AI 聊天应用的 10 条高级需求
最新动态
GitHub 开源: https://github.com/experdot/pointer [MIT]
前言
过去一段时间,我较为深入地使用了多款 Web 端和桌面端的大语言模型聊天工具。在日常使用中,我逐渐意识到,这些工具在基础的问答能力上已经做得不错,但在围绕对话本身的管理、组织和流转方面,仍然存在明显的不足。
这些不足在偶尔使用时并不显眼,但当 AI 对话成为日常工作流的一部分——用于编程辅助、方案讨论、资料整理——它们便成为实实在在的效率瓶颈。
以下是我在使用过程中总结的十条改进建议。它们并非凭空设想,而是源于反复遇到的具体问题。我尝试将它们按内在逻辑分为三个层次来阐述:信息的找回与组织、内容的编辑与输出、系统的灵活性与开放性。不同产品的完成度各有差异,这里仅就普遍存在的共性问题进行讨论。
第一部分:信息的找回与组织
对话一旦积累到一定数量,如何高效地找到过去的内容、如何保持历史记录的有序,就成为最先暴露的问题。
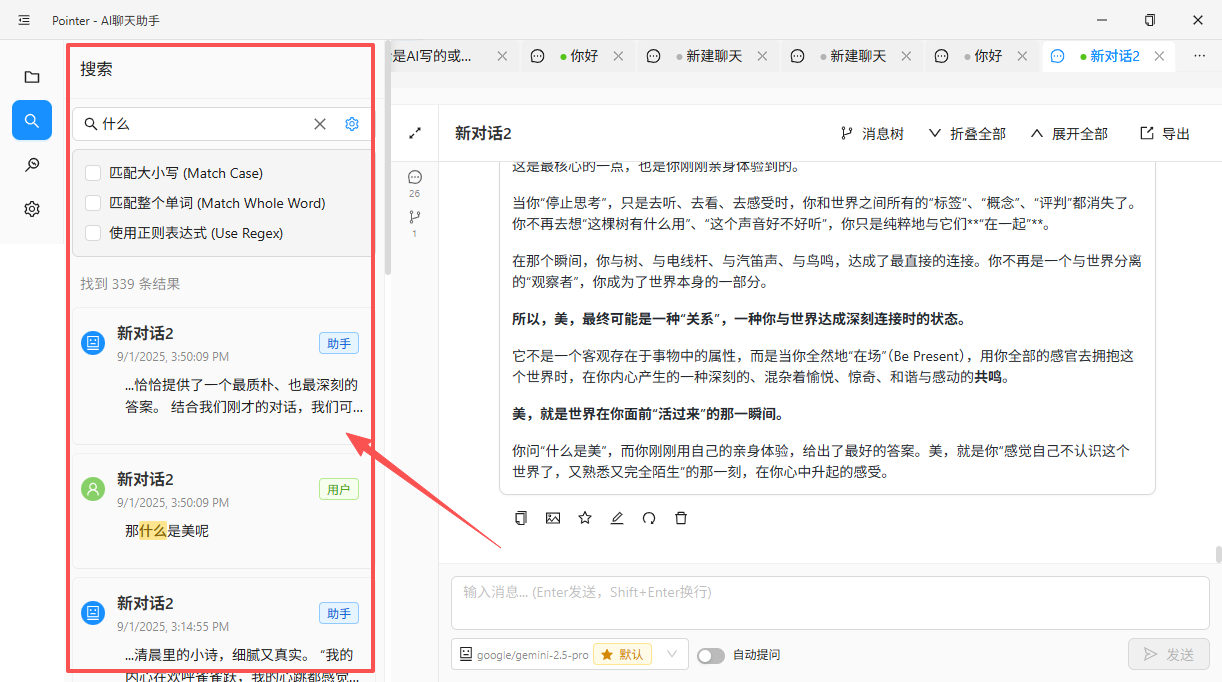
1. 全局检索
上次那个绝妙的点子,现在只记得它很绝妙了。
工作中经常出现这样的场景:几天前曾就某个技术问题与 AI 进行过讨论,当时得到了一个很实用的方案。现在需要再次引用,却怎么也找不到了。面对一长串按时间排列的对话列表,只能凭借模糊的记忆逐条翻阅,往往无功而返,最后不得不重新提问。
这实质上是一个信息检索问题。多数聊天工具目前要么完全不提供搜索功能,要么仅支持对话标题的简单匹配,无法深入到对话内容本身。
一个实用的全局检索功能,至少应当满足以下几点:
- 内容级的关键词搜索。 检索范围不应局限于对话标题,而应覆盖对话中的每一条消息。用户输入"正则表达式",就应当能找到所有提及该关键词的对话片段。
- 时间范围筛选。 支持按"最近一周"、"某个月份"等条件缩小范围,在对话量较大时尤为重要。
- 结果需关联上下文。 搜索结果不应只是孤立的文本片段。点击后,应当能够跳转到该消息在对话中的原始位置,并加载其前后的上下文,帮助用户回忆当时的讨论背景,判断这条结果是否是自己需要的。
- 与分类体系联动。 如果产品支持对话分类(见下文第 2 条),检索也应支持限定在某个分类或文件夹下进行,以提高结果的精确度。
简单来说,用户需要的是一个面向对话历史的搜索引擎。
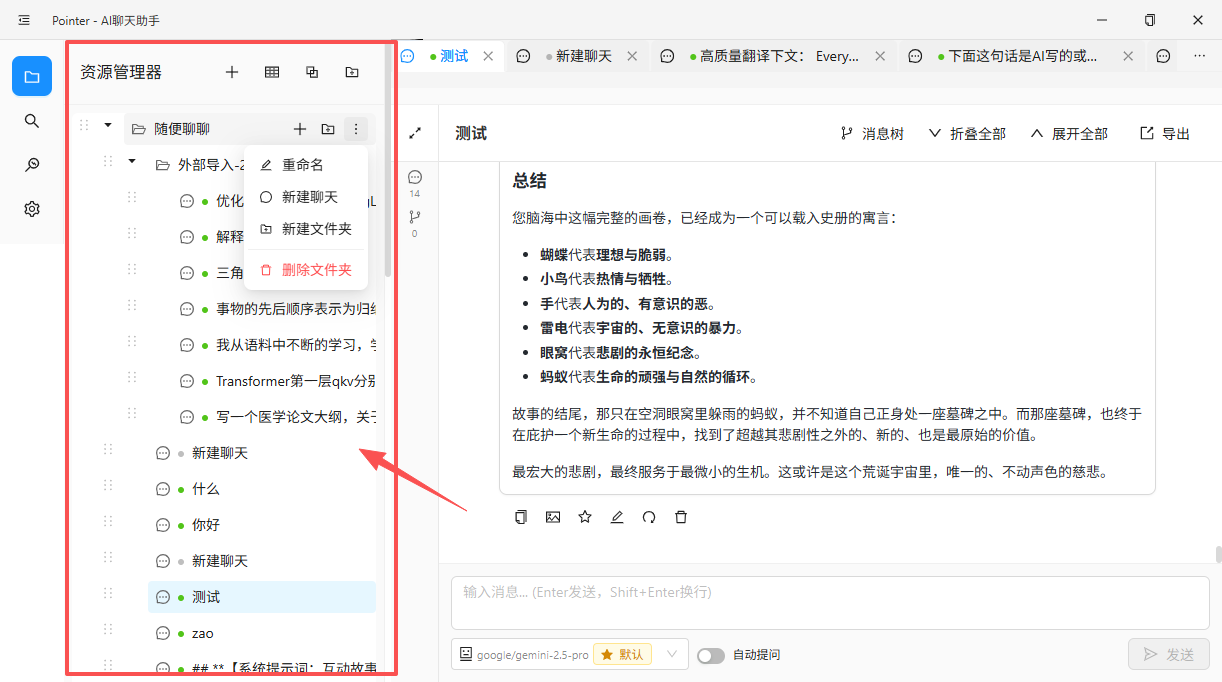
2. 对话分类
当你置顶了所有对话,也就没有任何对话被置顶。
目前主流的设计方案,是将所有对话按时间倒序排列为一个线性列表,辅以置顶功能。这种设计对轻度用户而言尚可接受,但对于每天进行大量对话的用户来说,这个列表会迅速膨胀为一团难以梳理的信息。置顶功能在对话数量有限时有效,但当"重要的对话"本身就有几十条时,置顶也就失去了意义。
用户需要一套由自己主导的分类系统,就像文件管理器中的目录结构一样:
- 文件夹与嵌套。 允许用户创建自定义文件夹,如"工作"、"学习"、"日常",并在其下建立子文件夹,如"项目 A"、"周报素材"。对话可以被移入对应的文件夹中。
- 拖拽与手动排序。 对话和文件夹都应支持拖拽操作,用户可以按自己的优先级自由排列,而非被迫接受时间排序。
- 批量管理。 一个常见的使用习惯是:将临时性的、即用即弃的问答集中放入一个"临时"文件夹,定期清理。然而,目前多数工具的删除操作要么是逐条进行,要么是全量清空,缺乏按文件夹批量管理的能力。能够"清空指定文件夹"而不影响其他内容,是一个基本但重要的需求。
这套机制的目标,是将无序的对话流转变为一棵条理清晰的知识树,让用户能够按照自己的认知结构来组织信息。
3. 对话折叠
鼠标滚轮的使用率首次超越了左键。
AI 有时会生成大段的代码、详尽的分析报告或冗长的列表。这些内容在首次阅读时是有价值的,但在后续回顾对话上下文时,它们会占据大量屏幕空间,迫使用户反复滚动才能找到前后的讨论要点,严重影响阅读的连续性。
一个简单的折叠机制可以有效缓解这一问题:
- 自动折叠。 当某条回复超过一定长度(例如 20 行),默认只显示开头若干行,末尾附上"展开全文"的入口。
- 手动折叠。 每条消息旁提供折叠/展开的控件,允许用户自行决定哪些内容需要收起。同时提供全局的"全部展开"或"全部折叠"操作,方便快速调整视图。
这个功能本身并不复杂,但它能显著改善长对话的可读性,让用户更好地聚焦于当前关心的内容。

第二部分:内容的编辑与输出
找到信息之后,下一步是对其进行处理——修正错误、提取关键内容、分享给他人。这一环节同样存在不少可以改进的地方。
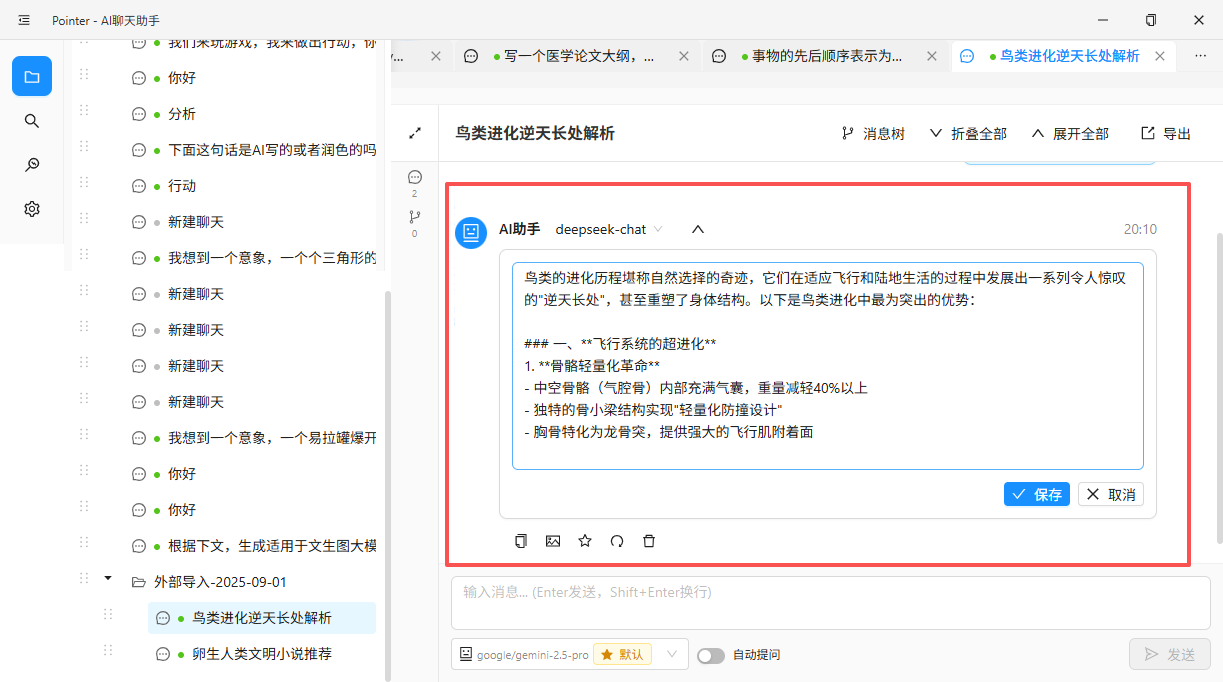
4. 编辑 AI 回复
这话我没说过。
大语言模型的"幻觉"问题目前仍无法完全避免。在实际使用中,AI 偶尔会给出事实性错误的回答——例如一个不存在的 API 参数,或一段逻辑有误的代码。如果这个错误出现在对话的早期,而用户没有及时察觉,后续的讨论就会在这个错误的基础上继续展开,导致问题逐步放大。
目前,多数工具只允许用户编辑自己的提问,而无法修改 AI 的回复。面对这种情况,用户通常只有两个选择:要么在后续消息中反复纠正,要么放弃当前对话、从头开始。两种方式都意味着已有上下文的浪费。
如果用户能够直接编辑 AI 的某条回复——例如,双击进入编辑模式,将错误的参数名改为正确的——那么后续对话就可以基于修正后的内容继续进行。对话的连贯性得以保留,用户也无需被动地迁就模型的错误。
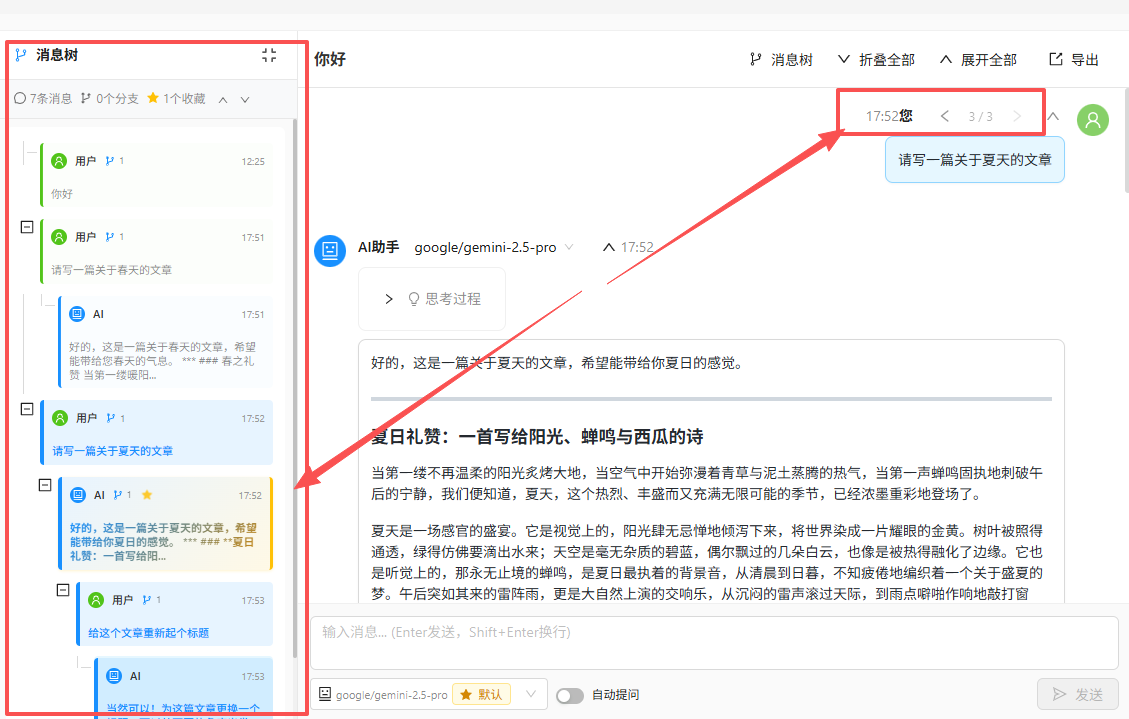
5. 树形聊天与分支书签
聊天树。
当"编辑"功能被引入后,对话的结构就不再是线性的。用户在某个节点修改了提问,产生了新的回复分支;原始的对话路径仍然保留。随着多次编辑和探索,对话自然演变为一棵树形结构。部分工具已经实现了这一点,值得肯定。
然而,树形结构引入了新的管理问题。当用户从同一个节点出发探索了多个分支后,其中某个分支产生了特别满意的结果。但在切换到其他分支查看之后再回来,可能已经记不清那个满意的结果位于哪个分支了。分支越多,这种"迷路"的风险越大,反而会抑制用户主动探索的意愿。
针对这一问题,一个可行的方案是在树形结构上增加"分支书签"功能:
- 当用户对某个节点或某条回复感到满意时,可以对其进行标记或命名。
- 在侧边栏的树状视图中,被标记的节点以高亮形式显示。
- 提供一个集中的书签列表,汇总所有标记过的节点,支持一键跳转。
这样,用户就可以放心地进行多路径探索,因为有价值的结果已经被记录下来,随时可以回溯。
6. 导出为图片
传统聊天应用:我们什么时候才能学会 Markdown?
AI 生成的内容通常包含丰富的 Markdown 格式——代码块带有语法高亮,表格结构清晰,层次分明。这些内容在聊天界面中的呈现效果很好,但在需要分享给他人时,问题就出现了。
- 复制文本,格式丢失。 将内容直接复制到微信、钉钉、飞书等即时通讯工具中,Markdown 格式会完全失效。代码失去高亮和缩进,表格退化为散乱的纯文本,可读性大打折扣。
- 手动截图,效率低下。 使用系统截图工具是一种常见的替代方案,但体验并不理想。当内容超出一屏时,需要进行长截图或多次截图拼接,操作繁琐,且容易引入无关的界面元素。
一个更合理的方案是:在每条 AI 回复旁提供"导出为图片"或"复制为图片"的按钮。点击后,将该回复连同其格式渲染为一张图片,存入系统剪贴板,供用户直接粘贴到任何应用中。如果还能提供一些可选项——例如是否包含用户的提问、选择亮色或暗色背景——则会更加实用。
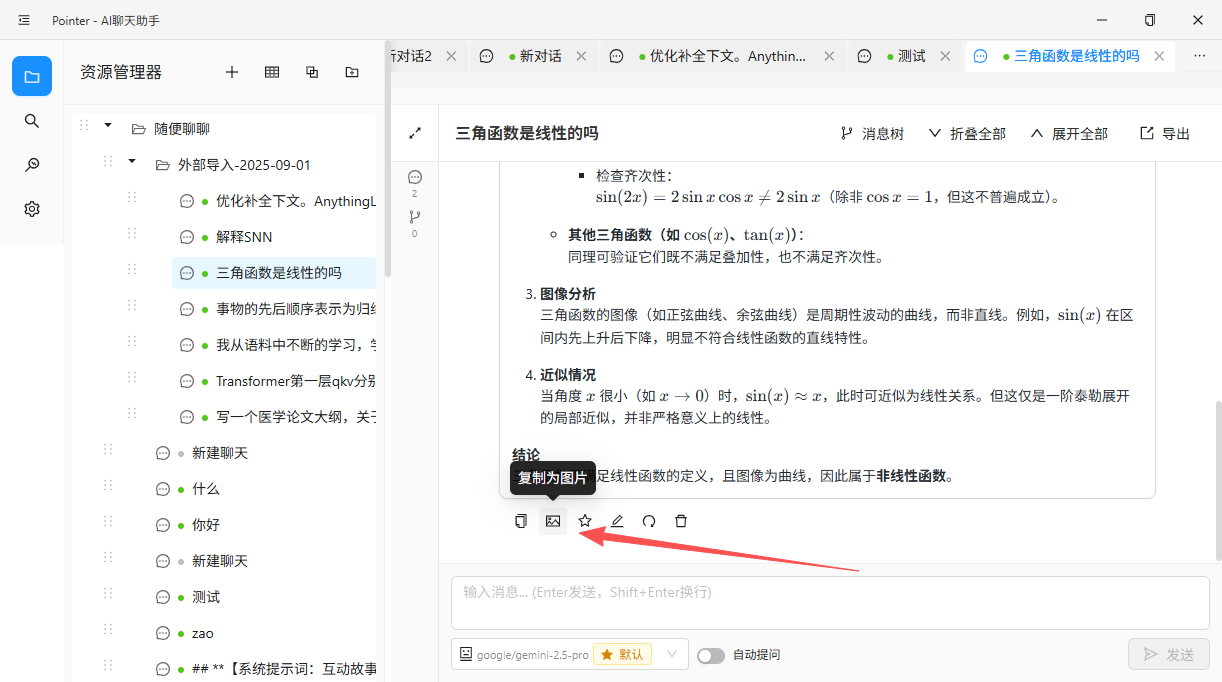
7. 选择性导出
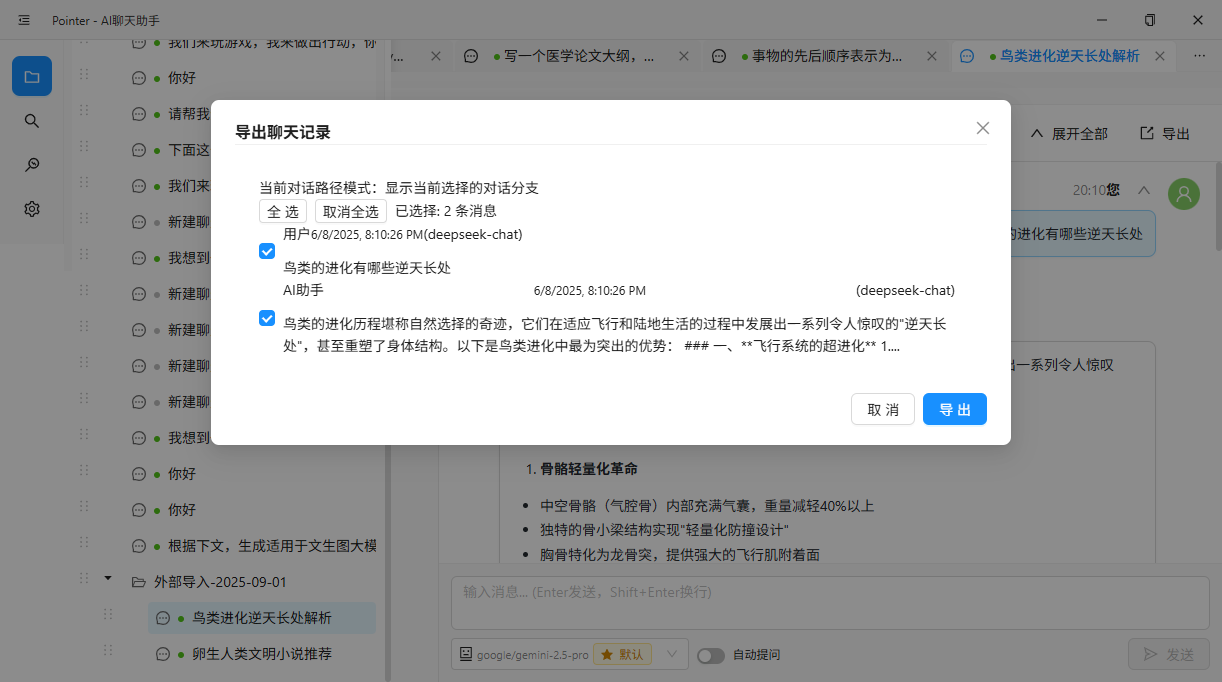
聊天分享的关键就是分享关键的聊天。
与上一条相关但不同的是,有时用户需要分享的并非某一条完整的回复,而是一段对话中散落在不同轮次的关键片段。
一段完整的对话往往包含了反复试探、纠正和调整的过程。其中真正有价值的内容,可能只是第 2、3、5 轮的问答,它们组合在一起才构成一个完整的解决方案。但目前的工具通常只支持"分享整段对话"或"复制单条消息",无法满足这种选择性提取的需求。用户不得不手动逐条复制,再到外部编辑器中整理拼接。
一个"勾选模式"可以解决这个问题:
- 在每条消息(包括用户提问和 AI 回复)前提供一个复选框。
- 用户自由勾选需要的条目。
- 勾选完成后,提供"合并复制为文本"和"合并导出为图片"两个选项。
这样,用户就能以最小的操作成本,生成一份只包含核心内容的、干净连贯的输出。
第三部分:系统的灵活性与开放性
前两部分关注的是单个对话内部的体验。而从更宏观的角度看,工具本身的灵活性和开放性同样值得重视。
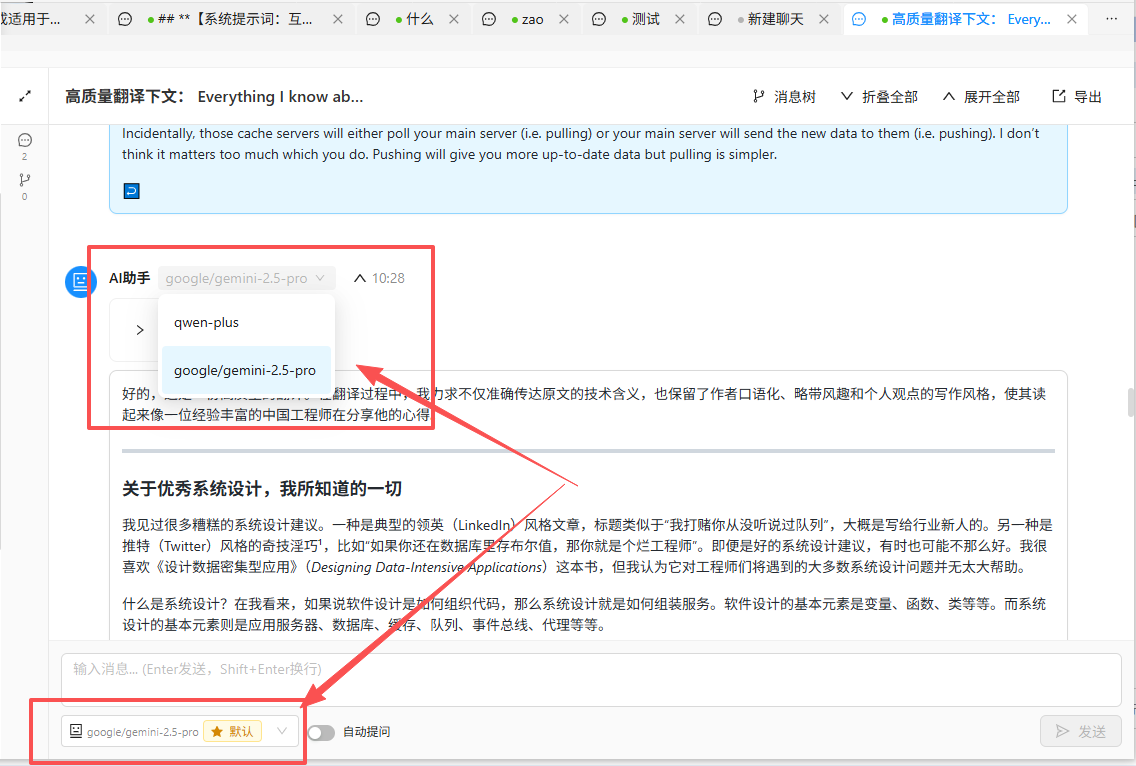
8. 对话中切换模型
模型如衣服。
不同的大语言模型在能力上各有侧重。有的模型在逻辑推理和代码生成方面表现突出,有的则在自然语言表达和创意写作上更为擅长。在实际工作中,一个完整的任务往往需要不同类型的能力介入。
然而,目前多数工具将模型选择绑定在对话创建时。如果中途想换用另一个模型来处理同一问题,用户需要手动复制上下文,打开新的对话甚至新的平台,再粘贴进去。这个过程不仅繁琐,还容易造成上下文的断裂和信息的丢失。
更理想的方式是允许用户在同一对话的不同轮次中自由切换模型。例如,先用擅长推理的模型分析数据,再切换到擅长写作的模型,让它基于前文的分析结果撰写报告。聊天记录中应清晰标注每条回复的生成模型,以便用户了解信息来源。
这种机制让不同模型能够在一个连贯的上下文中协同工作,充分发挥各自的优势。
9. 界面元素的可控性
没有闭环,因为没人点赞。
这一条涉及的是一个具体但普遍存在的界面设计问题:几乎所有 AI 聊天工具都会在每条回复下方放置"点赞"和"反对"按钮。这些按钮的初衷是收集用户反馈以改进模型,但从实际使用体验来看,它们带来的问题可能多于收益。
- 使用率低。 绝大多数用户使用聊天工具的目的是解决具体问题,而非为模型训练提供标注数据。这些按钮长期处于被忽视的状态。
- 误触风险。 它们通常紧邻"复制"等高频操作按钮,在快速操作时容易被意外点击。
- 隐私顾虑。 部分用户担心,点击反馈按钮可能会导致当前对话被标记并提交至后台进行人工审核,尤其在对话涉及敏感内容时,这种担忧并非没有道理。
改进的方向并不复杂:在设置中提供一个开关,允许用户选择隐藏这些按钮;或者将它们收入"更多操作"菜单中,降低误触概率的同时也减少视觉干扰。更根本地说,产品设计应当尊重用户对界面元素的控制权——用户有权决定自己的工作界面上保留哪些功能。
10. 标准化的导入与导出
聊天树是一棵居家盆栽。
用户在某个平台上积累的大量对话记录,本质上构成了一种个人知识资产。然而,当用户因各种原因需要迁移到其他平台或本地工具时,往往会发现这些数据被锁定在原有平台中,无法带走。
这个问题的解决依赖于标准化的导入导出功能:
- 完整的结构化导出。 导出格式应为结构化的数据文件(如 JSON),而非简单的纯文本。文件中需包含完整的对话元数据——消息的时间戳、角色标识(用户/AI)、对话的分支结构、所使用的模型信息等。只有保留了这些结构信息,导出的数据才具备在其他工具中完整还原的可能性。
- 对应的导入能力。 用户可以将导出的文件导入到任何兼容该格式的客户端中,恢复完整的对话历史和结构。
目前的现实是,各平台的数据格式各不相同,用户如果想实现数据迁移,只能自行编写格式转换器。这虽然可行,但显然不应是常态。至少,平台应当提供完善的数据导出功能,将选择权交给用户。
数据的自由流动是用户真正拥有数据所有权的基础。这一点,理应成为行业的基本共识。

结语
以上十条建议,归结起来指向同一个方向:大语言模型聊天工具需要从一个即时性的问答界面,逐步演进为一个可长期使用、结构清晰、内容可管理、数据可迁移的个人知识工具。
这并非过高的要求。每一条建议所涉及的功能,在技术上都并不复杂。它们更多地反映了一种产品设计层面的取舍——是将对话仅仅视为一次性的信息交换,还是将其作为用户持续积累的知识资产来对待。
我相信,随着使用场景的深入和用户群体的成熟,这些需求会越来越普遍地被感知到。希望这些来自实际使用中的观察,能够为相关产品的改进提供一些参考。
附录
GitHub 开源: https://github.com/experdot/pointer [MIT]
后续文章:20 个追求极致体验的 AI 聊天软件功能

 浙公网安备 33010602011771号
浙公网安备 33010602011771号