第一次作业:深入Linux源码分析进程模型
一.操作系统是怎么组织进程的
1.什么是进程
进程是处于执行期的程序以及它所包含的所有资源的总称,包括虚拟处理器,虚拟空间,寄存器,堆栈,全局数据段等。
在Linux中,每个进程在创建时都会被分配一个数据结构,称为进程控制块(Process Control Block,简称PCB)。PCB中包含了很多重要的信息,供系统调度和进程本身执行使用。所有进程的PCB都存放在内核空间中。PCB中最重要的信息就是进程PID,内核通过这个PID来唯一标识一个进程。PID可以循环使用,最大值是32768。init进程的pid为1,其他进程都是init进程的后代。
除了进程控制块(PCB)以外,每个进程都有独立的内核堆栈(8k),一个进程描述符结构,这些数据都作为进程的控制信息储存在内核空间中;而进程的用户空间主要存储代码和数据。
2.进程的创建
进程是通过调用::fork(),::vfork()和::clone()系统调用创建新进程。在内核中,它们都是调用do_fork实现的。传统的fork函数直接把父进程的所有资源复制给子进程。而Linux的::fork()使用写时拷贝页实现,也就是说,父进程和子进程共享同一个资源拷贝,只有当数据发生改变时,数据才会发生复制。通常的情况,子进程创建后会立即调用exec(),这样就避免复制父进程的全部资源。
三者的区别如下:
::fork():父进程的所有数据结构都会复制一份给子进程(写时拷贝页)。
::vfork():只复制task_struct和内核堆栈,所以生成的只是父进程的一个线程(无独立的用户空间)。
::clone():功能强大,带了许多参数。::clone()可以让你有选择性的继承父进程的资源,既可以选择像::vfork()一样和父进程共享一个虚拟空间,从而使创造的是线程,你也可以不和父进程共享,你甚至可以选择创造出来的进程和父进程不再是父子关系,而是兄弟关系。
3. 进程的撤销
进程通过调用exit()退出执行,这个函数会终结进程并释放所有的资源。父进程可以通过wait4()查询子进程是否终结。进程退出执行后处于僵死状态,直到它的父进程调用wait()或者waitpid()为止。父进程退出时,内核会指定线程组的其他进程或者init进程作为其子进程的新父进程。当进程接收到一个不能处理或忽视的信号时,或当在内核态产生一个不可恢复的CPU异常而内核此时正代表该进程在运行,内核可以强迫进程终止。
4. 进程管理
内核把进程信息存放在叫做任务队列(task list)的双向循环链表中(内核空间)。链表中的每一项都是类型为task_struct,称为进程描述符结构(process descriptor),包含了一个具体进程的所有信息,包括打开的文件,进程的地址空间,挂起的信号,进程的状态等。
Linux通过slab分配器分配task_struct,这样能达到对象复用和缓存着色(通过预先分配和重复使用task_struct,可以避免动态分配和释放所带来的资源消耗)。
内核把所有处于TASK_RUNNING状态的进程组织成一个可运行双向循环队列。调度函数通过扫描整个可运行队列,取得最值得执行的进程投入执行。避免扫描所有进程,提高调度效率。
5. 进程的内核堆栈
Linux为每个进程分配一个8KB大小的内存区域,用于存放该进程两个不同的数据结构:thread_info和进程的内核堆栈。
进程处于内核态时使用不同于用户态堆栈,内核控制路径所用的堆栈很少,因此对栈和描述符来说,8KB足够了。
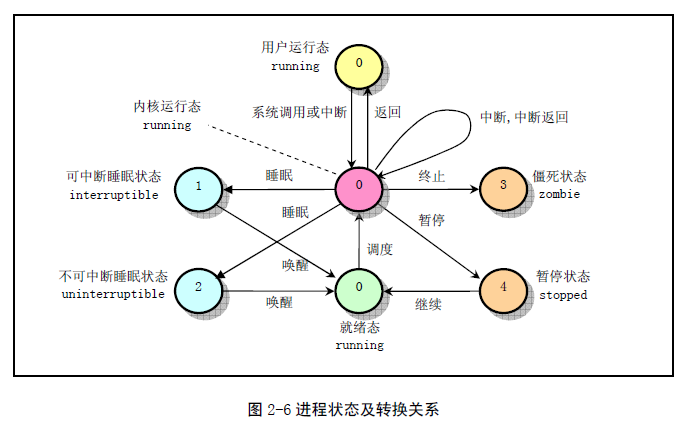
二.进程状态如何转换(给出进程状态转换图)
1、进程状态
R(TASK_RUNNING),可执行状态。
只有在该状态的进程才可能在CPU上运行,同一时刻可能有多个进程处于可执行状态。
- S(TASK_INTERRUPTIBLE),可中断的睡眠状态。
处于这个状态的进程因为等待某事件的发生(比如等待socket连接、等待信号量),而被挂起。当这些事件发生时,对应的等待队列中的一个或多个进程将被唤醒。一般情况下,进程列表中的绝大多数进程都处于TASK_INTERRUPTIBLE状态。
- D(TASK_UNINTERRUPTIBLE),不可中断的睡眠状态。
与TASK_INTERRUPTIBLE状态类似,进程处于睡眠状态,但是此刻进程是不可中断的。不可中断,指的是进程不响应异步信号,无法用kill命令关闭处于TASK_UNINTERRUPTIBLE状态的进程。
- T(TASK_STOPPED or TASK_TRACED),暂停状态或跟踪状态。
向进程发送一个SIGSTOP信号,它就会因响应该信号而进入TASK_STOPPED状态(除非该进程本身处于TASK_UNINTERRUPTIBLE状态而不响应信号)。当进程正在被跟踪时,它处于TASK_TRACED状态。
- Z(TASK_DEAD - EXIT_ZOMBIE),退出状态。
进程在退出的过程中,处于TASK_DEAD状态,如果它的父进程没有收到SIGCHLD信号,故未调用wait(如wait4、waitid)处理函数等待子进程结束,又没有显式忽略该信号,它就一直保持EXIT_ZOMBIE状态。只要父进程不退出,这个EXIT_ZOMBIE状态的子进程就一直存在。
- X(TASK_DEAD - EXIT_DEAD),退出状态,进程即将被销毁。
EXIT_DEAD状态是非常短暂的,几乎不可能通过ps命令捕捉到。
2、进程状态转换
盗一张图来说明一下进程状态转换的过程:
三.进程是如何调度的
Linux的调度程序-Schedule( )
1.基本原理
调度的实质就是资源的分配。系统通过不同的调度算法(Scheduling Algorithm)来实现这种资源的分配。通常来说,选择什么样的调度算法取决于的资源分配的策略(Scheduling Policy),在这里只说明与Linux调度相关的几种算法及这些算法的原理。
一个好的调度算法应当考虑以下几个方面:
(1)公平:保证每个进程得到合理的CPU时间。
(2)高效:使CPU保持忙碌状态,即总是有进程在CPU上运行。
(3)响应时间:使交互用户的响应时间尽可能短。
(4)周转时间:使批处理用户等待输出的时间尽可能短。
(5)吞吐量:使单位时间内处理的进程数量尽可能多。
很显然,这5个目标不可能同时达到,所以,不同的操作系统会在这几个方面中作出相应的取舍,从而确定自己的调度算法,例如UNIX采用动态优先数调度、BSD采用多级反馈队列调度、Windows采用抢先多任务调度等等。
下面来了解一下主要的调度算法及其基本原理:
1.时间片轮转调度算法
时间片(Time Slice)就是分配给进程运行的一段时间。在通常的轮转法中,系统将所有的可运行(即就绪)进程按先来先服务的原则,排成一个队列,每次调度时把CPU分配给队首进程,并令其执行一个时间片。当执行的时间片用完时,系统发出信号,通知调度程序,调度程序便据此信号来停止该进程的执行,并将它送到运行队列的末尾,等待下一次执行;然后,把处理机分配给就绪队列中新的队首进程,同时也让它执行一个时间片。这样就可以保证运行队列中的所有进程,在一个给定的时间内,均能获得一时间片的处理机执行时间。
2.优先权调度算法
为了照顾到紧迫型进程在进入系统后便能获得优先处理,引入了最高优先权调度算法。当将该算法用于进程调度时,系统将把处理机分配给运行队列中优先权最高的进程,这时,又可进一步把该算法分成两种方式:
(1) 非抢占式优先权算法(又称不可剥夺调度:Nonpreemptive Scheduling)
在这种方式下,系统一旦将处理机(CPU)分配给运行队列中优先权最高的进程后,该进程便一直执行下去,直至完成;或因发生某事件使该进程放弃处理机时,系统方可将处理机分配给另一个优先权高的进程。这种调度算法主要用于批处理系统中,也可用于某些对实时性要求不严的实时系统中。
(2) 抢占式优先权调度算法(又称可剥夺调度:Preemptive Scheduling)
该算法的本质就是系统中当前运行的进程永远是可运行进程中优先权最高的那个。在采用这种调度算法时,每当出现一新的可运行进程,就将它和当前运行进程进行优先权比较,如果高于当前进程,将触发进程调度。这种方式的优先权调度算法,能更好的满足紧迫进程的要求,故而常用于要求比较严格的实时系统中,以及对性能要求较高的批处理和分时系统中。Linux也采用这种调度算法
3.多级反馈队列调度
这是时下最时髦的一种调度算法。其本质是:综合了时间片轮转调度和抢占式优先权调度的优点,即:优先权高的进程先运行给定的时间片,相同优先权的进程轮流运行给定的时间片。
4.实时调度
最后我们来看一下实时系统中的调度。什么叫实时系统,就是系统对外部事件有求必应、尽快响应。在实时系统中,广泛采用抢占调度方式,特别是对于那些要求严格的实时系统。因为这种调度方式既具有较大的灵活性,又能获得很小的调度延迟;但是这种调度方式也比较复杂。
2. Linux进程调度时机
Linux的调度程序是一个叫Schedule()的函数,这个函数被调用的频率很高,由它来决定是否要进行进程的切换,如果要切换的话,切换到哪个进程等等。我们先来看在什么情况下要执行调度程序,我们把这种情况叫做调度时机。
Linux调度时机主要有:
1、进程状态转换的时刻:进程终止、进程睡眠;
2、当前进程的时间片用完时(current->counter=0);
3、设备驱动程序主动调用schedule;
4、进程从中断、异常及系统调用返回到用户态时;
时机1,进程要调用sleep()或exit()等函数进行状态转换,这些函数会主动调用调度程序进行进程调度;
时机2,由于进程的时间片是由时钟中断来更新的,因此,这种情况和时机4是一样的。
时机3,当设备驱动程序执行长而重复的任务时,直接调用调度程序。在每次反复循环中,驱动程序都检查need_resched的值,如果必要,则调用调度程序schedule()主动放弃CPU。
时机4,如前所述,不管是从中断、异常还是系统调用返回,最终都调用ret_from_sys_call(),由这个函数进行调度标志的检测,如果必要,则调用调度程序。那么,为什么从系统调用返回时要调用调度程序呢?这当然是从效率考虑。从系统调用返回意味着要离开内核态而返回到用户态,而状态的转换要花费一定的时间,因此,在返回到用户态前,系统把在内核态该处理的事全部做完。
每个时钟中断(timer interrupt)发生时,由三个函数协同工作,共同完成进程的选择和切换,它们是:schedule()、do_timer()及ret_form_sys_call()。我们先来解释一下这三个函数:
schedule():进程调度函数,由它来完成进程的选择(调度);
do_timer():暂且称之为时钟函数,该函数在时钟中断服务程序中被调用,被调用的频率就是时钟中断的频率即每秒钟100次(简称100赫兹或100Hz);
ret_from_sys_call():系统调用返回函数。当一个系统调用或中断完成时,该函数被调用,用于处理一些收尾工作,例如信号处理、核心任务等等。
这三个函数是如何协调工作的呢?
前面我们看到,时钟中断是一个中断服务程序,它的主要组成部分就是时钟函数do_timer(),由这个函数完成系统时间的更新、进程时间片的更新等工作,更新后的进程时间片counter作为调度的主要依据。在时钟中断返回时,要调用函数ret_from_sys_call(),前面我们已经讨论过这个函数,在这个函数中有如下几行:
cmpl $0, _need_resched
jne reschedule
……
restore_all:
RESTORE_ALL
reschedule:
call SYMBOL_NAME(schedule)
jmp ret_from_sys_call
这几行的意思很明显:检测 need_resched 标志,如果此标志为非0,那么就转到reschedule处调用调度程序schedule()进行进程的选择。调度程序schedule()会根据具体的标准在运行队列中选择下一个应该运行的进程。当从调度程序返回时,如果发现又有调度标志被设置,则又调用调度程序,直到调度标志为0,这时,从调度程序返回时由RESTORE_ALL恢复被选定进程的环境,返回到被选定进程的用户空间,使之得到运行。
Linux 调度程序和其他的UNIX调度程序不同,尤其是在“nice level”优先级的处理上,与优先权调度(priority高的进程最先运行)不同,Linux用的是时间片轮转调度(Round Robing),但同时又保证了高优先级的进程运行的既快、时间又长(both sooner and longer)。而标准的UNIX调度程序都用到了多级进程队列。大多数的实现都用到了二级优先队列:一个标准队列和一个实时(“real time”)队列。一般情况下,如果实时队列中的进程未被阻塞,它们都要在标准队列中的进程之前被执行,并且,每个队列中,“nice level”高的进程先被执行。
3.进程调度的依据
调度程序运行时,要在所有处于可运行状态的进程之中选择最值得运行的进程投入运行。选择进程的依据是什么呢?在每个进程的task_struct结构中有这么五项:
need_resched、nice、counter、policy 及rt_priority
need_resched: 在调度时机到来时,检测这个域的值,如果为1,则调用schedule() 。
counter: 进程处于运行状态时所剩余的时钟滴答数,每次时钟中断到来时,这个值就减1。当这个域的值变得越来越小,直至为0时,就把need_resched 域置1,因此,也把这个域叫做进程的“动态优先级”。
nice: 进程的“静态优先级”,这个域决定counter 的初值。只有通过nice(), sched_setparam()系统调用才能改变进程的静态优先级。
rt_priority: 实时进程的优先级
policy: 从整体上区分实时进程和普通进程,因为实时进程和普通进程的调度是不同的,它们两者之间,实时进程应该先于普通进程而运行,可以通过系统调用sched_setscheduler( )来改变调度的策略。对于同一类型的不同进程,采用不同的标准来选择进程。对于普通进程,选择进程的主要依据为counter和nice 。对于实时进程,Linux采用了两种调度策略,即FIFO(先来先服务调度)和RR(时间片轮转调度)。因为实时进程具有一定程度的紧迫性,所以衡量一个实时进程是否应该运行,Linux采用了一个比较固定的标准。实时进程的counter只是用来表示该进程的剩余滴答数,并不作为衡量它是否值得运行的标准,这和普通进程是有区别的
4.进程可运行程度的衡量
函数goodness()就是用来衡量一个处于可运行状态的进程值得运行的程度。该函数综合使用了上面我们提到的五项,给每个处于可运行状态的进程赋予一个权值(weight),调度程序以这个权值作为选择进程的唯一依据。函数主体如下:
static inline int goodness(struct task_struct * p, int this_cpu, struct mm_struct *this_mm)
{ int weight; /* 权值,作为衡量进程是否运行的唯一依据 *
weight=-1;
if (p->policy&SCHED_YIELD)
goto out; /*如果该进程愿意“礼让(yield)”,则让其权值为-1 */
switch(p->policy)
{
/* 实时进程*/
case SCHED_FIFO:
case SCHED_RR:
weight = 1000 + p->rt_priority;
/* 普通进程 */
case SCHED_OTHER:
{ weight = p->counter;
if(!weight)
goto out
/* 做细微的调整*/
if (p->mm=this_mm||!p->mm)
weight = weight+1;
weight+=20-p->nice; /*在剩余counter一样的情况下,短进程优先*/
}
}
out:
return weight; /*返回权值*/
}
其中,在sched.h中对调度策略定义如下:
#define SCHED_OTHER 0
#define SCHED_FIFO 1
#define SCHED_RR 2
#define SCHED_YIELD 0x10
这个函数比较很简单。首先,根据policy区分实时进程和普通进程。实时进程的权值取决于其实时优先级,其至少是1000,与conter和nice无关。普通进程的权值需特别说明两点:
为什么进行细微的调整?如果p->mm为空,则意味着该进程无用户空间(例如内核线程),则无需切换到用户空间。如果p->mm=this_mm,则说明该进程的用户空间就是当前进程的用户空间,该进程完全有可能再次得到运行。对于以上两种情况,都给其权值加1,算是对它们小小的奖励。
进程的优先级nice是从早期Unix沿用下来的负向优先级,其数值标志“谦让”的程度,其值越大,就表示其越“谦让”,也就是优先级越低,其取值范围为-20~+19,因此,(20-p->nice)的取值范围就是0~40。可以看出,普通进程的权值不仅考虑了其剩余的时间片,还考虑了其优先级,优先级越高,其权值越大。
根据进程调度的依据,调度程序就可以控制系统中的所有处于可运行状态的进程并在它们之间进行选择。
5.进程调度的实现
调度程序在内核中就是一个函数,为了讨论方便,我们同样对其进行了简化,略其对SMP的实现部分。
asmlinkage void schedule(void)
{
struct task_struct *prev, *next, *p; /* prev表示调度之前的进程, next表示调度之后的进程 */
struct list_head *tmp;
int this_cpu, c;
if (!current->active_mm) BUG();/*如果当前进程的的active_mm为空,出错*/
need_resched_back:
prev = current; /*让prev成为当前进程 */
this_cpu = prev->processor;
if (in_interrupt()) {/*如果schedule是在中断服务程序内部执行,
就说明发生了错误*/
printk("Scheduling in interrupt/n");
BUG();
}
release_kernel_lock(prev, this_cpu); /*释放全局内核锁,并开this_cpu的中断*/
spin_lock_irq(&runqueue_lock); /*锁住运行队列,并且同时关中断*/
if (prev->policy == SCHED_RR) /*将一个时间片用完的SCHED_RR实时
goto move_rr_last; 进程放到队列的末尾 */
move_rr_back:
switch (prev->state) { /*根据prev的状态做相应的处理*/
case TASK_INTERRUPTIBLE: /*此状态表明该进程可以被信号中断*/
if (signal_pending(prev)) { /*如果该进程有未处理的信号,则让其变为可运行状态*/
prev->state = TASK_RUNNING;
break;
}
default: /*如果为不可中断的等待状态或僵死状态*/
del_from_runqueue(prev); /*从运行队列中删除*/
case TASK_RUNNING:;/*如果为可运行状态,继续处理*/
}
prev->need_resched = 0;
/*下面是调度程序的正文 */
repeat_schedule: /*真正开始选择值得运行的进程*/
next = idle_task(this_cpu); /*缺省选择空闲进程*/
c = -1000;
if (prev->state == TASK_RUNNING)
goto still_running;
still_running_back:
list_for_each(tmp, &runqueue_head) { /*遍历运行队列*/
p = list_entry(tmp, struct task_struct, run_list);
if (can_schedule(p, this_cpu)) { /*单CPU中,该函数总返回1*/ int weight = goodness(p, this_cpu, prev->active_mm);
if (weight > c)
c = weight, next = p;
}
}
/* 如果c为0,说明运行队列中所有进程的权值都为0,也就是分配给各个进程的
时间片都已用完,需重新计算各个进程的时间片 */
if (!c) {
struct task_struct *p;
spin_unlock_irq(&runqueue_lock);/*锁住运行队列*/
read_lock(&tasklist_lock); /* 锁住进程的双向链表*/
for_each_task(p) /* 对系统中的每个进程*/
p->counter = (p->counter >> 1) + NICE_TO_TICKS(p->nice);
read_unlock(&tasklist_lock);
spin_lock_irq(&runqueue_lock);
goto repeat_schedule;
}
spin_unlock_irq(&runqueue_lock);/*对运行队列解锁,并开中断*/
if (prev == next) { /*如果选中的进程就是原来的进程*/
prev->policy &= ~SCHED_YIELD;
goto same_process;
}
/* 下面开始进行进程切换*/
kstat.context_swtch++; /*统计上下文切换的次数*/
{
struct mm_struct *mm = next->mm;
struct mm_struct *oldmm = prev->active_mm;
if (!mm) { /*如果是内核线程,则借用prev的地址空间*/
if (next->active_mm) BUG();
next->active_mm = oldmm;
} else { /*如果是一般进程,则切换到next的用户空间*/
if (next->active_mm != mm) BUG();
switch_mm(oldmm, mm, next, this_cpu);
}
if (!prev->mm) { /*如果切换出去的是内核线程*/
prev->active_mm = NULL;/*归还它所借用的地址空间*/
mmdrop(oldmm); /*mm_struct中的共享计数减1*/
}
}
switch_to(prev, next, prev); /*进程的真正切换,即堆栈的切换*/
__schedule_tail(prev); /*置prev->policy的SCHED_YIELD为0 */
same_process:
reacquire_kernel_lock(current);/*针对SMP*/
if (current->need_resched) /*如果调度标志被置位*/
goto need_resched_back; /*重新开始调度*/
return;
}
以上就是调度程序的主要内容。
四.谈谈自己对该操作系统进程模型的看法
进程实现是分时系统的核心部分之一,且与操作系统多方面的内容联系。Linux是十分成功的操作系统,许多方面的设计都十分新颖,而且在实现上也相当畜于技巧,其设计思路和方法都是值得借鉴的。
五.参考资料
http://www.jb51.net/LINUXjishu/66846.html
https://blog.csdn.net/sailor_8318/article/details/2452983

 浙公网安备 33010602011771号
浙公网安备 33010602011771号