大数据技术连载-03-1-大数据的存储-分布式文件系统Hadoop的HDFS的原理
03-HDFS-01-模块结构
hadoop的存储方式,有点像scci硬盘,坏一个节点无所谓。随时插拔增减。
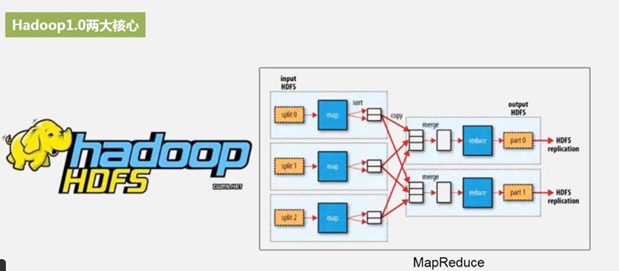
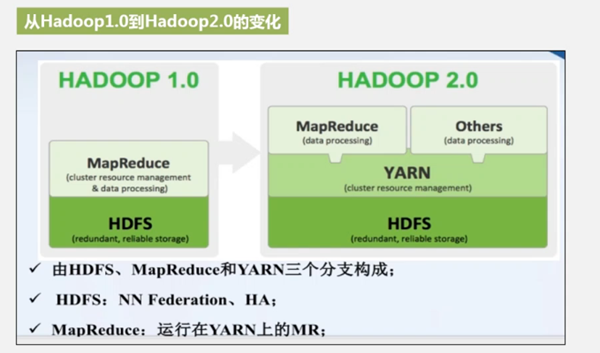
1.0 版本里,计算和资源调度在一个模块里。
2.0版本里:
资源调度YARN,独立成一个模块。MapReduce是YARN支持的第一个计算框架,是批处理硬盘计算框架。除此之外,还支持批处理内存计算的Spark和流式计算的Storm。
另外,HDFS也进行了优化。出现命名服务的分区联邦机制,NN Federation,高可用机制。

国内的星环最合适。
03-HDFS-02-的缺陷
读取速度慢,高延迟。
靠namenode索引元数据,如果大量小文件,会造成namenode的庞大。
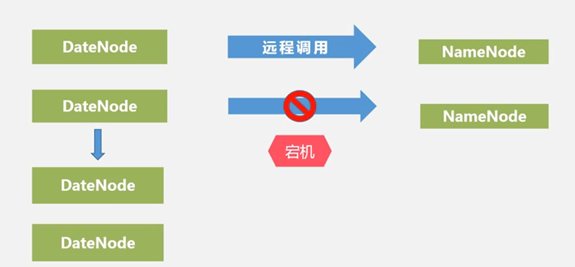
namenode是中心,成为性能瓶颈。
1.0版本,namenode有单点故障风险。2.0中有了热备。
只能添加,不能随意修改
03-HDFS-03-存储结构
块
每个块最少64M,比OS的块几十K大多了。
设计目的:
为了支持大规模数据存储。
为了降低寻址开销。namenode---->块---->数据。如果块小,则namenode会很大。
优点:
大文件分割成块之后,如果超大文件超出磁盘大小之后,就无法存储了。分割成块之后,可以分块存储。
可以按块进行备份。
03-HDFS-04-组件
(1) 名称节点
① 目录,元数据。
存储着文件的块在哪些机器上存储。
② 名称节点常驻内存。

③ 名称节点的内部机制:
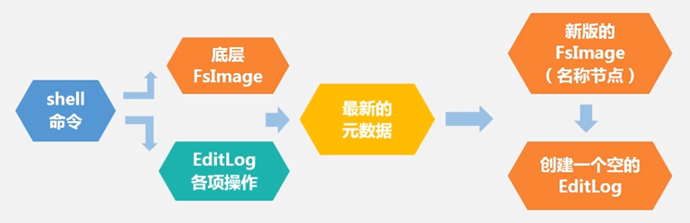
秉承数据仓库的概念,不修改,只增加。
启动时,主名称节点,加载硬盘中的FsImage,加载硬盘中的EditLog,然后进行合并,生成新的FsImage,同时把EditiLog清空。EditiLog相当于缓存目的的工作目录,而且是只增加。
当运行一段时间后,主名称节点的EditiLog可能会变大。此时,次名称节点开始拉取主名称节点的数据,并在自己里进行合并。合并完成之后,回传给主节点,主节点的EditLog又保持小型状态。
(2) 数据节点
存储实际数据
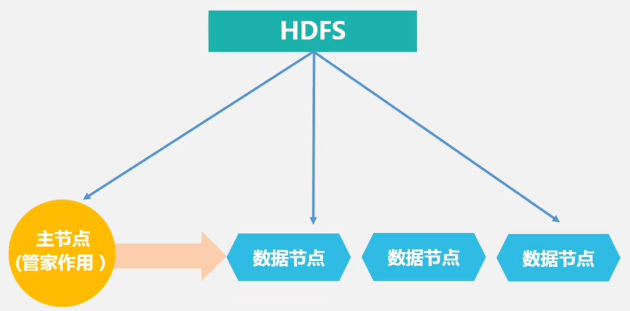
03-HDFS-05-体系结构
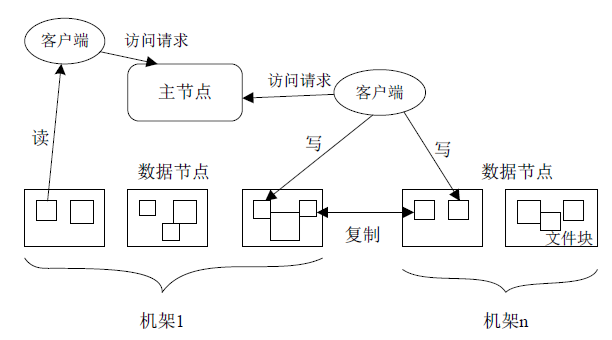
(1) 访问路径
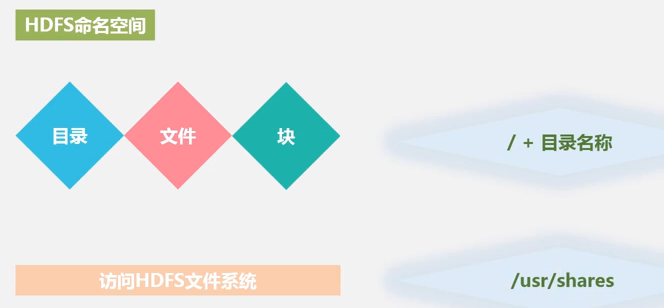
(2) 命名空间
03-HDFS-06-存储原理
面向块
(1) 冗余策略
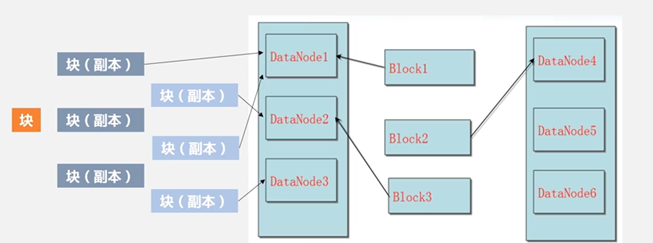
默认,每个块都冗余保存3份。因此,可以做到并发3读。
因为,HDFS的设计目的就是用廉价硬盘存储,因此需要很高的故障恢复能力。
(2) 写策略
(3) 读策略
物理位置就近读取。
(4) 迁移策略
数据节点失去心跳之后,HDFS系统会找到备份的数据,再复制一份出来。
即便没有故障,HDFS系统也会根据负载压力的变化进行数据节点的自动复制迁移。
(5) 数据校验策略
客户端读取一个块之后,会生成新的校验码,与存储的校验码比较。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号