2018年香港电影票房Top10
这次的数据分析作业差点就交不上了,要不是某天和好友聊天时,不小心提到了,我都不知道有这回事,真的是太太太恐怖了。
代码如下:
import requests
from bs4 import BeautifulSoup
import matplotlib.pyplot as plt
url='https://www.sohu.com/a/287919877_100146931'
r=requests.get(url)
try:
r.raise_for_status()
r.encoding=r.apparent_encoding
data=r.text
except:
print('ERROR')
soup=BeautifulSoup(data,'html.parser')
a=soup.find_all('li')
for i in range(12,22):
print(a[i].get_text())
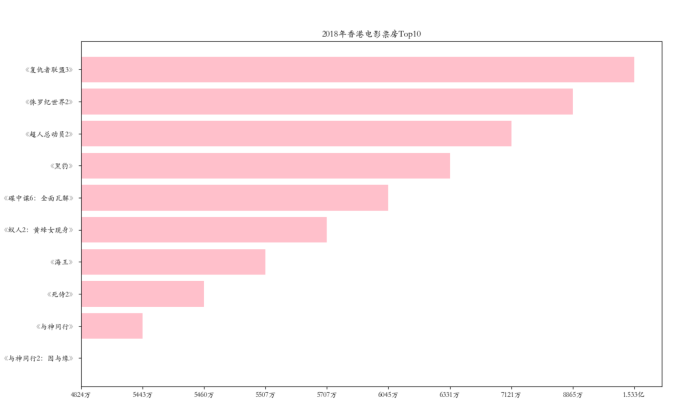
list_1=['1.533亿','8865万','7121万','6331万','6045万','5707万','5507万','5460万','5443万','4824万']
list_2=['《复仇者联盟3》','《侏罗纪世界2》','《超人总动员2》','《黑豹》',' 《碟中谍6:全面瓦解》','《蚁人2:黄蜂女现身》','《海王》','《死侍2》','《与神同行》','《与神同行2:因与缘》']
x=[]
y=[]
for i in range(10):
y.append(list_1[i])
x.append(list_2[i])
x.reverse()
y.reverse()
plt.barh(range(len(y)),y,tick_label=x,color='pink')
plt.rcParams['font.sans-serif'] = ['STKaiTi']
plt.rcParams['axes.unicode_minus'] = False
plt.title("2018年香港电影票房Top10")
plt.show()
这是图片(十分少女的粉色):

 浙公网安备 33010602011771号
浙公网安备 33010602011771号