为啥 Redis 使用跳表而不是红黑树
开发者所说,他为何选用 skiplist The Skip list
There are a few reasons:
- They are not very memory intensive. It's up to you basically. Changing parameters about the probability of a node to have a given number of levels will make then less memory intensive than btrees.
- A sorted set is often target of many ZRANGE or ZREVRANGE operations, that is, traversing the skip list as a linked list. With this operation the cache locality of skip lists is at least as good as with other kind of balanced trees.
- They are simpler to implement, debug, and so forth. For instance thanks to the skip list simplicity I received a patch (already in Redis master) with augmented skip lists implementing ZRANK in O(log(N)). It required little changes to the code.
About the Append Only durability & speed, I don't think it is a good idea to optimize Redis at cost of more code and more complexity for a use case that IMHO should be rare for the Redis target (fsync() at every command). Almost no one is using this feature even with ACID SQL databases, as the performance hint is big anyway.
About threads: our experience shows that Redis is mostly I/O bound. I'm using threads to serve things from Virtual Memory. The long term solution to exploit all the cores, assuming your link is so fast that you can saturate a single core, is running multiple instances of Redis (no locks, almost fully scalable linearly with number of cores), and using the "Redis Cluster" solution that I plan to develop in the future.
简言之,跳表和时间复杂度几乎和红黑树一样,而且实现起来简单。
跳表
往原始链表加多几级索引的话,查找效率将会进一步提升。这种链表加多级索引的结构,就叫做跳表。
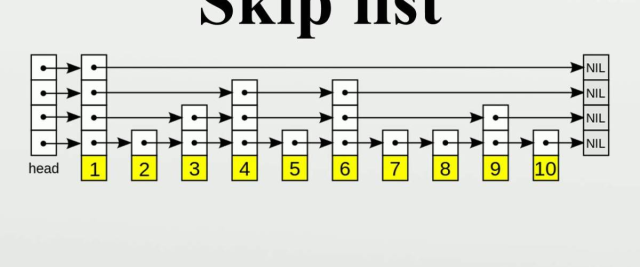
举个例子,查询 11 时,只需要 O(logn) 的复杂度
删除就得先查找,找到后从下往上删除。
插入的时候,首先要进行查询,然后从最底层开始,插入被插入的元素。然后看看从下而上,是否需要逐层插入。可是到底要不要插入上一层呢?跳表的思路是抛硬币,听天由命,产生一个随机数,50%概率再向上扩展,否则就结束。这样子,每一个元素能够有X层的概率为0.5^(X-1)次方。反过来,第X层有多少个元素的数学期望大家也可以算一下。
JS 实现跳表代码
出自使用JavaScript实现SkipList这种数据结构
/**
* author dreamapplehappy
*/
// 代码使用了ES6以及更高版本的JavaScript来表示,需要使用Babel之类的工具处理一下才可以在Node或者浏览器中运行
// 定义了跳表索引的最大级数
const MAX_LEVEL = 16;
/**
* 定义Node类,用来辅助实现跳表功能
*/
class Node{
// data属性存放了每个节点的数据
data = -1;
// maxLevel属性表明了当前节点处于整个跳表索引的级数
maxLevel = 0;
// refer是一个有着MAX_LEVEL大小的数组,refer属性存放着很多个索引
// 如果用p表示当前节点,用level表示这个节点处于整个跳表索引的级数;那么p[level]表示在level这一层级p节点的下一个节点
// p[level-n]表示level级下面n级的节点
refer = new Array(MAX_LEVEL);
}
/**
* 定义SkipList类
*/
class SkipList{
// levelCount属性表示了当前跳表索引的总共级数
levelCount = 1;
// head属性是一个Node类的实例,指向整个链表的开始
head = new Node();
// 在跳里面插入数据的时候,随机生成索引的级数
static randomLevel() {
let level = 1;
for(let i = 1; i < MAX_LEVEL; i++) {
if(Math.random() < 0.5) {
level++;
}
}
return level;
}
/**
* 向跳表里面插入数据
* @param value
*/
insert(value) {
const level = SkipList.randomLevel();
const newNode = new Node();
newNode.data = value;
newNode.maxLevel = level;
const update = new Array(level).fill(new Node());
let p = this.head;
for(let i = level - 1; i >= 0; i--) {
while(p.refer[i] !== undefined && p.refer[i].data < value) {
p = p.refer[i];
}
update[i] = p;
}
for(let i = 0; i < level; i++) {
newNode.refer[i] = update[i].refer[i];
update[i].refer[i] = newNode;
}
if(this.levelCount < level) {
this.levelCount = level;
}
}
/**
* 查找跳表里面的某个数据节点,并返回
* @param value
* @returns {*}
*/
find(value) {
if(!value){return null}
let p = this.head;
for(let i = this.levelCount - 1; i >= 0; i--) {
while(p.refer[i] !== undefined && p.refer[i].data < value) {
p = p.refer[i];
// 标记1,此处用于文章的说明
}
}
if(p.refer[0] !== undefined && p.refer[0].data === value) {
return p.refer[0];
}
return null;
}
/**
* 移除跳表里面的某个数据节点
* @param value
* @returns {*}
*/
remove(value) {
let _node;
let p = this.head;
const update = new Array(new Node());
for(let i = this.levelCount - 1; i >= 0; i--) {
while(p.refer[i] !== undefined && p.refer[i].data < value){
p = p.refer[i];
}
update[i] = p;
}
if(p.refer[0] !== undefined && p.refer[0].data === value) {
_node = p.refer[0];
for(let i = 0; i <= this.levelCount - 1; i++) {
if(update[i].refer[i] !== undefined && update[i].refer[i].data === value) {
update[i].refer[i] = update[i].refer[i].refer[i];
}
}
return _node;
}
return null;
}
// 打印跳表里面的所有数据
printAll() {
let p = this.head;
while(p.refer[0] !== undefined) {
// console.log(p.refer[0].data)
p = p.refer[0];
}
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号