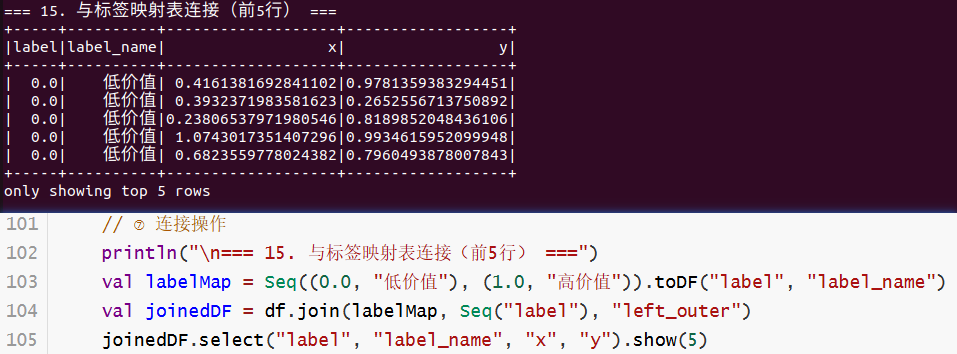
println("\n=== 15. 与标签映射表连接(前5行) ===")
val labelMap = Seq((0.0, "低价值"), (1.0, "高价值")).toDF("label", "label_name")
val joinedDF = df.join(labelMap, Seq("label"), "left_outer")
joinedDF.select("label", "label_name", "x", "y").show(5)
// ⑧ Spark SQL操作
println("\n===== Spark SQL操作开始 =====")
// a. 注册临时视图
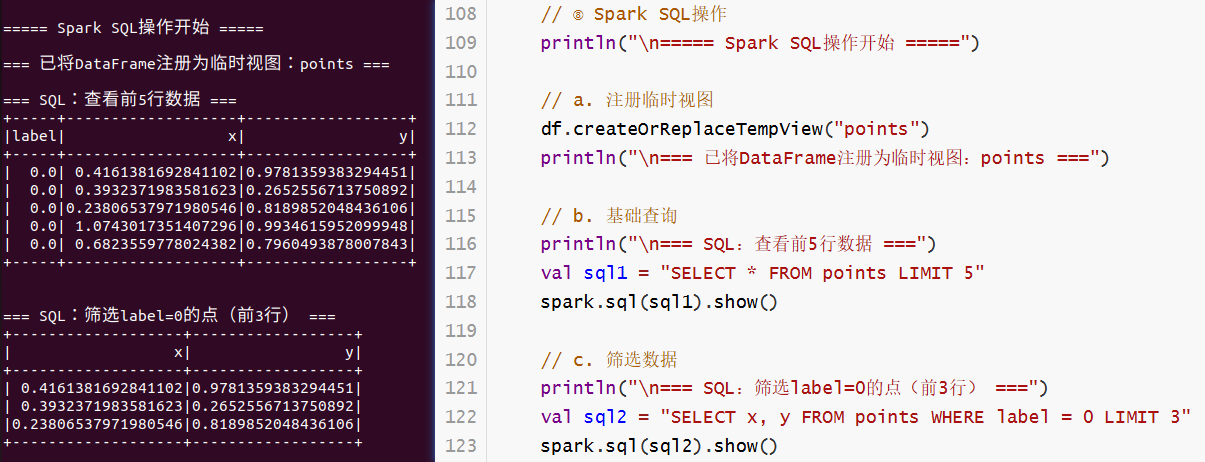
df.createOrReplaceTempView("points")
println("\n=== 已将DataFrame注册为临时视图:points ===")
// b. 基础查询
println("\n=== SQL:查看前5行数据 ===")
val sql1 = "SELECT * FROM points LIMIT 5"
spark.sql(sql1).show()
// c. 筛选数据
println("\n=== SQL:筛选label=0的点(前3行) ===")
val sql2 = "SELECT x, y FROM points WHERE label = 0 LIMIT 3"
spark.sql(sql2).show()
// d. 分组统计(SQL)
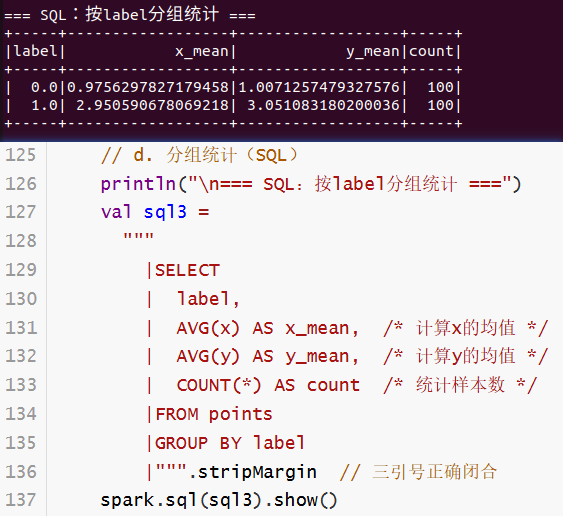
println("\n=== SQL:按label分组统计 ===")
val sql3 =
"""
|SELECT
| label,
| AVG(x) AS x_mean, /* 计算x的均值 */
| AVG(y) AS y_mean, /* 计算y的均值 */
| COUNT(*) AS count /* 统计样本数 */
|FROM points
|GROUP BY label
|""".stripMargin // 三引号正确闭合
spark.sql(sql3).show()
// e. 复杂查询(新增列+筛选)
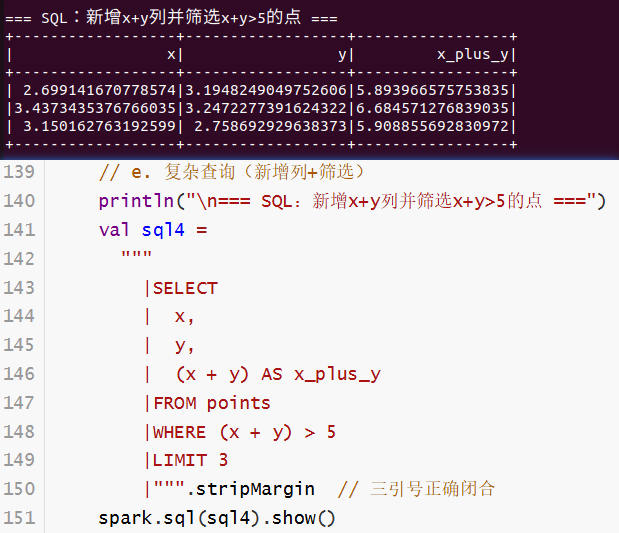
println("\n=== SQL:新增x+y列并筛选x+y>5的点 ===")
val sql4 =
"""
|SELECT
| x,
| y,
| (x + y) AS x_plus_y
|FROM points
|WHERE (x + y) > 5
|LIMIT 3
|""".stripMargin // 三引号正确闭合
spark.sql(sql4).show()
// f. 关联查询
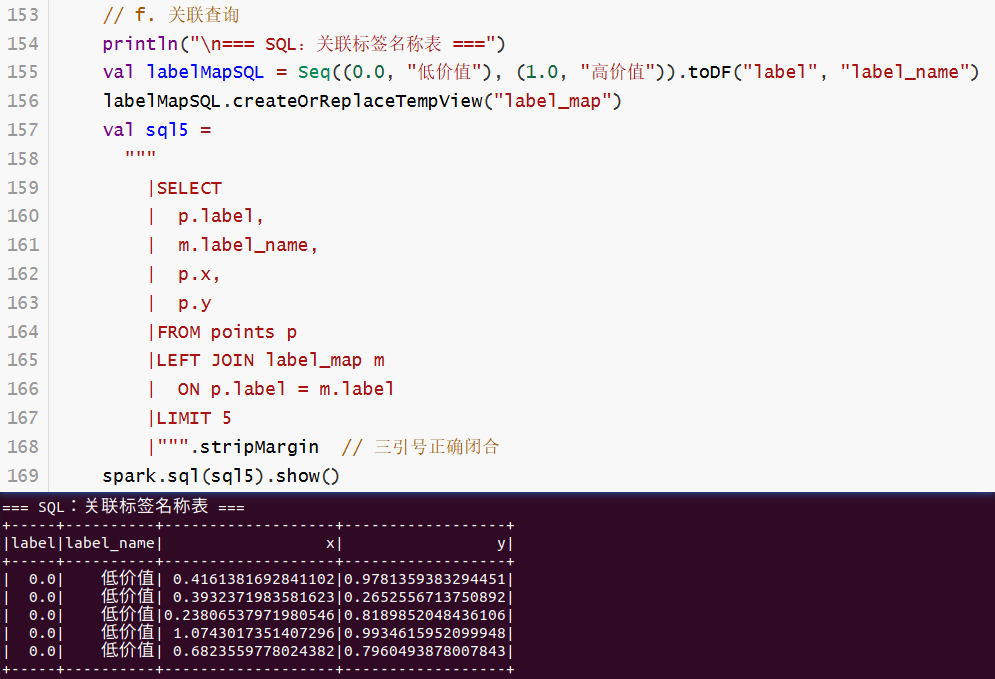
println("\n=== SQL:关联标签名称表 ===")
val labelMapSQL = Seq((0.0, "低价值"), (1.0, "高价值")).toDF("label", "label_name")
labelMapSQL.createOrReplaceTempView("label_map")
val sql5 =
"""
|SELECT
| p.label,
| m.label_name,
| p.x,
| p.y
|FROM points p
|LEFT JOIN label_map m
| ON p.label = m.label
|LIMIT 5
|""".stripMargin // 三引号正确闭合
spark.sql(sql5).show()
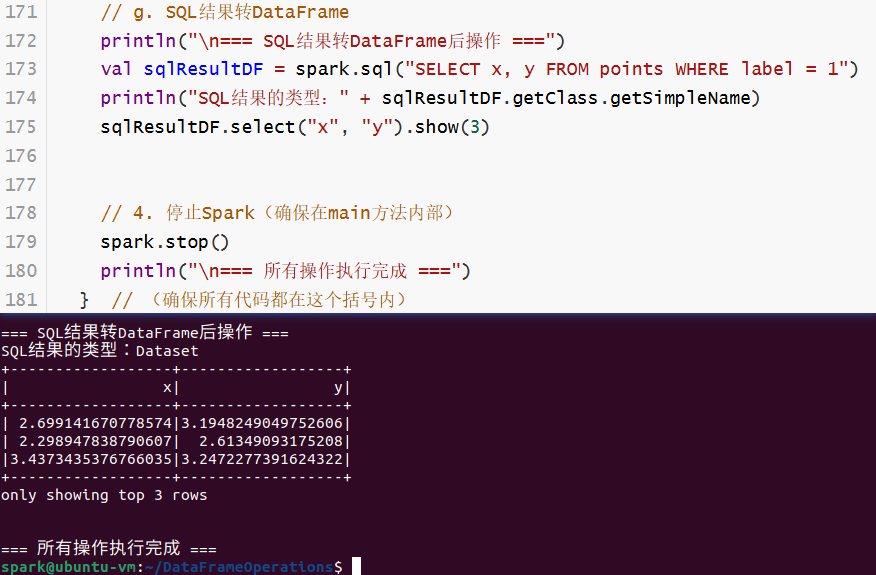
// g. SQL结果转DataFrame
println("\n=== SQL结果转DataFrame后操作 ===")
val sqlResultDF = spark.sql("SELECT x, y FROM points WHERE label = 1")
println("SQL结果的类型:" + sqlResultDF.getClass.getSimpleName)
sqlResultDF.select("x", "y").show(3)
// 4. 停止Spark(确保在main方法内部)
spark.stop()
println("\n=== 所有操作执行完成 ===")
} // (确保所有代码都在这个括号内)
} // object
FileStreaming.py
注意修改第17行的文件夹位置。
# 注意:确保该文件位于 /home/spark/SparkStreaming/logfile/目录下
from pyspark import SparkContext, SparkConf
from pyspark.streaming import StreamingContext
# 1. 配置Spark环境
conf = SparkConf()
conf.setAppName('FileStreamWordCount') # 应用名称,可自定义
conf.setMaster('local[2]') # 本地模式,使用2个核心(适合本地测试)
sc = SparkContext(conf=conf)
sc.setLogLevel("WARN") # 减少日志输出,只显示WARN及以上级别
# 2. 初始化StreamingContext,批次间隔10秒(与你终端输出的Time间隔一致)
ssc = StreamingContext(sc, 10)
# 3. 设置文件监控路径(关键修改:改为你的实际logfile目录)
# 你的实际目录是/home/spark/SparkStreaming/logfile/,需用file://协议
lines = ssc.textFileStream('file:///home/spark/SparkStreaming/logfile/')
# 4. 单词统计逻辑(拆分、计数)
words = lines.flatMap(lambda line: line.split(' ')) # 按空格拆分单词
wordCounts = words.map(lambda x: (x, 1)).reduceByKey(lambda a, b: a + b) # 统计次数
# 5. 打印结果(每10秒输出一次统计)
wordCounts.pprint()
# 6. 启动流处理并等待终止
ssc.start()
ssc.awaitTermination()
NetworkWordCount.py
# 存放路径:/home/spark/SparkStreaming/socket/NetworkWordCount.py
from __future__ import print_function
import sys
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
if __name__ == "__main__":
# 检查命令行参数(必须传入主机名和端口)
if len(sys.argv) != 3:
print("用法: NetworkWordCount.py <主机名> <端口号>", file=sys.stderr)
exit(-1)
# 1. 初始化SparkContext
sc = SparkContext(appName="SocketWordCount")
sc.setLogLevel("WARN") # 减少日志输出,只显示警告和错误
# 2. 初始化StreamingContext,批次间隔5秒
ssc = StreamingContext(sc, 5)
# 3. 通过socket接收数据(从命令行参数获取主机和端口)
lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))
# 4. 单词统计逻辑(严格4个空格缩进,无Tab混用)
word_counts = lines \
.flatMap(lambda line: line.split(" ")) \
.filter(lambda word: word != "") \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b) # 按单词聚合,累加计数
# 5. 打印每批次结果(默认显示前10条)
word_counts.pprint()
# 6. 启动流处理并等待终止
ssc.start()
ssc.awaitTermination()
RDDQueueStream.py
# 存放路径:/home/spark/SparkStreaming/rddqueue/RDDQueueStreaming.py
import time
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
if __name__ == "__main__":
# 1. 初始化Spark环境,设置日志级别减少冗余输出
sc = SparkContext(appName="RDDQueueStreaming")
sc.setLogLevel("WARN") # 只显示警告和错误日志
# 2. 初始化StreamingContext,批次间隔2秒
ssc = StreamingContext(sc, 2)
# 3. 创建RDD队列,用于存放待处理的RDD
rddQueue = []
# 4. 向队列中添加5个RDD(每个RDD包含1-1000的整数,每隔1秒添加一个)
for i in range(5):
# 生成包含1-1000的RDD,分成10个分区
rdd = ssc.sparkContext.parallelize([j for j in range(1, 1001)], 10)
rddQueue.append(rdd)
time.sleep(1) # 间隔1秒添加下一个RDD
# 5. 创建RDD队列流(从队列中读取RDD进行处理)
inputStream = ssc.queueStream(rddQueue)
# 6. 处理逻辑:计算每个数模10的结果的计数(如1→1%10=1,11→11%10=1,统计1的出现次数)
mappedStream = inputStream.map(lambda x: (x % 10, 1)) # 映射为(模10结果, 1)
reducedStream = mappedStream.reduceByKey(lambda a, b: a + b) # 按模10结果聚合计数
# 7. 打印每批次的统计结果
reducedStream.pprint()
# 8. 启动流处理,等待所有RDD处理完成后再停止(修正原代码stop过早的问题)
ssc.start()
ssc.awaitTerminationOrTimeout(15) # 等待15秒(足够处理5个RDD)
ssc.stop(stopSparkContext=True, stopGraceFully=True) # 优雅停止
WindowedNetworkWordCount.py
注意修改第22行路径。
# 存放路径:/home/spark/SparkStreaming/socket/WindowedNetworkWordCount.py
from __future__ import print_function
import sys
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
if __name__ == "__main__":
# 检查命令行参数(必须提供主机名和端口)
if len(sys.argv) != 3:
print("用法: WindowedNetworkWordCount.py <主机名> <端口号>", file=sys.stderr)
exit(-1)
# 1. 初始化Spark环境,设置日志级别
sc = SparkContext(appName="WindowedSocketWordCount")
sc.setLogLevel("WARN") # 减少冗余日志,只显示警告和错误
# 2. 初始化StreamingContext,批次间隔10秒(与窗口滑动间隔一致)
ssc = StreamingContext(sc, 10)
# 3. 设置检查点目录(关键修改:适配你的路径)
# 检查点用于窗口计算中的状态存储(如增量更新计数)
checkpoint_path = "file:///home/spark/SparkStreaming/socket/checkpoint"
ssc.checkpoint(checkpoint_path)
# 4. 通过socket接收数据(从命令行参数获取主机和端口)
lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))
# 5. 窗口化单词计数逻辑(修复缩进问题)
# 窗口长度30秒(包含3个批次),滑动间隔10秒(每10秒更新一次)
# reduceByKeyAndWindow:先累加窗口内新增数据,再减去窗口外过期数据(高效计算)
counts = lines \
.flatMap(lambda line: line.split(" ")) \
.filter(lambda word: word != "") \
.map(lambda word: (word, 1)) \
.reduceByKeyAndWindow(
lambda x, y: x + y,
lambda x, y: x - y,
windowDuration=30,
slideDuration=10
)
# 6. 打印窗口化统计结果
counts.pprint()
# 7. 启动流处理并等待终止
ssc.start()
ssc.awaitTermination()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号