Hadoop实验
Hadoop实验
1. Hadoop安装配置
1.1 单机版
1.1.1下载安装
浏览器前往https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/,下载hadoop-3.3.6.tar.gz ,默认下载到~/Downloads文件夹。使用sudo tar -zxf ~/Downloads/hadoop-3.3.6.tar.gz -C /usr/local将其解压安装到/usr/local中。进入到/usr/local,使用sudo mv hadoop-3.3.6/ hadoop将其目录名改成hadoop,然后使用sudo chown -R $USER /usr/local/hadoop/修改权限(注意使用绝对路径,相对路径不会影响到/usr/local导致后续出现权限问题),将hadoop目录及其子目录的所有者改为hadoop用户,避免后续操作因权限不足无法读写文件。
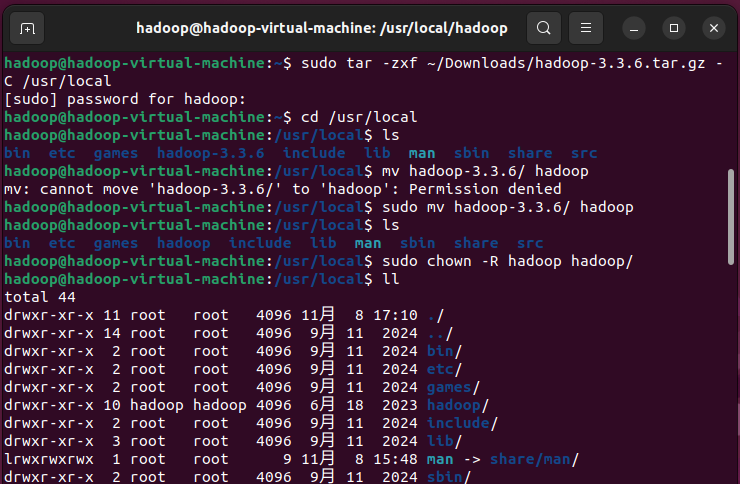
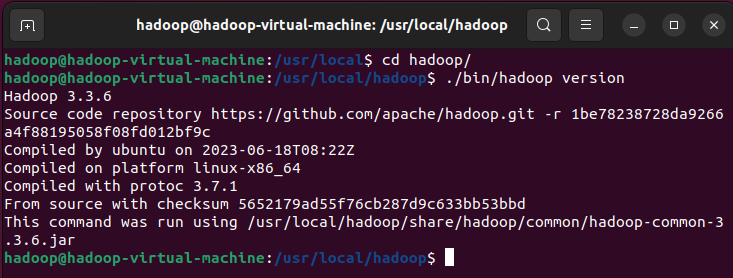
使用./bin/hadoop version检查Hadoop可用性。
1.1.2 Hadoop伪分布式配置
Hadoop可以在单节点上以伪分布式的⽅式运⾏,Hadoop进程以分离的Java进程来运⾏,单个节点既作为NameNode,也作为DataNode,同时读取的是HDFS中的⽂件。
Hadoop的运行方式是由配置⽂件决定的(运行Hadoop时会读取配置⽂件)。Hadoop的配置⽂件位于/usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置⽂件core-site.xml和 hdfs-site.xml。Hadoop配置⽂件是xml格 式 ,每个配置以声明property的name和value的⽅式来实现。
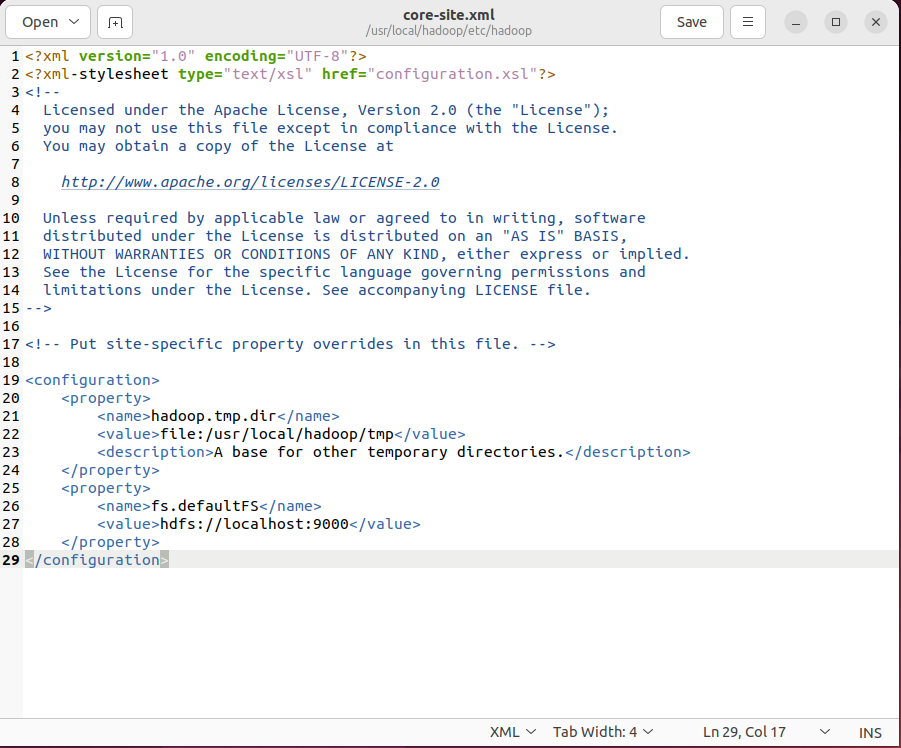
(1)修改core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hadoop.tmp.dir:指定了Hadoop临时⽬录的路径 。临时⽬录被设置为/usr/local/hadoop/tmp,临时⽬录⽤于存储Hadoop运行时产生的临时文件,如本地数据块、中间结果等。
fs.defaultFS:指定了默认的⽂件系统的URI。⽂件系统URI被设置为hdfs://localhost:9000, 表示使⽤Hadoop分布式⽂件系统(HDFS)作为默认⽂件系统,并且HDFS的NameNode服务器运⾏在本地主机的端口9000上。
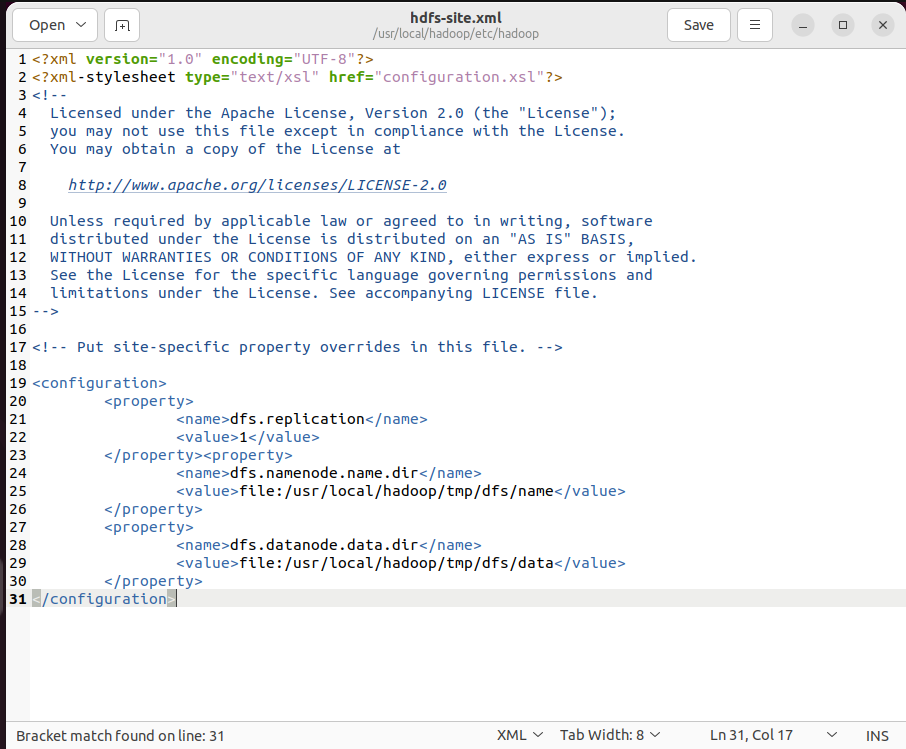
(2)修改hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property><property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
dfs.replication:对于分布式⽂件系统HDFS⽽⾔, —般都是采⽤冗余存储,冗余因⼦通常为3,即—份数据保存三份副本。在伪分布式配置中,只有本机作为DataNode节点,数据只能保存—份,所以dfs.replication的值设置为1。
dfs.namenode.name.dir:⽤于配置主(Primary)NameNode的⽬录路径,表示主NameNode的数据将存储在本地⽂件系统的/usr/local/hadoop/tmp/dfs/name路径下。
dfs.datanode.data.dir:⽤于配置数据节点(DataNode)的⽬录路径,表示数据节点的数据将存储在本地⽂件系统的/usr/local/hadoop/tmp/dfs/data路径下。
伪分布式虽然只需要配置fs.defaultFS和dfs.replication就可以运⾏(官⽅教程如此)。不过若没有配置hadoop.tmp.dir参数,则默认使⽤的临时⽬录在重启时有可能被系统清理掉,导致必须重新执⾏format才⾏,所以我们进⾏了设置;同时也指定dfs.namenode.name.dir和dfs.datanode.data.dir,否则在接下来的步骤中可能会出错。
(3)初始化NameNode元数据目录
初始化NameNode元数据目录(创建fsimage等文件),仅需执行一次;若多次执行,会导致元数据版本不一致,DataNode无法连接(需删除tmp目录后重新格式化)。
#NameNode的格式化
./bin/hdfs namenode -format
#开启NameNode和DataNode守护进程
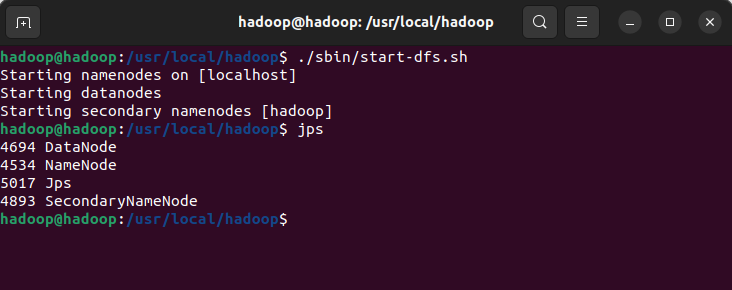
./sbin/start-dfs.sh
#检查是否成功启动
jps
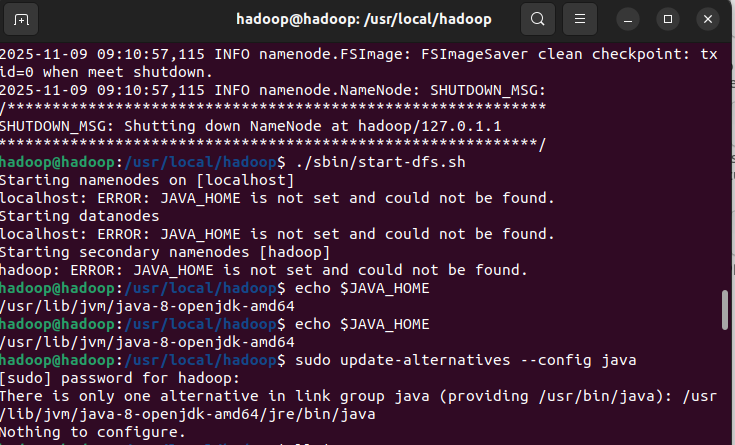
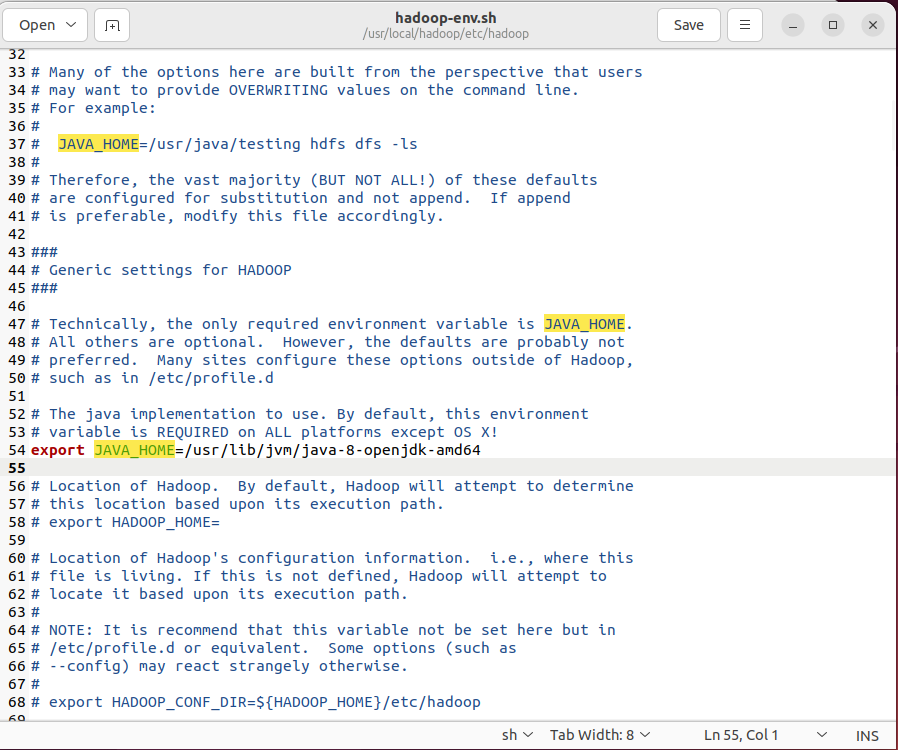
实验时发现即使~/.bashrc配置好了JAVA_HOME,运行./sbin/start-dfs.sh时仍然会提示ERROR: JAVA_HOME is not set and could not be found.。为此需要编辑./etc/hadoop/hadoop-env.sh,添加export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64然后source ./etc/hadoop/hadoop-env.sh,之后即可正常启动。
1.2 集群版
集群环境规划:以“1个Master+2个Slave”为例,节点配置为:
Master:CPU4核、内存4GB、硬盘20GB(20G在后续安装IDEA时不够,可以的话最好40G,但这里为了方便直接克隆就用20G的)
Slave1/Slave2:CPU2核、内存4GB、硬盘20GB
1.2.1 环境配置
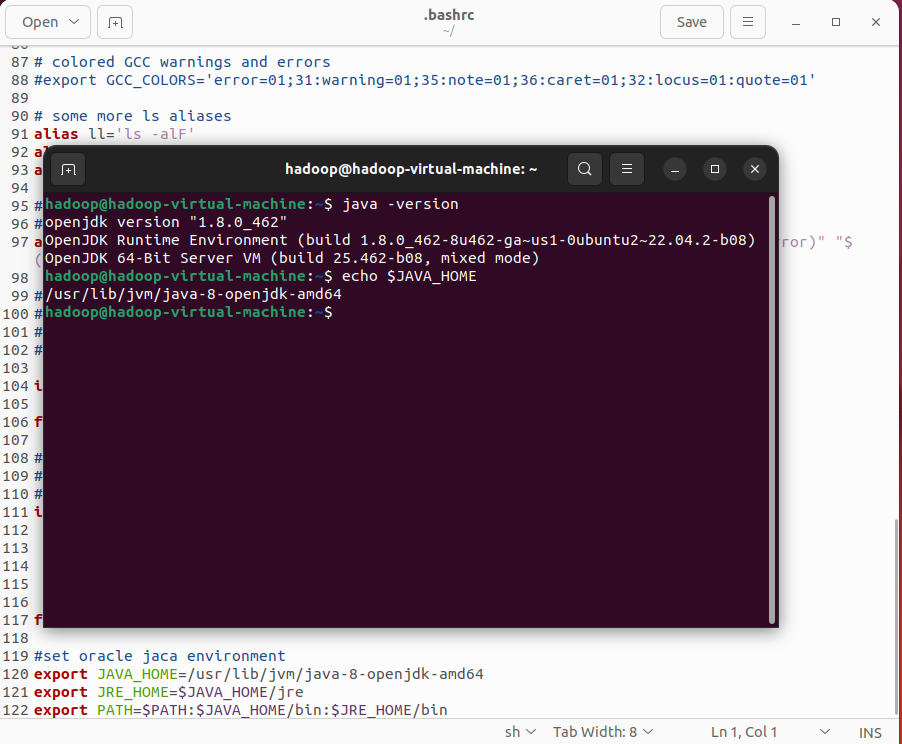
通过单机版实验时的快照克隆虚拟机为master,修改配置为4核4G。该快照已换源,但还未安装Java,使用sudo apt install openjdk-8-jdk进行安装,使用sudo update-alternatives --config java获取JDK根目录,然后配置~/.bashrc添加下面的内容然后source。
#set oracle jaca environment
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export JRE_HOME=$JAVA_HOME/jre
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
关机后通过克隆得到slave1和slave2。分别修改三台虚拟机的hostname,分别为master,slave1,slave2(/etc/hosts中127.0.1.1的主机名不用管,后续直接删除或注释),修改完后重启。
#修改主机名
sudo gedit /etc/hostname # 或使用sudo hostnamectl set-hostname master
#重启虚拟机,主机名修改生效
sudo reboot
重启后执行hostname,输出新主机名,说明修改成功。
执行sudo apt-get install net-tools安装网络工具,运行ifconfig查看inet地址处的虚拟机内网IP。主机名映射如下:
# Hadoop hosts
192.168.26.130 master
192.168.26.131 slave1
192.168.26.132 slave2
将其添加到/etc/hosts,同时注释或删除127.0.1.1的映射。
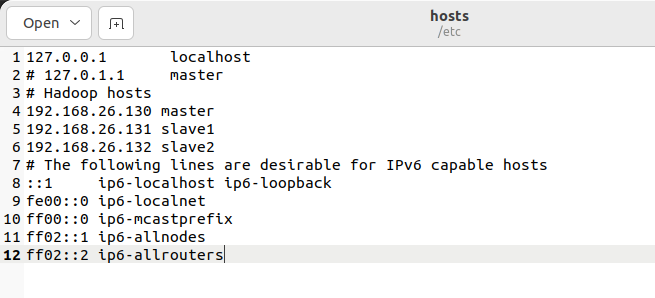
hosts文件作用:将主机名映射到IP地址,避免集群节点间通过IP地址通信(便于记忆与维护),所有节点的hosts文件需配置相同的映射关系。
1.2.2 ssh配置
Hadoop集群节点间通过SSH通信(如Master向Slave发送启动命令),SSHServer需在所有节点安装,SSHClient默认已安装。
#安装SSH Server
sudo apt install openssh-server -y
# 启动ssh
sudo service ssh start
# 设置开机⾃启
sudo systemctl enable ssh
# 确认是否设置开机⾃启成功
sudo systemctl is-enabled ssh
设置免密连接登录,通过生成RSA密钥对(公钥+私钥),将公钥复制到目标节点的authorized_keys文件中,后续登录时无需输入密码。仅在master节点执行下面命令即可。
# 生成RSA密钥对
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
# 注意master节点自己也要添加公钥(启动dfs时会用到)
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
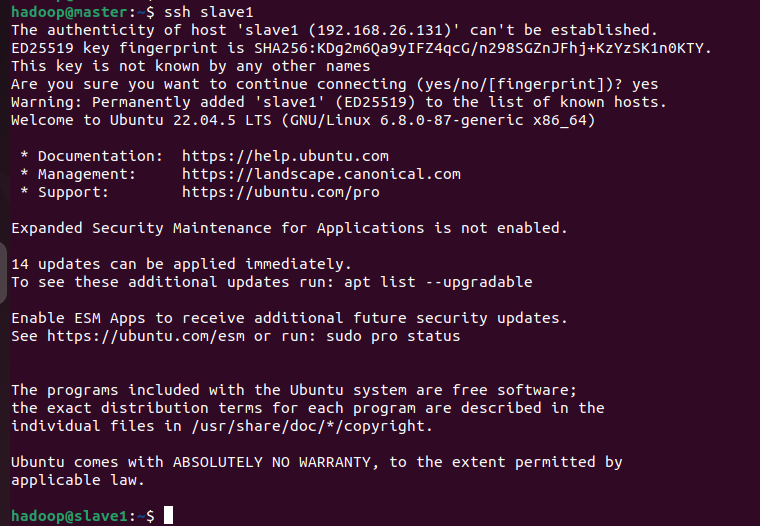
分别在两台slave虚拟中执行以下两条命令,两台slave虚拟机都需要执行,注意是在slave虚拟机执行,其中hadoop@master @前面是用户名,后面是主机名hostname。
scp hadoop@master:~/.ssh/id_rsa.pub ~/.ssh/master_rsa.pub
cat ~/.ssh/master_rsa.pub >> ~/.ssh/authorized_keys
1.2.3 安装Hadoop
安装hadoop 只需要在master主机中安装即可,后面会通过节点复制。
安装链接: https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common
# cd到Downloads目录,可以看到下载的hadoop包
cd ~/Downloads
ls
# 解压
tar -zxvf hadoop-3.3.6.tar.gz -C ~/
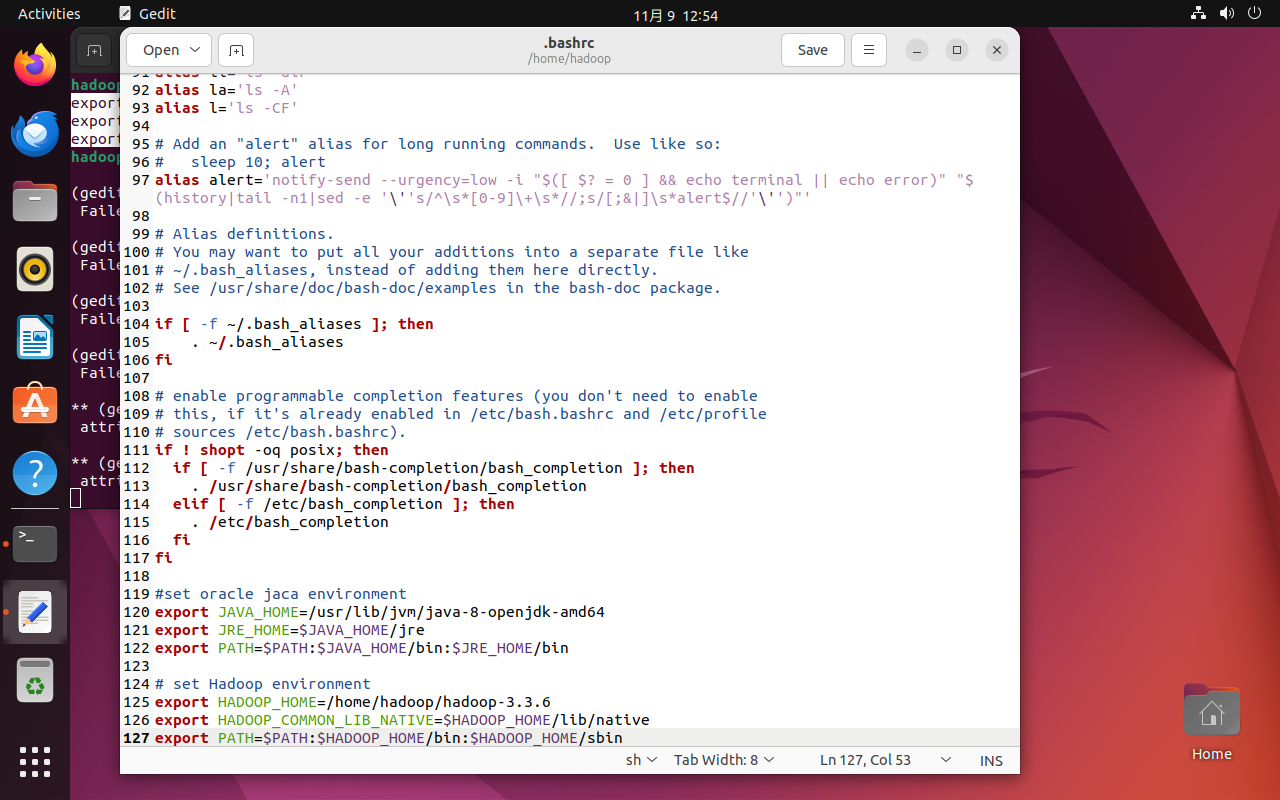
安装完成后编辑~/.bashrc修改环境变量,添加以下内容然后source。
# set Hadoop environment
export HADOOP_HOME=/home/hadoop/hadoop-3.3.6
export HADOOP_COMMON_LIB_NATIVE=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
1.2.4 核心配置文件
进入~/hadoop-3.3.6/etc/hadoop,修改以下配置文件(修改前建议cp备份):
-
hadoop-env.sh:Hadoop环境变量配置(指定 JAVA_HOME) -
core-site.xml:Hadoop核心配置(默认文件系统、临时目录) -
hdfs-site.xml:HDFS配置(副本数、元数据/数据存储路径) -
mapred-site.xml:MapReduce配置(框架类型、历史服务器地址) -
yarn-site.xml:YARN配置(资源管理器、节点管理器端口) -
workers:集群节点列表(指定Slave节点主机名)
编辑hadoop-env.sh,指定JAVA_HOME。

编辑core-site.xml,添加如下内容:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
<description>hdfs namenode port</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-3.3.6/tmp</value>
<description>A base for other temporary directories</description>
</property>
</configuration>
编辑hdfs-site.xml,添加如下内容:
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/hadoop-3.3.6/dfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/hadoop-3.3.6/dfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
<final>true</final>
</property>
<property>
<name>dfs.webhdfs.enable</name>
<value>true</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>master:50090</value>
</property>
</configuration>
编辑mapred-site.xml,添加如下内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
编辑yarn-site.xml,添加如下内容:
<configuration>
<!-- Site specific YARN configuration property -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
workers文件作用:指定Hadoop集群中的Slave节点(DataNode与NodeManager运行节点),Master节点默认不运行DataNode(若需Master运行DataNode,可将master添加到workers文件)。
配置workers文件,加入三台主机名主机名必须一致,与在hosts中写入的hostname必须一致。

所有节点的配置文件需完全一致,避免因配置差异导致集群通信失败;路径需使用绝对路径,且确保所有节点的路径存在(如/home/hadoop/hadoop-3.3.6/dfs/name),并设置权限(sudo chown -R $USER /home/hadoop/hadoop-3.3.6)。
1.2.5 向slave虚拟机复制hadoop节点
在master节点执行:
scp -r hadoop-3.3.6 hadoop@slave1:~/
scp -r hadoop-3.3.6 hadoop@slave2:~/
1.2.6 启动Hadoop
在master节点cd到hadoop-3.3.6中,执行以下命令格式化namenode:
./bin/hdfs namenode -format
执行后会自动在master节点启动NameNode/SecondaryNameNode,在slave节点启动DataNode。
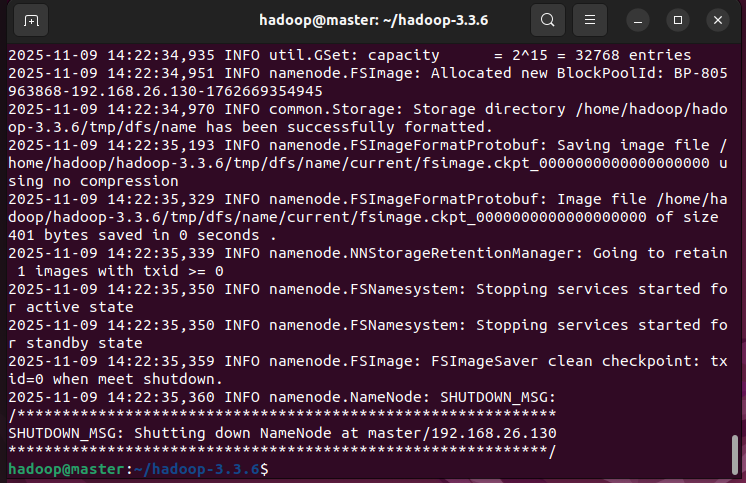
#启动hdfs
./sbin/start-dfs.sh
#输入jps查看节点
jps
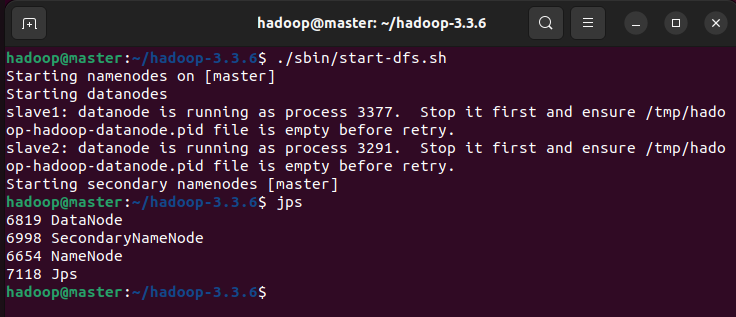
到slave节点输入jps查看启动情况,若是出现错误,可查看日志文件(位于~/hadoop-3.3.6/logs目录),如hadoop-master-namenode-master.log,日志中“ERROR”信息可定位问题原因。
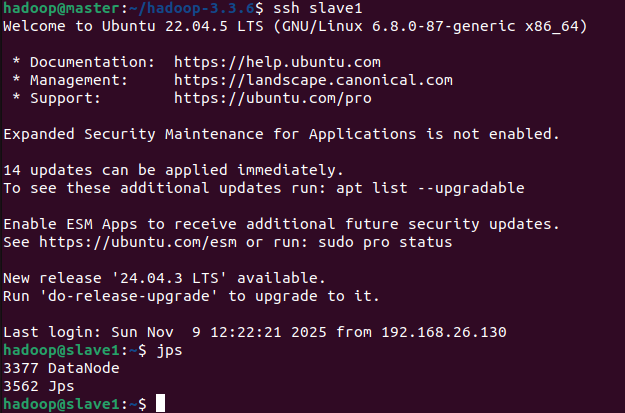
1.2.7 Web UI访问
在master节点浏览器输入http://master:9870(或 http://192.168.26.130:9870 )。若需在主机(Windows/Mac)访问,需确保虚拟机与主机在同一局域网,且关闭虚拟机防火墙。
-
Overview:查看集群状态(如启动时间、版本、容量)
-
Datanodes:查看 Slave 节点状态(如IP、存储使用率、是否活跃)
-
Browse the file system:浏览HDFS文件目录
1.2.8 启动YARN
在master节点执行./sbin/start-yarn.sh,执行后会在Master节点启动ResourceManager,在Slave节点启动NodeManager。
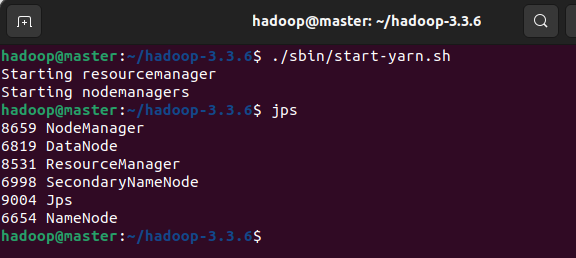
在Master节点执行jps,新增进程:ResourceManager、NodeManager(若Master在workers文件中,会启动NodeManager)。也可通过访问http://master:8088访问查看。
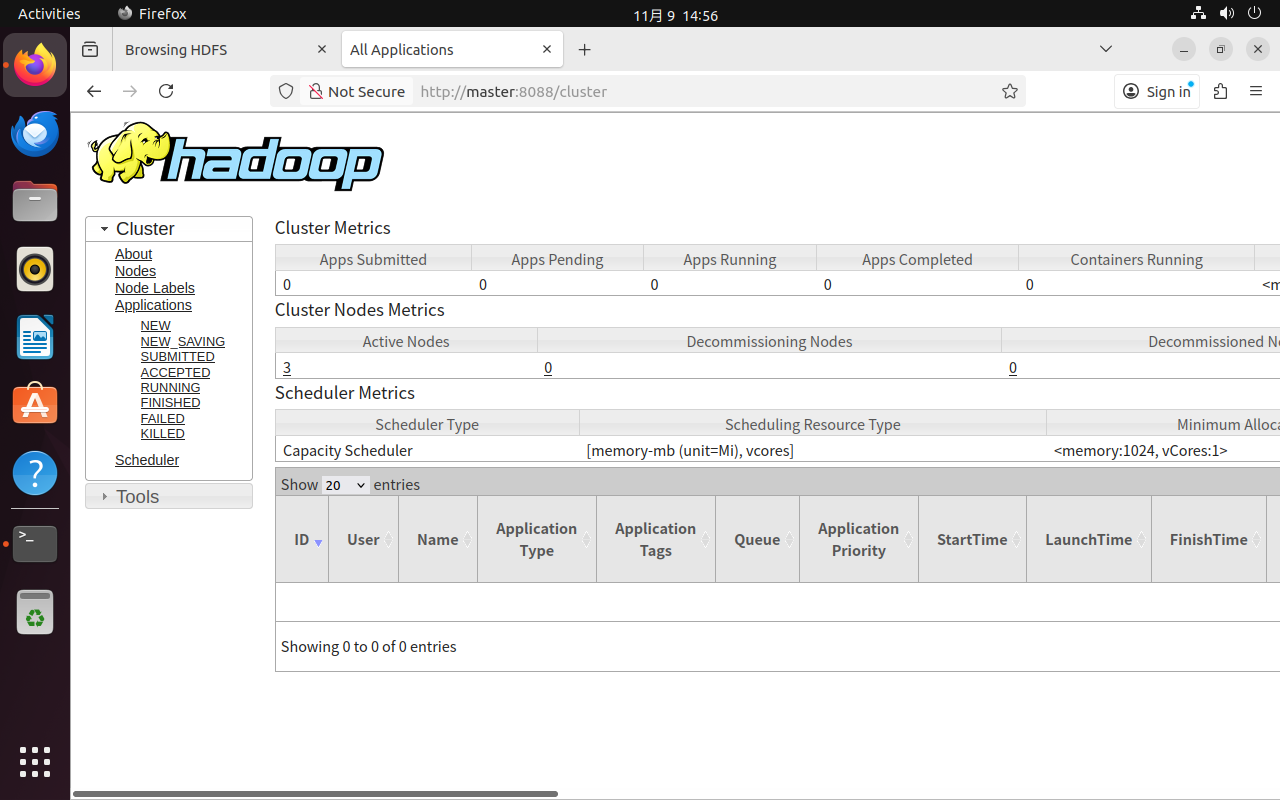
在Slave节点执行jps,新增进程:NodeManager。
1.2.9 历史记录服务
历史记录服务用于记录MapReduce作业的运行日志(如提交时间、运行状态、日志链接),便于查看作业历史信息。
仅需在Master节点执行,Slave节点无需启动。
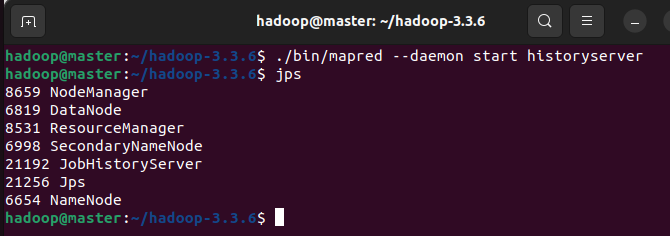
# 启动历史记录服务
./bin/mapred --daemon start historyserver
# 查看服务是否开启
jps
2. MapReduce实验
实验使用MapReduce进行词频统计。
2.1 数据准备
在Linux系统本地创建两个文件,即文件wordfile1.txt和wordfile2.txt。在实际应用中,这两个文件可能会非常大,会被分布存储到多个节点上。但是,为了简化任务,这里的两个文件只包含几行简单的内容。
针对这两个小数据集样本编写的MapReduce词频统计程序,不作任何修改,就可以用来处理大规模数据集的词频统计。
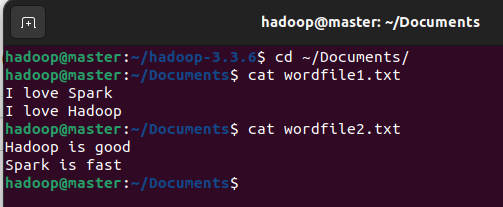
在HDFS文件目录中创建/user/hadoop/input ,为后续上传文件准备存储路径。
hdfs dfs -mkdir -p /user/hadoop/input/
通过-p参数递归创建多级目录,确保
/user/hadoop/input路径下的所有父目录不存在时自动创建。
使用put命令将本地文件上传到HDFS的指定目录。
hdfs dfs -put ~/Documents/wordfile1.txt /user/hadoop/input
hdfs dfs -put ~/Documents/wordfile2.txt /user/hadoop/input
2.2 编写MapReduce Java程序
前往Eclipse官网下载Eclipse IDE for Java DevelopersPackage,因为installer需要Java 17,所以选择直接下载Package,解压后双击Eclipse运行即可。
新建Project,编辑相关设置。点击Next >后点击界面中的Libraries选项卡,点击Classpath后在右侧点击Add External JARs…按钮,添加如下内容:
-
hadoop-3.3.6/share/hadoop/common/目录下的hadoop-common-3.3.6.jar和haoop-nfs-3.3.6.jar
-
hadoop-3.3.6/share/hadoop/common/lib”目录下的所有JAR包(
Ctrl+A全选所有jar包) -
hadoop-3.3.6/share/hadoop//mapreduce目录下的所有JAR包,不包括jdiff、lib-examples和sources目录
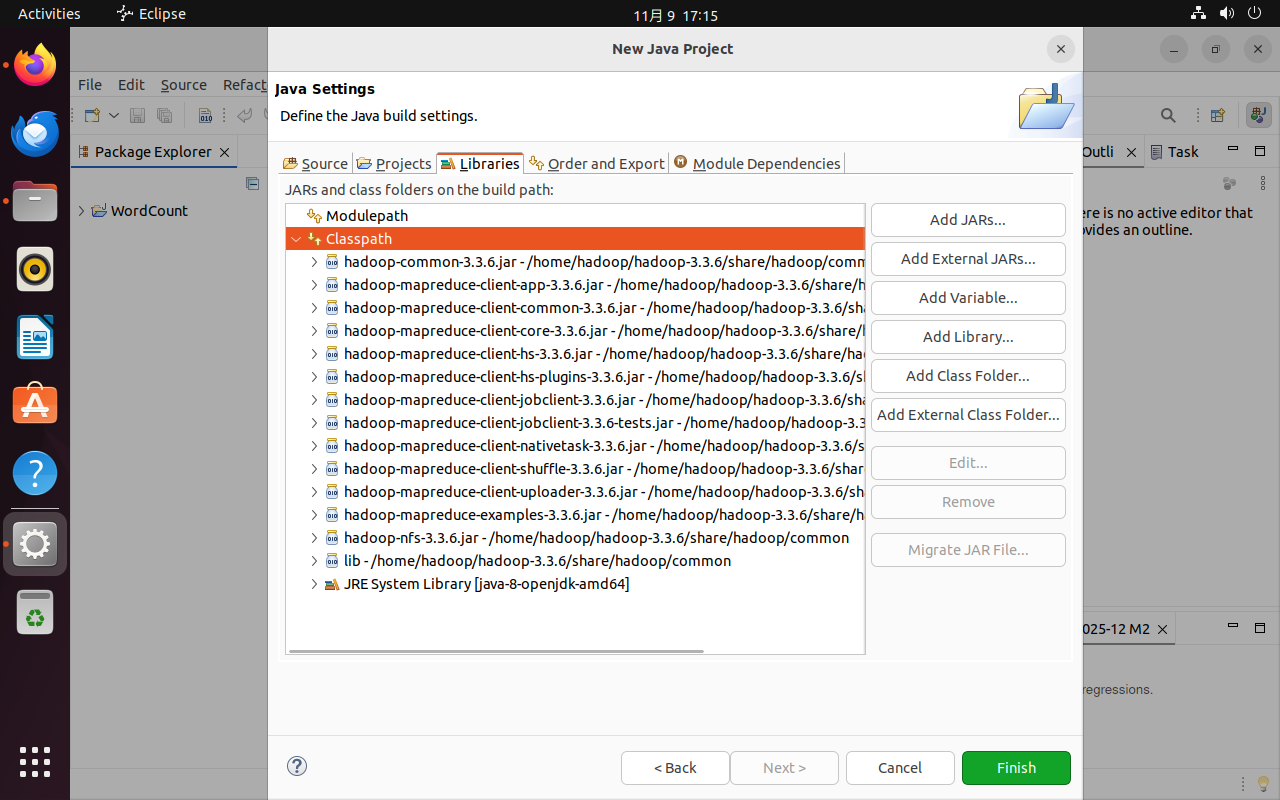
新建Class,编辑package和name均为wordCount后点击Finish。
编辑wordCount.java文件内容为词频统计程序代码(详见附录)。
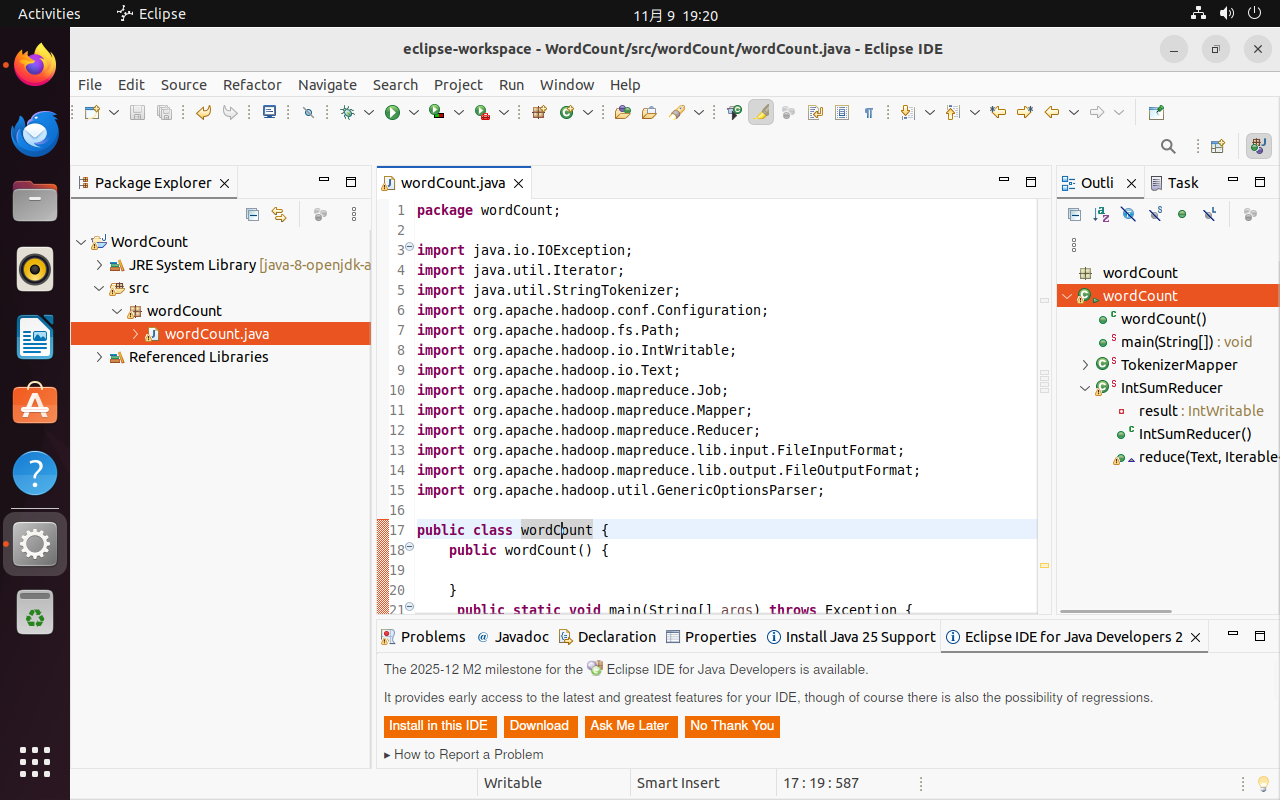
2.3 编译打包Java程序
编译上面编写的代码,可以直接点击Eclipse工作界面上部的运行程序的快捷按钮,当把鼠标移动到该按钮上时,在弹出的菜单中选择“Run as”,继续在弹出来的菜单中选择“Java Application”开始运行程序。程序运行结束后,会在底部的“Console”面板中显示运行结果信息。
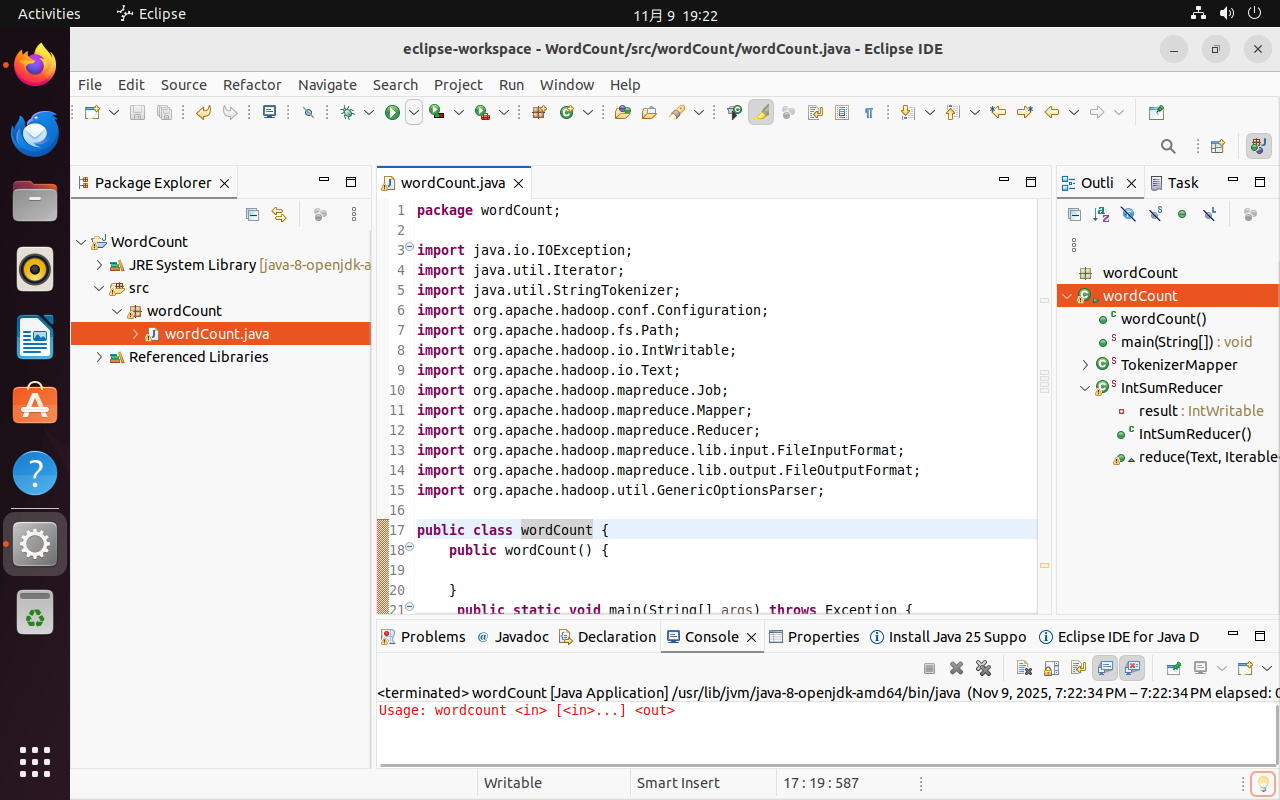
运行报错是正常的,因为这是个命令行应用,需要提供命令行参数,因此下面将其导出为jar包。
在Eclipse工作界面左侧的Package Explorer面板中,在工程名称wordCount上点击鼠标右键,在弹出的菜单中选择Export,如下图所示。
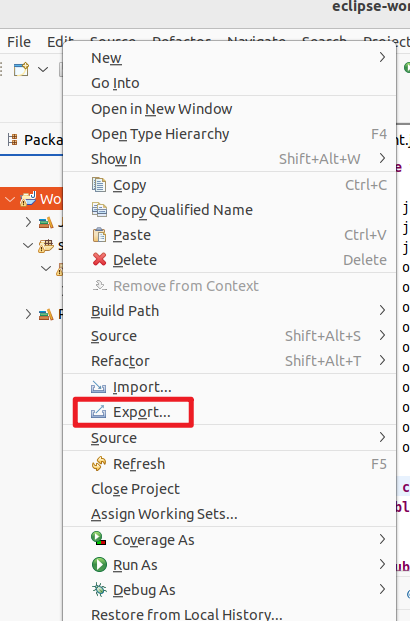
在弹出的界面中选择Java-->Runable JAR file,然后点击next。
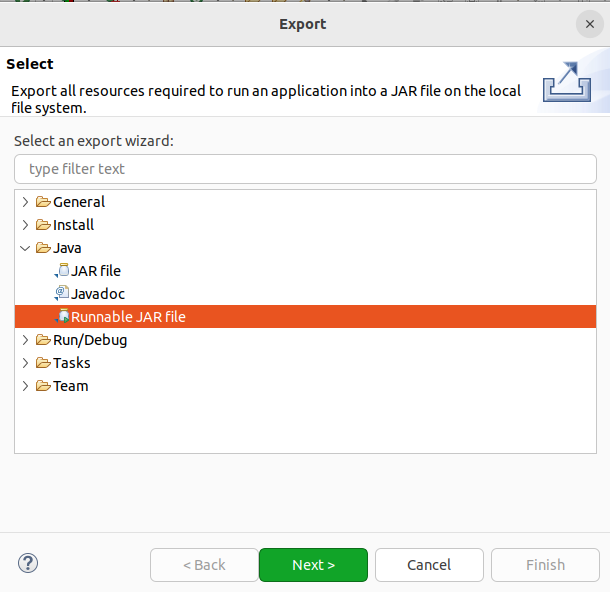
Launch configuration用于设置生成的JAR包被部署启动时运行的主类,需要在下拉列表中选择刚才配置的类wordCount-wordCount。在Export destination中需要设置JAR包要输出保存到哪个目录。在Library handling下面选择Extract required libraries into generated JAR。然后,点击Finish按钮。
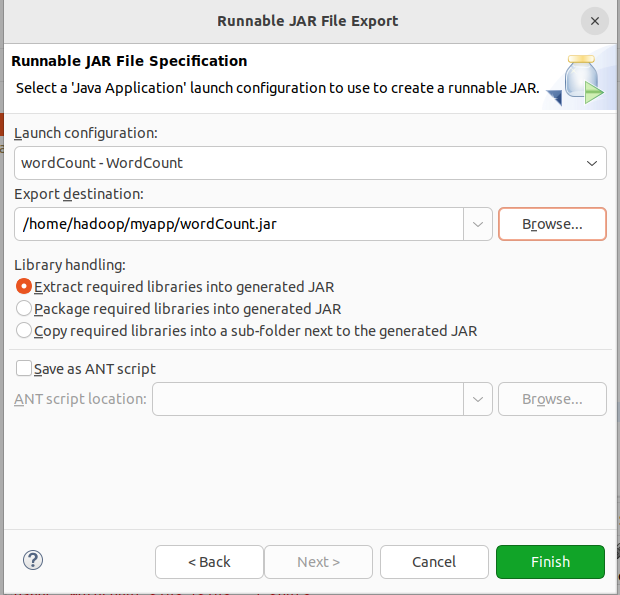
之后会弹出一个警告界面,可以忽略该界面的信息,直接点击界面右下角的OK按钮,启动打包过程。打包过程结束后,会出现一个警告信息界面,忽略。
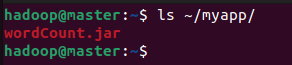
至此,已经顺利把wordCount工程打包生成了wordCount.jar。可以到Linux系统中使用ls ~/myapp查看生成的JAR包文件。
2.4 运行程序
在运行程序之前,需要确保启动Hadoop(./sbin/start-dfs.sh启动)。
在启动Hadoop之后,需要首先删除HDFS中与当前Linux用户hadoop对应的output目录,即HDFS中的/user/hadoop/output目录,这样确保后面程序运行不会出现问题。如果HDFS中已经存在目录/user/hadoop/output,执行hdfs dfs -rm -r /user/hadoop/output进行删除。
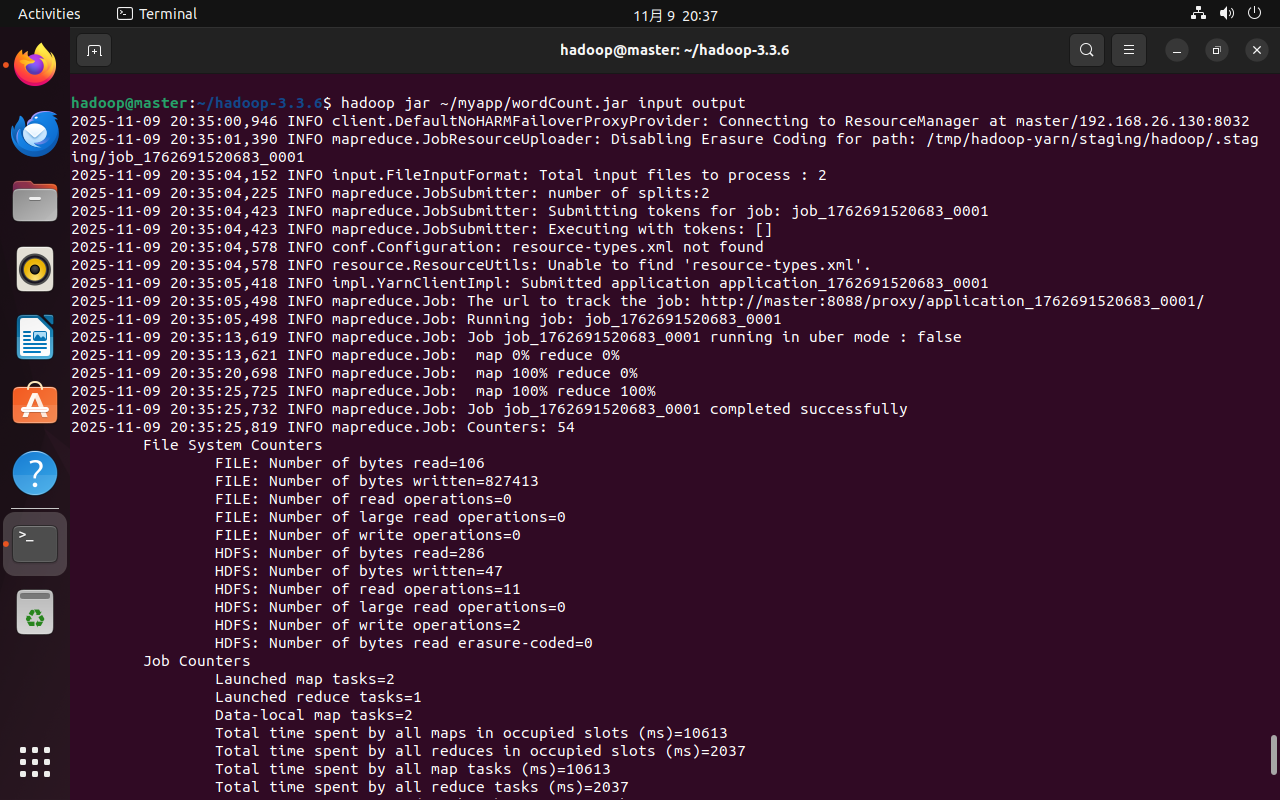
在Linux系统中,使用hadoop jar命令运行程序:
cd ~/hadoop-3.3.6
./bin/hadoop jar ~/myapp/wordCount.jar input output
# 或在任意目录下直接使用hadoop(因已配置PATH)
hadoop jar ~/myapp/wordCount.jar input output
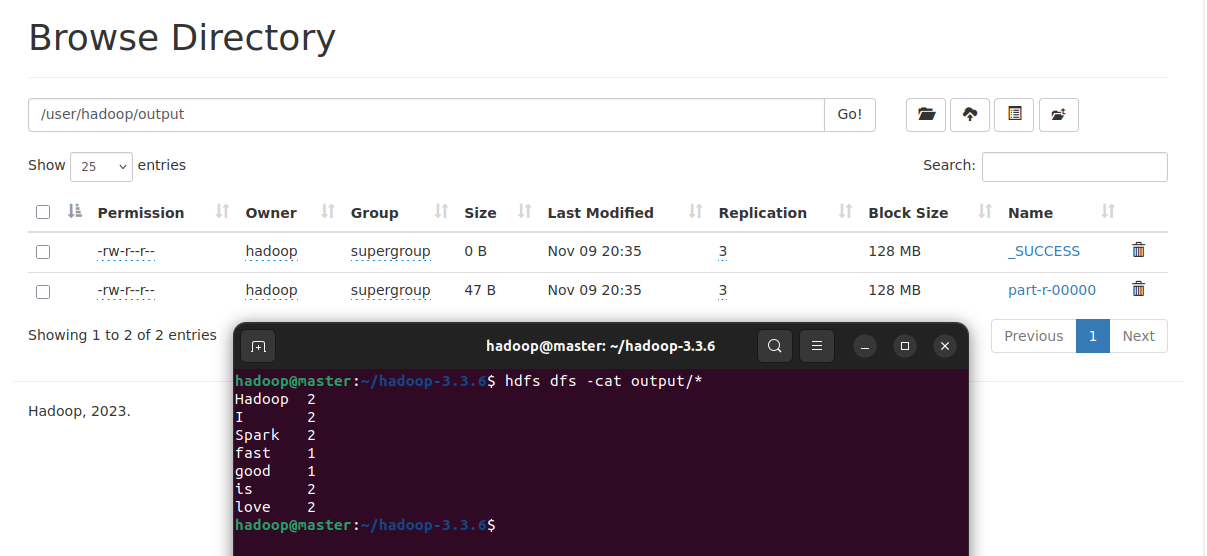
词频统计结果已经被写入了HDFS的/user/hadoop/output目录中。使用hdfs dfs -cat output/*查看结果。
3. HDFS实验
3.1 常用HDFS操作
在操作前需明确HDFS的核心组件(NameNode管理元数据、DataNode存储数据块)、数据模型(文件分块存储,默认块大小128MB)、权限模型(与Linux类似,分为所有者、组、其他用户权限),避免操作时因概念混淆导致错误。
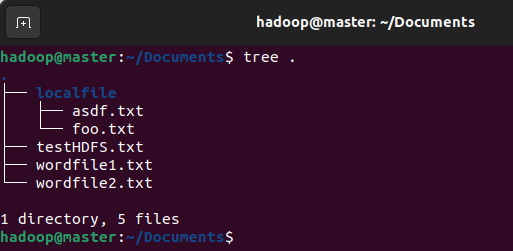
执行下面的命令准备操作的文件:
echo testHDFS > ~/Documents/testHDFS.txt
mkdir ~/Documents/localfile
touch ~/Documents/localfile/foo.txt
touch ~/Documents/localfile/asdf.txt
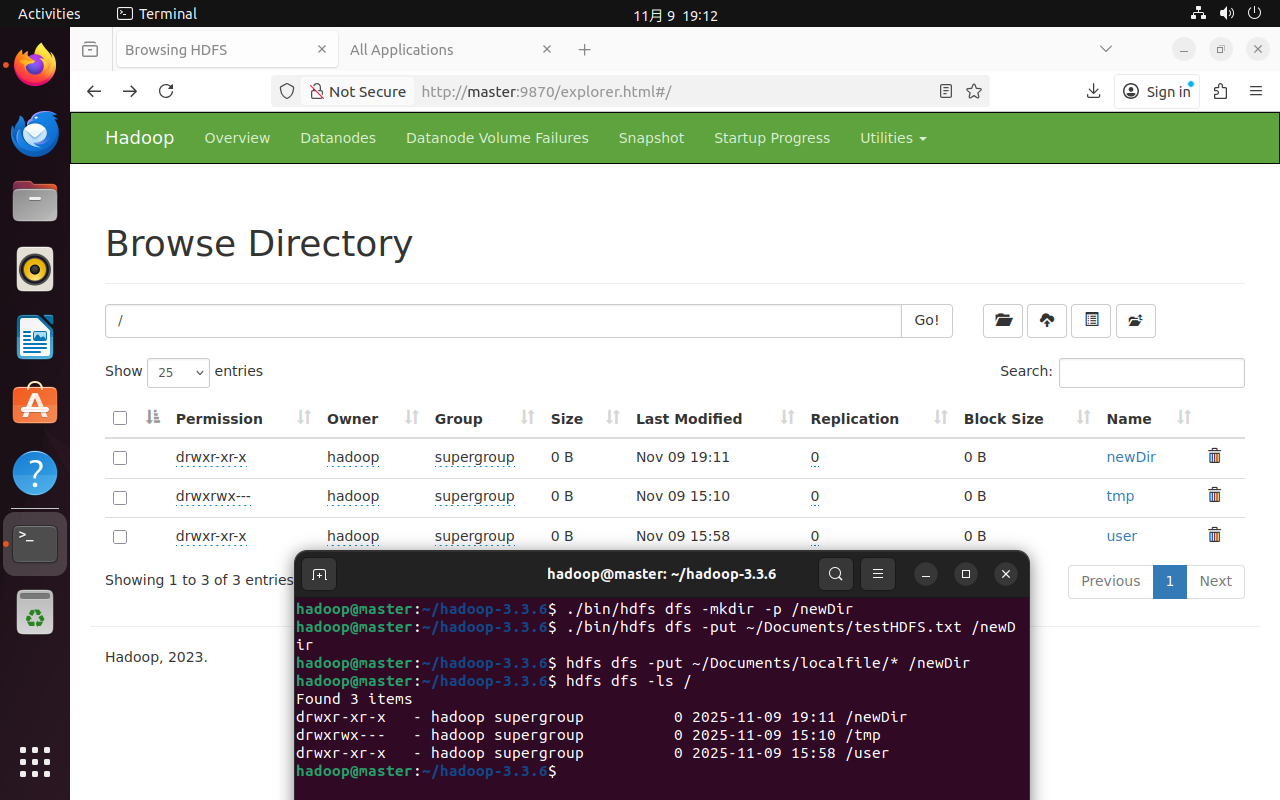
执行下面的命令,前往http://master:9870的browse the file system可以实时查看操作效果。
cd ~/hadoop-3.3.6 # 因配置了环境变量,也可直接使用hdfs
# 创建文件夹
./bin/hdfs dfs -mkdir -p /newDir
# 上传文件
./bin/hdfs dfs -put ~/Documents/testHDFS.txt /newDir/
# 批量上传上传本地目录下所有文件
hdfs dfs -put ~/Documents/localfile/* /newDir
# 查看HDFS中的文件和目录
hdfs dfs -ls /
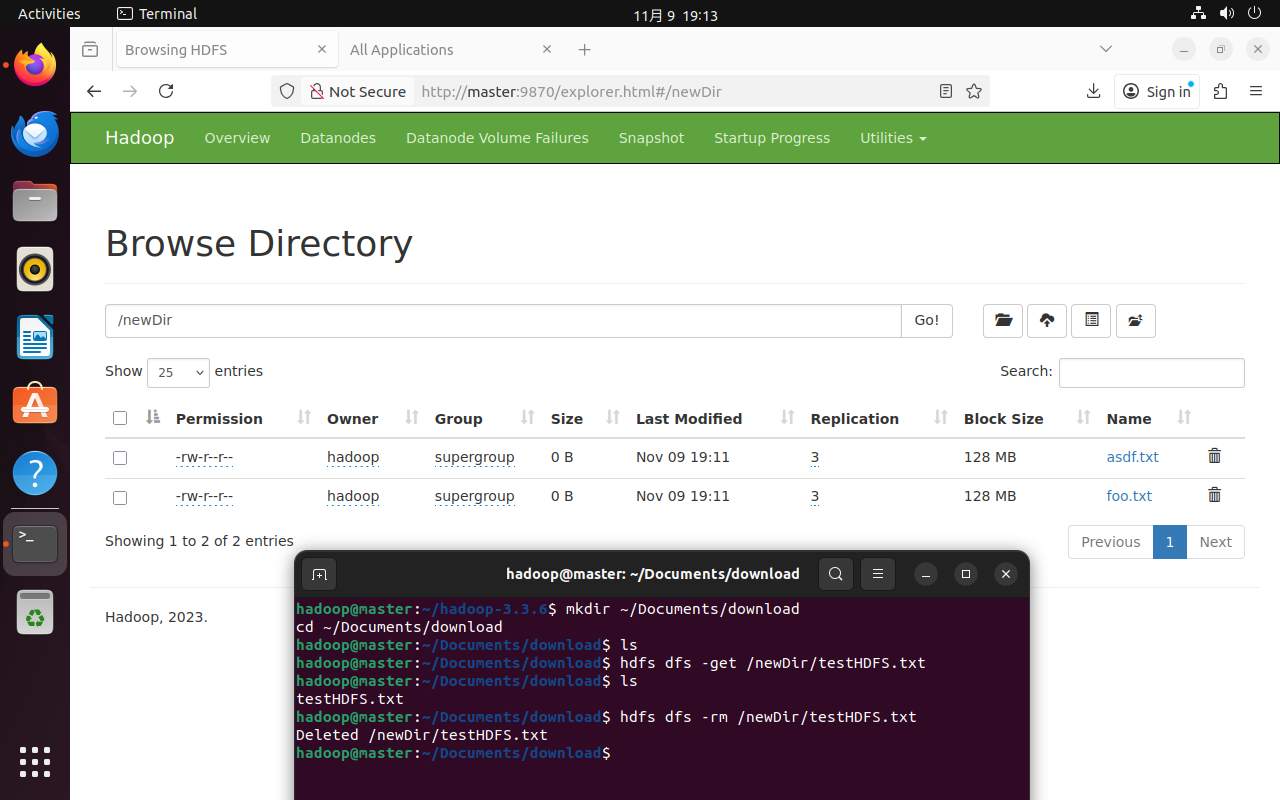
mkdir ~/Documents/download
cd ~/Documents/download
# 从HDFS下载文件
hdfs dfs -get /newDir/testHDFS.txt
# 删除HDFS中的文件
hdfs dfs -rm /newDir/testHDFS.txt
3.2 HDFS Java API
3.2.1 安装IDEA
进入IDEA官网,下载IDEA社区版。
# 在Downloads文件夹下解压
cd ~/Downloads
sudo tar -zxf ideaIC-2025.2.4.tar.gz -C /opt
# 修改配置文件
gedit ~/.bashrc
#添加如下环境变量
export IDEA_HOME=/opt/idea-IC-252.27397.103
export PATH=${IDEA_HOME}/bin:$PATH
# 更新启用环境变量
source ~/.bashrc
3.2.2 创建项目
cd $IDEA_HOME/bin后执行./idea.sh启动IDEA。新建项目HDFS_JavaAPI,build system选择Maven。其他配置默认即可。
Maven作用说明:Maven是Java项目管理工具,可自动管理项目依赖(JAR包)、构建项目(编译、打包),避免手动下载与导入JAR包的繁琐操作。
Maven 项目默认结构为:
src/main/java:存放 Java 源代码(如org.example包下的JavaAPI.java)
src/main/resources:存放配置文件(如log4j.properties,用于日志配置)
src/test/java:存放测试代码(如 JUnit 测试类)
pom.xml:Maven 核心配置文件(管理依赖、构建规则)
编辑pom.xml(Maven项目的核心文件)文件,写入以下内容,然后右键-->Maven-->Sync Project导入依赖。
<dependencies>
<!-- Hadoop所需依赖包 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.4</version>
</dependency>
<!-- junit测试依赖 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>
pom.xml作用:定义项目依赖的JAR包(如Hadoop相关JAR包、JUnit测试JAR包),Maven会根据配置自动从中央仓库下载依赖到本地仓库(默认~/.m2/repository)。
右键test/java创建一个类JavaAPI,添加[附录](#HDFS Java API)中内容。注意init函数中的用户名配置正确。
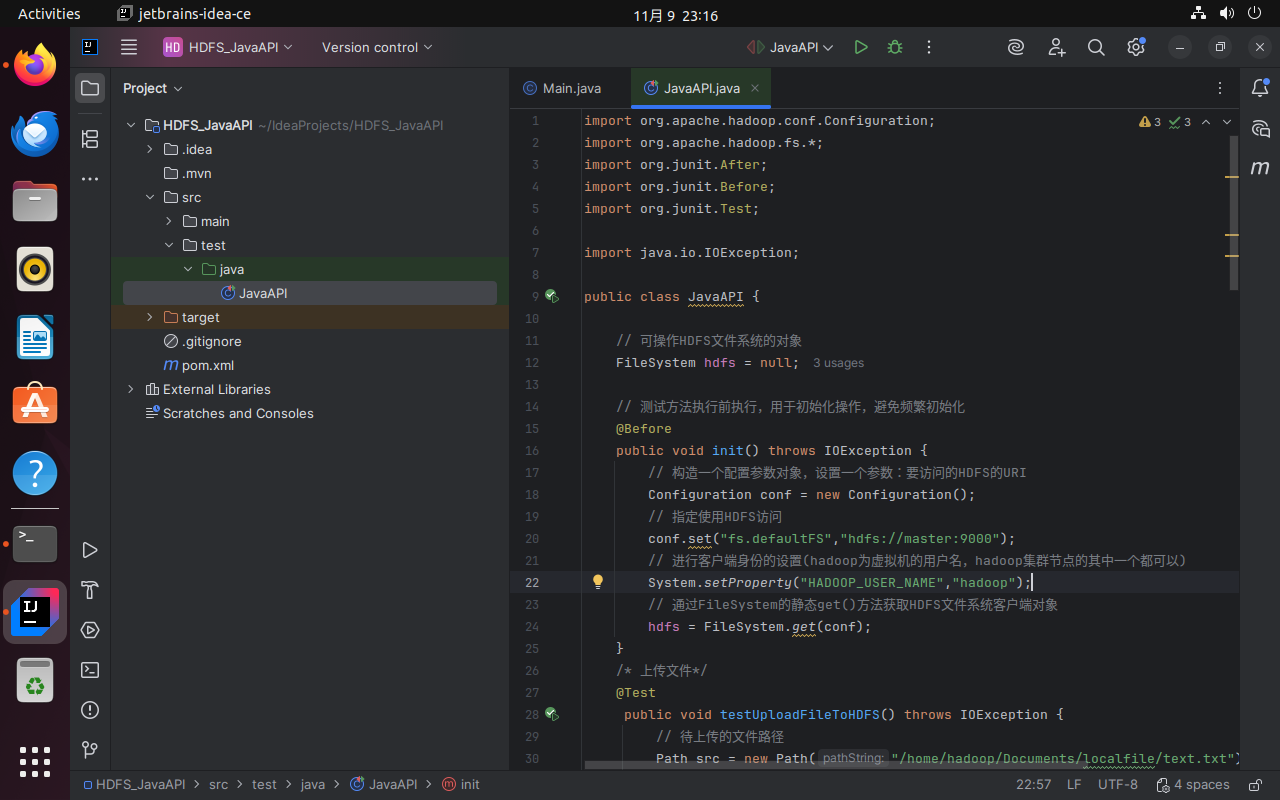
3.2.3 测试文件准备
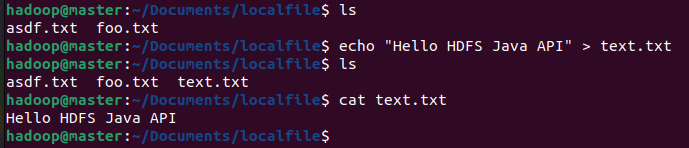
在本地~/Documents/localfile目录下创建text.txt(内容如"Hello HDFS Java API"),用于后续上传测试。
批量创建文件:可通过命令行快速创建(
for i in {1..5}; do echo "Test file $i" > ~/Documents/localfile/text$i.txt; done,创建 text1.txt 到 text5.txt)
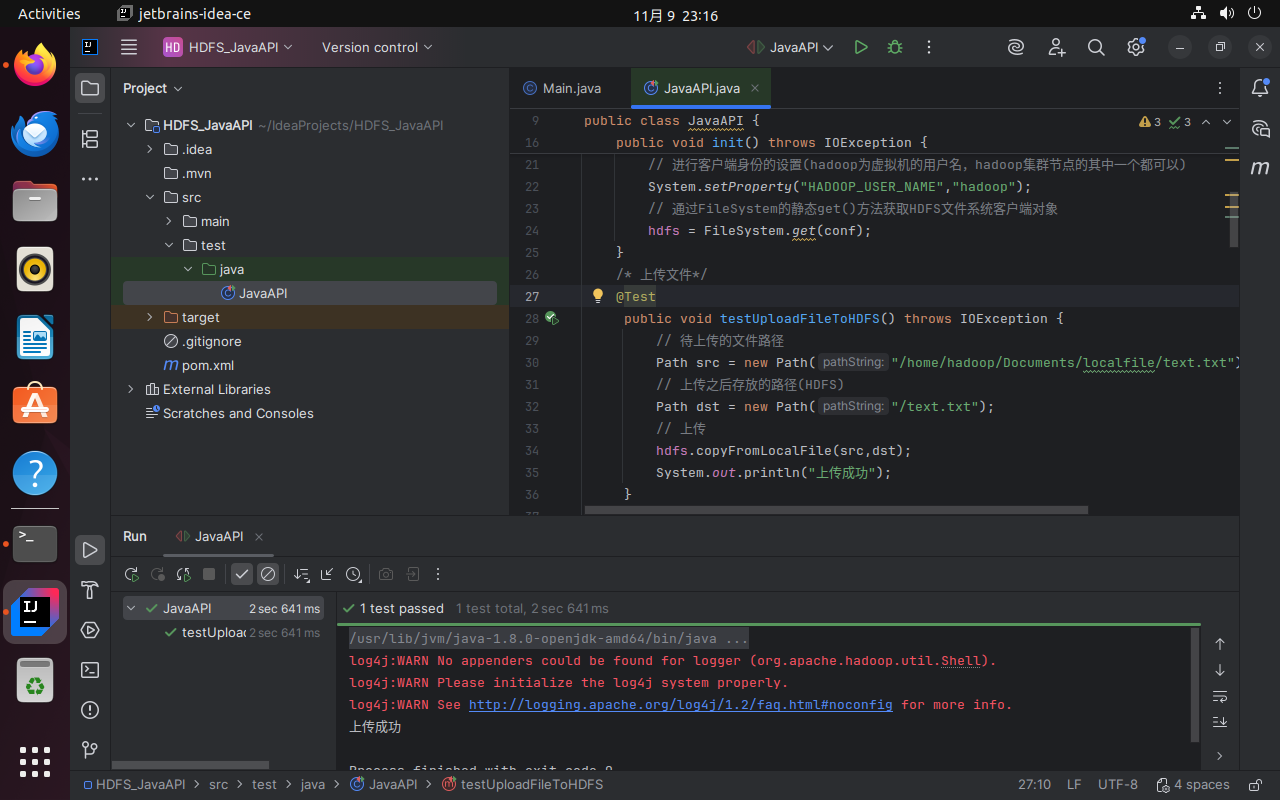
3.2.4 执行Java API
单独取消testUploadFileToHDFS的注释,运行程序。
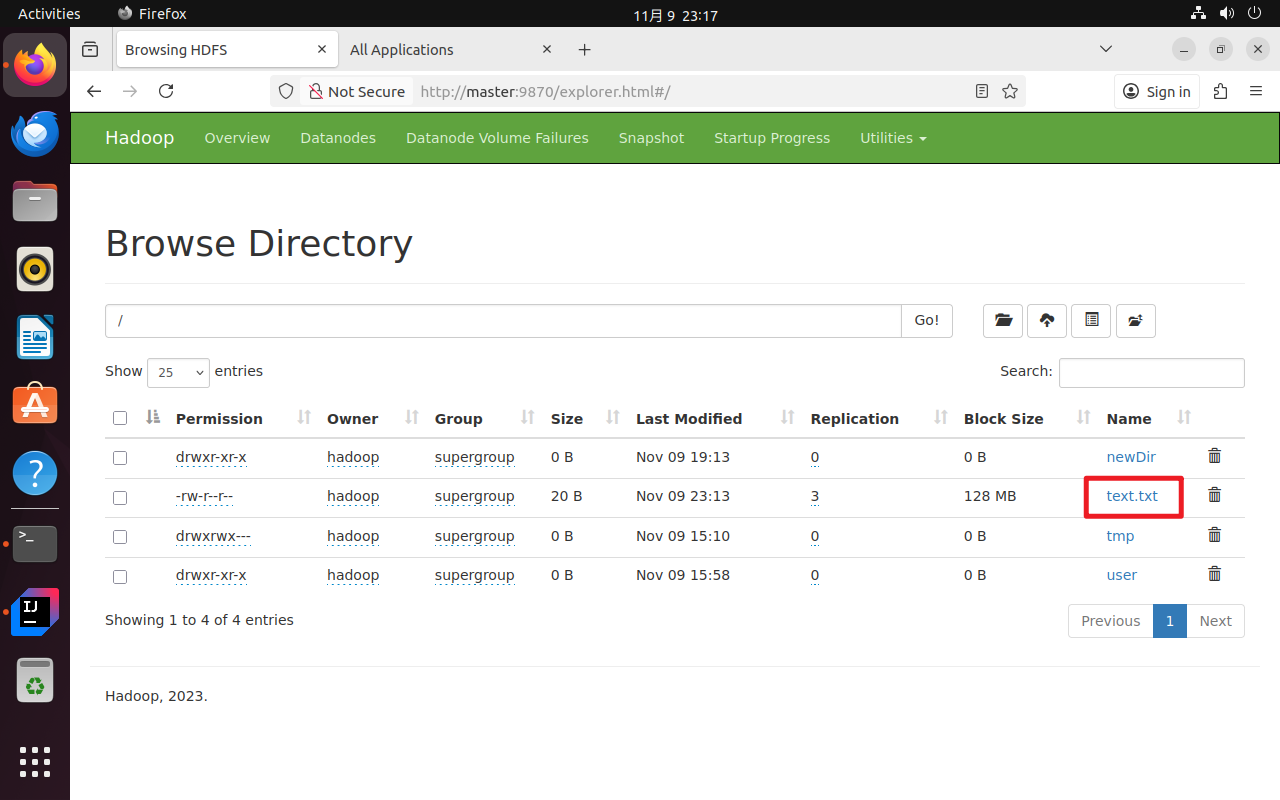
单独取消testDownFileToLocal的注释,运行程序。
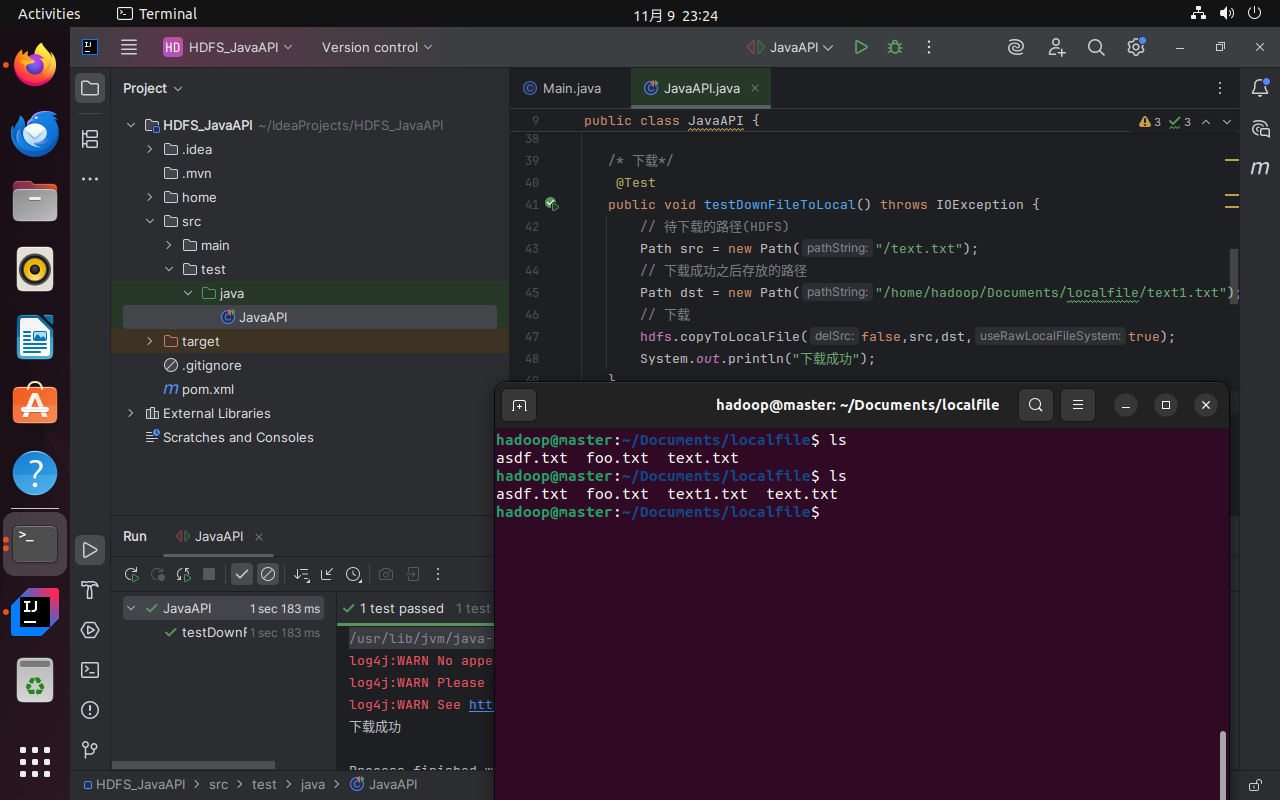
单独取消testRenameFile的注释,运行程序。
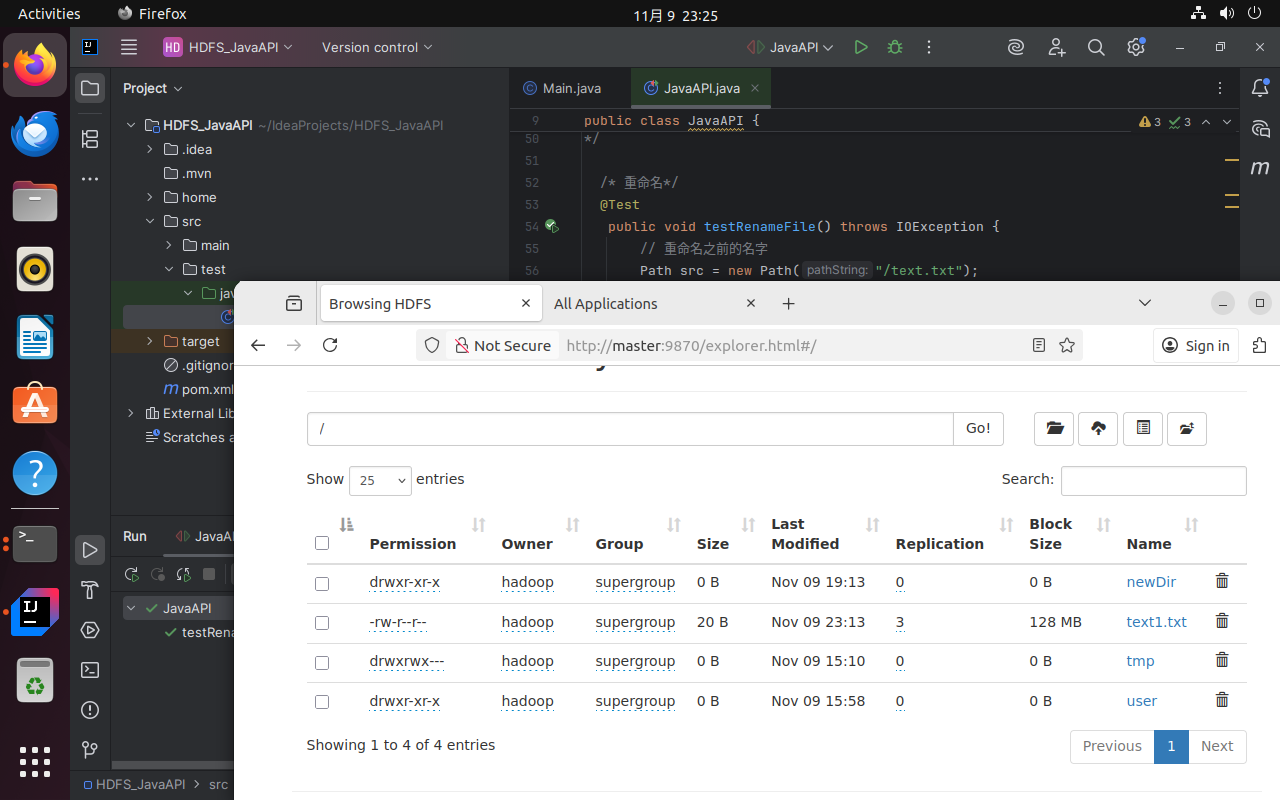
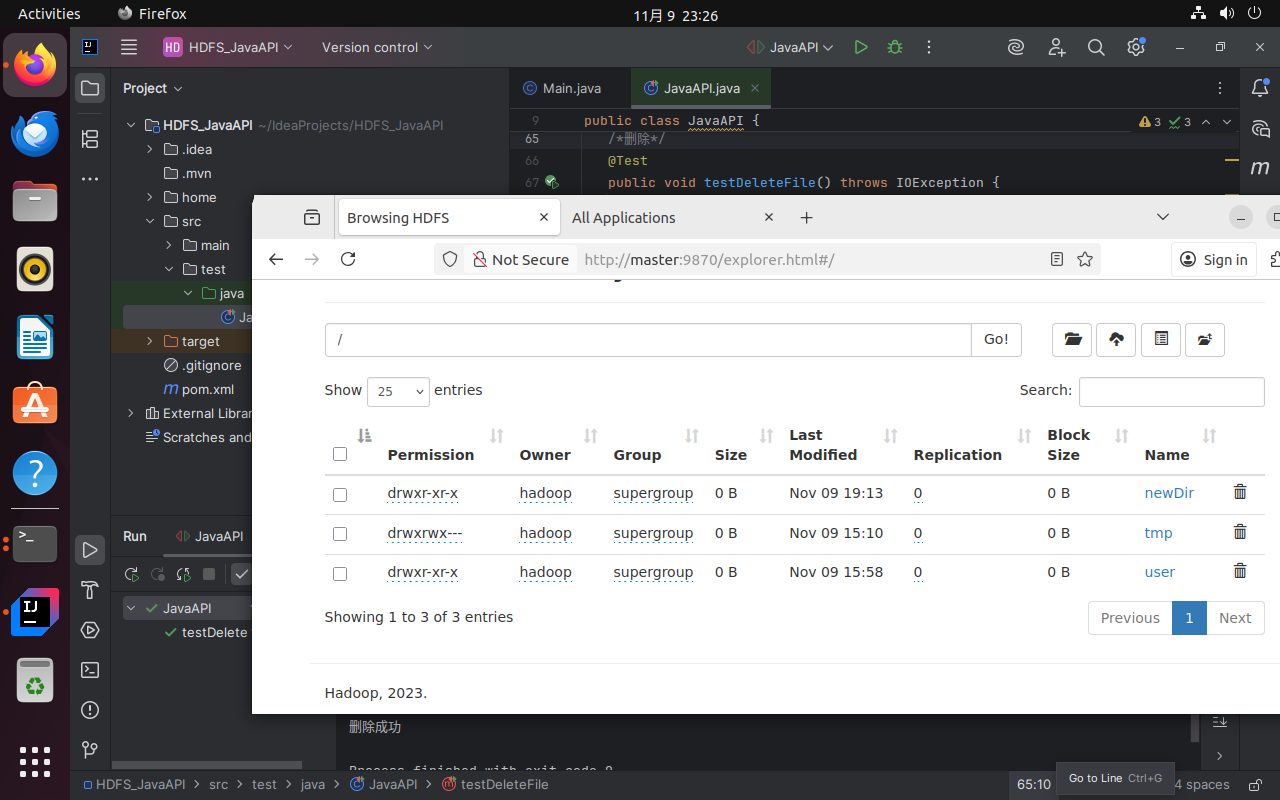
单独取消testDeleteFile的注释,运行程序。
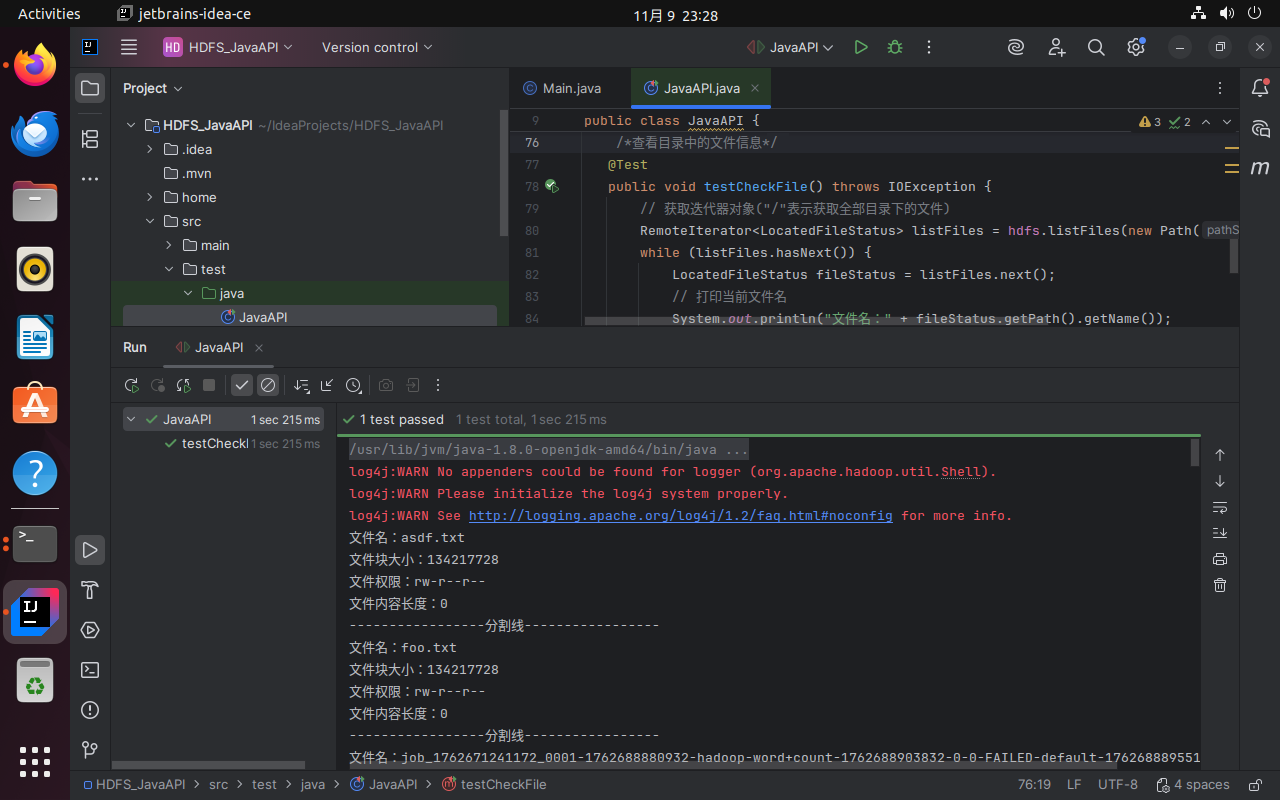
单独取消testCheckFile的注释,运行程序。
4. HBase安装配置实验
4.1 安装HBase
前往https://archive.apache.org/dist/hbase/2.5.4/或华为云镜像https://repo.huaweicloud.com/apache/hbase/2.5.4/下载hbase-2.5.4-bin.tar.gz,使用sudo tar -zxf ~/Downloads/hbase-2.5.4-bin.tar.gz -C /usr/local解压。
cd到/usr/local,为方便后续操作,使用sudo mv ./hbase-2.5.4 ./hbase将文件夹重命名。
使用sudo chown -R $USER ./hbase把hbase目录权限赋予给hadoop用户。
将hbase下的bin目录添加到path中,这样,启动hbase就无需到/usr/local/hbase目录下,大大的方便了hbase的使用。编辑~/.bashrc文件,添加export PATH=SPATH:/usr/local/hbase/bin,保存后source更新环境变量。也可使用下面的命令快速编辑。
echo "export PATH=$PATH:/usr/local/hbase/bin" >> ~/.bashrc
source ~/.bashrc
使用hbase version查看版本,看到输出版本消息表示HBase已经安装成功。
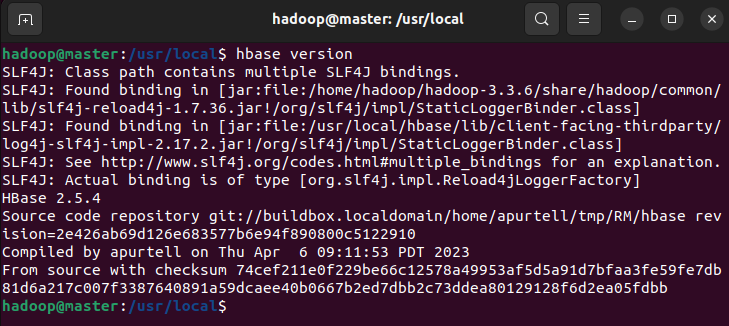
此处执行发现路径中有冲突的jar包,一个在hbase目录下,另一个在hadoop目录下。但是最后面还是有正常输出版本号的。此时先忽略此问题,下一步配置HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP后即可解决。
4.2 HBase配置
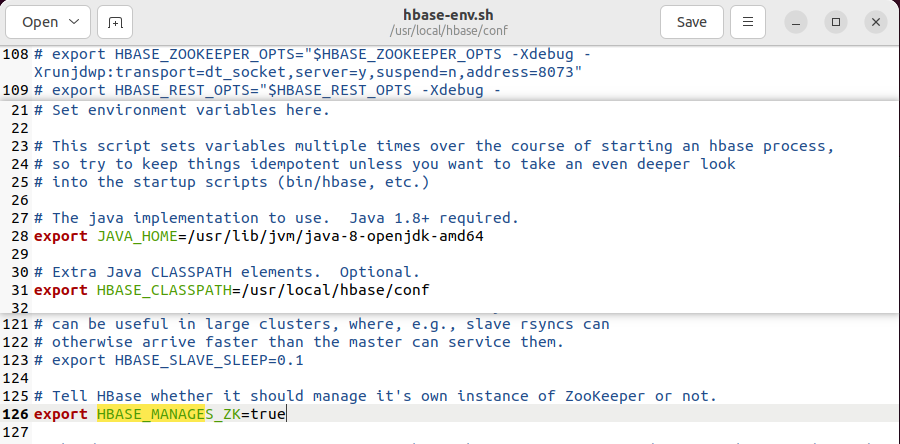
编辑/usr/local/hbase/conf/hbase-env.sh文件,配置JAVA_HOME,HBASE_CLASSPATH,HBASE_MANAGES_ZK,HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP。
HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP:不包含Hadoop的lib,默认为false,这会导致上一步的jar包冲突。
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HBASE_CLASSPATH=/usr/local/hbase/conf
export HBASE_MANAGES_ZK=true
export HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP=true
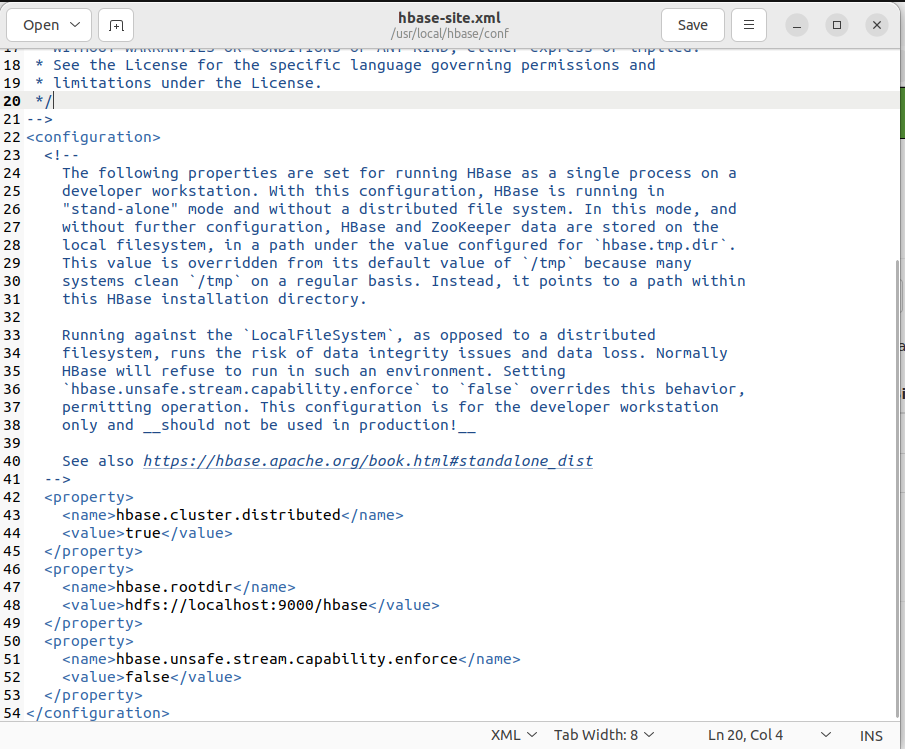
编辑/usr/local/hbase/conf/hbase-site.xml,修改hbase.rootdir,指定HBase数据在HDFS上的存储路径;将属性hbase.cluter.distributed设置为true。配置内容如下。
当前Hadoop集群运行在伪分布式模式下,在本机上运行,且NameNode运行在9000端口。
hbase.rootdir指定HBase的存储目录
hbase.cluster.distributed设置集群处于分布式模式。
<configuration>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
编辑regionservers,文件内容改为:
master
slave1
slave2
确保已启动Hadoop。输入命令jps,能看到NameNode,DataNode和SecondaryNameNode都已经成功启动,表示Hadoop启动成功。若未启动则在hadoop-3.3.6下使用./sbin/start-dfs.sh、./sbin/start-yarn.sh进行启动。
切换目录至/usr/local/hbase,再使用./bin/start-hbase.sh启动HBase。输入jps,伪分布式环境下应新增HMaster进程,集群Master节点新增HMaster,Slave节点新增HRegionServer。
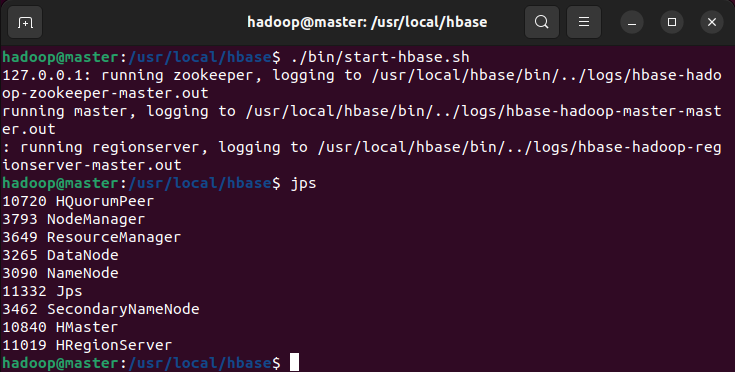
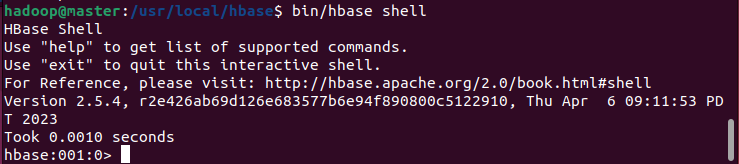
使用./bin/hbase shell 进入shell界面,成功进入即代表配置成功。
停止hbase,执行后会自动停止 HMaster、HRegionServer 及内置 ZooKeeper 服务,终端显示 “stopping hbase......” 表示停止中,停止完成后无额外提示。
需先停止 HBase,再停止 Hadoop(避免 HDFS 被占用导致无法正常停止),顺序为:./bin/stop-hbase.sh → cd ~/hadoop-3.3.6 → ./sbin/stop-yarn.sh → ./sbin/stop-dfs.sh。
4.3 HBase shell使用
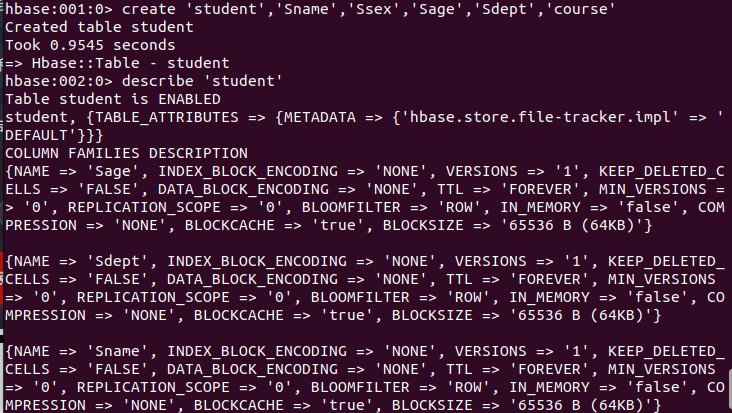
使用./bin/hbase shell 进入HBase shell界面,使用create 'student','Sname','Ssex','Sage','Sdept','course'创建表。此时,即创建了一个student表,属性有:Sname,Ssex,Sage,Sdept,course。因为HBase的表中会有一个系统默认的属性作为行键,无需自行创建,默认为put命令操作中表名后第一个数据。创建完student表后,可通过describe 'student'命令查看student表的基本信息。
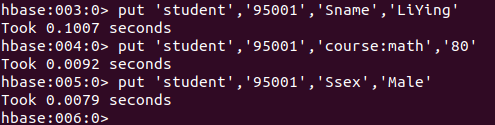
HBase中用put命令添加数据,注意:一次只能为一个表的一行数据的一个列,也就是一个单元格添加一个数据,所以直接用shell命令插入数据效率很低,在实际应用中,一般都是利用编程操作数据。
当运行命令:put 'student','95001','Sname','LiYing'时,即为student表添加了学号为95001,名字为LiYing的一行数据,其行键为95001。运行下面的命令为其添加数据:
put 'student','95001','Sname','LiYing'
# 为95001行下的course列族的math列添加了一个数据。
put 'student','95001','course:math','80'
# 为95001行下的Ssex列添加了一个数据。
put 'student','95001','Ssex','Male'
HBase中有两个用于查看数据的命令:
- get命令,用于查看表的某一行数据;
- scan命令用于查看某个表的全部数据。
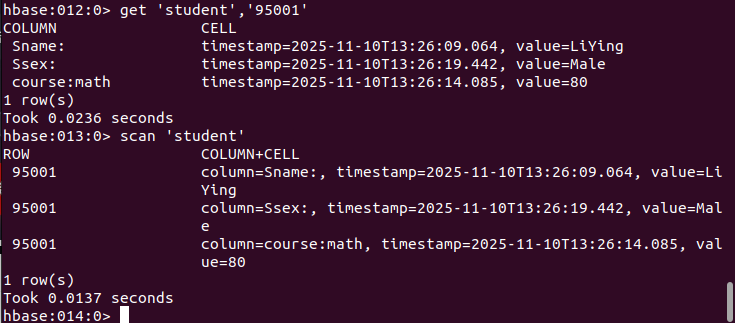
# 返回‘student’表‘95001’行的数据。
get 'student','95001'
# 返回‘student’表的全部数据
scan 'student'
在HBase中用delete以及deleteall命令进行删除数据操作,它们的区别是:
-
delete用于删除一个数据,是put的反向操作;
-
deleteall操作用于删除一行数据。
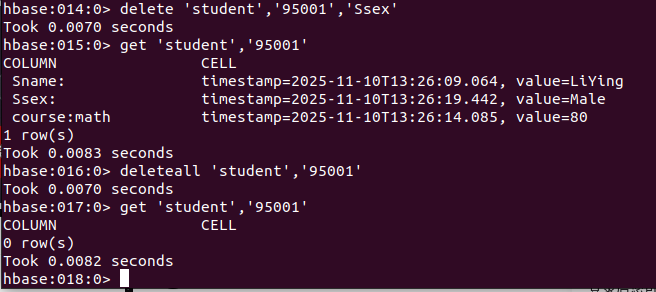
#删除student表中95001行下的Ssex列的所有数据
delete 'student','95001','Ssex'
#删除student表中的95001行的全部数据
deleteall 'student','95001'
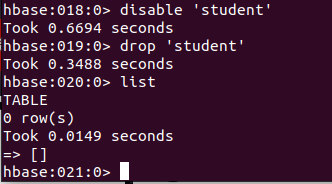
删除表有两步,第一步先让该表不可用,第二步删除表。
# 使表不可用
disable 'student'
# 删除表
drop 'student'
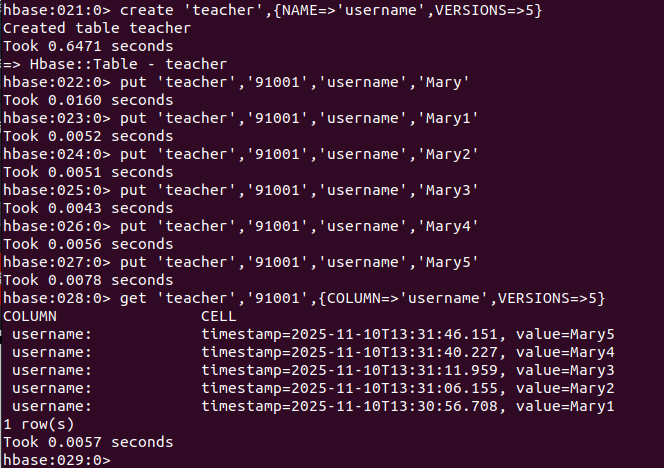
查询表历史数据。在创建表的时候,指定保存的版本数(假设指定为5)。
create 'teacher',{NAME=>'username',VERSIONS=>5}
# 插入数据然后更新数据,使其产生历史版本数据。
put 'teacher','91001','username','Mary'
put 'teacher','91001','username','Mary1'
put 'teacher','91001','username','Mary2'
put 'teacher','91001','username','Mary3'
put 'teacher','91001','username','Mary4'
put 'teacher','91001','username','Mary5'
# 查询时,默认会查询出最新的数据,但可指定查询的历史版本数。
get 'teacher','91001',{COLUMN=>'username',VERSIONS=>5}
最后退出数据库操作,输入exit命令即可退出,注意:这里退出HBase数据库是退出对数据库表的操作,而不是停止启动HBase数据库后台运行。
附录
词频统计程序代码
package wordCount;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class wordCount {
public wordCount() {
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if(otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(wordCount.class);
job.setMapperClass(wordCount.TokenizerMapper.class);
job.setCombinerClass(wordCount.IntSumReducer.class);
job.setReducerClass(wordCount.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true)?0:1);
}
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public TokenizerMapper() {
}
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
IntWritable val;
for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = (IntWritable)i$.next();
}
this.result.set(sum);
context.write(key, this.result);
}
}
}
HDFS Java API
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
public class JavaAPI {
// 可操作HDFS文件系统的对象
FileSystem hdfs = null;
// 测试方法执行前执行,用于初始化操作,避免频繁初始化
@Before
public void init() throws IOException {
// 构造一个配置参数对象,设置一个参数:要访问的HDFS的URI
Configuration conf = new Configuration();
// 指定使用HDFS访问
conf.set("fs.defaultFS","hdfs://master:9000");
// 进行客户端身份的设置(hadoop为虚拟机的用户名,hadoop集群节点的其中一个都可以)
System.setProperty("HADOOP_USER_NAME","hadoop");
// 通过FileSystem的静态get()方法获取HDFS文件系统客户端对象
hdfs = FileSystem.get(conf);
}
/* 上传文件
@Test
public void testUploadFileToHDFS() throws IOException {
// 待上传的文件路径
Path src = new Path("/home/hadoop/Documents/localfile/text.txt");
// 上传之后存放的路径(HDFS)
Path dst = new Path("/text.txt");
// 上传
hdfs.copyFromLocalFile(src,dst);
System.out.println("上传成功");
}
*/
/* 下载
@Test
public void testDownFileToLocal() throws IOException {
// 待下载的路径(HDFS)
Path src = new Path("/text.txt");
// 下载成功之后存放的路径
Path dst = new Path("/home/hadoop/Documents/localfile/text1.txt");
// 下载
hdfs.copyToLocalFile(false,src,dst,true);
System.out.println("下载成功");
}
*/
/* 重命名
@Test
public void testRenameFile() throws IOException {
// 重命名之前的名字
Path src = new Path("/text.txt");
// 重命名之后的名字
Path dst = new Path("/text1.txt");
// 重命名
hdfs.rename(src,dst);
System.out.println("重命名成功");
}
*/
/*删除
@Test
public void testDeleteFile() throws IOException {
// 待删除路径
Path src = new Path("/text1.txt");
// 删除
hdfs.delete(src,true);
System.out.println("删除成功");
}
*/
/*查看目录中的文件信息
@Test
public void testCheckFile() throws IOException {
// 获取迭代器对象("/"表示获取全部目录下的文件)
RemoteIterator<LocatedFileStatus> listFiles = hdfs.listFiles(new Path("/"), true);
while (listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
// 打印当前文件名
System.out.println("文件名:" + fileStatus.getPath().getName());
// 打印当前文件块大小
System.out.println("文件块大小:" + fileStatus.getBlockSize());
// 打印当前文件权限
System.out.println("文件权限:" + fileStatus.getPermission());
// 打印当前文件内容的长度
System.out.println("文件内容长度:" + fileStatus.getLen());
// 获取该文件块的信息(包含长度,数据块,DataNodes的信息)
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
for (BlockLocation bl : blockLocations) {
System.out.println("block-length:" + bl.getLength());
System.out.println("block-offset:" + bl.getOffset());
// 获取DataNodes的主机名
String[] hosts = bl.getHosts();
for (String host : hosts) {
System.out.println(host);
}
}
System.out.println("-----------------分割线-----------------");
}
}
*/
// 测试方法执行后执行,用于处理结尾的操作,关闭对象
@After
public void close() throws IOException {
// 关闭文件操作对象
hdfs.close();
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号