Nim 从入门到实战
Nim
Nim 是一个与其 1.0 版本相似的新颖且令人兴奋的命令式编程语言。我使用 Nim 是为了它的性能与优雅,这无疑让我感到了莫大的乐趣。在这篇文章中我将向您展示一个我写的 Nim 项目的全部流程。
本文我们要实现 Brainfuck 语言的解释器。虽然 Nim 是一个实用且特性丰富的编程语言,而 Brainfuck 则是仅由八个命令组成的一无是处的编程语言,但它的简陋对我们实现一个简单的解释器却是极棒的。稍后我们将实现具有高性能的编译时的将 Brainfuck 编译为 Nim 的解释器。我们最终将将其制作成 nimble包 并发布到在线仓库。
安装 Nim
安装 Nim 非常简单,你可以直接参照官方说明。 Nim 对 Windows 系统直接提供可执行文件。在其他操作系统上你可以运行build.sh来编译生成的 C 语言代码,这在现代计算机操作系统上应该只需要不到 1 分钟。
这给我们带来了关于 Nim 的第一个有趣的事实:它主要编译成 C(C++、ObjectiveC 甚至 JavaScript),然后使用您选择的高度优化的 C 编译器生成实际程序。你就可以免费从成熟的 C 生态系统中受益。
如果你选择引导完全用Nim本身编写的 Nim 编译器,你可以看到编译器只需几个简单步骤(不到2分钟)就可以完成自举:
$ git clone https://github.com/nim-lang/Nim
$ cd Nim
$ git clone --depth 1 https://github.com/nim-lang/csources
$ cd csources && sh build.sh
$ cd ..
$ bin/nim c koch
$ ./koch boot -d:release
通过这种方式,您可以获得 Nim 的开发版本。使用两个步骤应该来保持最新:
$ git pull
$ ./koch boot -d:release
要是你没有git,现在也是绝佳的安装它的时机。大部分nimble包都需要git来获取。在基于 Debian 的操作系统上(比如 Ubuntu)我们可以像这样安装它:
$ sudo apt-get install git
安装完成后,你需要将nim 添加到你的环境变量中。以下是在 bash 中的操作方法:
$ echo 'export PATH=$PATH:$your_install_dir/bin' >> ~/.profile
$ source ~/.profile
$ nim
Nim Compiler Version 0.17.3 [Linux: amd64]
Copyright (c) 2006-2017 by Andreas Rumpf
::
nim command [options] [projectfile] [arguments]
Command:
compile, c compile project with default code generator (C)
doc generate the documentation for inputfile
...
只要nim告诉了我们其版本与状态,我们就可以愉快的继续了。现在 Nim 标准库只是一些简单的模块,其他所有包都可以使用nimble来安装。让我们遵循单行安装说明:
$ ./koch nimble
Nimble 的二进制目录也需要添加到环境变量:
$ echo 'export PATH=$PATH:$HOME/.nimble/bin' >> ~/.profile
$ source ~/.profile
$ nimble update
Downloading Official package list
Success Package list downloaded.
现在我们在终端可以查看所有可用的 nimble 包:
$ nimble search docopt
docopt:
url: https://github.com/docopt/docopt.nim (git)
tags: commandline, arguments, parsing, library
description: Command-line args parser based on Usage message
license: MIT
website: https://github.com/docopt/docopt.nim
让我们安装我们发现的这个不错的 docopt 库,也许我们稍后会需要它:
$ nimble install docopt
...
Verifying dependencies for docopt@0.6.5
Installing docopt@0.6.5
Success: docopt installed successfully.
请注意库的安装速度有多快(对我来说不到1秒)。这个是尼姆的另一个很好的效果。基本上,库的源代码只是下载后,不会编译任何类似共享库的内容。取而代之的是一旦我们使用了这个库,它将被简单地静态编译到我们的程序中。
主流的编辑器中支持 Nim 的编辑器有 Emacs(nim-mode),Vim(nimrod.vim这只是我的选择)以及 Sublime(NimLime)。对于本指南的范围任何文本编辑器都 OK。
项目配置
现在我们可以开始我们的项目了:
$ mkdir brainfuck
$ cd brainfuck
第一步当然就是万年不变的 Hello World 了!让我们创建 hello.nim并写入以下内容:
echo "Hello World"
让我们先使用以下两个单独的步骤来编译运行它:
$ nim c hello
$ ./hello
Hello World
然后只需一步,通过指示 Nim 编译器方便地编译并直接执行二进制文件:
$ nim c -r hello
Hello World
让我们让代码做些稍微复杂一点的事情,这应该需要一个更长的运行时间:
var x = 0
for i in 1 .. 100_000_000:
inc x # 自增 x,这是一个注释
echo "Hello World ", x
在这段代码中我们先声明变量x的值为 0 再把它循环加了 1000 万次。再次尝试编译它。注意跑了多长时间。Nim的表现糟糕吗?当然不是,恰恰相反!我们目前只是在完全调试模式下构建二进制文件,添加了对整数溢出、数组越界等等的检查,以及不优化二进制。使用选项-d:release可以让我们进入发行版编译模式,令程序运行如窜稀:
$ nim c hello
$ time ./hello
Hello World 100000000
./hello 2.01s user 0.00s system 99% cpu 2.013 total
$ nim -d:release c hello
$ time ./hello
Hello World 100000000
./hello 0.00s user 0.00s system 74% cpu 0.002 total
简直快得升天!C编译器优化了整个for循环。666!
创建一个项目可以使用nimble init来初始化基本的包配置文件:
$ nimble init brainfuck
Info: In order to initialise a new Nimble package, I will need to ask you
... some questions. Default values are shown in square brackets, press
... enter to use them.
Prompt: Initial version of package? [0.2.0]
Answer:
Prompt: Your name? [Dennis Felsing]
Answer:
Prompt: Package description?
Answer: A brainfuck interpreter
Prompt: Package license? [MIT]
Answer:
Prompt: Lowest supported Nim version? [0.17.3]
Answer: 0.10.0
Success: Nimble file created successfully
创建出的brainfuck.nimble应像这样:
# Package
version = "0.2.0"
author = "Dennis Felsing"
description = "A brainfuck interpreter"
license = "MIT"
# Dependencies
requires "nim >= 0.10.0"
让我们在此 nimble 包构建文档中添加对 docopt 和我们想要创建的二进制文件的需求:
# Package
version = "0.2.0"
author = "Dennis Felsing"
description = "A brainfuck interpreter"
license = "MIT"
bin = @["brainfuck"]
# Dependencies
requires "nim >= 0.10.0"
requires "docopt >= 0.1.0"
因为我们已经安装了 git,所以我们希望保留源代码的修订版代码,可能想在某个时候在线发布,让我们初始化一个 git 存储库:
$ git init
$ git add brainfuck.nim brainfuck.nimble .gitignore
我刚刚初始化了.gitignore文件到此:
nimcache/
*.swp
我们让 git 忽略 vim 的交换文件,以及nimcache所目录包含的为我们的项目生成的C代码。如果你好奇的话可以去看看 Nim 是如何编译成 C 语言的。
为了看看 nimble 能做什么,让我们初始化我们的主程序brainfuck.nim:
echo "Welcome to brainfuck"
我们依然可以像编译hello.nim那样编译它,但既然我们以及准备好了把它编译成brainfuck包的配置,那就让nimble来编译吧:
$ nimble build
Verifying dependencies for brainfuck@0.2.0
Info: Dependency on docopt@>= 0.6.5
Verifying dependencies for docopt@0.6.5
Building brainfuck/brainfuck using c backend
$ ./brainfuck
Welcome to brainfuck
nimble install可用于在系统上安装二进制文件,以便我们可以从任何位置运行它:
$ nimble install
Verifying dependencies for brainfuck@0.2.0
Info: Dependency on docopt@>= 0.6.5>= 0.6.5 already satisfied
Verifying dependencies for docopt@0.6.5
Installing brainfuck@0.2.0
Building brainfuck/brainfuck using c backend
Success: brainfuck installed successfully.
$ brainfuck
Welcome to brainfuck
这非常适合程序工作的情况,但实际上nimble build为我们做了一个发布版本。这比调试版本需要更长的时间,并且省略了在开发过程中非常重要的检查,因此现在更适合使用nim c \-r brainfuck。在开发过程中,请经常执行我们的程序,以了解一切的工作原理。
编程
编程时,Nim 的文档很有用。如果您还不知道在哪里可以找到什么,可以查找文档目录。
让我们从修改brainfuck.nim来启动我们的开发之旅吧:
import os
首先,我们导入 os 模块,这将用来读取命令行参数。
let code = if paramCount() > 0: readFile paramStr(1)
else: readAll stdin
paramCount()告诉我们传递给程序的命令行参数的数量。如果我们得到一个命令行参数,我们假设它是一个文件名,然后直接用readFile paramStr(1)读入。否则,我们从标准输入中读取所有内容。在这两种情况下,结果都存储在code变量中,该变量已用let关键字声明为不可变(即常量)。
为了看到其确实运行了,我们使用echo code:
echo code
尝试一下:
$ nim c -r brainfuck
...
Welcome to brainfuck
I'm entering something here and it is printed back later!
I'm entering something here and it is printed back later!
输入你的“code”后,以换行符和 ctrl-d 结束。或者你可以输入一个文件名,nim c \-r brainfuck之后的所有内容都作为命令行参数传递给生成的二进制文件:
$ nim c -r brainfuck .gitignore
...
Welcome to brainfuck
nimcache/
*.swp
继续:
var
tape = newSeq[char]()
codePos = 0
tapePos = 0
我们声明了一些需要的变量。我们必须记住我们在code字符串的当前位置(codePos)和tape(磁带)的指针(tapePos)。Brainbuck 在无限增长的tape上工作,我们将其表示为由char(字符)组成的seq(序列)。序列是 Nim 的变长数组,除了使用newSeq声明之外,还可以使用var x = @[1, 2, 3]初始化序列。
让我们花点时间了解下:变量的类型不必被指定,它是由编译器自动推断的。如果我们想更加明确,我们可以这样做:
var
tape: seq[char] = newSeq[char]()
codePos: int = 0
tapePos: int = 0
接下来我们编写一个小函数,然后立即调用它:
proc run(skip = false): bool =
echo "codePos: ", codePos, " tapePos: ", tapePos
discard run()
有几点是需要注意的:
- 我们需要一个默认值为
false的skip参数; - 显而易见的是参数为
bool类型; - 返回值的类型也是
bool,可为什么我们没有返回呢?这是因为返回值默认为二进制的 0 ,也就是false。 - 在所有函数中我们都可以用
result = true隐式赋值result. - 通过使用
return true立即返回,可以更改控制流。 - 当我们调用
run()时必须discard(丢弃)掉它的返回值。不然会出现以下错误:brainfuck.nim(16, 3) Error: value of type 'bool' has to be discarded这是为了防止我们忘记处理返回值。
在我们继续之前,让我们思考一下 bringfuck 的运作方式。如果您以前了解过图灵机,其中一些内容可能看起来很相似。我们有一个输入字符串code和一个char序列tape,它们都可以在一个方向上无限增长。以下是输入字符串中可能出现的命令,除此之外的所有字符都要被忽略。
| Op(操作码) | Meaning(作用) | Nim equivalent(等价的 Nim 操作) |
|---|---|---|
> |
右移磁带的指针 | inc tapePos |
< |
左移磁带的指针 | dec tapePos |
+ |
自增指针指向值 | inc tape[tapePos] |
- |
自减指针指向值 | dec tape[tapePos] |
. |
输出指针指向值 | stdout.write tape[tapePos] |
, |
输入到指针指向值 | tape[tapePos] = stdin.readChar |
[ |
若指针指向值为\0,跳转到对应的] |
|
] |
若指针指向值非\0跳转到对应的[ |
凭借这些,bringfuck 就成为了最简单的图灵完备的编程语言之一。
前六个指令都可以使用 case 语句简单地转换为 Nim 方法。
proc run(skip = false): bool =
case code[codePos]
of '+': inc tape[tapePos]
of '-': dec tape[tapePos]
of '>': inc tapePos
of '<': dec tapePos
of '.': stdout.write tape[tapePos]
of ',': tape[tapePos] = stdin.readChar
else: discard
到目前为止,我们只处理输入中的单个字符,让我们将其作为一个循环来处理所有字符:
proc run(skip = false): bool =
while tapePos >= 0 and codePos < code.len:
case code[codePos]
of '+': inc tape[tapePos]
of '-': dec tape[tapePos]
of '>': inc tapePos
of '<': dec tapePos
of '.': stdout.write tape[tapePos]
of ',': tape[tapePos] = stdin.readChar
else: discard
inc codePos
让我们尝试一个简单的程序,如下所示:
$ echo ">+" | nim -r c brainfuck
Welcome to brainfuck
Traceback (most recent call last)
brainfuck.nim(26) brainfuck
brainfuck.nim(16) run
Error: unhandled exception: index out of bounds [IndexError]
Error: execution of an external program failed
什么玩意儿?!我们的代码崩溃了!我们做错了什么?磁带应该无限增长,但我们根本没有增加它的长度!下面一个简单的解决方案,只需在case语句前添加:
if tapePos >= tape.len:
tape.add '\0'
最后两个命令[与]形成一个循环。我们也可以将其添加到代码中:
proc run(skip = false): bool =
while tapePos >= 0 and codePos < code.len:
if tapePos >= tape.len:
tape.add '\0'
if code[codePos] == '[':
inc codePos
let oldPos = codePos
while run(tape[tapePos] == '\0'):
codePos = oldPos
elif code[codePos] == ']':
return tape[tapePos] != '\0'
elif not skip:
case code[codePos]
of '+': inc tape[tapePos]
of '-': dec tape[tapePos]
of '>': inc tapePos
of '<': dec tapePos
of '.': stdout.write tape[tapePos]
of ',': tape[tapePos] = stdin.readChar
else: discard
inc codePos
当我们遇到[时我们循环递归run直到遇到]时tapePos指向值为\0。
如果您使用的是 Nim 0.11 或更高版本,则会遇到另一个问题:inc与dec对char的操作有溢出(和下溢)检查。这意味着,当我们自减\0时,会出现运行时错误! 但是在 bringfuck 中,我们希望这样的操作可以得到\255。我们可以使用uint8类型来代替char类型,因为无符号整数在 Nim 中没有溢出检查。但这样做将导致我们要在uint8与char之间反复横跳。更方便的方法是定义我们自己的无溢出检查的xinc和xdec函数:
{.push overflowchecks: off.}
proc xinc(c: var char) = inc c
proc xdec(c: var char) = dec c
{.pop.}
我们使用 Nim 的编译指示系统来禁用溢出检查,仅用于这部分代码,而不触及程序其余部分的配置。现在当然有两段 case 需要修改:
of '+': xinc tape[tapePos]
of '-': xdec tape[tapePos]
欧了,我们已经有一个可以跑的 brainfuck 解释器了。为了测试它,我们创建一个包含三个文件的examples 目录:
helloworld.b, rot13.b, mandelbrot.b.
$ nim -r c brainfuck examples/helloworld.b
Welcome to brainfuck
Hello World!
$ ./brainfuck examples/rot13.b
Welcome to brainfuck
You can enter anything here!
Lbh pna ragre nalguvat urer!
ctrl-d
$ ./brainfuck examples/mandelbrot.b
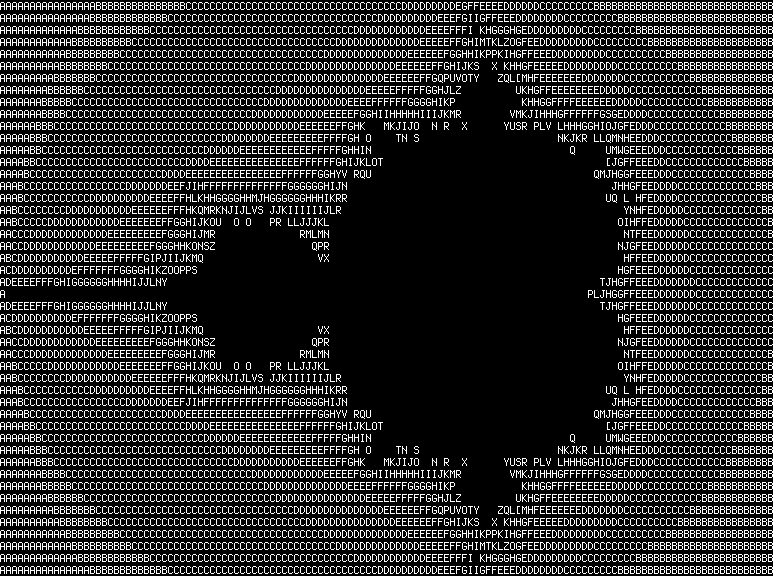
最后一个你会注意到我们的解释器有多慢。编译时添加-d:release参数可以加速,但在我的机子上绘制曼德勃罗集仍然跑了差不多 90 秒。为了实现窜稀的速度,稍后我们将编译 brainfuck 到 Nim ,而不是解释它。Nim 的元编程功能非常适合这一点。
但现在让我们保持简单。我们的解释器正在工作,现在我们可以将我们的工作变成一个可复用的库。我们所要做的就是用一个大proc包围代码:
proc interpret*(code: string) =
var
tape = newSeq[char]()
codePos = 0
tapePos = 0
proc run(skip = false): bool =
...
discard run()
when isMainModule:
import os
echo "Welcome to brainfuck"
let code = if paramCount() > 0: readFile paramStr(1)
else: readAll stdin
interpret code
注意我们在这个函数的声明部分添加了一个*,这表示将它暴露给外部程序调用。除此之外的一切都是不可被外部程序访问的。
文件尾部的代码仍然被编译到二进制文件中。when isMainModule表示只有当文件是主模块时其中的代码才会被编译。快速地使用nimble install来安装我们的 bringfuck 库,我们就可以像下面这样在本机的任何位置调用它了。
import brainfuck
interpret "++++++++[>++++[>++>+++>+++>+<<<<-]>+>+>->>+[<]<-]>>.>---.+++++++..+++.>>.<-.<.+++.------.--------.>>+.>++."
666!此时,我们可以与其他人共享代码,但让我们先添加一些文档:
proc interpret*(code: string) =
## 解释 brainfuck 的 `code` 字符串以及从 stdin 读取并返回结果到 stdout
...
nim doc brainfuck可以构建文档,你就可以在线查看了!
元编程
正如我之前所说的,我们的解释器对于绘制曼德勃罗集的程序来说仍然很慢。让我们写一段在编译时创建 Nim 代码 AST(抽象语法树)的代码:
import macros
proc compile(code: string): PNimrodNode {.compiletime.} =
var stmts = @[newStmtList()]
template addStmt(text): typed =
stmts[stmts.high].add parseStmt(text)
addStmt "var tape: array[1_000_000, char]"
addStmt "var tapePos = 0"
for c in code:
case c
of '+': addStmt "xinc tape[tapePos]"
of '-': addStmt "xdec tape[tapePos]"
of '>': addStmt "inc tapePos"
of '<': addStmt "dec tapePos"
of '.': addStmt "stdout.write tape[tapePos]"
of ',': addStmt "tape[tapePos] = stdin.readChar"
of '[': stmts.add newStmtList()
of ']':
var loop = newNimNode(nnkWhileStmt)
loop.add parseExpr("tape[tapePos] != '\\0'")
loop.add stmts.pop
stmts[stmts.high].add loop
else: discard
result = stmts[0]
echo result.repr
模板addStmt就是为了减少样板。我们还可以在当前使用addStmt的每个位置显式地编写相同的操作。(这正是模板的作用!)parseStmt将一段 Nim 代码从字符串转换为相应的 AST,我们将其存储在列表中。
大多数代码与解释器类似,只是我们现在不执行代码,而是生成代码,并将其添加到语句列表中。[与]更复杂:它们被转换成围绕中间代码的 while 循环。
我们在这里有点作弊,因为我们现在使用固定长度的tape,不再检查不足和溢出。这主要是为了简单的代码。要查看此代码的作用,最后一行的echo result.repr将打印我们生成的 Nim 代码。
通过在static块内调用它来尝试,这将在编译时强制执行:
static:
discard compile "+>+[-]>,."
编译期间将打印生成的代码:
var tape: array[1000000, char]
var codePos = 0
var tapePos = 0
xinc tape[tapePos]
inc tapePos
xinc tape[tapePos]
while tape[tapePos] != '\0':
xdec tape[tapePos]
inc tapePos
tape[tapePos] = stdin.readChar
stdout.write tape[tapePos]
通常用于编写宏的是dumpTree宏,它打印一段代码的 AST(实际的 AST,而不是字符串),例如:
import macros
dumpTree:
while tape[tapePos] != '\0':
inc tapePos
这打印了以下树:
StmtList
WhileStmt
Infix
Ident !"!="
BracketExpr
Ident !"tape"
Ident !"tapePos"
CharLit 0
StmtList
Command
Ident !"inc"
Ident !"tapePos"
这就是我知道我们需要StmtList的原因。在 Nim 中进行元编程时,通常最好使用dumpTree并打印出要生成的代码的 AST。
宏可用于将生成的代码直接插入程序:
macro compileString*(code: string): typed =
## Compiles the brainfuck `code` string into Nim code that reads from stdin
## and writes to stdout.
compile code.strval
macro compileFile*(filename: string): typed =
## Compiles the brainfuck code read from `filename` at compile time into Nim
## code that reads from stdin and writes to stdout.
compile staticRead(filename.strval)
现在,我们可以轻松地将绘制曼德勃罗集的程序编译成 Nim 了:
proc mandelbrot = compileFile "examples/mandelbrot.b"
mandelbrot()
使用完全优化进行编译现在需要相当长的时间(大约4秒),因为绘制曼德勃罗集的程序非常庞大,GCC需要一些时间来优化它。作为回报,程序仅在1秒内运行:
$ nim -d:release c brainfuck
$ ./brainfuck
编译器设置
默认情况下,Nim 使用 GCC 编译其中间 C 代码,但是通常 clang 的编译速度更快,甚至可能产生更高效的代码。这总是值得尝试的。要使用 clang 进行编译,可以使用nim \-d:release \--cc:clang c brainfuck。如果你想默认使用 clang 编译brainfuck.nim,创建一个brainfuck.nim.cfg文件并写入cc = clang。要更改全局默认后端编译器(C 编译器),可以使用同样的方法编辑 Nim 安装目录中的config/nim.cfg文件。
对默认编译器的修改可能导致 Nim 发出我们并不在意的提示信息,我们可以通过在 Nim 的config/nim.cfg文件中设置hints = off。另一个更加烦人的警告是当你把l(小写L)作为标识符时,Nim 它太像数字1了:
a.nim(1, 4) Warning: 'l' should not be used as an identifier; may look like '1' (one) [SmallLshouldNotBeUsed]
如果你不喜欢这个,可以使用warning[SmallLshouldNotBeUsed] = off来关闭它。
Nim的另一个优点是我们可以使用 C 的调试器,比如 GDB。 例如使用nim c \--linedir:on \--debuginfo c brainfuck进行编译,这样就可以用 gdb ./brainfuck来进行调试了。
命令行参数解析
到目前为止,我们一直在手动解析命令行参数。但我们已经安装了 docopt.nim 库,我们可以直接使用它:
when isMainModule:
import docopt, tables, strutils
proc mandelbrot = compileFile("examples/mandelbrot.b")
let doc = """
brainfuck
Usage:
brainfuck mandelbrot
brainfuck interpret [<file.b>]
brainfuck (-h | --help)
brainfuck (-v | --version)
Options:
-h --help Show this screen.
-v --version Show version.
"""
let args = docopt(doc, version = "brainfuck 1.0")
if args["mandelbrot"]:
mandelbrot()
elif args["interpret"]:
let code = if args["<file.b>"]: readFile($args["<file.b>"])
else: readAll stdin
interpret(code)
使用 docopt 的优势在于文档即规范。使用起来 so easy:
$ nimble install
...
brainfuck installed successfully.
$ brainfuck -h
brainfuck
Usage:
brainfuck mandelbrot
brainfuck interpret [<file.b>]
brainfuck (-h | --help)
brainfuck (-v | --version)
Options:
-h --help Show this screen.
-v --version Show version.
$ brainfuck interpret examples/helloworld.b
Hello World!
重构
由于我们的项目正在增长,我们将主要源代码转移到src目录并添加tests目录,我们很快就会需要它。最终的目录结构如下:
$ tree
.
├── brainfuck.nimble
├── examples
│ ├── helloworld.b
│ ├── mandelbrot.b
│ └── rot13.b
├── license.txt
├── readme.md
├── src
│ └── brainfuck.nim
└── tests
├── all.nim
├── compile.nim
├── interpret.nim
└── nim.cfg
这还要求我们更改 nimble 文件:
srcDir = "src"
bin = @["brainfuck"]
为了提高代码的可复用性,我们将其重构。主要关注点就是我们总是从 stdin 读取,然后写入 stdout。
我们扩展了interpret过程,以接收输入和输出流,而不是仅接受code: string作为其参数。这使用提供了FileStream和StringStream的 streams 模块:
## :作者: Dennis Felsing
##
## 该模块实现了 brainfuck 语言的解释器
## 以及将 brainfuck 编译成高效的 Nim 代码的编译器。
##
## 例:
##
## .. 语言:: nim
## import brainfuck, streams
##
## interpret("++++++++[>++++[>++>+++>+++>+<<<<-]>+>+>->>+[<]<-]>>.>---.+++++++..+++.>>.<-.<.+++.------.--------.>>+.>++.")
## # 打印 "Hello World!"
##
## proc mandelbrot = compileFile("examples/mandelbrot.b")
## mandelbrot() # 绘制曼德勃罗集
import streams
proc interpret*(code: string; input, output: Stream) =
## 解释 brainfuck 的 `code` 字符串以及从 `input` 读取并写入到 `output`
##
## 例:
##
## .. 语言:: nim
## var inpStream = newStringStream("Hello World!\n")
## var outStream = newFileStream(stdout)
## interpret(readFile("examples/rot13.b"), inpStream, outStream)
我也添加了全面的文档,其中包括示例代码。你可以查看完整文档。
大多数代码保持不变,除了处理 bringfuck 操作.和,,现在使用output代替stdout,使用input代替stdin:
of '.': output.write tape[tapePos]
of ',': tape[tapePos] = input.readCharEOF
为什么我们要使用这个奇怪的readCharEOF而不是readChar呢?在大多数操作系统上EOF(end of file,文件结束)代表-1。我们的 bringfuck 语言巧妙地运用了它。这意味着我们的 bringfuck 并不能在所有系统上运行。同时,streams 模块力求独立于平台,因此当我们读取到EOF时它将返回0。我们使用readCharEOF以显眼的方式将其转换为 brainfuck 的-1:
proc readCharEOF*(input: Stream): char =
result = input.readChar
if result == '\0': # Streams 读取到 EOF 时返回的 1
result = '\255' # BF 假设 EOF 是 -1
此时,您可能会注意到Nim中标识符声明的顺序很重要。如果您在interpret下面声明readCharEOF,则不能在interpret中使用它。我个人力求遵循这一点,因为它在每个模块中创建了从简单代码到更复杂代码的层次结构。如果您仍然想规避这一点,请通过在interpret上方添加此声明来拆分readCharEOF的声明和定义:
proc readCharEOF*(input: Stream): char
像以前一样使用解释器的代码同样 easy:
proc interpret*(code, input: string): string =
## 解释 brainfuck 的 `code` 字符串以及从 `input` 读取并直接返回结果
var outStream = newStringStream()
interpret(code, input.newStringStream, outStream)
result = outStream.data
proc interpret*(code: string) =
## 解释 brainfuck 的 `code` 字符串以及从 stdin 读取并返回结果到 stdout
interpret(code, stdin.newFileStream, stdout.newFileStream)
现在可以使用interpret函数返回字符串。这对于以后的测试很重要:
let res = interpret(readFile("examples/rot13.b"), "Hello World!\n")
interpret(readFile("examples/rot13.b")) # 输出到 stdout
对于编译器来说,清理有点复杂。首先,我们必须将input和output作为字符串,这样使用这个函数的人就可以使用他们想要的任何流:
proc compile(code, input, output: string): PNimrodNode {.compiletime.} =
要将输入和输出流初始化为传递的字符串,还需要两个附加语句:
addStmt "var inpStream = " & input
addStmt "var outStream = " & output
当然,现在我们必须使用outStream和inpStream而不是 stdout 和 stdin,以及使用readCharEOF而不是readChar。注意,我们可以从解释器直接调用readCharEOF函数,而无需重复代码:
of '.': addStmt "outStream.write tape[tapePos]"
of ',': addStmt "tape[tapePos] = inpStream.readCharEOF"
我们还添加了一条语句,如果我们库的用户错误地使用了它,该语句将中止编译,并显示一条非常 amazing 的错误消息:
addStmt """
when not compiles(newStringStream()):
static:
quit("Error: Import the streams module to compile brainfuck code", 1)
"""
要将新的compile函数连接到再次使用 stdout 和 stdin 的compileFile宏,我们可以这样写:
macro compileFile*(filename: string): typed =
compile(staticRead(filename.strval),
"stdin.newFileStream", "stdout.newFileStream")
要从输入字符串读取并写回输出字符串,可以执行以下操作:
macro compileFile*(filename: string; input, output: untyped): typed =
result = compile(staticRead(filename.strval),
"newStringStream(" & $input & ")", "newStringStream()")
result.add parseStmt($output & " = outStream.data")
这段笨拙的代码允许我们像这样编写一个编译用的rot13函数,将input字符串和result组合到编译的程序:
proc rot13(input: string): string =
compileFile("../examples/rot13.b", input, result)
echo rot13("Hello World!\n")
方便起见我对compileString做了同样的操作。你可以在 Github 查看brainfuck.nim的完整代码。
测试
在 Nim 中测试代码有两种主要方法,本文将介绍这两种方法。对于小块的代码,您可以在文件末尾添加when isMainModule语句并在其中使用assert断言语句进行调试。这确保了当模块用作库时不会执行测试代码。
在Nim中,可以使用--assertions:off关闭常规断言,这在编译发布版本时 Nim 会自动设置。因此,我们使用doAssert语句而不是assert语句,这样即使在发布版本中也不会对其进行优化。您可以在许多标准库模块的末尾找到这样的测试:
when isMainModule:
doAssert align("abc", 4) == " abc"
doAssert align("a", 0) == "a"
doAssert align("1232", 6) == " 1232"
doAssert align("1232", 6, '#') == "##1232"
对于更大的项目使用 unittest 模块更加方便。
我们将测试分为tests/目录中的3个文件:
tests/interpret.nim用于测试解释器。我们定义了一个新的测试模块,包含两个测试部分,每个测试部分测试不同的输入并检查输出:
import unittest, brainfuck
suite "brainfuck interpreter":
test "interpret helloworld":
let helloworld = readFile("examples/helloworld.b")
check interpret(helloworld, input = "") == "Hello World!\n"
test "interpret rot13":
let rot13 = readFile("examples/rot13.b")
let conv = interpret(rot13, "How I Start\n")
check conv == "Ubj V Fgneg\n"
check interpret(rot13, conv) == "How I Start\n"
类似的,tests/compile.nim用于测试编译器:
import unittest, brainfuck, streams
suite "brainfuck compiler":
test "compile helloworld":
proc helloworld: string =
compileFile("../examples/helloworld.b", "", result)
check helloworld() == "Hello World!\n"
test "compile rot13":
proc rot13(input: string): string =
compileFile("../examples/rot13.b", input, result)
let conv = rot13("How I Start\n")
check conv == "Ubj V Fgneg\n"
check rot13(conv) == "How I Start\n"
注意,我们在调用编译器时使用的是../examples/,而不是像调用解释器时使用的examples/。这是因为编译器使用的staticRead是将调用它的程序所在路径作为起始路径的,也就是tests/。
要一起执行这两个测试,我们只需使用nimble test,它会自动构建并执行tests目录中的源文件:
$ nimble test
Executing task test in /home/d067158/git/nim-brainfuck/brainfuck.nimble
Verifying dependencies for brainfuck@1.1
Info: Dependency on docopt@>= 0.1.0>= 0.1.0 already satisfied
Verifying dependencies for docopt@0.6.5
Compiling /home/d067158/git/nim-brainfuck/tests/compile.nim (from package brainfuck) using c backend
Hint: used config file '/media/nim/config/nim.cfg' [Conf]
[Suite] brainfuck compiler
[OK] compile helloworld
[OK] compile rot13
Success: Execution finished
Verifying dependencies for brainfuck@1.1
Info: Dependency on docopt@>= 0.1.0>= 0.1.0 already satisfied
Verifying dependencies for docopt@0.6.5[email protected]
Compiling /home/d067158/git/nim-brainfuck/tests/interpret.nim (from package brainfuck) using c backend
Hint: used config file '/media/nim/config/nim.cfg' [Conf]
[Suite] brainfuck interpreter
[OK] interpret helloworld
[OK] interpret rot13
Success: Execution finished
Success: All tests passed
我们的库变得非常 Amazing 了!这样我们就有了一个功能齐全的库、二进制文件和测试框架。
是时候在 Github 上发布所有内容了,并提交一个拉取请求,让brainfuck包含在 nimble packages 中了。一旦软件包被接受,您可以在官方列表中找到它,并使用 nimble 搜索和安装:
$ nimble search brainfuck
brainfuck:
url: https://github.com/def-/nim-brainfuck.git (git)
tags: library, binary, app, interpreter, compiler, language
description: A brainfuck interpreter and compiler
license: MIT
website: https://github.com/def-/nim-brainfuck
$ nimble install brainfuck
自动更新 Nim
CircleCI 可实现 Nim 的自动更新,以便每当 Nim 更新时自动编译和运行我们的测试并推送到 Github。由于 CircleCI 并不了解 Nim 本身,我们必须教它如何引导编译器:
dependencies:
override:
- |
if [ ! -x ~/nim/bin/nim ]; then
git clone -b devel --depth 1 https://github.com/nim-lang/Nim ~/nim/
git clone --depth 1 https://github.com/nim-lang/csources ~/nim/csources/
cd ~/nim/csources; sh build.sh; cd ..; rm -rf csources
ln -fs ~/nim/bin/nim ~/bin/nim
bin/nim c koch; ./koch boot -d:release; ./koch nimble
ln -fs ~/nim/bin/nimble ~/bin/nimble
else
cd ~/nim; git fetch origin
git merge FETCH_HEAD | grep "Already up-to-date" || (bin/nim c koch; ./koch boot -d:release; ./koch nimble)
fi
cache_directories:
- "~/bin/"
- "~/nim/"
- "~/.nimble/"
compile:
override:
- nimble build -y
这会自动使编译器保持最新版本。如果你想使用最近发布的 Nim 版本,而不是开发版本的,使用master分支而不是devel分支进行git clone。现在就可以直接运行测试了:
test:
override:
- nimble test -y
构建状态徽章 可以像这样添加到
可以像这样添加到readme.md中:
# Brainfuck for Nim [](https://circleci.com/gh/def-/nim-brainfuck)
再次查看 Github 页面以获得最终结果,并查看 CircleCI 页面以获得实际构建。
写在最后
我们的 Nim 之旅到此为止,希望你喜欢它并且像我一样发现了它的乐趣所在。
如果你还想进一步了解 Nim,我最近写了《What is special about Nim?》与《What makes Nim practical?》,并且有“extensive collection of small programs”。
如果你想以更标准的方式来入坑 Nim,《Official Tutorial》与《Nim by Example》可以指导你。
“Nim community”实在太友善且乐于助人了,谢谢为本文档捉虫与提意见的每一位,特别鸣谢 Flaviu Tamas,Andreas Rumpf 以及 Dominik Picheta。你们真的,我哭死。
译者注:感谢原文作者的支持,原文请到 How I Start。
同时,本文档的翻译仍然有许多不足,出于缺少 Nim 的中文资料我只能对一些词语使用直译。
本文使用CC BY-NC-ND进行许可,转载请注明作者及译者

 浙公网安备 33010602011771号
浙公网安备 33010602011771号