


数据的爬取和分析
涉及:
- 使用Requests进行网页爬取
- 使用BeautifulSoup进行HTML解析
- 正则表达式入门
- 使用潜在狄利克雷分布模型解析话题提取
简单页面的爬取
1.准备Requests库和User Agent
安装 pip install requests
Requests库基于urllib,是一个常用的http请求库
user agent——让爬虫假装是一个正常的用户在使用浏览器对目标网站的服务器发出请求
直接百度“UA查询”,也可以使用自己的
2.确定目标网站并分析结构
http://www.gov.cn/
大学生要多关心宏观政治和形势,所以爬取下我国最新政策文件
目标地址:
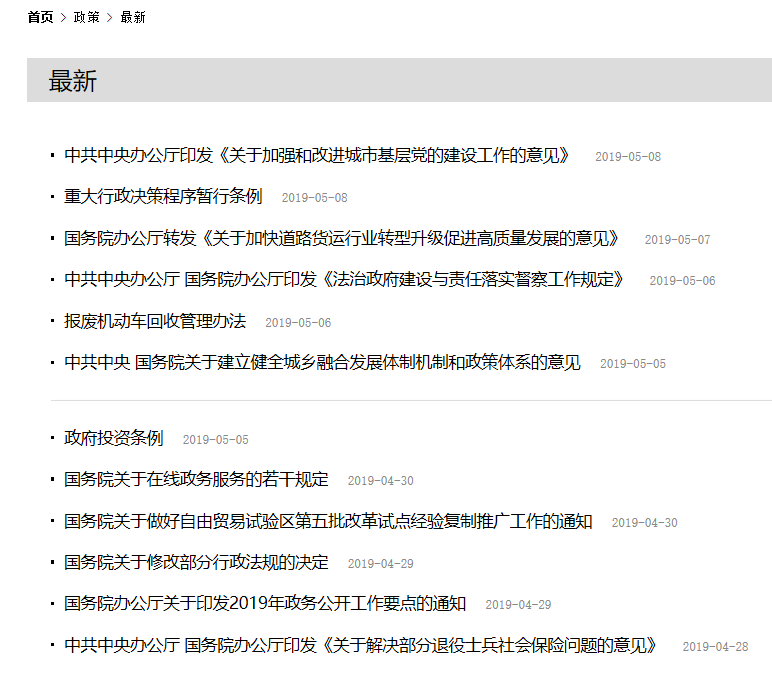
选中此页,网址为:http://www.gov.cn/zhengce/2019-05/05/content_5388880.htm
3.进行爬取并保存为本地文件
A.导入requests库,并配置user agent
#导入requests库 import requests #指定我们的uesr agent user_agent = 'Mozilla/5.0 (Windows NT 10.0 ;Win64; x64)\AppleWebKit/537.36 (KHTML ,like Gecko) Chrome/62.0.3202.94 Safari/537.36' headers = {'User_Agent':user_agent}
B.使用requests向服务器发送请求
#requests库用来发送请求的语句是requests.get r = requests.get("http://www.gov.cn/zhengce/content/2017-11/23/content_5241727.htm",headers=headers) #打印结果 print(r.text)
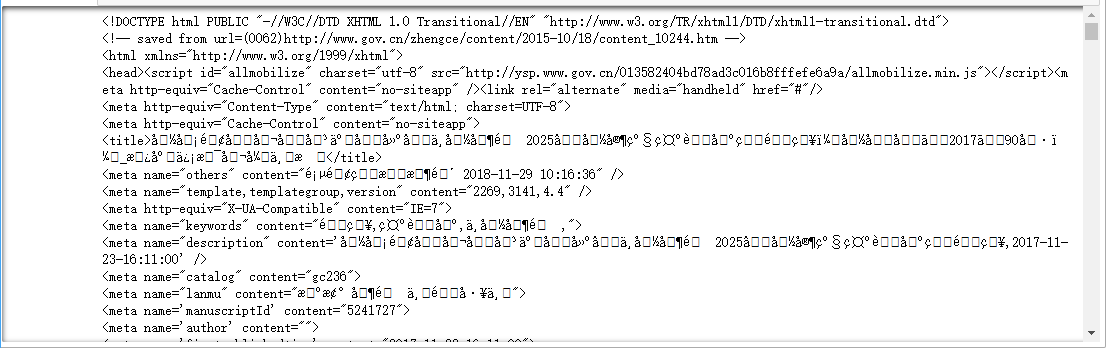
【结果分析】
出现了乱码
使用encoding查询一下requests的编码方式:
#使用.encoding 查询编码方式 print(r.encoding)
ISO-8859-1
而页面中的编码方式为
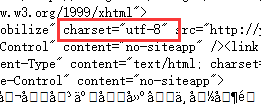
C.调整requests的编码方式
#修改encoding为utf-8 r.encoding = 'utf-8' print(r.text)
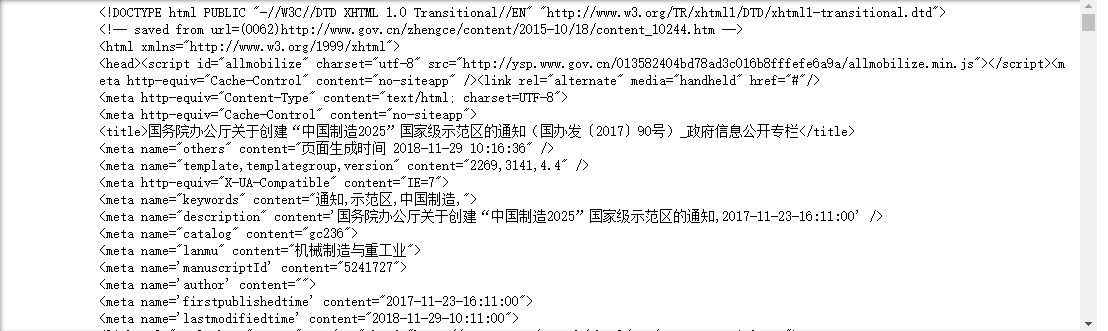
【结果分析】
中文文本已经正常显示了,但掺杂着大量的html代码
解决办法:
- 将爬取的文件保存为html文件,用浏览器打开
- 使用html解析器,将页面中的重要内容抽取出来,保存为我们需要的任意格式的文件
D.第一种方法:
#指定保存html文件的路径/文件名/编码 with open('e:/Doyo/xx.html','w',encoding='utf-8') as f: #将文本写入 f.write(r.text)

点击即可浏览
稍微复杂点的爬取
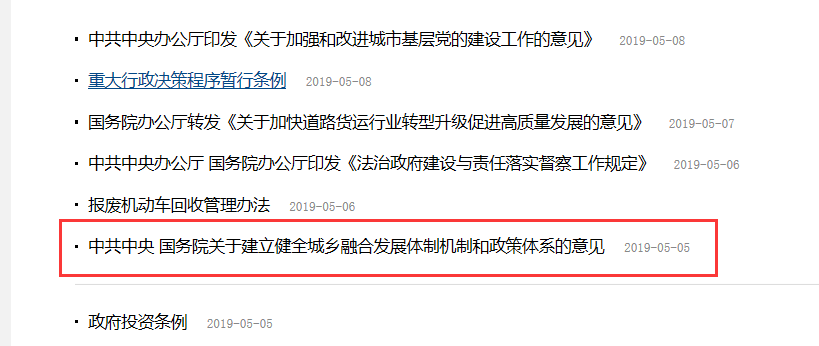
爬取最新政策页面栏
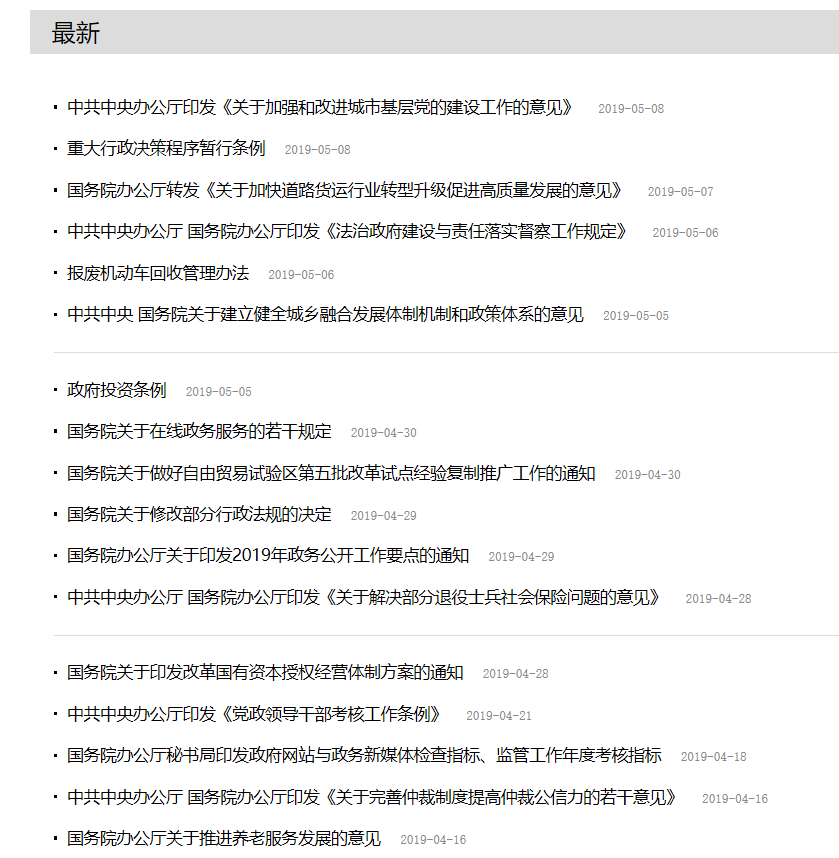
网页分析如下:
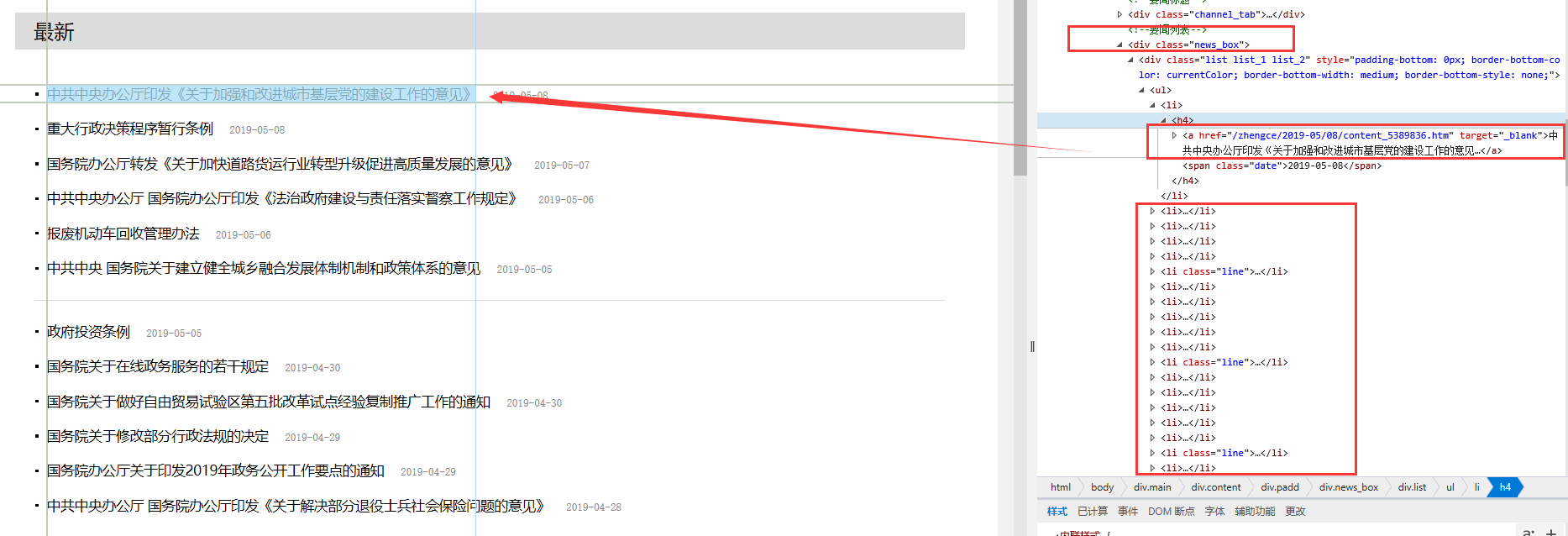
【结果分析】
红色方框中便是我们想要的内容
正则表达式
正则表达式是一个特殊的字符序列
能帮助我们检查一个字符串中是否与某种模式匹配
python中的re模块可以提供全部的正则表达式功能
#导入re模块 import re #指定匹配模式为从开始位置匹配数字 pattern = re.compile(r'\d+') #第一句话,前是文本,后是数字 result1 = re.match(pattern,'你说什么都是对的233') #如果匹配成功,打印匹配的内容 if result1: print(result1.group()) #否则打印匹配失败 else: print('匹配失败') #第二句话,前是数字,后是文本 result2 =re.match(pattern,'233你说什么都是对的') if result2: print(result2.group()) else: print('匹配失败')
匹配失败
233
【结果分析】
指定的re匹配模式是: \d+【这里的\d+ 被称为元字符】
意思是匹配一个或多个数字,如果不加“+”的话,只会匹配一个数字
即看看开头有没有数字

希望不管数字在开头还是结尾或是中间,都可以匹配它们:
#用.search() 进行搜索 result3 = re.search(pattern,'你说什么233都是对的') if result3: print(result3.group()) else: print('匹配失败')
233
re模块中的多种语法:

使用BeautifulSoup进行HTML解析
安装 pip install beautifulsoup4
#导入beautifulsoup4 from bs4 import BeautifulSoup #创建一个名为soup的对象 soup = BeautifulSoup(r.text,'lxml',from_encoding = 'utf-8') print(soup)

【结果分析】
这里我们指定BeautifulSoup使用lxml作为html解析器,当然,也可以使用python标准库,但lxml解析速度较快
最后生成的文件中,含有若干个标签Tag,每个标签都注明了其作用
使用BeautifulSoup将title进行提取:
#使用 .'标签名' 提取该部分内容 print(soup.title)
<title>国务院办公厅关于创建“中国制造2025”国家级示范区的通知(国办发〔2017〕90号)_政府信息公开专栏</title>
只显示文字:
- 使用 .string 提取文字部分
- 使用 .get_text()提取文字部分

提取正文的部分:
首先检查一下soup,看下正文在哪里

正文放在<p></p>标签内
#打印标签<p>中的内容 print(soup.p.string)
国务院办公厅关于创建“中国制造2025”
默认情况下,BeautifulSoup只提取第一个<p></p>中的内容
找全部<p>的内容
#使用find_all找到所有的<p>标签中的内容 texts = soup.find_all('p') #使用for循环打印 for text in texts: print(text.string)

提取链接
#找到倒数第一个<a>标签 link = soup.find_all('a')[-1] print('提取到的链接',link.get('href'))
提取到的链接 http://www.gov.cn/home/2014-02/18/content_5046260.htm
【结果分析】
使用[-1]来把最后一个标签赋值给link
保存到本地

import requests #导入csv库,便于把爬取的页面保存为csv文件 import csv #导入beautifulsoup4 from bs4 import BeautifulSoup import re #指定我们的uesr agent user_agent = 'Mozilla/5.0 (Windows NT 10.0 ;Win64; x64)\AppleWebKit/537.36 (KHTML ,like Gecko) Chrome/62.0.3202.94 Safari/537.36' headers = {'User_Agent':user_agent} #发送请求的语句是requests.get zc = requests.get("http://www.gov.cn/zhengce/zuixin.htm",headers=headers) #encoding为utf-8 zc.encoding = 'utf-8' #创建BeautifulSoup对象 p = BeautifulSoup(zc.text,'lxml') #使用正则表达式匹配所有包含'content'单词的链接 contents = p.find_all(href=re.compile('content')) #定义一个空列表 rows = [] #设置一个for循环,将每个数据中的链接和文本进行提取 for content in contents: href=content.get('href') row = ('国务院',content.string,href) #将提取的内容添加到前面定义的空列表中 rows.append(row) #定义csv的文件头 header = ['发文部门','标题','链接'] #建立一个名叫zc.csv的文件,以写入模式打开,设置编码为gb18030 with open('d:/zc.csv','w',encoding='gb18030') as f: f_csv = csv.writer(f) #写入文件头 f_csv.writerow(header) #写入列表 f_csv.writerows(rows) print('信息获取完成,目标保存在D盘,zc.csv文件')

对文本数据进行话题提取
如果我们想快速了解一大段文字的核心内容,如何做?
使用潜在狄利克雷分布对文本进行话题提取:
目标网址:http://www.budejie.com/
单击“段子”,地址栏显示http://www.budejie.com/text/
"下一页",则变成了http://www.budejie.com/text/2
所以,该网站是在网址做后加数字来区分页面
但
所以我们就把页面锁定在1~50页
分析网页,发现段子的正文保存在<div class='j-r-list-c-desc'>标签中
爬取
import requests #导入csv库,便于把爬取的页面保存为csv文件 import csv #导入beautifulsoup4 from bs4 import BeautifulSoup import re import time #指定我们的uesr agent user_agent = 'Mozilla/5.0 (Windows NT 10.0 ;Win64; x64)\AppleWebKit/537.36 (KHTML ,like Gecko) Chrome/62.0.3202.94 Safari/537.36' headers = {'User_Agent':user_agent} #创建一个空列表 all_jokes=[] #设置一个for循环,让爬虫从第一页爬到第50页 for i in range(1,51): content = requests.get('http://www.budejie.com/text/{}'.format(i),headers=headers) #替换掉网页中的<br> <br/>等无用的标签 replaced = content.text.replace('<br>','').replace('<br />','').replace('<br/>','') #使用BeautifulSoup提取段子的正文 soup = BeautifulSoup(replaced,'lxml') jokes = soup.find_all('div',class_='j-r-list-c-desc') for joke in jokes: text = joke.a.string #将段子正文添加到列表中 all_jokes.append(text) #打印正在爬取的页面 print('正在爬取第{}页'.format(i)) #每爬取一页休眠2秒,防止给服务器太多负担 time.sleep(2)
爬虫正在工作...

#以写入模式在D盘打开jokes的txt文件,编码为utf-8 with open('d:/jokes.txt','w',encoding='utf-8') as f: for j in all_jokes: #将爬取的段子写入文件中 f.write(str(j)) f.write('\n')

使用潜在狄利克雷分布进行话题提取:
潜在狄利克雷分布,LDA,是基于不同的词语共同出现的频率来进行分组的模型
比如,某个文档中“妹子”和“吃货”两个词经常出现,那么LDA便会将这两个词归入同一话题中

载入之前保存的txt文件:
#以读取模型打开之前存好的txt文件 file = open('d:/jokes.txt','r',encoding='utf-8') #读取文本的所有行 lines = file.readlines() #提取文本中的字符串数据 line = str(lines)
#导入结巴分词 import jieba #分词处理 line = jieba.cut(line) x = ' '.join(line) #保存为另一个txt文件 with open('d:/cut_jokes.txt','w') as f: f.write(x)

话题提取:首先将文本数据转化为向量
#导入TfidfVectorizer from sklearn.feature_extraction.text import TfidfVectorizer #导入LDA模型 from sklearn.decomposition import LatentDirichletAllocation #定义一个函数,用来打印提取后的话题和高频词 def print_topics (model,feature_names,n_top_words): for topic_idx ,topic in enumerate(model.compenents_): message = 'topic #%d:' % topic_idx message += ' '.join([feature_names[i] for i in topic.argsort()[:-n_top_words - 1 :-1]]) print(message) print() #载入分词处理过的文本文件 f = open('d:/cut_jokes.txt','r') #定义每个话题提取20个高频词 n_top_words = 20 #Tfidf最大特征数为1000 tf = TfidfVectorizer(max_features=1000) #将转化为向量的文本数据作为训练数据 x_train = tf.fit_transform(f) #指定LDA模型提取10个话题 lda = LatentDirichletAllocation(n_components=10) lda.fit(x_train) #将结果打印 print_topics(lda,tf.get_feature_names(),n_top_words)



 浙公网安备 33010602011771号
浙公网安备 33010602011771号