机器学习【一】K最近邻算法
基本原理

K的含义就是最近邻的个数。在sklearn中,KNN的K值是通过n_neighbors参数来调节的

不适用:对数据集认真的预处理、对规模超大的数据集拟合的时间较长、对高维数据集拟合欠佳、对稀疏数据集无能为力
from sklearn.neighbors import KNeighborsClassifier #导入KNN分类器
import matplotlib.pyplot as plt #导入画图工具
from sklearn.model_selection import train_test_split #导入数据集拆分工具
data = make_blobs(n_samples=200, centers = 2,random_state = 8) #生成样本数为200,分类为2的数据
X ,y = data #将生成的数据可视化
plt.scatter(X[:,0],X[:,1],c=y,cmap=plt.cm.spring,edgecolor='k')
plt.show()

接下来用KNN拟合这些数据:
clf = KNeighborsClassifier()
clf.fit(X,y)
x_min,x_max = X[:,0].min() -1,X[:,0].max() + 1
y_min,y_max = X[:,1].min() -1,X[:,1].max() + 1
xx,yy = np.meshgrid(np.arange(x_min,x_max, .02),np.arange(y_min,y_max, .02))
Z = clf.predict(np.c_[xx.ravel(),yy.ravel()])
Z = Z.reshape(xx.shape)
plt.pcolormesh(xx,yy,Z,cmap=plt.cm.Pastel1)
plt.scatter(X[:, 0],X[:, 1],c = y,cmap = plt.cm.spring, edgecolor = 'k')
plt.xlim(xx.min(),xx.max())
plt.ylim(yy.min(),yy.max())
plt.title("Classifier:KNN")
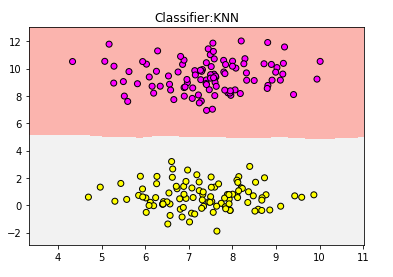

可见,分到了浅灰色一类
验证代码如下:
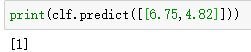
2.处理多元分类任务
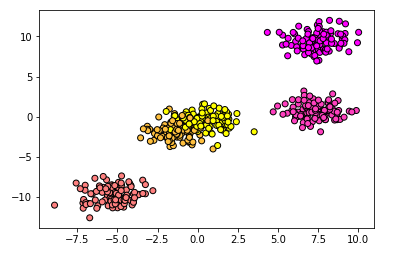
data2 = make_blobs(n_samples=500, centers = 5,random_state = 8)
X2,y2 = data2
#用散点图将数据可视化
plt.scatter(X2[:,0],X2[:,1],c = y2,cmap = plt.cm.spring,edgecolor='k')
plt.show()
用KNN建立模型拟合数据:
clf = KNeighborsClassifier()
clf.fit(X2,y2)
x_min,x_max = X2[:,0].min() -1,X2[:,0].max() + 1
y_min,y_max = X2[:,1].min() -1,X2[:,1].max() + 1
xx,yy = np.meshgrid(np.arange(x_min,x_max, .02),np.arange(y_min,y_max, .02))
Z = clf.predict(np.c_[xx.ravel(),yy.ravel()])
Z = Z.reshape(xx.shape)
plt.pcolormesh(xx,yy,Z,cmap=plt.cm.Pastel1)
plt.scatter(X2[:, 0],X2[:, 1],c = y2,cmap = plt.cm.spring, edgecolor = 'k')
plt.xlim(xx.min(),xx.max())
plt.ylim(yy.min(),yy.max())
plt.title("Classifier:KNN")
plt.show()
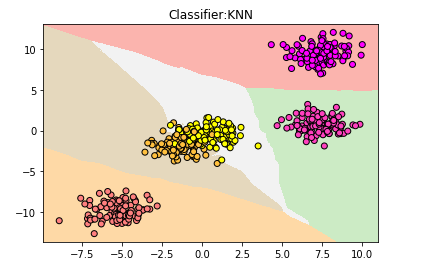
但仍然有小部分数据进入错误的分类

3.用于回归分析
make_regression函数,一个非常好的用于回归分析的数据集生成器
from sklearn.datasets import make_regression
#生成特征数量为1,噪音为50的数据集
X,y = make_regression(n_features=1,n_informative=1,noise=50,random_state=8)
#用散点图将数据点可视化
plt.scatter(X,y,c='orange',edgecolor='k')
plt.show()
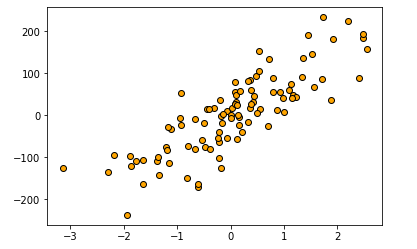
如上,横轴代表样本特征的数值,范围大概在-3~3;
纵轴代表样本的测定值,范围在-250~250
使用KNN进行回归分析:
#导入用于回归分析的KNN模型
from sklearn.neighbors import KNeighborsRegressor
reg = KNeighborsRegressor()
#利用KNN模型拟合数据
reg.fit(X,y)
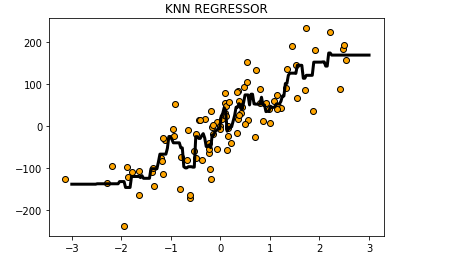
#把预测结果可视化
z = np.linspace(-3,3,200).reshape(-1,1)
plt.scatter(X,y,c='orange',edgecolor='k')
plt.plot(z,reg.predict(z),c='k',linewidth=3)
#添加标题
plt.title("KNN REGRESSOR")
plt.show()
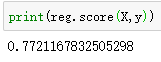
from sklearn.neighbors import KNeighborsRegressor
reg = KNeighborsRegressor(n_neighbors=2)
#利用KNN模型拟合数据
reg.fit(X,y)
#把预测结果可视化
z = np.linspace(-3,3,200).reshape(-1,1)
plt.scatter(X,y,c='orange',edgecolor='k')
plt.plot(z,reg.predict(z),c='k',linewidth=3)
#添加标题
plt.title("KNN REGRESSOR:n_neighbors=2")
plt.show()

KNN实战——酒的分类
使用load_wine函数载入的酒数据集,是一种Bunch对象,包括键【keys】和数值【values】
检查酒的数据集有哪些键:
from sklearn.datasets import load_wine
#载入数据集
wine_dataset = load_wine()
#打印数据集中的键
print(wine_dataset.keys())
#打印数据集中的数值,详见博客--机器学习入门
#print(wine_dataset.values())

数据集中有多少样本【samples】变量【features】:
可以使用.shape语句告诉我们大概的数据轮廓
from sklearn.datasets import load_wine
#载入数据集
wine_dataset = load_wine()
#打印数据集中有多少样本和变量
print(wine_dataset['data'].shape)

即有178个样本,13个特征变量
#查看更细节的信息
print(wine_dataset['DESCR'])
生成训练数据集和测试数据集
sklearn中,有一个 train_test_split 函数,用来帮助用户把数据集拆分的工具
原理:
将数据集随机排列,默认情况下,将75%的数据及对应的标签划到训练数据集,将25%的数据和对应的标签划归到测试数据集
一般用大写的X表示数据特征,小写的y表示数据对应的标签
因为X是一个二维数组,也称为矩阵,y是一个一维数组,或者说是一个向量
#导入数据集拆分工具
from sklearn.model_selection import train_test_split
#将数据集拆分为训练+ 测试集
X_train,X_test,y_train,y_test = train_test_split(wine_dataset['data'],wine_dataset['target'],random_state=0)
上述,train_test_split 函数生成一个伪随机数,并根据这个伪随机数对数据集拆分
相同的 random_state 参数,会一直生成同样的伪随机数,但当这个值我们设为0的时候,或者保持缺省的时候,每次生成的伪随机数均不同
#导入数据集拆分工具
from sklearn.model_selection import train_test_split
#将数据集拆分为训练+ 测试集
X_train,X_test,y_train,y_test = train_test_split(wine_dataset['data'],wine_dataset['target'],random_state=0)
#训练集中特征向量的形态
print(X_train.shape)
#测试集中特征向量的形态
print(X_test.shape)
#训练集中目标的形态
print(y_train.shape)
#测试集中目标的形态
print(y_test.shape)

使用KNN建模
#导入KNN分类模型
from sklearn.neighbors import KNeighborsClassifier
#指定模型的n_neighbors参数值为1
knn = KNeighborsClassifier(n_neighbors=1)
#使用模型对数据拟合
knn.fit(X_train,y_train)
print(knn)

# knn的拟合方法,把自身作为结果返回,从结果中可以看到模型的全部参数设定【除了n_neighbors=1,其余默认即可】
KNN根据训练集建立模型,在训练数据集中寻找和新输入的数据最近的数据点,然后把这个数据点的标签,分给新的数据点
代码详细解释:
机器学习模块,都是在固定的类中运行的
而KNN是在neighbors模块的KNeighborsClassifier类中运行
从一个类中创建对象的时候,需要给模型一个参数,对于KNeighborsClassifier类最关键的参数就是近邻的数量,也就是n_neighbors
knn则是在该类中创建的一个对象
该对象中,有一个“拟合”的方法——> fit 【用此建模】
建模的依据就是训练集中的样本数据X_train和对应的标签y_train
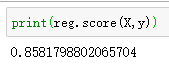
使用模型对新样本的分类进行预测
print(knn.score(X_test,y_test))
测试集的得分:
0.7555555555555555
对新酒进行分类预测:
import numpy as np
#输入新的数据点
X_new = np.array([[13.2,2.77,2.51,18.5,96.6,1.04,2.55,0.57,1.47,6.2,1.05,3.33,820]])
#使用.predict预测
pre = knn.predict(X_new)
print(wine_dataset['target_names'][pre])
['class_2']
KNN不适用:
需要提前对数据集认真的预处理、对规模超大的数据集拟合的时间较长、对高维数据集拟合欠佳、对稀疏数据集无能为力
在高维数据集中表现良好的算法:广义线性模型

 浙公网安备 33010602011771号
浙公网安备 33010602011771号